本文是发表在TMI2022年6月的工作,提出了一种简单有效的数据增强方法方法用于少数据量(几千或者几万个样本)多模态(医学图像问答)任务。
代码链接:
摘要
医学视觉问题回答(VQA)旨在正确的回答与给定医学图像相关的临床问题。然而,由于医疗数据的人工注释费用昂贵,缺乏标记的数据限制了医学VQA的发展。在本文中,我们提出了一种简单而有效的数据增强方法——VQAMix,以缓解数据限制问题。具体来说,VQAMix通过线性组合一堆VQA样本产生更多的标记训练样本,这可以很容易地嵌入到任何视觉语言模型中以提高性能。然而,混合两个VQA样本会在不同样本的图像和问题之间构建新的联系,这将导致这些编造的图像-问题对的答案缺失或毫无意义。为了解决答案缺失的问题,我们首先开发了带缺失标签的学习(LML)策略,它大致上排除了缺失的答案。为了缓解无意义的答案问题,我们设计了带条件混合标签的学习(LCL)策略,该策略进一步利用语言类型的先决条件,迫使混合对拥有属于同一类别的合理答案。在VQA-RAD和PathVQA基准山的实验结果表明,我们提出的方法明显提高了基线的性能,在两个骨干的平均结果上跟别提高了7%和5%,更重要的是,VQAMix可以提高置信度和模型的可解释性,这对医学VQA模型的实际应用意义重大。代码可以在以下链接访问。GitHub - haifangong/VQAMix: [IEEE TMI'22] VQAMix: Conditional Triplet Mixup for Medical Visual Question Answering标签:视觉问题回答,VQAMix,医学图像,视觉和语言,医学QA,数据增强
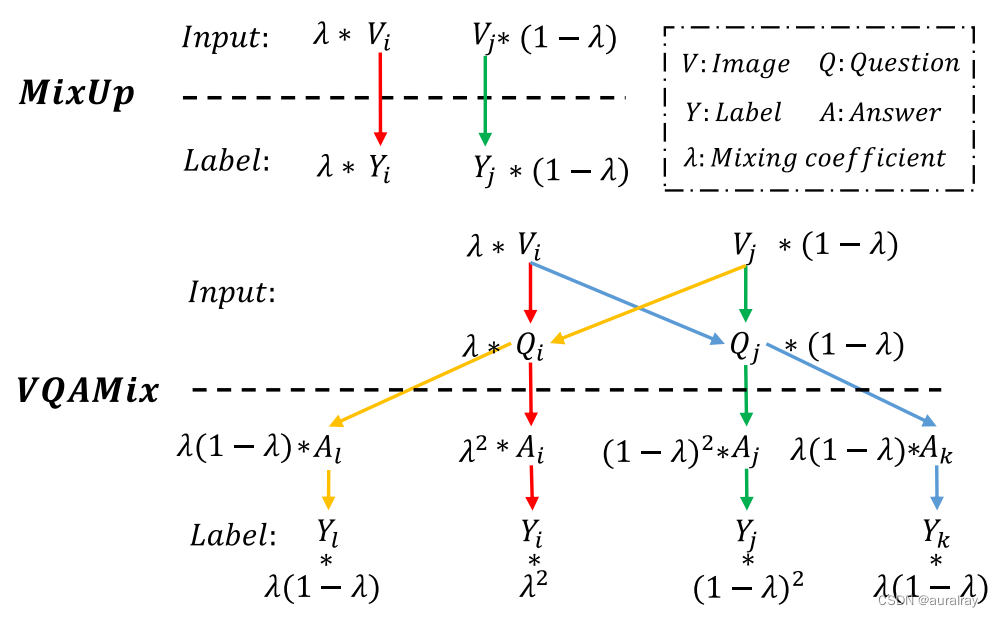
MixUp与VQAMix对比示意图。在MixUp中,按随机权重缩放的两幅图像被线性组合,它们对应的标签用相同的权重进行融合。在VQAMix中,两个图像-问题对进行线性组合。
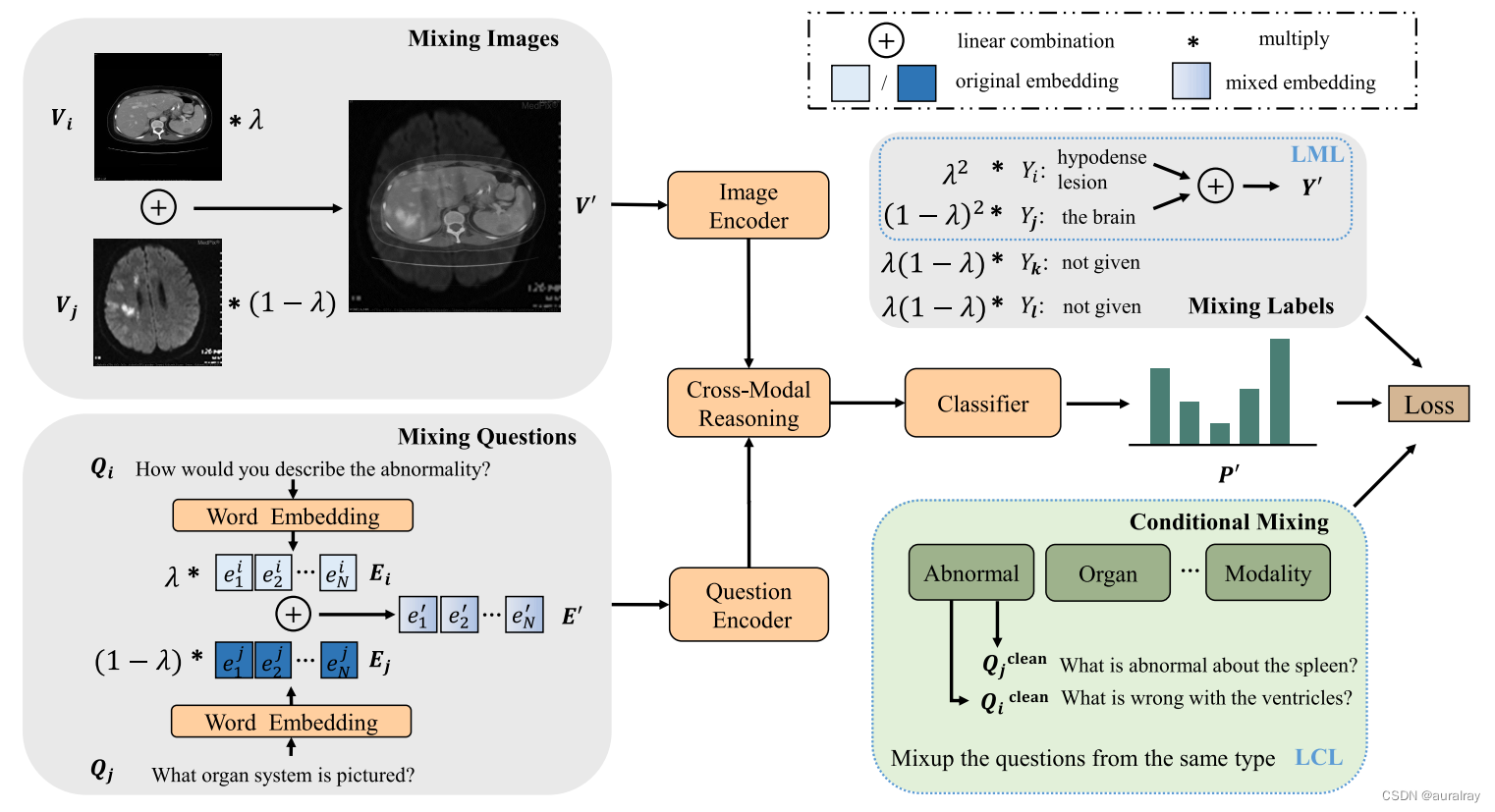
本文所提出的通过缺失标签学习(LML)和条件混合标签学习(LCL)策略增强的VQAMix概述。两个VQA样本在训练阶段线性组合。为了保证混合标签能够用于监督VQA模型的学习,在缺少标签下的学习(LML)和在条件混合标签的学习(LCL)方案都将这两种未指定的标签进行丢弃,以解决标签缺失问题。此外,为了避免无意义的答案,LCL方案进一步利用问题的类别来避免模型遭受无意义的混合标签影响。
方法:
1.三元组混合
设{V, Q, A}表示VQA数据集中的一个样本,其中V、Q、A分别表示输入图像、给定问题和对应的答案。答案A被编码为一个独热向量Y。给定两个VQA训练样本{{V_i, Q_i, A_i}, {V_j, Q_j, A_j}}, VQAMix用于生成一个新的训练样本{V', Q', a '}。首先,VQAMix从Beta分布中获得混合系数lambda,其中alpha是一个超参数。然后,对两个输入图像V_i, V_j进行线性组合,混合系数lambda,得到混合图像V':
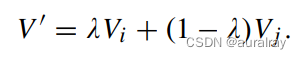
与图像混合不同,问题混合并不应用于输入空间,因为问题的输入空间是不连续的。因此,VQAMix在嵌入空间中采用两个输入问题的线性组合:
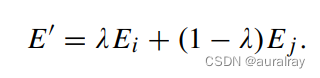
其中E'是混合问题的嵌入表示,E_i和E_j表示问题Q_i和Q_j的嵌入表示。更具体地说,E_i和E_j由以下过程提取。首先,将2个输入问题裁剪为N单词,当长度小于N时,对其进行零填充;因此,我们得到Q_i={w^i_1, w^i_2,…, w^i_N} and Q_j={w^j_1, w^j_2,…w ^ j_N } 。然后,利用词向量方法将每个词映射为D-dim向量,得到两个问题的表示向量E_i={e^i_1, e^i_2,…, e^i_N} 和 E_j={e^j_1, e^j_2,…e ^ j_N } 。
给定混合图像和混合问题,存在4对图像-问题对,包括{V_i, Q_i}, {V_j, Q_j}, {V_i, Q_j},和{V_j, Q_i}。{V_i, Q_i}和{V_j, Q_j}的答案分别是A_i和A_j,而{V_i, Q_j}和{V_j, Q_i}的答案没有给出。我们假设{V_i, Q_j}和{V_j, Q_i}的答案是A_k和A_l。答案的标签 {V_i, Q_i }, {V_j, Q_j }, {V_i, Q_j },和 {V_j, Q_i }是Y_{i}, Y_ {j} , Y_ {k},和Y_分别{l} 。那么标签混合过程可以构建为:
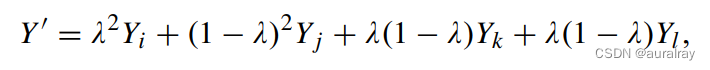
每个标签的系数表示对应的图像-问题对的概率分布(也参见图1)。
由于答案A_k和A_l是缺失的,直接使用Y'来监督VQA模型的学习可能不是最优的。此外,混合标签可能没有意义,因为没有(V', Q')的混合类型的约束。基于这些考虑,我们提出了带条件三元组混合方案来处理上述问题。
2 带条件的三元组混合
2.1学习缺失标签
为了处理标签缺失问题,本文提出了一种简单直接的策略Learning with missing Labels (LML),直接丢弃这些标签,表示为:
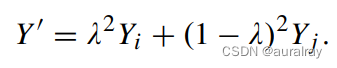
使用这种策略,我们计算预测得分S'(在sigmoid函数之后)和噪声标签Y'之间的二元交叉熵损失来训练VQA模型:
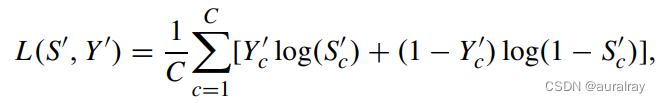
其中C是候选答案集中答案的个数。
2.2基于条件混合标签的学习
在LML策略中,标签Y'中存在噪声成分,可能会对深度神经网络的性能产生负面影响。为了解决这个问题,本文提出了另一种使混合标记有意义的策略,称为Learning with Conditional-mixed labels (LCL)。
考虑到标签缺失本质上是由于混合了不同领域的答案造成的,本文提出条件混合,使模型在条件混合标签下进行学习。具体来说,有三种方法可以实现条件混合:(1)只混合具有相同成像模型的(v, q, a)元组;(2)只混淆相同问题类别的(v, q, a)元组;(3)将(v, q, a)元组与相同的图像模型和问题类别混合。
然而,我们应该使用哪种策略来进行有意义的数据增强?本文提出将(v, q, a)元组与同一类别的问题进行混合,基于以下考虑:(1)与问题和答案相比,问题和答案在隐空间中更接近,问题的类型可以直接反映答案的类型,从而使混合标签具有意义;(2)不同模态的图像易于区分,且在医学VQA任务中图像的局限性比问题对要大得多,因此不同模态的mixup图像可以提高图像的多样性;(3)由于有些问题是关于图像的模型和器官的,约束来自同一模型和器官的图像可以减少训练过程中的不确定性,从而使模型在这些样本上过拟合。例如,假设有两个混合对(q1:成像的模态是什么;v1: CT成像;(q2:这个图形可能属于什么形态;v2:核磁共振成像;a2: MRI)。如果我们混合这些对,模型可以更好地从不同模态的图像中学习特征表示。因此,我们提出了条件问题约束,即特定类别问题集Q,可以表示为:
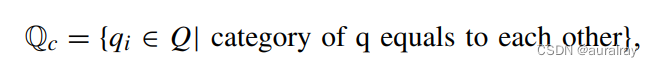
其中问题的类别是通过相应数据集中的“问题类型”获得的。
基于将(v, q, a)元组与问题q混合在同一个mathbb{q}_c中,混合类别的答案可能是有意义的,我们将有意义的答案的标签定义为Y " 。使用Y " ,我们可以计算忽略存在未知答案的损失,以减少噪声的影响:
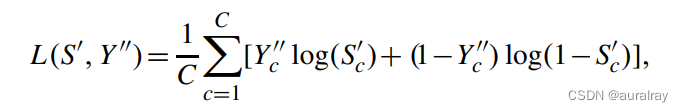
其中C是候选答案集中答案的个数。因此,设B为批次大小,训练批次的最终损失为:
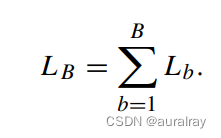
实验:
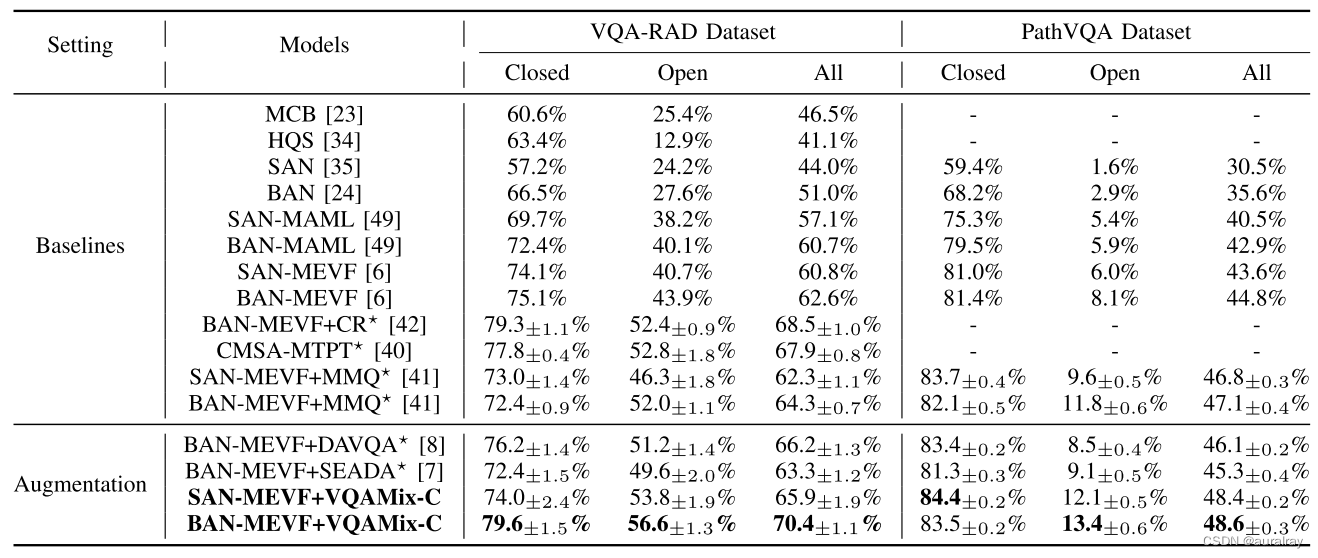
在VQA-RAD测试集和PathVQA测试集上与最新方法进行对比实验。^star表示在我们的设备上使用5个不同的种子重新实现的结果。最好的结果显示在粗体中。
总结:本文提出一种新的数据增强方法VQAMix,以缓解医疗VQA中的数据限制。从技术上讲,VQAMix将两个训练样本与一个随机系数相结合,以提高训练数据的多样性,而不依赖于外部数据。为了缓解(v, q, a)元组组合带来的固有答案缺失问题和无意义答案问题,首先采用缺失标签策略进行学习,粗略地丢弃缺失答案;在此基础上,利用语言类别的先验知识加入条件混合约束,进一步建立了条件-混合标签的学习方法,使标记具有意义。在VQA-RAD和PathVQA基准上的广泛实验结果表明,所提出的方法为不同的模型带来了显著的增益。此外,VQAMix可以改进置信度校准,使预测得分更好地反映准确性,并提供更合理的类激活图,这对医学VQA模型在实际应用中具有意义。作为一种通用的解决方案,VQAMix可以进一步运用于各类多模态数据的增强与正则化(例如:分子/蛋白质数据,病理图像/基因组数据),具有很高的现实意义。