1. 前言
上周工作之余逛github看到一个本地缓存库bigcache,这个是allegro公司开源的一个项目,主要是用于本地缓存使用,根据他们的博客说明,他们编写这个库最初的目的就是实现一个非常快速的缓存服务。
看了下bigcache这个库的源码,这个库主要在两个方面进行了一定的创新:
- 并发性
- 缓存获取的时候会产生并发,会涉及锁的争用问题,bigcache通过分片的机制解决了并发的问题
- 省略垃圾收集器
- Go中的垃圾收集器在GC期间会在扫描和标记阶段去访问map中的每一个键值对,当map很大的时候会造成系统性能的下降。在go中如果你使用的map的键值都不包含任何指针元素的话,则GC会忽略这些内容,所以bigcache通过将所有的键都定义成整数类型,从而避免了GC。
2. 为什么不使用Redis等缓存中间件呢?
关于为什么不使用Redis/Memcached这类缓存,这是因为这些缓存中间件都属于外部依赖,在对缓存进行操作时都存在网络上的延迟,所以就生出了bigcache。
3. 并发分片
缓存服务会同时接收多个请求,因此需要对缓存提供并发访问,而实现并发访问的简单方法是利用读写锁,即sync.RWMutex来实现,从而确保每一次只有一个goroutine可以修改缓存,但这样会阻塞其他的Goroutine,从而触及性能瓶颈。
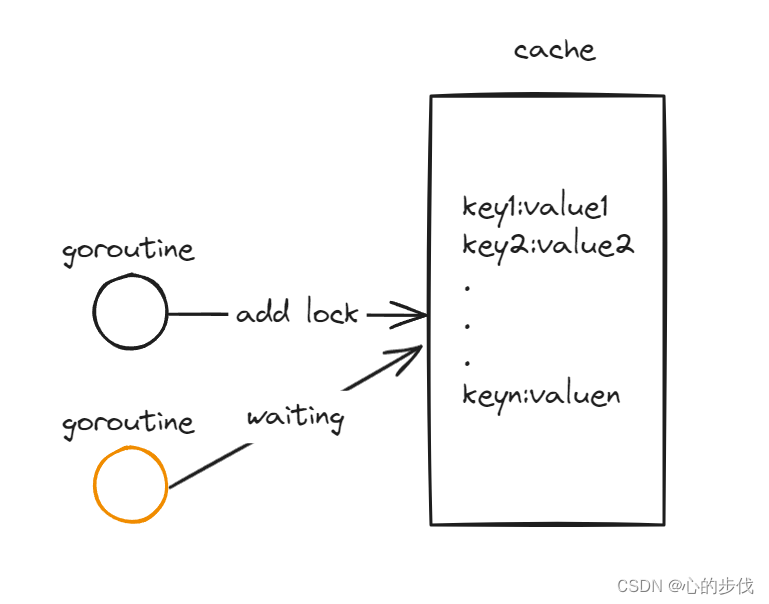
为了解决这个问题,bigcache通过分片的机制,即将cache分成N个shard,即每个shard存储一部分数据,而在对Key的数据进行获取或者存储的时候,通过hash(key)%N 即可实现分片位置的获取。在N足够大的时候,锁的争用可以最小化到几乎为0。
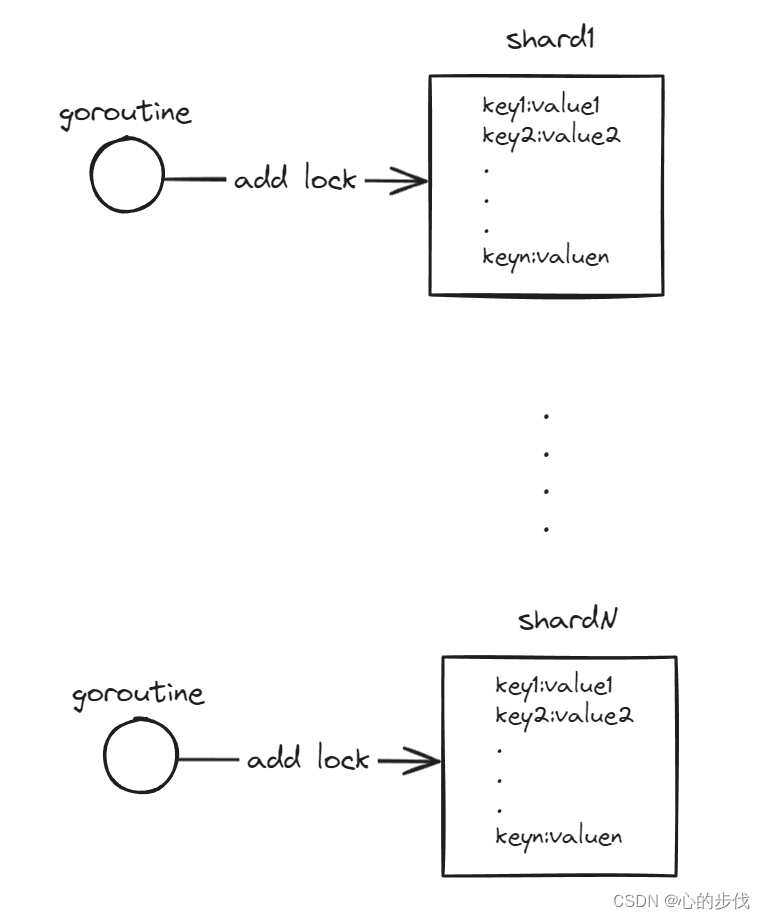
3.过期键值的驱逐
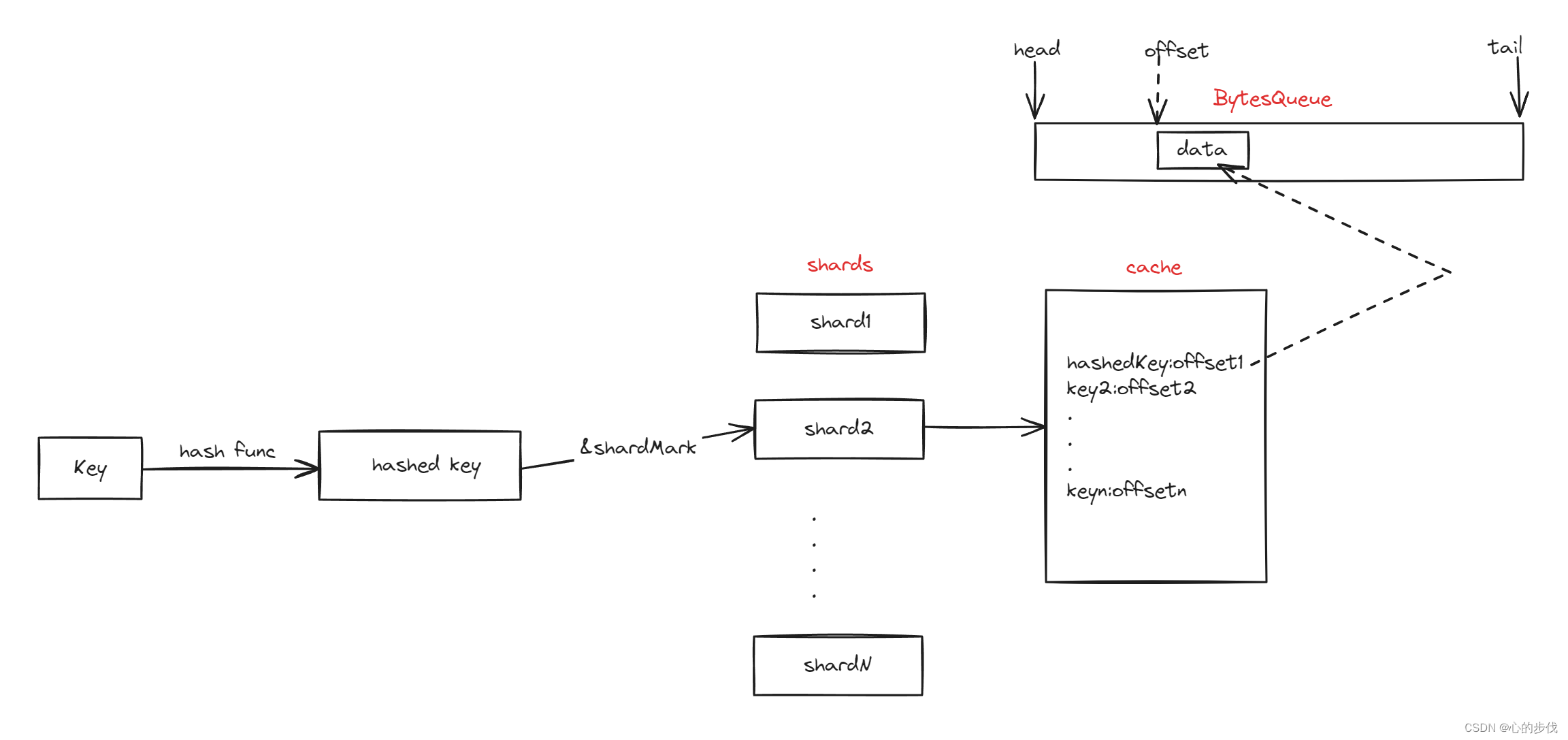
本地缓存肯定有缓存大小的上限,为了避免本地缓存无限增大的问题,就需要驱逐过期的键值对,bigcache通过一个fifo的队列(在bigcache中,这个fifo的实现是通过BytesQueue来实现的,即每个键值的插入与删除都是通过具体的偏移量来实现的,驱逐则是通过移动fifo的头类实现的),来实现数据驱逐的问题。
当缓存的键值对数据被添加到缓存中的时候,会发生两个额外的操作:
- 包含key和创建时间的键值对会被添加到队列的尾部
- 从队列中读取最旧的元素,将元素的创建时间戳与当前时间进行比较,如果超出了存活的生命周期大小,则队列中的元素键值对将会被删除。
由于键值的驱逐是需要获取锁来实现的,所以一般都是在写入缓存的期间执行驱逐行为。
4. 省略垃圾收集器
在Go中,如果你有一个map,则垃圾收集器会在标记和扫描阶段访问该map的每一个项目,当map足够大的时候,可能会对应用程序的性能造成较大的影响。
因为bigcache的定位就是满足数百万个键值对的存储,所以会使得GC耗费的时间变长,从而使得应用程序性能下降。
GC只在堆上发生,可以考虑去堆外存储这些元素,但如果去堆外存储,则需要依赖额外的库(offheap)。
另一种是通过减少指针的数量来实现零GC开销的map,可以参考freecache,将键值保存在环形缓冲区中,使用索引切片查找条目。
最后一种就是bigcache使用的基于go的一个优化方法,优化表明如果map中的键值没有使用指针类型,则GC会忽略这些内容。但Go中所有的数据基本都是基于指针构建的,比如结构体、切片以及数组等。这就意味着我们需要把这些键值修改为ini或者bool这样的数据,从而避免键值设置为指针。
在上面并发分片中,采用分片的方式存储多组缓存数据从而增加并发度,这里bigcache会复用分片的理论,因为分片是将key通过hash方法变成一个int类型的key,而通过int类型的key我们可以找到具体的分片位置,具体的缓存是存储在分片中的,而分片缓存中的map是map[int][int]类型的,则key表示我们获取的hashkey,值则表示具体的数据的偏移量。这样在获取某个key数据的时候,我们只需要:
- 通过hash函数获取hashedKey
- 通过hashedKey获取分片
- 通过分片中hashedKey的偏移量
- 通过偏移量获取数据
5. 总结
bigcache用于在本地存储数以百万计的键值对拥有比较好的性能,这个主要得意于其采用的:
- 并发分片
- 零GC
并发分片的方式帮助bigcache在分片足够大的时候,可以做到goroutine争用为0,而通过Go官方对map键值非指针的情况下,GC会忽略这些内容的优化,bigcache通过将key转化为hash整数,从而定位到具体的shard分片,继而将值量化为具体的BytesQueue中的偏移量,实现了map[int][int]结构,从而实现了零GC。
这里面的BytesQueue也挺有趣的,将所有的键值数据通过byte的形式与偏移量进行具体的转化,从而实现了基于bytes数组的fifo队列。
另外bigcache还提供除了一组http的接口用于其他服务调用获取缓存数据。