此博客内容根据《SQL优化核心思想》的流程来进行书写,仅作为个人学习记录使用。当然,有问题可以一起来探讨!
一、基数(CARDINALITY)
某个列唯一键(Distinct_Keys)的数量叫作基数。性别列只有男女,那么基数为2。
以test为例,其中的某个列的基数如下:
select count(distinct owner),count(distinct object_id),count(*) from test;
从中我们可以看出总共有72889行,OWNER列的基数为26,说明该列有大量的重复值,OBJECT_ID与总条数一至,可以理解为主键,OWNER分布如下:
SQL> col OWNER for a15;
SQL> select owner,count(*) from test group by owner order by 2 desc;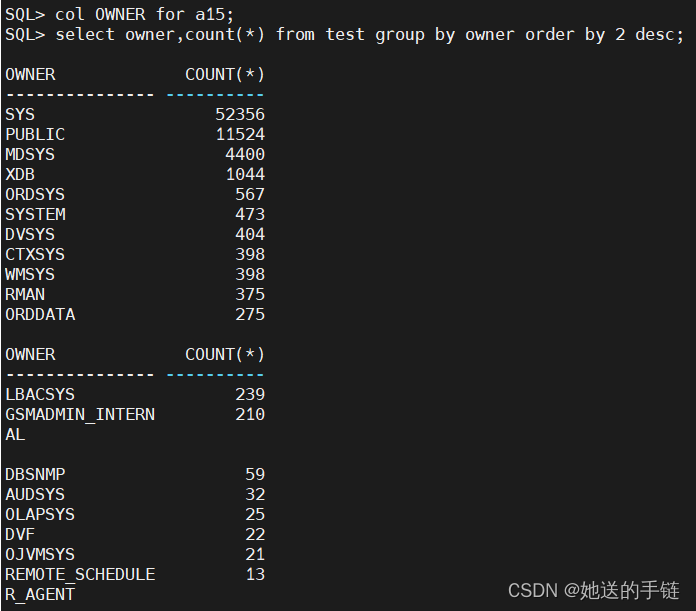
总结:
如果某个列基数很低,该列数据分布就会非常不均衡,由于该列数据 分布不均衡,会导致 SQL 查询可能走索引,也可能走全表扫描。在做 SQL 优化的时候,如果 怀疑列数据分布不均衡,我们可以使用 select 列,count(*) from 表 group by 列 order by 2 desc 来查看列的数据分布。
如果 SQL 语句是单表访问,那么可能走索引,可能走全表扫描,也可能走物化视图扫描。 在不考虑有物化视图的情况下,单表访问要么走索引,要么走全表扫描。现在,回忆一下走索 引的条件:返回表中 5%以内的数据走索引,超过 5%的时候走全表扫描。
二、选择性(SELECTIVITY)
基数与总行数的比值再乘以 100%就是某个列的选择性。
搜集某个表中的信息:
BEGIN
DBMS_STATS.GATHER_TABLE_STATS(ownname => 'user',
tabname => 'xxx',
estimate_percent => 100,
method_opt => 'for all columns size 1',
no_invalidate => FALSE,
degree => 1,
cascade => TRUE);
END;
/ 查看某个表中每个列的基数和选择性:
#这里注意用户名和表明都需要大写,否则查不到信息!!!!!!!
col column_name for a15;
select a.column_name,
b.num_rows,
a.num_distinct Cardinality,
round(a.num_distinct / b.num_rows * 100, 2) selectivity,
a.histogram,
a.num_buckets
from dba_tab_col_statistics a, dba_tables b
where a.owner = b.owner
and a.table_name = b.table_name
and a.owner = 'user'
and a.table_name = 'xxx';
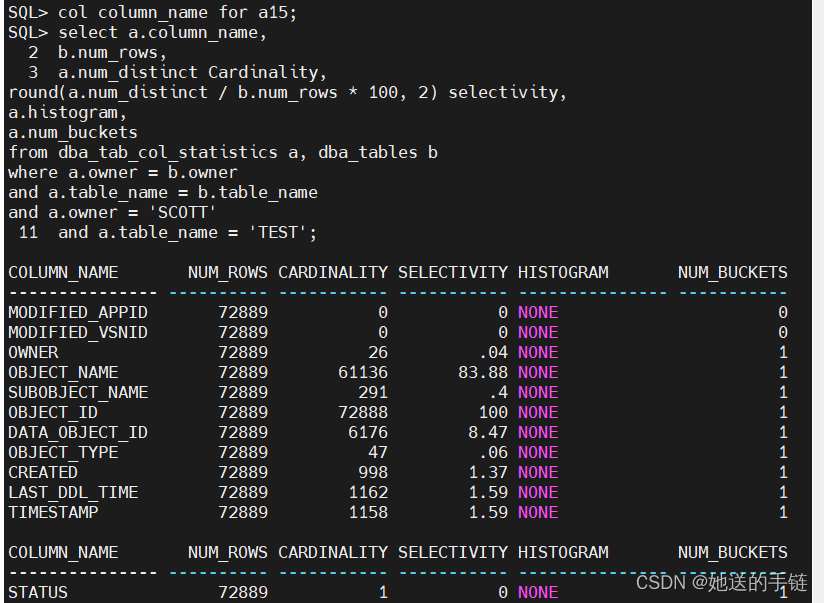
查看占比最大列的详细数据分布:
col OBJECT_NAME for a20;
select *
from (select object_name, count(*)
from test
group by object_name
order by 2 desc)
where rownum <= 10;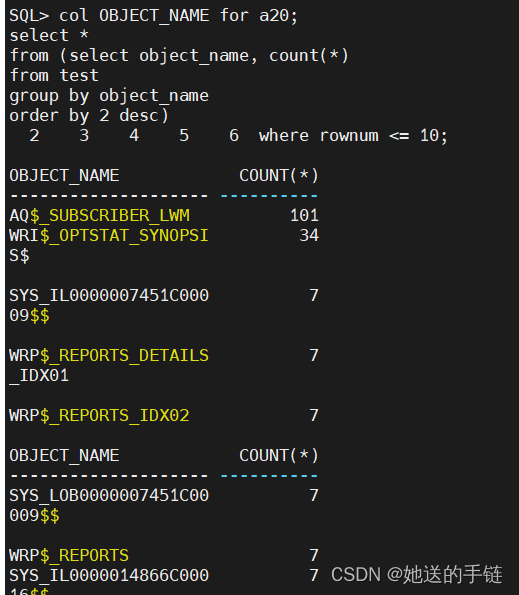
所以不管 object_name 传入任何值,最多返回101 行数据。
结论:
当一个列出现在 where 条件中,该列没有创建索引并且选择性大于 20%,那么该列就必须创建索引,从而提升 SQL 查询性能。当然,如果表只有几 百条数据,那我们就不用创建索引了。
那么如何快速找出哪些列需要创建索引呢?
在使用脚本之前先刷新数据库监控信息:
begin
dbms_stats.flush_database_monitoring_info;
end;
/思路:
1.查询出哪个表的哪个列出现在where 条件中
select r.name owner, o.name table_name, c.name column_name
from sys.col_usage$ u, sys.obj$ o, sys.col$ c, sys.user$ r
where o.obj# = u.obj#
and c.obj# = u.obj#
and c.col# = u.intcol#
and r.name = 'SCOTT'
and o.name = 'TEST';2.查询出选择性大于等于 20%的列
select a.owner,
a.table_name,
a.column_name,
round(a.num_distinct / b.num_rows * 100, 2) selectivity
from dba_tab_col_statistics a, dba_tables b
where a.owner = b.owner
and a.table_name = b.table_name
and a.owner = 'SCOTT'
and a.table_name = 'TEST'
and a.num_distinct / b.num_rows >= 0.2; 3.确保这些列没有创建索引
select table_owner, table_name, column_name, index_name
from dba_ind_columns
where table_owner = 'SCOTT'
and table_name = 'TEST'; 总结
如下:
----注意修改用户名称(owner)和表名(table_name)
----使用sysdba用户操作
select owner, column_name, num_rows, Cardinality, selectivity, 'Need index' as notice
from (select b.owner,a.column_name,b.num_rows,a.num_distinct Cardinality,
round(a.num_distinct / b.num_rows * 100, 2) selectivity
from dba_tab_col_statistics a, dba_tables b
where a.owner = b.owner
and a.table_name = b.table_name
and a.owner = 'SCOTT'
and a.table_name = 'TEST')
where selectivity >= 20
and column_name not in (select column_name
from dba_ind_columns
where table_owner = 'SCOTT'
and table_name = 'TEST')
and column_name in
(select c.name
from sys.col_usage$ u, sys.obj$ o, sys.col$ c, sys.user$ r
where o.obj# = u.obj#
and c.obj# = u.obj#
and c.col# = u.intcol#
and r.name = 'SCOTT'
and o.name = 'TEST');三、直方图(HISTOGRAM)
当某个列基数很低,该列数据分布就会不均衡。数据分布不均衡会导致在查询该列的时候,要么走全表扫描,要么走索引扫描,这个时候很容易走错执行计划。 如果没有对基数低的列收集直方图统计信息,基于成本的优化器(CBO)会认为该列数据分布是均衡的。所以要对基数很低(<1%)的列进行直方图收集。当然,对没有出现在 where 条件中的列收集直方图完全是做无用功,浪费数据库资源。
脚本如下:
抓出必须创建直方图的列:
select a.owner,
a.table_name,
a.column_name,
b.num_rows,
a.num_distinct,
trunc(num_distinct / num_rows * 100,2) selectivity,
'Need Gather Histogram' notice
from dba_tab_col_statistics a, dba_tables b
where a.owner = 'SCOTT'
and a.table_name = 'TEST'
and a.owner = b.owner
and a.table_name = b.table_name
and num_distinct / num_rows<0.01
and (a.owner, a.table_name, a.column_name) in
(select r.name owner, o.name table_name, c.name column_name
from sys.col_usage$ u, sys.obj$ o, sys.col$ c, sys.user$ r
where o.obj# = u.obj#
and c.obj# = u.obj#
and c.col# = u.intcol#
and r.name = 'SCOTT'
and o.name = 'TEST')
and a.histogram ='NONE'; 总结:
直方图是用来帮助 CBO 在对基数很低、数据分布不均衡的列进行 Rows 估算的时候,可以得到更精确的Rows
四、回表(TABLE ACCESS BY INDEX ROWID)
什么叫回表:
当对一个列创建索引之后,索引会包含该列的键值以及键值对应行所在的 rowid。通过索引中记录的 rowid 访问表中的数据就叫回表。回表一般是单块读,回表次数太多会严重影响 SQL 性能,如果回表次数太多,就不应该走索引扫描了,应该直接走全表扫描。
例子:
set line 150;
set autot trace;
select * from test where owner='SYS';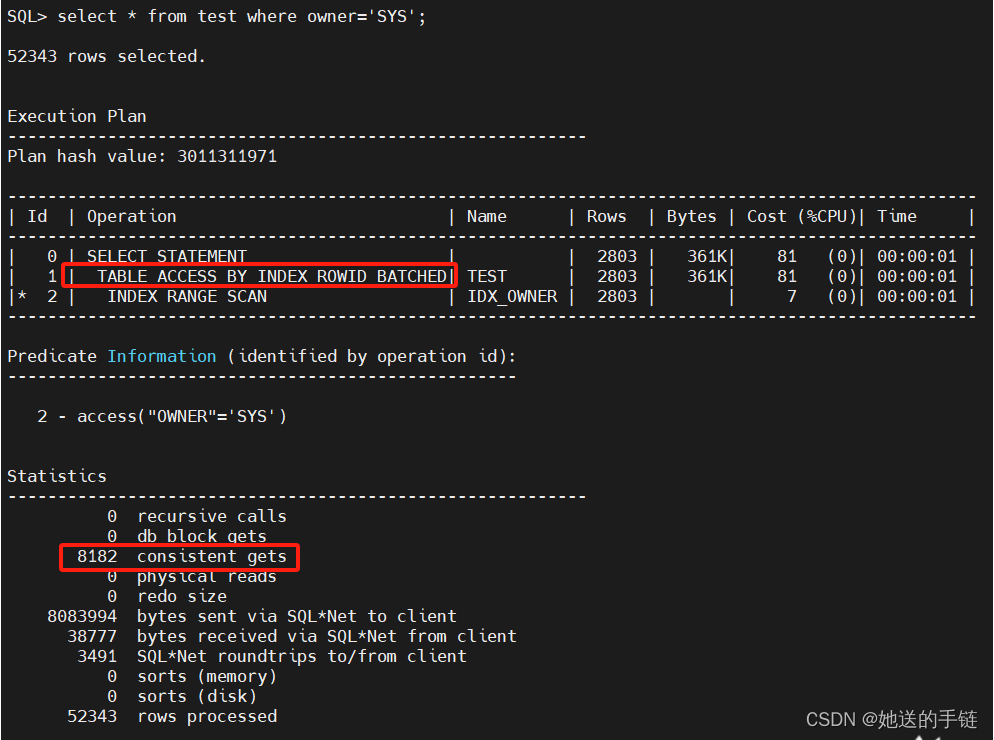
执行计划中框起来的(TABLE ACCESS BY INDEX ROWID)就是回表。索引返回多少行 数据,回表就要回多少次,每次回表都是单块读(因为一个 rowid 对应一个数据块)。该 SQL 返回了52343行数据,那么回表一共就需要52343次。
请思考:上面执行计划的性能是耗费在索引扫描中还是耗费在回表中?
实验:
为了消除 arraysize 参数对逻辑读的影响, 设置 arraysize=5000。arraysize 表示 Oracle 服务器每次传输多少行数据到客户端,默认为 15。如果一个块有 150 行数据,那么这个块就会被读 10 次,因为每次只传输 15 行数据到客户 端,逻辑读会被放大。设置了 arraysize=5000 之后,就不会发生一个块被读 n 次的问题了。
set arraysize 5000
select owner from test where owner='SYS';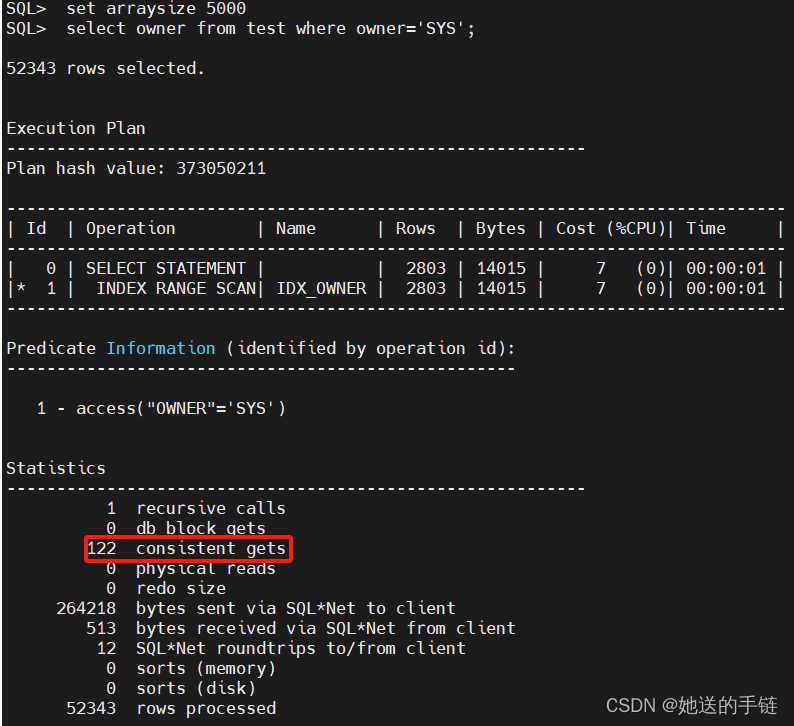
从上面可知,索引扫描只耗费了 74 个逻辑读。
select * from test where owner='SYS';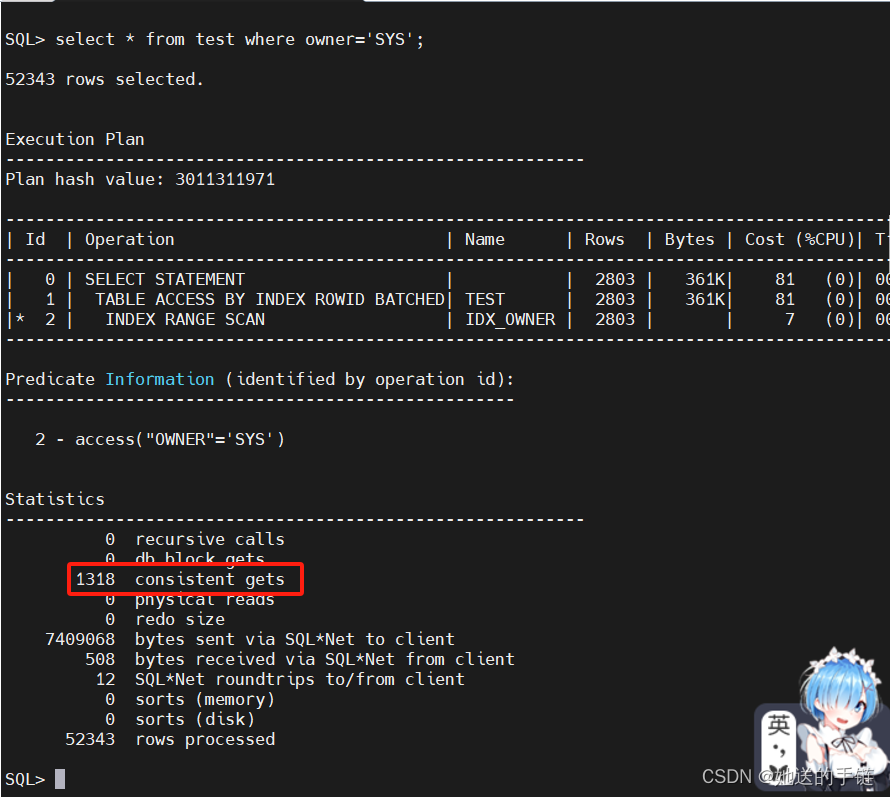
set autot off
select count(distinct dbms_rowid.rowid_block_number(rowid)) blocks from test where owner = 'SYS';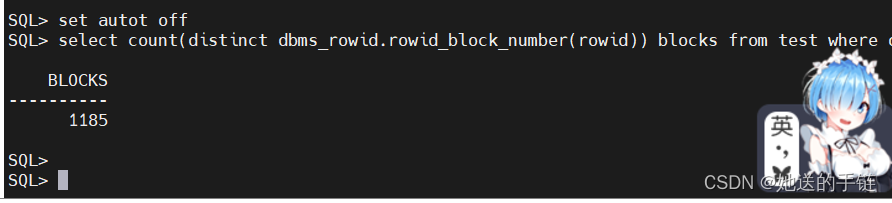
SQL 在有回表的情况下,一共耗费了 1318个逻辑读,那么这 1318个逻辑读是怎么来的呢? SQL 返回的 52343 条数据一共存储在 1185 个数据块中,访问这 1185 个数据块就需要消耗 1185 个逻辑读,加上索引扫描的 122 个逻辑读,再加上 11 个逻辑读[其中 11=ROUND(52343/5000)],这 样累计起来刚好就是 1318 个逻辑读。 因此我们可以判断,该 SQL 的性能确实绝大部分损失在回表中! 更糟糕的是:假设 52343 条数据都在不同的数据块中,表也没有被缓存在 buffer cache 中, 那么回表一共需要耗费 52343 个物理 I/O,简直不可想象。
总结:
在无法避免回表的情况下,走索引如果返回数据量太多,必然会导致回表次数太多,从而 导致性能严重下降。类似于这样的 Select * from table where ... 就必须回表,所以我们必须严禁使用 Select *。类似于这样的 Select count(*) from table 这样的 SQL 就不需要回表。所以返回表中 5%以内的数据走索引、超过表中 5%的数据 走全表扫描。
五、集群因子(CLUSTERING FACTOR)
集群因子用于判断索引回表需要消耗的物理 I/O 次数。
根据算法我们知道集群因子介于表的块数和表行数之间。
如果集群因子与块数接近,说明表的数据基本上是有序的,而且其顺序基本与索引顺序一 样。这样在进行索引范围或者索引全扫描的时候,回表只需要读取少量的数据块就能完成。
如果集群因子与表记录数接近,说明表的数据和索引顺序差异很大,在进行索引范围扫描 或者索引全扫描的时候,回表会读取更多的数据块。
集群因子只会影响索引范围扫描(INDEX RANGE SCAN)以及索引全扫描(INDEX FULL SCAN),因为只有这两种索引扫描方式会有大量数据回表。 集群因子不会影响索引唯一扫描(INDEX UNIQUE SCAN),因为索引唯一扫描只返回一 条数据。集群因子更不会影响索引快速全扫描(INDEX FAST FULL SCAN),因为索引快速全扫描不回表。
实验:
先对测试表 test 的 object_id 列创建一个索引 idx_id:
create index idx_id on test(object_id); 
查看该索引的集群因子:
col OWNER for a10;
col CLUSTERING_FACTOR for a15;
col index_name for a15;
select owner, index_name, clustering_factor from dba_indexes where owner = 'SCOTT' and index_name = 'IDX_ID'; 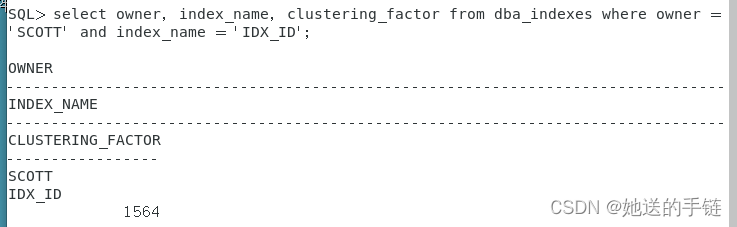
索引 idx_id 的叶子块中有序地存储了索引的键值以及键值对应行所在的 ROWID。
select * from (select object_id, rowid from test where object_id is not null order by object_id) where rownum<=5; 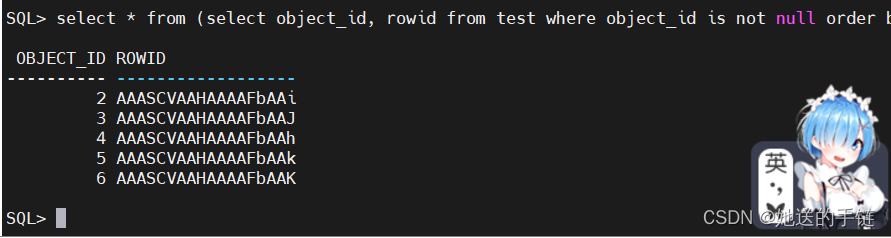
人工计算集群因子的 SQL 脚本:
select sum(case
when block#1 = block#2 and file#1 = file#2 then
0
else
1
end) CLUSTERING_FACTOR
from (select dbms_rowid.rowid_relative_fno(rowid) file#1,
lead(dbms_rowid.rowid_relative_fno(rowid), 1, null) over(order by object_id) file#2,
dbms_rowid.rowid_block_number(rowid) block#1,
lead(dbms_rowid.rowid_block_number(rowid), 1, null) over(order by object_id) block#2
from test
where object_id is not null);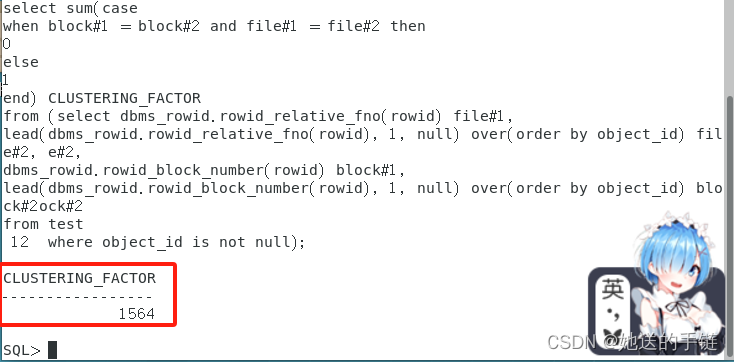
表的总块数如下可知:
select count(distinct dbms_rowid.rowid_block_number(rowid)) blocks from test; 
在第一节基数的时候我们知道,表的总行数为72889行,总块数为1412块,得知集群因子非常接近表的总块数。现在,我们来查看下面 SQL 语句的执行计
set arraysize 5000
set autot trace
select * from test where object_id < 1000;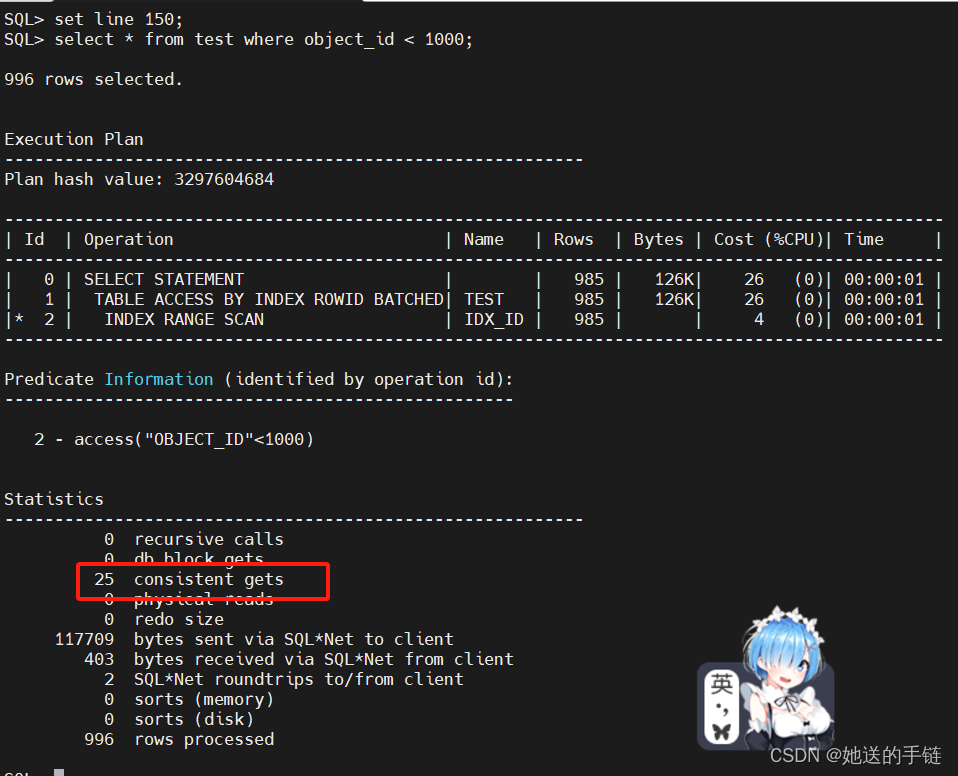
耗费了25个逻辑读。
接下来新建一个test2,来对数据进行随机排序。
create table test2 as select * from test order by dbms_random.value;
#在 object_id 列创建索引 idx_id2
create index idx_id2 on test2(object_id);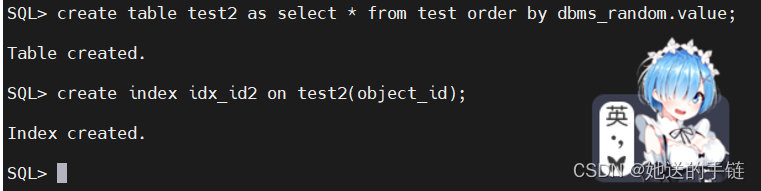
查看索引 idx_id2 的集群因子。
set autot trace
select owner, index_name, clustering_factor from dba_indexes where owner = 'SCOTT' and index_name = 'IDX_ID2'; 
索引 idx_id2 的集群因子接近于表的总行数(72889),回表的时候会读取更多的数据块,现在我们 来看一下 SQL 的执行计划。
set arraysize 5000
set autot trace
select /*+ index(test2) */ * from test2 where object_id <1000;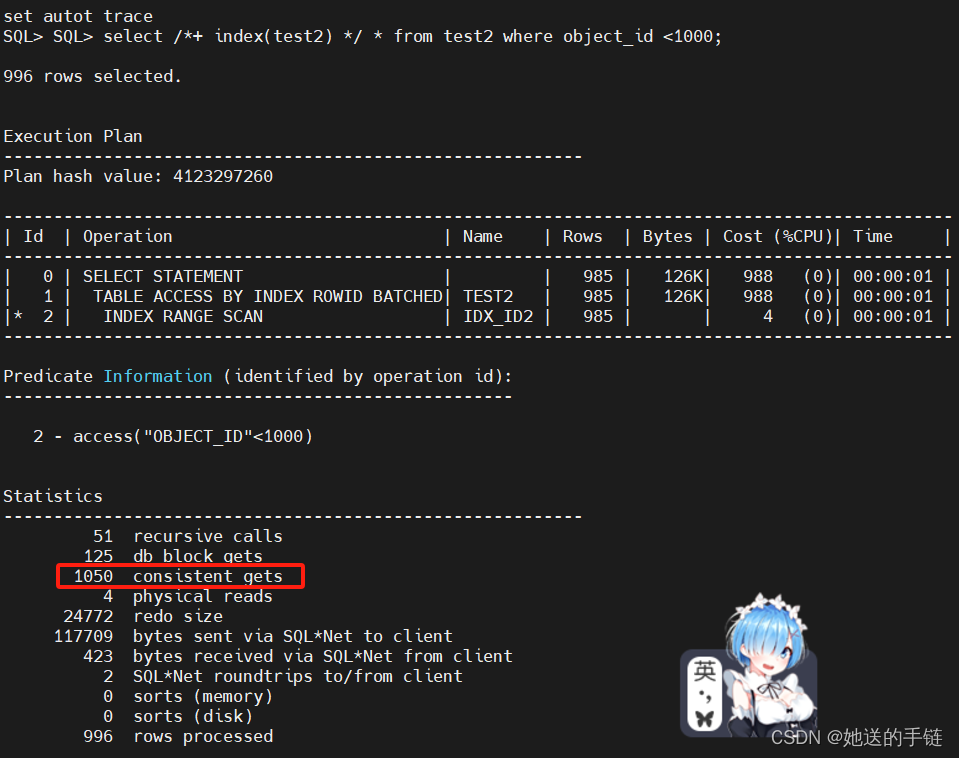
从上图得知,进行了1K+逻辑读。
通过上面实验我们得知,集群因子太大会严重影响索引回表的性能,集群因子影响的是索引回表的物理 I/O 次数。我们假 设索引范围扫描返回了 1 000 行数据,如果 buffer cache 中没有缓存表的数据块,假设这 1000 行数据都在同一个数据块中,那么回表需要耗费的物理 I/O 就只需要一个;假设这 1000 行数 据都在不同的数据块中,那么回表就需要耗费 1 000 个物理 I/O。因此,集群因子影响索引回 表的物理 I/O 次数。
切记不要尝试重建索引来降低集群因子,这根本没用,因为表中的数据顺序始终没变。 唯一能降低集群因子的办法就是根据索引列排序对表进行重建(create table new_table as select * from old_table order by 索引列),但是这在实际操作中是不可取的,因为我们无法照顾到每 一个索引。
总结:
集群因子只影响索引范围扫描和索引全扫描。当索引范围扫描,索引全扫描不回表或者返回数据量很少 的时候,不管集群因子多大,对 SQL 查询性能几乎没有任何影响。在进行 SQL 优化的时候,往往会建立合适的组合索引消除回表,或者建 立组合索引尽量减少回表次数。