一致哈希算法
如何使用一致哈希算法实现哈希寻址
我们一起来看一个例子,对于1000万个key的3节点KV存储,如果我们使用一致哈希算法增加1个节点,即3节点集群变为4节点集群,则只需要迁移24.3%的数据,如代码所示
package main
import (
"flag"
"fmt"
"log"
"stathat.com/c/consistent"
"strconv"
)
var keysPtr = flag.Int("keys", 10000, "key number")
var nodesPtr = flag.Int("nodes", 3, "node number of old cluster")
var newNodesPtr = flag.Int("new-nodes", 4, "node number of new cluster")
func hash(key int, nodes int) int {
return key % nodes
}
func main() {
flag.Parse()
var keys = *keysPtr
var nodes = *nodesPtr
var newNodes = *newNodesPtr
c := consistent.New()
for i := 0; i < nodes; i++ {
c.Add(strconv.Itoa(i))
}
newC := consistent.New()
for i := 0; i < newNodes; i++ {
newC.Add(strconv.Itoa(i))
}
migrate := 0
for i := 0; i < keys; i++ {
server, err := c.Get(strconv.Itoa(i))
if err != nil {
log.Fatal(err)
}
newServer, err := newC.Get(strconv.Itoa(i))
if err != nil {
log.Fatal(err)
}
if server != newServer {
migrate++
}
}
migrateRatio := float64(migrate) / float64(keys)
fmt.Printf("%f%%\n", migrateRatio*100)
}
go run ./consistent-hash.go -keys 10000000 -nodes 3 -new-nodes 4
24.301550%
你看,使用了一致哈希算法后,我们需要迁移的数据量仅为使用哈希算法时的三分之一,是不是大大提升了效率呢?
总的来说,使用一致哈希算法在扩容或缩容时,都只需要重定位环空间中的一小部分数据。也就是说,一致哈希算法具有较好的容错性和可扩展性。需要注意的是,在哈希寻址中常出现这样的问题:客户端访问请求集群在少数的节点上,导致有些机器高负载,有些机器低负载的情况。那么有什么办法能让数据访问分布得比较均匀呢?答案就是虚拟节点。
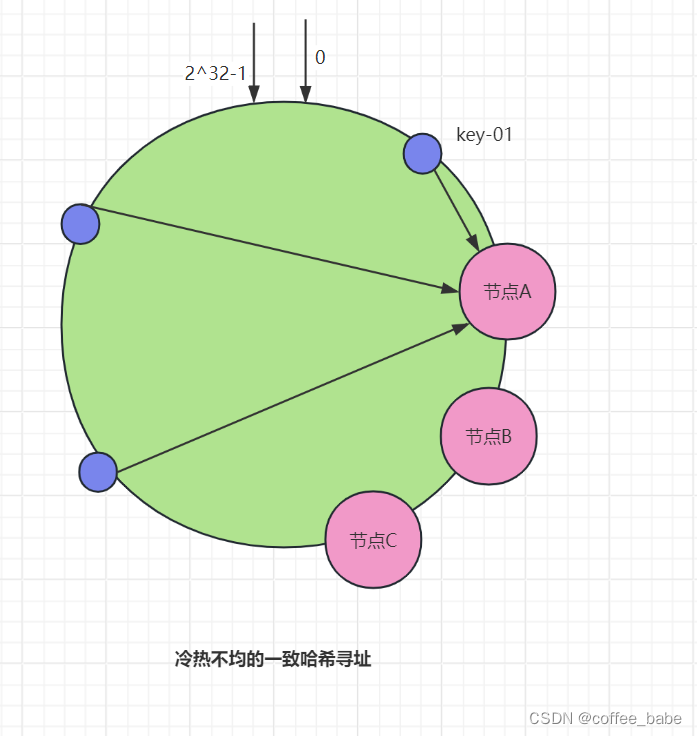
在一致哈希算法中,如果节点太少,则很容易因为节点分布不均匀造成数据访问的冷热不均,也就是说,大多数访问请求都会集中少量几个节点上,如图所示。从图中可以看到,虽然集群有3个节点,但访问请求主要集中在节点A上。那么如何通过虚拟节点解决冷热不均的问题呢?
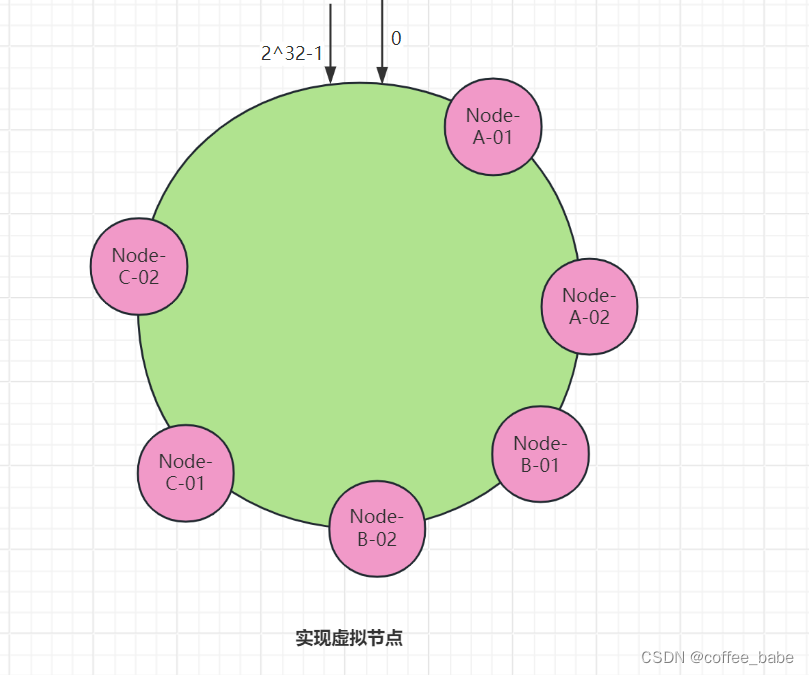
其实,可以对每一个服务器节点计算多个哈希值,在每个计算结果位置上都放置一个虚拟节点,并将虚拟节点映射到实际节点。比如,在主机名的后面增加比那好,分别计算Node-A-01、Node-A-02、Node-B-01、Node-B-02、Node-C-01、Node-C-02的哈希值,形成6个虚拟节点,如图所示,可以从图中看到,增加了节点后,节点在哈希环上的分布就相对均匀了,这时,如果有访问请求寻址到Node-A-01这个虚拟节点,将被重定位到节点A。你看这样我们就解决了冷热不均匀的问题。可能有人已经发现了,节点数越多,使用哈希算法时需要迁移的数据就越多,而使用一致哈希算法时需要迁移的数据就越少,如代码清单所示
go run ./hash.go -keys 10000000 -nodes 3 -new-nodes 4
74.999980%
go run ./hash.go -keys 10000000 -nodes 10 -new-nodes 11
90.909000%
go run ./consistent-hashgo.go -keys 10000000 -nodes 3 -new-nodes 4
24.301550%
go run ./consistent-hashgo.go -keys 10000000 -nodes 10 -new-nodes 11
6.479330%
从示例代码的输出中可以看到,当我们向10节点集群中增加节点时,如果使用哈希算法,则需要迁移高达90.91%的数据,如果使用一致哈希算法,则需要迁移6.48%的数据。
需要注意的是,使用一致哈希算法实现哈希寻址时,可以通过增加节点数来降低节点宕机对整个集群的影响,以及故障恢复时需要迁移的数据量。后续在需要时,你也可以通过增加节点数来提升系统的容灾能力和故障恢复效率。
思考
Raft集群具有容错能力,能容忍少数的节点故障,那么在多个Raft集群组成的KV系统中,如何设计一致哈希算法,以实现当某个集群的领导者节点出现故障并选举出新的领导者后,整个系统还能稳定运行呢?
在多个Raft集群组成的KV系统中,设计一致哈希算法以实现领导者节点故障后系统的稳定运行,需要确保在领导者节点变更时,数据的一致性和服务的连续性。以下是一些建议的步骤和考虑因素:
- 1.虚拟节点和环形哈希空间:
一致哈希算法通过引入虚拟节点和环形哈希空间,实现了节点动态扩缩容时数据迁移的最小化。在Raft集群组成的KV系统中,每个Raft集群可以视为一个物理节点,并在其上创建多个虚拟节点。虚拟节点能够平滑地将数据分布到多个物理节点上,减少单个物理节点故障对系统的影响。 - 2.领导者故障检测与恢复:
当某个Raft集群的领导者节点出现故障时,该集群内部会通过Raft的领导者选举机制选举出新的领导者。KV系统需要监控Raft集群的状态,并在检测到领导者节点故障时,更新其内部的一致哈希映射,确保新的领导者节点能够接管服务。 - 3.数据同步与一致性:
在领导者节点故障期间,可能会有一些数据尚未同步到新的领导者节点。因此,在选举出新的领导者后,需要确保数据的同步和一致性。
这可以通过Raft的日志复制机制来实现。新的领导者节点可以从其他跟随者节点那里拉取缺失的日志条目,并应用到状态机中以更新系统状态。 - 4.路由与负载均衡:
一致哈希算法通过计算键的哈希值,并将其映射到环形哈希空间上的某个虚拟节点,从而确定数据的存储位置。在多个Raft集群组成的KV系统中,需要设计一种路由机制,使得客户端能够根据键的哈希值将数据路由到正确的Raft集群和虚拟节点上。同时,还需要考虑负载均衡的问题,确保各个Raft集群之间的负载相对均衡。 - 5.故障恢复与容错性:
在设计系统时,需要考虑各种可能的故障场景,并制定相应的故障恢复策略。
例如,当某个Raft集群完全故障时,系统需要能够自动将其从一致哈希映射中移除,并将该集群上的数据迁移到其他健康的集群上。
此外,还需要考虑如何在不影响系统稳定性的前提下,对系统进行扩容和缩容。
6.测试与验证:
在实际部署之前,需要对系统进行充分的测试和验证,以确保其能够在各种故障场景下稳定运行。
这包括单元测试、集成测试、压力测试等不同类型的测试。
综上所述,设计一致哈希算法以实现多个Raft集群组成的KV系统的稳定运行,需要综合考虑虚拟节点、领导者故障检测与恢复、数据同步与一致性、路由与负载均衡、故障恢复与容错性以及测试与验证等多个方面。
重点总结
- 1.一致哈希算法是一种特殊的哈希算法,该算法可以使节点增减变化时只影响到部分数据的路由寻址,也就是说我们只要迁移部分数据,就能实现集群的稳定了。
- 2.当节点数较少时,可能会出现节点在哈希环上分布不均匀的情况,即每个节点实际在环上占据的区间大小不一,最终导致业务对节点的访问冷热不均,而这个问题可以通过引入更多的虚拟节点来解决。
- 3.一致哈希算法本质上是一种路由寻址算法,适合简单的路由寻址场景,比如,在KV存储系统内部,它的特点是简单,不需要维护路由信息
有人可能会有这样的疑问:关于Raft算法的原理以及一致哈希算法如何突破集群"领导者"的限制,但是有的公司的配置中心、名字路由等使用的是ZooKeeper,那么ZAB协议是如何实现一致性的呢?ZAB协议和Raft算法又有什么不一样呢?