前面说了中文分类的过程,这次说一下情感分类相关的代码,其实情感分类也属于中文多分类的一种,知识情感分类一般会专门区分出来,但是代码基本是一致的,
基本步骤:
1、加载数据集
数据集我们使用hugging face上的数据集,打开hugging face–》datasets
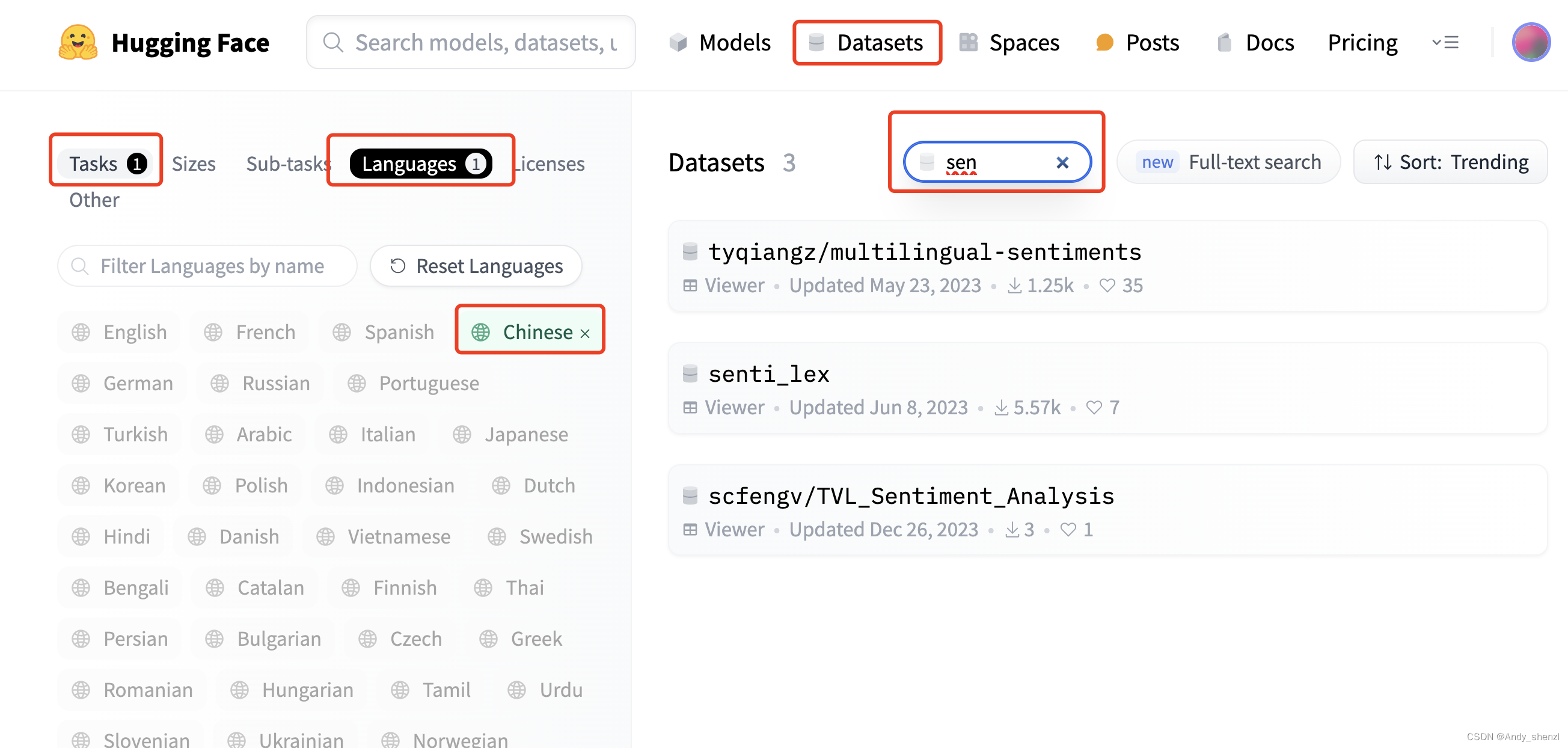
task选择“Text Classification“
languages选择Chinese
搜索sentiments即可,可以自己选择一个合适的来训练
进入查看
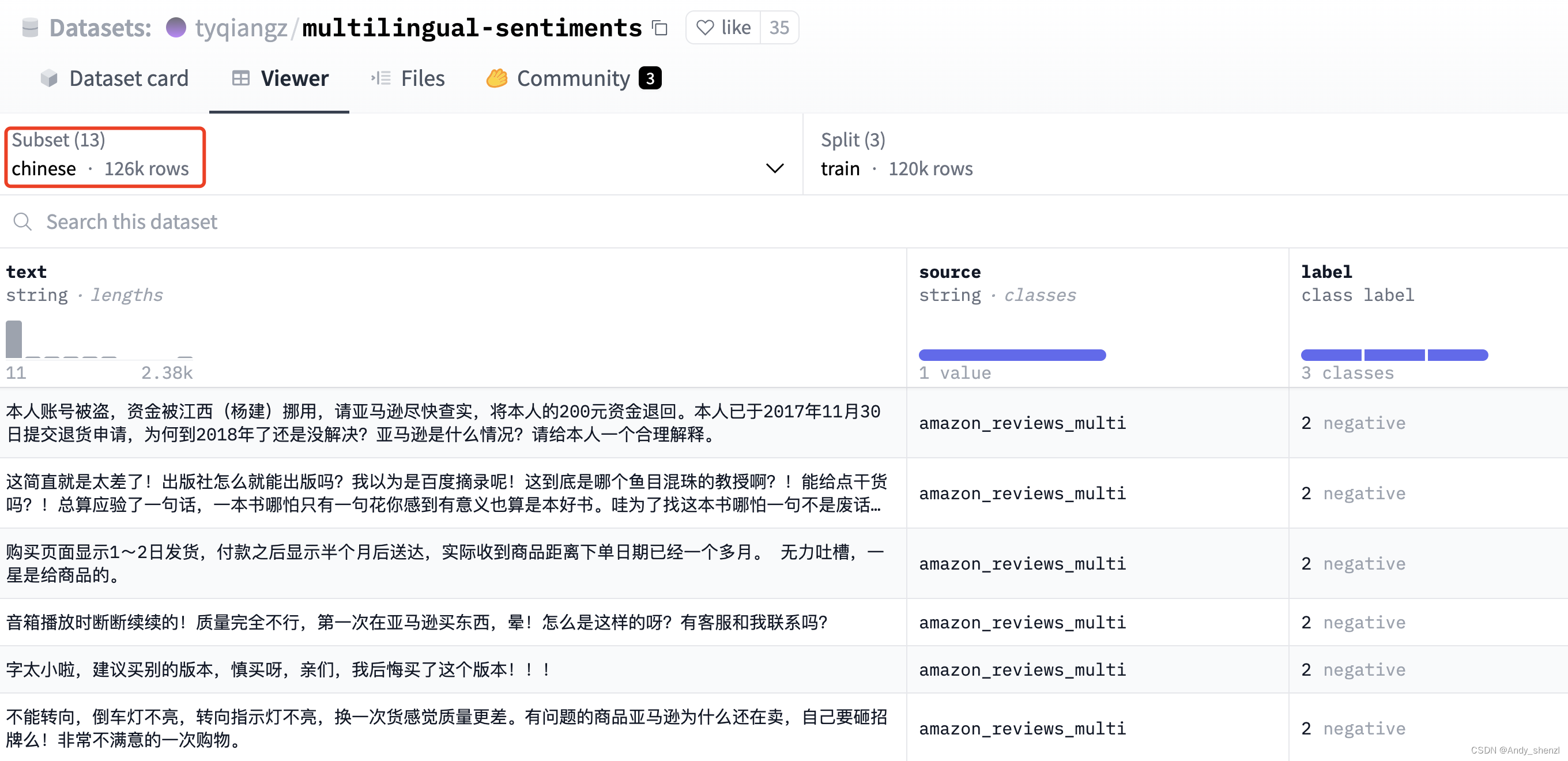
dataset = load_dataset("tyqiangz/multilingual-sentiments", "chinese",cache_dir="./data")
dataset
自己定义一个缓存的位置来存储数据
DatasetDict({
train: Dataset({
features: ['text', 'source', 'label'],
num_rows: 120000
})
validation: Dataset({
features: ['text', 'source', 'label'],
num_rows: 3000
})
test: Dataset({
features: ['text', 'source', 'label'],
num_rows: 3000
})
})
可通过下面代码查看数据
dataset.num_rows
dataset["train"].info
dataset["train"].info.features
dataset["train"][0]
{'text': '本人账号被盗,资金被江西(杨建)挪用,请亚马逊尽快查实,将本人的200元资金退回。本人已于2017年11月30日提交退货申请,为何到2018年了还是没解决?亚马逊是什么情况?请给本人一个合理解释。',
'source': 'amazon_reviews_multi',
'label': 2}
2 数据预处理
tokenizer = AutoTokenizer.from_pretrained("./model/tiansz/bert-base-chinese")
def tokenization(example):
return tokenizer(example["text"], max_length=128, truncation=True)
dataset = dataset.map(tokenization, batched=True)
dataset.set_format(type="torch", columns=["input_ids", "token_type_ids", "attention_mask", "label"])
dataset
DatasetDict({
train: Dataset({
features: ['text', 'source', 'label', 'input_ids', 'token_type_ids', 'attention_mask'],
num_rows: 120000
})
validation: Dataset({
features: ['text', 'source', 'label', 'input_ids', 'token_type_ids', 'attention_mask'],
num_rows: 3000
})
test: Dataset({
features: ['text', 'source', 'label', 'input_ids', 'token_type_ids', 'attention_mask'],
num_rows: 3000
})
})
3 创建模型
model = AutoModelForSequenceClassification.from_pretrained("./model/tiansz/bert-base-chinese", num_labels=3)
4 创建评估函数
acc_metric = evaluate.load("accuracy")
acc_metric.description
‘\nAccuracy is the proportion of correct predictions among the total number of cases processed. It can be computed with:\nAccuracy = (TP + TN) / (TP + TN + FP + FN)\n Where:\nTP: True positive\nTN: True negative\nFP: False positive\nFN: False negative\n’
def eval_metric(eval_predict):
predictions, labels = eval_predict
predictions = predictions.argmax(axis=-1)
acc = acc_metric.compute(predictions=predictions, references=labels)
return acc
5 创建训练器
train_args = TrainingArguments(output_dir="./checkpoints", # 输出文件夹
per_device_train_batch_size=64, # 训练时的batch_size
per_device_eval_batch_size=128, # 验证时的batch_size
logging_steps=10, # log 打印的频率
evaluation_strategy="epoch", # 评估策略
save_strategy="epoch", # 保存策略
save_total_limit=3, # 最大保存数
learning_rate=2e-5, # 学习率
weight_decay=0.01, # weight_decay
metric_for_best_model="accuracy", # 设定评估指标
load_best_model_at_end=True, # 训练完成后加载最优模型
report_to=['tensorboard']
)
trainer = Trainer(model=model,
args=train_args,
train_dataset=dataset["train"],
eval_dataset=dataset["validation"],
data_collator=DataCollatorWithPadding(tokenizer=tokenizer),
compute_metrics=eval_metric)
6 训练模型
trainer.train()

7 评估
trainer.evaluate(dataset["test"])
{'eval_loss': 0.46777570247650146,
'eval_accuracy': 0.8153333333333334,
'eval_runtime': 2.796,
'eval_samples_per_second': 1072.977,
'eval_steps_per_second': 8.584,
'epoch': 3.0}
8 预测
from transformers import pipeline
pipe = pipeline("text-classification", model=model, tokenizer=tokenizer, device=0)
sen = "这个电影不错,我很喜欢"
pipe(sen)
[{'label': 'LABEL_0', 'score': 0.9698687195777893}]
id2label_dic = {
0:"积极",
1:"中性",
2:"消极"
}
model.config.id2label = id2label_dic
pipe = pipeline("text-classification", model=model, tokenizer=tokenizer, device=0)
sen = "这个电影不错,我很喜欢"
pipe(sen)
[{'label': '积极', 'score': 0.9698687195777893}]
sen = "这味道太差了"
pipe(sen)
[{'label': '消极', 'score': 0.8582561016082764}]
sen = "1+2=3"
pipe(sen)
[{'label': '中性', 'score': 0.34471380710601807}]