Hive服务
HiveServer2、Hive Metastore 服务服务共同构成了 Hive 生态系统中的核心功能,分别负责管理元数据和提供数据查询服务,为用户提供了一个方便、高效的方式来访问和操作存储在 Hive 中的数据。
1. Hive 查询服务(HiveServer2):
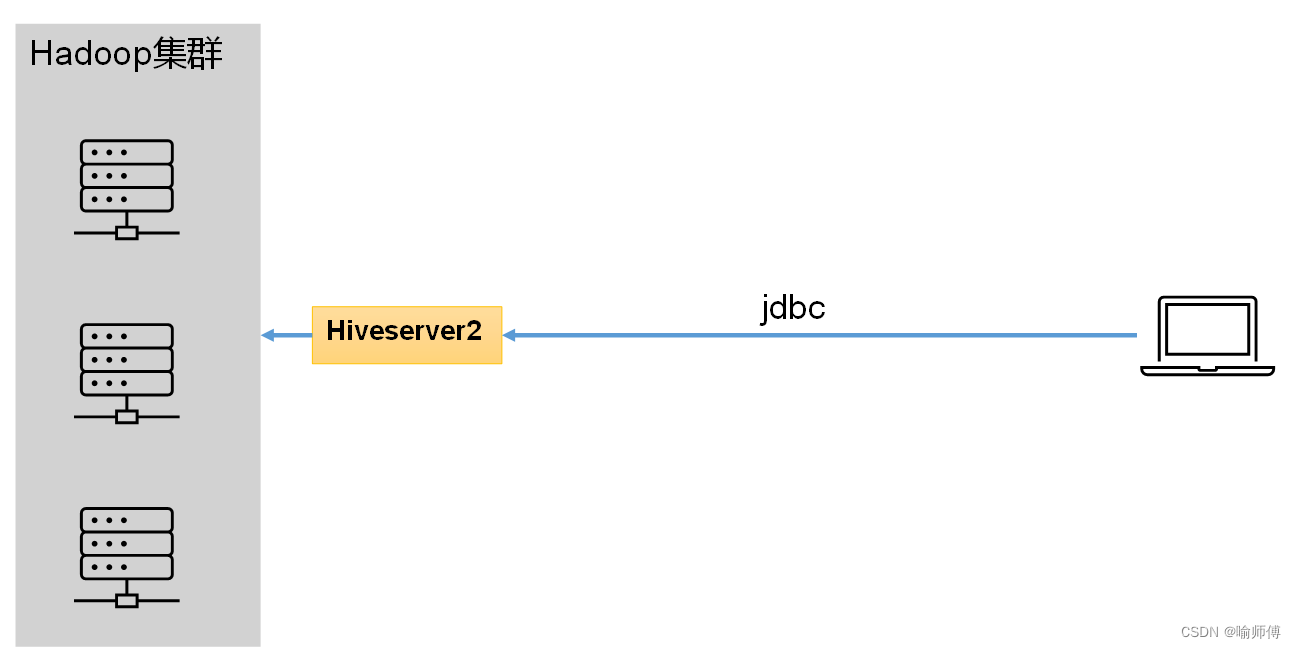
- Hive 查询服务是通过 JDBC 或 ODBC 接口提供 SQL 查询功能的服务,为用户提供远程访问Hive数据的功能,例如用户期望在个人电脑中访问远程服务中的Hive数据,就需要用到Hiveserver2。
- 它允许用户通过标准 SQL 查询语言来访问存储在 Hive 中的数据,并将查询结果返回给客户端。
- HiveServer2 提供了多用户并发访问的能力,并支持身份验证、授权等安全特性。
- 用户可以通过各种客户端工具(如 Beeline、Python、Java 等)连接到 HiveServer2,执行查询操作。
Hiveserver2用户说明
- 在远程访问Hive数据时,客户端并未直接访问Hadoop集群,而是由Hivesever2代理访问。
- 由于Hadoop集群中的数据具备访问权限控制,所以此时需考虑一个问题:那就是访问Hadoop集群的用户身份是谁?是Hiveserver2的启动用户?还是客户端的登录用户?
- 答案是都有可能,具体是谁,由Hiveserver2的hive.server2.enable.doAs参数决定,该参数的含义是是否启用Hiveserver2用户模拟的功能。
- 若启用,则Hiveserver2会模拟成客户端的登录用户去访问Hadoop集群的数据,不启用,则Hivesever2会直接使用启动用户访问Hadoop集群数据。模拟用户的功能,默认是开启的。
1.未开启用户模拟
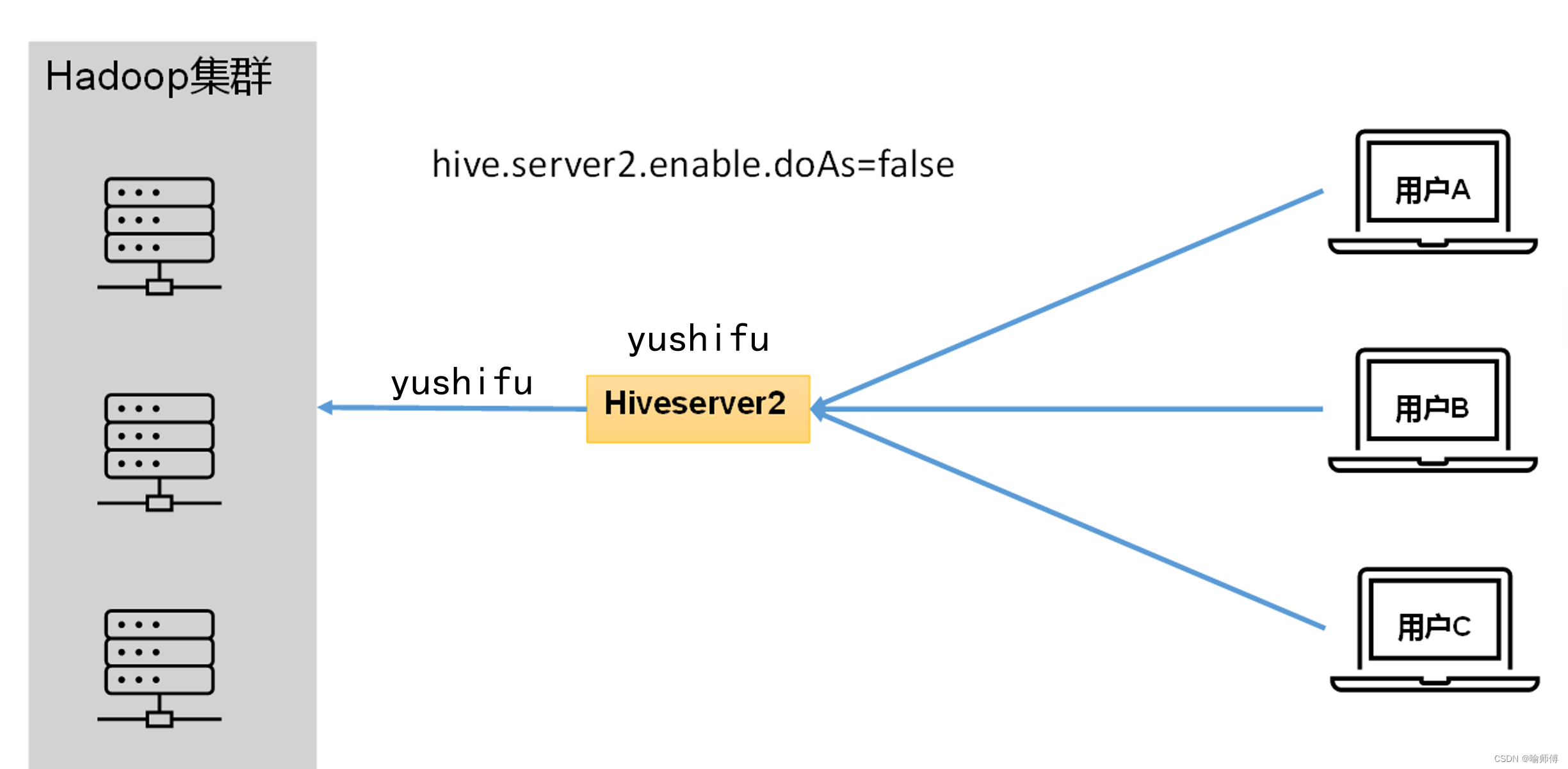
在生产环境中未开启用户模拟功能可能会造成以下影响:
- 权限混淆:
- 如果未开启用户模拟功能,所有的查询和操作都将以 HiveServer2 进程的身份进行。
- 这样一来,不同用户之间的权限将会混淆,所有用户都将共享相同的权限。
- 这可能导致数据访问和操作的混乱,无法实现对不同用户的精细化权限控制。
- 安全风险:
- 缺乏用户模拟功能会增加系统的安全风险。因为所有的查询和操作都以相同的身份进行,一旦有用户的凭据泄露或者被滥用,就可能导致对系统中敏感数据的非法访问和操作。
- 这可能会造成数据泄露、数据损坏或者其他安全问题。
- 难以追踪和审计:
- 缺乏用户模拟功能会使得对用户操作的追踪和审计变得困难。
- 由于所有的操作都以相同的身份进行,无法准确追踪到是哪个用户执行了具体的查询或操作,也无法对用户的行为进行有效的审计和监控。
- 管理复杂性增加:
- 在没有用户模拟功能的情况下,管理员需要更加谨慎地管理用户的权限,以确保不会发生数据访问和操作的冲突。这增加了管理的复杂性,并可能需要花费更多的时间和精力来维护系统的安全和稳定性。
因此,在生产环境中,强烈建议开启用户模拟功能,以确保不同用户之间的权限隔离和系统安全性。
2.开启用户模拟

生产环境,推荐开启用户模拟功能,因为开启后才能保证各用户之间的权限隔离,增强了系统的安全性和可管理性。
- 权限隔离:
- 用户模拟功能允许不同用户以其自己的身份进行查询和操作,从而实现了权限的精细化管理和隔离。每个用户只能访问其被授权的数据和执行被授权的操作,有效保护了数据的安全性和完整性。
- 安全性增强:
- 通过用户模拟功能,系统可以对不同用户进行身份验证,并根据其角色和权限进行访问控制。这样可以有效防止未经授权的用户访问敏感数据,降低数据泄露和滥用的风险,提高系统的安全性。
- 审计和追踪:
- 用户模拟功能使得对用户操作的审计和追踪变得更加容易。每个查询和操作都可以被追踪到相应的用户身份,管理员可以准确地了解到是哪个用户执行了什么样的操作,从而更好地监控系统的使用情况和安全状态。
- 管理灵活性:
- 用户模拟功能提供了灵活的角色和权限管理机制,管理员可以根据实际需求为不同用户分配适当的角色和权限。这样可以根据实际情况灵活调整用户的权限,满足不同用户的需求,提高系统的管理灵活性和可维护性。
2. Hive Metastore 服务:
- Hive的metastore服务的作用是为Hive CLI或者Hiveserver2提供元数据访问接口。
- Hive Metastore 是负责管理 Hive 元数据的服务。
- 它存储了关于 Hive 数据库、表、分区、列等元数据信息,包括表的结构、存储位置等。
- Hive Metastore 通常使用关系型数据库(如 MySQL、Derby 等)来存储元数据信息。
- 这个服务的作用是提供对元数据的持久化存储和管理,以便其他 Hive 组件可以通过它来获取元数据信息。
metastore运行模式
在 Apache Hive 中,Metastore 有两种运行模式——嵌入式模式和独立服务模式。
1. 嵌入式模式(Embedded Mode):
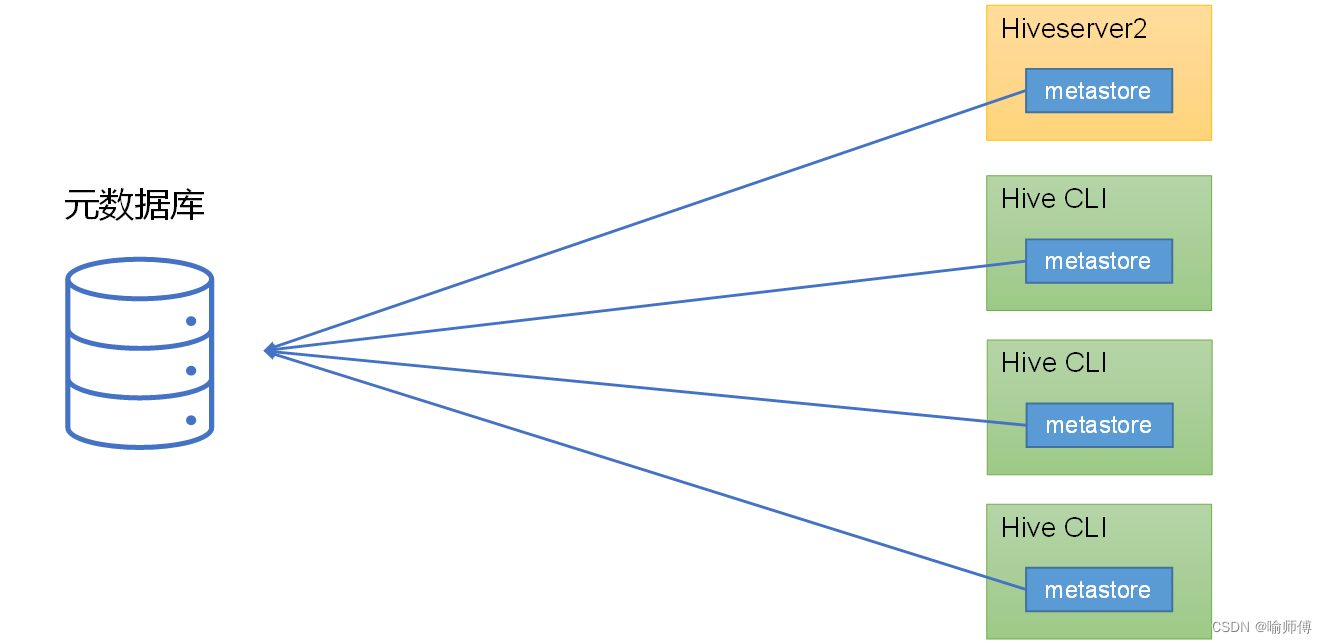
在嵌入式模式下,Metastore 服务与 HiveServer2 进程运行在同一台机器上,它们共享相同的 JVM 进程。
这种模式下,Metastore 直接作为 HiveServer2 的一部分运行,没有单独的 Metastore 服务进程。
嵌入式模式下,每个Hive CLI都需要直接连接元数据库,当Hive CLI较多时,数据库压力会比较大。
每个客户端都需要用户元数据库的读写权限,元数据库的安全得不到很好的保证。
这种模式通常用于小规模的数据处理任务或者单机环境下的开发和测试。
2. 独立服务模式(Standalone Mode):
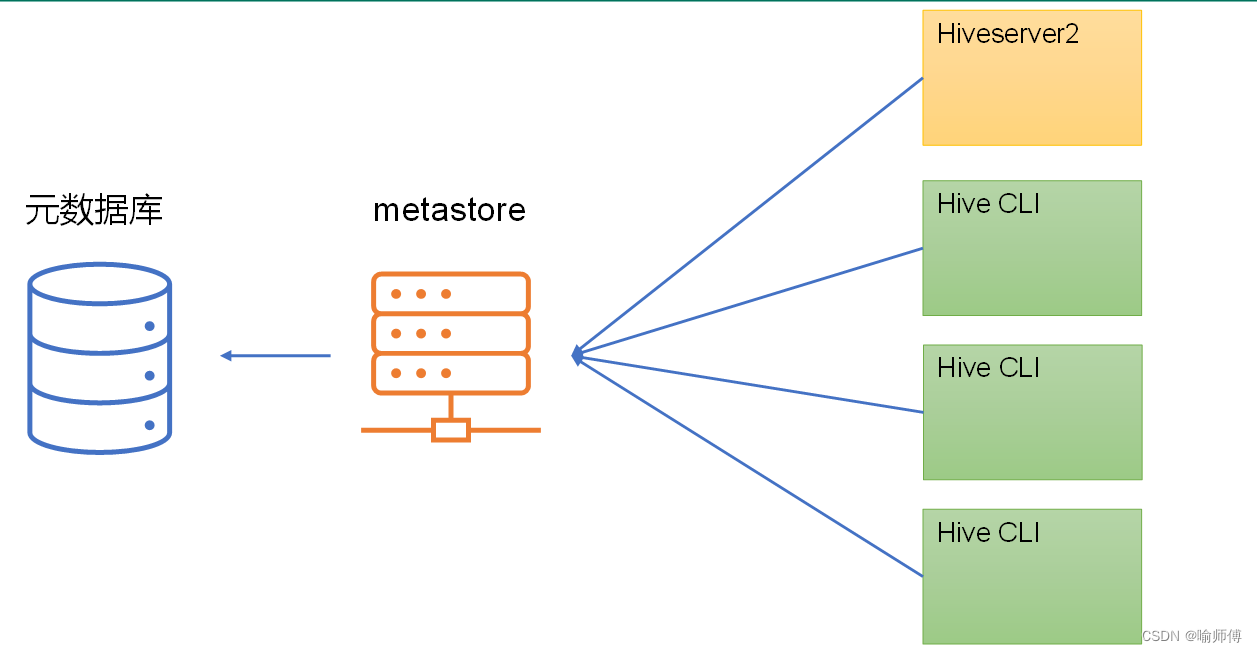
- 在独立服务模式下,Metastore 作为一个独立的服务运行在专用的服务器上,与 HiveServer2 进程分开。
- HiveServer2 进程通过网络与 Metastore 服务通信,Metastore 负责管理元数据,包括表、分区、列等信息。
- 这种模式通常用于生产环境,因为它提供了更好的可扩展性和灵活性,可以通过多台服务器构建高可用的 Metastore 集群,以应对大规模数据处理任务的需求。
选择适合的运行模式取决于实际的使用场景和需求。对于小规模或者开发测试环境,嵌入式模式可能更加方便简单;而对于生产环境或者大规模数据处理任务,独立服务模式则更为适合。