【 一 】Scrapy介绍
【0】前言
Scrapy知识预备
爬虫毕竟是在网页里面抓取数据的,因此前端那些东西没学过也要稍微懂点。HTML、CSS简单的语法,Xpath、正则表达式等等,需要有一些简单的基础。
Scrapy一个开源和协作的框架,其最初是为了页面抓取(更确切来说,网络抓取)所设计的,使用它可以快速、简单、可扩展的方式从网站中提取所需要的数据。但目前Scrapy的用途十分广泛,可用与如数据挖掘、监测和自动化测试等领域,也可以应用在获取API所返回的数据(如: Amazon Associatates web services)或者统一的网络爬虫。
Scrapy就是爬虫界的django
【 1 】开源和协作的框架
- 其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的,
- 使用它可以以快速、简单、可扩展的方式从网站中提取所需的数据。
- 但目前Scrapy的用途十分广泛,可用于如数据挖掘、监测和自动化测试等领域,也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。
- Scrapy 是基于twisted框架开发而来,twisted是一个流行的事件驱动的python网络框架。
- 因此Scrapy使用了一种非阻塞(又名异步)的代码来实现并发。
- Scrapy框架类似于Django框架
(摘自Scrapy官方文档:docs.scrapy.org/en/latest/i…
- https://docs.scrapy.org/en/latest/topics/architecture.htm
【 2 】Scrapy的基本介绍
【1】组件介绍
- Scrapy Engine(引擎) : 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
- Scheduler(调度器) : 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
- Downloader(下载器) :负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理,
- Spider(爬虫) :它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器).
- Item Pipeline(管道) :它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方。
- Downloader Middlewares(下载中间件) :你可以当作是一个可以自定义扩展下载功能的组件。
- Spider Middlewares(Spider中间件) :你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)
| 组件 | 作用 |
|---|---|
| Scrapy Engine | 引擎,处理整个框架的数据流 |
| Scheduler | 调度器,接收引擎发过来的请求,将其排至队列中,当引擎再次请求时返回 |
| Downloader | 下载器,下载所有引擎发送的请求,并将获取的源代码返回给引擎,之后由引擎交给爬虫处理 |
| Spiders | 爬虫,接收并处理所有引擎发送过来的源代码,从中分析并提取item字段所需要的数据,并将需要跟进的url提交给引擎,再次进入调度器 |
| Item Pipeline | 管道,负责处理从爬虫中获取的Item,并进行后期处理 |
| Downloader Middlewares | 下载中间件,可以理解为自定义扩展下载功能的组件 |
| Spider Middlewares | Spider中间件,自定义扩展和操作引擎与爬虫之间通信的功能组件 |
【2】数据流控制
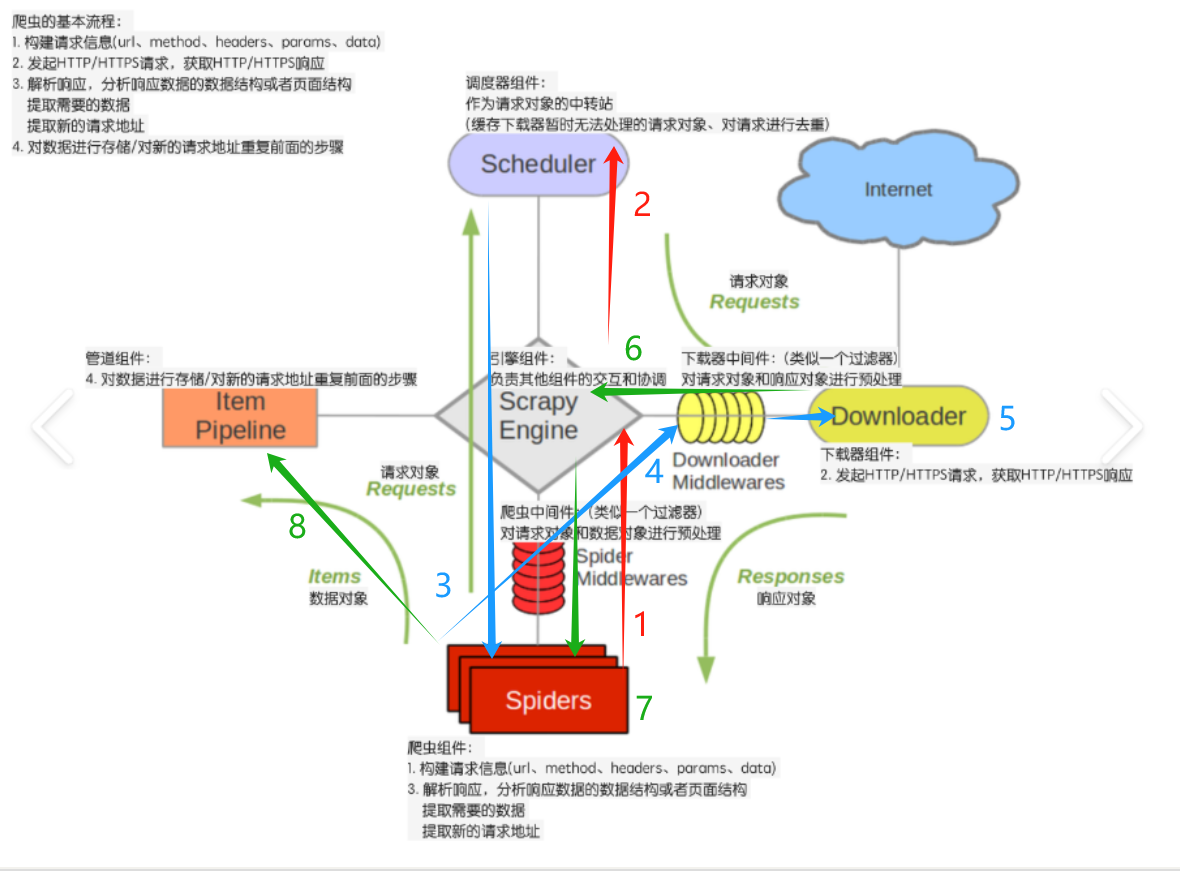 在Scrapy中,数据流由执行引擎控制,流程如下:
在Scrapy中,数据流由执行引擎控制,流程如下:
- 引擎从Spider获取要爬取的初始请求。
- 引擎将请求安排到调度器中,并请求下一个要爬取的请求。
- 调度器将下一个要爬取的请求返回给引擎。
- 引擎将请求发送给下载器,经过下载器中间件。
- 页面下载完成后,下载器生成一个带有该页面的响应,并将其发送给引擎,此过程会经过下载器中间件。
- 引擎从下载器接收响应,并将其经过Spider中间件发送给Spider进行处理。
- Spider处理响应,经过Spider中间件返回抓取的数据项和新的请求。
- 引擎将处理后的数据项发送到数据管道,然后将处理后的请求发送给调度器,并请求下一个要爬取的请求。
- 重复上述过程(从步骤3)直到调度器没有更多的请求为止。
其流程可以描述如下:
- 调度器把requests–>引擎–>下载中间件—>下载器
- 下载器发送请求,获取响应---->下载中间件---->引擎—>爬虫中间件—>爬虫
- 爬虫提取url地址,组装成request对象---->爬虫中间件—>引擎—>调度器
- 爬虫提取数据—>引擎—>管道
- 管道进行数据的处理和保存
【 3 】小结
scrapy的概念:Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架
scrapy框架的运行流程以及数据传递过程:
调度器把requests–>引擎–>下载中间件—>下载器
下载器发送请求,获取响应---->下载中间件---->引擎—>爬虫中间件—>爬虫
爬虫提取url地址,组装成request对象---->爬虫中间件—>引擎—>调度器
爬虫提取数据—>引擎—>管道
管道进行数据的处理和保存
scrapy框架的作用:通过少量代码实现快速抓取
掌握scrapy中每个模块的作用:
引擎(engine):负责数据和信号在不同模块间的传递 调度器(scheduler):实现一个队列,存放引擎发过来的request请求对象
下载器(downloader):发送引擎发过来的request请求,获取响应,并将响应交给引擎
爬虫(spider):处理引擎发过来的response,提取数据,提取url,并交给引擎
管道(pipeline):处理引擎传递过来的数据,比如存储
下载中间件(downloader middleware):可以自定义的下载扩展,比如设置代理ip
爬虫中间件(spider middleware):可以自定义request请求和进行response过滤理解异步和非阻塞的区别:异步是过程,非阻塞是状态
【 二 】Scrapy框架的基本使用
【1】查看帮助
scrapy -h
scrapy <command> -h
- 第一个命令用于查看全部可用命令的帮助信息
- 第二个命令用于查看特定命令的帮助信息
【2】全局命令和项目命令
- Project-only必须切到项目文件夹下才能执行
- Global的命令则不需要
Global commands:
startproject #创建项目
genspider #创建爬虫程序
settings #如果是在项目目录下,则得到的是该项目的配置
runspider #运行一个独立的python文件,不必创建项目
shell #scrapy shell url地址 在交互式调试,如选择器规则正确与否
fetch #独立于程单纯地爬取一个页面,可以拿到请求头
view #下载完毕后直接弹出浏览器,以此可以分辨出哪些数据是ajax请求
version #scrapy version 查看scrapy的版本,scrapy version -v查看scrapy依赖库的版本
Project-only commands:
crawl #运行爬虫,必须创建项目才行,确保配置文件中ROBOTSTXT_OBEY = False
check #检测项目中有无语法错误
list #列出项目中所包含的爬虫名
parse #scrapy parse url地址 --callback 回调函数 #以此可以验证我们的回调函数是否正确
bench #scrapy bentch压力测试
【1】全局命令(Global commands)
startproject:创建一个新的 Scrapy 项目。genspider:创建一个新的爬虫程序。settings:显示一个 Scrapy 项目的配置信息。runspider:运行一个独立的 Python 文件作为爬虫,不需要创建项目。shell:进入 Scrapy 的交互式调试环境,可以检查选择器规则是否正确。fetch:单独请求一个页面,并获取响应结果。view:下载指定页面并在浏览器中打开,用于检查通过哪些请求获取数据。version:查看当前安装的 Scrapy 版本号。
【2】项目命令(Project-only commands)
crawl:运行一个 Scrapy 爬虫,必须在项目目录下执行且确保配置文件中的ROBOTSTXT_OBEY设置为False。check:检查项目中是否存在语法错误。list:列出项目中包含的所有爬虫名称。parse:使用回调函数解析给定的 URL,用于验证回调函数是否正确。bench:用于对 Scrapy 进行压力测试。
【 3 】创建Scrapy项目
- 新建项目 (scrapy startproject xxx):新建一个新的爬虫项目**
【1】创建工程
scrapy startproject one

【2】查看文件目录结构
在Windows系统中,你可以使用
tree命令来显示当前目录及其子目录中的文件结构:# tree /F在类Unix/Linux系统中,你可以使用
tree命令来显示当前目录及其子目录中的文件结构,但需要先安装tree工具。如果没有安装,你可以使用ls命令来显示当前目录中的文件和目录:# ls -R
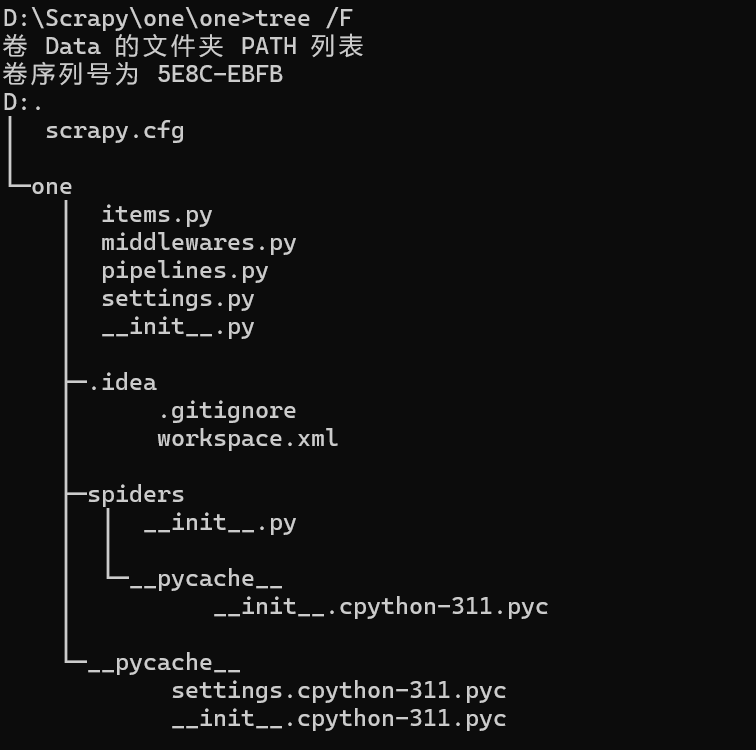
| 文件 | 作用 |
|---|---|
| scrapy.cfg | 配置文件 |
| spiders | 存放你Spider文件,也就是你爬取的py文件 |
| items.py | 相当于一个容器,和字典较像 |
| middlewares.py | 定义Downloader Middlewares(下载器中间件)和Spider Middlewares(蜘蛛中间件)的实现 |
| pipelines.py | 定义Item Pipeline的实现,实现数据的清洗,储存,验证。 |
| settings.py | 全局配置 |
- scrapy.cfg
- 项目的主配置信息,用来部署scrapy时使用,爬虫相关的配置信息在settings.py文件中。
- items.py
- 设置数据存储模板,用于结构化数据
- 如:Django的Model
- pipelines
- 数据处理行为
- 如:一般结构化的数据持久化
- settings.py
- 配置文件
- 如:递归的层数、并发数,延迟下载等。强调:配置文件的选项必须大写否则视为无效,正确写法USER_AGENT=‘xxxx’
- spiders
- 爬虫目录
- 如:创建文件,编写爬虫规则
【 3 】创建爬虫
要在Scrapy中创建一个爬虫,你可以使用以下命令:
# scrapy genspider <spider_name> <start_url>
其中,<spider_name>是你要创建的爬虫的名称,<start_url>是你要开始爬取的起始URL。
scrapy genspider 命令创建一个新的爬虫时,你需要提供两个参数:
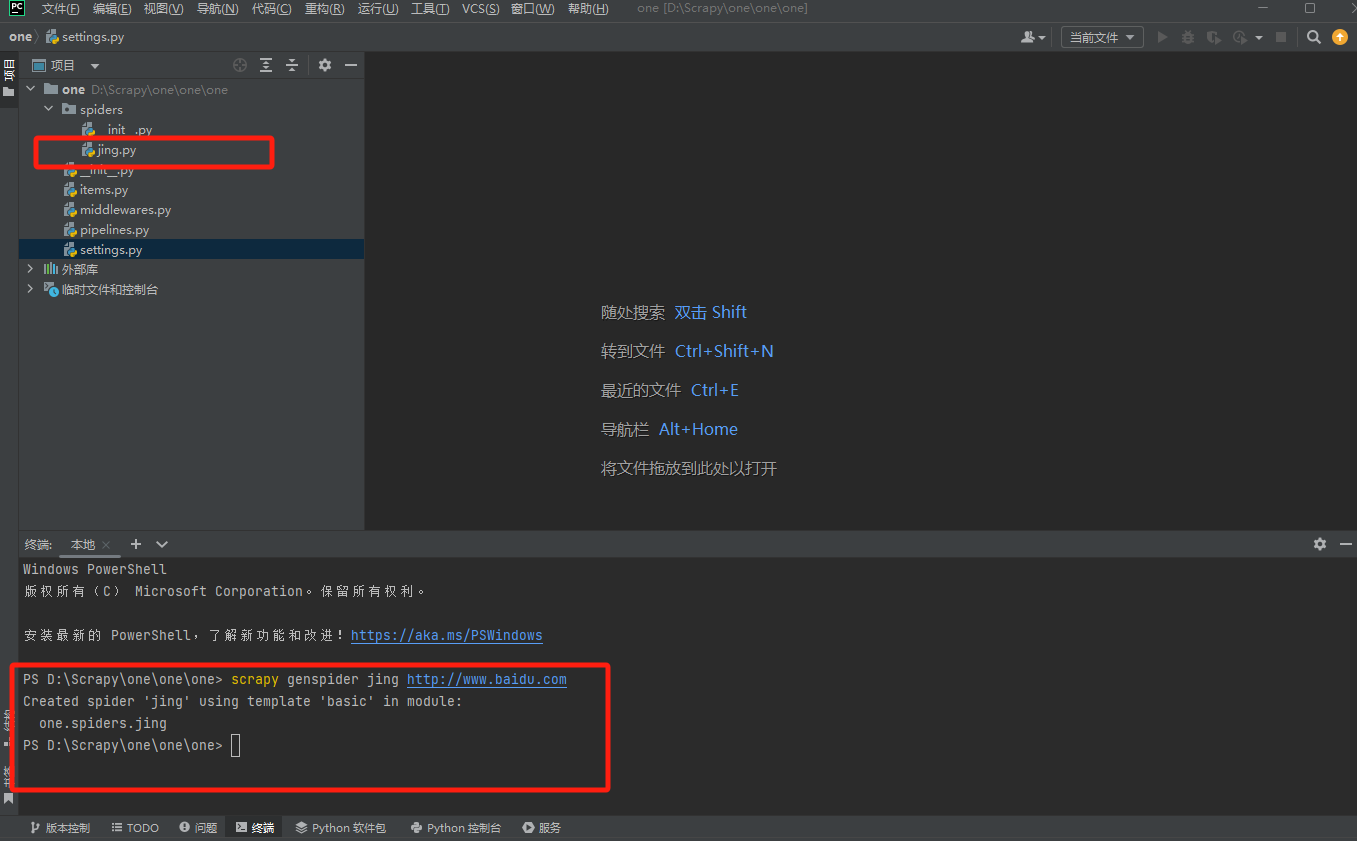
# scrapy genspider example http://example.com
# scrapy genspider jing http://www.baidu.com
- 爬虫文件的名字(可以是任何你喜欢的名字)。
- 要爬取的网站的起始URL
【4】简单测试
import scrapy
class JingSpider(scrapy.Spider):
# 爬虫文件的唯一标识
name = "jing"
# 允许访问的域名
allowed_domains = ["www.baidu.com"]
# 起始 的 URL 列表 (重要)
# 列表内部的 url 都会被框架进行异步请求发送
start_urls = ["http://www.baidu.com"]
# 数据解析主函数:自动调用
# 调用的次数取决于 start_urls 列表内元素的个数
def parse(self, response):
# response : 表示的就是响应对象
print("response:::", response.text)
【5】启动项目
- 通过指定的命令启动
Scrapy项目,而非通过文件启动
scrapy crawl jing
【6】优化启动
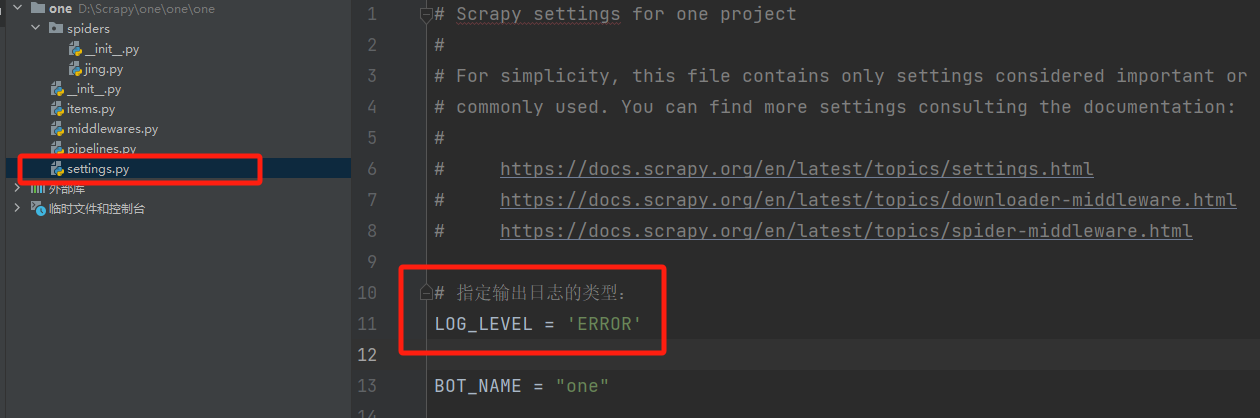
【1】降低日期等级
- 在
settings.py文件中添加指定配置项
# 指定输出日志的类型:
LOG_LEVEL = 'ERROR'
【2】不遵循ROBOTS协议
ROBOTSTXT_OBEY = False
【3】以启动文件启动项目
- 每一次终端启动和麻烦,我们可以在项目根目录下新建启动文件
- bin.py:
from scrapy.cmdline import execute
execute(['scrapy', 'crawl', '自定义爬虫文件名', "--nolog"])
【 三 】Scrapy框架之数据解析
【1】项目执行流程简解
- 启动爬虫:
- 开始执行爬虫程序。
- 创建Request对象:
- 将start_urls地址包装成request对象,其中包含待爬取的网页链接、回调函数等信息。
- 交给引擎:
- 将创建好的request对象交给引擎进行处理。
- 调度器排队:
- 引擎将请求交给调度器,调度器按照一定的策略(如先进先出)将请求放入队列中进行排队。
- 引擎处理:
- 引擎从调度器中取出请求,并选择合适的下载中间件进行处理。
- 下载器处理:
- 下载器根据请求中的链接发起网络请求,下载相应的页面内容,并将下载结果返回给引擎。
- 下载完成:
- 下载器将网页内容下载完成后,将下载结果返回给引擎。
- 引擎传递给爬虫:
- 引擎将下载结果传递给相应的爬虫解析函数(例如parse函数)进行处理。
- 爬虫解析:
- 爬虫解析函数对下载下来的网页内容进行解析,提取出需要的数据,并生成新的Request对象或是Item对象。
- 回到步骤2:
- 解析函数可以继续生成新的Request对象,或是处理Item对象
- 然后回到步骤2,继续执行后续的请求和解析过程。
【2】Xpath解析器
【1】概览
- Scrapy xpath语法,Xpath是XML Path的简介,基于XML树状结构,可以在整个树中寻找锁定目标节点。由于HTML文档本身就是一个标准的XML页面,因此我们可以使用XPath的语法来定位页面元素。
【2】路径表达式
| 表达式 | 描述 | 实例 |
|---|---|---|
| nodename | 选取nodename节点的所有子节点 | //div |
| / | 从根节点选取 | /div |
| // | 选取任意位置的节点,不考虑他们的位置 | //div |
| . | 选取当前节点 | ./div |
| … | 选取当前节点的父节点 | … |
| @ | 选取属性 | //@calss |
- 示例
| 语法 | 说明 |
|---|---|
| artical | 选取所有artical元素的子节点 |
| /artical | 选取根元素artical |
| ./artical | 选取当前元素下的artical |
| …/artical | 选取父元素下的artical |
| artical/a | 选取所有属于artical的子元素a元素 |
| //div | 选取所有div 子元素,无论div在任何地方 |
| artical//div | 选取所有属于artical的div 元素,无论div元素在artical的任何位置 |
| //@class | 选取所有class属性 |
| a/@href | 选取a标签的href属性 |
| a/text() | 选取a标签下的文本 |
| string(.) | 解析出当前节点下所有文字 |
| string(…) | 解析出父节点下所有文字 |
【3】谓语
- 谓语被嵌在方括号内,用来查找某个特定的节点或包含某个制定的值的节点
| 语法 | 说明 |
|---|---|
| /artical/div[1] | 选取所有属于artical 子元素的第一个div元素 |
| /artical/div[last()] | 选取所有属于artical子元素的最后一个div元素 |
| /artical/div[last()-1] | 选取所有属于artical子元素的倒数第2个div元素 |
| /artical/div[position()❤️] | 选取所有属于artical子元素的前2个div元素 |
| //div[@class] | 选取所有拥有属性为class的div节点 |
| //div[@class=”main”] | 选取所有div下class属性为main的div节点 |
| //div[price>3.5] | 选取所有div下元素值price大于3.5的div节点 |