文字识别步骤参考:https://github.com/PaddlePaddle/PaddleOCR/blob/main/doc/doc_ch/recognition.md
微调步骤参考:https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.7.1/doc/doc_ch/finetune.md
训练必要性
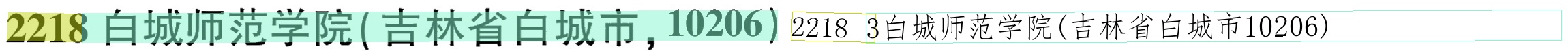
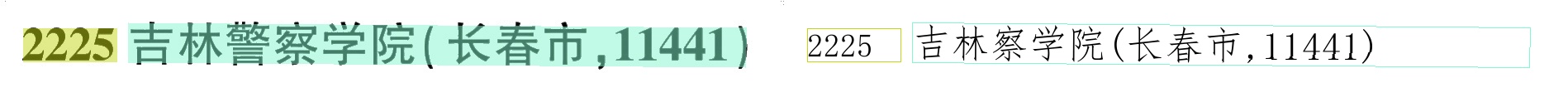
原始模型标点符号和括号容易识别不到
数据准备
参考:https://github.com/PaddlePaddle/PaddleOCR/blob/main/doc/doc_ch/dataset/ocr_datasets.md
通用数据 用于训练以文本文件存储的数据集(SimpleDataSet);
一张图片 一行文本
格式类似:

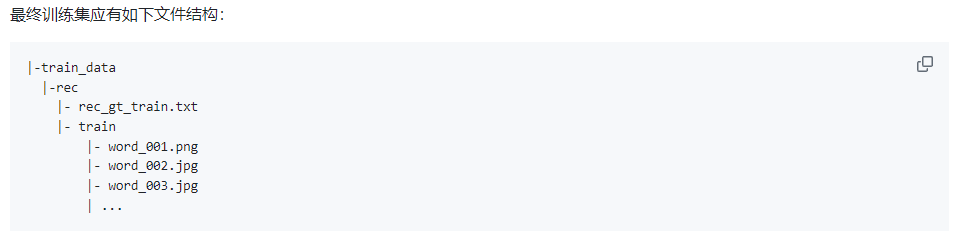
注意:图像文件名写xxx.jpg即可,文件夹名可以在配置文件中指定
数据源:垂直领域的pdf,经过剪裁生成了10万张图片(文本内容没有去重,为了保证一些词出现的频率不变)
开始训练
训练v4的模型,所以选择配置文件:ch_PP-OCRv4_rec.yml ,需要做如下更改
更改学习率为[1e-4, 2e-5]左右,
更改图片文件夹路径
更改batch_size大小(训练报错时,适当调节大小,)
下载pretrain model,使用v4预训练模型
https://paddleocr.bj.bcebos.com/PP-OCRv4/chinese/ch_PP-OCRv4_rec_train.tar
注意:v4预训练模型没有best,只有student
正常启动训练
python3 tools/train.py -c configs/rec/PP-OCRv4/ch_PP-OCRv4_rec.yml -o Global.pretrained_model=./pretrain_models/ch_PP-OCRv4_rec_train/student Global.save_model_dir=./output/rec_ppocr_v4
注意使用ch_PP-OCRv4_rec_distill.yml配置文件训练,报错KeyError: ‘NRTRLabelDecode’,官方暂时没有解决。
python3 tools/train.py -c configs/rec/PP-OCRv4/ch_PP-OCRv4_rec_distill.yml -o Global.pretrained_model=./pretrain_models/ch_PP-OCRv4_rec_train/student
导出模型
python3 tools/export_model.py -c configs/rec/PP-OCRv4/ch_PP-OCRv4_rec_jilin.yml -o Global.pretrained_model=./output/rec_ppocr_v4/best_accuracy Global.save_inference_dir=./inference/PP-OCRv4_rec_jilin/
python3 tools/infer/predict_rec.py --rec_model_dir="./inference/PP-OCRv4_rec/" --image_dir="./train_data/rec/jilin_001_0_27_5.jpg"
推理
python3 tools/infer_rec.py -c configs/rec/PP-OCRv4/ch_PP-OCRv4_rec.yml -o Global.pretrained_model=./output/rec_ppocr_v4/best_accuracy Global.infer_img=./train_data/rec/jilin_001_0_27_5.jpg
实践:
参考:https://blog.csdn.net/qq_52852432/article/details/131817619
一共训练了20轮,第五轮训练测试集达到最大精度,85%,之后精度逐渐下降

预测
图片:

训练的模型:
(‘2218白城师范学院(吉林省白城市,10206)’, 0.9582517743110657)
(‘2225吉林警察学院(长春市,11441)’, 0.9862592816352844)
原始v4模型:
(2218白城师范学院(吉林省白城市,10206)', 0.9726919531822205)
(‘2225吉林警察学院(长春市,11441)’, 0.9829413294792175)
总结
可以看到,训练后模型识别括号基本统一成英文了。其实光是识别,起始v4效果已经很好了,原来检测的效果不太行,会拉低识别正确率
改进:微调文字检测模型,待完成后补充
其他需要注意的
实践时,使用了预训练模型,但一开始模型准确率acc一直为0,因为数据准备错误了,图片包含了多行文字,后来修正了图片,acc飞速提高。
其他版本
由于我数据集存在很多文本, 更改max_length,从25改到50,并且image.shape的宽从320改成640,batch_size改成了32
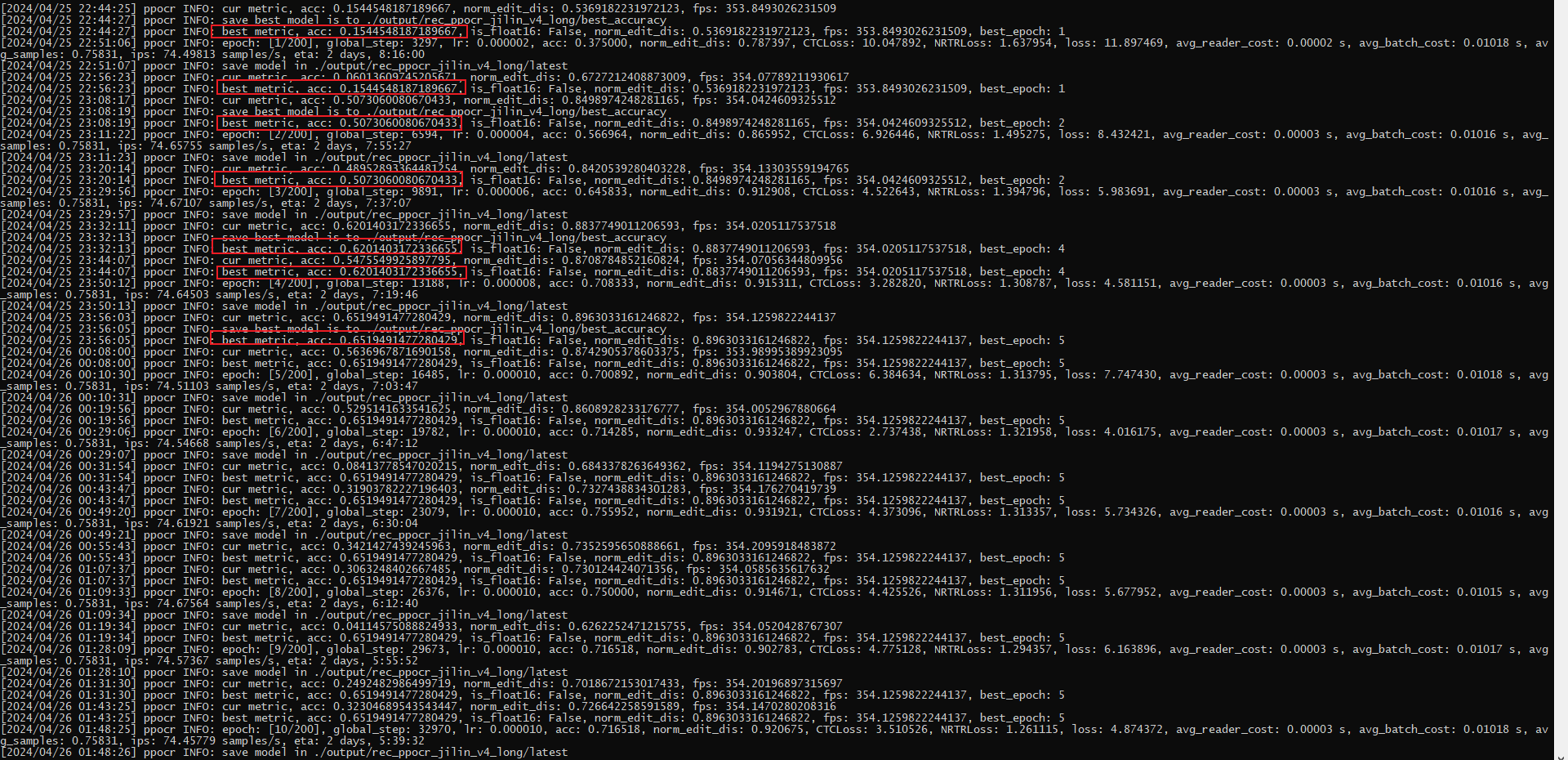
第5个epoch达到最大的acc 65%,效果不够好
训练模型可能有的疑问
参考:添加链接描述
如何识别文字比较长的文本

合成数据与真实数据比例

如何生成数据

文本识别训练时宽高比大于 10 或者文本长度大于 25 的图像会直接丢弃吗?会
参考:https://github.com/PaddlePaddle/PaddleOCR/issues/5017如果大部分图像都超过了25个字符,建议训练时根据实际情况修改:max_text_length,并将input_size设置为宽高比更大的比例
参考:https://github.com/PaddlePaddle/PaddleOCR/issues/7500
参考:https://aistudio.baidu.com/projectdetail/4484441
1.7 简单的对于精度要求不高的OCR任务,数据集需要准备多少张呢?
A:(1)训练数据的数量和需要解决问题的复杂度有关系。难度越大,精度要求越高,则数据集需求越大,而且一般情况实际中的训练数据越多效果越好。
(2)对于精度要求不高的场景,检测任务和识别任务需要的数据量是不一样的。对于检测任务,500张图像可以保证基本的检测效果。对于识别任务,需要保证识别字典中每个字符出现在不同场景的行文本图像数目需要大于200张(举例,如果有字典中有5个字,每个字都需要出现在200张图片以上,那么最少要求的图像数量应该在200-1000张之间),这样可以保证基本的识别效果。
1.8 当训练数据量少时,如何获取更多的数据?
A:当训练数据量少时,可以尝试以下三种方式获取更多的数据:(1)人工采集更多的训练数据,最直接也是最有效的方式。(2)基于PIL和opencv基本图像处理或者变换。例如PIL中ImageFont, Image, ImageDraw三个模块将文字写到背景中,opencv的旋转仿射变换,高斯滤波等。(3)利用数据生成算法合成数据,例如pix2pix等算法。
1.9 如何更换文本检测/识别的backbone?
A:无论是文字检测,还是文字识别,骨干网络的选择是预测效果和预测效率的权衡。一般,选择更大规模的骨干网络,例如ResNet101_vd,则检测或识别更准确,但预测耗时相应也会增加。而选择更小规模的骨干网络,例如MobileNetV3_small_x0_35,则预测更快,但检测或识别的准确率会大打折扣。幸运的是不同骨干网络的检测或识别效果与在ImageNet数据集图像1000分类任务效果正相关。飞桨图像分类套件PaddleClas汇总了ResNet_vd、Res2Net、HRNet、MobileNetV3、GhostNet等23种系列的分类网络结构,在上述图像分类任务的top1识别准确率,GPU(V100和T4)和CPU(骁龙855)的预测耗时以及相应的117个预训练模型下载地址。
(1)文字检测骨干网络的替换,主要是确定类似与ResNet的4个stages,以方便集成后续的类似FPN的检测头。此外,对于文字检测问题,使用ImageNet训练的分类预训练模型,可以加速收敛和效果提升。
(2)文字识别的骨干网络的替换,需要注意网络宽高stride的下降位置。由于文本识别一般宽高比例很大,因此高度下降频率少一些,宽度下降频率多一些。可以参考PaddleOCR中MobileNetV3骨干网络的改动。
V4使用的高精度中文场景文本识别模型SVTR详解
参考:https://aistudio.baidu.com/projectdetail/4263032
参考:https://github.com/PaddlePaddle/PaddleOCR/blob/main/applications/%E9%AB%98%E7%B2%BE%E5%BA%A6%E4%B8%AD%E6%96%87%E8%AF%86%E5%88%AB%E6%A8%A1%E5%9E%8B.md,但一直没下载成功SVTR中文模型文件