YOLO-World: Real-Time Open-Vocabulary Object Detection
论文链接:http://arxiv.org/abs/2401.17270
代码链接:https://github.com/AILab-CVC/YOLO-World

1、摘要
为解决YOLO在开放场景中的应用这一局限,文中提出YOLO-World,这是一种创新方法,通过视觉-语言建模和在大型数据集上的预训练,增强了YOLO的开放词汇检测能力。特别地,作者设计了一个新的可重参数化视觉-语言路径聚合网络(RepVL-PAN)和区域-文本对比损失,以促进视觉和语言信息的交互。所提方法在零样本情况下以高效率出色地检测各种物体。在具有挑战性的LVIS数据集上,YOLO-World在V100上实现了35.4 AP的精度,速度达到52.0 FPS,这在准确性和速度上都优于许多最先进的方法。此外,微调后的YOLO-World在多个下游任务上表现出色,包括目标检测和开放词汇实例分割。
YOLO-World遵循标准的YOLO架构[20],并利用预训练的CLIP[39]文本编码器对输入文本进行编码。作者进一步提出可参数化视觉-语言路径聚合网络(RepVL-PAN),以连接文本特征和图像特征,从而提升视觉-语义表示。在推理阶段,可以移除文本编码器,将文本嵌入重参数化为RepVL-PAN的权重,以实现高效部署。文中还研究了YOLO检测器的开放词汇预训练方案,通过在大型数据集上进行区域-文本对比学习,将检测数据、定位数据和图像-文本数据统一为区域-文本对。预训练的YOLO-World凭借丰富的区域-文本对,展现出强大的大词汇检测能力,而且随着数据量的增加,开放词汇能力的提升更为显著。

还探索了一种提示-然后-检测(prompt-then-detect)范式,以进一步提升现实世界中开放词汇对象检测的效率。如图2所示,传统的对象检测器[16,20,23,[41][42][43]52]专注于预定义和训练过的固定词汇(闭集)检测。而先前的开放词汇检测器[24,30,56,59]通过文本编码器在线编码用户的提示,然后进行物体检测。值得注意的是,这些方法倾向于使用大型的、具有深度的模型,如Swin-L[32],来增加开放词汇的容量。相比之下,提示-然后-检测范式(图2(c))首先将用户的提示编码为一个离线词汇,且词汇可以根据不同的需求变化。然后,高效的检测器可以在运行时即时推断离线词汇,无需重新编码提示。对于实际应用,一旦训练了检测器,即YOLO-World,可以预先编码提示或类别,构建离线词汇,然后无缝地将其集成到检测器中。
2、创新点
- 引入了YOLO-World,这是一款尖端的开放词汇对象检测器,适用于实际应用,具有高效率。
- 提出了一个可重新参数化的视觉-语言PAN来连接视觉和语言特征,以及一个用于 YOLO-World 的开放词汇区域-文本对比预训练方案。
- 在大规模数据集上预训练的 YOLO-World 表现出强大的零样本性能,并在 LVIS 上以 52.0FPS 实现 35.4AP。预训练的 YOLO-World 可以很容易地适应下游任务,例如开放词汇实例分割和引用对象检测。
3、原理
Pre-training Formulation: Region-Text Pairs
传统的物体检测方法,如YOLO系列[20],是通过实例标注集 Ω = { B i , c i } i = 1 N Ω = \{B_{i}, c_{i}\}_{i=1}^{N} Ω={Bi,ci}i=1N进行训练的,其中包含边界框 { B i } \{B_{i}\} {Bi}和类别标签 { c i } \{c_{i}\} {ci}。在本论文中,我们重新定义实例标注为区域-文本对 Ω = { B i , t i } i = 1 N Ω = \{B_{i}, t_{i}\}_{i=1}^{N} Ω={Bi,ti}i=1N,其中 t i t_{i} ti是对应区域 B i B_{i} Bi的文本描述。具体来说,文本 t i t_{i} ti可以是类别名称、名词短语或对象描述。此外,YOLO-World采用图像 I I I和文本 T T T(一组名词)作为输入,输出预测的边界框集合 B k {Bk} Bk和相应的对象嵌入集合 { e k } ( e k ∈ R D ) \{e_{k}\}(e_{k} ∈ R^{D}) {ek}(ek∈RD)
Model Architecture

提出的YOLO-World的整体架构如图3所示,它由YOLO检测器、文本编码器和**可参数化视觉-语言路径聚合网络(RepVL-PAN)**组成。文本编码器将输入文本编码为文本嵌入,YOLO检测器的图像编码器则从输入图像中提取多尺度特征。RepVL-PAN通过融合图像特征和文本嵌入,增强两者的表现力,实现跨模态融合。
YOLO检测器 YOLO Detector. YOLO-World主要基于YOLOv8构建,它包含Darknet作为图像编码器,用于多尺度特征金字塔的路径聚合网络(PAN),以及用于边界框回归和对象嵌入的头部。
文本编码器 Text Encoder. 对于文本T,采用CLIP预训练的Transformer文本编码器,提取对应的文本嵌入 W = T e x t E n c o d e r ( T ) ∈ R C × D W = TextEncoder(T) ∈ R^{C \times D} W=TextEncoder(T)∈RC×D,其中 C C C是名词的数量, D D D是嵌入维度。CLIP文本编码器相比纯文本语言编码器在连接视觉对象和文本方面具有更强的视觉语义能力。当输入文本是caption或referring expression参考表达时,采用n-gram算法提取名词短语,然后输入到文本编码器。
文本对比性头部 Text Contrastive Head. 采用与先前工作类似的解耦头部,包含两个 3 × 3 3 \times 3 3×3卷积层,用于回归边界框 { b k } k = 1 K \{b_{k}\}^{K}_{k=1} {bk}k=1K和对象嵌入 { e k } k = 1 K \{e_k\}^{K}_{k=1} {ek}k=1K,其中 K K K表示对象数量。文中提出文本对比性头部,通过以下方式获取对象-文本相似度 s k , j s_{k,j} sk,j:
s k , j = α ⋅ L 2 − N o r m ( e k ) ⋅ L 2 − N o r m ( w j ) ⊤ + β , ( 1 ) s_{k,j} = \alpha \cdot L2-Norm(e_{k}) \cdot L2-Norm(w_{j})^{⊤} + \beta, \ (1) sk,j=α⋅L2−Norm(ek)⋅L2−Norm(wj)⊤+β, (1)
其中L2-Norm( ⋅ \cdot ⋅)是L2归一化, w j ∈ W w_{j} ∈ W wj∈W是第 j j j个文本嵌入。此外,添加了可学习的缩放因子 α \alpha α和偏移因子 b e t a beta beta。L2归一化和线性变换对于稳定区域-文本训练至关重要。
在线词汇训练 Training with Online Vocabulary. 在训练阶段,为每个包含4张图像的mosaic样本构建一个在线词汇T。具体来说,采样mosaic图像中涉及的所有正向名词,并从对应数据集中随机采样一些负向名词。每个mosaic样本的词汇最多包含M个名词,M默认设置为80。
离线词汇推理 Inference with Offline Vocabulary. 在推理阶段,采用离线词汇的提示-然后检测策略以提高效率。如图3所示,用户可以定义一系列自定义提示,包括caption或类别。然后,使用文本编码器对这些提示进行编码,得到离线词汇嵌入。离线词汇允许避免对每个输入进行计算,并提供调整词汇的灵活性。
Re-parameterizable Vision-Language PAN

图4显示了所提出的RepVL-PAN的结构,该结构遵循[20,29]中的top-down自上而下和bottom-up自下而上的路径,以建立具有多尺度图像特征 C 3 , C 4 , C 5 {C3,C4,C5} C3,C4,C5的特征金字塔 P 3 , P 4 , P 5 {P3,P4,P5} P3,P4,P5。此外,提出了文本引导的CSPLayer(T-CSPLayer)和Image-Pooling Attention(I-Pooling Attention)来进一步增强图像特征和文本特征之间的交互,从而改善开放词汇能力的视觉语义表示。在推理过程中,可以将离线词汇表嵌入重新参数化为卷积层或线性层的权重,以便部署。
文本引导的CSPLayer Text-guided CSPLayer. 如图4所示,CSPLayer(也称为C2f)在上采样或下采样融合后使用。文中扩展了[20]中的CSPLayer,将文本指导融入多尺度图像特征,形成文本引导的CSPLayer。具体来说,给定文本嵌入 W W W和图像特征 X l ∈ R H × W × D ( l ∈ 3 , 4 , 5 ) X_{l} ∈ R^{H \times W \times D}(l ∈ {3, 4, 5}) Xl∈RH×W×D(l∈3,4,5),在最后一个Dark瓶颈块之后采用最大sigmoid注意力,通过以下方式将文本特征融合到图像特征中:
X l ′ = X l ⋅ δ ( max j ∈ { 1.. C } ( X l W j T ) ) T , (2) X'_{l} = X_{l} \cdot \delta\left(\max_{j \in \{1..C\}}(X_{l} W^{T}_{j})\right)^{T}, \quad \text{(2)}\ Xl′=Xl⋅δ(j∈{1..C}max(XlWjT))T,(2)
其中更新后的 X l ′ X'_{l} Xl′与跨阶段特征连接作为输出。 Δ \Delta Δ表示sigmoid函数。
图像池化注意力 Image-Pooling Attention. 为了增强文本嵌入与图像感知信息,提出图像池化注意力来更新文本嵌入。不直接使用图像特征的跨注意力,而是利用多尺度特征的最大池化,得到3×3的区域,总共得到27个patch token,记为 X ∈ R 27 × D X \in \mathbb{R}^{27 \times D} X∈R27×D。然后通过以下方式更新权重:
W ′ = W + MultiHead-Attention ( W , X , X ) (3) W' = W + \text{MultiHead-Attention}(W, X, X) \quad \text{(3)} W′=W+MultiHead-Attention(W,X,X)(3)
这里,MultiHead-Attention表示多头注意力机制,它结合了文本嵌入 X X X和图像特征 X X X进行注意力计算,从而增强文本嵌入的图像相关性。
Pre-training Schemes
学习区域-文本对比损失 Learning from Region-Text Contrastive Loss.
对于mosaic样本 I I I和文本 T T T,YOLO-World输出 K K K个对象预测 { B k , s k } k = 1 K \{B_k, s_k\}^{K}_{k=1} {Bk,sk}k=1K,以及注解 Ω = { B i , t i } i = 1 N Ω=\{B_{i}, t_{i}\}^{N}_{i=1} Ω={Bi,ti}i=1N。文中遵循[20]的做法,利用任务相关的标签分配task-aligned label assignment[9]将预测与真实标签匹配,并为每个正向预测分配一个文本索引作为分类标签。基于此词汇表,构建区域-文本对比损失 L c o n L_{con} Lcon,通过对象-文本(区域-文本)相似度和对象-文本分配的交叉熵计算区域-文本对的损失。此外,采用IoU损失和分布式focal损失(distributed focal loss)进行边界框回归,总训练损失定义为:
L ( I ) = L c o n + λ I ∗ ( L i o u + L d f l ) , L(I) = L_{con} + \lambda_{I} * (L_{iou} + L_{dfl}), L(I)=Lcon+λI∗(Liou+Ldfl),
其中 λ I \lambda_{I} λI是一个指示因子,当输入图像 I I I来自检测或定位数据时设为1,来自图像文本数据时设为0。考虑到图像文本数据中的噪声框,文中仅计算边界框位置准确的样本的回归损失。
基于图像文本数据的伪标签 Pseudo Labeling with Image-Text Data.
文中提出了一种自动标记方法来生成区域-文本对,而不是直接使用图像-文本对进行预训练。具体来说,标注方法包含三个步骤:
(1)提取名词短语extract noun phrases:首先利用n-gram算法从文本中提取名词短语;
(2)伪标签pseudo labeling:采用预先训练的开放词汇检测器,例如GLIP [24],为每个图像的给定名词短语生成伪框,从而提供粗略的区域-文本对;
(3)过滤filtering:采用预先训练的CLIP[39]来评估图像-文本对和区域-文本对的相关性,并过滤低相关性的伪注释和图像。通过结合非最大抑制 (NMS) 等方法进一步过滤冗余边界框。文中建议读者参考附录了解详细方法。通过上述方法,用821k伪注释对CC3M[47]中的246k图像进行采样和标记。
4、实验
Implementation Details
YOLO-World的实现基于MMYOLO工具箱[3]和MMDetection工具箱[2]。遵循[20]的做法,为不同延迟需求提供了YOLO-World的三个变体,例如小型(S)、中型(M)和大型(L)。采用开源的CLIP[39]作为文本编码器,使用预训练权重来编码输入文本。除非特别说明,所有模型的推理速度测量都在一台NVIDIA V100 GPU上进行,且不使用额外的加速机制,如FP16或TensorRT。
Pre-training
Experimental Setup. 预训练阶段采用AdamW优化器[34],初始学习率为0.002,权重衰减为0.05。YOLO-World在32块NVIDIA V100 GPU上进行预训练,总批次大小为512。预训练过程中,作者遵循先前研究[20]的做法,采用颜色增强、随机仿射、随机翻转以及4张图像的mosaic技术进行数据增强。在预训练期间,文本编码器被冻结。

Pre-training Data. 对于YOLO-World的预训练,主要采用detection or grounding数据集,包括Objects365(V1)[46]、GQA [17]、Flickr30k [38],如表1所示。在[24]之后,从GoldG [21](GQA和Flickr30k)的COCO数据集中排除了图像。用于预训练的检测数据集的注释包含边界框和类别或名词短语。此外,还使用图像-文本对(即CC3M†[47])扩展了预训练数据,文中通过第3.4节中讨论的伪标记方法标记了246k图像。
Zero-shot Evaluation.预训练后,直接在LVIS数据集[14]上以零样本方式评估所提出的YOLO-World。LVIS 数据集包含 1203 个对象类别,远远超过预训练检测数据集的类别,可以衡量大词汇检测的性能。根据之前的工作[21,24,56,57],文中主要评估LVIS minival [21],并报告Fixed AP[4]进行比较。最大预测数设置为 1000。

Main Results on LVIS Object Detection.
表2以零样本方式将所提出的YOLO-World与LVIS基准上的最新方法[21,30,56,57,59]进行了比较。考虑到计算负担和模型参数,主要与那些基于较轻量主干的方法进行比较,例如Swin-T[32]。值得注意的是,YOLO-World 在零样本性能和推理速度方面优于以前的先进方法。与包含更多数据的 GLIP、GLIPv2 和 Grounding DINO 相比,例如 Cap4M (CC3M+SBU [37]),在 O365 和 GolG 上预训练的 YOLO-World 即使使用更少的模型参数也能获得更好的性能。与DetCLIP相比,YOLO-World实现了相当的性能(35.4对34.4),同时推理速度提高了20×。实验结果还表明,具有13M参数的YOLO-World-S等小型模型可用于视觉语言预训练,并获得较强的开放词汇能力。
Ablation Experiments
消融研究从两个主要方面分析 YOLOWorld,即预训练和架构。除非另有说明,否则主要进行基于 YOLO-World-L 的消融实验,并对 Objects365 进行预训练,并在 LVIS minival 上进行零样本zero-shot评估。
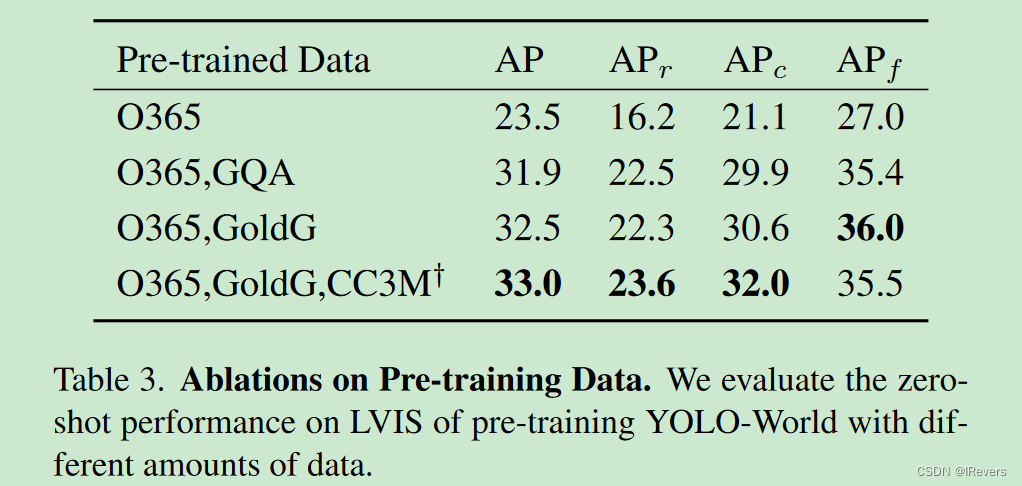
Pre-training Data. 表3使用不同的数据评估了预训练 YOLO-World 的性能。与在 Objects365 上训练的基线相比,添加 GQA 可以显著提高性能,在 LVIS 上获得$ 8.4 AP $增益。这种改进可以归因于GQA数据集提供的更丰富的文本信息,这可以增强模型识别大型词汇对象的能力。添加部分 CC3M 样本(占完整数据集的 8%)可以进一步带来 0.5 A P 0.5 AP 0.5AP 增益和 1.3 A P 1.3 AP 1.3AP 在稀有物体上。表3表明,添加更多数据可以有效提高大词汇场景的检测能力。此外,随着数据量的增加,性能不断提高,突出了利用更大、更多样化的数据集进行训练的好处。

Ablations on RepVL-PAN.表4展示了YOLO-World的RepVL-PAN(包括文本引导CSPLayers和图像池注意力)在零样本LVIS检测方面的有效性。具体来说,采用两种设置,即(1)在O365上进行预训练和(2)在O365和GQA上进行预训练。与仅包含类别注释的 O365 相比,GQA 包含富文本,尤其是名词短语的形式。如表4所示,所提出的RepVL-PAN在LVIS上将基线(YOLOv8-PAN [20])提高了1.1 AP,并且在难以检测和识别的LVIS的稀有类别( A P r AP_{r} APr)方面的改进是显着的。此外,当YOLO-World使用GQA数据集进行预训练时,这些改进变得更加显着,并且实验表明,所提出的RepVL-PAN在处理富文本信息时效果更好。

Text Encoders.表5比较了使用不同文本编码器的性能,即BERT-base[5]和CLIP-base(ViT-base)[39]。我预训练期间利用了两种设置,即冻结frozen和微调fine-tuned,微调文本编码器的学习率是基本学习率的 0.01× 倍。如表 5 所示,CLIP 文本编码器获得的结果优于 BERT(LVIS 中罕见类别的 +10.1 AP),后者使用图像文本对进行预训练,并且具有更好的以视觉为中心的嵌入能力。在预训练期间微调 BERT 会带来显着的改进 (+3.7 AP),而微调 CLIP 会导致性能严重下降。下降的原因是对 O365 进行微调可能会降低预训练 CLIP 的泛化能力,该 CLIP 仅包含 365 个类别,并且缺乏丰富的文本信息。
Fine-tuning YOLO-World
本节进一步微调了 YOLO-World 在 COCO 数据集和 LVIS 数据集上的闭集目标检测以证明预训练的有效性。
Experimental Setup.使用预先训练的权重来初始化 YOLO-World 以进行微调。所有模型都使用 AdamW 优化器针对 80 个epochs进行微调,初始学习率设置为 0.0002。此外,还对 CLIP 文本编码器进行了微调,学习因子为 0.01。对于LVIS数据集,作者遵循以前的工作[8,13,63],并在LVIS基础(常见和频繁)上微调YOLO-World,并在LVIS小说(罕见)上对其进行评估。

COCO Object Detection. 将预训练的YOLO-World与之前的YOLO检测器[20,23,52]进行了比较,如表6所示。为了在 COCO 数据集上微调 YOLO-World,考虑到 COCO 数据集的词汇量很小,作者删除了建议的 RepVL-PAN 以进一步加速。从表6可以看出,所提方法在COCO数据集上可以达到不错的零样本性能,这表明YOLO-World具有很强的泛化能力。此外,YOLO-World在COCO train2017上进行微调后展示了比以前从头开始训练的方法更高的性能。

LVIS Object Detection.表7评估了YOLO-World在标准LVIS数据集上的微调性能。首先,与在完整的LVIS数据集上训练的YOLOv8s[20]相比,YOLO-World实现了显著的改进,特别是对于较大的模型,例如,YOLO-World-L比YOLOv8-L高出 7.2 A P 7.2 AP 7.2AP和 10.2 A P r 10.2 AP_{r} 10.2APr。这些改进可以证明所提出的用于大词汇检测的预训练策略的有效性。此外,YOLO-World作为一种高效的单级检测器,在整体性能上优于以前的两级方法[8,13,22,53,63],无需额外的设计,例如可学习的提示[8]或基于区域的算法[13]。
Open-Vocabulary Instance Segmentation
本节进一步微调了 YOLO-World,以便在开放词汇设置下对对象进行分割,这可以称为开放词汇实例分割 (OVIS)。以前的方法[18]已经探索了OVIS在新物体上的伪标记。不同的是,考虑到YOLO-World具有较强的迁移和泛化能力,直接对带有掩码注释的数据子集进行微调YOLO-World,并评估大词汇设置下的分割性能。具体来说,在两种设置下对开放词汇实例分段进行基准测试:
(1) COCO到LVIS设置:在COCO(包含80个类别)数据集上,带有掩码注解的YOLO-World进行微调,模型需要从80类别扩展到1203类别(80 ->1203)。
(2) LVIS-base到LVIS设置:在包含866个类别(常见且频繁)的LVIS-base上进行微调,模型同样需要从866类别扩展到1203类别(866 -> 1203)。文中使用包含1203类别的标准LVIS val2017进行评估,其中337个稀有类别是未见过的,可用于衡量开放词汇性能。

结果如表8所示,采用了两种微调策略:(1)仅微调分割头,(2)微调所有模块。在策略(1)下,微调后的YOLO-World仍保留了预训练阶段获得的零样本能力,能够在无需额外微调的情况下对未见过的类别进行泛化。策略(2)使YOLO-World更好地适应LVIS数据集,但可能会牺牲零样本能力。
表8展示了在不同设置(基于COCO或LVIS-base)和策略(微调分割头或微调所有模块)下微调YOLO-World的比较。首先,基于LVIS-base的微调通常能获得更好的性能,但 A P AP AP与 A P r AP_{r} APr( A P r / A P AP_{r} /AP APr/AP)的比率变化不大,例如YOLO-World在COCO和LVIS-base上的比率分别为76.5%和74.3%。考虑到检测器冻结,性能差距可能源于LVIS数据集提供了更详细和密集的分割注解,有利于学习分割头。当微调所有模块时,YOLO-World在LVIS上的性能显著提升,如YOLO-World-L的AP提高了9.6。然而,微调可能会降低开放词汇性能,使YOLO-World-L的box A P r AP_{r} APr下降0.6。
Visualizations
展示了预训练的YOLO-World-L在三种场景下的可视化结果:
(a) 零样本推断,使用LVIS类别;
(b) 输入包含细粒度类别和属性的自定义提示;
(\c) 引指检测。这些可视化结果显示了YOLO-World在开放词汇场景中的强大泛化能力和指代能力。

Zero-shot Inference on LVIS. 图5展示了基于预训练YOLO-World-L在零样本情况下生成的LVIS类别的可视化结果。预训练的YOLO-World显示出强大的零样本迁移能力,能够在图像中检测尽可能多的物体。

Inference with User’s Vocabulary. 图6展示了YOLO-World在作者定义的类别下的检测能力。可视化结果显示,预训练的YOLO-World-L不仅能够进行(1)细粒度检测(即识别物体的部分)还具备(2)细粒度分类(即区分不同物体子类)的能力。

Referring Object Detection. 图7利用一些描述性的(区分性)名词短语作为输入,如站立的人,来探究模型能否定位图像中与给定输入匹配的区域或对象。可视化结果显示了短语及其对应的边界框,表明预训练的YOLO-World具有指代或定位能力。这得益于提出的基于大规模训练数据的预训练策略。
5、总结
YOLO-World是一个尖端的实时开放词汇检测器,旨在提高实际应用中的效率和开放词汇能力。本文将流行的 YOLO 重塑为用于开放词汇预训练和检测的视觉语言 YOLO 架构,并提出了RepVL-PAN,它将视觉和语言信息与网络连接起来,并且可以重新参数化以实现高效部署。进一步提出了有效的预训练方案,包括检测、接地和图像文本数据,以赋予YOLO-World强大的开放词汇检测能力。实验可以证明YOLO-World在速度和开放词汇性能方面的优势,并表明视觉语言预训练在小模型上的有效性,对未来的研究具有深刻的启示。
6、附录(可不看)
A. Additional Details
A.1. Re-parameterization for RepVL-PAN
离线词汇表的推理过程对 RepVL-PAN 进行了重新参数化,以实现更快的推理速度和部署。首先,通过文本编码器预先计算文本嵌入 W ∈ R C × D W \in R^{C \times D} W∈RC×D.
Re-parameterize T-CSPLayer. 在RepVL-PAN中的每个T-CSPLayer中,可以通过重塑文本嵌入 W ∈ R C × D × 1 × 1 W \in R^{C \times D \times 1 \times 1} W∈RC×D×1×1为 1 × 1 1 \times 1 1×1卷积层(或线性层)的权重,简化并重新参数化添加文本指导的过程,如下所示:
X ′ = X ∗ ( Sigmoid ( max ( Conv ( X , W ) , dim = 1 ) ) ) , ( 4 ) X' = X * (\text{Sigmoid}(\text{max}(\text{Conv}(X, W), \text{dim}=1))), \ (4) X′=X∗(Sigmoid(max(Conv(X,W),dim=1))), (4)
其中 X ′ X' X′和 X X X分别表示输入和输出的图像特征,矩阵乘法通过reshape或transpose操作实现。
Re-parameterize I-Pooling Attention.
对I-Pooling注意力进行了参数重置,通过简化为:
X ~ = ( cat ( MP ( X 3 , 3 ) , MP ( X 4 , 3 ) , MP ( X 5 , 3 ) ) ) , ( 5 ) \tilde{X} = (\text{cat}(\text{MP}(X_{3}, 3), \text{MP}(X_{4}, 3), \text{MP}(X_{5}, 3))), \ (5) X~=(cat(MP(X3,3),MP(X4,3),MP(X5,3))), (5)
其中cat表示聚集, M P ( • , 3 ) MP(•, 3) MP(•,3)表示 3 × 3 3 \times 3 3×3输出特征的最大池化。 X 3 , X 4 , X 5 {X_{3}, X_4, X_5} X3,X4,X5是RepVL-PAN中的多尺度特征, X X X展平后形状为 B × D × 27 B \times D \times 27 B×D×27。然后,更新文本嵌入:
W ′ = W + ( Softmax ( W ∗ X ~ , dim = − 1 ) ∗ W ) . ( 6 ) W' = W + (\text{Softmax}(W * \tilde{X}, \text{dim}=-1) * W). \ (6) W′=W+(Softmax(W∗X~,dim=−1)∗W). (6)
A.2. Fine-tuning Details
当将 YOLO-World 转移到 COCO [26] 对象检测时,作者删除了 RepVL-PAN 中的所有 T-CSPLayers 和 Image-Pooling Attention,该检测仅包含 80 个类别,并且对视觉语言交互的依赖性相对较低。微调过程使用预先训练的权重初始化 YOLO-World,微调的学习率设置为 0.0002,权重衰减设置为 0.05。微调后,使用给定的 COCO 类别预先计算类文本嵌入,并将嵌入存储到分类层的权重中。
B. Automatic Labeling on Large-scale Image-Text Data

本节详细描述了使用大规模图像文本数据(如CC3M [47])对区域-文本对进行标注的步骤。整体标注流程如图8所示,主要包括三个步骤:(1)提取对象名词;(2)伪标签生成;(3)过滤。如第3.4节中提到的,采用简单的n-gram算法从描述中提取名词。
Region-Text Proposals. 从第一步获取的对象名词集合 T = { t k } K T = \{t_{k}\}^{K} T={tk}K中,我们利用预训练的开放词汇检测器GLIP-L [24]生成伪框 B i {B_{i}} Bi和置信度分数 c i {c_{i}} ci:
B i , t i , c i i = 1 N = G L I P − L a b e l e r ( I , T ) , ( 7 ) {B_{i}, t_{i}, c_{i}}^{N}_{i=1} = GLIP-Labeler(I, T), \ (7) Bi,ti,cii=1N=GLIP−Labeler(I,T), (7)
其中 { B i , t i , c i } i = 1 N \{B_{i}, t_{i} , c_{i}\}^{N}_{i=1} {Bi,ti,ci}i=1N 是粗粒度的区域-文本提议。
CLIP-based Re-scoring & Filtering. 考虑到包含大量噪声的区域-文本提议,我们提出了一种恢复和过滤流程,利用预训练的CLIP [39]。给定输入图像 I I I,描述T和粗粒度提议 B i , t i , c i N i = 1 {B_{i}, t_{i}, c_{i}} N i=1 Bi,ti,ciNi=1,具体流程如下:
(1) 计算图像-文本相似度Image-Text Score:将图像 I I I及其描述 T T T输入到CLIP中,得到图像-文本相似度分数 s i m g s^{img} simg。
(2) 计算区域-文本相似度Region-Text Score:根据区域框 B i {B_{i}} Bi从输入图像中裁剪出区域图像,然后将裁剪后的图像及其文本 t i {t_{i}} ti输入到CLIP,得到区域-文本相似度向量 S r = { s i r } i = 1 N S_{r} = \{s^{r}_{i}\}^{N}_{i=1} Sr={sir}i=1N。
(3) [可选] 重新标注Re-Labeling:对于每个裁剪的图像,与所有名词一起前向传播,将具有最大相似性的名词分配给它,有助于修正GLIP错误标注的文本。
(4) 重评分Rescoring:使用区域-文本相似度 S r S^{r} Sr重新调整置信度分数 c ~ i = c i ∗ s i r \tilde{c}_{i} = c_{i} * s^{r}_{i} c~i=ci∗sir。
(5) 区域级过滤Region-level Filtering:首先根据文本将区域-文本提议分组,然后执行非极大值抑制(NMS)过滤重复预测(NMS阈值设为0.5)。接着,过滤掉置信度分数低的提议(阈值设为0.3)。
(6) 图像级过滤Image-level Filtering:计算保留的区域-文本分数的平均值 s r e g i o n s^{region} sregion,得到图像级区域-文本分数 s = s i m g ∗ s r e g i o n s = \sqrt{s^{img} * s^{region}} s=simg∗sregion。保留分数大于0.3的图像。上述阈值是根据标注结果的一部分和整个流程的自动化设置的,无需人工验证。最终,这些标注样本用于预训练YOLO-World。文中将为CC3M提供伪标签,供进一步研究使用。
C. Pre-training YOLO-World at Scale

当预训练小型模型,如YOLO-World-S时,一个自然的问题是:小型模型需要多大的容量,以及需要多少训练数据或何种类型的数据?为了解答这个问题,作者利用不同数量的伪标签化的区域-文本对来预训练YOLO-World。如表9所示,增加图像-文本样本可以提升YOLO-World-S的零样本性能。表9表明:(1)增加图像-文本数据可以整体提升YOLO-World-S的零样本性能;(2)对于小型模型(YOLO-World-S),使用过多的伪标签数据可能产生一些负面影响,尽管它能提高对罕见类别的性能( A P r AP_{r} APr)。然而,使用精细标注的数据(GoldG)对小型模型有显著的提升,这表明大规模高质量标注数据能显著增强小型模型的能力。主文本中的表3已经显示,结合精细标注数据和伪标注数据进行预训练可以取得更好的效果。将在未来的工作中进一步探索预训练小型模型或YOLO检测器所需的数据。
-S),使用过多的伪标签数据可能产生一些负面影响,尽管它能提高对罕见类别的性能( A P r AP_{r} APr)。然而,使用精细标注的数据(GoldG)对小型模型有显著的提升,这表明大规模高质量标注数据能显著增强小型模型的能力。主文本中的表3已经显示,结合精细标注数据和伪标注数据进行预训练可以取得更好的效果。将在未来的工作中进一步探索预训练小型模型或YOLO检测器所需的数据。