在法律领域,语言模型(Language Models, LLMs)的发展一直面临着独特的挑战。法律文本的复杂性、专业术语的广泛使用以及对精确性和可靠性的极高要求,使得法律领域的自然语言处理(Natural Language Processing, NLP)任务变得尤为困难。近年来,随着大语言模型(Large Language Models,LLMs)的快速发展,我们见证了在多个基准测试中性能的显著提升,例如SuperGLUE、MMLU,以及各种人类考试,包括美国律师资格考试。然而,特定领域训练(domain-specific training)与领域内评估(within-domain evaluation)之间的相互作用尚不清楚。
分享几个网站
GPT-3.5研究测试:
https://hujiaoai.cn
GPT-4研究测试:
https://higpt4.cn
Claude-3研究测试(全面吊打GPT-4):
https://hiclaude3.com
本文将探讨在法律特定语料库上训练的模型在法律领域评估基准上的表现。我们将展示特定领域预训练和指令调整(instruction tuning)如何提高性能,但这种效果并不会在所有任务、训练体制、模型大小和其他因素中普遍存在。此外,尽管大型封闭模型在法律文本上的表现要好于较小的开放模型,但在法律领域,由于信任和数据保护的原因,许多公司需要在本地部署模型,因此不能使用公共模型,这强调了开放模型的需求。
如下图所示,本研究提出的FLawN-T5模型,通过在领域内指令调整和继续预训练Flan-T5模型,探索提升模型性能的潜力。通过整合和编写指令,本文创建了首个法律指令数据集LawInstruct,并在此基础上对T5系列模型进行了继续预训练和指令调整,取得了在LegalBench上的新的最佳表现。论文还对不同的数据集配置进行了广泛的消融研究,为领域适应提供了新的见解,并公开发布了许可较为宽松的数据集部分。
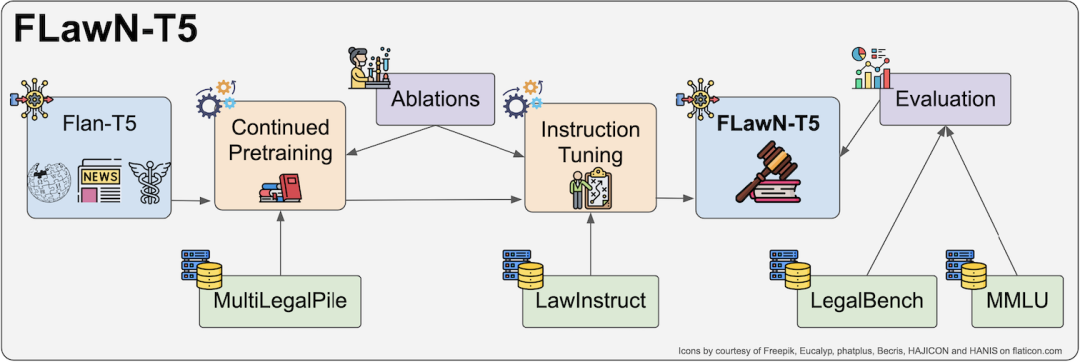
论文标题:
FLawN-T5: An Empirical Examination of Effective Instruction Tuning Data Mixtures for Legal Reasoning
论文链接:
https://arxiv.org/pdf/2404.02127.pdf
项目地址:
https://huggingface.co/lawinstruct/lawinstruct
https://github.com/JoelNiklaus/LawInstruct/
构建法律指令数据集:LawInstruct的创立与特点
1. 覆盖范围与语言多样性
LawInstruct是一个大型的法律指令数据集,它的创建是为了填补现有法律任务数据集的空白,并加速法律领域模型的发展。这个数据集涵盖了17个司法管辖区,包括24种语言,从而确保了其广泛的覆盖范围和语言多样性。这种多样性对于构建能够处理不同法律系统和语言环境的模型至关重要。
2. 数据集规模与任务类型
LawInstruct数据集的规模相当庞大,包含了总计1200万个示例。这些示例涉及多种任务类型,如问答(QA)、蕴含、摘要和信息提取等,每个任务都配有相应的指令和输出。这种多任务性质的数据集为法律领域的自然语言处理模型提供了丰富的训练材料,有助于提升模型在各种法律推理任务上的性能。
下图是LawInstruct中的StackExchangeQuestionsLegal的指令模板,填充了指令(Instruction)、提示(Prompt)和答案(Answer)。模型被训练为基于指令和提示生成答案。

模型性能提升:特定领域预训练与指令调整
1. 预训练的法律语料库:MultiLegalPile
为了进一步提升模型的性能,研究人员使用了MultiLegalPile,这是一个689GB的多语言法律语料库,包含来自17个司法管辖区的文本。这个语料库的多样性和规模为模型提供了一个广泛的法律领域预训练平台。通过在此语料库上进行预训练,模型能够更好地适应法律语言的特点和复杂性。
2. 指令调整的影响与改进
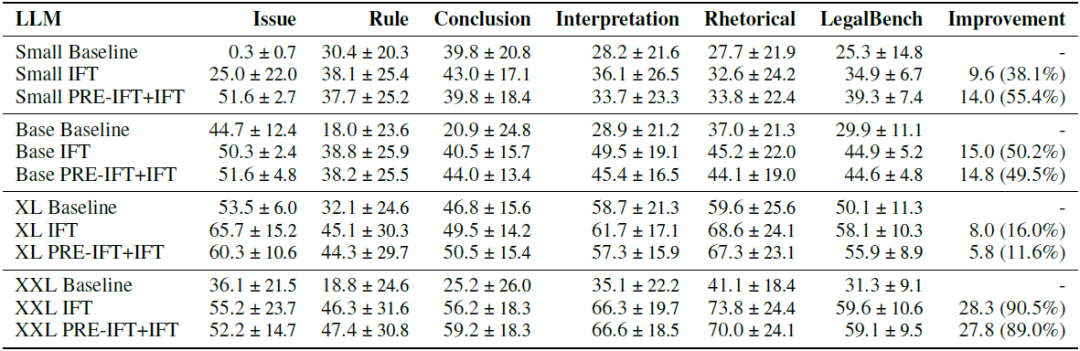
指令调整是提升模型性能的另一个关键步骤。通过在LawInstruct上进行微调,研究人员发现Flan-T5 XL模型在LegalBench上的平衡准确率提高了8个百分点,即提升了16%(下表)。然而,这种效果并不是在所有任务、训练体制、模型大小和其他因素中都能普遍实现的。这表明,虽然指令调整对于模型性能的提升至关重要,但其效果可能受到多种因素的影响。因此,研究人员需要继续探索不同的指令调整策略,以便找到最有效的方法来提升法律领域模型的性能。
实验设置与评估方法
1. 模型选择与实验环境
在本研究中,我们选择了T5 v1.1+LM适应模型、Flan-T5以及mT5模型,并考虑了不同的模型尺寸,包括Small、Base、XL和XXL。这些模型被选中的原因包括:Flan-T5 XL和XXL在LegalBench上的表现最佳、T5和mT5允许我们在受控环境中测量多语言性的影响,以及T5模型家族包含从60M参数(Small)到11B参数(XXL)的不同规模,允许我们研究在较小规模下的扩展行为。实验使用了随机种子42,并在TPUv4 pods上进行,使用了2到512个核心。
2. 评估标准:LegalBench与MMLU
评估工作主要在LegalBench和MMLU上进行。LegalBench由162个任务组成,评估了法律分类和推理的不同方面。每个任务根据所涉及的法律推理的广泛类型被分配到六个类别之一。LegalBench的任务来自之前构建的数据集和法律社区成员(如律师、法律影响组织、法学学者)收集的新任务。Massively Multilingual Language Understanding (MMLU) 评估模型的事实知识,包含57个主题的多项选择问题,其中包括与法律相关的三个主题:法理学、国际法和职业法。评估时,我们将温度设置为0,以符合LegalBench评估的公认做法,该评估侧重于最高可能性的Token序列,变化最小。
结果分析:FLawN-T5模型的表现
1. 在LegalBench上的表现
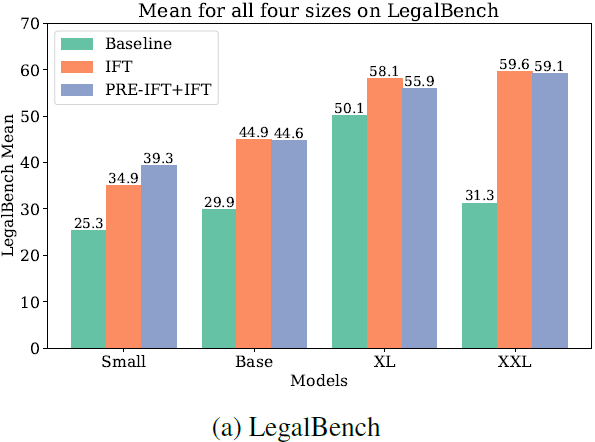
如下图所示,通过在LawInstruct上对Flan-T5模型进行指令调整,我们在LegalBench上取得了58.1的平衡准确率,相比基线提高了8分或16%。对于Small模型,甚至提高了9.6分或38.1%,当我们继续对其进行预训练时,提高了14分或55.4%。
2. 在MMLU上的泛化能力
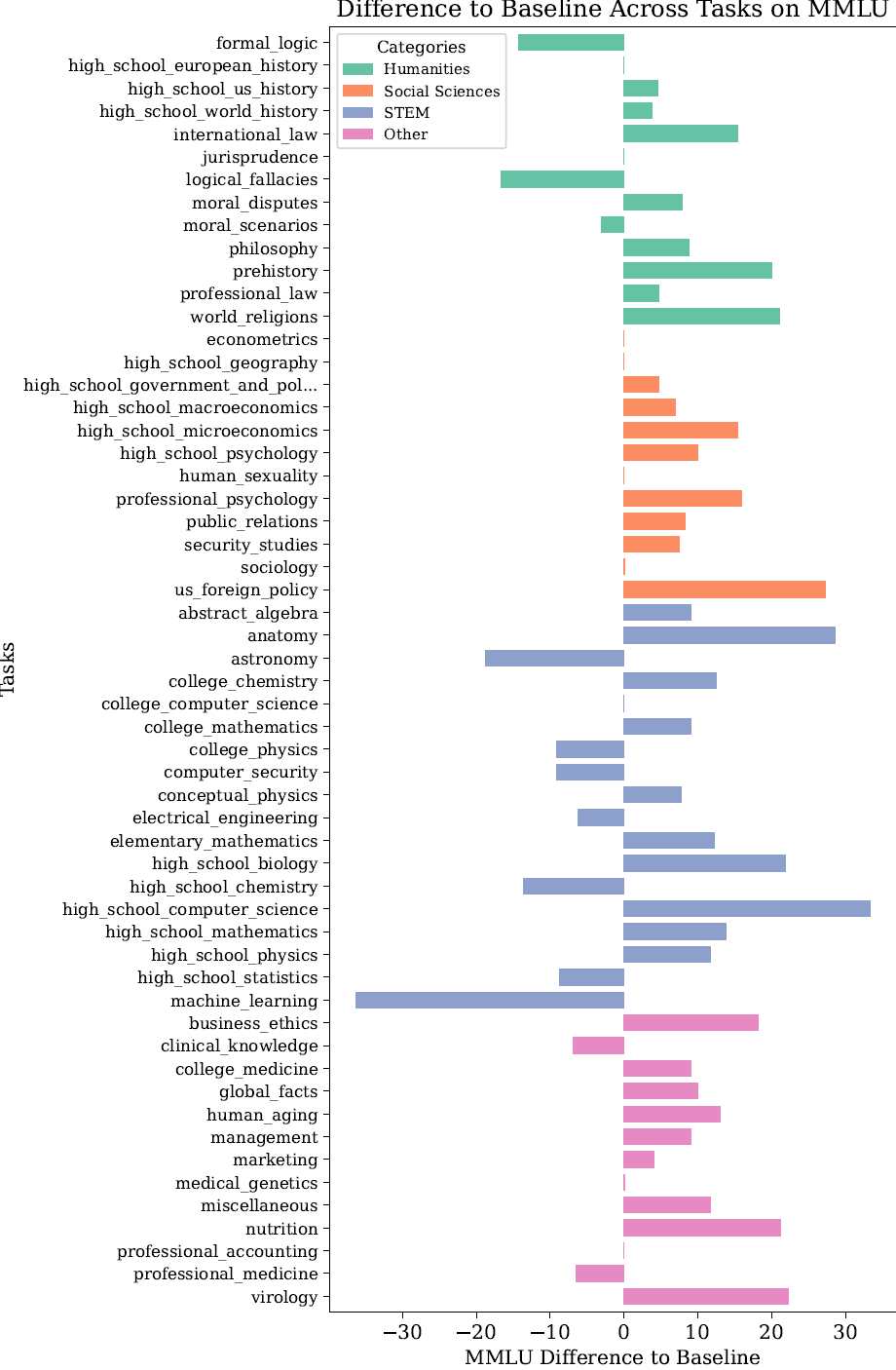
如下图所示,在MMLU上,大多数类别和任务的表现都有所提升,尤其是社会科学和其他类别。我们发现,性能主要在STEM类别中下降,在人文科学中也有所下降。有趣的是,机器学习类别的下降最大,但高中计算机科学类别的上升最大。在人文科学中,更多“硬”学科受到性能下降的影响,如形式逻辑和逻辑谬误。总体而言,我们在结论和解释类别中看到较低的改进。结论是LegalBench类别中需要更复杂推理能力的类别之一;也许更大的模型在那里会看到更大的收益。
深入探讨:不同训练策略的影响
在本章节中,我们将深入探讨不同训练策略对LLMs在法律领域的性能影响。通过对指令调整的起点模型、数据混合与采样方式、训练数据的许可证类型以及指令样式的多样性等方面的分析,我们旨在揭示这些因素如何影响模型的法律推理能力。
1. 指令调整的起点模型
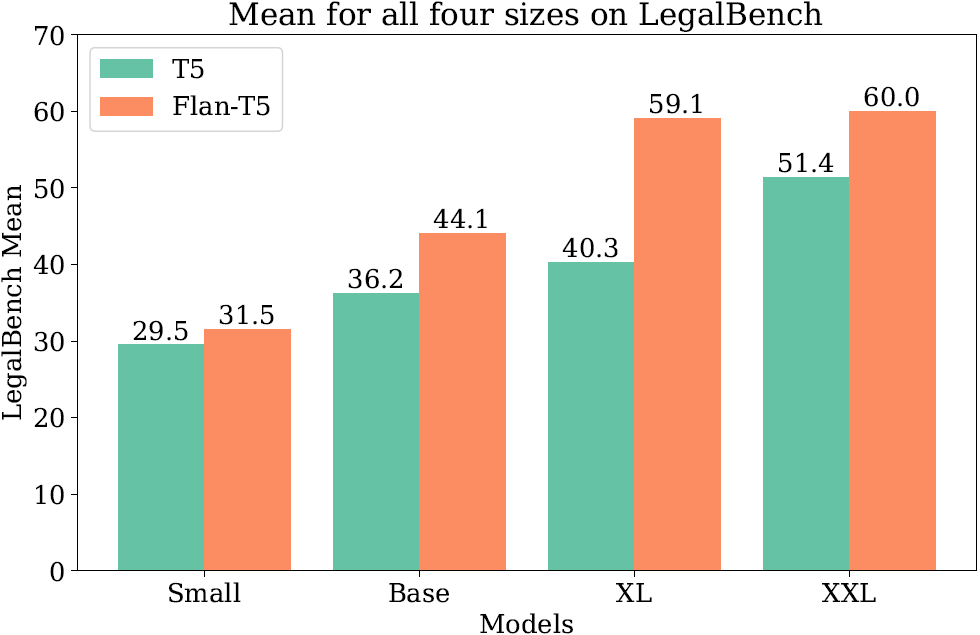
我们对分别从基础T5模型和Flan-T5模型开始的指令调整进行比较(这些模型有四种不同的尺寸,小型、基础型、XL和XXL)。研究结果显示(下图),对于较大规模的模型,以经过指令调整的Flan-T5作为起点能够带来更佳的性能表现,尤其是在LegalBench测试中。因此,在后续的实验中,除非有特别说明,我们通常将Flan-T5模型作为起始模型进行指令调整。
2. 数据混合与采样方式
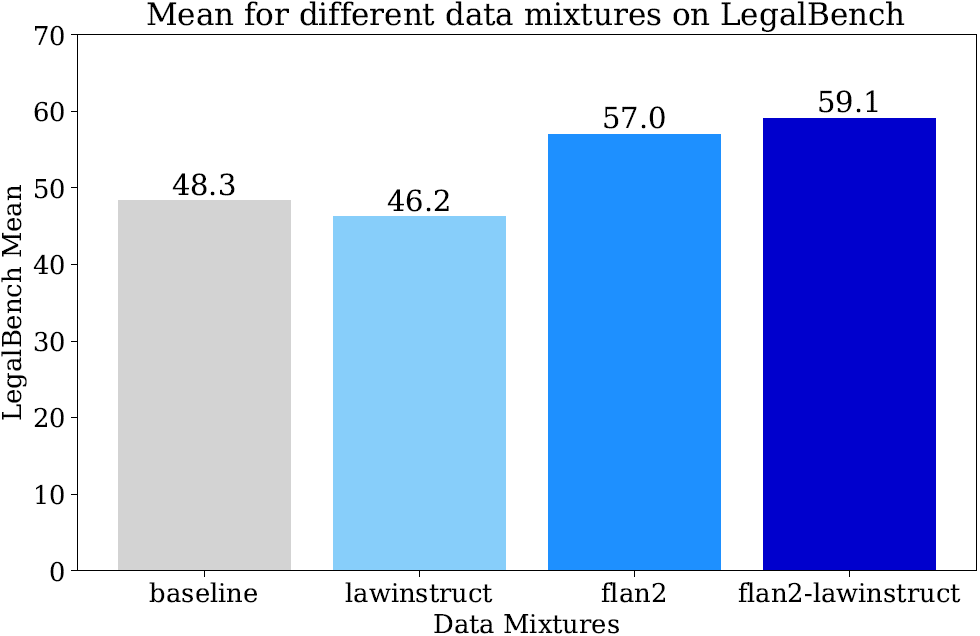
数据混合和采样方式对模型的性能有显著影响。在实验中,研究人员发现,当仅使用法律指令数据集(LawInstruct)进行训练时,模型在下游任务的准确性会下降。这可能是因为LawInstruct中的指令与原始Flan指令的表述方式不同。然而,当将法律指令数据与一般指令数据(如flan2)混合时,模型的性能得到了提升(下图)。
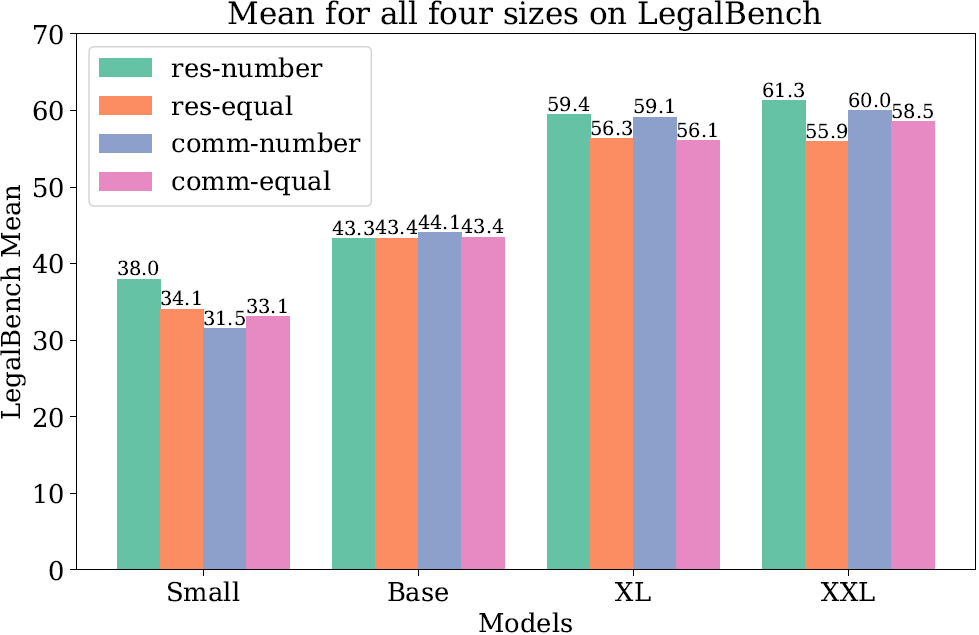
此外,通过样本数量进行采样通常比平等采样每个数据集更能提高性能,尤其是在大型模型中(下图中number/equal的对比)。
3. 训练数据的许可证类型
训练数据的许可证类型也是一个重要因素。研究发现(上图中res/comm的对比),对于大型模型,使用商业许可证的数据就足以达到良好的性能。这表明,在某些情况下,更多样化的、仅供研究使用的数据并没有显著的额外好处。
4. 指令样式的多样性
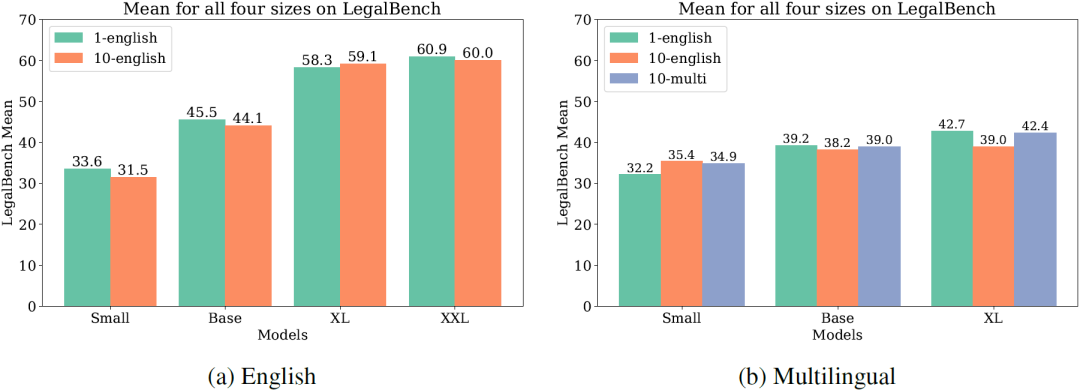
指令样式的多样性对模型性能的影响是混合的。在一些情况下,使用单一的手工编写指令比使用十个由GPT-4改写的指令更有效(下图)。然而,对于小型模型,多样化的指令样式似乎更有益。整体而言,使用单一指令可能已经足够,而无需额外的多样化。
结论与未来展望:法律领域模型的发展方向
我们成功创建并发布了LawInstruct,这是首个针对法律领域的指令调整数据集。通过整合多个高质量注释的数据集,并为不同法律任务编写详细的指令,我们对基于T5的模型进行了指令调整,开发出了FLawN-T5,并在LegalBench的所有参数尺寸上取得了最先进的成果。
未来的计划,首先进一步扩展LawInstruct,纳入更多高质量的法律数据集,如长篇幅法律问答、关键词生成、否定范围解析和法律违规检测等,这些都是我们实验之后发布的数据集。此外,我们期望与法律专业人士合作,识别并标注法律领域的新任务,以更好地适应和解决实际法律问题。
其次,探索合成数据在法律领域的应用。包括根据指令生成响应或反向操作,从响应生成指令。然而,我们必须注意进行严格的质量检查,以防止生成的错误内容对法律领域的应用造成损害。
最后,我们计划研究T5预训练数据集C4与MultiLegalPile之间的重叠,以更深入地理解持续预训练的潜在好处。通过这些工作,我们希望进一步提升法律领域语言模型的性能和应用广度。
