How Cypher changed in Neo4j v5
Neo4j v5 中 Cypher 的变化
几周前,Neo4j 5 发布了。如果你像我一样,在 Neo4j 4 的后期版本中忽略了所有的弃用警告,你可能需要更新你的 Cypher 查询以适应最新版本的 Neo4j。幸运的是,新的 Cypher 语法没有显著差异,所以更新过程应该不会太困难。然而,我决定写这篇博客文章来帮助你过渡。此外,我还将介绍一些新的 Cypher 语法,这些语法可以简化你的查询。
Jupyter Notebook on GitHub.
这篇博客文章中的 Cypher 示例可以在 GitHub 上的 Jupyter Notebook 中找到。
Neo4j 环境搭建
为了跟随本篇文章中的代码示例,您需要搭建一个 Neo4j 环境。像往常一样,您可以使用 Neo4j 桌面应用程序来搭建一个本地环境。另一方面,您可以使用作为 Neo4j Aura 提供的免费云实例。如果您选择 Neo4j Aura 路线,使用永久免费的实例并启动一个不带有预填充图的空白项目。_
附言:永久免费的 Neo4j Aura 实例不提供 GDS 支持。_
Dataset 数据集
我找到了一个描述《沙丘》系列中角色的数据集。
Frank Herbert’s DUNE Characters弗兰克·赫伯特的《沙丘》角色Social networks in a fantastic world… help build the dataset!一个奇妙世界中的社交网络……帮助构建数据集!www.kaggle.com网址:www.kaggle.com
Dune 数据集在 Kaggle 上可用,为了让您更方便,我已经将数据集复制到一个 GitHub 仓库,这样您就不必下载数据集,可以轻松地在您的本地或云实例的 Neo4j 中导入它。此外,我已经将关系类型“父母-子女”和“其他家庭成员”重命名为“家庭成员”,并移除了“未知”关系。
Graph Model 图模型
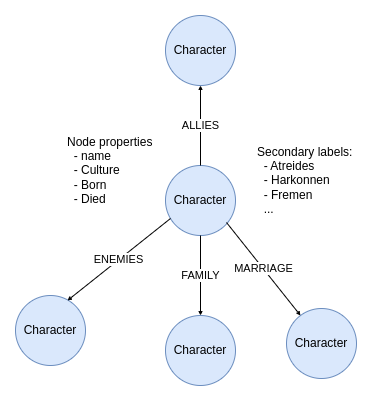
Dune graph model. Image by the author.
沙丘图模型。图片由作者提供。
图模型围绕角色展开。角色节点具有多个属性,如名称、文化,以及他们的出生或死亡时间。此外,他们对家族的忠诚度被表示为次要节点标签。使用次要节点标签而不是单独的节点的主要原因是为了展示 Cypher 中的新节点标签过滤选项。角色之间有四种类型的关系:
- ALLIES 盟友
- ENEMIES, 敌人,
- FAMILY 家庭
- MARRIAGE 婚姻
Dataset import 数据集导入
As with most imports, you first want to define unique constraints in Neo4j. Unique constraints ensure that a given property is unique for every node with a particular label.
与大多数导入操作一样,您首先希望在 Neo4j 中定义唯一性约束。唯一性约束确保对于具有特定标签的每个节点,给定属性是唯一的。
The syntax for defining unique constraints has slightly changed in Neo4j v5.
在 Neo4j v5 中,定义唯一性约束的语法略有变化。
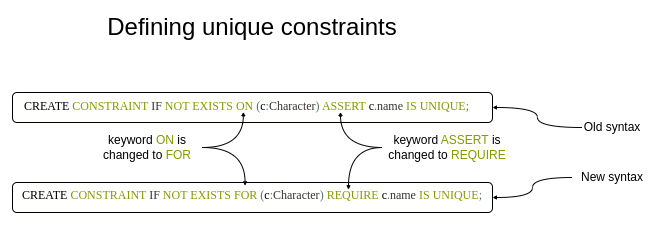
Syntax change for UNIQUE CONSTRAINTS. Image by the author.
唯一约束的语法变更。图片由作者提供。
The new syntax for unique constraints has two keywords replaced. The ON keyword is replaced with FOR, while the ASSERT is changed to REQUIRE.
新的唯一约束语法有两个关键字被替换。ON 关键字被替换为 FOR,而 ASSERT 被更改为 REQUIRE。
The following Cypher statements define the unique constraint for name property of Character nodes.
以下 Cypher 语句为角色节点的名称属性定义了唯一约束。
CREATE CONSTRAINT IF NOT EXISTS FOR (c:Character) REQUIRE c.name IS UNIQUE;
Next, you need to import the CSV file. Even though the Dune CSV file has only 1000 rows, you will pretend you are dealing with a large CSV file with many thousands of rows. Therefore, you want to use batch import into multiple transactions. As USING PERIODIC COMMIT clause has been deprecated in Neo4j v5, you need to use the new batched transaction syntax.
接下来,你需要导入 CSV 文件。尽管 Dune CSV 文件只有 1000 行,但你会假装你正在处理一个包含数千行的大型 CSV 文件。因此,你想要使用批量导入到多个事务中。由于 USING PERIODIC COMMIT 子句已在 Neo4j v5 中被弃用,你需要使用新的批量事务语法。
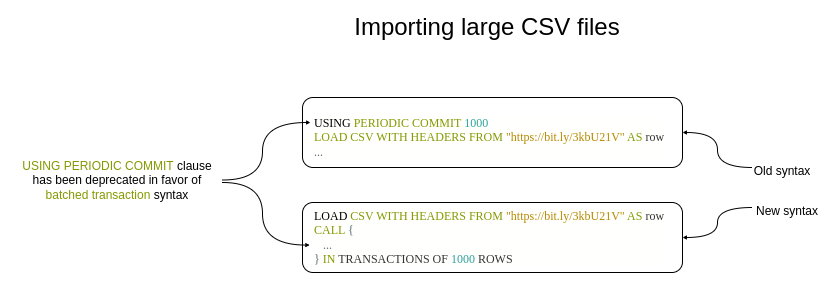
Syntax change for importing large CSV files. Image by the author.
导入大型 CSV 文件的语法变更。图片由作者提供。
The subqueries were already introduced in Neo4j v4 but have taken on a more prominent role in v5. The subqueries are instantiated with a CALL clause and wrapped with curly brackets {}. They are great for various functionalities like post-union processing, limiting results per row, and conditional execution. Additionally, the Cypher subqueries are now the only native Cypher syntax (excluding APOC) to batch a single Cypher statement into multiple transactions. In order to specify that the Cypher subquery should be split into multiple transactions, you need to add IN TRANSACTIONS OF x ROWS, where the x represents the number of rows for each batch.
子查询在 Neo4j v4 中已经引入,但在 v5 中扮演了更重要的角色。子查询使用 CALL 子句实例化,并用花括号 {} 包裹。它们非常适合各种功能,如联合后处理、限制每行的结果以及条件执行。此外,Cypher 子查询现在是唯一的原生 Cypher 语法(不包括 APOC)将单个 Cypher 语句拆分为多个事务。为了指定 Cypher 子查询应该拆分为多个事务,你需要添加 IN TRANSACTIONS OF x ROWS,其中 x 表示每个批次的行数。
The following Cypher statement contains two nested subqueries. The top-level subquery is used to batch the import into a new transaction for every 10 rows. On the other hand, you use the nested Cypher subquery as a conditional execution feature.
下面的 Cypher 语句包含两个嵌套子查询。顶级子查询用于将导入批处理到每 10 行的新事务中。另一方面,您使用嵌套的 Cypher 子查询作为条件执行特性。
LOAD CSV WITH HEADERS FROM "https://bit.ly/3kbU21V" AS row
CALL {
WITH row // Explicit import of variables
MERGE (c:Character {name:row.Character})
SET c += apoc.map.clean(row,
["name", "Detail", "to", "relationship_type", "House_Allegiance"], [])
WITH c, row
CALL apoc.create.addLabels(c, [row.House_Allegiance]) YIELD node
// nested subquery for conditional execution
CALL {
WITH row, c // Explicit import of variables
WITH row, c
WHERE row.to IS NOT NULL
MERGE (c1:Character {name: row.to})
WITH row, c, c1
CALL apoc.merge.relationship(c, toUpper(row.relationship_type), {}, {}, c1)
YIELD rel
RETURN count(*) AS count
}
RETURN count(*) AS finalCount
} IN TRANSACTIONS OF 10 ROWS // Define batched transaction for every 10 rows
RETURN count(*)
The import query is a bit more complicated because I wanted to do the import in a single Cypher statement. It starts with the LOAD CSV clause that you might have seen before. In order to batch the import into multiple transactions, you need to initiate a Cypher subquery with the CALL clause. The top-level subquery ends with the IN TRANSACTIONS OF x ROWS clause, which specifies the transaction batching.
导入查询有点复杂,因为我想用单个 Cypher 语句完成导入。它以您可能之前见过的 LOAD CSV 子句开始。为了将导入分批到多个事务中,您需要使用 CALL 子句启动一个 Cypher 子查询。顶级子查询以 IN TRANSACTIONS OF x ROWS 子句结束,该子句指定了事务批处理。
If you want to use any variable in the Cypher statement, you must explicitly import it with the WITH clause. First, the top-level subquery import the row variable from the outer query. Next, it merges the Character node and sets a couple of properties. Since adding dynamic secondary labels is not supported in plain Cypher, you can use the APOC’s procedure.
如果您想在使用 Cypher 语句中的任何变量,您必须使用 WITH 子句明确导入它。首先,顶级子查询从外部查询导入行变量。接下来,它合并了角色节点并设置了一些属性。由于在普通 Cypher 中不支持添加动态二级标签,您可以使用 APOC 的过程。
Some of the Dune characters have additional relationships defined in the to and relationship_type columns of the CSV. On the other hand, the to and relationship_type columns are empty for several rows. The FOREACH conditional execution trick was my go-to option for the better part of my blog post. However, as the theme of this blog post are Cypher subqueries, I have decided to show you how to use Cypher subqueries for conditional execution. First, with the nested Cypher subquery, you need to import both the row and the c variables. Next, you need to filter out only rows where the to column is not null. However, you cannot filter variables in the same WITH clause used to import them. Therefore, you need to add a second WITH clause to filter rows. Lastly, you use the APOC’s procedure for merging relationships, as the plain Cypher syntax does not support creating properties with dynamic relationship types.
一些《沙丘》中的角色在 CSV 文件的 to 和 relationship_type 列中定义了额外的关系。另一方面,有几行的 to 和 relationship_type 列是空的。FOREACH 条件执行技巧是我博客文章的大部分内容的首选解决方案。然而,由于这篇博客文章的主题是 Cypher 子查询,我决定向您展示如何使用 Cypher 子查询进行条件执行。首先,使用嵌套的 Cypher 子查询,您需要导入 row 和 c 变量。接下来,您需要过滤出 to 列不为空的行。但是,您不能在用于导入它们的同一 WITH 子句中过滤变量。因此,您需要添加第二个 WITH 子句来过滤行。最后,使用 APOC 的过程来合并关系,因为普通的 Cypher 语法不支持创建具有动态关系类型的属性。
You can check out the documentation if this example was a bit too packed for you.
如果这个例子对你来说有点过于复杂,你可以查看文档。
New inline filtering options
新的内联过滤选项
There are many new options available for inline filtering in Neo4j v5. So what exactly is inline filtering? Essentially, it is the ability to filter a graph pattern directly in the MATCH clause.
Neo4j v5 中有许多新的内联过滤选项可用。那么究竟什么是内联过滤呢?本质上,它就是直接在 MATCH 子句中过滤图模式的能力。
You will begin by learning the new syntax for filtering node labels. In Neo4j v5, the following logical expressions were introduced to allow more flexible node filtering.
你将首先学习过滤节点标签的新语法。在 Neo4j v5 中,引入了以下逻辑表达式,以允许更灵活的节点过滤。
- & — AND expression & — 与表达式
- | — OR expression — 或运算表达式
- ! — NOT expression — 非运算表达式
For example, if you want to match all nodes with either the Fremen or Harkonnen label, you can use the | expression.
例如,如果你想匹配所有带有 Fremen 或 Harkonnen 标签的节点,你可以使用|运算表达式。
MATCH (c:Fremen|Harkonnen)
RETURN count(*)
On the other hand, if you need to find all nodes with both the Character and Harkonnen labels, you can use the & expression.
另一方面,如果你需要找到同时具有 Character 和 Harkonnen 标签的所有节点,你可以使用 & 表达式。
MATCH (c:Character&Harkonnen)
RETURN count(*)
The ! expression allows you to negate node labels. For example, say that you want to match all nodes with the Character label but don’t have the Harkonnen label.
! 表达式允许你否定节点标签。例如,假设你想要匹配所有具有 Character 标签但不具有 Harkonnen 标签的节点。
MATCH (c:Character&!Harkonnen)
RETURN count(*)
The Cypher now also supports nested expressions for filtering node labels. For example, the following Cypher statement matches all nodes that don’t have the Fremen or the Harkonnen labels.
Cypher 现在还支持用于过滤节点标签的嵌套表达式。例如,以下 Cypher 语句匹配所有没有 Fremen 或 Harkonnen 标签的节点。
MATCH (c:!(Fremen|Harkonnen))
RETURN count(*)
The expressions are nested using the parenthesis ().
表达式使用括号()进行嵌套。
Another feature added to Cypher is the option to include the WHERE clause within the MATCH clause. This allows you to apply all the flexibility of the Cypher filtering by node properties directly within the MATCH statement.
Cypher 增加的另一个特性是在 MATCH 子句中包含 WHERE 子句的选项。这允许您在 MATCH 语句中直接应用所有基于节点属性的 Cypher 过滤的灵活性。
For example, the following Cypher statement matches all characters where the Culture property starts with Z and the Died property is not null.
例如,以下 Cypher 语句匹配所有 Culture 属性以 Z 开头且 Died 属性不为空的角色。
MATCH (c:Character WHERE c.Culture STARTS WITH "Z" AND c.Died IS NOT NULL)
RETURN c.name AS character
The same logical expressions used to filter nodes can also be used when filtering relationship types. For example, the | expression, which expresses the logical OR, has been in Cypher for quite some time.
用于过滤节点的相同逻辑表达式也可用于过滤关系类型。例如,表示逻辑“或”的 | 表达式已经在 Cypher 中存在一段时间了。
The following Cypher statement matches all Character nodes with the Culture property values of Bene Gesserit and expands their ALLIES or FAMILY relationships.
以下 Cypher 语句匹配所有具有 Culture 属性值为 Bene Gesserit 的 Character 节点,并扩展他们的 ALLIES 或 FAMILY 关系。
MATCH p=(c:Character WHERE c.Culture = "Bene Gesserit")-[r:ALLIES|FAMILY]-()
RETURN [n in nodes(p) | n.name] AS pairs, type(r) AS results
Using only the & expression does not really make sense as a single relationship cannot have more than one type. However, the combined with the negation ! expression the & can come in handy.
仅使用 & 表达式实际上没有太大意义,因为单个关系不能有超过一种类型。然而,结合否定 ! 表达式,& 可以派上用场。
For example, the following Cypher statement expands all relationships that are not ALLIES or FAMILY.
例如,以下 Cypher 语句扩展了所有不是 ALLIES 或 FAMILY 的关系。
MATCH p=(c:Character WHERE c.Culture = "Fremen")-[r:!ALLIES&!FAMILY]-()
RETURN [n in nodes(p) | n.name] AS pairs, type(r) AS results
Existential subqueries 存在量子查询
Next, you will learn how the syntax for existential subqueries changed. An existential subquery can be used to find graph patterns that are part of a specified pattern.
接下来,你将学习存在量子查询的语法是如何变化的。存在量子查询可以用来找到作为指定模式一部分的图模式。
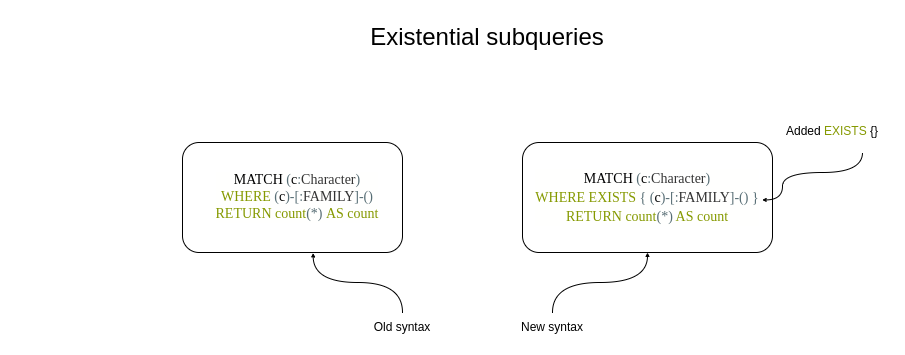
Syntax change for existential filters. Image by the author.
存在性过滤器的语法变更。图片由作者提供。
In this example, the existential subquery is used to find Character nodes that have either incoming or outgoing FAMILY relationships. I am a fan of existential subqueries as they offer the flexibility to filter nodes based on any graph patterns without having to expand them in the MATCH clause and worry about query cardinality (number of rows). In Neo4j v5, you have to add the EXISTS clause and wrap the specified graph pattern used for filtering with curly brackets in order to execute existential subqueries.
在这个例子中,使用存在性子查询来查找具有进入或离开 FAMILY 关系的角色节点。我是存在性子查询的粉丝,因为它们提供了基于任何图模式过滤节点的灵活性,而无需在 MATCH 子句中展开它们,并担心查询基数(行数)。在 Neo4j v5 中,您必须添加 EXISTS 子句,并用花括号括起用于过滤的指定图模式,才能执行存在性子查询。
MATCH (c:Character)
WHERE exists { (c)-[:FAMILY]-() }
RETURN count(*) AS count
Additionally, you can now introduce new reference variables in the existential subqueries. For example, the following existential subquery filters Character nodes with a FAMILY relationship. However, only the patterns where the end node of the FAMILY relationship has both the ALLIES and the MARRIAGE relationship are considered.
此外,您现在可以在存在性子查询中引入新的引用变量。例如,以下存在性子查询过滤具有 FAMILY 关系的角色节点。然而,只有在 FAMILY 关系的结束节点同时具有 ALLIES 和 MARRIAGE 关系的模式才被考虑。
MATCH (c:Character)
WHERE exists { (c)-[:FAMILY]-(t)
WHERE (t)-[:ALLIES]-() AND (t)-[:MARRIAGE]-() }
RETURN count(*) AS count
You may also see examples of a MATCH clause used within the existential subquery. Based on my experience, the MATCH clause is entirely optional. However, it might make the existential subquery syntax more readable and intuitive.
您还可以看到在存在子查询中使用 MATCH 子句的示例。根据我的经验,MATCH 子句完全是可选的。然而,它可能使存在子查询的语法更易于阅读和直观。
MATCH (c:Character)
WHERE exists { MATCH (c)-[:FAMILY]-(t)
WHERE (t)-[:ALLIES]-() AND (t)-[:MARRIAGE]-() }
RETURN count(*) AS count
Check out the documentation for more examples of existential subqueries.
查看文档以获取更多存在子查询的示例。
Count subqueries 计数子查询
The last category of subqueries in this post is the so-called count subqueries. They are used to count the number of defined graph patterns. For example, I frequently used them in my previous blog posts to count the number of relationships a node has.
本帖子中子查询的最后一个类别是所谓的计数子查询。它们用于计算已定义图形模式的数量。例如,我经常在我以前的博客文章中使用它们来计算一个节点有多少关系。
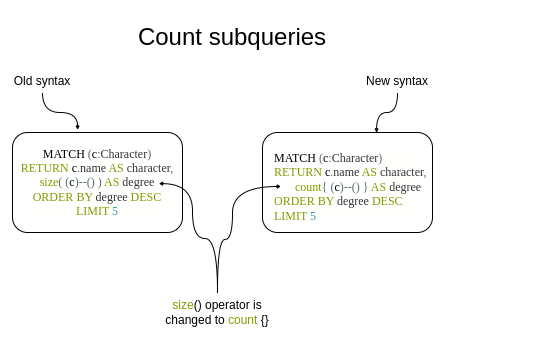
Syntax change for counting subqueries. Image by the author.
计数子查询的语法变更。图片由作者提供。
Previously, you could wrap a graph pattern with the size() in order to count the number of particular patterns. It is a handy syntax to count graph patterns without affecting the cardinality of the main query. Additionally, it might outperform other approaches to counting the number of relationships. In Neo4j v5, you need to replace the size() operator with the count{}.
以前,你可以用 size() 包装一个图形模式来计算特定模式的数量。这是一种方便的语法,可以在不影响主查询基数的情况下计算图形模式的数量。此外,它可能比其他计算关系数量的方法性能更好。在 Neo4j v5 中,你需要用 count{} 替换 size() 操作符。
The following Cypher statement returns the top five Character node ordered by their degree (relationship count).
下面的 Cypher 语句按照它们的度数(关系计数)返回前五个角色节点。
MATCH (c:Character)
RETURN c.name AS character,
count{ (c)--() } AS degree
ORDER BY degree DESC
LIMIT 5
As before, you can filter nodes by using the counting subqueries in a WHERE clause. In this example, the Cypher statement filters nodes with more than relationships.
如同之前,你可以使用 WHERE 子句中的计数子查询来过滤节点。在这个例子中,Cypher 语句过滤了具有多于某个数量关系节点。
MATCH (c:Character)
WHERE count{ (c)--() } > 2
RETURN count(*) AS count