Reka Core, Flash, and Edge: A Series of Powerful Multimodal Language Models
相关链接:arxiv
关键字:Multimodal Language Models、Reka Core、Reka Flash、Reka Edge、State-of-the-Art
摘要
我们介绍了 Reka Core、Flash 和 Edge,这是一系列由 Reka 从头开始训练的强大多模态语言模型。Reka 模型能够处理和推理文本、图像、视频和音频输入。这份技术报告讨论了这些模型的一些训练细节,并提供了全面的评估结果。我们展示了 Reka Edge 和 Reka Flash 不仅是各自计算类别中的最新技术,而且还超过了许多更大的模型,为各自的计算类别提供了巨大的价值。同时,我们最有能力且最大的模型 Reka Core,在自动评估和盲人评估中接近最佳前沿模型(OpenAI, 2023; Google, 2023; Anthropic, 2024)。在图像问答基准测试(例如 MMMU, VQAv2)中,Core 与 GPT4-V 竞争性表现。在多模态聊天中,Core 在盲人第三方人类评估设置下排名第二,超过了其他模型,如 Claude 3 Opus。在文本基准测试中,Core 不仅在一系列成熟基准测试(例如 MMLU, GSM8K)上与其他前沿模型竞争性表现,而且在人类评估中超过了 GPT4-0613。在视频问答(Perception-Test)中,Core 超过了 Gemini Ultra。模型已在 chat.reka.ai 生产环境中使用。还可以在 showcase.reka.ai 找到非挑选的定性示例展示。
核心方法
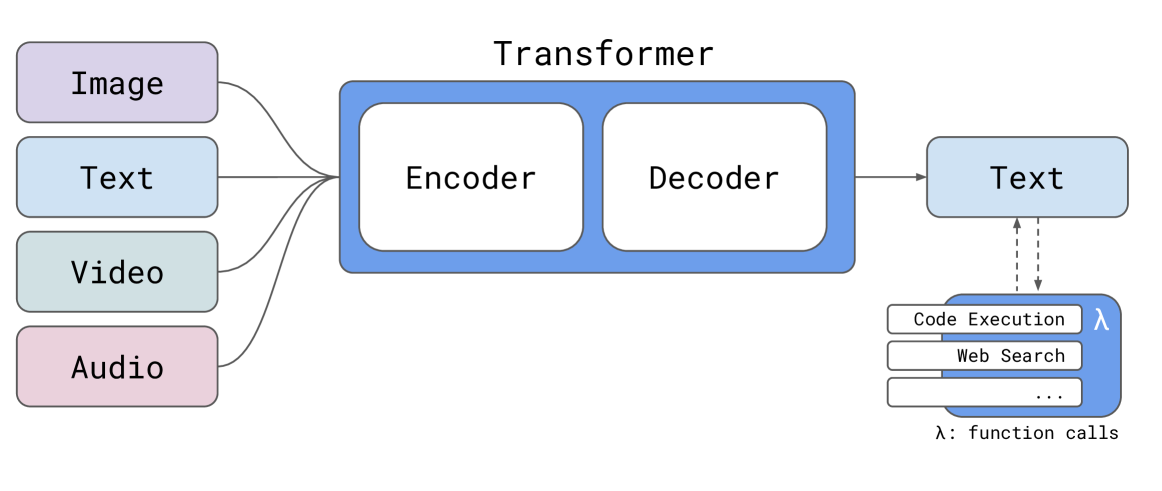
- 模型规模:Reka Edge 和 Flash 分别拥有 7B 和 21B 参数的密集模型。
- 多模态输入:模型能够处理文本、图像、视频和音频输入。
- 架构:采用模块化的编码器-解码器架构,支持多模态输入。
- 训练数据:包括大量公开可用和专有/许可的数据集,知识截止日期为 2023 年 11 月。
- 上下文长度:标准模型的上下文长度为 8K,而 Reka Flash 和 Core 的长上下文模型为 128K。
- 计算与基础设施:主要在 Nvidia H100s 上使用 Pytorch 进行训练。
- 后训练:包括指令调整和强化学习的人类反馈。
实验说明
Reka 模型在语言和视觉(视频 + 图像)任务上的综合评估和基准测试,以及作为初创公司训练大型多模态模型的一些有趣技术细节和幕后情况。讨论的领域包括基础设施、数据管道、计算、注释管道等。
实验结果数据
| Model / Eval | Reka Core v0.5 | Reka Flash v1.5 | GPT-4 | Claude 3 Opus | Claude 3 Sonnet | Gemini Ultra | Gemini Pro 1.5 |
|---|---|---|---|---|---|---|---|
| MMLU (Knowledge) | 83.2 | 75.9 | 86.4 | 86.8 | 79.0 | 83.7 | 81.9 |
| GSM8K (Reasoning) | 92.2 | 85.8 | 92.0 | 95.0 | 92.3 | 94.4 | 91.7 |
| HumanEval (Coding) | 76.8 | 72.0 | 76.5 | 84.9 | 73.0 | 74.4 | 71.9 |
| GPQA (main) (Hard QA) | 38.2 | 34.0 | 38.1 | 50.2 | 39.1 | 35.7 | 41.5 |
| MMMU (Image QA) | 56.3 | 53.3 | 56.8 | 59.1 | 53.1 | 59.4 | 58.5 |
| VQAv2 (Image QA) | 78.1 | 78.4 | 77.2 | - | - | 77.8 | 73.2 |
| Perception-test (Video QA) | 59.3 | 56.4 | - | - | - | 54.7 | 51.13 |
实验结果显示 Reka Core 在多个基准测试中与其他前沿模型竞争性表现,并在某些情况下超过了 Gemini Ultra 和 Claude 3 系列模型。Reka Flash 和 Core 在视频问答中超过了 Gemini Ultra 和 Pro 1.5。
结论
我们介绍了新的一系列强大的多模态模型,即 Reka Core、Flash 和 Edge。Reka Flash 和 Edge 在计算类别基础上树立了新的最先进技术,通常为它们的规模提供了巨大的价值。我们的核心模型在人类评估和自动基准测试中接近前沿类别模型。Reka Core 仍在改进中,因此我们预计在中期内会看到更多的改进。大型语言模型(LLM)领域仍在快速发展,尽管有大量的噪声。我们希望这份技术报告展示了在有限资源下从头开始构建前沿类别模型所需的严谨性。