前言
目标检测作为计算机视觉领域的一个核心任务,其目的是识别出图像中所有感兴趣的目标,并给出它们的类别和位置。YOLO(You Only Look Once)系列模型因其检测速度快、性能优异而成为该领域的明星。随着YOLOv4的推出,目标检测的性能得到了进一步的提升。本文将详细介绍YOLOv4相对于前代YOLO模型的改进点,以及它在目标检测领域的新贡献。
YOLO系列概述
YOLO系列自2016年推出YOLOv1起,就以其卓越的速度和准确度引领着目标检测技术的潮流。YOLOv1将目标检测任务转化为一个回归问题,每个格子(grid cell)负责预测该区域内的物体。随后的YOLOv2通过批量归一化、高斯YOLO等技术进一步提升性能。YOLOv3引入多尺度预测,通过三个不同尺度的网络来检测不同尺寸的物体,极大地提升了对小目标的检测能力。
YOLOv1:开创性的工作
核心特点:
- 将目标检测视为一个回归问题,通过单次前向传播即可预测图像中的目标位置和类别。
- 输入图像被划分为一个个格子(grid cell),每个格子负责预测该区域内的目标。
- 每个格子预测边界框(bounding box)及其置信度(confidence score),以及类别概率。
增长点:
- 相比于传统的两阶段检测器(如R-CNN系列),YOLOv1大幅提高了检测速度。
- 简化了检测流程,去除了候选区域(Region Proposal Network, RPN)的步骤。
YOLOv2:性能与速度的双重提升
核心特点:
- 引入了批归一化(Batch Normalization)和高分辨率特征图,提高了模型的训练稳定性和预测准确性。
- 采用了anchor box技术,增强了对不同尺度目标的检测能力。
- 引入了k-means聚类来自动生成anchor box的尺寸,使模型更加适应数据集特性。
增长点:
- 相比于YOLOv1,YOLOv2在保持速度优势的同时,显著提高了检测的准确度和召回率。
YOLOv3:多尺度预测与更深网络
核心特点:
- 采用了三个不同尺度的特征图进行目标检测,增强了对不同大小目标的检测能力。
- 主干网络升级为更深的Darknet-53,提供了更强的特征提取能力。
- 引入了特征金字塔网络(FPN)和路径聚合网络(PAN),进一步增强了特征的融合和利用。
增长点:
- YOLOv3在多尺度目标检测方面取得了突破,尤其是在小目标检测上的性能有显著提升。
- 更深的网络结构和特征融合技术使得YOLOv3在准确性上有了大幅度的提高。
YOLOv4:高效、强大的检测模型
核心特点:
- 设计了强大而高效的检测模型,可以在普通的GPU上进行快速准确的训练。
- 验证和改进了多种SOTA的训练技巧,如CmBN、PAN、SAM等,使其更适合单GPU训练。
- 引入了Mosaic数据增强和自对抗训练(SAT),进一步提升了模型的泛化能力。
增长点:
- YOLOv4在前代基础上,通过综合优化和技术创新,达到了更高的速度和准确度。
- 引入的新技术如Mish激活函数、CSPDarknet53等,进一步提升了模型的性能和训练效率。
YOLOv4的创新点(进入正题)
数据增强与正则化
YOLOv4引入了多项创新技术,显著提升了模型在目标检测任务中的表现。
1. Mosaic数据增强
YOLOv4采用了Mosaic数据增强技术,该技术通过将四个不同图像的部分拼接在一起,形成一个增强的输入图像。这种方法使得模型能够更好地理解不同的图像背景,从而提高对复杂场景的检测准确性。
2. 自对抗训练(SAT)
自对抗训练是YOLOv4引入的另一种创新技术。SAT通过在训练过程中引入扰动,模拟不同的视觉环境,增强模型对多样化情况的适应能力。这不仅提升了模型的检测准确性,还增强了其在各种实际场景中的鲁棒性。
3. DropBlock正则化
YOLOv4采用了DropBlock正则化技术来替代传统的Dropout。DropBlock通过随机丢弃更大的特征图区域,更有效地降低了特征之间的相互依赖性,从而降低了计算负载,并防止了过拟合的发生。
技术融合的优势
通过这些技术的融合,YOLOv4实现了以下优势:
- 提高检测准确性:Mosaic数据增强和自对抗训练提升了模型对复杂场景的理解能力,从而提高了检测准确性。
- 增强鲁棒性:SAT技术使得模型能够适应多样化的视觉环境,增强了模型在不同情况下的鲁棒性。
- 优化模型效率:DropBlock正则化在防止过拟合的同时,优化了模型的计算效率。
- 增强泛化能力:DropBlock的使用增强了模型的泛化能力,确保了在不同数据集和实际场景中的优异性能。
示例代码(伪代码)
# 假设使用PyTorch框架实现YOLOv4的训练过程
model = YOLOv4(num_classes=COCO_CLASSES, img_size=416)
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# 训练循环
for epoch in range(num_epochs):
for images, targets in train_loader:
# Mosaic数据增强
images = mosaic_augment(images)
# 自对抗训练
images = self_adversarial_training(images)
# 前向传播
outputs = model(images)
# 计算损失
loss = compute_loss(outputs, targets)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 周期性评估
if (epoch + 1) % eval_frequency == 0:
mAP = evaluate_model(model, validation_loader)
print(f'Epoch {epoch+1}/{num_epochs}, mAP: {mAP}')
网络结构优化
YOLOv4通过精心设计的网络结构和创新技术,实现了在目标检测任务中的高效率和高精度。以下是对YOLOv4网络结构和技术特点的优化分析:
1. 主干网络:CSPDarknet53
YOLOv4选用了CSPDarknet53作为其主干网络,这是一种为提高模型效率而设计的轻量化深度神经网络结构。CSPDarknet53的特点包括:
- 计算成本降低:通过减少网络中的计算量,CSPDarknet53在不牺牲检测精度的前提下,提高了模型的训练和推理速度。
- Cross Stage Partial连接:该机制将网络分支与主干部分相结合,进一步优化了计算效率。
2. 特征融合技术
YOLOv4引入了以下两种技术以增强特征的融合和提取能力:
SPP (Spatial Pyramid Pooling)
- 多尺度特征捕获:SPP允许网络在不同尺度下对特征进行池化,有效捕获不同大小物体的信息。
- 尺度适应性增强:通过这种池化机制,YOLOv4的模型对不同尺度物体的检测能力得到显著提升。
PAN (Path Aggregation Network)
- 特征图整合:PAN技术整合了不同层级的特征图,加强了信息的聚合和传递。
- 特征表征提升:这增强了模型的特征表征能力和对语义信息的提取效率。
技术优势
结合CSPDarknet53、SPP和PAN技术,YOLOv4的优势包括:
- 高效率:CSPDarknet53结构减少了模型的计算负担,加快了处理速度。
- 尺度不变性:SPP技术提升了模型对多尺度物体的检测性能。
- 特征表达增强:PAN技术增强了模型对复杂场景中小目标的检测能力。
示例代码(伪代码)
# 假设使用PyTorch框架实现YOLOv4的主干网络CSPDarknet53
class CSPDarknet53(nn.Module):
def __init__(self):
super(CSPDarknet53, self).__init__()
# 初始化网络结构
def forward(self, x):
# 实现前向传播
return x
# 实例化YOLOv4模型
model = YOLOv4(backbone=CSPDarknet53(), num_classes=COCO_CLASSES, img_size=416)
# 后续训练和评估过程...
损失函数与后处理更新
1. 边界框回归损失函数:CIoU Loss
YOLOv4在边界框回归中采用了CIoU Loss,这是一种先进的损失函数,用于更精确地优化边界框预测。CIoU Loss的特点包括:
- 交并比(IoU)考虑:CIoU Loss不仅考虑了边界框的交并比,还考虑了边界框中心点之间的距离。
- 宽高相关性:此外,CIoU Loss还考虑了边界框的宽度和高度之间的相关性,这有助于更准确地衡量边界框之间的相似性。
- 位置偏差优化:通过这些因素的综合考量,CIoU Loss能够更好地纠正边界框的位置偏差。
2. 后处理策略:DIoU-NMS
在后处理阶段,YOLOv4采用了DIoU-NMS (Distance-IoU Non-Maximum Suppression),这是一种改进的非极大值抑制方法,它在评估边界框重叠程度时考虑了更多因素:
- 对角线距离:DIoU-NMS考虑了边界框之间的对角线距离,这有助于更准确地评估边界框的重叠程度。
- 重叠框优化:相比传统的NMS,DIoU-NMS避免了过多重叠框的保留,从而提高了检测结果的准确性和稳定性。
技术优势
通过CIoU Loss和DIoU-NMS的应用,YOLOv4在目标检测中展现了以下优势:
- 预测精度提高:CIoU Loss的使用使得边界框预测更加精确。
- 鲁棒性增强:DIoU-NMS在复杂场景中提供了更稳定的检测结果。
结论
YOLOv4通过采用CIoU Loss和DIoU-NMS等先进技术,显著提升了目标检测的精度和鲁棒性。这些策略的应用使得YOLOv4在处理复杂场景和小目标检测等任务时具有更强的适应性和泛化能力。
示例代码(伪代码)
# 假设使用PyTorch框架实现YOLOv4的CIoU Loss和DIoU-NMS
class CIoULoss(nn.Module):
def __init__(self):
super(CIoULoss, self).__init__()
# 初始化CIoU损失函数所需的参数
def forward(self, pred_boxes, true_boxes):
# 计算CIoU Loss
return ciou_loss
def diou_nms(boxes, scores, iou_threshold):
# 实现DIoU-NMS
# 根据DIoU距离和IoU阈值进行非极大值抑制
return filtered_boxes
# 模型训练和评估过程...
YOLOv4的网络结构详解
Backbone:CSPDarknet53
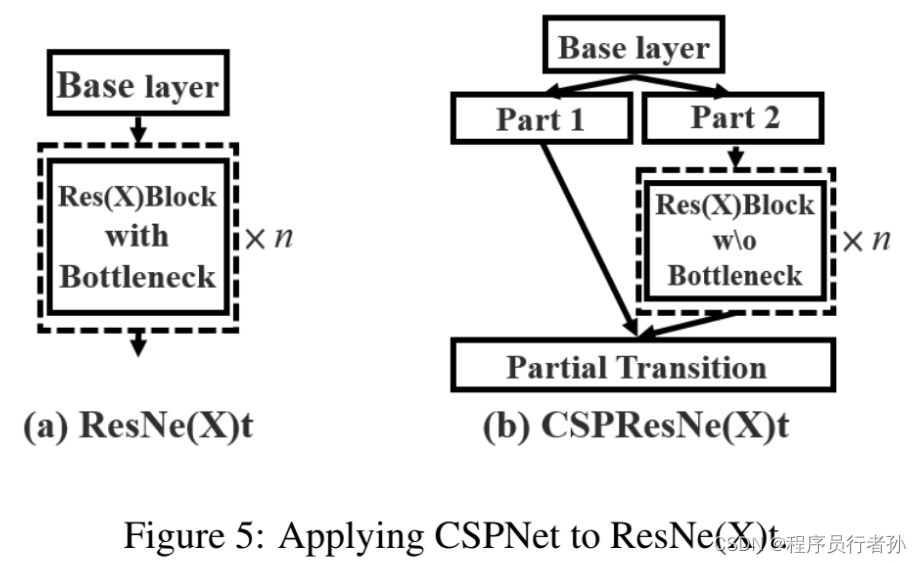
YOLOv4的骨干网络CSPDarknet53采用了CSPNet(Cross Stage Partial Network)的设计思想,以提高目标检测的效率和精度。以下是对CSPDarknet53网络结构及其对YOLOv4性能影响的清晰化表述:
CSPDarknet53骨干网络
设计理念
CSPDarknet53利用CSPNet的设计思想,通过以下方式优化网络结构:
- 分支和合并机制:在网络中引入特征图的分割与重组,实现不同层次上的特征融合。
- 参数和计算量减少:这种架构减少了模型的参数数量和计算量,从而提高效率。
性能提升
CSPDarknet53的设计带来了以下性能优势:
- 训练和推理效率:优化设计显著提升了模型的训练和推理速度。
- 高精度保持:在减少计算量的同时,保持了模型的高精度检测性能。
网络优化策略
CSPDarknet53通过以下策略实现网络优化:
- 部分连接:引入CSPNet的部分连接策略,降低网络中的冗余计算。
- 重要信息保留:在各个阶段中有效地保持重要信息的传递。
目标检测任务中的表现
CSPDarknet53增强了YOLOv4在目标检测任务中的表现:
- 特征提取能力:加强了网络在不同层级上的特征提取能力。
- 信息融合能力:提升了特征图的信息融合能力,增强了模型的表现。
复杂场景下的性能
CSPDarknet53的使用使得YOLOv4在复杂场景下能够:
- 保持稳定性能:即使在处理复杂场景和大规模数据时也能维持稳定的表现。
- 准确性:具备出色的检测准确性。
小结
CSPDarknet53作为YOLOv4的骨干网络,通过CSPNet的设计思想,有效地平衡了模型的效率和准确性。这种结构不仅提高了目标检测的速度,而且确保了检测的质量,使YOLOv4成为一个在多种场景下都具有竞争力的目标检测模型。
Neck:SPP和PAN
SPP(Spatial Pyramid Pooling)和PAN(Path Aggregation Network)在YOLOv4中的作用
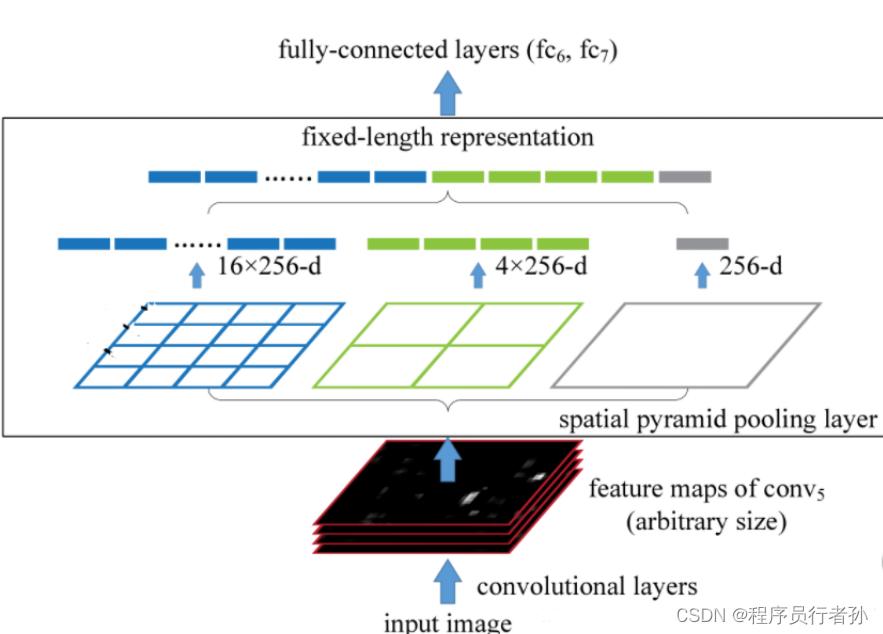
SPP(Spatial Pyramid Pooling)
- 功能:通过不同尺寸的池化核提取特征。
- 优势:
- 多尺度特征表达:网络可以在不同尺度下捕捉物体特征。
- 增强感知能力:提高对多尺度物体的识别能力。
- 提升准确性与鲁棒性:通过在不同层级上进行池化操作,网络能更好地捕捉不同尺度物体的特征信息。
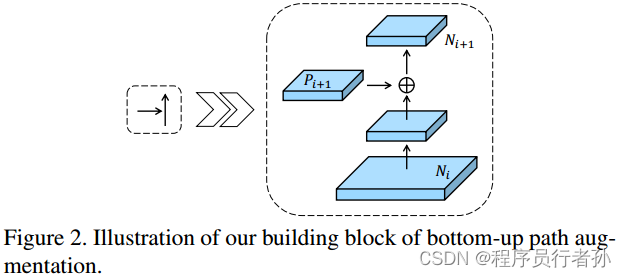
PAN(Path Aggregation Network)
- 功能:加强低层次特征到高层次特征的直接连接。
- 优势:
- 信息保持与整合:在信息传递过程中保持低层次特征的详细信息,并有效整合到高层次特征中。
- 提升小目标检测:直接连接有助于理解物体的细微特征和上下文信息,提高小目标的检测精度和稳定性。
综合效果
- Neck的作用:SPP和PAN作为Neck的关键技术,共同增强了YOLOv4模型的目标识别能力。
- 多尺度识别:SPP通过多尺度特征表达,提升了模型对不同尺度物体的识别。
- 复杂场景适应性:PAN通过低高层次特征连接,增强了模型在复杂场景下的表现。
- 整体性能提升:两者结合,提高了YOLOv4在目标检测任务中的准确性和鲁棒性。
Head:YOLOv3 Head
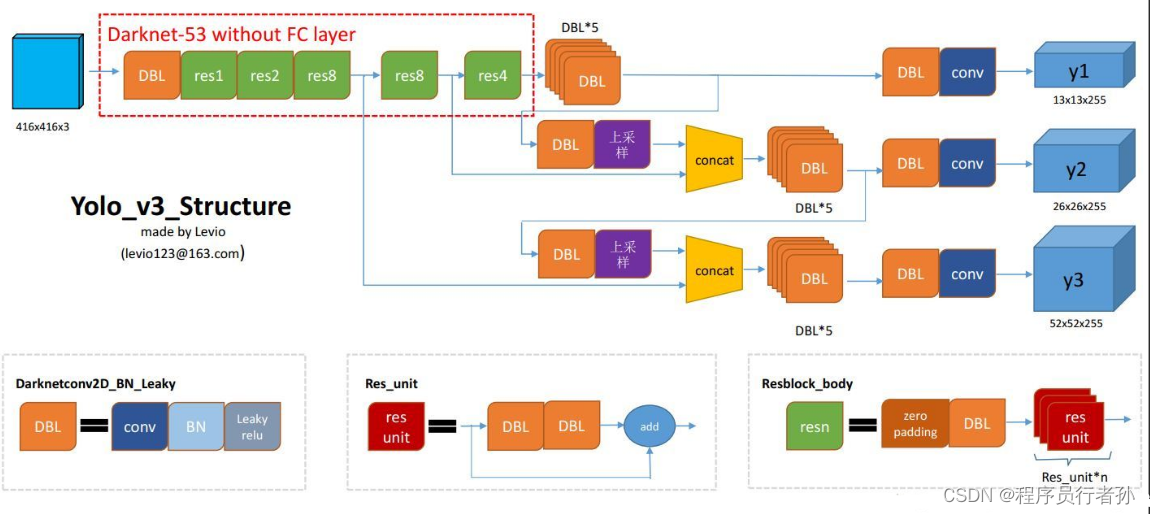
1. Head部分功能与组成
- 定义:YOLOv3网络结构中负责目标检测输出的关键部分。
- 组成:由多个预测层构成,主要任务是将特征图转换成目标框的位置和类别信息。
2. 多尺度预测层设计
- 构成:包含三个不同尺度的预测层,各自负责检测相应尺度的目标。
- 优势:
- 泛化能力:有效检测不同大小和尺度的物体,增强了模型的泛化能力。
- 多尺度检测:每个预测层专注于特定尺度的目标,提高了检测的准确性。
3. 预测层工作流程与后处理
- 卷积与激活:每个预测层由卷积层和线性激活函数(如Leaky ReLU)组成,用于特征图的进一步处理。
- 目标框生成:通过卷积操作,将处理后的特征图转换成目标框的位置和类别信息。
- 后处理步骤:
- 过滤:移除低置信度的边界框。
- 非极大值抑制:对边界框进行优化,以提高最终检测结果的准确性。
- 结果输出:经过后处理,得到最终的检测结果。
小结
YOLOv3的Head部分通过其多尺度预测层的设计和精细的后处理步骤,实现了对目标的高效检测和准确定位,确保了模型在各种目标检测任务中的卓越性能。
YOLOv4的性能提升策略
激活函数的选择与优化
YOLOv4在选择激活函数时,进行了细致的考量和实验,最终选择了适合其架构的激活函数,以提升模型性能。
激活函数选择
Mish激活函数:YOLOv4实验了多种激活函数后,选择了Mish激活函数,它由
Mish(x) = x * tanh(softplus(x))定义,其中softplus(x) = log(1 + exp(x))。Mish因其在各种任务中展现出的优异性能而被选用,它结合了ReLU和Swish的特点,同时解决了ReLU的梯度消失和Swish计算复杂的问题。
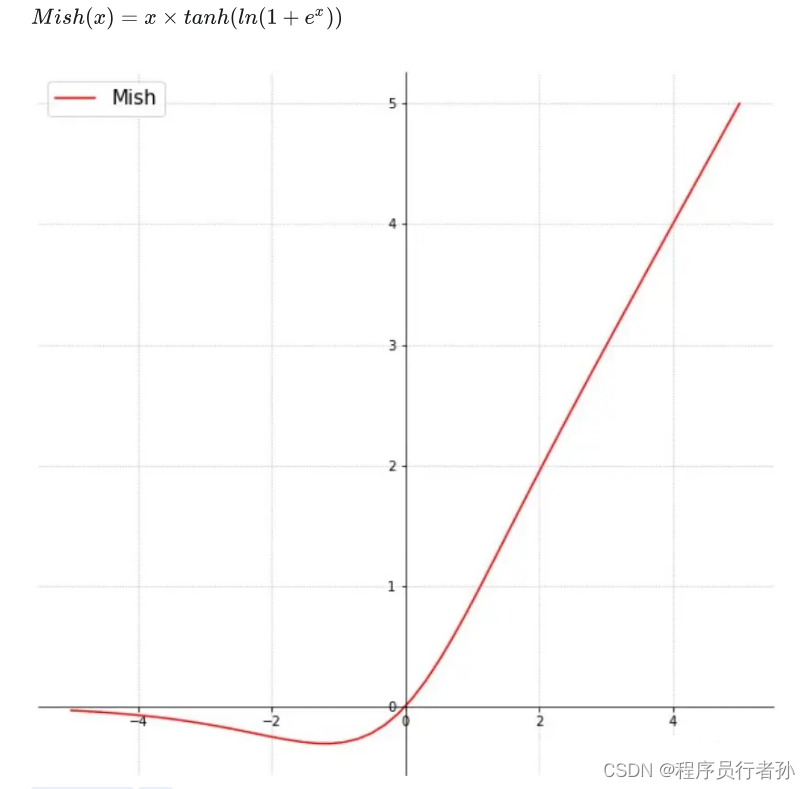
Swish激活函数:虽然Swish在某些任务中表现良好,但在YOLOv4的实验中,Mish相比于Swish有更好的表现。
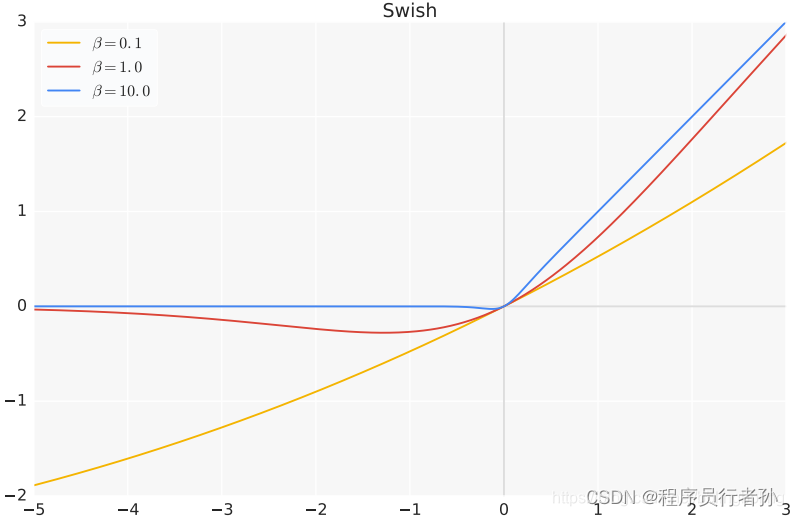
Leaky ReLU:在某些变体或特定的网络层中,YOLOv4也可能使用Leaky ReLU激活函数,它允许负输入的小的梯度通过,从而缓解了ReLU的梯度消失问题。
激活函数优化
激活函数的参数调整:YOLOv4的开发者对激活函数的参数进行了调整,以适应不同网络层的需求。
网络结构的协同设计:激活函数的选择与网络的其他部分协同设计,以确保整个网络的最优性能。
实验验证:通过广泛的实验,YOLOv4的开发者验证了不同激活函数对模型性能的影响,选择了最适合目标检测任务的激活函数。
计算效率:YOLOv4在保持高准确率的同时,也注重模型的计算效率。Mish等激活函数的计算成本较低,有助于实现实时目标检测。
泛化能力:优化的激活函数有助于提高模型的泛化能力,使YOLOv4能够在不同的数据集和实际应用场景中表现良好。
特征融合技术
YOLOv4采用了先进的特征融合技术,如FPN和PAN,这些技术有助于提取更丰富的特征表示,提升检测性能。
特征融合技术是深度学习中用于结合来自不同特征层的信息,以增强模型性能的方法。在计算机视觉中,特征融合通常指的是将不同尺度或分辨率的特征图(feature maps)结合起来,以获取更丰富的图像表示。这种技术在处理多尺度目标或需要细节和上下文信息的任务中尤其有用。
特征融合的简单实现
以下是一个使用Python和PyTorch库实现的简单特征融合示例。假设我们有两个不同尺度的特征图,我们想要将它们融合在一起:
import torch
import torch.nn as nn
# 假设有两个不同尺度的特征图
feature_map_large = torch.randn(1, 256, 64, 64) # 大的特征图,例如来自深层网络
feature_map_small = torch.randn(1, 128, 32, 32) # 小的特征图,例如来自较浅层网络
# 为了融合它们,我们首先需要将它们调整到相同的尺度
# 这里使用上采样(Upsampling)将小的特征图调整到大的特征图的尺度
upsampled_small = nn.functional.interpolate(feature_map_small, size=(64, 64), mode='bilinear', align_corners=False)
# 然后我们可以使用各种融合策略,例如简单的拼接(Concatenation)
# 拼接特征图并进行通道维度上的组合
combined_feature_maps = torch.cat((feature_map_large, upscaled_small), dim=1)
# 接下来,我们可以设计一个卷积层来进一步整合这些特征
class FusionLayer(nn.Module):
def __init__(self, input_channels, output_channels):
super(FusionLayer, self).__init__()
self.conv = nn.Conv2d(input_channels, output_channels, kernel_size=1)
def forward(self, x):
return self.conv(x)
# 实例化融合层并应用到组合的特征图上
fusion_layer = FusionLayer(combined_feature_maps.shape[1], 256) # 假设我们想要256个输出通道
fused_feature_maps = fusion_layer(combined_feature_maps)
# 现在 fused_feature_maps 包含了融合后的特征信息
在这个示例中,我们首先通过双线性插值(bilinear upsampling)将小的特征图上采样到与大的特征图相同的分辨率。然后,我们将这两个特征图在通道维度上拼接起来,形成一个新的特征图。最后,我们设计了一个简单的卷积层(FusionLayer),它使用1x1的卷积核来进一步整合这些特征。
超参数的调优
YOLOv4使用了遗传算法等先进的超参数调优技术,寻找到了最佳的超参数组合,进一步提升了模型的性能。
超参数调优(Hyperparameter Tuning)是机器学习中一个重要的步骤,它涉及选择模型的最优超参数,以提高模型的性能。超参数不是模型从数据中学习得到的,而是在训练之前手动设置的参数,例如学习率、正则化参数、网络层数、每层的神经元数量等。
超参数调优的目标是找到一组超参数值,使得模型在验证集上的性能最优。这个过程可以通过多种方法实现,包括:
- 网格搜索(Grid Search):通过遍历给定的参数网格,训练并评估模型,选择最佳的超参数组合。
- 随机搜索(Random Search):随机选择超参数组合进行训练和评估,可以在更少的迭代次数内找到接近最优的参数。
- 贝叶斯优化(Bayesian Optimization):使用概率模型来预测超参数对性能的影响,并选择最有可能导致性能提升的超参数组合。
- 自动化机器学习(AutoML):使用自动化工具来选择超参数,如Google的AutoML、H2O.ai等。
网格搜索调优
以下是使用Python的scikit-learn库进行网格搜索超参数调优的示例代码:
from sklearn.model_selection import GridSearchCV
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
# 加载数据集
iris = load_iris()
X, y = iris.data, iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 定义模型
rf = RandomForestClassifier(random_state=42)
# 定义要搜索的超参数网格
param_grid = {
'n_estimators': [10, 50, 100, 200],
'max_depth': [None, 10, 20, 30],
'min_samples_split': [2, 5, 10]
}
# 创建GridSearchCV对象
grid_search = GridSearchCV(estimator=rf, param_grid=param_grid, cv=5, scoring='accuracy')
# 执行网格搜索
grid_search.fit(X_train, y_train)
# 输出最佳超参数
print("Best parameters found: ", grid_search.best_params_)
# 评估最佳模型
best_model = grid_search.best_estimator_
accuracy = best_model.score(X_test, y_test)
print("Accuracy of the best model: ", accuracy)
在这个示例中,我们使用了RandomForestClassifier作为模型,定义了一个包含不同n_estimators(树的数量)、max_depth(树的最大深度)和min_samples_split(分裂内部节点所需的最小样本数)的参数网格。然后,我们使用GridSearchCV对象来执行网格搜索,它会在给定的参数网格上进行交叉验证,并找到最佳的超参数组合。最后,我们输出了找到的最佳超参数,并评估了使用这些超参数训练的模型在测试集上的准确率。
多尺度训练
YOLOv4在训练过程中采用了多尺度训练,使得模型对不同尺寸的目标具有更好的泛化能力。
多尺度训练(Multi-scale Training)是一种在深度学习中用于提高模型泛化能力的方法,特别是在计算机视觉任务中。这种训练方式涉及在多个不同的尺度或分辨率上对模型进行训练,目的是使模型能够更好地理解和识别不同尺寸的物体。
在卷积神经网络(CNN)中,多尺度训练可以通过以下几种方式实现:
输入图像的多尺度:在训练过程中,输入图像可以被缩放到不同的尺寸,使模型学会在不同尺度上识别特征。
特征金字塔:构建一个特征金字塔,其中不同层级的CNN输出用于捕捉不同尺度的特征。
多尺度卷积核:使用不同大小的卷积核来捕捉不同尺度的特征。
锚点框的多尺度:在目标检测任务中,为每个类别定义多个不同尺寸的锚点框。
多尺度训练示例代码
以下是一个使用PyTorch库实现的多尺度训练的简单示例,其中我们对输入图像使用不同的尺度进行训练:
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
# 定义一个简单的CNN模型
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
self.conv1 = nn.Conv2d(3, 16, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(16, 32, kernel_size=3, padding=1)
self.fc1 = nn.Linear(8*8*32, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = nn.functional.relu(self.conv1(x))
x = nn.functional.max_pool2d(x, 2)
x = nn.functional.relu(self.conv2(x))
x = nn.functional.max_pool2d(x, 2)
x = x.view(x.size(0), -1) # Flatten the tensor
x = nn.functional.relu(self.fc1(x))
x = self.fc2(x)
return x
# 实例化模型
model = SimpleCNN()
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 定义数据加载器,包括多尺度变换
train_loader = torch.utils.data.DataLoader(
datasets.CIFAR10(root='./data', train=True, download=True,
transform=transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.RandomChoice([
transforms.Resize(32),
transforms.Resize(48),
transforms.Resize(64) # 多尺度变换
]),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])),
batch_size=64, shuffle=True
)
# 多尺度训练循环
for epoch in range(10): # 假设我们训练10个epoch
for batch_idx, (inputs, targets) in enumerate(train_loader):
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, targets)
loss.backward()
optimizer.step()
if batch_idx % 100 == 0:
print(f"Epoch {epoch}, Batch {batch_idx}, Loss {loss.item()}")
# 注意:这只是一个简化的示例,实际训练可能需要更复杂的数据增强和训练逻辑。
在这个示例中,我们首先定义了一个简单的CNN模型SimpleCNN。然后,我们创建了一个数据加载器train_loader,它使用transforms.RandomChoice来随机选择输入图像的尺寸(32x32、48x48或64x64),从而实现多尺度训练。在训练循环中,我们使用优化器更新模型的权重,以最小化损失函数。
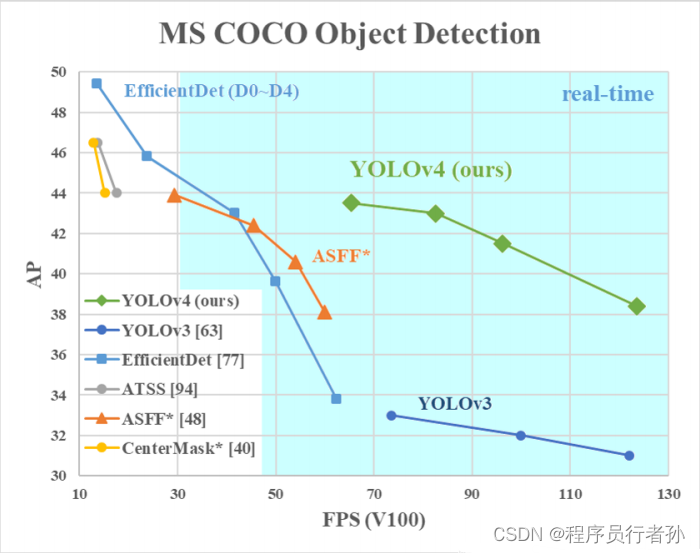
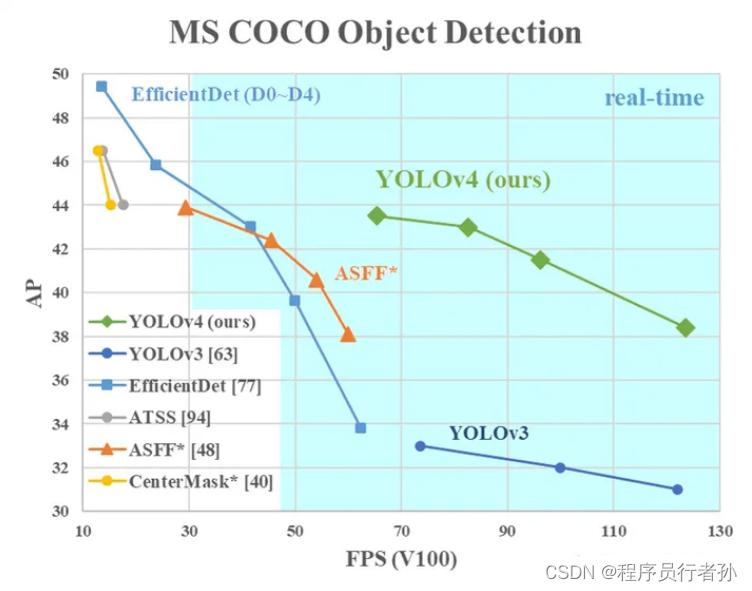
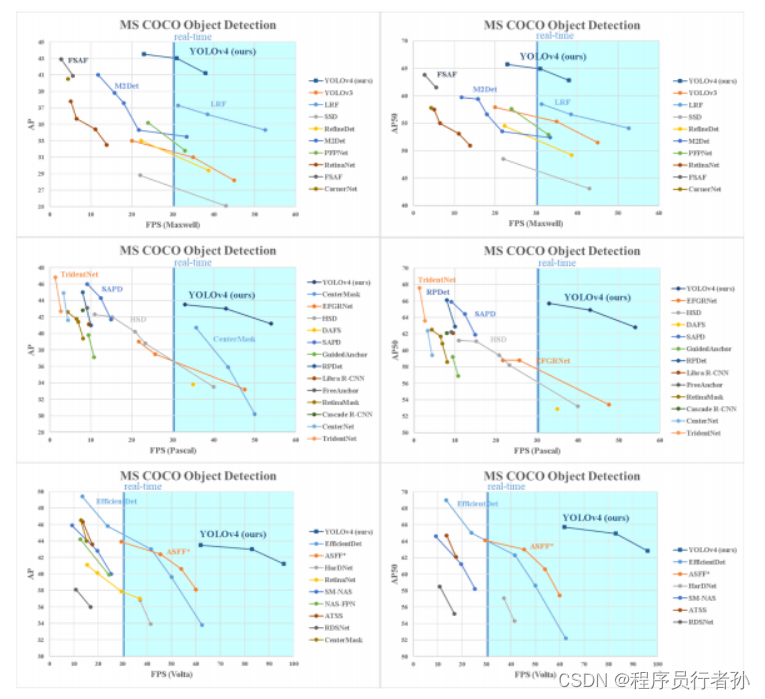
YOLOv4的实验结果与分析
YOLOv4在COCO数据集上的表现超越了先前的YOLO模型和其他目标检测模型,如SSD、RetinaNet等。它在保持高速度的同时,显著提升了检测精度。
结论
YOLOv4是目标检测领域的一个重要进展,它在保持实时性的同时,显著提升了检测精度。通过一系列创新的技术,YOLOv4证明了单阶段检测器在实际应用中的潜力和价值。