文章目录

早期都是单库单表
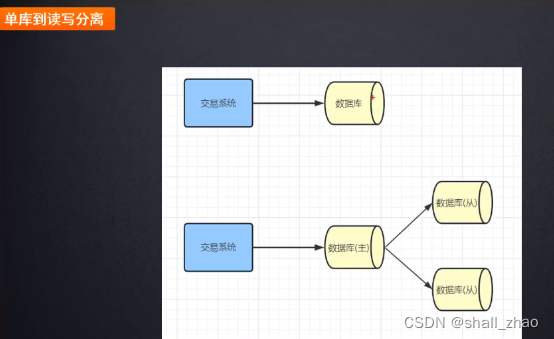
读多写少——主库用来写,从库用来读
主库写完了之后,同步到从数据库,通过从数据库分担压力
中小公司完全OK
单库的写压力太大——数据库的垂直和水平拆分
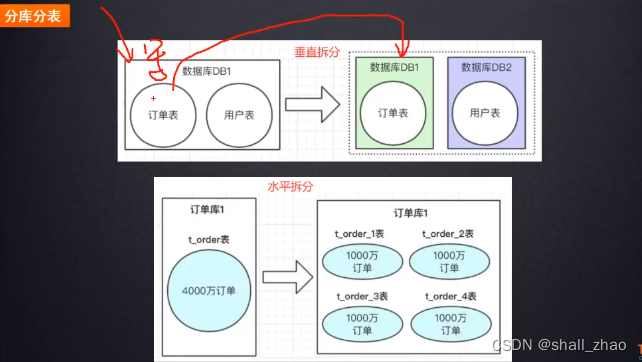
垂直拆分——比如微服务架构,根据不同业务我们拆分微服务应用,数据库的表也要按照业务分开。
水平拆分——虽然拆分成单表,如果一张表的量超过500万或1000万,数据的增量太快,这里假如到达4000万,就要把一张订单表拆成多张表。
垂直分库,水平分表
分表怎么分呢?
hash分表
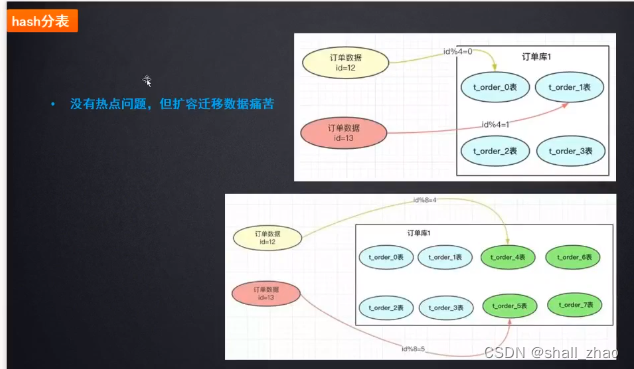
hash分表的方式有个问题——假如分的四张表又快满了,还要再拆表,那总共八张表了,按照以前的**id%(表的个数)**的办法落在其他表中,以前的算法落得表和现在不一是同一个表了,查不到了,所以必须要把老数据做一次迁移。
数据迁移扩容痛苦
range分表
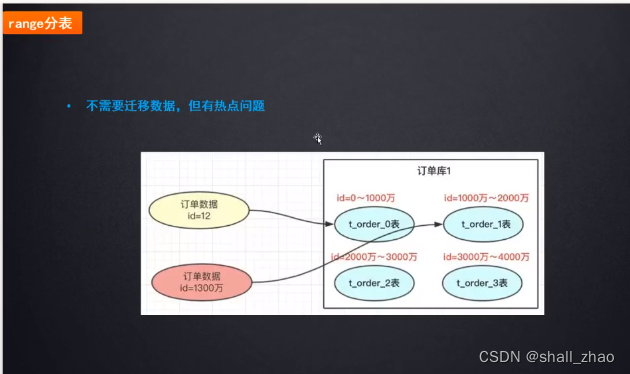
就是把数据按照范围顺序放,这样根据id算一下在什么范围,即使扩容了也可以找到。
当订单id在1000万以内,操作同一张表,如果并发特别大,压力特别大,那各种修改,新增,加大量的锁,性能肯定受影响。
这个问题就叫热点的问题
多数据源操作与分布式事务问题
其实市面上有很多很好的分库分表框架,直接用
ShardingSphare分库分表(京东开源)
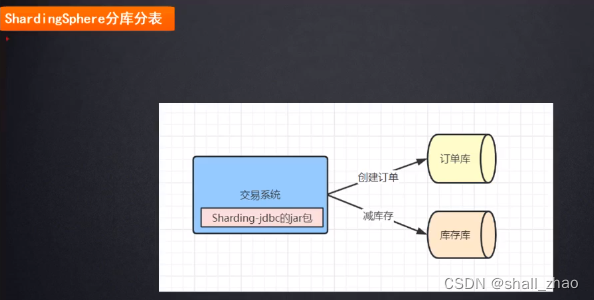
非常轻量,
内部有很多的组件,Sharding-jdbc组件,其实就是帮我们做分库分表的,做好分库分表的配置文件,按照什么字段,什么规则配置好。
关联查询怎么办?跨多个库,多张表怎么办?——要考虑业务场景

从用户端思考,对于一个用户,我们尽量让他的数据落在一个库,一张表,这样查起来容易得多。用userId来分,这样插用户信息免费,那查订单呢?在orderId后面拼接上serId(后四位)
商家端:用商家的id作为分库分表的字段合适,上面的规则不适用了啊?查商家的订单就要跨库了呀,在互联网公司,商家端的数据会单独再存一份。按照商家端的id做路由分库分表。
运营管理端:要查全量数据,怎么办?
如果非实时的情况,可以把全量的数据放到数据仓库中(大数据),查的比较慢,可以走数据仓库;
如果要求实时的话(elasticsearch),一般需求是定好的,我们根据要查询的几个维度的字段,建立索引到ES的大宽表,这时候查起来就很快了。
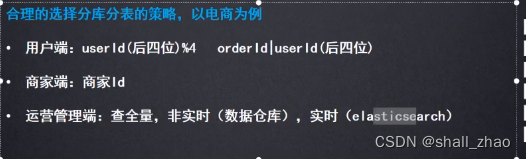
线上单库如何迁移到多库多表
一般都是不停机迁移,但前段不断有新的增删改查操作来修改数据,我们的迁移是把数据复制过去,这时候要是来了一条修改已迁移的数据,怎么办?难道重头扫一遍吗?
监听binlog
数据库的binlog日志,
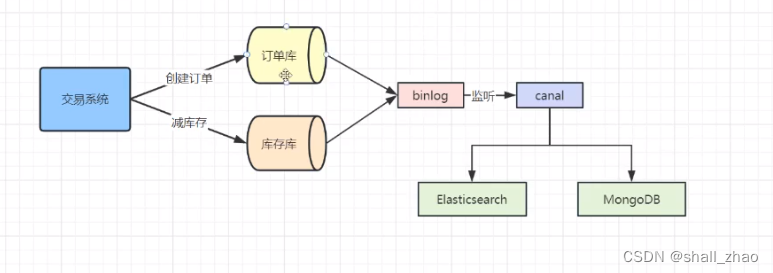
数据库有很多日志的,面试的时候很经常问。
binlog用来记录数据库的所有修改操作,
后端虽然在做全量的迁移,实时的增删改的操作,我们可以拿出来写进我们的新系统(多库多表),这样就同步了。
依旧有问题——临界的时候
insert一条语句,sql执行了一次,在迁移完成后,binlog在新数据库又执行了一次,会逐渐冲突(不过这个问题不大)。
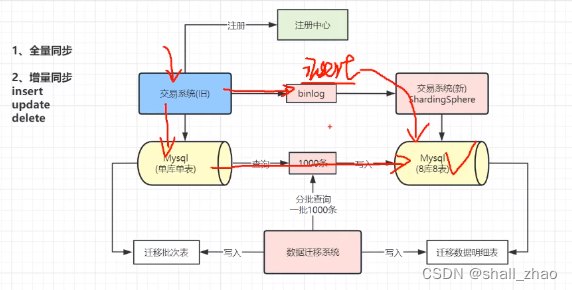
update语句和delete语句问题大了。
假设update语句修改了单库单表,还没更新的时候,这时候被迁移查到了,准备写到多库多表,还没写成功的时候,这时候binlog更新了多库多表,查不到就更新为空,这时候老库的数据迁移过来了,实际写入多库多表的数据是旧数据。
delete同样在临界的时候会有问题。
过一段时间把binlog的执行失败的sql语句从新做一遍
binlog执行失败的sql丢到队列中去,过一段时间重新执行。
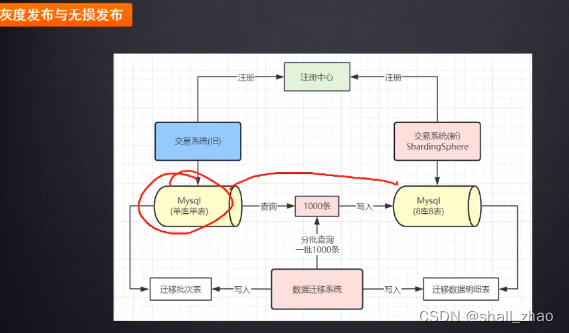
又有问题了——数据达到一致后,直接上线吗?——灰度发布
搞一小部分流量先打过来,看数据能不能进入到我们的多库多表,试探一下数据是不是正确,没问题了再全部上线。
灰度发布时间不能太长,否则会造成很多的报错,比如有个请求打到单库单表,而这个数据在多库多表中,这就报错啦。所以不能太长时间。
无损发布
就是把单库单表的数据断掉,直接把多库多表全流量切换上线。
这要是有问题的话,回退比较麻烦
所以一般采用的是灰度发布
既想要解决数据热点的问题,又想不做数据迁移
我们设计一套分库分表方案,并且解决热点问题?
TiDB 分布式数据库
这就不用做分库分表了,很多事情他帮我们做了。
后面就是卖课广告了