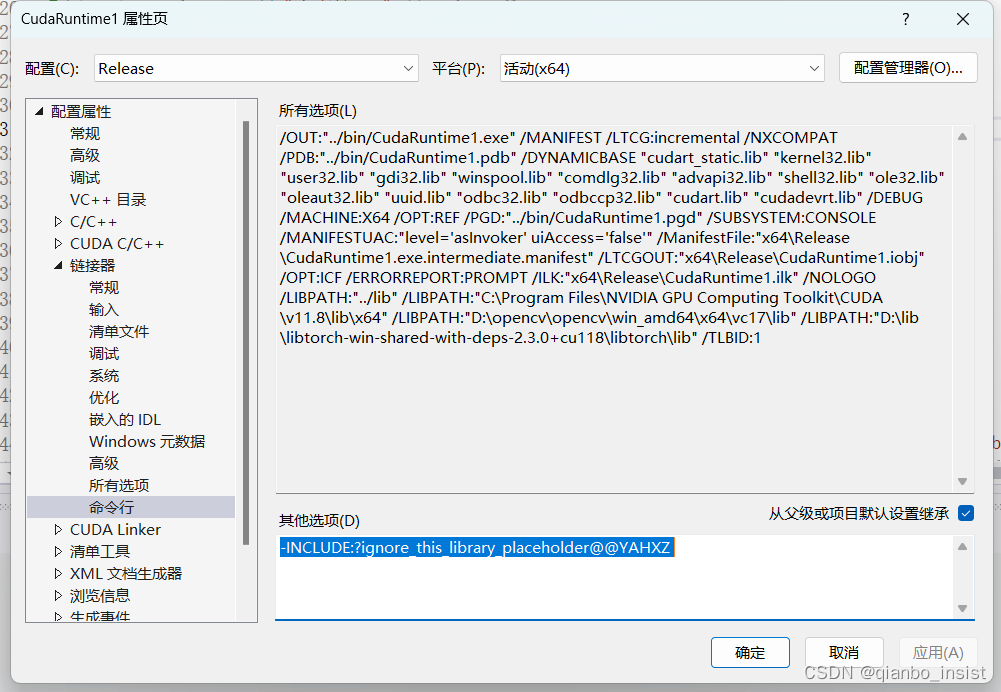
1、支持GPU情况
libtorch 支持GPU情况比较奇怪,目前2.3 版本需要在链接器里面加上以下命令,否则不会支持gpu
-INCLUDE:?ignore_this_library_placeholder@@YAHXZ
2 探测是否支持
加一个函数看你是否支持torch,不然不清楚,看到支持gpu才行
void IsSupportCuda()
{
if (torch::cuda::is_available())
{
std::cout << "支持GPU" << std::endl;
}
else
{
std::cout << "不支持GPU" << std::endl;
}
torch::Tensor tensor = torch::rand({ 5,3 });
torch::Device device1(torch::kCUDA);
tensor.to(device1);
std::cout << tensor <<"--"<< tensor.options() << std::endl;
};
int main() {
IsSupportCuda();
return 0;
}
转化
使用命令转,如下图所示
yolo export model=yolov8s.pt imgsz=640 format=torchscript
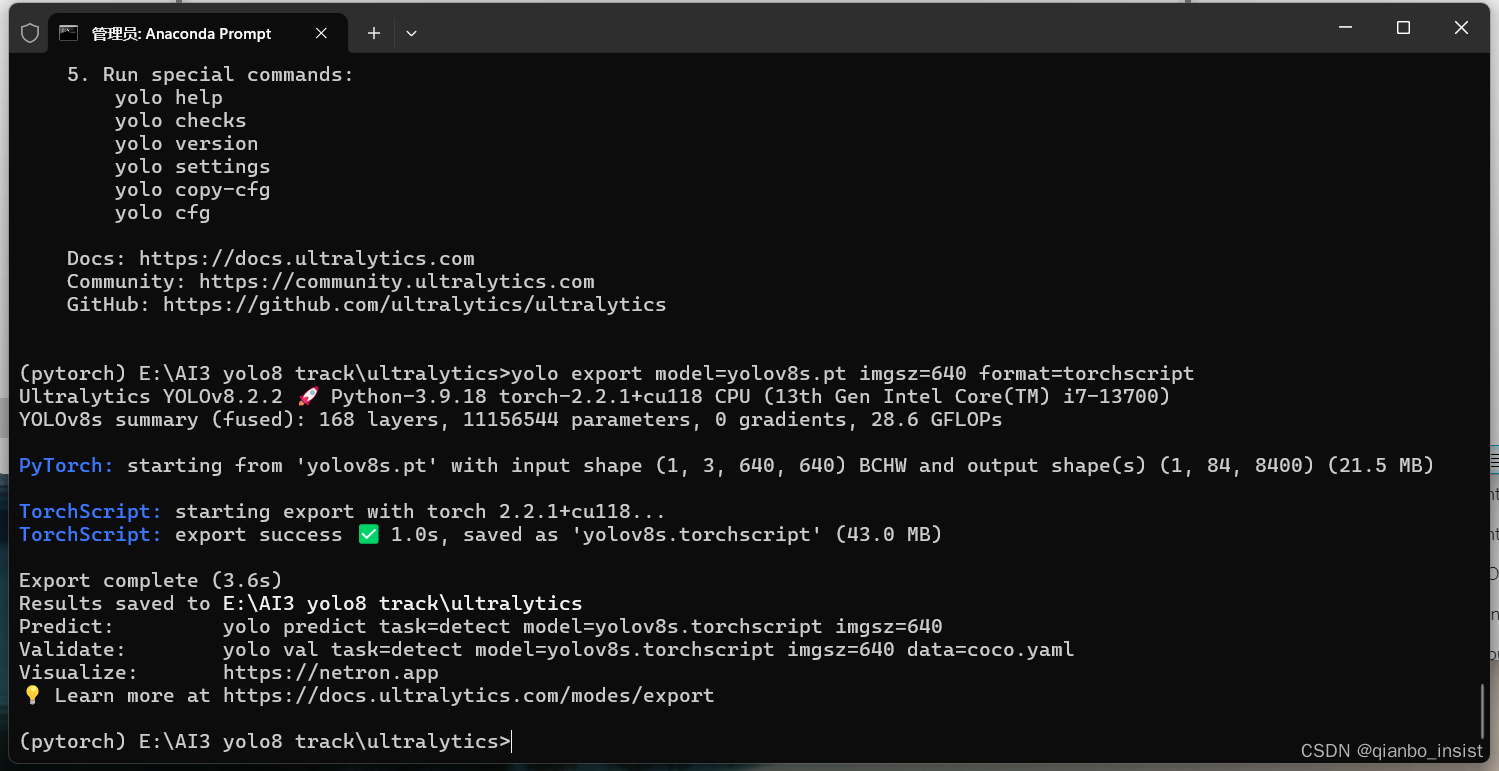
成功以后在目录下面生成文件yolov8s.torchscript
c++ 调用
int main() {
//IsSupportCuda();
//return 0;
// Device
torch::Device device(torch::cuda::is_available() ? torch::kCUDA : torch::kCPU);
// Note that in this example the classes are hard-coded
std::vector<std::string> classes{ "person", "bicycle", "car", "motorcycle", "airplane", "bus", "train", "truck", "boat", "traffic light", "fire hydrant",
"stop sign", "parking meter", "bench", "bird", "cat", "dog", "horse", "sheep", "cow", "elephant", "bear", "zebra",
"giraffe", "backpack", "umbrella", "handbag", "tie", "suitcase", "frisbee", "skis", "snowboard", "sports ball", "kite",
"baseball bat", "baseball glove", "skateboard", "surfboard", "tennis racket", "bottle", "wine glass", "cup", "fork", "knife",
"spoon", "bowl", "banana", "apple", "sandwich", "orange", "broccoli", "carrot", "hot dog", "pizza", "donut", "cake", "chair",
"couch", "potted plant", "bed", "dining table", "toilet", "tv", "laptop", "mouse", "remote", "keyboard", "cell phone",
"microwave", "oven", "toaster", "sink", "refrigerator", "book", "clock", "vase", "scissors", "teddy bear", "hair drier", "toothbrush" };
try {
// Load the model (e.g. yolov8s.torchscript)
std::string model_path = "./yolov8s.torchscript";
torch::jit::script::Module yolo_model;
yolo_model = torch::jit::load(model_path);
yolo_model.eval();
yolo_model.to(device, torch::kFloat32);
// Load image and preprocess
cv::Mat image = cv::imread("d:/bus.jpg");
cv::Mat input_image;
letterbox(image, input_image, { 640, 640 });
torch::Tensor image_tensor = torch::from_blob(input_image.data, { input_image.rows, input_image.cols, 3 }, torch::kByte).to(device);
//auto image_tensor_float = image_tensor.to(torch::kFloat32);
//image_tensor_float /= 255.0;
image_tensor = image_tensor.toType(torch::kFloat32).div(255);
image_tensor = image_tensor.permute({ 2, 0, 1 });
image_tensor = image_tensor.unsqueeze(0);
std::vector<torch::jit::IValue> inputs{ image_tensor };
// Inference
torch::Tensor output = yolo_model.forward(inputs).toTensor().cpu();
// NMS
auto keep = non_max_suppression(output)[0];
auto boxes = keep.index({ Slice(), Slice(None, 4) });
keep.index_put_({ Slice(), Slice(None, 4) }, scale_boxes({ input_image.rows, input_image.cols }, boxes, { image.rows, image.cols }));
// Show the results
for (int i = 0; i < keep.size(0); i++) {
int x1 = keep[i][0].item().toFloat();
int y1 = keep[i][1].item().toFloat();
int x2 = keep[i][2].item().toFloat();
int y2 = keep[i][3].item().toFloat();
float conf = keep[i][4].item().toFloat();
int cls = keep[i][5].item().toInt();
std::cout << "Rect: [" << x1 << "," << y1 << "," << x2 << "," << y2 << "] Conf: " << conf << " Class: " << classes[cls] << std::endl;
}
getchar();
}
catch (const c10::Error& e) {
std::cout << e.msg() << std::endl;
}
return 0;
}
解码后视频帧调用
先使用opencv,同时使用硬件加速,使用硬件解码,新版本的使用方法已经不一样了,以下先举个例子,指定使用ffmpeg
int main() {
// 创建一个 VideoCapture 对象,并指定使用 FFmpeg 作为后端
cv::ocl::setUseOpenCL(true);
if (!cv::ocl::haveOpenCL()) {
std::cerr << "OpenCL is not available.\n";
return -1;
}
else {
std::cout << cv::ocl::Device().getDefault().name() << std::endl;
}
cv::VideoCapture cap1("rtsp://127.0.0.1/99-640.mkv", cv::CAP_FFMPEG, {
cv::CAP_PROP_HW_ACCELERATION,(int)cv::VIDEO_ACCELERATION_D3D11,
cv::CAP_PROP_HW_DEVICE, 0
});
// cv::VideoCapture cap2("d:/8k.mp4", cv::CAP_FFMPEG);
// 检查是否成功打开视频文件
if (!cap1.isOpened()) {
std::cerr << "Error opening video file" << std::endl;
return -1;
}
// 检查是否支持硬件加速
double hw1 = cap1.get(cv::CAP_PROP_HW_ACCELERATION);
// double hw2 = cap2.get(cv::CAP_PROP_HW_ACCELERATION);
if (hw1 >= cv::VIDEO_ACCELERATION_ANY ) {
// 支持硬件加速,尝试启用
//cap.set(cv::CAP_PROP_HW_ACCELERATION, cv::VIDEO_ACCELERATION_ANY);
std::cout << "Hardware acceleration enabled" << std::endl;
}
else {
std::cout << "Hardware acceleration not supported or not available" << std::endl;
}
// 设置硬件加速(如果支持的话)
// 注意:不是所有的平台和驱动程序都支持硬件加速
// cap.set(cv::CAP_PROP_HW_ACCELERATION, cv::VIDEO_ACCELERATION_ANY);
cv::UMat uFrame,Frame; // GPU 上的 UMat 对象,用于直接接收解码后的数据
// 读取并处理视频帧
while (true) {
// 尝试直接从 VideoCapture 读取帧到 UMat
cv::UMat m;
bool ret = cap1.read(m);
if (!ret) {
std::cout << "End of video" << std::endl;
break;
}
int w = m.cols;
int h = m.rows;
//m.copyTo(uFrame);
//uFrame = m.getUMat(cv::ACCESS_READ);
cv::UMat m1,m2,m3,m4,m5;
//视频矫正
rectify_umat(m, w, h, default_K0, default_D0, m1);
//cv::Mat m1, m2, m3,m4;
//放大增强
cv::resize(m1, m2, cv::Size(w*2, h*2),0,0,cv::INTER_CUBIC);
letterbox(m2, input_image, { 640, 640 });
torch::Tensor image_tensor = torch::from_blob(input_image.data, { input_image.rows, input_image.cols, 3 }, torch::kByte).to(device);
//auto image_tensor_float = image_tensor.to(torch::kFloat32);
//image_tensor_float /= 255.0;
image_tensor = image_tensor.toType(torch::kFloat32).div(255);
image_tensor = image_tensor.permute({ 2, 0, 1 });
image_tensor = image_tensor.unsqueeze(0);
std::vector<torch::jit::IValue> inputs{ image_tensor };
// Inference
torch::Tensor output = yolo_model.forward(inputs).toTensor().cpu();
// NMS
auto keep = non_max_suppression(output)[0];
auto boxes = keep.index({ Slice(), Slice(None, 4) });
keep.index_put_({ Slice(), Slice(None, 4) }, scale_boxes({ input_image.rows, input_image.cols }, boxes, { image.rows, image.cols }));
// Show the results
for (int i = 0; i < keep.size(0); i++) {
int x1 = keep[i][0].item().toFloat();
int y1 = keep[i][1].item().toFloat();
int x2 = keep[i][2].item().toFloat();
int y2 = keep[i][3].item().toFloat();
float conf = keep[i][4].item().toFloat();
int cls = keep[i][5].item().toInt();
std::cout << "Rect: [" << x1 << "," << y1 << "," << x2 << "," << y2 << "] Conf: " << conf << " Class: " << classes[cls] << std::endl;
}
func_3_umat(m2, m3);
func_1_umat(m3, m4);
func_0_umat(m4, m5);
cv::imshow("m", m);
cv::imshow("m2", m2);
cv::imshow("res", m5);
if (cv::waitKey(10) == 'q') {
break;
}
}
// 释放资源
cap1.release();
//cap2.release();
cv::destroyAllWindows();
return 0;
}
改进
未完待续。。。