异常检测问题
异常检测虽然主要用于无监督学习问题上,但是和监督学习问题很相似。
异常检测(Anomaly Detection):给定正确样本集{ x ( 1 ) , x ( 2 ) . . . x ( n ) x^{(1)},x^{(2)}...x^{(n)} x(1),x(2)...x(n)},记新样本即要检测的样本为 x t e s t x_{test} xtest。对x进行建模即画出x的概率分布图像p(x),将 x t e s t x_{test} xtest代入 p ( x t e s t ) p(x_{test}) p(xtest),给定阈值 ε \varepsilon ε,如果 p ( x t e s t ) < ε p(x_{test})<\varepsilon p(xtest)<ε则代表着 x t e s t x_{test} xtest在原本样本集中出现的概率很小,标记为异常。如果 p ( x t e s t ) ≥ ε p(x_{test})\ge\varepsilon p(xtest)≥ε,标记为正常。
在APP中,异常检测通常用于做欺诈检测:通过对正常用户的建模寻找可能存在的非法用户、异常用户进行处理。
在工业上异常检测通常用于检测产品的质量,对符合标准的产品进行建模,对新生产好的产品进行检测查看是否需要进一步测试。
1. 高斯分布
高斯分布也就是正态分布。
参数估计:参数估计就是给定一个数据集估算出 μ 和 σ 2 \mu 和\sigma^2 μ和σ2的值。
μ = 1 m ∑ i = 1 m x ( i ) \mu =\frac{1}{m}\sum_{i=1}^{m}x^{(i)} μ=m1∑i=1mx(i)
σ 2 = 1 m ∑ i = 1 m ( x ( i ) − μ ) 2 \sigma ^2=\frac{1}{m}\sum_{i=1}^{m}(x^{(i)}-\mu )^2 σ2=m1∑i=1m(x(i)−μ)2
通俗来讲 μ \mu μ就是均值, σ 2 \sigma^2 σ2就是方差
2. 用高斯分布推导异常检测算法

首先选择一些对出现异常问题时反应较大的特征,给出训练集{ x ( 1 ) , x ( 2 ) . . . x ( n ) x^{(1)},x^{(2)}...x^{(n)} x(1),x(2)...x(n)}求出对应的{ μ ( 1 ) , μ ( 2 ) . . . μ ( n ) \mu_{(1)},\mu_{(2)}...\mu_{(n)} μ(1),μ(2)...μ(n)}和{ σ ( 1 ) 2 , σ ( 2 ) 2 . . . σ ( n ) 2 \sigma^2_{(1)},\sigma^2_{(2)}...\sigma^2_{(n)} σ(1)2,σ(2)2...σ(n)2}。将新样本代入求出的正态分布函数中求概率, 如果小于阈值 ε \varepsilon ε就标注为异常。
这里的 x j x_j xj是指 x x x这个新样本在各个方向上的投影值,或者说是 x x x这个特征向量中的各个特征的值。
3. 评估异常检测算法
前面有说过对于算法来讲,我们进行评估的时候往往需要判断很多事情才能得出算法的优劣,所以使用数字指标会方便很多。对于异常检测算法我们同样使用数字指标去评估算法的好坏,具体如下:
将正常样本赋值y=1,异常样本赋值y=0。一共选取10000+40个样本,其中10000个样本是正常的,40个样本是异常的。将10000个样本按照6:2:2的比例分为训练集、验证集和测试集,40个样本按照1:1的比例放导验证集和测试集中。至此训练集中包含6000个正常样本,验证集中包含2000个正常样本和20个异常样本,测试集中包含2000个正常样本和20个异常样本。
虽然给正常样本异常样本赋值y但是这本质上还是无监督问题不是监督问题。
用训练集中的6000个正常样本进行异常检测算法求出 μ 、 σ 2 \mu、\sigma^2 μ、σ2后,得到p(x)。求出验证集和测试集中的样本的p(x)判断y值并与真正结果相比较,计算查准率和召回率得出F值,判断异常检测算法的好坏。

也可以使用之前的模型选择方法定义阈值 ε \varepsilon ε,求出p(x)后使用不同的 ε \varepsilon ε在验证集上进行检验,选取F值最高的 ε \varepsilon ε在测试集上进行检验。
4. 异常检测算法和监督学习算法的取舍
相信会有一些人觉得上面的异常检测算法很像监督学习的方法,也会疑惑为什么不直接用监督学习的算法进行异常检测,现在对二者进行取舍:
当出现👆偏斜类问题时,选择异常检测算法。

当出现异常有很多类型而且未来可能出现没出现过的异常时,选择异常检测算法。
二者实际应用对比:

5. 如何选择异常检测算法的特征
通常使用误差分析确定一场算法的特征,和之前监督学习算法的误差分析很像。

先完整的训练出一个算法,在一组验证集上运行算法,找出预测出错的样本提取共同特征改善算法。
特征矫正(非官方叫法):当我们选取完特征后,在选取样本时最好查看他的图像是否能够满足正太分布。
输入一个特征 x x x的一组值,画出图像(octave中hist函数),如果图像和正态分布很像就不用调整,如果不像就调整一下使其像正态分布。
调整手段:取对数等数学变形。
如:初始图象如下图的集合
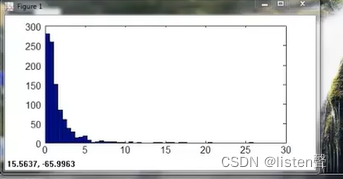
经过①处理后变成了下图
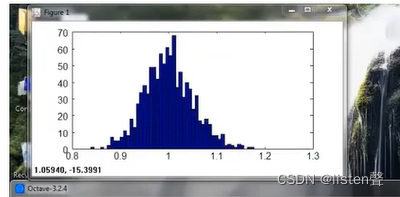
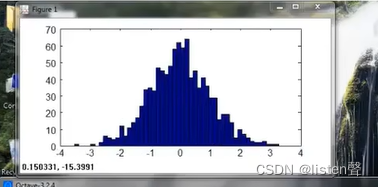
经过②处理后变成了下图

6. 多元高斯分布
多元高斯分布和高斯分布的不同是多元高斯分布并不分别对每个特征进行高斯建模,而是一次性将所有特征值建模成一个高斯函数。

Σ \Sigma Σ就是PCA中的协方差矩阵。
det(A) %求矩阵A的行列式的octave代码
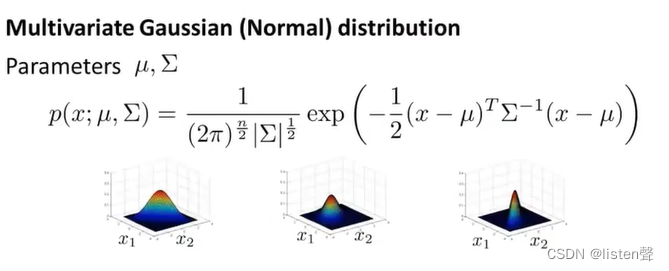
👆是多元高斯分布的表达式,接下来会用多元高斯分布构建异常检测算法。
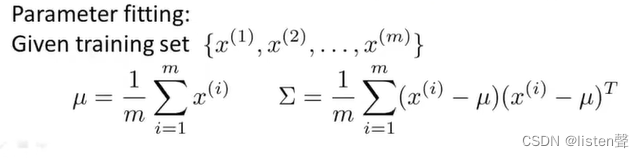
👆参数估计。
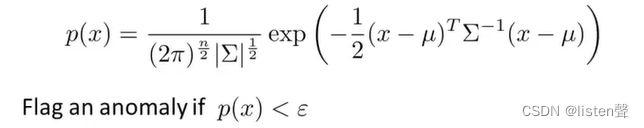
👆将新的样本代入p(x)进行检验,如果小于阈值就标注异常。
实际上,最开始的模型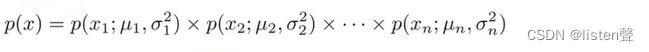
就是当 Σ \Sigma Σ矩阵主对角线是方差、非主对角线元素都是0时的多元高斯分布模型。
那么如何在两个模型之间选择呢?

原始模型被使用的更多一些,但多元高斯模型在捕捉不同特征之间关系方面更加灵活。如果想要使用原始模型去对特征之间的关系进行综合比较需要创建一个新特征如两个原本特征的比值等等,但是多元高斯模型可以自动捕捉这些关系;原始模型的计算成本较低,能够使用大规模运算,多元高斯模型的运算代价就比较大,当数据量较大时可能成本会很高;对于训练集较小的情况下原始模型也可以很好的运行,但是多元高斯模型需要样本数量>特征数量才可以,不然 Σ \Sigma Σ不可逆不能运行。
吴恩达老师的选择方法:
当样本数量 ≥ \ge ≥特征数量的十倍时,选用多元高斯模型;其余选用原始模型。
当 Σ \Sigma Σ不可逆时,一方面是样本数量小于特征数量,再就是特征线性相关(即存在冗余特征)。