引言:了解到了协议的定制,我们就知道在进行客户端与服务端通信时,对于报文的封装协议的定制是必不可少的,虽说协议是我们自己定制,但是有大佬们直接为我们写了一套完整的,可靠的协议,例如http协议(超文本传输协议)就是其中之一。
目录
1.什么是URL?
url其实就是网址,向www.baidu.com我们知道这是域名,对于我们一般的服务器,想要访问服务器就需要ip地址与端口号,然而在实际的访问中,我们一般不用ip地址加端口号,而是用域名访问服务器,这样更加方便,因此通过解析域名就可以找到ip地址。
而端口号一般是固定不变的,且是让人们熟知的,浏览器一般默认都是http或者https,是绑定端口号了的。而我们去访问网页的某个东西,上面的网址也就是url(统一资源定位符)。
我们用域名表示唯一的服务器,协议表示唯一的端口号,后面的就是标识资源.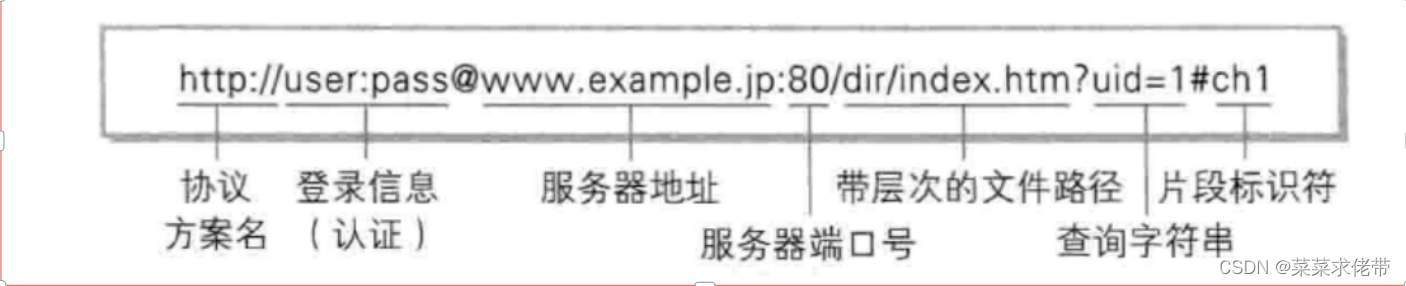
而我们一般在网络上的行为就是两种:1.拿取数据。2.上传数据。
但是我们通过url拿到的,或者着我们上传的数据,与url一些特殊的字符冲突,因此这时候还需要BS双方进行编码(encode)和解码(decode)。
2.http请求与响应的格式
HTTP(超文本传输协议)是一种应用层协议,用于传输超媒体文档,例如HTML。它被设计用于Web浏览器与Web服务器之间的通信,但也可用于其他目的。HTTP遵循经典的客户端-服务器模型:客户端打开一个连接以发出请求,然后等待直到收到服务器端的响应。
我们已经知道协议的定制是由请求与响应的,那么gttp的请求与响应是什么样的?
先看格式:
http request
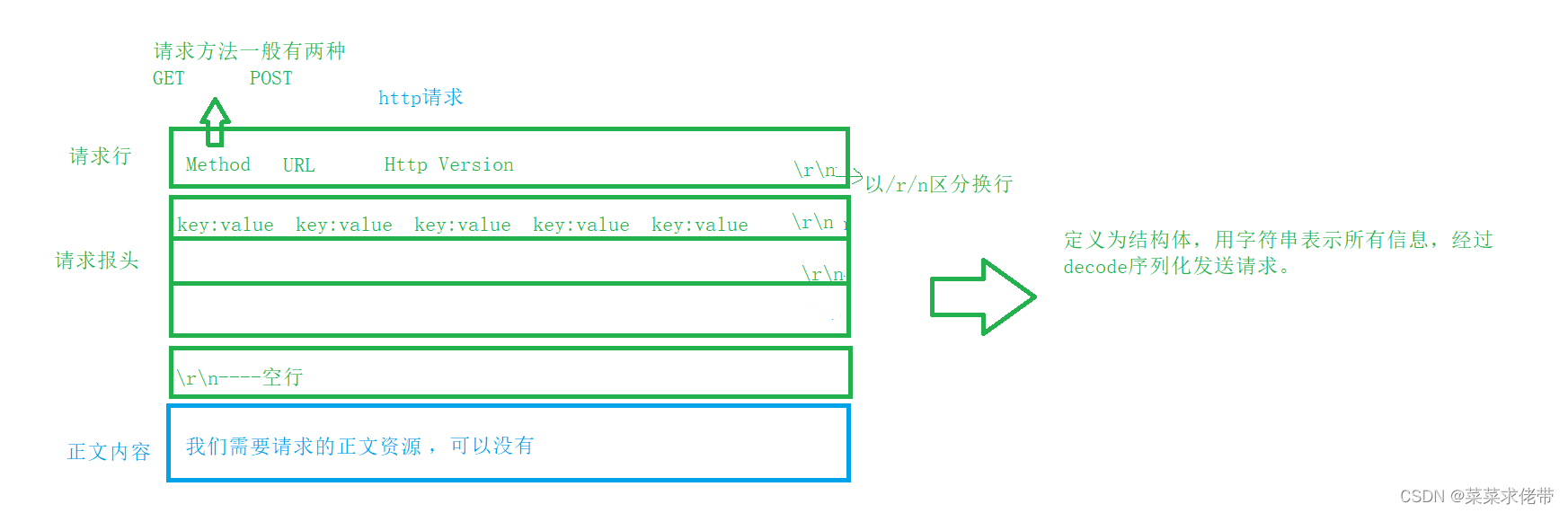
htt response

我们可以利用telnet向www.baidu.com发送请求,格式就如上图其中请求包头可以为空,正文可以为空,但是换行符不能少。
GET / HTTP/1.1

可以看收到了请求并做出回应,第一行为状态行 有三部分协议版本 状态码 状态描述。
我们可以使用工具fiddler进行抓包。
现在我们就写一个最简单的httpserver。
3.httpserver的编写
对于http。在我们读写信息时,除了用read读,用recv也是可以读取的。
一般我们去访问http请求的时候,就会给我们返回一些数据,其中就有一个UserAgent,这个是用来标识其他主机的,一般我们在爬取网页时,就会添加UA面对反爬,还有浏览器是什么,等数据。
在接受请求的时候,并不能保证发送的报文数据有几条,因此我们需要去构建特定格式的报文,一条条的读,一条一条的写。
收到请求之后,我么也可以编写响应报文:这里我们就先自己构建一个响应报文,响应包头+版本号+正文。
这就是我们发出的请求:
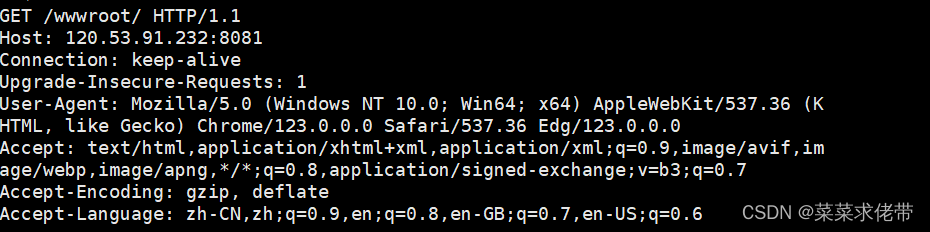
响应是打印hello world。
4.构建请求与响应
所以在整个过程中涉及两个知识点:
1.一是我们在发送请求时,是发送的一串封装的报文包括请求行+请求头+正文,服务端收到请求做出响应,而响应也是封装的报文,但浏览器在接收到响应后只会显示正文数据。
2.在请求的时候,会在请求头中添加需要的网页,需要的资源,把路径通过url给我们呈现出来,我们的网页并不是用静态编码的方式写到服务器,而是一个个文件,这样就去动态的去服务器找需要的文件,一般请求的hi一个/,默认为web根目录.
3.这些网页文件我们都会放在一个wwwroot(web根目录)的主页面文件,之后将该文件的路径传给我们的服务器.
在我们发出请求的的时候,我们可以去直接去请求某个目录下的某个文件,动态的更具网页获取信息,例如我们在请求头中添加照片或文件的路径,我们的浏览器就会根据请求去找到文件并在浏览器中显示出来。
在封装响应时,我们会动态的去给content:例如我们就给wwwroot下的index.html,在我们做出响应时,浏览器会动态的去找对应的文件。
因此在实际编写中,我们会去定制我们的request与response。根据请求去生成对应的响应。
但是用户在搜索时,也不是直接的去修改url,而是自动跳转页面,而是生成一个链接,我们可以去w3cscholl网站去了解

通过生成链接,用户使用并且访问更加的简单以及清晰明了,这样用户在主页只需要点击超链接,就可以实现html的互相访问。
httpserver.hpp
#include"Socket.h"
#include<pthread.h>
#include<vector>
#include<fstream>
#include<sstream>
using std::cout;
using std::endl;
using std::cerr;
const uint16_t defaultport=8080;
const std::string wwwroot="./wwwwroot";
const std::string home_page="/index.html";
const std::string sep="\r\n";
struct PthreadData
{
PthreadData( int sockfd,std::string clientip,uint16_t port):_newsockfd(sockfd),_clientip(clientip),_clientport(port)
{
}
int _newsockfd;
std::string _clientip;
uint16_t _clientport;
};
class HttpServer
{
public:
HttpServer(uint16_t port=defaultport):_port(port)
{
_listensock.Createsockfd();
_listensock.Bind(_port);
_listensock.Listen();
}
static std::string ReadFile(const std::string file)
{
std::ifstream in (file);
if(!in.is_open()){return "404";}
//读取文件
std::string content;
std::string buffer;
while(getline(in,buffer))
{
content+=buffer;
}
in.close();
return content;
}
class httprequest
{
public:
void Dserialize(std::string req)//序列化,一变多
{
//根据/n/r获取相应行,响应头,正文
while(true)
{
size_t pos=req.find(sep);
if(pos==std::string::npos)
{
break;
}
std::string temp=req.substr(0,pos);
req_head.push_back(temp);
//处理完移走
req.erase(0,pos+sep.size());
}
text=req;//由于请求头可能会很长,在切分是不好切分,我们直接将正文与请求头都作为正文
}
void parse()
{
std::stringstream ss(req_head[0]);
ss>>method>>url>>version;
file_path=wwwroot;
if(url=="/"|url=="/index.html")//访问的是主页
{
file_path+=home_page;
}else{
file_path+=url;//主页外的目录
}
}
public:
std::vector<std::string> req_head;
std::string text;
//二次解析的内容
std::string method;
std::string url;
std::string version;
std::string file_path;
};
static void HttpHandle(int &sockfd)
{
char buffer[1024];
size_t n=recv(sockfd,buffer,sizeof(buffer),0);
if(n<0)
{
cerr<<"读写失败"<<",错误码:"<<errno<<",错误信息:"<<strerror(errno)<<endl;
exit(RECVERROR);
}
//打印发送的请求
buffer[n]=0;
cout<<buffer;
httprequest request;
request.Dserialize(buffer);
request.parse();
//通过请求获取到要访问的路径
//对请求做出响应
//构建响应报文
std::string text=ReadFile(request.file_path);//正文
std::string response_head="Content-length:";//报头
std::string response_line="http/1.1,200,ok\r\n";//响应行
response_head+=std::to_string(text.size());//报头
std::string blank_line="\r\n";
response_head+=blank_line;
std::string response=response_line;
response+=response_head;
response+=blank_line;
response+=text;
response+="\r\n";
//发送响应
send(sockfd,response.c_str(),response.size(),0);
close(sockfd);
}
static void *Routine(void *args)
{
//分离线程
pthread_detach(pthread_self());
PthreadData* data=static_cast<PthreadData*>(args);
HttpHandle(data->_newsockfd);
delete data;
return nullptr;
}
void Start()
{
while(true)
{
std::string ip;
uint16_t port;
int sockfd=_listensock.Accept(&ip,&port);
//获取接收信息的套接字
if(sockfd<0)
{
cerr<<"接受失败"<<",错误码:"<<errno<<",错误信息:"<<strerror(errno)<<endl;
exit(ACCEPTERROR);
}
//用线程进行读写
PthreadData*data=new PthreadData(sockfd,ip,port);
pthread_t tid;
pthread_create(&tid,NULL,Routine,data);
}
}
~HttpServer()
{
}
private:
Sock _listensock;
uint16_t _port;
};
5.http的细节字段
我们知道http的请求字段中第一行为请求行,里面包括了method,url,版本等。
method:
对于这个方法,我们可以详细的来了解一下:
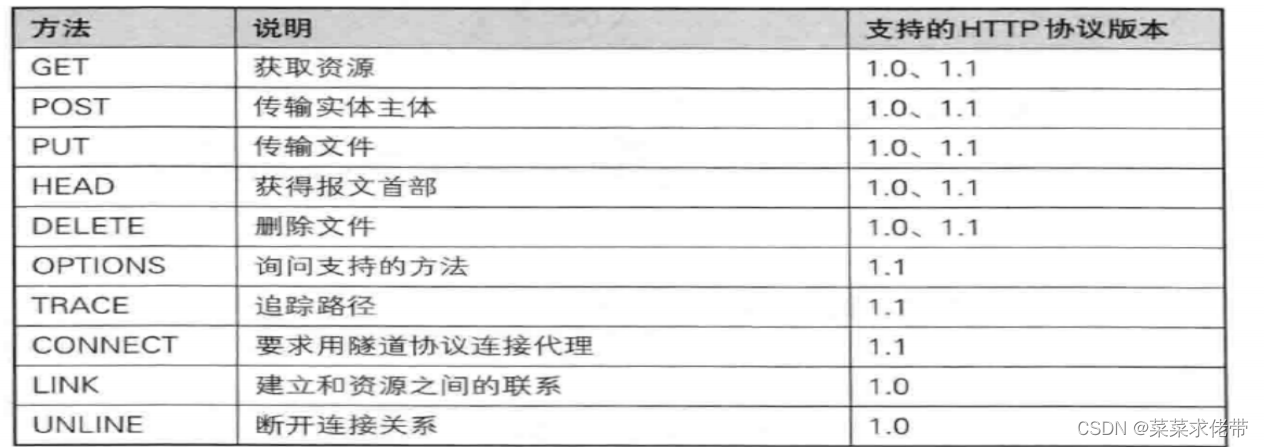
大部分情况下我们获取资源都是用的是GET方法,也有一些情况我们使用POST,POST也可以获取网页资源,但是更多的情况是在网页中上传你的东西。我们基本上也只有这两个方法,其他的方法要么国企,要么是被禁止用的。
get我们一般在对有表单标签的页面处会使用,例如登陆时,就需要我们像表单提交数据,数据通过在原url后追加我们的提交数据而提交到服务器上,而当设置为post方式传参的ihou,返回的参数是在正文后面的。不论是post还是get其实都不安全,只要被抓包,数据就可能泄露,只是post相对更加私密一些,参数追加到正文后面。
状态码与报头
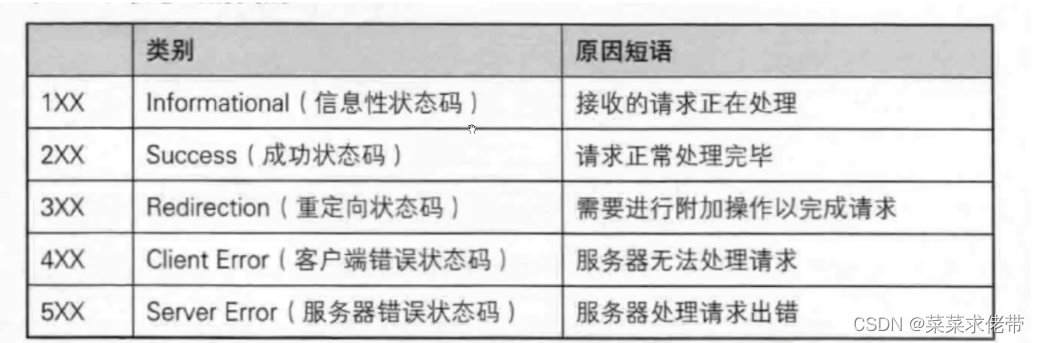
如常见的404not found,504:bad getway.403:forbidden.302:重定向.
例如我们在获取请求后,构建请求报文时,若找不到对应请求,就直接跑去wwwroot下的404html.
状态码之后的下一行就是请求报头:
Content-Type: 数据类型 (text/html 等 )Content-Length: Body 的长度Host: 客户端告知服务器 , 所请求的资源是在哪个主机的哪个端口上 ;User-Agent: 声明用户的操作系统和浏览器版本信息 ;referer: 当前页面是从哪个页面跳转过来的 ;location: 搭配 3xx 状态码使用 , 告诉客户端接下来要去哪里访问 ;Cookie: 用于在客户端存储少量信息 . 通常用于实现会话 (session) 的功能
重定向就是状态为3XX时,根据包头里的location,让服务器知道浏览器访问新的网页。
此外报头的属性也是有很多的,上面列举了几个。 还有connect等,双方通信是否建立长连接。
cookie就是服务器给浏览器写回的内容,当然我们也可以使用setcookie这个选项,让服务器向浏览器进行数据写入,因为cookie的存在,这使得我们我们在重新访问浏览器会将cookie之前访问时的内容直接写入浏览器中(例如账户信息,密码等)。
但是过度的把个人信息放在cookie中,一旦被盗取,就非常危险,用户的合法性登录就需要来确定
因此每次我们都会使用一个seesion文件,session id(服务端分配)来标识seesion文件(用户信息,有效时间), 但是当越多的用户登陆,就会产生大量的session,因此session文件就需要被管理,一般通过redis进行管理。
6.http加密-https
为了保证数据安全的情况下,我们有引入了https,https也是一个应用层协议,是为了确保http中的请求与响应是安全的.
HTTPS(超文本传输协议安全版)是HTTP(超文本传输协议)的扩展。它使用加密技术在计算机网络上进行安全通信,并广泛用于互联网。
史记载应用层与系统调用接口之间哈有一个加密层(SSL),在HTTPS中,通信协议使用传输层安全性(TLS)或以前的安全套接字层(SSL)进行加密。因此,它也被称为HTTP over TLS或HTTP over SSL。
数据加密一般分为两种:对称加密与非对称加密。
对称加密使用同一个密钥进行加密解密,非对称加密一个密钥(公钥)用来加密,一个密钥(私钥)用来解密。
对称加密相对于非对称快些但安全性稍微差点。
常见的对称加密(DES,3DES,RC系列,BLOWFISH等)。
报文摘要(MD5、SHA):报文摘要是一种用于生成消息摘要或哈希值的算法,它将任意长度的消息作为输入,并产生固定长度的摘要输出。报文摘要通常用于验证消息的完整性,检测数据是否被篡改。
对于报文的加密,我们有几种方案:
1.只使用对称加密。
双方都各有一个密钥,且没有别人知道,此时通信的安全是可以保证的。可以问题来了,你怎么确定,客户端和服务端就能达成一个约定,说只用这个密钥,对于客户端来说很难保证。
2.只使用非对称加密。
此时当客户端向服务端发送请求时,服务端获取到请求时,会将自己的公钥告知客户端,因为客户端,客户端将数据加密后,再发送给我服务端,服务端使用私钥解密数据。
此时我们会感觉数据是安全的。
但是解密之后,封装完数据,因为客户端只有公钥,再次使用公钥加密, 需要将数据作为响应回传给客户端,因为公钥是已知的,就可能出现数据被其他人解析获知。
3.双方都是非对称加密
很明显,双方每次在进行数据交互时,都要进行各自的公钥加密,私钥解密,且要进行密钥的交换,效率大大折扣,且依旧有安全问题。
4.非对称和对称加密
最开始请求的时候使用非对称加密(同时协商对称加密的密钥),在将数据响应给客户端时,使用对称加密。(对称密钥生成在加密前的原文)。

但是方2,3,4忽略另一个问题,中间人(运营商)如果在最开始就攻击了,比如发第一个请求时就去攻击你。
1. 服务器具有⾮对称加密算法的公钥S,私钥S'2. 中间⼈具有⾮对称加密算法的公钥M,私钥M'3. 客⼾端向服务器发起请求,服务器明⽂传送公钥S给客⼾端4. 中间⼈劫持数据报⽂,提取公钥S并保存好,然后将被劫持报⽂中的公钥S替换成为⾃⼰的公钥 M, 并将伪造报⽂发给客⼾端5. 客⼾端收到报⽂,提取公钥M(⾃⼰当然不知道公钥被更换过了),⾃⼰形成对称秘钥X,⽤公钥M加 密X,形成报⽂发送给服务器6. 中间⼈劫持后,直接⽤⾃⼰的私钥M'进⾏解密,得到通信秘钥X,再⽤曾经保存的服务端公钥S加 密后,将报⽂推送给服务器7. 服务器拿到报⽂,⽤⾃⼰的私钥S'解密,得到通信秘钥X8. 双⽅开始采⽤X进⾏对称加密,进⾏通信。但是⼀切都在中间⼈的掌握中,劫持数据,进 ⾏窃听甚 ⾄修改,都是可以
第⼀组(⾮对称加密): ⽤于校验证书是否被篡改. 服务器持有私钥(私钥在形成CSR⽂件与申请证书时获得), 客⼾端持有公钥(操作系统包含了可信任的 CA 认证机构有哪些, 同时持有对应的公钥). 服务器在客⼾端请求是,返回携带签名的证书. 客⼾端通过这个公钥进⾏证书验证, 保证证书的合法性,进⼀步保证证书中携带的服务端公钥权威性。
第⼆组(⾮对称加密): ⽤于协商⽣成对称加密的密钥. 客⼾端⽤收到的CA证书中的公钥(是可被信任的) 给随机⽣成的对称加密的密钥加密, 传输给服务器, 服务器通过私钥解密获取到对称加密密钥.
第三组(对称加密): 客⼾端和服务器后续传输的数据都通过这个对称密钥加密解密.