课程地址:新版Java面试专题视频教程,java八股文面试全套真题+深度详解(含大厂高频面试真题)_哔哩哔哩_bilibili
课程名称:新版Java面试专题视频教程,java八股文面试全套真题+深度详解(含大厂高频面试真题)
一、面试准备
技术栈细化;
二、Redis篇
Redis的面试占很大篇幅,很重要。
 1. 布隆过滤器:
1. 布隆过滤器:
1. 自己写
- 布隆过滤器_百度百科 (这里有自己写的java代码实现布隆过滤器)
2. Google 开发著名的 Guava 库(单机、内存)
- 【项目实践03】【布隆过滤器】-CSDN博客
- https://juejin.cn/post/6844904007790673933?searchId=202404272300043574EFFB0E7CD94BEB09
- 布隆过滤器介绍及实战应用(防止缓存穿透)_布隆过滤器实战-CSDN博客
3. Redisson实现(适用分布式)
2. 缓存击穿概念&解决方案
常见的解决方案有两种:
互斥锁:给重建缓存逻辑加锁,避免多线程同时指向
逻辑过期:热点key不要设置过期时间,在活动结束后手动删除。

缓存击穿实现代码:
3. 双写一致




总结:
- 第一种方案:更新数据之后删除缓存,并为缓存设置过期时间。(延迟双删也有不一致风险,反而增加了业务复杂性:黑马微服务课程2-CSDN博客);
- 第二种方案:采用Redisson提供的读写锁,强一致,性能低,只有要求强一致的场景采用;
- 第三种方案:最终一致方案,使用MQ中间件。
- 第四种方案:canal中间件,最终一致方案。
4. 持久化
1)RDB的执行原理?
bgsave开始时会fork主进程得到子进程,子进程共享主进程的内存数据。完成fork后读取内存数据并写入 RDB 文件。 fork采用的是copy-on-write技术: 当主进程执行读操作时,访问共享内存; 当主进程执行写操作时,则会拷贝一份数据,执行写操作。
2)AOF vs RDB
RDB全称Redis Database Backup file(Redis数据备份文件),也被叫做Redis数据快照。简单来说就是把内存中的所有数据都记录到磁盘中。当Redis实例故障重启后,从磁盘读取快照文件,恢复数据。
AOF全称为Append Only File(追加文件)。Redis处理的每一个写命令都会记录在AOF文件,可以看做是命令日志文件。
AOF默认是关闭的。AOF的命令记录的频率也可以通过redis.conf文件来配。
因为是记录命令,AOF文件会比RDB文件大的多,通过执行bgrewriteaof命令,可以让AOF文件执行重写功能,进行文件压缩。Redis也会在触发阈值时自动去重写AOF文件。阈值也可以在redis.conf中配置:


5. 数据过期策略
假如redis的key过期之后,会立即删除吗?
- 惰性删除:访问key的时候判断是否过期,如果过期,则删除;
- 定期删除:定期检查一定量的key是否过期( SLOW模式+ FAST模式)
- Redis的过期删除策略:惰性删除 + 定期删除两种策略进行配合使用
6. 数据淘汰策略
假如缓存过多,内存是有限的,内存被占满了怎么办?
- Redis提供了8种不同的数据淘汰策略,默认是noeviction不删除任何数据,内存不足直接报错
- LRU:最少最近使用。用当前时间减去最后一次访问时间,这个值越大则淘汰优先级越高
- LFU:最少频率使用。会统计每个key的访问频率,值越小淘汰优先级越高
- 平时开发过程中用的比较多的就是allkeys-lru(结合自己的业务场景)
数据淘汰策略-使用建议
- 优先使用 allkeys-lru 策略。充分利用 LRU 算法的优势,把最近最常访问的数据留在缓存中。如果业务有明显的冷热数据区分,建议使用。
- 如果业务中数据访问频率差别不大,没有明显冷热数据区分,建议使用 allkeys-random,随机选择淘汰。
- 如果业务中有置顶的需求,可以使用 volatile-lru 策略,同时置顶数据不设置过期时间,这些数据就一直不被删除,会淘汰其他设置过期时间的数据。
- 如果业务中有短时高频访问的数据,可以使用 allkeys-lfu 或 volatile-lfu 策略。
关于数据淘汰策略其他的面试问题
1)数据库有1000万数据 ,Redis只能缓存20w数据, 如何保证Redis中的数据都是热点数据 ?
- 使用allkeys-lru(挑选最近最少使用的数据淘汰)淘汰策略,留下来的都是经常访问的热点数据。
2)Redis的内存用完了会发生什么?
- 主要看数据淘汰策略是什么?如果是默认的配置( noeviction ),会直接报错。
7. 分布式锁
redis分布式锁,是如何实现的?
需要结合项目中的业务进行回答,通常情况下,分布式锁使用的场景: 集群情况下的定时任务、抢单、幂等性场景。
1)抢券:加synchronized可以吗?
如果是单体项目,并且只启动了一台服务,synchronized锁是没问题的。但如果集群部署,也就是将同一份代码部署在多台服务器上,synchronized就不行了。synchronized属于本地锁,JVM锁,只能解决同一JVM下线程的互斥,无法解决多个JVM下线程的互斥,所以在集群下,就不能使用本地锁了,只能使用外部锁解决(分布式锁)。
2)Redis分布式锁setnx
- 死锁问题 -> 设置失效时间;
- 锁的失效时长不好控制 -> 自动续期(看门狗线程);
- 释放别人的锁 -> 设置锁key对应的UUID的value值;
3)Redisson分布式锁
redisson实现的分布式锁-执行流程
- 每隔releaseTime时间做一次续期(releaseTime表示锁的过期时间,默认10秒);
- 其他线程非阻塞方式获取锁(while循环,不断尝试获取锁,有一定阈值);
- 加锁、设置过期时间都是基于lua脚本完成。

redisson实现的分布式锁:
- 可重入;(可以重入,多个锁重入需要判断是否是当前线程,在redis中进行存储的时候使用的hash结构,来存储线程信息和重入的次数);
- 主从不一致(解决方案是RedLock红锁,但实现复杂、性能差,实际很少用,还是使用Redisson,因为Master宕机导致主从不一致概率低);
- redis本身就是支持高可用的,做到强一致性,就非常影响性能。所以如果有强一致性要求高的业务,建议使用zookeeper实现的分布式锁。
8. Redis集群
1)Redis集群有哪些方案?★★★
- 主从复制
- 哨兵模式
- 分片集群
2)主从集群
问题一:redis主从数据同步的流程是什么?
单节点Redis的并发能力是有上限的,要进一步提高Redis的并发能力,就需要搭建主从集群,实现读写分离。 一般都是一主多从,主节点负责写数据,从节点负责读数据。
全量同步:
- 从节点请求主节点同步数据(replication id、 offset )
- 主节点判断是否是第一次请求,是第一次就与从节点同步版本信息(replication id和offset)
- 主节点执行bgsave,生成rdb文件后,发送给从节点去执行
- 在rdb生成执行期间,主节点会以命令的方式记录到缓冲区(一个日志文件)
- 把生成之后的命令日志文件发送给从节点进行同步
增量同步:
- 从节点请求主节点同步数据,主节点判断不是第一次请求,不是第一次就获取从节点的offset值
- 主节点从命令日志中获取offset值之后的数据,发送给从节点进行数据同步
3)哨兵模式

Redis集群哨兵模式也会产生脑裂的问题,导致数据丢失。
问题一:Redis集群脑裂,该怎么解决呢?
集群脑裂是由于主节点和从节点和sentinel处于不同的网络分区,使得sentinel没有能够心跳感知到主节点,所以通过选举的方式提升了一个从节点为主,这样就存在了两个master,就像大脑分裂了一样,这样会导致客户端还在老的主节点那里写入数据,新节点无法同步数据,当网络恢复后,sentinel会将老的主节点降为从节点,这时再从新master同步数据,就会导致数据丢失
解决:我们可以修改redis的配置,可以设置最少的从节点数量以及缩短主从数据同步的延迟时间,达不到要求就拒绝请求,就可以避免大量的数据丢失。
redis中有两个配置参数:
- min-replicas-to-write 1 表示最少的salve节点为1个
- min-replicas-max-lag 5 表示数据复制和同步的延迟不能超过5秒
问题二:怎么保证redis的高并发高可用?
首先可以搭建主从集群,再加上使用redis中的哨兵模式,哨兵模式可以实现主从集群的自动故障恢复,里面就包含了对主从服务的监控、自动故障恢复、通知;如果master故障,Sentinel会将一个slave提升为master。当故障实例恢复后也以新的master为主;同时Sentinel也充当Redis客户端的服务发现来源,当集群发生故障转移时,会将最新信息推送给Redis的客户端,所以一般项目都会采用哨兵的模式来保证redis的高并发高可用。
问题三:你们使用redis是单点还是集群,哪种集群?
我们当时使用的是主从(1主1从)加哨兵。一般单节点不超过10G内存,如果Redis内存不足则可以给不同服务分配独立的Redis主从节点。尽量不做分片集群。因为集群维护起来比较麻烦,并且集群之间的心跳检测和数据通信会消耗大量的网络带宽,也没有办法使用lua脚本和事务。
4)分片集群
1. 分片集群结构
主从和哨兵可以解决高可用、高并发读的问题。但是依然有两个问题没有解决:
- 海量数据存储问题
- 高并发写的问题
使用分片集群可以解决上述问题,分片集群特征:
- 集群中有多个master,每个master保存不同数据
- 每个master都可以有多个slave节点
- master之间通过ping监测彼此健康状态
- 客户端请求可以访问集群任意节点,最终都会被转发到正确节点
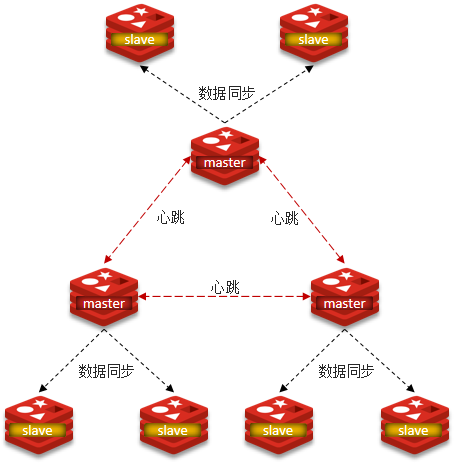

分片集群:不再需要Sentinel哨兵了,已经具有了哨兵所有的功能。
2. redis的分片集群有什么作用
- 集群中有多个master,每个master保存不同数据
- 每个master都可以有多个slave节点
- master之间通过ping监测彼此健康状态
- 客户端请求可以访问集群任意节点,最终都会被转发到正确节点
3. Redis分片集群中数据是怎么存储和读取的?
- Redis 分片集群引入了哈希槽的概念,Redis 集群有 16384 个哈希槽
- 将16384个插槽分配到不同的实例
- 读写数据:根据key的有效部分计算哈希值,对16384取余(有效部分,如果key前面有大括号,大括号的内容就是有效部分,如果没有,则以key本身做为有效部分)余数做为插槽,寻找插槽所在的实例。
9. Redis其他面试题
1)Redis是单线程的,但是为什么还那么快?
2)能解释一下I/O多路复用模型?
Redis是纯内存操作,执行速度非常快,它的性能瓶颈是网络延迟而不是执行速度, I/O多路复用模型主要就是实现了高效的网络请求。




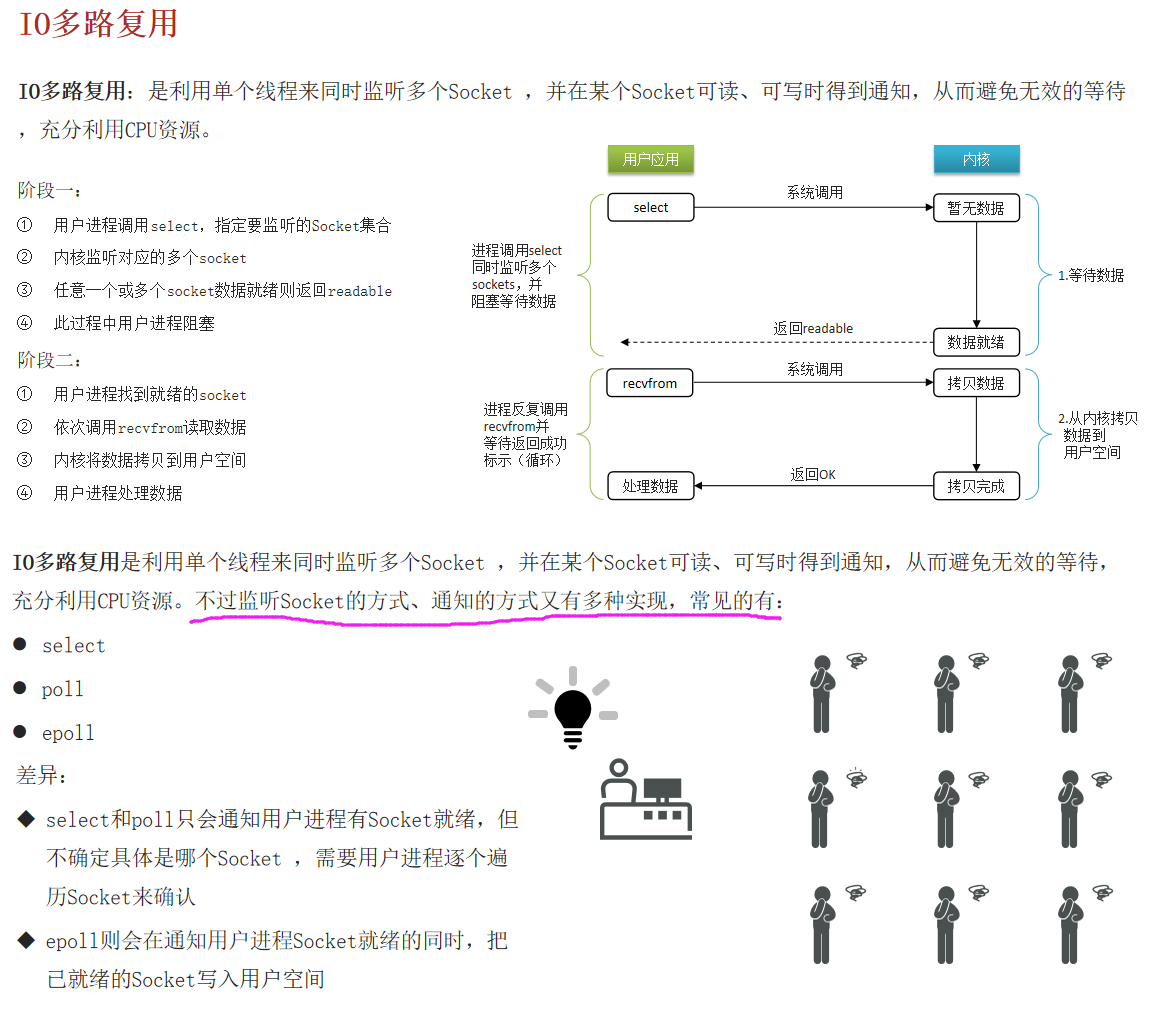

能解释一下I/O多路复用模型?
I/O多路复用
是指利用单个线程来同时监听多个Socket ,并在某个Socket可读、可写时得到通知,从而避免无效的等待,充分利用CPU资源。目前的I/O多路复用都是采用的epoll模式实现,它会在通知用户进程Socket就绪的同时,把已就绪的Socket写入用户空间,不需要挨个遍历Socket来判断是否就绪,提升了性能。
Redis网络模型
就是使用I/O多路复用结合事件的处理器来应对多个Socket请求
- 连接应答处理器
- 命令回复处理器,在Redis6.0之后,为了提升更好的性能,使用了多线程来处理回复事件;
- 命令请求处理器,在Redis6.0之后,将命令的转换使用了多线程,增加命令转换速度,在命令执行的时候,依然是单线程。
三、MySQL篇
3.1 如何定位慢查询?
方案一:使用开源工具,如:调试工具Arthas, 运维工具Prometheus和Skywalking。
方案二:开启MySQL自带慢日志功能,slow_query_log设置为1表示开启,long_query_time通常设置为2秒,具体如下图所示。开启之后,对于执行时间超过2秒的sql,就会被写入慢sql的日志文件。不过,通常用于调试阶段,生产上开启这个功能会损耗一定的性能。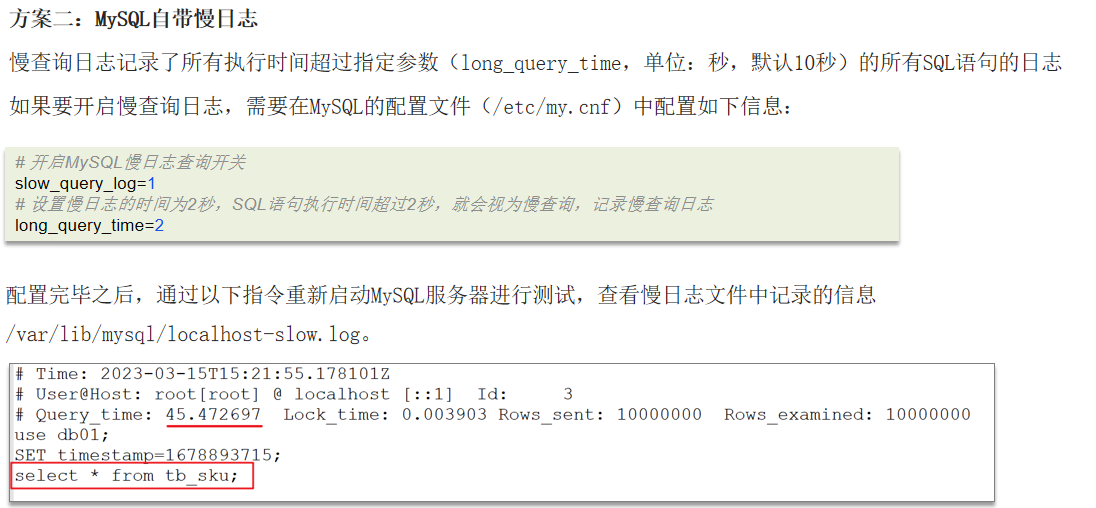
3.2 SQL语句执行很慢, 如何分析呢?
聚合查询 -> 可以新增临时表
多表查询 -> 可以试着优化sql语句的结构
表数据量过大查询 -> 可以添加索引
上面这三种,都可以SQL执行计划(找到慢的原因);须掌握possible_key、key、key_len、Extra、type这几个字段。

可以采用MySQL自带的分析工具 EXPLAIN
- 通过key和key_len检查是否命中了索引(索引本身存在是否有失效的情况)
- 通过type字段查看sql是否有进一步的优化空间,是否存在全索引扫描或全盘扫描
- 通过extra建议判断,是否出现了回表的情况,如果出现了,可以尝试添加索引或修改返回字段来修复
深度分页查询(后面分析)
3.3 MYSQL支持的存储引擎
存储引擎就是存储数据、建立索引、更新/查询数据等技术的实现方式 。存储引擎是基于表的,而不是基于库的,所以存储引擎也可被称为表类型。


3.4 索引
1)索引的底层数据结构了解过吗?
MySQL的InnoDB引擎采用的B+树的数据结构来存储索引
- 阶数更多,路径更短
- 磁盘读写代价B+树更低,非叶子节点只存储指针,叶子阶段存储数据
- B+树便于扫库和区间查询,叶子节点是一个双向链表
2)B树与B+树对比:
①:磁盘读写代价B+树更低;②:查询效率B+树更加稳定;③:B+树便于扫库和区间查询
3)什么是聚集索引,什么是非聚集索引?
- 聚簇索引(聚集索引):数据与索引放到一块,B+树的叶子节点保存了整行数据,有且只有一个
- 非聚簇索引(二级索引):数据与索引分开存储,B+树的叶子节点保存对应的主键,可以有多个

4)什么是回表查询?
先通过二级索引去找到对应的主键值,再通过主键值到聚集索引中找到整行的(或select后面的除主键以外的)数据。

5)什么叫覆盖索引?
覆盖索引是指查询使用了索引,返回的列,必须在索引中全部能够找到
- 使用id查询,直接走聚集索引查询,一次索引扫描,直接返回数据,性能高。
- 如果返回的列中没有创建索引,有可能会触发回表查询,尽量避免使用select *

6)MYSQL超大分页怎么处理 ?

7)索引创建原则有哪些?
- 针对于数据量较大,且查询比较频繁的表建立索引。
- 针对于常作为查询条件(where)、排序(order by)、分组(group by)操作的字段建立索引。
- 尽量选择区分度高的列作为索引,尽量建立唯一索引,区分度越高,使用索引的效率越高。
- 如果是字符串类型的字段,字段的长度较长,可以针对于字段的特点,建立前缀索引。
- 尽量使用联合索引,减少单列索引,查询时,联合索引很多时候可以覆盖索引,节省存储空间,避免回表,提高查询效率。
- 要控制索引的数量,索引并不是多多益善,索引越多,维护索引结构的代价也就越大,会影响增删改的效率。
- 如果索引列不能存储NULL值,请在创建表时使用NOT NULL约束它。当优化器知道每列是否包含NULL值时,它可以更好地确定哪个索引最有效地用于查询。
8)什么情况下索引会失效 ?
- 违反最左前缀法则;
- 范围查询右边的列,不能使用索引;(不包含自身)
- 不要在索引列上进行运算操作, 索引将失效;
- 字符串不加单引号,造成索引失效;(类型转换)
- 以%开头的Like模糊查询,索引失效。
3.5 SQL优化经验

- 表的设计优化(参考阿里开发手册《嵩山版》)
①设置合适的数值(tinyint int bigint),要根据实际情况选择
②设置合适的字符串类型(char和varchar)char定长效率高,varchar可变长度,效率稍低
- SQL语句优化
①SELECT语句务必指明字段名称(避免直接使用select * )
②SQL语句要避免造成索引失效的写法
③尽量用union all代替union,union会多一次过滤,效率低
④避免在where子句中对字段进行表达式操作
⑤Join优化 能用innerjoin 就不用left join right join,如必须使用 一定要以小表为驱动,
内连接会对两个表进行优化,优先把小表放到外边,把大表放到里边。left join 或 right join,不会重新调整顺序
- 主从复制、读写分离
①如果数据库的使用场景读的操作比较多的时候,为了避免写的操作所造成的性能影响 可以采用读写分离的架构。 读写分离解决的是,数据库的写入,影响了查询的效率。

3.6 事务相关★★★
- 事务特性(ACID);
- 隔离级别;(MySQL有四种隔离级别)
- MVCC
并发事务带来哪些问题?怎么解决这些问题呢?MySQL的默认隔离级别是?
- 脏读 -> 读已提交来解决;
- 不可重复读 -> 可重复读来解决;
- 幻读 -> 串行化来解决。
- MySQL默认的隔离级别是可重复读。

1)undo log和redo log的区别


总结:undo log和redo log的区别
- redo log: 记录的是数据页的物理变化,服务宕机可用来同步数据
- undo log :记录的是逻辑日志,当事务回滚时,通过逆操作恢复原来的数据
- redo log保证了事务的持久性,undo log保证了事务的原子性和一致性
2)事务中的隔离性是如何保证的呢?
- 锁:排他锁(如一个事务获取了一个数据行的排他锁,其他事务就不能再获取该行的其他锁。平时使用的update、delete、insert自动会获取排他锁。)
- mvcc : 多版本并发控制
3)解释一下MVCC(讲的非常好)★★★★★
MVCC,全称 Multi-Version Concurrency Control,多版本并发控制。指维护一个数据的多个版本,使得读写操作没有冲突。
MVCC的具体实现,主要依赖于数据库记录中的隐式字段、undo log日志、readView。


MVCC总结:


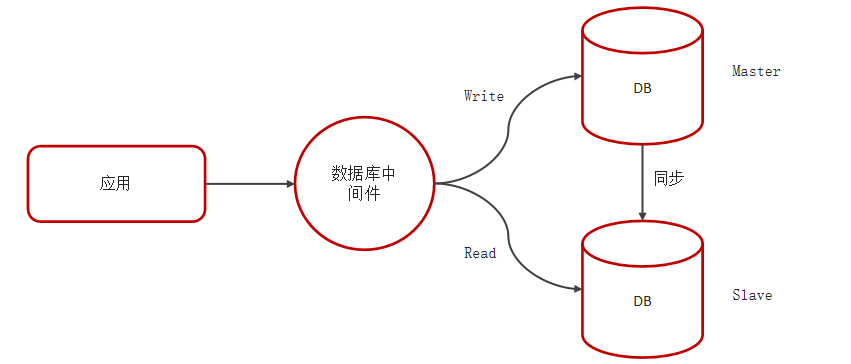
3.7 MySQL主从同步原理


3.8 项目用过分库分表吗?
1)什么时候需要分库分表

2)四种拆分策略
垂直拆分(垂直分库、垂直分表)
水平拆分(水平分库、水平分表)

水平分库:将一个库的数据拆分到多个库中;
水平分表:将一个表的数据拆分到多个库(或者同一个库)的表中。

3)分库分表中间件
分库之后会面临一些问题:
- 分布式事务一致性问题
- 跨节点关联查询
- 跨节点分页、排序函数
- 主键避重
于是,引入了分库分表中间件,可以很好的解决这些问题。常用的有:
- sharding-sphere
- mycat


四、框架篇
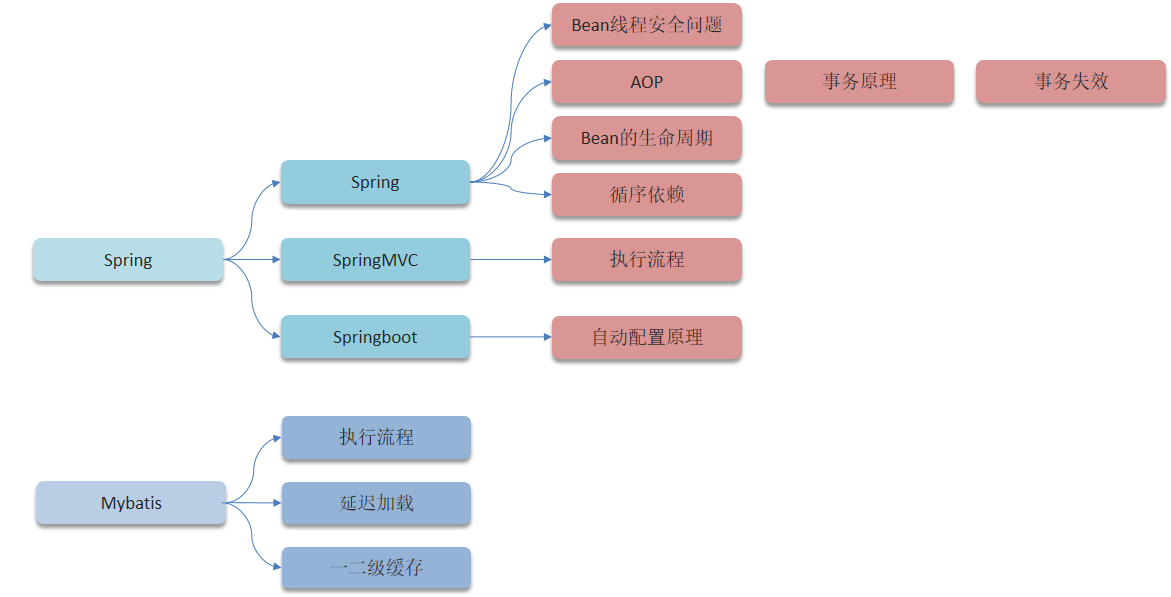
4.1 Spring部分
1. Spring框架中的单例bean是线程安全的吗?
不是线程安全的
Spring框架中有一个@Scope注解,默认的值就是singleton,单例的。
因为一般在spring的bean的中都是注入无状态的对象,没有线程安全问题,如果在bean中定义了可修改的成员变量,是要考虑线程安全问题的,可以使用多例或者加锁来解决。

2. 什么是AOP,你们项目中有没有使用到AOP?
AOP称为面向切面编程,用于将那些与业务无关,但却对多个对象产生影响的公共行为和逻辑,抽取并封装为一个可重用的模块,这个模块被命名为“切面”(Aspect),减少系统中的重复代码,降低了模块间的耦合度,同时提高了系统的可维护性。
常见的AOP使用场景:
- 记录操作日志
- 缓存处理
- Spring中内置的事务处理
核心是:使用aop中的环绕通知+切点表达式(找到要记录日志的方法),通过环绕通知的参数获取请求方法的参数(类、方法、注解、请求方式等),获取到这些参数以后,保存到数据库。
3. Spring中的事务是如何实现的?
Spring支持编程式事务管理和声明式事务管理两种方式。
- 编程式事务控制:需使用TransactionTemplate来进行实现,对业务代码有侵入性,项目中很少使用
- 声明式事务管理:声明式事务管理建立在AOP之上的。其本质是通过AOP功能,对方法前后进行拦截,将事务处理的功能编织到拦截的方法中,也就是在目标方法开始之前加入一个事务,在执行完目标方法之后根据执行情况提交或者回滚事务。
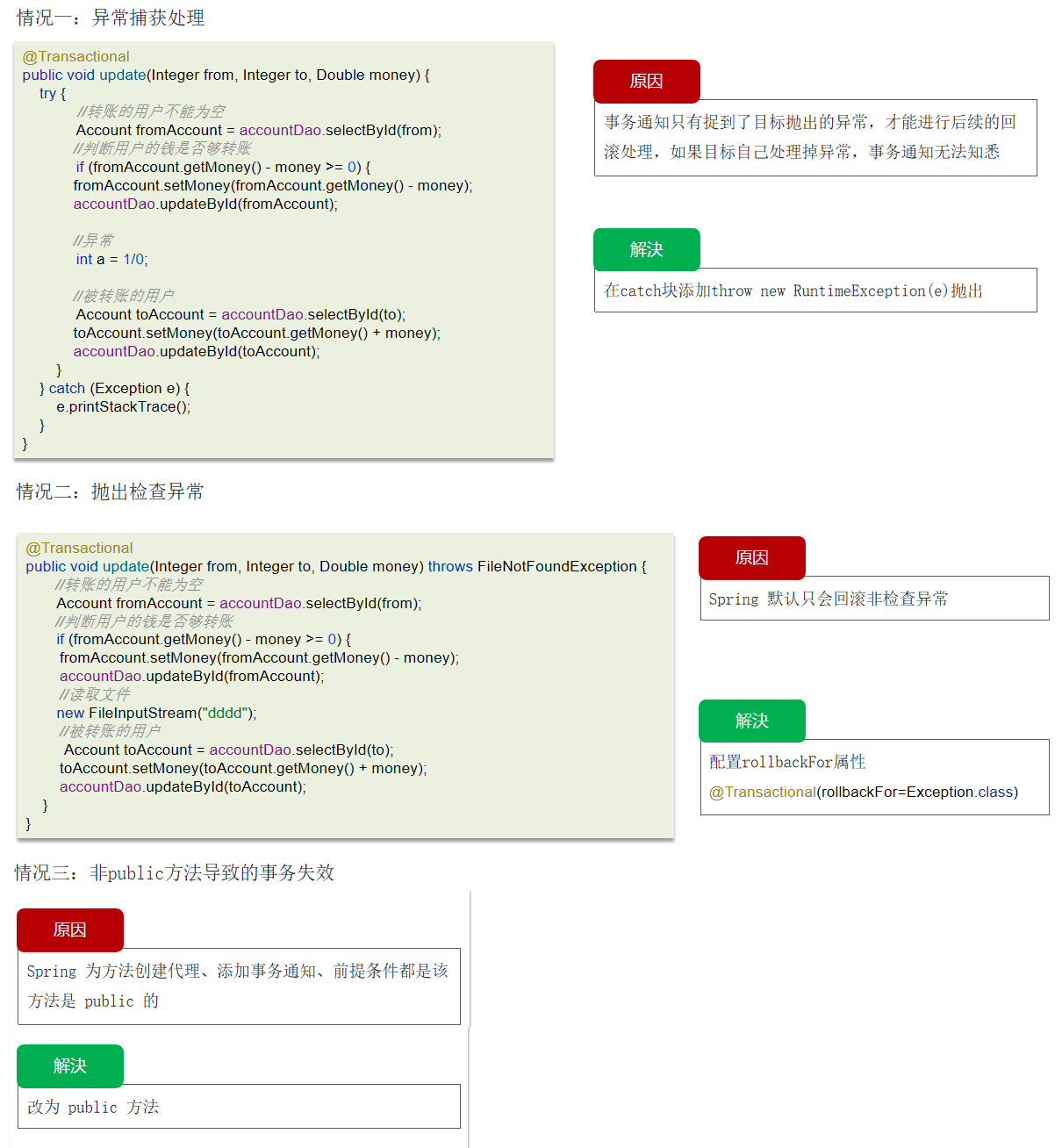
4. Spring中事务失效的场景有哪些?
失效场景非常多,这里列举三个。
5. Spring的bean的生命周期?
搞懂Spring容器是如何管理和创建bean实例,方便调试和解决问题。



6. Spring中的循环引用
- 循环依赖:循环依赖其实就是循环引用,也就是两个或两个以上的bean互相持有对方,最终形成闭环。比如A依赖于B,B依赖于A
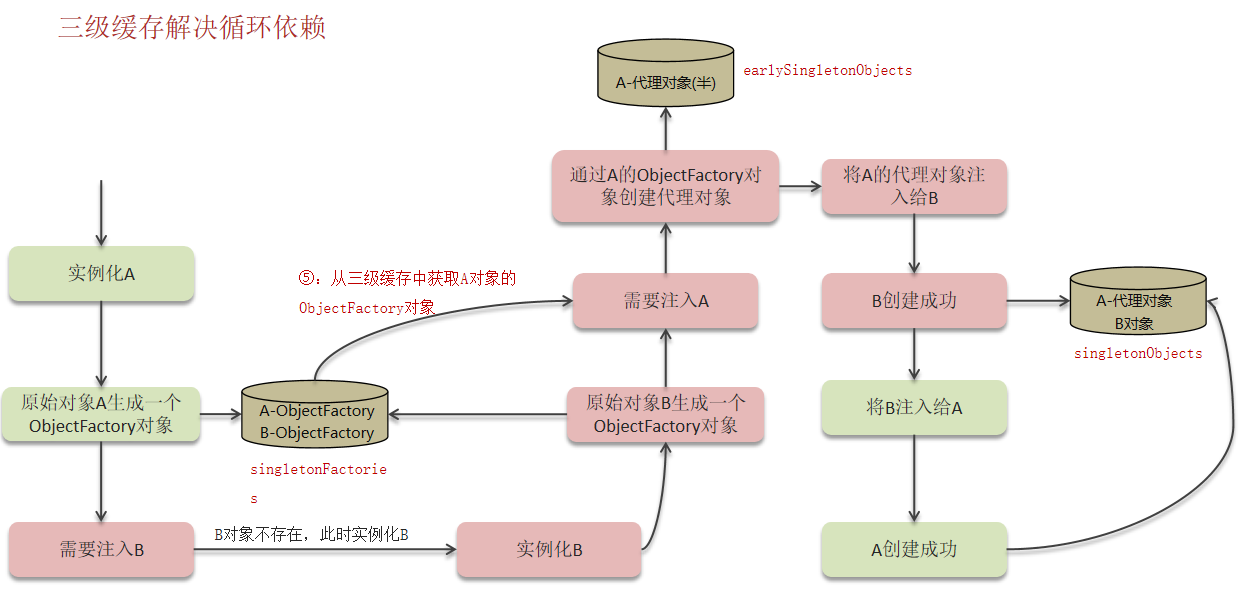
- 循环依赖在spring中是允许存在,spring框架依据三级缓存已经解决了大部分的循环依赖(三级缓存可以解决set方法注入的循环依赖)(三级缓存无法解决构造函数注入的循环依赖,需要手动解决)
①一级缓存:单例池,缓存已经经历了完整的生命周期,已经初始化完成的bean对象
②二级缓存:缓存早期的bean对象(生命周期还没走完)
③三级缓存:缓存的是ObjectFactory,表示对象工厂,用来创建某个对象的(“某个对象”指代理对象或者原始对象都行,下面流程图中,“需要注入A”那一步,会从三级缓存中获取A对象的工厂对象,根据需要去创建代理对象或者原始对象)
问题一:为什么还需要三级缓存?一级和二级不够吗?
答:一级缓存和二级缓存可以解决普通对象引起的循环依赖,如果A是代理对象的话,就得依赖三级缓存了。
问题二:二级缓存的作用?
答:对象工厂创建的对象都存储在二级缓存中,上面流程图中的“B创建成功”前一步需要将A的代理对象(或原始对象的半成品)注入给B,这时可以直接从二级缓存中获取;“A创建成功”的前一步也是同样的道理。对象都是单例的。如果多次调用对象工厂的话,可能产生的是多例对象,处理起来会更麻烦。对象工厂创建的对象都存储在二级缓存中,使用的时候直接拿出来就行,不用再次去生成对象,这也是二级缓存的核心作用。
问题三:构造方法出现了循环依赖怎么解决?
原因:由于bean的生命周期中构造函数是第一个执行的,spring框架并不能解决构造函数的的依赖注入。
答:在其中一个Bean的构造器的形参上加@Lazy懒加载注解即可(什么时候需要对象再进行bean对象的创建):


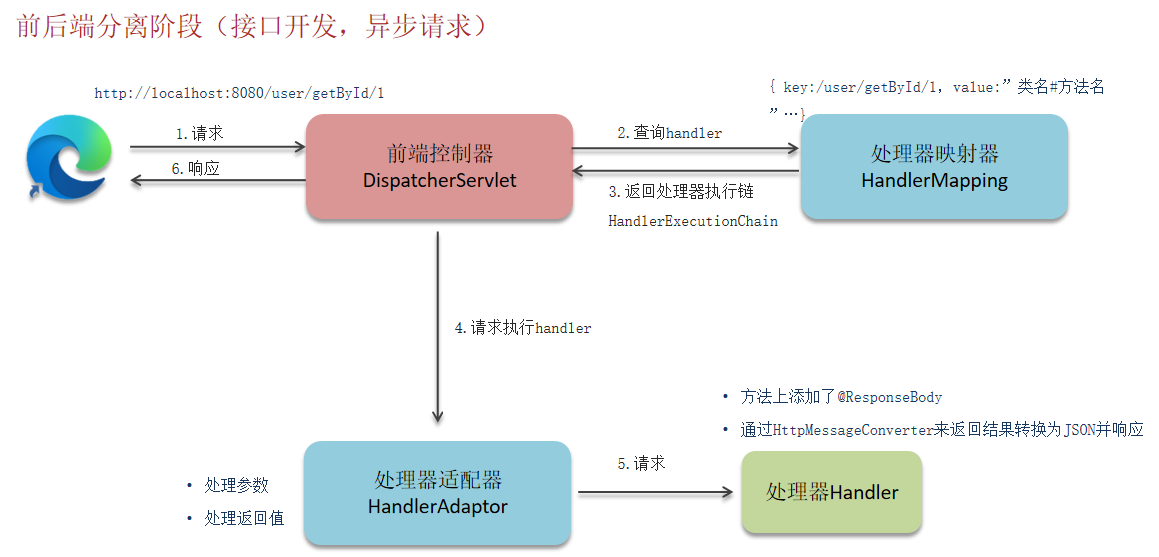
4.2 SpringMVC
SpringMVC的执行流程?
问:SpringMVC中重要的组件有哪些?
就是上图中4个。
- 前端控制器:调度中心,接收所有的请求,它处理完之后交给处理器映射器;
- 处理器映射器:通过URL找到对象的方法;
- 处理器适配器:执行handler;处理handler中的参数和返回值;
- 视图解析器:将处理器适配器返回的逻辑视图(ModelAndView)解析为真正的视图,再渲染给页面。


当前的开发都是接口开发,并没有ModelAndView,返回的都是JSON,那怎么办呢?