文章目录
摘要
在学习web开发时,面对的总是一个一个技术,这让我感觉很割裂,不踏实。因此,我想了解web开发的发展历程,通过不同历史时期技术上、需求上的变化,更好的把握核心。
主要内容

web2.0:ajax。结束了网页只能整存整取的时代,允许网页实现局部刷新。增强了网页的交互性,逼近桌面应用。
移动互联网:2010年,随着智能手机的普及。
万物互联网:在移动互联网的基础上继续发展。元宇宙
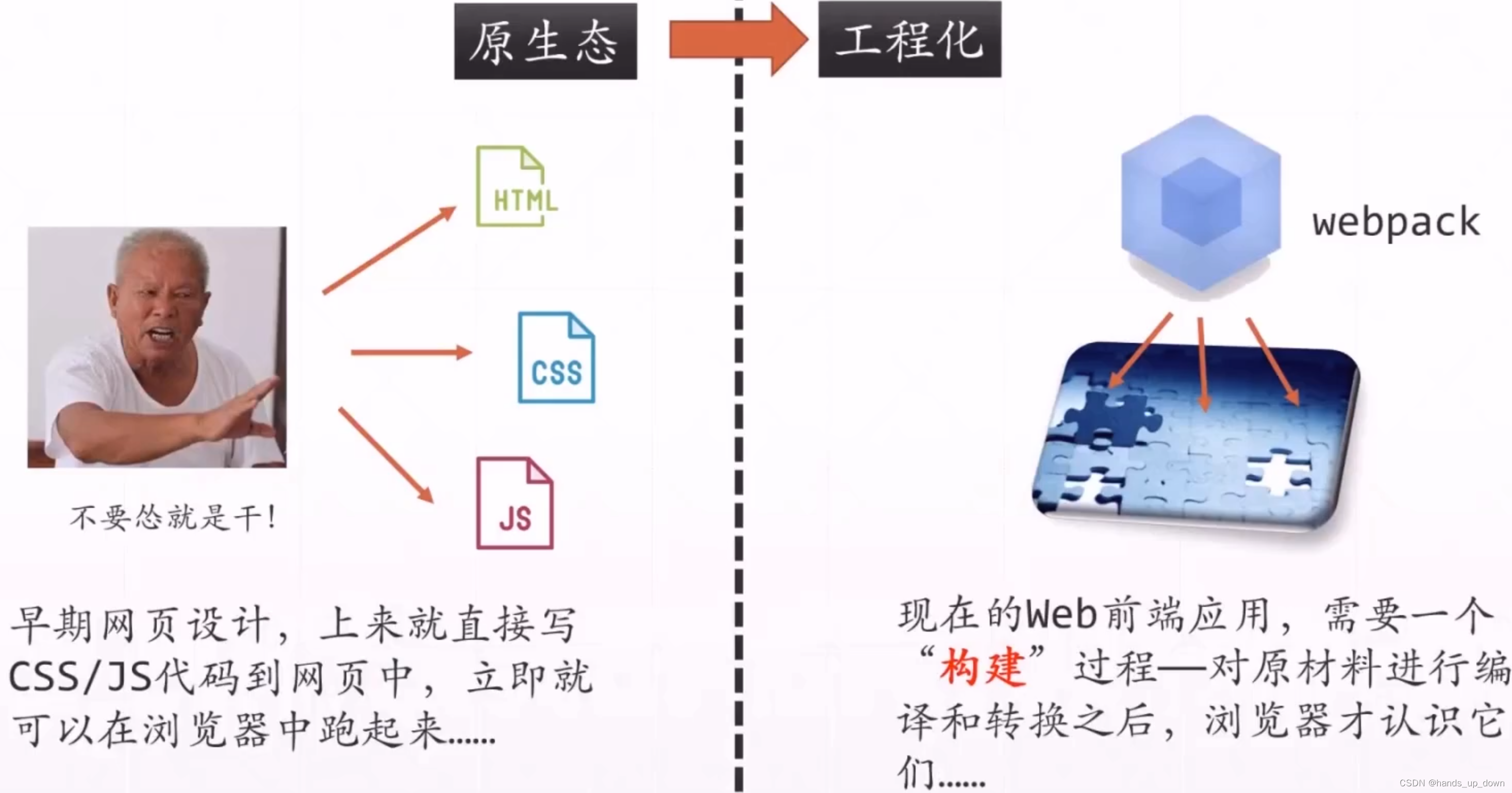
不同的时代对应不同的技术
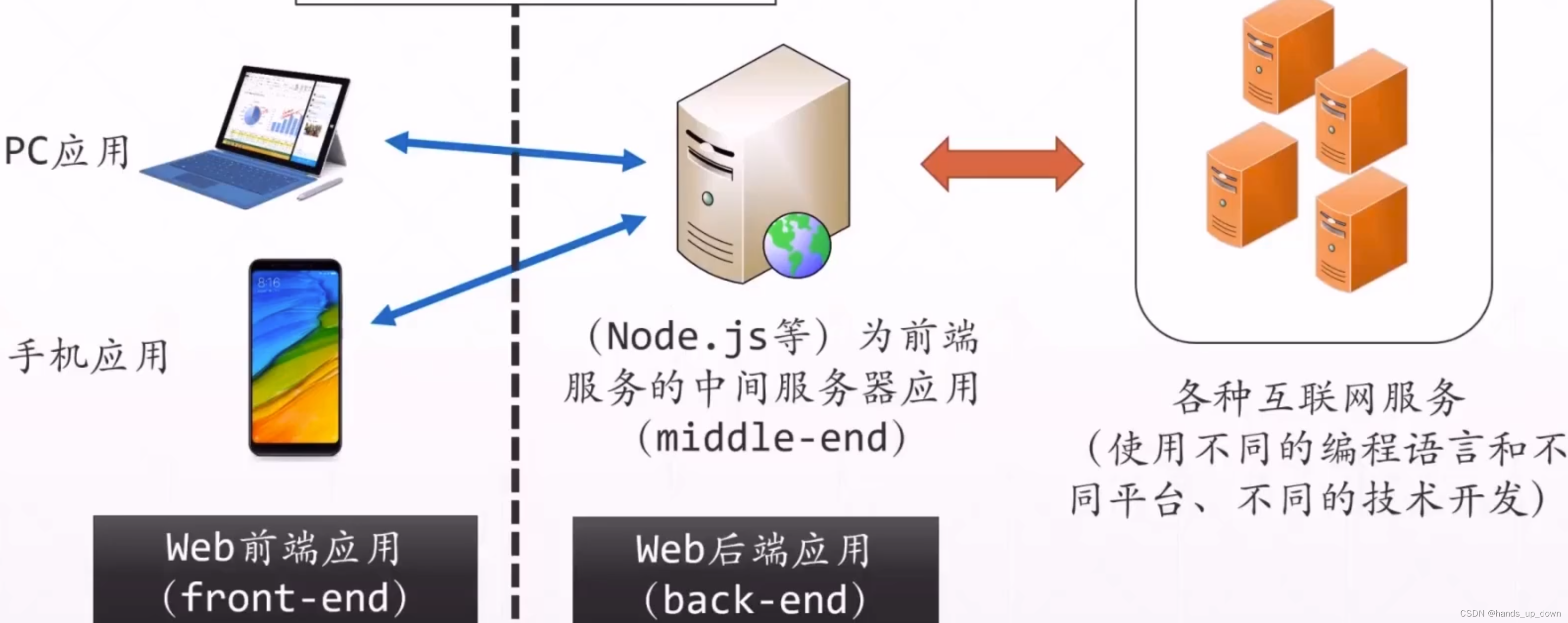
前端技术的中间阶段-单页面应用

数据使用json格式进行传输,就是用一个json对象存储各项数据,客户端和服务端都有专门的用于解析json对象的工具。简单说,就是使用json统一了数据传输的格式
vue:既可以做前后端分离的项目,也可以应用于单页面应用,中庸之道
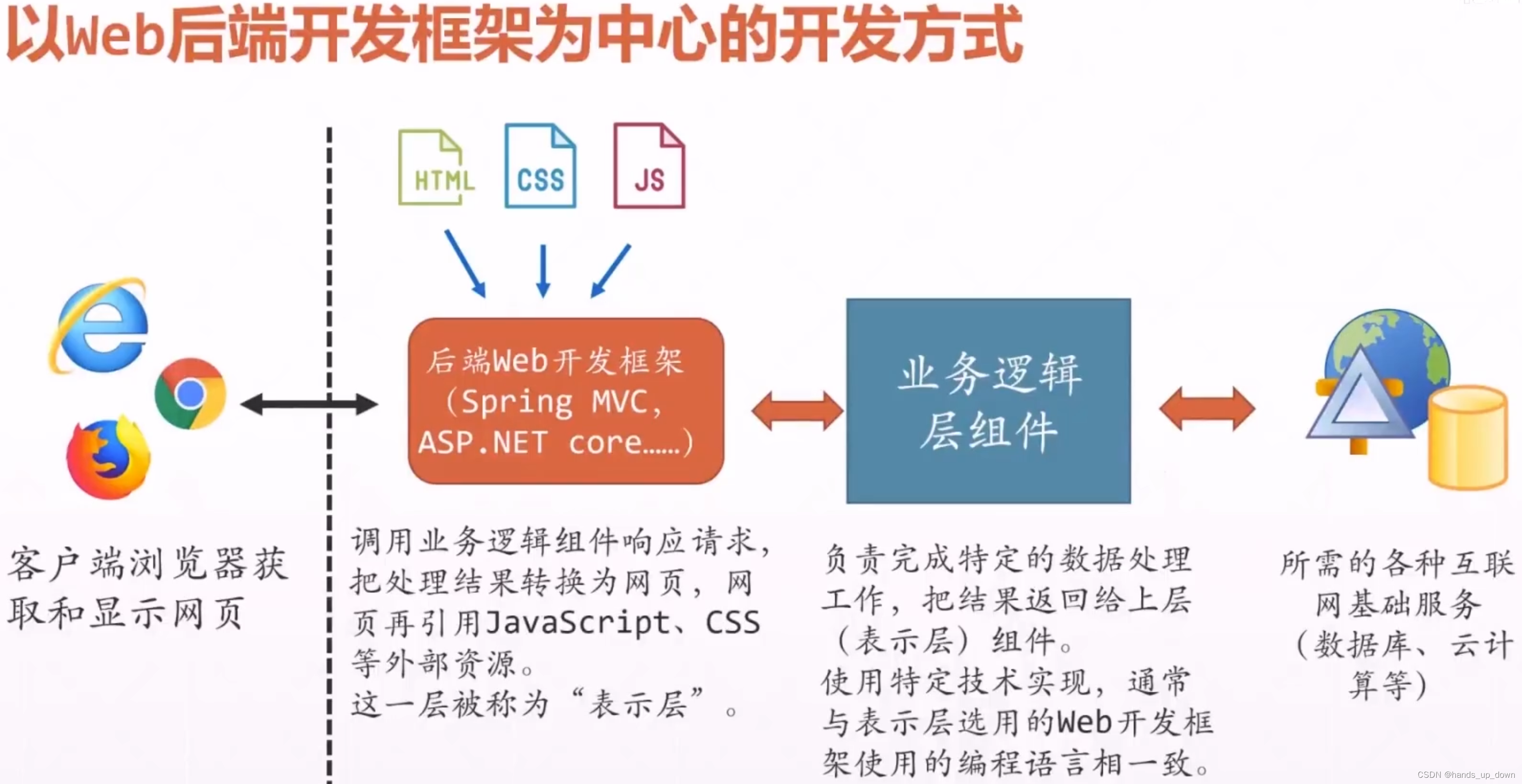
前后端分离
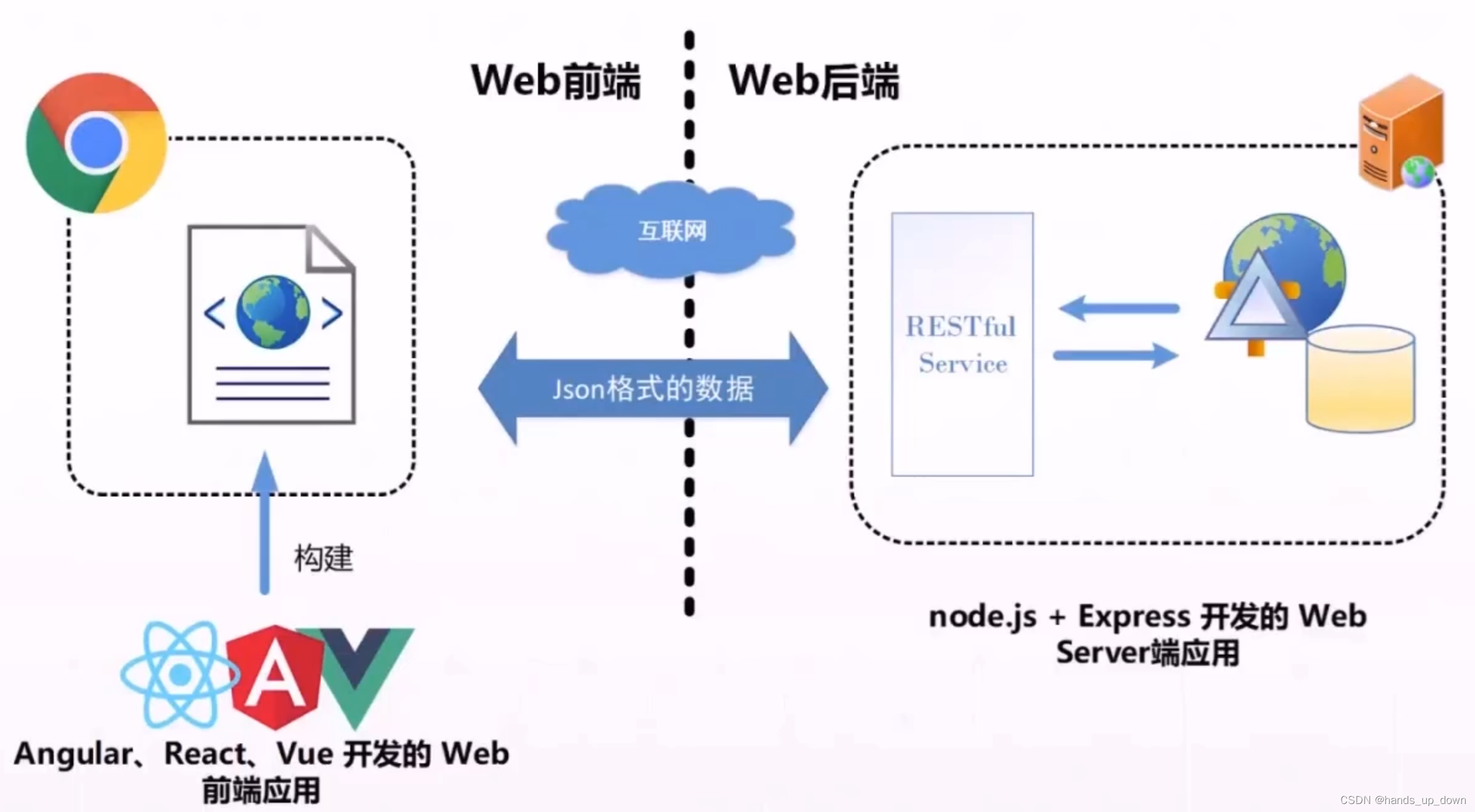
这个构建我倒是挺熟悉的,使用maven提供的构建命令将项目打包,上传到maven仓库,打包好的项目既可以部署,也可以被其他项目作为依赖引用
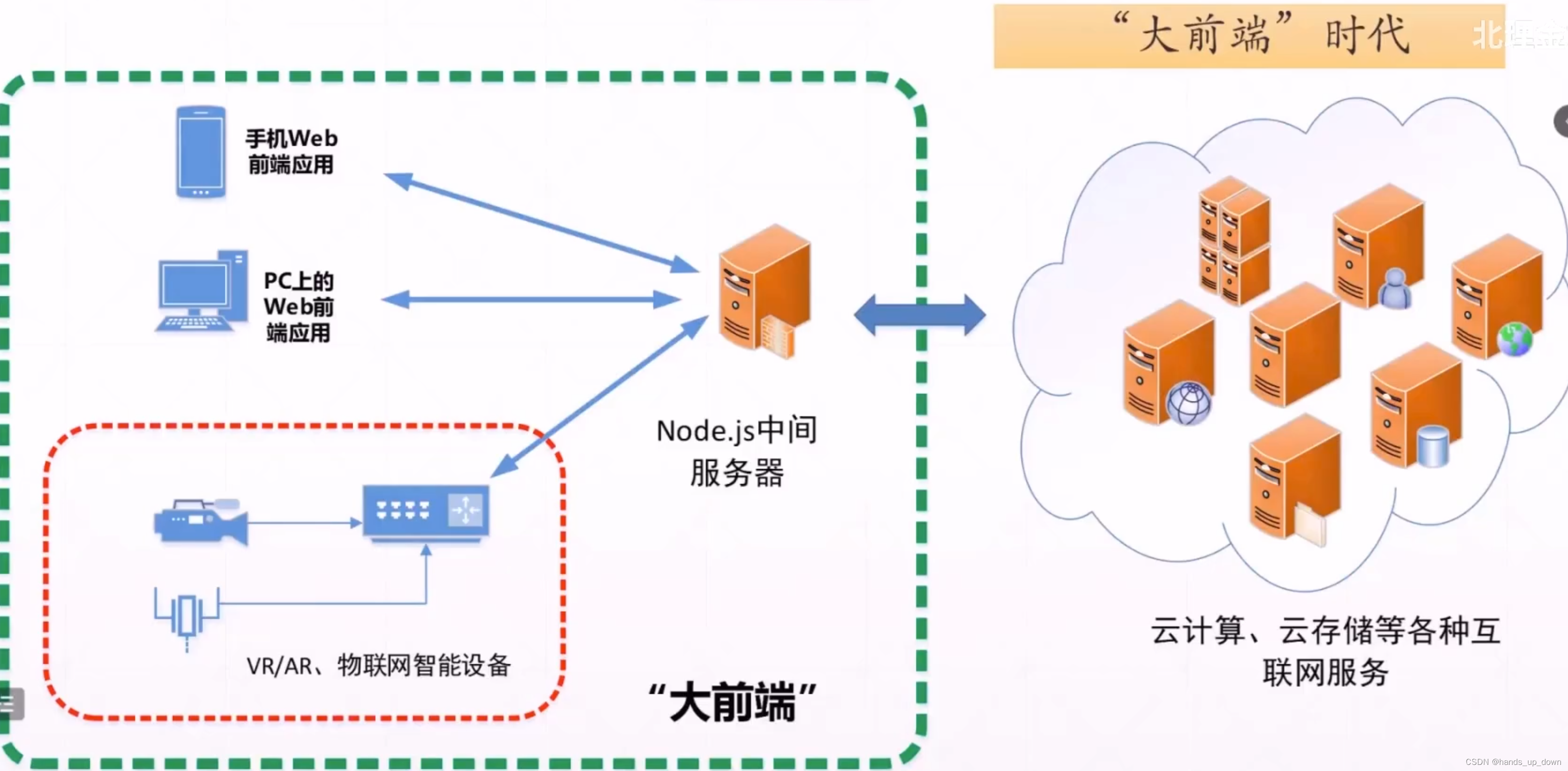
移动互联网前端:微信小程序
物联网智能设备:摄像头、智能家居。标准不统一,未来要统一通讯协议,就像互联网一样
网络安全:数字人民币,离线情况下也可以交易
后端技术演化-云计算平台
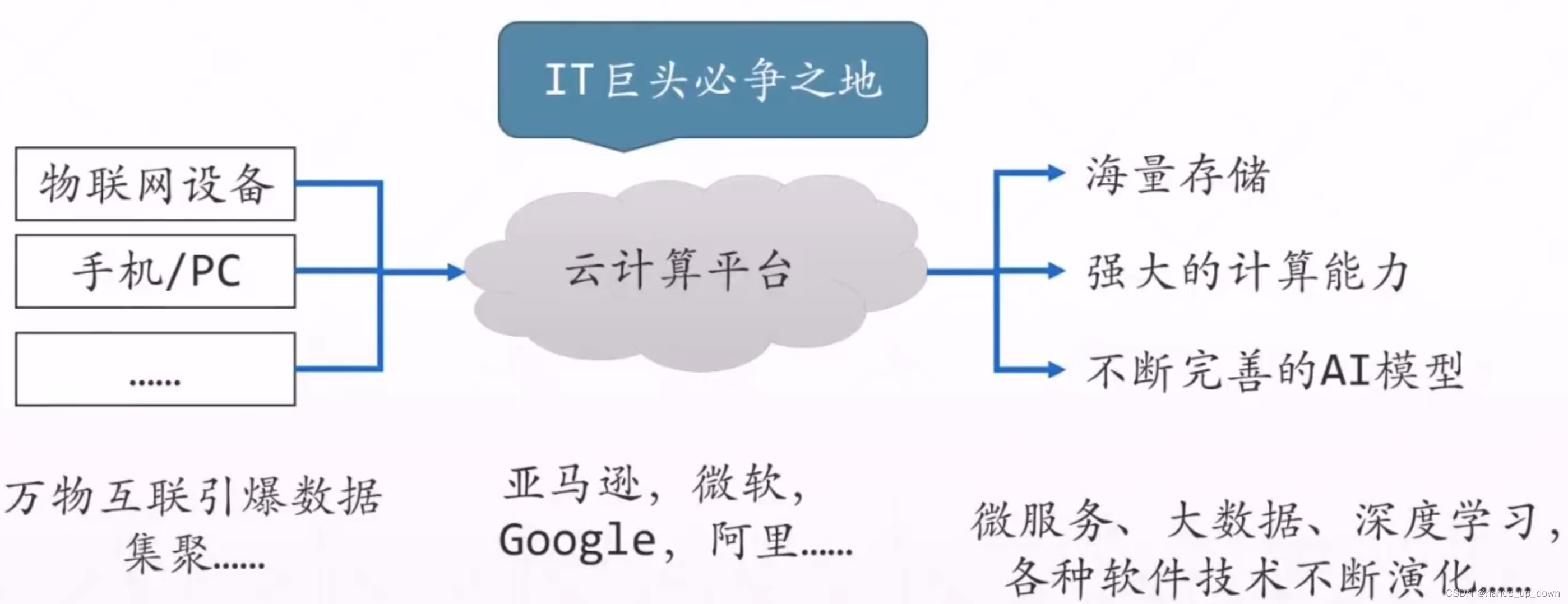
.NET: 生态不强,主要用于工业场景,政务、公司内网、流水线、地铁闸机等
总体趋势

反应式编程
异步非阻塞
比如HTTP服务器,对于这些服务器来说,它肯定服务的不只是一个人,它要服务很多人。如果按照同步的方法,那么服务器一次就要被一个客户端独占了。而在我们通常的使用场景中,一个客户端并不是时时刻刻都在向服务器发送请求,比如我们浏览网页的时候,我们点进去一个页面,get到服务器端返回来的页面以后,我们起码也要在这个页面上浏览好几秒钟才会再次向服务器发送请求跳转到下一个页面吧。如果服务器被一个客户端独占了,自然就没有办法响应其它客户端的请求。那肯定不行。怎么办呢?这时候就采用异步的方法。
所谓的同步和异步就好像是打电话和发邮件的区别。打电话得保证双方都得同时占线,而且双方打电话的时候就不能干其它事情了,如果电话那头话说得又非常慢,你还得耐着性子等着他说完。发邮件则不是,你给对方发邮件,对方空闲下来就会去看看邮箱,没有空的时候他就会忙他的事情。你也是,发完邮件以后你就去干自己的事情,不用像打电话一样必须等着对方说完才会去做自己的事情,这样能极大的提高对时间的利用效率。
这里也是,若HTTP服务器采用异步的方法,服务器就不会被一个客户端独占了。你向服务器发送请求,服务器不会马上响应你,而是会等到它忙忘手中的事情才回来理你。这样的话服务器不会马上响应你的需求,影响大吗?得看你的实际需求,如果你是在浏览网页,可能基本上没什么影响,因为你并不是时时刻刻都会向服务器发起请求,而是隔三岔五的请求一下。而对于服务器来说,这样它就能同时服务很多客户端了,而不会被一个客户端长时间占线。
那我还有一个问题,后端服务器是如何实现异步的????总不能是天生的吧
即时响应性,对用户有反应:
对用户有反应我们才说响应,一般我们说的响应,基本上都说得针对跟用户来交互。只要有可能,系统就会及时响应。
回弹性,对失败有反应:
应用失败了系统不能无动于衷,不能等着它挂掉,要有反应,使其具备可恢复性。可恢复性可以通过复制、监控、隔离和委派等方式实现。在可恢复性的系统中,故障被包含在每个组件中,各组件之间相互隔离,从而允许系统的某些部分出故障并且在不连累整个系统的前提下进行恢复。当某个模块出现问题时,需要将这个问题控制在一定范围内,这便需要使用隔绝的技术,避免雪崩等类似问题的发生。或是将出现故障部分的任务委托给其他模块。回弹性主要是系统对错误的容忍。
弹性,对容量和压力变化有反应:
在不同的工作负载下,系统保持响应。系统可以根据输入的工作负载,动态地增加或减少系统使用的资源。这意味着系统在设计上可以通过分片、复制等途径来动态申请系统资源并进行负载均衡,从而去中心化,避免节点瓶颈。如果没有状态的话,就进行水平扩展,如果存在状态,就使用分片技术,将数据分至不同的机器上。
消息驱动,对输入有反应:
响应系统的输入,也可以叫做消息驱动。反应式系统依赖异步消息传递机制,从而在组件之间建立边界,这些边界可以保证组件之间的松耦合、隔离性、位置透明性,还提供了以消息的形式把故障委派出去的手段。
回压:
Backpressure 其实是一种现象,在数据流从上游生产者向下游消费者传输的过程中,上游生产速度大于下游消费速度,导致下游的 Buffer 溢出,这种现象就叫做 Backpressure 出现。这句话的重点不在于”上游生产速度大于下游消费速度”,而在于”Buffer 溢出”。回压和 Buffer 是一对相生共存的概念,只有设置了 Buffer,才有回压出现;只要设置了 Buffer,一定存在出现回压的风险。
比如我们开发一个后端服务,有一个 Socket 不断地接收来自用户的请求来把用户需要的数据返回给用户。我们服务所能承受的同时访问用户数是有上限的,假设最多只能承受 10000 的并发,再多的话服务器就有当掉的风险了。对于超过 10000 的用户,程序会直接丢弃。那么对于这个案例 10000 就是我们设置的 Buffer,当超过 10000 的请求产生时,就造成了回压的产生;而我们程序的丢弃行为,就是对于回压的处理。
对于回压我们一般有两种处理方式,一种就是上面举例中的拒绝或丢弃,这是否定应答的方式,另一种是肯定应答,先收下来,然后再慢慢处理。
反应式编程的实现范式:
反应式编程的规范可以总结为4个接口Publisher,Subscriber,Subscription,Processor
Publisher负责生成数据,并将数据发送给Subscriber。一个Subscriber对应着一个Subscription。Subscriber可以使用Subscription来管理其订阅情况。
首先是Subscriber订阅Publisher。订阅成功以后,Subscriber就会得到一个Subscription对象。Subscription中有两个方法:request方法和cancel方法。
Subscriber得到一个Subscription对象以后,就可以调用该Subscription对象的request方法,请求Publisher发送数据给Subscriber。通过调用cancel方法就可以取消对Publisher的订阅。
Processor则是用来处理Publisher发送给Subscriber的数据。
消息队列发展史
来源
计算机和生活的一个小映射:
肌糖原类似于内存,脂肪类似于磁盘。锻炼首先消耗肌糖原,其次是燃烧脂肪。吃饭首先补充的也是肌糖原,然后多的部分才会累积成脂肪
分区:相当于扩建,比如原来只有面馆1,有多个分区后,就有面馆1,面馆2、面馆i。流量增加之后,就可以通过分区实现水平扩容
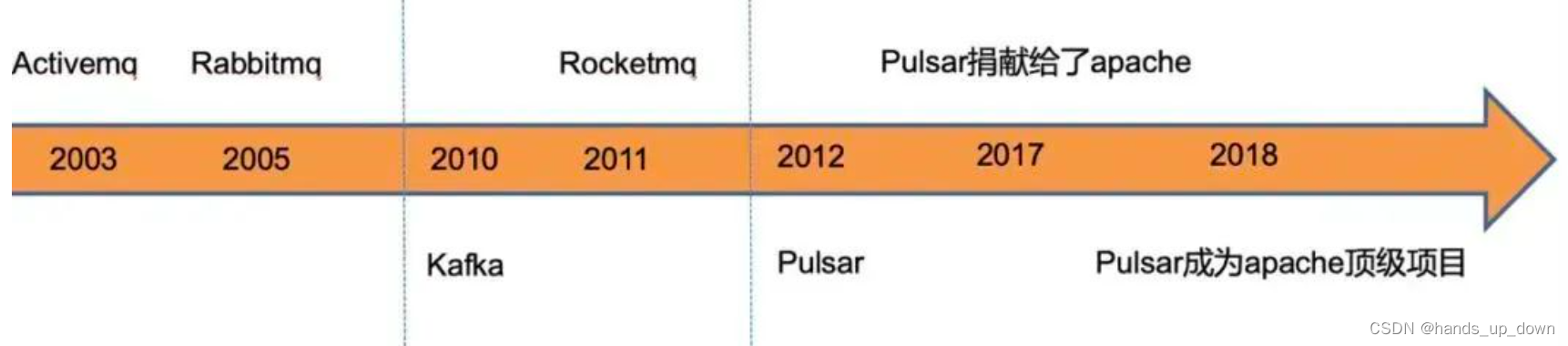
早期的消息队列:聚焦同步调用问题。系统之间层层调用导致时延很高,但是同时又要保证同步。于是考虑是否能将一些同步操作异步化
2010:流量持续增大,数据量持续增大。吞吐量,一致性
2012:线上交易兴起。对于数据一致性要求非常高,远远高于对大流量处理的要求。
2012之后:云计算开始兴起,开始考虑标准化,平台化,避免重复造轮子。同时,这个时期的消息队列,计算节点和存储节点在同一个节点上,不利于容器化,服务容器化要求服务没有状态。如果节点有数据,节点挂了之后需要恢复数据。很困难
kafka,rocketmq,pulsar
在共用一个磁盘条件下,topic越多,kafka效率越低
rocketmq:完全顺序写
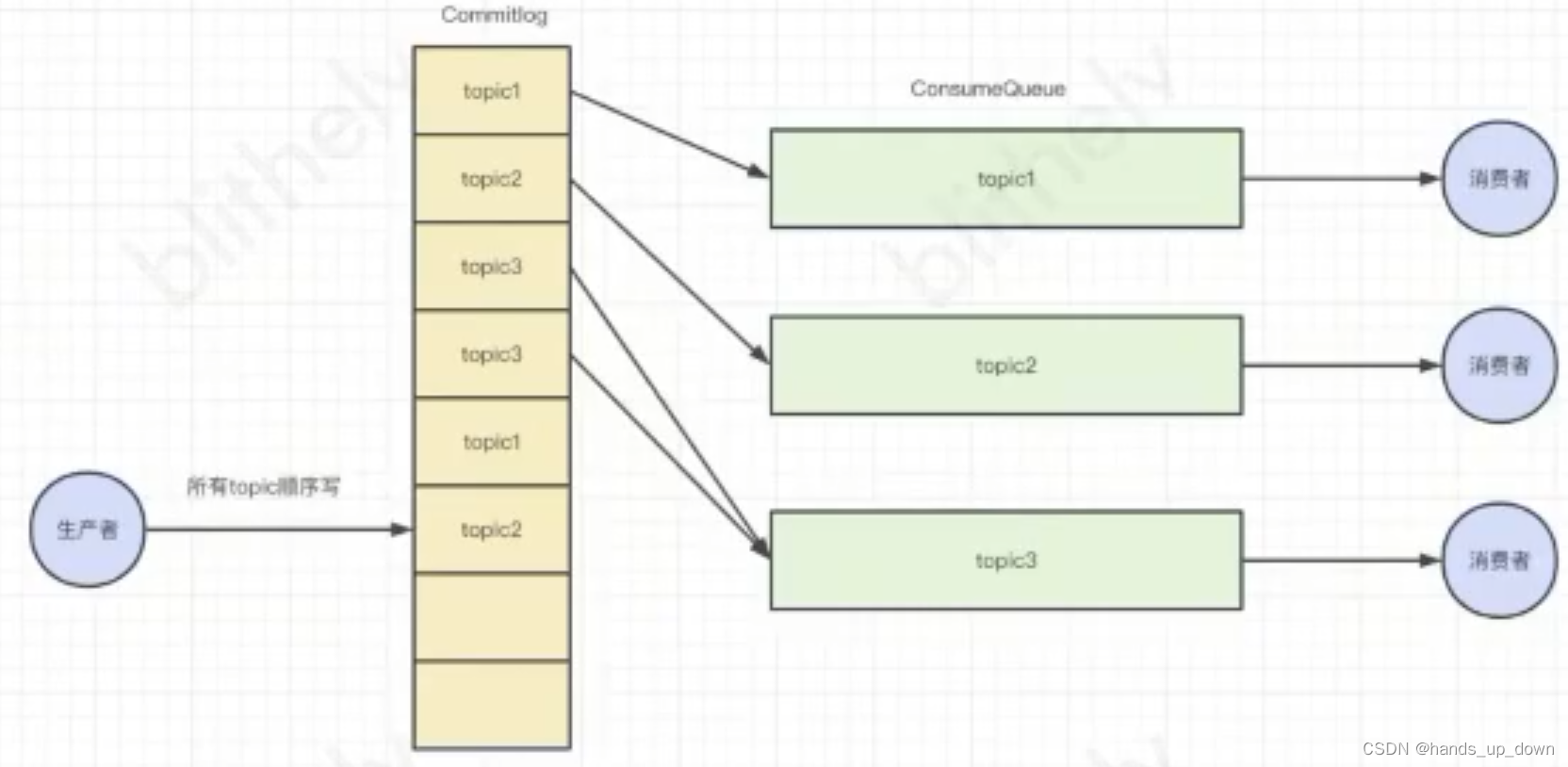
为了利用磁盘顺序写更快的特性,将所有topic写到一个文件中
但代价就是,读,变得更加复杂了。需要在读取的时候,挑出相应的部分。这就意味着,需要记录额外的状态,记录同一个topic的起始位置和结束位置。增加了索引文件
PS:之前做计算机视觉项目的时候,中间结果要存到txt文件中,我当时就考虑过存多个文件还是一个文件,最后我选择存一个文件。首先需要设计好存储的格式,什么时候换行,什么时候加tab等等。然后读取的时候,需要根据存储的格式,编写相应的读取逻辑来解析存储文件。不得不说,确实,存的时候简单了,读取就变得麻烦
pulsar
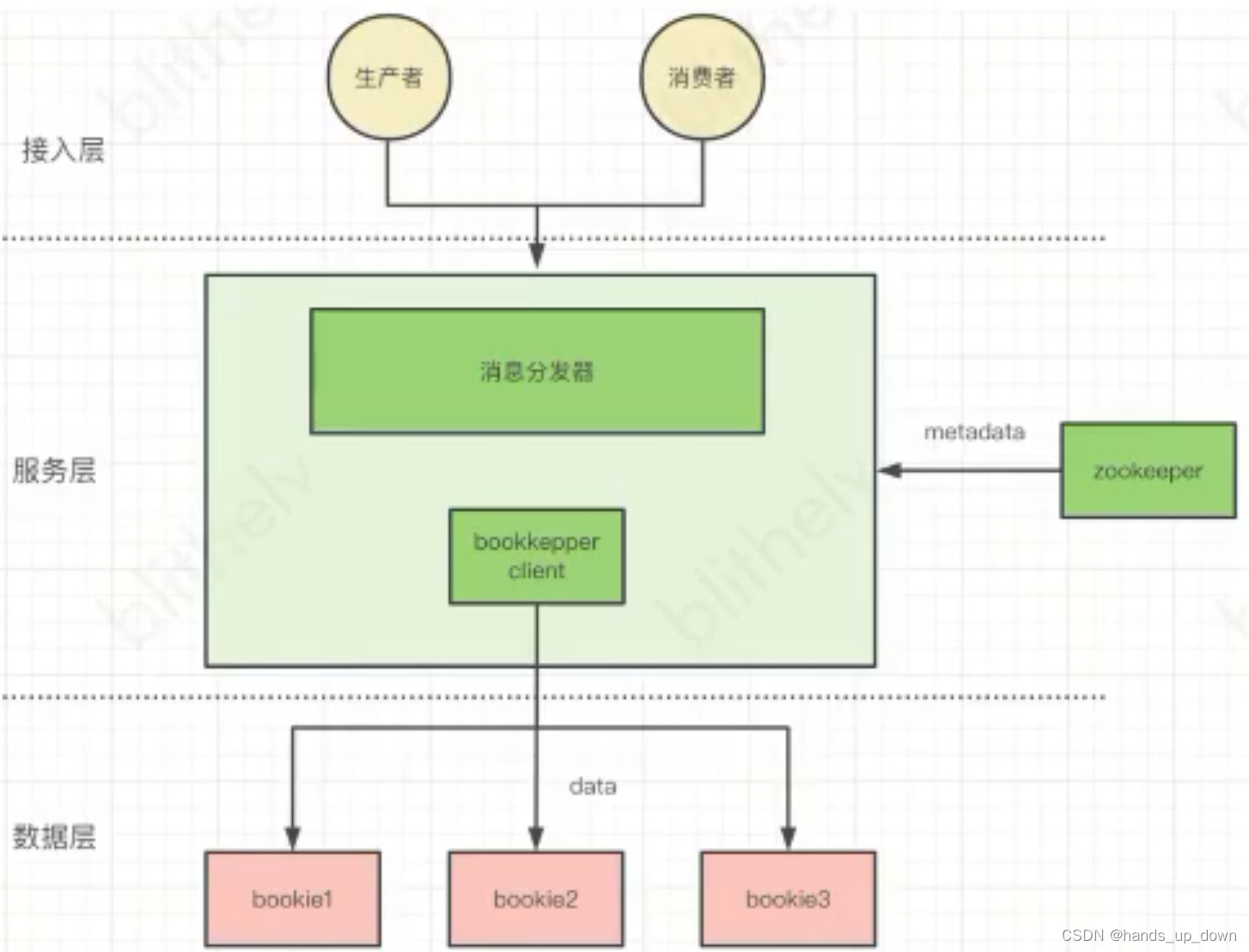
计算节点和数据节点分层,服务层全部无状态,无数据,有利于容器化
又引入了zookeeper
主从并发写入
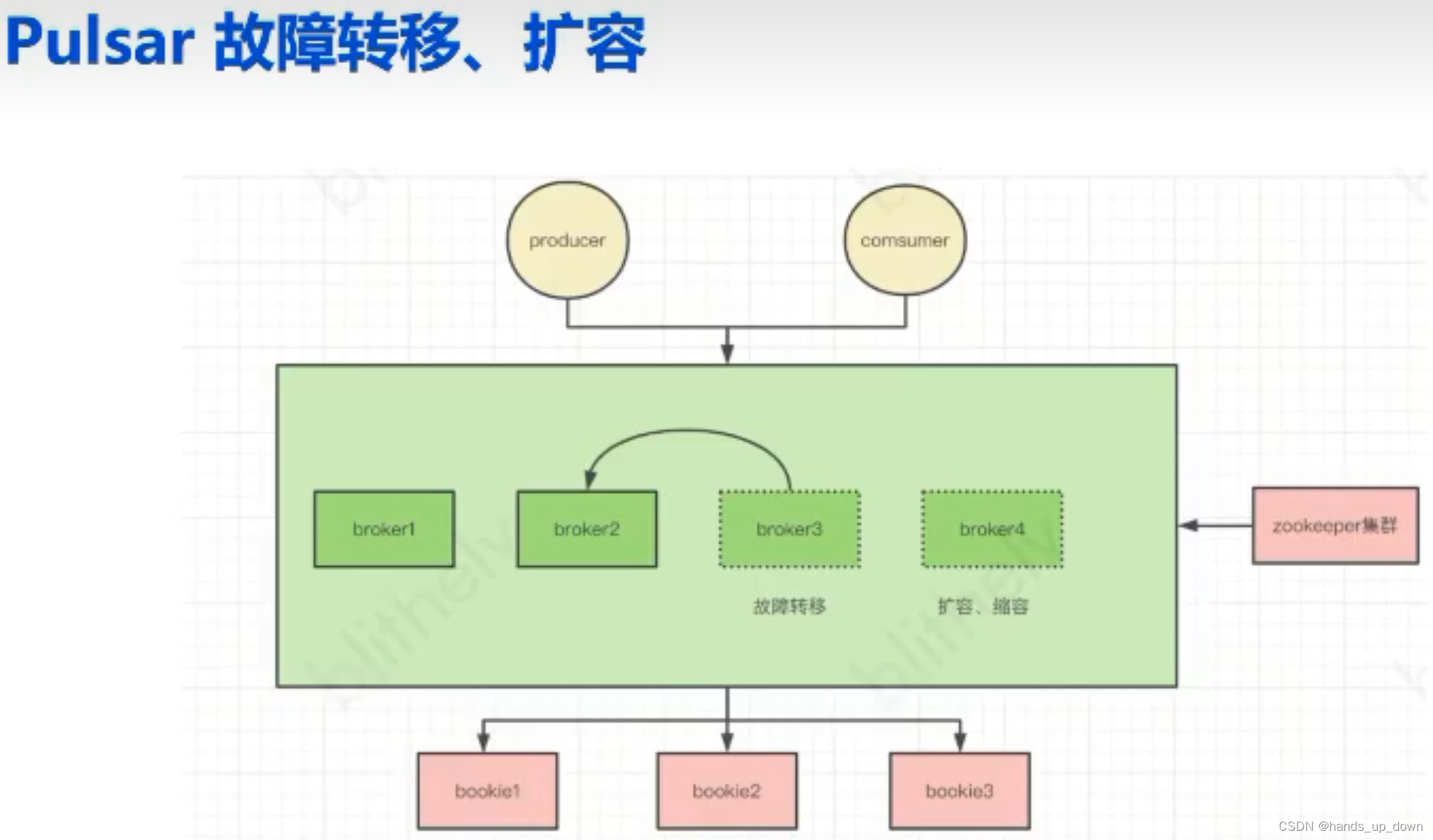
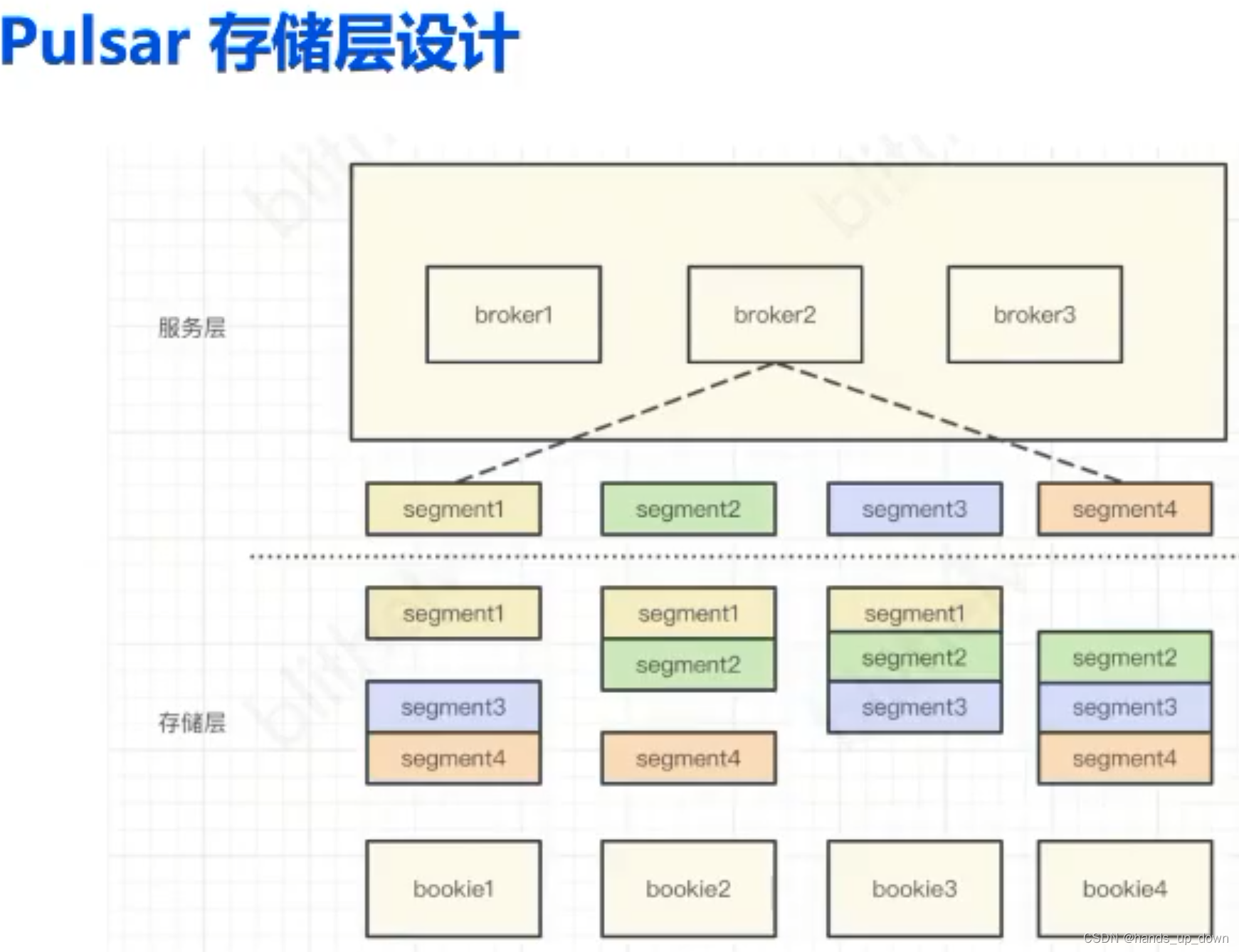
磁盘快满了,存储层可以动态新增节点
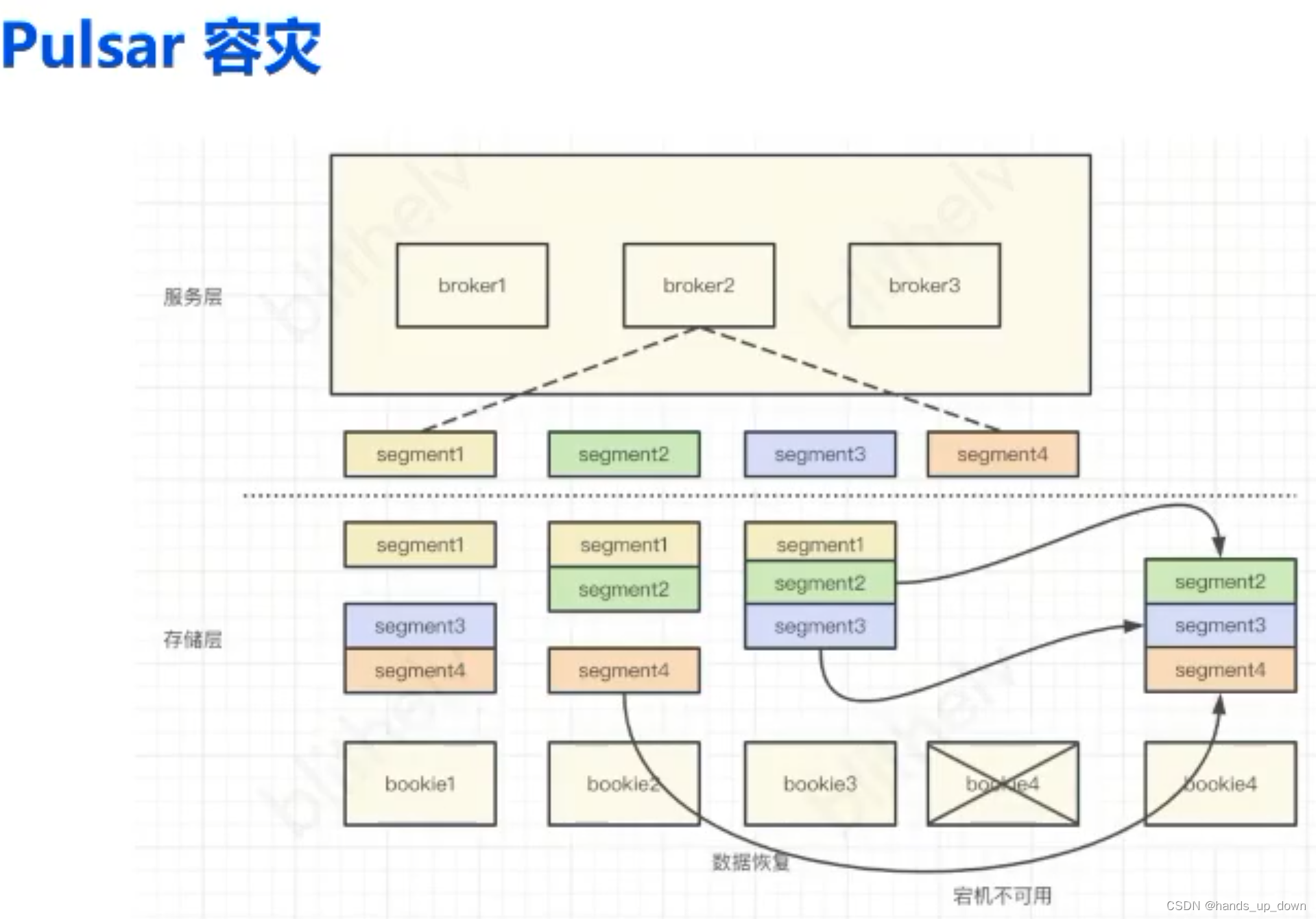
如果存储层第4个节点挂了,只需要从其他节点找到第4个节点包含的数据,迁移到新增节点即可。对外无感知,运维更加简单
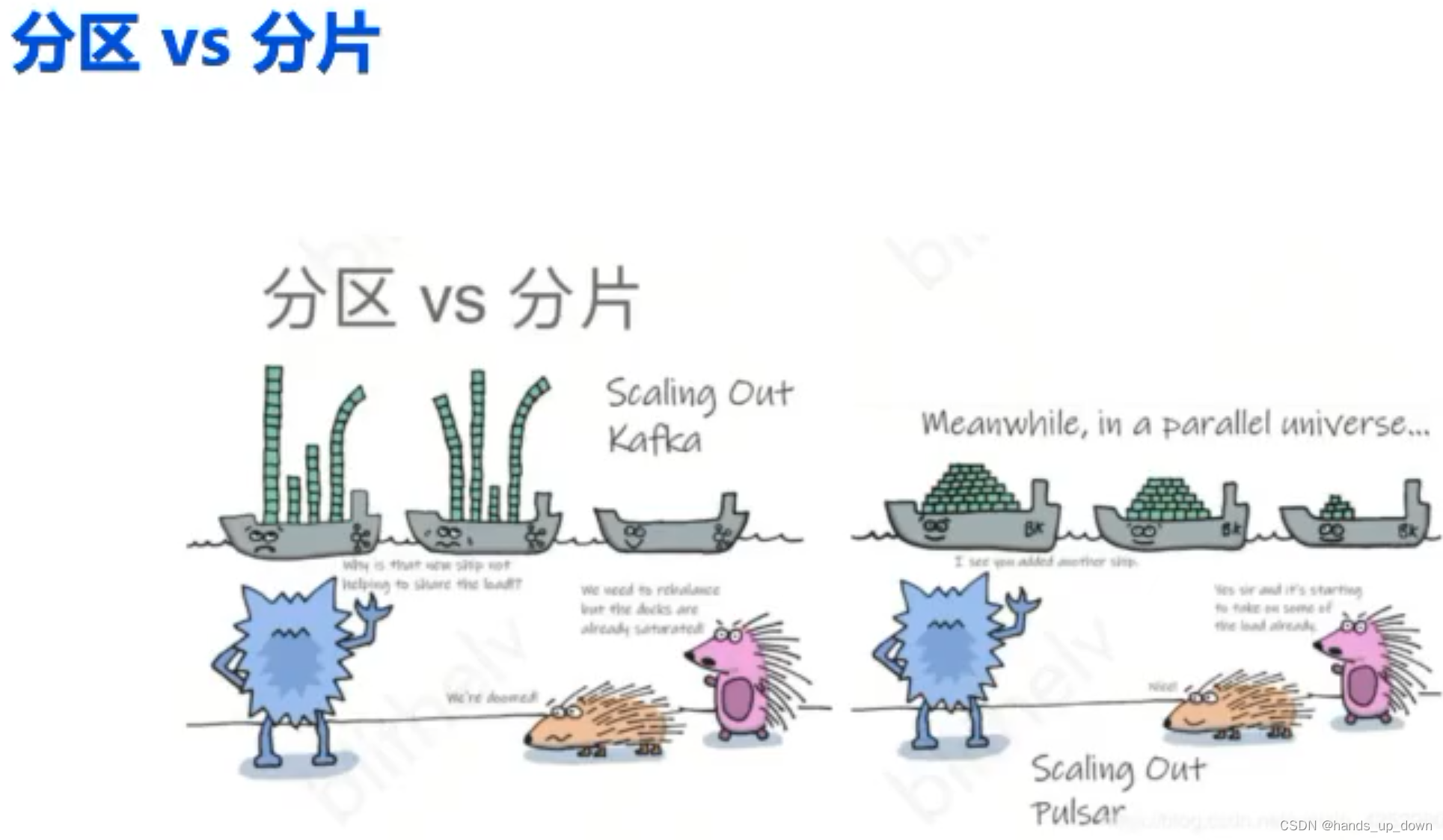
假设一艘小船就是一个topic,对于kafka、rocketmq的策略,topic3上就没有数据,整体利用率不够高
网易后端架构演进
来源
小型网站:个人开发
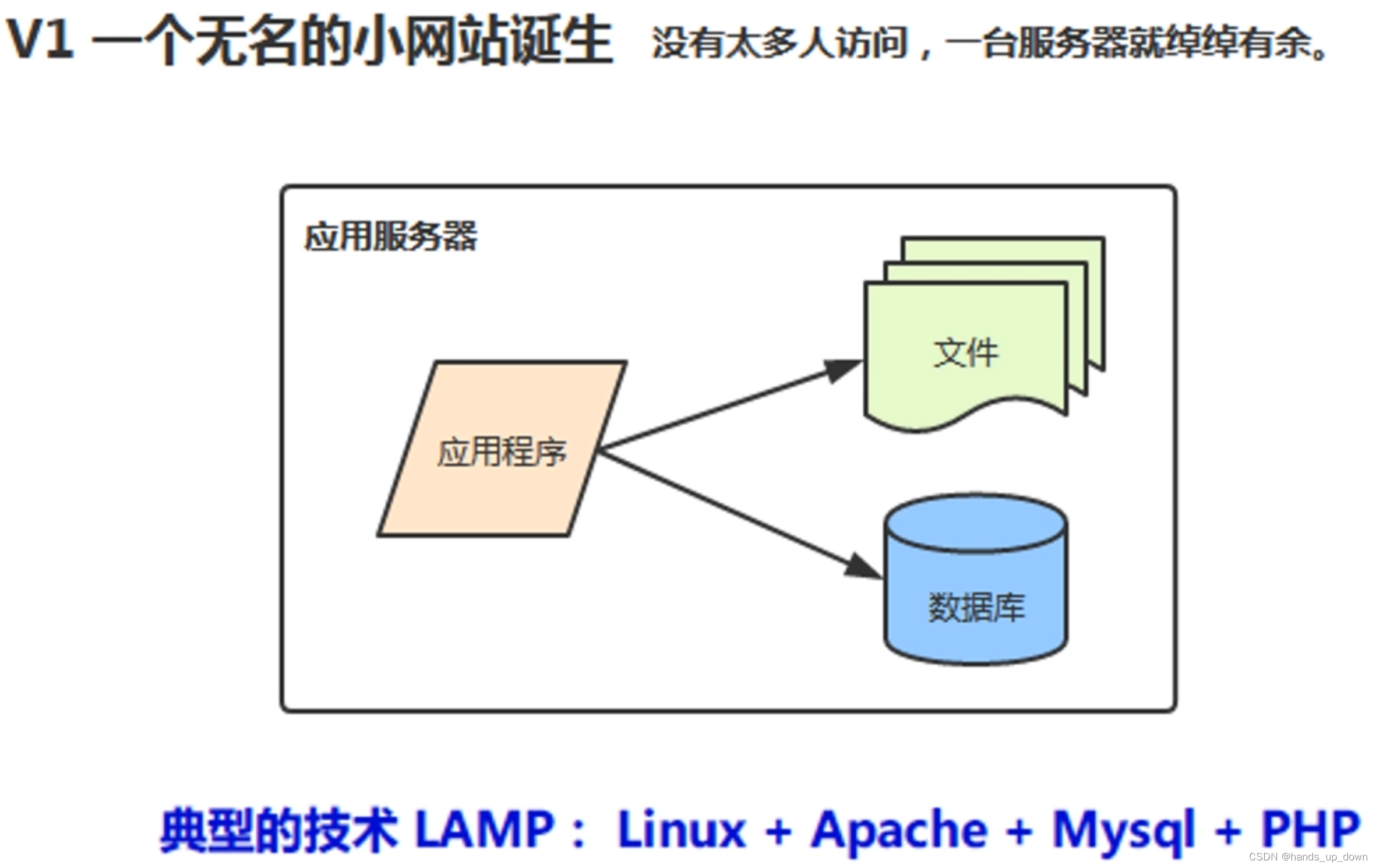
淘宝最初就是采用这套技术方案,一个月就完成了网站上线
但是流量很快就超过了这套技术方案的负载能力
架构瓶颈

如何用最经济的方式解决上述问题???用100万设计方案解决未来3年的架构问题,还是0成本解决未来3个月的架构问题
v2:服务与数据分离
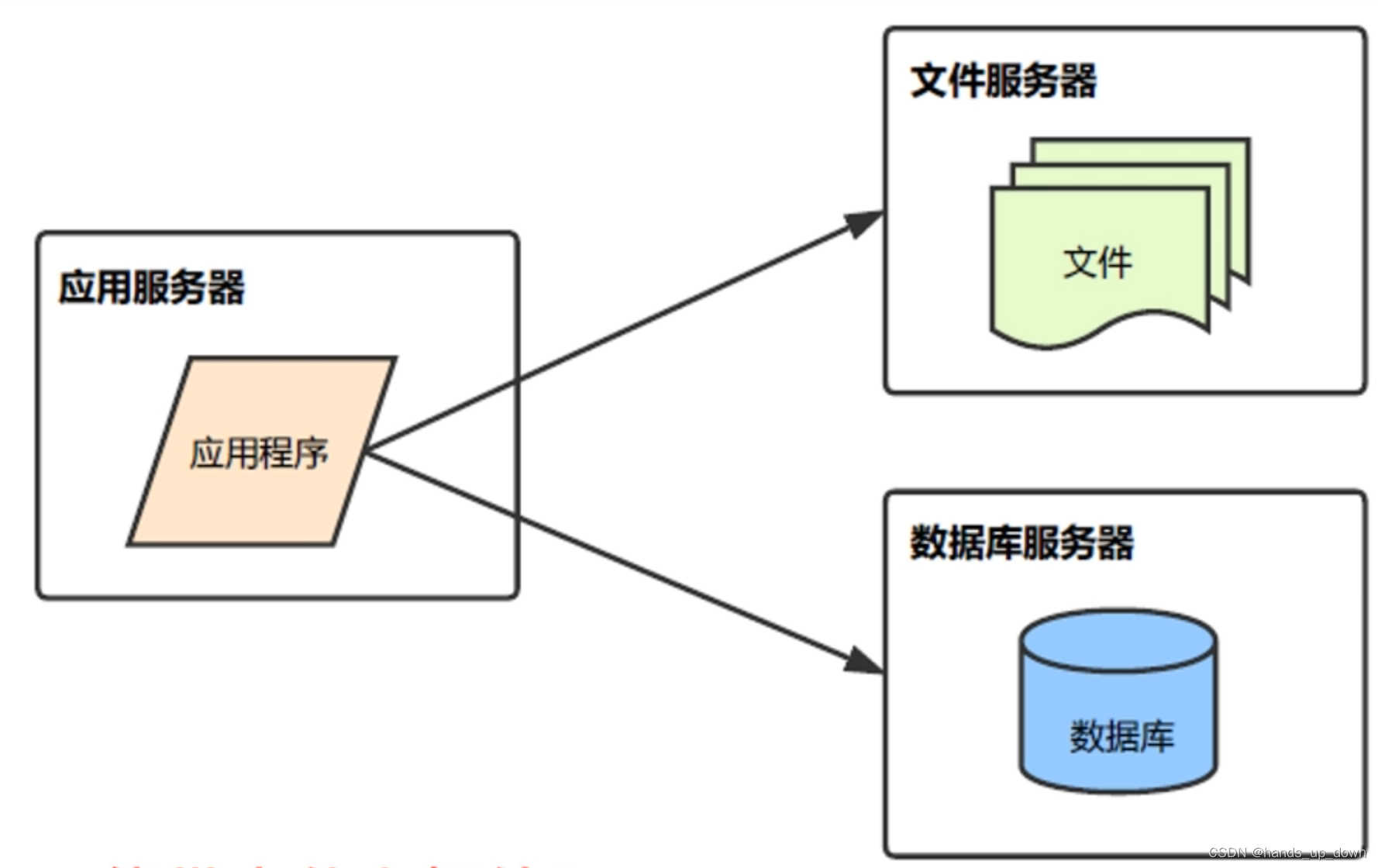
我还没遇到过需要使用文件服务器的场景

数据库瓶颈
v2的方案随着流量增加又会遇到新的问题

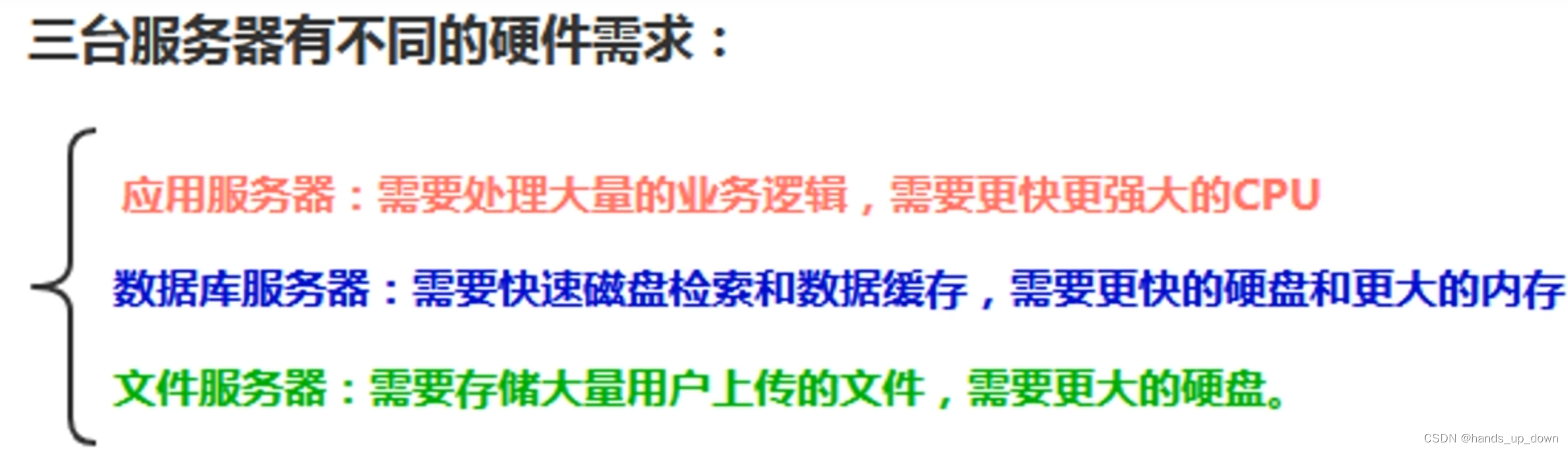
数据库优化:分布式缓存,分库分表,硬件优化
v3:使用缓存优化数据库
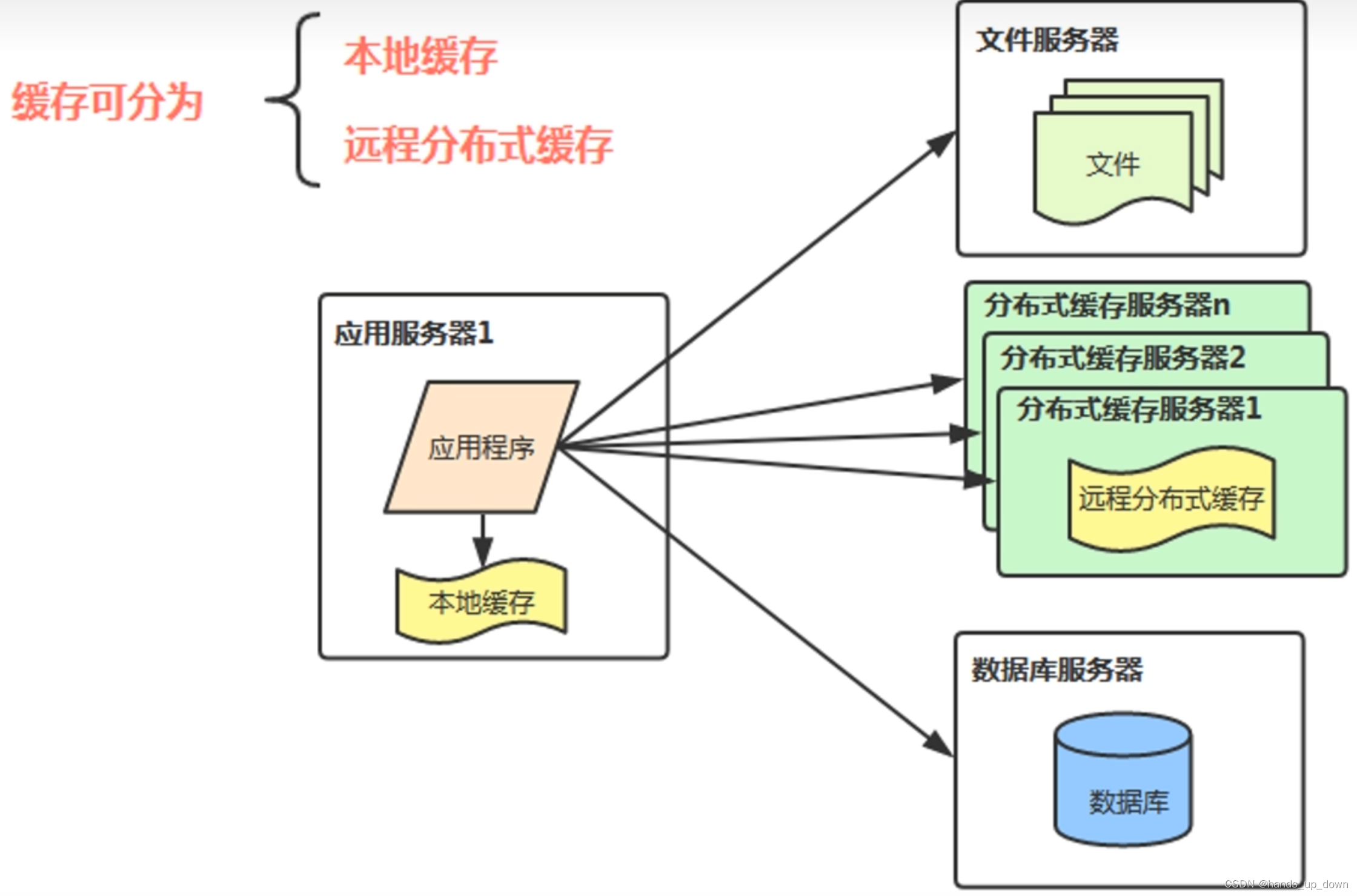
空间换时间,加载局部性数据到内存,访问内存比访问磁盘快很多
用户数据,量大,不适合本地缓存,可以放到远程缓存;字典数据可以放本地
常用缓存:redis,memcache
redis也是一种轻量化的消息队列组件,其架构与kafka、rocketmq、pulsar都不一样
服务器瓶颈
v3又支撑了几个月

高并发,提升网站并发处理能力
并发请求数量很大,超出单台计算机处理能力
v4:应用服务集群
应用服务器集群
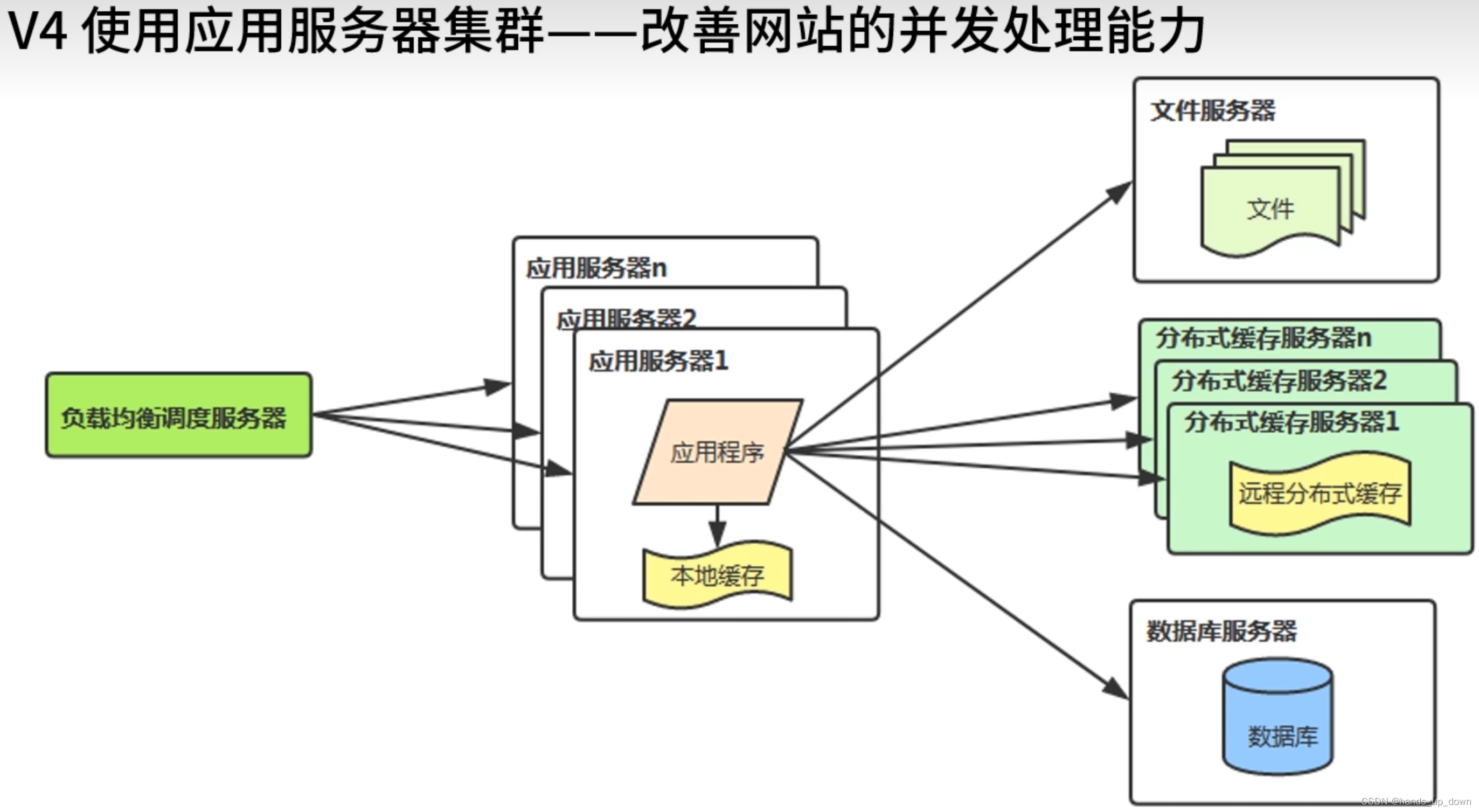
为什么用集群服务器,不用更强的服务器???众人拾柴火焰高,李元霸太少,并且李元霸本身也有上限,他一个人能修长城,能修金字塔吗!!还有个就是成本问题,多个小机器的成本远远低于一个大机器
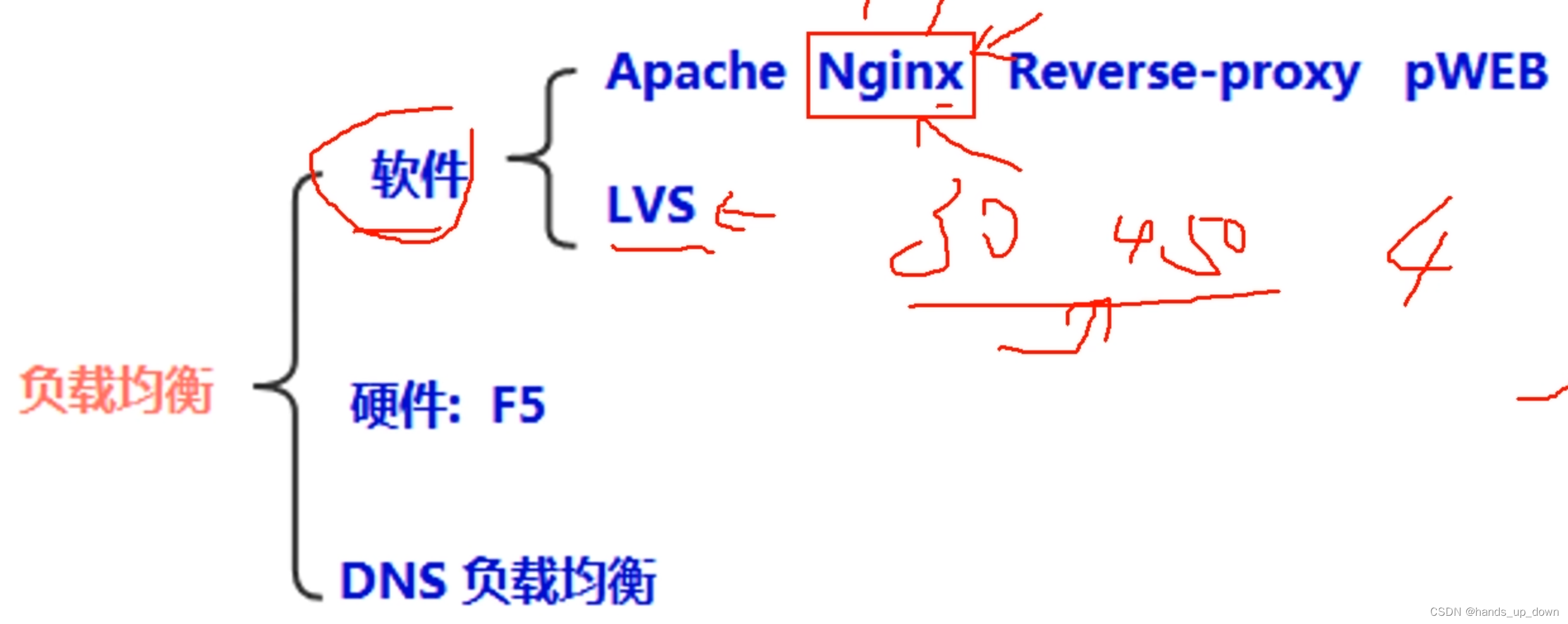
nginx工作在应用层,LVS工作在传输层,LVS更快,可以处理更高的并发
数据库缓存瓶颈-缓存击穿、雪崩

v5:数据库读写分离
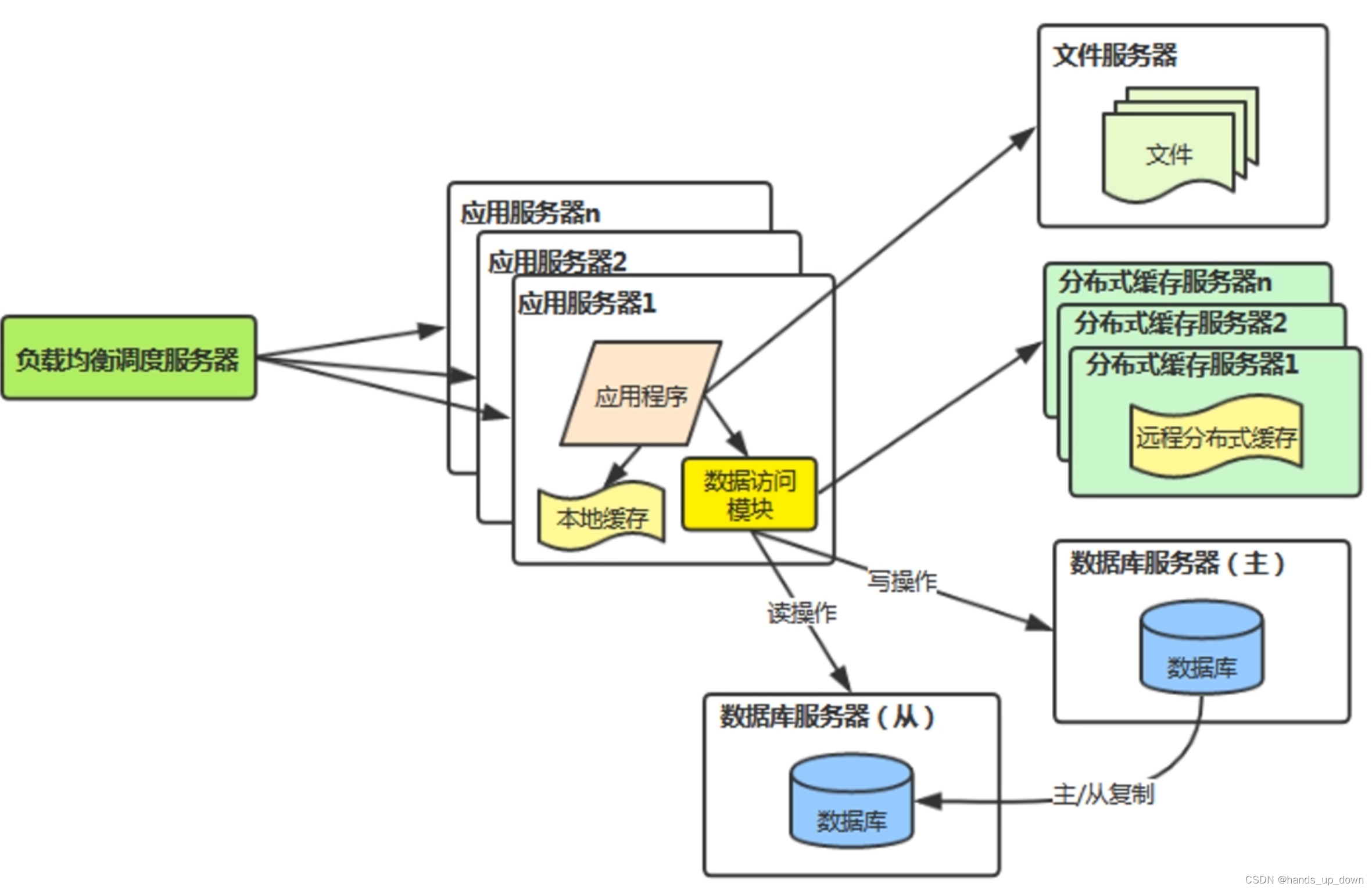
主库负责写,从库负责读,主从数据要一致
DAO层的写法不能变,增加模块专门负责数据库操作的转发

网络体验瓶颈

v6:反向代理+CDN加速
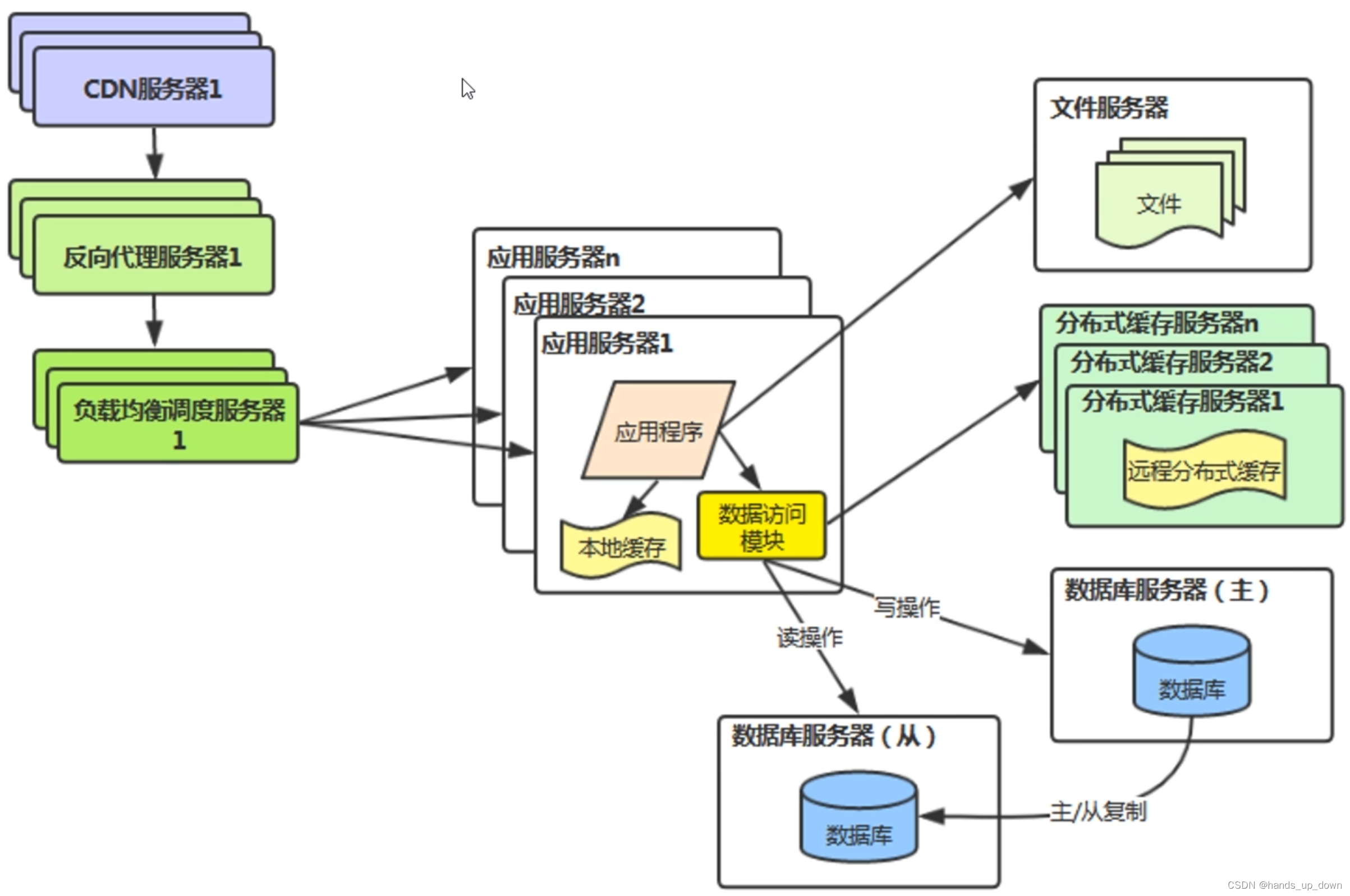
CDN:内容分发网络。不是一台机器,而是一个网络。网络的节点就是设置在各地的CDN服务器,比如在重庆,东北,新疆等。缓存静态资源
反向代理:也是用于缓存静态资源
反向代理部署在核心系统的外围,CDN则是在各地部署

数据库容量瓶颈

v7:分布式文件系统,分布式数据库系统,分库分表
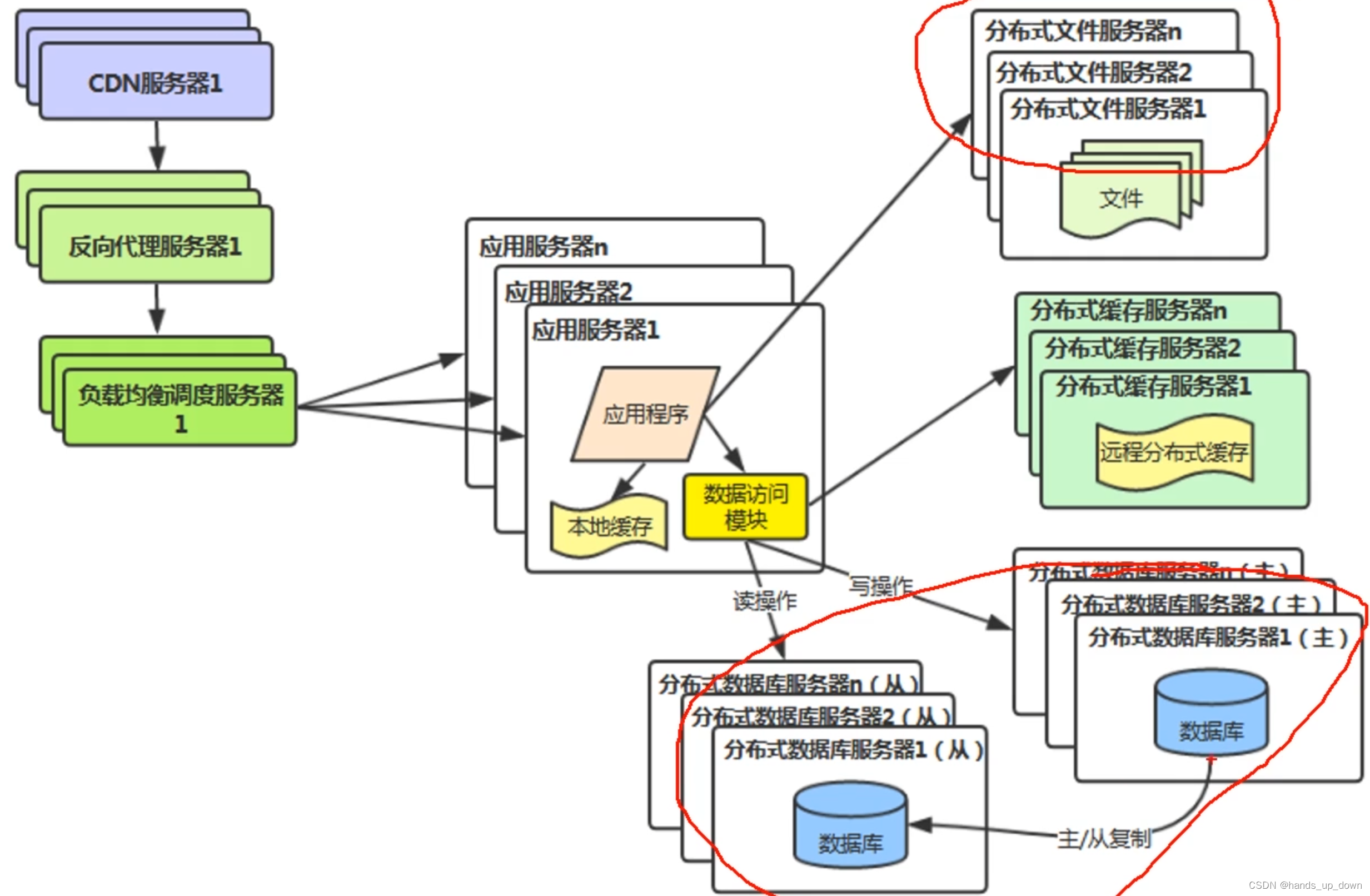
分布式文件系统怎么做??

HDFS:大数据分布式文件系统。大文件,至少128M
比如有几百T的文件。
数据库存储、搜索瓶颈


v8:NoSQL、搜索引擎
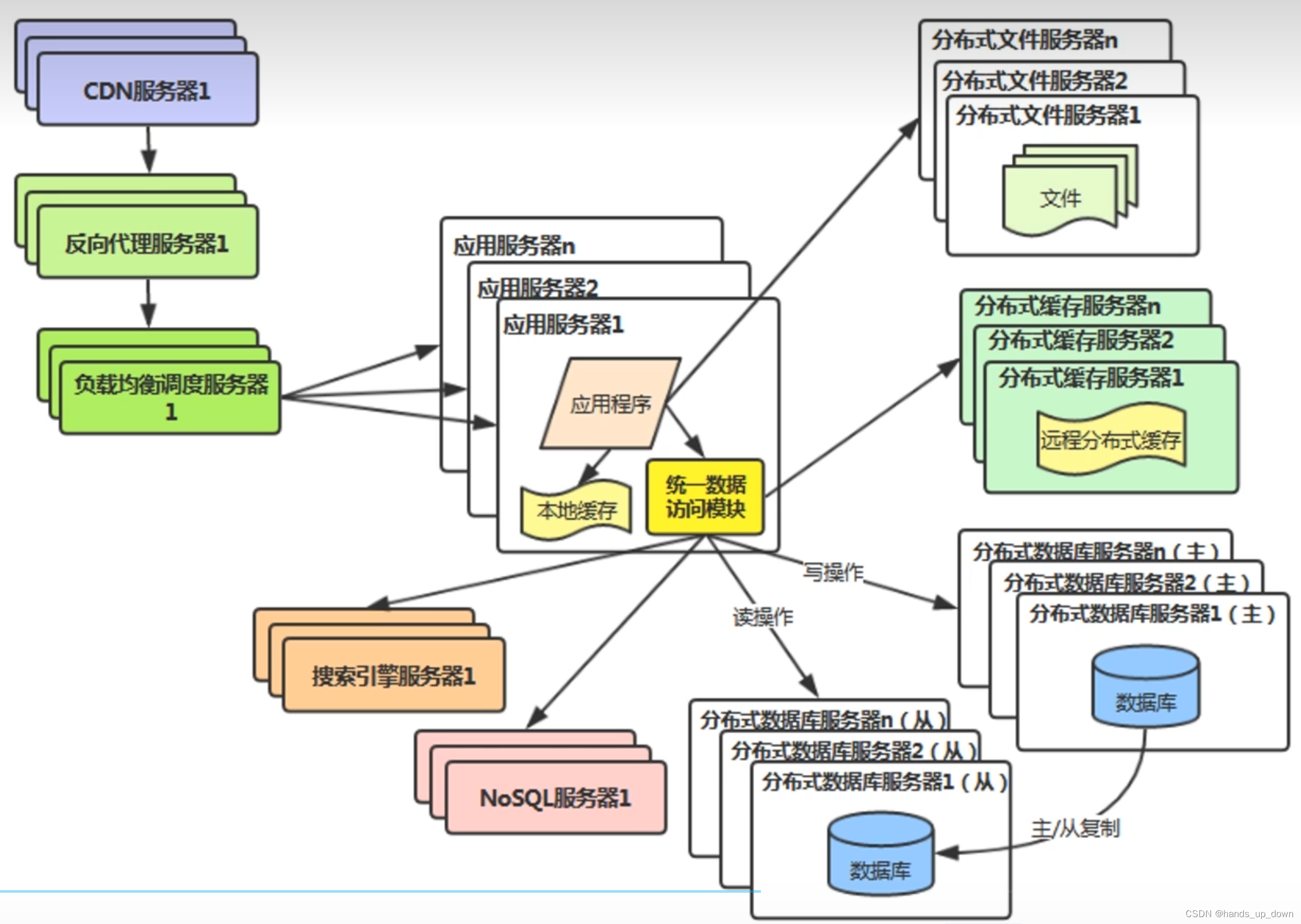

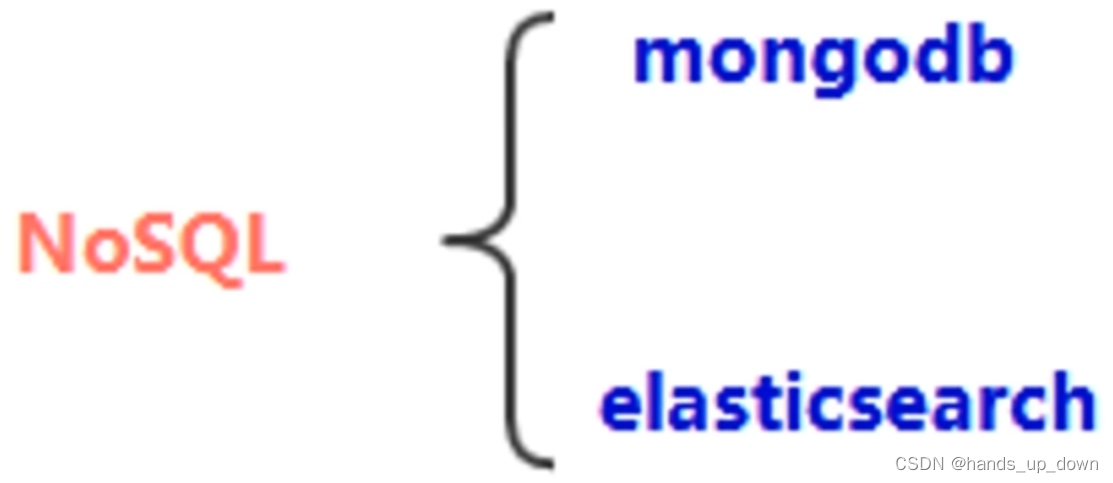
开发效率瓶颈

v9:业务拆分
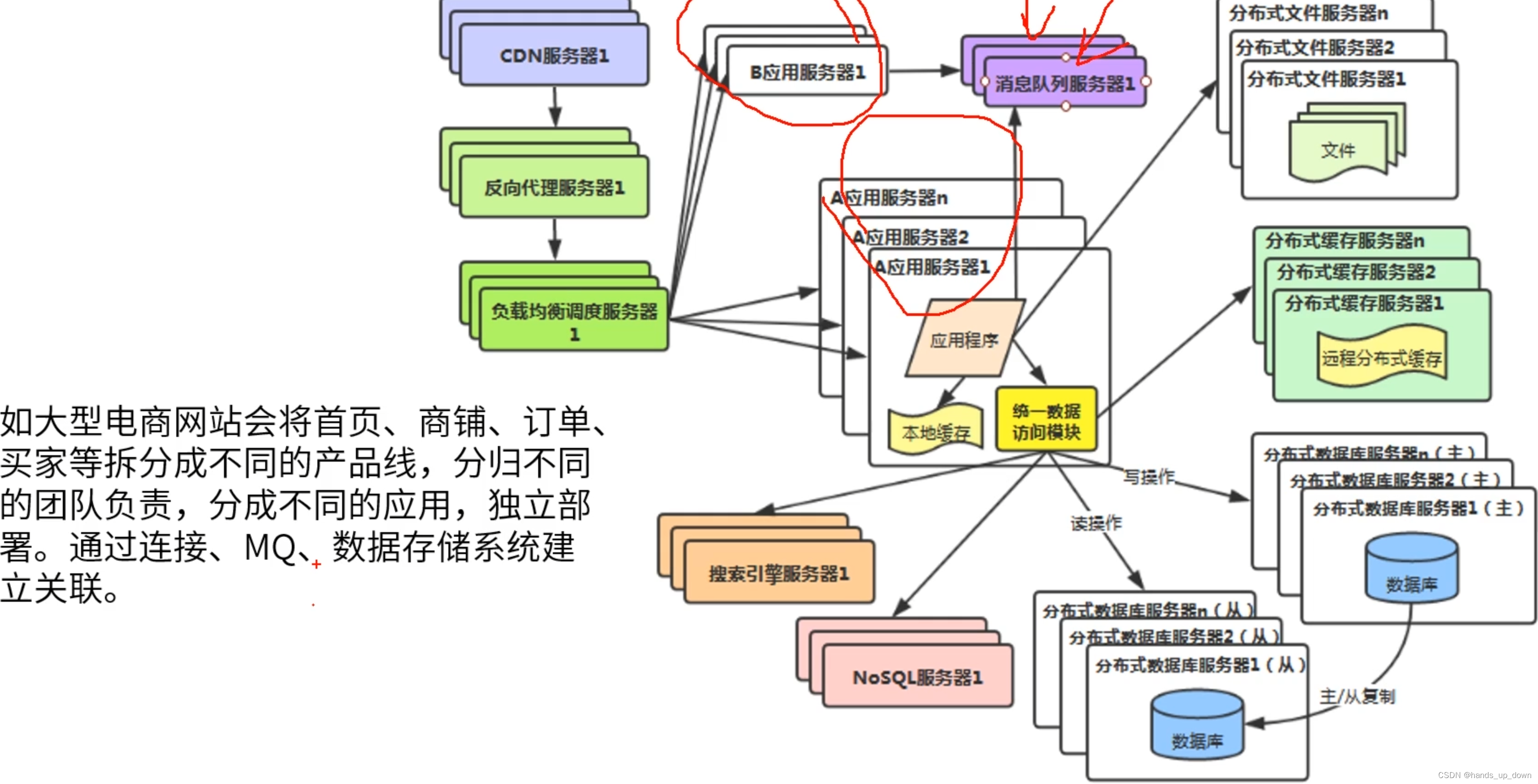
数据库连接数量瓶颈
之前咋应用服务器数量有限的情况下,数据库就难以招架了,现在应用服务器的数量提升了几个数量级,导致数据库可供连接的接口不够了(连接池用完了)

v10:分布式服务(服务化),微服务
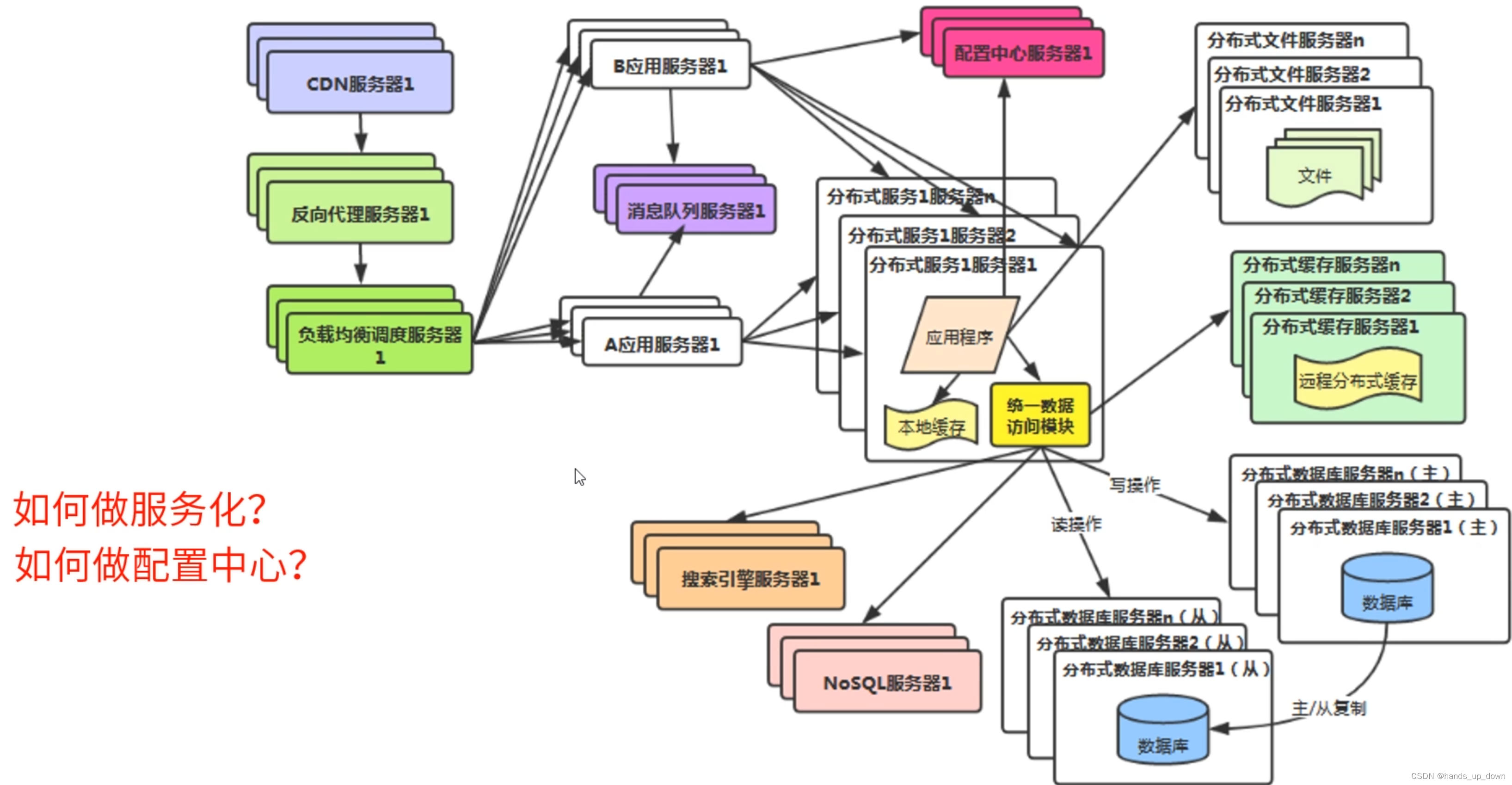
微服务架构需要配置中心,所有的服务都要在配置中心进行注册,这样在分发请求的时候才找得到对应的服务
springcloud:完整的微服务解决方案
dubbo:RPC开发框架
PS:微服务架构不要无脑上,对硬件资源的消耗很大,一定要根据实际情况选择
总结

spring家族的一些概念
SSM:spring + spring mvc + mybatis
Spring 是一个开源应用框架,提供了IOC(控制反转)和AOP(面向切面编程),使得开发者能够写出松耦合、易于测试的代码。Spring框架的核心功能可以通过几种方式结合起来,例如:通过Spring MVC提供Web应用开发,通过Spring Cloud提供分布式系统的集成服务。
Spring MVC 是基于Servlet的一个MVC框架,用于构建Web应用。它与Spring框架紧密集成,简化了Web应用的开发。
Spring Cloud 是一系列工具,提供了快速构建分布式系统的通用模式,例如配置管理、服务发现、智能路由、微代理、控制总线、全局锁等。它集成了诸如Netflix OSS等框架,并且使用Spring Boot风格进行封装。
Spring Boot 是一个快速开发的工具,它用于创建独立的、生产级的Spring应用。Spring Boot通过一系列的自动配置来简化Spring应用的开发,使用Spring Boot,你可以“just run”你的应用。
分界线
Spring:一个通用的、用于Enterprise Java的开源应用框架。
Spring MVC:一个MVC的实现,用于构建Web应用。
Spring Cloud:一系列工具,用于快速构建分布式系统的通用模式。
Spring Boot:一个用于快速开发、快速运行、快速部署的工具。