预训练的代码语言模型在代码生成方面取得了可喜的性能,并提高了人类开发人员的编程效率。然而,现有的代码 LM 评估通常忽略了它们的 自我求精能力,这些评估仅关注一次性预测的准确性。对于代码 LM 无法实现正确程序的情况,开发人员实际上发现很难调试和修复错误的预测,因为它不是由开发人员自己编写的。不幸的是,我们的研究表明,代码语言模型也无法有效地自我改进其错误的生成。在本文中,我们提出了 Cycle 框架,学习根据可用的反馈(例如测试套件报告的执行结果)来自我改进错误的生成。我们在三个流行的代码生成基准测试(HumanEval、MBPP 和 APPS)上评估 Cycle。结果表明,Cycle 成功地保持了(有时还提高了)一次性代码生成的质量,同时显着提高了代码 LM 的自我优化能力。我们在 350M、1B、2B 和 3B 上实现了具有不同数量参数的 Cycle 的四种变体,实验表明,Cycle 在基准测试和不同的模型大小上始终如一地提高了代码生成性能高达 63.5%。我们还注意到,Cycle 的性能优于参数多 3 倍的代码自优化LM。
Intriduction
在本文中,我们提出了 Cycle 框架,试图提高代码 LM 在探索模式下的性能。创建 Cycle 的基本原则是认识到,期望代码 LM 在探索模式中表现出色可能要求过高,而在探索模式中,人类的意图往往不明确或没有明确指定。然而,这些模型应该具备根据从其他来源收到的反馈(例如测试套件报告的执行结果)迭代改进代码生成的能力。从本质上讲,Cycle 的目标是使代码语言模型能够根据可用的反馈来调整和增强其输出,从而缩小人类开发人员的探索性编程需求与代码语言模型的能力之间的差距。
探索模式中代码 LM 的局限性。在这项工作中,我们重点关注代码生成的场景,给定问题的自然语言 (NL) 描述(通常包装在文档字符串中),代码 LM 将相应地实现程序。为了方便我们以后的讨论,我们首先具体化我们场景中的加速模式和探索模式。
• 加速模式:给定问题的NL 描述,代码LM 直接相应地预测代码。
• 探索模式:如果加速模式的预测未能通过测试用例并且返回执行反馈,则代码LM 会尝试改进错误代码,而无需进一步的人工指令。
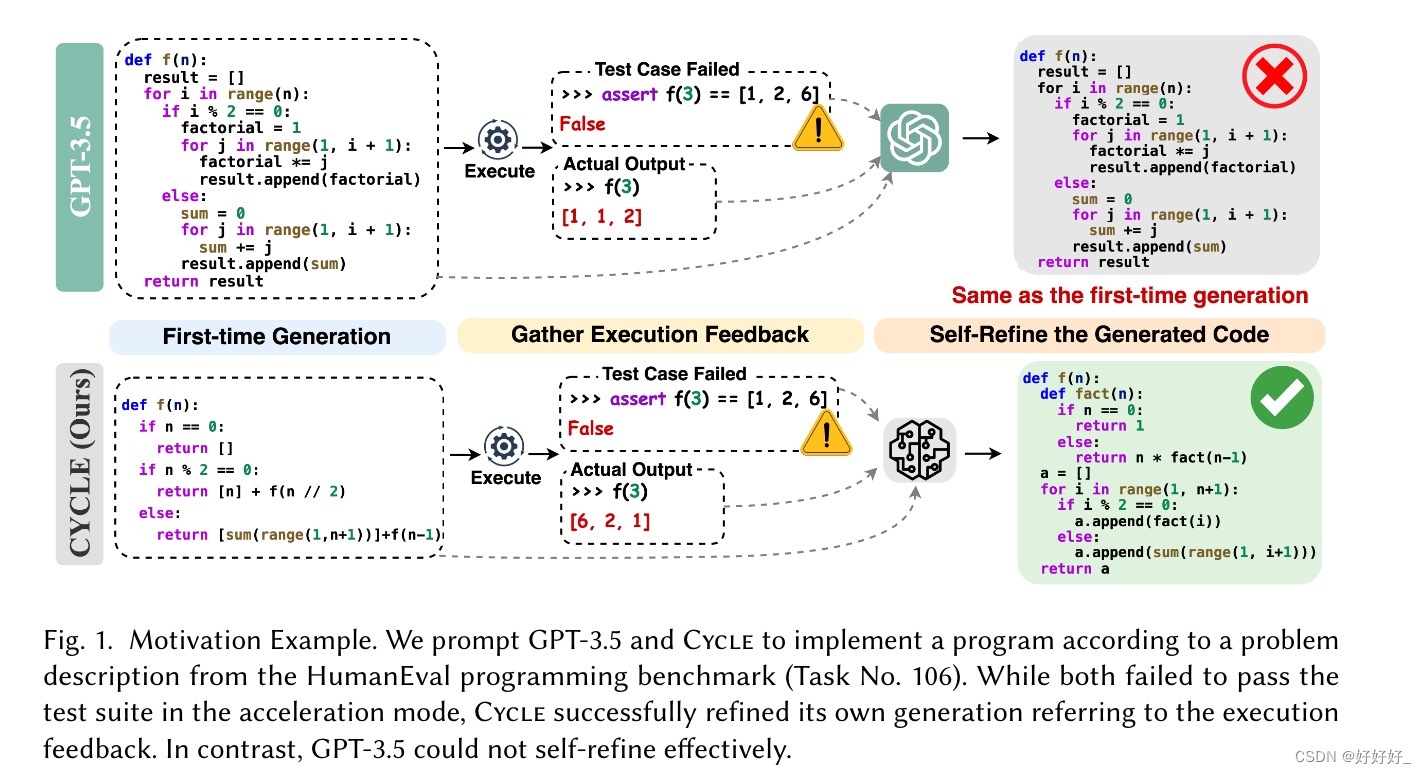
如图1所示,我们提示GPT-3.5[Ouyang et al. 2022] 以及来自 HumanEval 编程基准的问题描述 [Chen 等人。 2021]。 GPT-3.5无法实现加速模式下的功能,其生成的代码未能通过该问题的测试套件。从GPT-3.5的生成过程中我们可以看出,虽然程序很短,只有14行,但对于人类来说并不容易理解。复杂性主要来自于嵌套的 for 循环,使得手动识别和纠正错误变得更加困难。因此,在陈等人的推动下。 [2023],我们尝试将测试套件报告的错误生成和执行反馈作为附加参考与问题描述连接起来,并期望模型在探索模式下自行完善生成的代码。不幸的是,GPT-3.5 无法有效理解执行反馈的指导,只是简单地复制粘贴错误代码作为新的预测。这种探索模式自我完善的弱点在开源代码语言模型中更为严重。我们使用 CodeGen(27 亿个参数)进行类似的实验 [Nijkamp 等人。 2023b] 和 StarCoder(30 亿个参数)[Li 等人。 2023] 关于整个 HumanEval 基准测试,包含 164 个编程问题。我们观察到现有的代码语言模型在探索模式下表现不佳,无法根据执行反馈自我完善错误的代。 CodeGen 在 42.2% 的情况下生成错误代码的精确副本作为其精确预测,而 StarCoder 在 64.8% 的情况下进行复制。探索模式中如此弱的自我完善能力令人担忧,因为它给人类开发人员带来了修复模型生成代码带来的错误的进一步负担。
我们的方法:在这项工作中,我们认为应该通过利用执行结果的可用反馈,在探索模式中增强代码 LM 的自我优化能力。事实上,使用这种执行反馈训练的模型即使在加速模式下也有可能表现得更好。为此,我们设计了 Cycle,一个框架,通过共同关注三个信息源来教会代码 LM 自我完善(通过继续训练预训练模型):(i)自然语言的高级问题描述,( ii) 模型在之前的尝试中可能生成的错误代码,以及 (iii) 执行反馈。我们开发了一个输入模板,整合了这三个信息源,并利用它们来训练代码 LM。虽然传统的代码语言模型的训练主要依赖于第一个信息源,但包含先前的错误代码有助于模型更全面地掌握自身的错误。执行反馈反过来又指导代码 LM 生成与问题描述精确一致的程序。尽管如此,当我们天真地将之前生成的错误代码包含在输入中时,代码LM通常会采取捷径,本质上是在生成新代码时从错误的输入中进行复制。为了阻止代码 LM 采用此类快捷方式,我们采用了一种掩码技术,称为过去一代掩码 (PGM)。这种策略稍微混淆了过去几代的错误,激励模型探索更广泛的代码优化解决方案。此外,为了在加速和探索模式下代码生成的熟练程度之间取得平衡,我们采用了一种数据混合策略来操纵自我细化功能和通用代码完成功能的比率。为了使用上述策略有效地训练 Code LM,我们必须整理模拟探索模式开发的数据。因此,我们进一步设计了一个训练数据自动生成阶段作为现有的预训练代码数据集 [Kocetkov 等人。 2022 年;尼坎普等人。 2023b;徐等人。 2022]定制自我提升训练具有挑战性。我们的数据收集阶段自动提示预训练的代码LM揭示其在代码生成中的优势和劣势,通过执行测试用例进行验证,并构建数据样本以增强其优势,同时完善其劣势。
最后,我们实现了 Cycle 来实现自动化的自我完善工作流程,模仿人类开发人员的迭代编程实践。工作流程首先提示代码语言模型根据高级问题描述初始化实现,然后通过执行不断验证预测的正确性,并汇总综合信息以进一步细化。
我们做出了以下新颖的贡献:
• 我们的工作揭示了代码语言模型在自我改进方面的弱点,揭示了这些模型在理解执行反馈并相应地纠正自己的错误方面并不能有效。
• 为了发挥代码语言模型自我改进的潜力,我们提出了 Cycle,这是一个通过学习改进自己生成的代码来增强代码语言模型生成性能的框架。我们首先提出了一种基于知识蒸馏的数据收集方法来自动构建样本来教导代码语言模型进行自我改进。然后,我们提出了专门为学习自我完善而设计的培训策略。最后,我们实现了一个迭代式自我完善工作流程,可以自动执行探索模式下生成代码的过程。
• 我们对三种流行的代码生成基准测试进行了广泛的实验,其中包括 350M 至 3B 模型参数的四种 Cycle 变体,结果表明 Cycle 持续将代码生成性能提高了 63.5%。 Cycle 还可以匹配甚至超越具有 3 倍参数的基线代码 LM。
• 我们进行深入分析,从多个角度讨论Cycle的设计和性能。最后,我们提出了见解和要点,以激励进一步研究提高代码 LM 的自我改进能力,这有望帮助人类开发人员进行迭代编程,并普遍提高代码 LM 在探索模式下的性能。我们匿名发布我们的代码、数据和模型检查点。代码可以从 https://github.com/ARiSE-Lab/CYCLE_OOPSLA_24 获取。
Overview of the Approach
在本节中,我们简要介绍 Cycle,解释高层设计及其背后的直觉。我们在图 2 中展示了 Cycle 的概述。从高层次来看,Cycle 包含三个阶段。
第一阶段:自我优化的数据准备。训练代码 LM 的细化能力的数据需要精心设计的功能,例如带有代码片段迭代修正的开发日志及其错误暴露反馈循环。这些特征并不自然地与大规模预训练数据集一起出现[Kocetkov 等人。 2022 年;尼坎普等人。 2023b;徐等人。 2022年]。大规模与训练数据集通常会优先考虑数据量,而不提供定制接口。因此,我们提出了一种自动化方法,从预先训练的代码 LM 中提取这些特征,并在它们之上构建数据集。总体思路是向预先训练的代码语言模型提示编程问题,要求它们生成代码来实现所请求的功能。这些问题应该得到明确的定义,并附有测试套件和规范的解决方案,以便可以有效地验证模型的生成。当代码 LM 出错时,我们会收集其错误生成以及测试套件报告的相应执行反馈。然后我们相应地构建数据样本,这些样本可以用来教导代码语言模型通过参考执行反馈和伴随编程挑战的规范解决方案来纠正自己的错误。
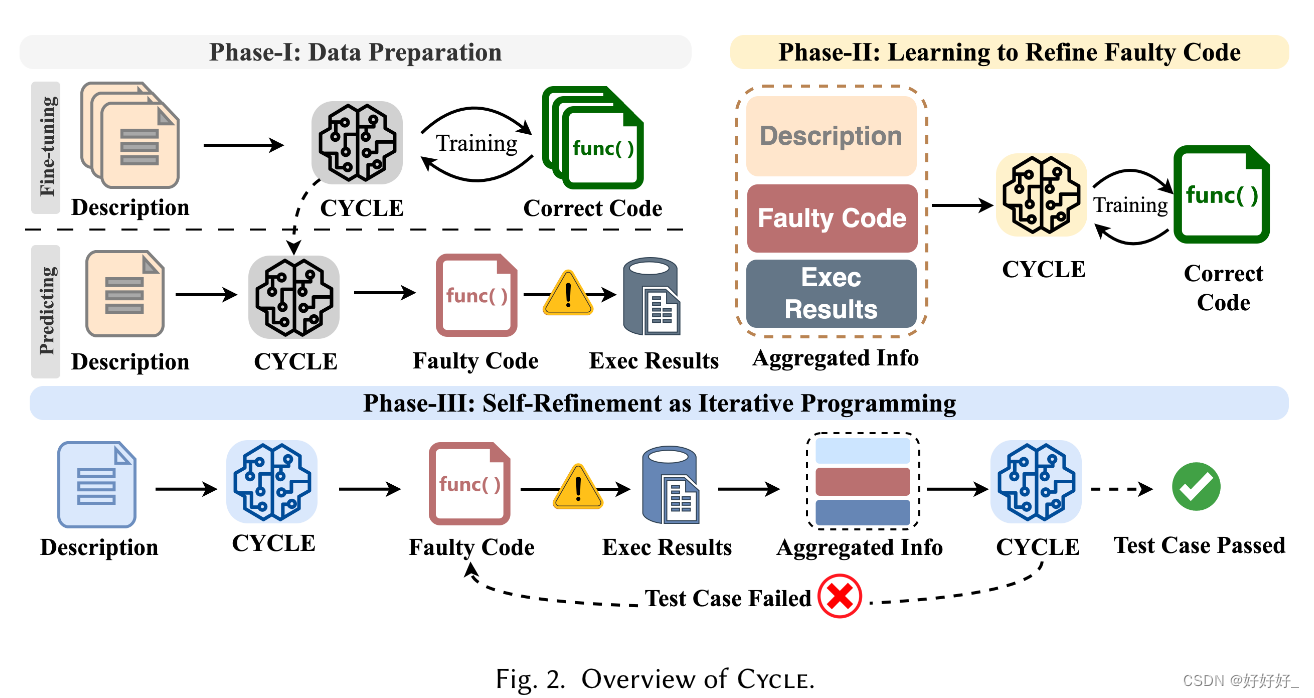
使用正确的代码微调代码 LM:代码 LM 使用多达数万亿个代码标记进行预训练,但预训练数据中继承的噪声可能会触发意外的预测 [Li 等人,2017]。 2022] 甚至是易受攻击的代码 [He and Vechev 2023]。我们在构建自我优化样本时应该避免这些恶意行为。意外的预测可能会揭示随机错误,并且在执行后无法获得有意义的反馈。并且,当易受攻击的代码生成时,可能会给执行系统带来安全威胁。因此,我们建议首先在正确的代码上微调预训练的代码语言模型,以最大限度地减少模型的恶意行为。具体来说,我们收集了大量的编程挑战,并附有规范的解决方案,并且我们对预先训练的代码 LM 进行微调,以根据问题描述来预测这些保证正确的程序。
提示codeLM 提炼出弱点 :通过对规范解决方案的微调,我们期望模型做出与正确代码相差不远的错误预测。我们通过问题描述提示微调模型,然后使用随附的测试套件执行其预测。带有错误消息的执行结果暴露了模型在代码生成方面的优点和缺点,这些结果被收集并保存为资源以构建训练样本以学习细化。
第二阶段:学习优化错误生成:利用第一阶段准备的数据,我们构建了训练样本,以基于三种类型的信息来进行代码优化学习。具体来说,我们使用我们提出的模板聚合问题描述、代码 LM 生成的错误代码以及相应的执行结果,以制定模型输入,使模型能够同时共同处理综合信息。然后我们使用随附的规范解作为模型预测的目标。与第一阶段的微调不同,第一阶段的微调仅教会模型实现自然语言描述的功能,此阶段的代码优化训练将提供模型自身的错误和执行反馈以及问题描述,这迫使模型既要推理其过去的生成与问题描述之间的不一致,又要学会理解执行结果中的隐含指导。我们精心设计了我们的训练策略,以有效且高效地学习代码优化。
第三阶段:作为迭代编程的自我完善:在了解了第二阶段的代码优化之后,我们部署模型根据问题描述自动生成代码,并类似于人类开发人员的迭代编程实践,迭代优化代码以实现所需的功能。当问题描述被输入到模型中时,模型将首先生成最佳的代码,并且生成将自动与测试套件一起执行。如果检测到失败的测试用例,我们的框架将使用第二阶段提出的模板自动聚合描述、错误代码和执行反馈。最后,聚合的信息将再次输入到模型中进行自我完善。
