论文地址:YOLO-World: Real-Time Open-Vocabulary Object Detection
YOLO-World通过开放词汇检测功能增强了YOLO目标检测。
一、摘要
You Only Look Once (YOLO) 系列检测对预定义和训练对象类别的依赖限制了它们在开放场景中的适用性。为了解决这一局限性,我们推出了 YOLO-World,这是一种创新方法,通过视觉语言建模和大规模数据集上的预训练,增强了 YOLO 的开放词汇检测功能。具体而言,我们提出了一种新的可重新参数化的视觉语言路径聚合网络(RepVL-PAN)和区域文本对比损失,以促进视觉和语言信息之间的交互。我们的方法擅长以零样本(zero shot)、高效率检测各种物体。在具有挑战性的 LVIS 数据集上,YOLO-World 在 V100 上以 52.0 FPS 实现了 35.4 AP,在准确性和速度方面都优于许多最先进的方法。此外,经过微调的 YOLO-World 在多个下游任务上取得了出色的性能,包括对象检测和开放词汇实例分割。

二、主要贡献
- YOLO-World 通过开放词汇检测功能增强了 YOLO 目标检测。
- 引入RepVL-PAN和区域文本对比丢失,促进视觉和语言信息之间的交互。
- YOLO-World在zero-shot目标检测方面实现了高效率,并在精度和速度方面优于最先进的方法。
- 在对象检测、开放词汇实例分割等下游任务中表现良好。
- 主要贡献包括引入 YOLO-World、提出 RepVL-PAN 和区域文本对比预训练方案,以及在大规模数据集上展示强大的零样本性能。

三、方法

3.1.预训练公式:区域-文本对
传统的对象检测方法,包括 YOLO 系列 [20],使用实例注释 Ω = {Bi ,ci} 进行训练,实例注释由边界框 {Bi} 和类别标签 {ci} 组成。在本文中,我们将实例注释重新表述为区域-文本对 Ω = {Bi , ti} ,其中 ti 是区域 Bi 的对应文本。具体来说,文本 ti 可以是类别名称、名词短语或对象描述。此外,YOLO-World 采用图像 I 和文本 T(一组名词)作为输入,并输出预测框 {Bˆ k} 和相应的对象嵌入 {ek} (ek ∈ RD)。
3.2. 模型架构
所提出的 YOLO-World 的整体架构如图 3 所示,它由一个 YOLO 检测器、一个文本编码器和一个可重新参数化的视觉语言路径聚合网络 (RepVL-PAN) 组成。给定输入文本,YOLO-World 中的文本编码器将文本编码为文本嵌入。YOLO检测器中的图像编码器从输入图像中提取多尺度特征。然后,我们利用RepVL-PAN通过利用图像特征和文本嵌入之间的跨模态融合来增强文本和图像表示。
YOLO探测器
YOLO-World主要基于YOLOv8[20]开发,包含Darknet backbone[20,43]作为图像编码器,一个用于多尺度特征金字塔的路径聚合网络(PAN),以及一个用于边界盒回归(box regression)和对象嵌入(object embeddings)的头。
文本编码器
给定文本 T,我们采用 CLIP [39] 预先训练的 Transformer 文本编码器来提取相应的文本嵌入 W =TextEncoder(T)∈ R C×D,其中 C 是名词的数量,D 是嵌入维度。与纯文本语言编码器相比,CLIP文本编码器在将视觉对象与文本连接起来方面提供了更好的视觉语义功能[5]。当输入文本是标题或引用表达式时,我们采用简单的 n-gram 算法提取名词短语,然后将它们输入到文本编码器中。
文字对比头
根据之前的工作[20],我们采用具有两个3×3个convs来回归边界框{bk} 和对象嵌入{ek} ,其中K表示对象的数量。我们提出一个文本对比头来获得对象-文本相似度sk,j,
![]()
其中 L2-Norm(·) 是 L2 归一化,wj ∈ W 是第 j 个文本嵌入。此外,我们还添加了具有可学习比例因子α和移位因子β的仿射变换。L2范数和仿射变换对于稳定区域文本训练都很重要。
使用在线词汇进行训练
在训练过程中,我们为每个包含 4 张图像的mosaic样本构建一个在线词汇表 T。具体来说,我们对图像中涉及的所有正样本(positive nouns)进行采样,并从相应的数据集中随机抽取一些负样本(negtive nouns)。每个mosaic样本的词汇表最多包含 M 个名词,默认情况下 M 设置为 80。
使用离线词汇进行推理
在推理阶段,我们提出了一种带有离线词汇的prompt-then-detect策略,以提高效率。如图 3 所示,用户可以定义一系列自定义提示,其中可能包括标题或类别。然后,我们利用文本编码器对这些提示进行编码并获得离线词汇嵌入。离线词汇表可以避免对每个输入进行计算,并根据需要灵活调整词汇表。
3.3. 可重新参数化的视觉语言 PAN
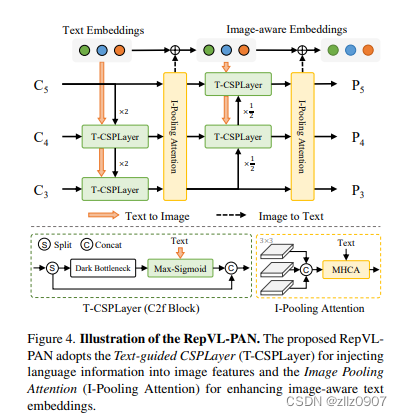
图 4 显示了所提出的 RepVL-PAN 的结构,该结构遵循 [20, 29] 中的自上而下和自下而上的路径,以建立具有多尺度图像特征 {C3, C4, C5} 的特征金字塔 {P3, P4, P5}。此外,我们提出了文本引导的CSPLayer(T-CSPLayer)和图像池注意力(I-Pooling Attention)来进一步增强图像特征和文本特征之间的交互,从而改善开放词汇能力的视觉语义表示。在推理过程中,可以将离线词汇表嵌入重新参数化为卷积层或线性层的权重,以便部署。
文本引导式 CSPLayer
如图 4 所示,在自上而下或自下而上的融合之后,使用跨级部分层 (CSPLayer)。我们扩展了 [20] 的 CSPLayer(也称为 C2f),将文本引导合并到多尺度图像特征中,以形成文本引导的 CSPLayer。具体来说,给定文本嵌入 W 和图像特征 Xl ∈ R H×W×D (l ∈ {3, 4, 5}),我们在最后一个dark bottleneck之后采用最大 sigmoid 注意力,通过以下方式将文本特征聚合为图像特征:
![]()
其中更新的 X′ l 与跨级特征连接作为输出。δ表示 sigmoid 函数。
图像池注意力
为了使用图像感知信息增强文本嵌入,我们通过提出图像池注意力来聚合图像特征以更新文本嵌入。我们没有直接对图像特征使用交叉注意力,而是利用多尺度特征的最大池化来获得 3×3 个区域,从而产生总共 27 个patch tokens X ̃ ∈ R 27×D。然后,通过以下方式更新文本嵌入:
![]()
3.4. 预训练方案
在本节中,我们介绍了在大规模检测、grounding和图像文本数据集上预训练 YOLO-World 的训练方案。
从区域文本对比损失中学习
给定mosaic样本 I 和文本 T,YOLO-World 输出 K 个对象预测 {Bk, sk} 以及注释 Ω = {Bi , ti} 。我们遵循 [20] 并利用任务对齐的标签分配 [9] 将预测与真实注释进行匹配,并使用文本索引分配每个正预测作为分类标签。基于该词汇,我们通过对象-文本(区域-文本)相似性和对象-文本赋值之间的交叉熵,构建了具有区域-文本对的区域-文本对比损失Lcon。此外,我们采用IoU损耗和分布焦点损耗( distributed focal loss)进行边界盒回归,总训练损耗定义为:L(I) = Lcon + λI ·(Liou + Ldfl),其中 λI 是一个指标因子,当输入图像 I 来自检测或grounding数据时设置为 1,当它来自图像文本数据时设置为 0。考虑到图像-文本数据集具有噪声框,我们仅计算具有精确边界框的样本的回归损失。
使用图像-文本数据进行伪标记
我们提出了一种自动标记方法来生成区域-文本对,而不是直接使用图像-文本对进行预训练。具体来说,标注方法包含三个步骤:(1)提取名词短语:我们首先利用n-gram算法从文本中提取名词短语;(2)伪标签:我们采用预先训练的开放词汇检测器,例如GLIP [24],为每个图像的给定名词短语生成伪框,从而提供粗略的区域-文本对。(3)过滤:我们采用预先训练的CLIP[39]来评估图像-文本对和区域-文本对的相关性,并过滤低相关性的伪注释和图像。我们通过结合非最大抑制 (NMS) 等方法进一步过滤冗余边界框。通过上述方法,我们用 821k 伪注释对 CC3M [47] 中的 246k 图像进行采样和标记。
四、实验
为了验证所提方法的有效性,论文在具有挑战性的LVIS数据集上进行了实验。实验包括了零样本检测和细粒度的下游任务,如对象检测和开放词汇表实例分割。
在LVIS minival测试集上,YOLO-World在零样本情况下达到了35.4的AP,同时保持了52.0 FPS的高速度。此外,经过微调后的YOLO-World在多个下游任务上也展现了卓越的性能。