看到Stream流这个概念,我们很容易将其于IO流联系在一起,事实上,两者并没有什么关系,IO流是用于处理数据传输的,而Stream流则是用于操作集合的。
当然,为了方便我们区分,我们依旧在这里复习一下IO流的相关知识。
1.什么是IO流?
IO: output: input流:像水流一样传输数据
2.IO流的作用?
用于读写数据(本地文件,网络)存储和读取数据的解决方案
3.IO流按照流向可以分类哪两种流?
输出流:程序
输入流:文件
4.IO流按照操作文件的类型可以分类哪两种流?
字节流:可以操作所有类型的文件
字符流:只能操作纯文本文件
5.什么是纯文本文件?
用windows系统自带的记事本打开并且能读懂的文件txt文件,md文件,xml文件,lrc文件等
在学习Stream流之前,我们需要先学习Lambda表达式的用法。,这涉及到几个概念,分别是函数式编程,匿名内部类
函数式编程
函数式接口(Functional Interface)就是一个有且仅有一个抽象方法,但是可以有多个非抽象方法的接口。
匿名内部类
假设我们有一个接口A
内部有一个未被实现的方法eat
如果我们想在main中直接调用eat方法
Lambda表达式
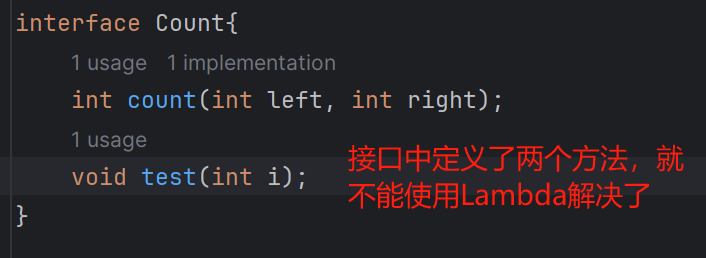
Lambda该怎么用呢?其可以用在只有一个方法的接口上。
Function<T, R> 是 Java 8 中的一个函数式接口,
用于表示接受一个输入参数 T,并返回一个结果 R 的函数。
Function接口中有一个抽象方法apply,用于定义函数的逻辑。
Function接口通常用于将数据进行转换、映射或者执行某种转换操作。
通过这种函数式接口,我们可以实现不同的操作。
package Lambda;
import java.util.function.Function;
public class Lambda1 {
public static void main(String[] args) {
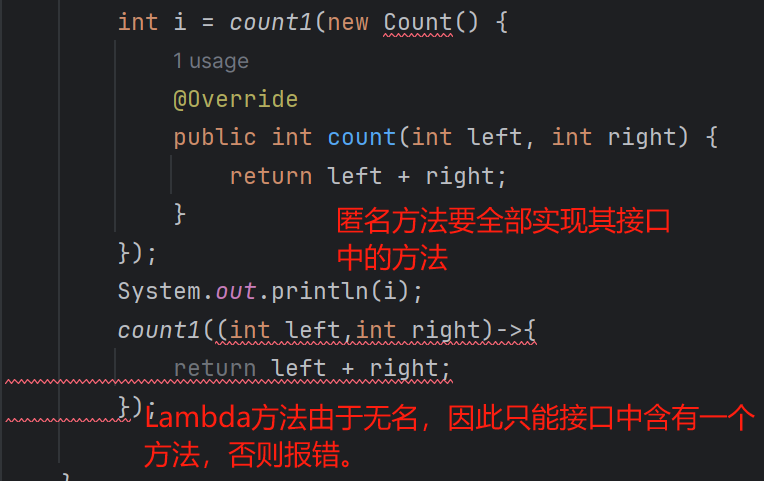
//使用匿名内部类,直接重写接口中的方法,省去创建实现类实现接口的过程和创建实现类对象的过程。
Integer i = TypeConver(new Function<String, Integer>() {
@Override
public Integer apply(String s) {
return Integer.valueOf(s);
}
});
System.out.println(i);
Integer m = TypeConver((String s) ->{return Integer.valueOf(s);});
System.out.println(m);
//Lambda实现字符串拼接
String string = TypeConver((String str) -> {
return str + "你好";
});
System.out.println(string);
}
public static <R> R TypeConver(Function<String,R> function){
String str="12345";
R result=function.apply(str);
return result;
}
}
案例4:对IntConsumer接口进行实现。
package Lambda;
import java.util.function.IntConsumer;
public class Lambda2 {
public static void main(String[] args) {
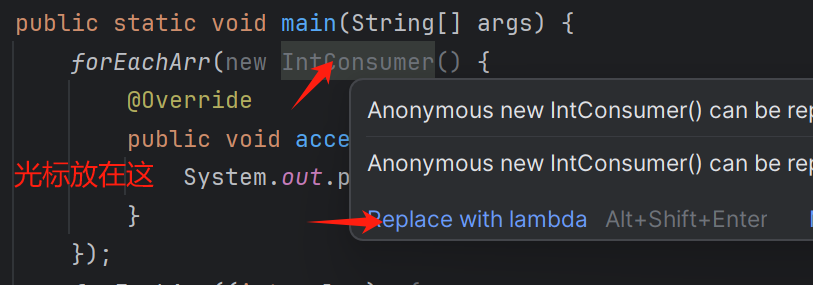
forEachArr(new IntConsumer() {
@Override
public void accept(int value) {
System.out.println(value);
}
});
forEachArr((int value)->{
System.out.println(value);
});
}
public static void forEachArr(IntConsumer intConsumer){
int[] arr={1,2,3,4,5,6,7,8};
for(int i:arr){
intConsumer.accept(i);
}
}
}
事实上,我们可以将含有匿名内部类的写法直接一键转化为Lambda表达式的形式。
由此可见,Lambda就是对匿名内部类的优化。
Stream流
学完了Lambda表达式,我们来看看Stream到底是如何操作集合的,尽管集合中为我们提供了大量的方法,但在Stream操作面前根本不值一提。
场景:获取List中元素含"州"的元素,并放入一个List集合中。Stream支持链式编程与Lamba表达式
下面首先是通过我们的一般方法来实现
List<String> citys=hashMap.get("江苏省");
for (String c:citys){
System.out.println(c);
}
List<String> cs1=new ArrayList<>();
for(String city:citys){
if(city.contains("州")){
cs1.add(city);
}
}
System.out.println(cs1);
使用Stream实现,当然,这里的forEach只是将其输出了一下,并没有将其放到一个新的List中。
citys.stream().filter(new Predicate<String>() {
@Override
public boolean test(String s) {
return s.contains("州");
}
}).forEach(new Consumer<String>() {
@Override
public void accept(String s) {
System.out.println(s);
}
});
通过Stream与Lambda实现:
List<String> cs2=citys.stream()
.filter(s->s.contains("州"))
.collect(Collectors.toList());
Stream的流操作涉及三个过程,分别是流创建,中间操作以及结束操作,如果我们不启用结束操作,那么中间操作的过程也是不会执行的。
创建流
package Stream;
import java.util.*;
import java.util.stream.Stream;
public class CreateStream {
public static void main(String[] args) {
//列表创建Stream
List list=new ArrayList<>();
Collections.addAll(list, 1,2,3,4,5);
Stream stream = list.stream();
stream.filter(o -> {
int i= (int) o;
return i>=2;
}).forEach(o -> System.out.print(o));
//数组创建Stream
Integer[] arr={1,2,3,4,5,6,7,8};
Stream<Integer> stream1 = Arrays.stream(arr);
Stream<Integer> stream2 = Stream.of(arr);
stream1.filter(s->s>=2).forEach(s->System.out.print(s));
stream2.forEach(s->{
System.out.print(s);
});
//对于双列集合,将其转换为单列集合后再创建Stream流
HashMap<String, Integer> hashMap = new HashMap<>();
hashMap.put("李白",135);
hashMap.put("杜甫",123);
hashMap.put("白居易",234);
//通过entrySet方法可以将map转换为set
Set<Map.Entry<String, Integer>> entries = hashMap.entrySet();
System.out.println();
//set可以创建stream流
Stream<Map.Entry<String, Integer>> stream3 = entries.stream();
stream3.forEach(s->{
System.out.println(s);
});
}
}
中间操作
filter操作
filter,筛选操作,我们先前已经使用过了。
map操作
map,可以对流中的元素进行计算与转换。如下,通过map操作,将原本列表中的对象转换为字符串
list.stream().filter(new Predicate<Author>() {
@Override
public boolean test(Author author) {
return author.getAge()>50;
}
}).forEach(new Consumer<Author>() {
@Override
public void accept(Author author) {
System.out.println(author);
}
});

list.stream().filter(new Predicate<Author>() {
@Override
public boolean test(Author author) {
return author.getAge()>50;
}
}).map(new Function<Author, String>() {
@Override
public String apply(Author author) {
return author.getName();
}
}).forEach(new Consumer<String>() {
@Override
public void accept(String s) {
System.out.println(s);
}
});
可以看到,通过map操作,将原本流中的对象转换为字符串

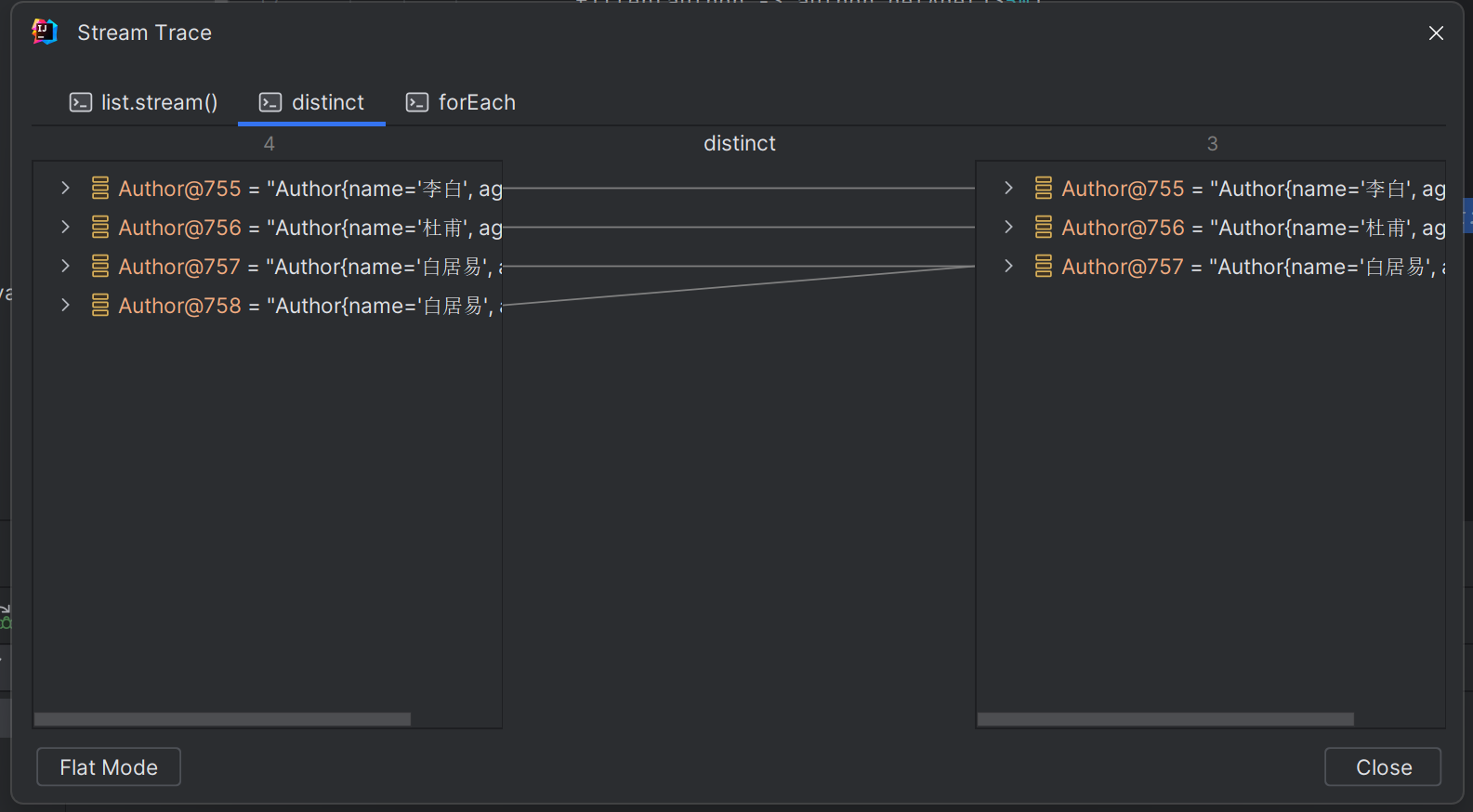
distinct操作
去除流中的重复元素。其内部是依靠Object中的equals方法来实现的,因此可能需要重写equals方法。
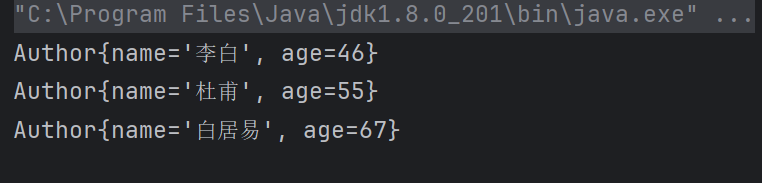
list.add(new Author("李白",46));
list.add(new Author("杜甫",55));
list.add(new Author("白居易",67));
list.add(new Author("白居易",67));
list.stream().distinct().forEach(author -> System.out.println(author));

这里推荐一个插件 Java Stream Debugger,可以方便我们对Stream进行调试。
sorted操作
sorted共有两个,分别是空参的与非空参的。其中空参的那个需要我们在类上实现Comparable接口的方法,而非空参则采用在sorted中实现排序比较。
我们先来试一下无参的sorted。
ArrayList<Author> list = new ArrayList<>();
list.add(new Author("李白",46));
list.add(new Author("杜甫",55));
list.add(new Author("白居易",67));
list.add(new Author("白居易",67));
list.stream().sorted().forEach(author -> System.out.println(author));
发生报错,说要让我们去实现Comparable接口

package Stream;
import java.util.Objects;
public class Author implements Comparable<Author>{
private String name;
private Integer age;
public String getName() {
return name;
}
public Integer getAge() {
return age;
}
@Override
public int compareTo(Author o) {
return this.getAge()-o.getAge();
}
}
随后再次运行即可。
那么带参数的该怎么做呢?
list.stream().distinct().sorted(new Comparator<Author>() {
@Override
public int compare(Author o1, Author o2) {
return o2.getAge()-o1.getAge();
}
}).forEach(author -> System.out.println(author));
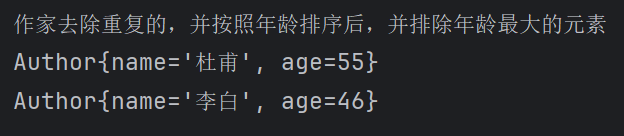
limit操作
设置流的最大长度,超出的将被抛弃。设置排序后的前2个。
list.stream().distinct().sorted((o1, o2) -> o2.getAge()-o1.getAge())
.limit(2)
.forEach(author -> System.out.println(author));

skip操作
跳过流中的前n个元素,返回后面的元素。
flatMap操作
先前所接触的map可以将一个对象转换为另一个对象,而flatMap可以将一个对象转换为多个对象作为流中的元素。
下面的代码是什么意思呢,事实上,他是将原本的Author中的Book提取处理,由原本一个Author变为多个Book。
authors.stream().distinct()
.map(author -> author.getBooks())
.forEach(books -> System.out.println(books));

authors.stream().distinct().flatMap(new Function<Author, Stream<Books>>() {
@Override
public Stream<Books> apply(Author author) {
return author.getBooks().stream();
}
}).forEach(new Consumer<Books>() {
@Override
public void accept(Books books) {
System.out.println(books);
}
});
其对应的lambda表达式的写法:
authors.stream().distinct()
.flatMap(author -> author.getBooks().stream())
.forEach( books -> System.out.println(books));

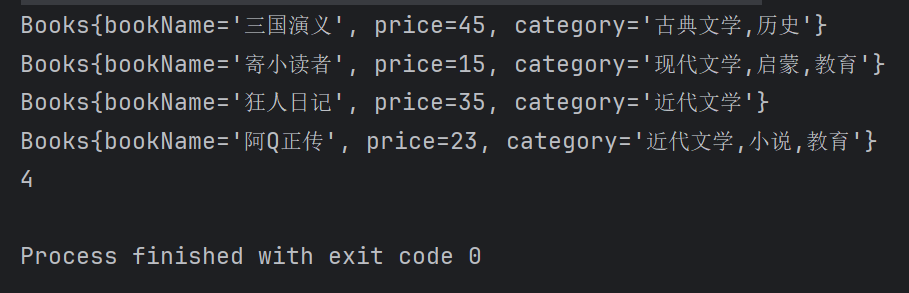
接下来我们再通过一个案例来看看flatMap的作用,我们的书籍类中有一个类别属性,其属性内含有多个值,我们是这样定义的:

我们希望这个类别值能够按",”分开,因此也使用flatMap实现:
List<Author> authors=getAuthors();
authors.stream().distinct().flatMap(new Function<Author, Stream<Books>>() {
@Override
public Stream<Books> apply(Author author) {
return author.getBooks().stream();
}
}).distinct().flatMap(new Function<Books, Stream<String>>() {
@Override
public Stream<String> apply(Books books) {
return Arrays.stream(books.getCategory().split(","));
}
}).forEach(new Consumer<String>() {
@Override
public void accept(String s) {
System.out.println(s);
}
});
对应的Lambda表达式如下:
authors.stream().distinct()
.flatMap( author -> author.getBooks().stream())
.distinct()
.flatMap( books -> Arrays.stream(books.getCategory().split(",")))
.forEach((Consumer<String>) s -> System.out.println(s));

终结操作
forEach操作
这个用于遍历输出流中的元素,前面我们已经用过多次了。
count操作
用于计算流中元素的数量,注意要删除重复元素。
统计这些作者发表的书籍的数目。
ArrayList<Author> authors = getAuthors();
authors.stream()
.flatMap( author -> author.getBooks().stream())
.distinct()
.forEach(books -> System.out.println(books));
long count = authors.stream()
.flatMap( author -> author.getBooks().stream())
.distinct().count();
System.out.println(count);
min与max操作
ArrayList<Author> authors = getAuthors();
Optional<Integer> max = authors.stream()
.flatMap(author -> author.getBooks().stream())
.distinct()
.map(new Function<Books, Integer>() {
@Override
public Integer apply(Books books) {
return books.getPrice();
}
}).max(new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o1 - o2;
}
});
System.out.println(max.get());
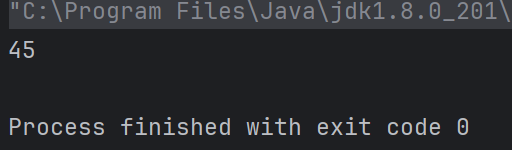
对应的Lambda表达式写法:
ArrayList<Author> authors = getAuthors();
Optional<Integer> max = authors.stream()
.flatMap(author -> author.getBooks().stream())
.distinct()
.map(books -> books.getPrice())
.max((o1, o2) -> o1 - o2);
System.out.println(max.get());
collect操作
将流中的元素转换为集合。集合分为三种,分别是List、Set以及Map。
需求:获取所有作者名字的集合
collect转换为List集合,如下:
ArrayList<Author> authors = getAuthors();
List<String> collect = authors.stream().map(new Function<Author, String>() {
@Override
public String apply(Author author) {
return author.getName();
}
}).distinct().collect(Collectors.toList());//我们不调用对象去写匿名方法,而是直接调用Collectors这个工具类
System.out.println(collect);
转换为Set的方式很类似,如下:
Set<String> collect1 = authors.stream().map(new Function<Author, String>() {
@Override
public String apply(Author author) {
return author.getName();
}
}).distinct().collect(Collectors.toSet());
System.out.println(collect1);
其对应的Lambda表达式如下:
ArrayList<Author> authors = getAuthors();
List<String> collect = authors.stream().map(author -> author.getName())
.distinct()
.collect(Collectors.toList());//我们不调用对象去写匿名方法,而是直接调用Collectors这个工具类
System.out.println(collect);
Set<String> collect1 = authors.stream().map(author -> author.getName())
.distinct().collect(Collectors.toSet());
System.out.println(collect1);
转换为Map,需要指定两个参数,分别是Key与Value,内部匿名方法实现如下:
Map<String, List<Books>> collect2 = authors.stream().distinct()
.collect(Collectors.toMap(new Function<Author, String>() {
@Override
public String apply(Author author) {
return author.getName();
}
}, new Function<Author, List<Books>>() {
@Override
public List<Books> apply(Author author) {
return author.getBooks();
}
}));
System.out.println(collect2);
对应的Labmbda表达式如下:
Map<String, List<Books>> collect2 = authors.stream().distinct()
.collect(Collectors.toMap( author -> author.getName(), author -> {
return author.getBooks();
}));
System.out.println(collect2);

anyMatch操作
该操作用于进行查找与匹配,其返回值为Boolean,如下面判断是否有作家年龄在80岁以上:
boolean b = authors.stream().anyMatch(new Predicate<Author>() {
@Override
public boolean test(Author author) {
return author.getAge() > 80;
}
});
System.out.println(b);
对应的Lambda表达式:
boolean b = authors.stream().anyMatch(author -> author.getAge() > 80);
allMatch操作
所有流元素是否满足条件,若满足则返回True,否则为False。判断所有作家是否都大于30岁。
ArrayList<Author> authors = getAuthors();
boolean b = authors.stream().allMatch(new Predicate<Author>() {
@Override
public boolean test(Author author) {
return author.getAge() > 30;
}
});
System.out.println(b);
findAny操作
findAny的返回值是Optional对象,返回值是其中一个流元素,即任意一个流元素,他可以调用ifPresent方法,即判断结果为否存在。
ArrayList<Author> authors = getAuthors();
Optional<Author> any = authors.stream().filter(new Predicate<Author>() {
@Override
public boolean test(Author author) {
return author.getAge() > 16;
}
}).findAny();
any.ifPresent(new Consumer<Author>() {
@Override
public void accept(Author author) {
System.out.println(author);
}
});
Lambda表达式写法。
ArrayList<Author> authors = getAuthors();
Optional<Author> any = authors.stream()
.filter(author -> author.getAge() > 16)
.findAny();
any.ifPresent(author -> System.out.println(author));

findFirst操作
findFirst返回查询的第一个结果。
ArrayList<Author> authors = getAuthors();
Optional<Author> first = authors.stream().sorted()
.distinct()
.findFirst();
System.out.println(first);

reduce操作
归并操作,reduce的作用是把stream中的元素给组合起来,按照指定方式得出一个结果,故又被称为缩减操作。reduce的作用是把stream中的元素给组合起来,我们可以传入一个初始值,它会按照我们的计算方式依次拿流中的元素和初始化值进行计算,计算结果再和后面的元素计算。
下面的代码即reduce的原理,可以看到,我们所需的值,一个是初始化值,另一个便是遍历的值了。
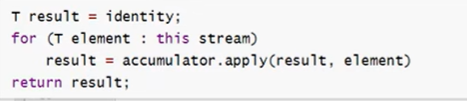
在使用reduce时,一般情况下都需要在前面加一个map用于转换,这在谷歌中十分常用。
计算作家的年龄之和:
ArrayList<Author> authors = getAuthors();
Integer reduce = authors.stream().distinct().map(new Function<Author, Integer>() {
@Override
public Integer apply(Author author) {
return author.getAge();
}
}).reduce(0, new BinaryOperator<Integer>() {
@Override
public Integer apply(Integer result, Integer element) {
return result + element;
}
});
System.out.println(reduce);
对应的Lambda表达式:
Integer reduce1 = authors.stream()
.distinct().map(author -> author.getAge())
.reduce(0, (result, element) -> result + element);
利用reduce求流元素中的最大值:其实我们max也可求出,事实上,max的实现就是reduce。通过指定的初始值为一个最小的int类型,此时第一次max的值即为Integer.MIN_VALUE,随后通过三目运算求出即可。
ArrayList<Author> authors = getAuthors();
Integer reduce = authors.stream().map(author -> author.getAge())
.reduce(Integer.MIN_VALUE, new BinaryOperator<Integer>() {
@Override
public Integer apply(Integer max, Integer element) {
return max > element ? max : element;
}
});
System.out.println(reduce);
对应的Lambda表达式:
Integer reduce1 = authors.stream().map(author -> author.getAge())
.reduce(Integer.MIN_VALUE, (max, element) -> max > element ? max : element);
上面的reduce方法中需要传递两个参数,分别是初始值以及BinaryOperator(一种操作对象)事实上,reduce还有其他形式,比如不指定初始值的情况,其计算原理如下:可以看到,它是将流元素中的第一个值赋值给初始值。
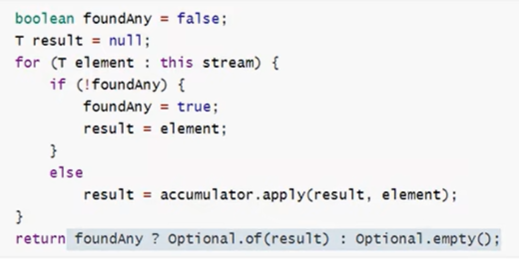
那么了解了这一种reduce的计算原理后,我们先前的计算最值似乎更简单了。
即无需指定初始值,直接计算即可。需要注意的是,其最终的返回值被封装为Optional,所以要调用get方法来获取值。
ArrayList<Author> authors = getAuthors();
Optional<Integer> reduce = authors.stream().map(author -> author.getAge())
.reduce(new BinaryOperator<Integer>() {
@Override
public Integer apply(Integer result, Integer element) {
return result > element ? result : element;
}
});
System.out.println(reduce.get());
如果不调用get方法,reduce的值为:
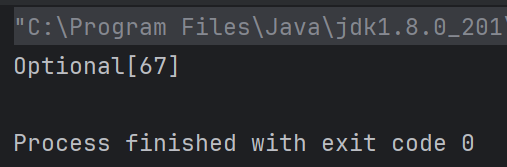
Stream注意事项
- 惰性求值(如果没有终结操作,没有中间操作是不会得到执行的)
- 流是一次性的(一旦一个流对象经过一个终结操作后。这个流就不能再被使用)
- 不会影响原数据(我们在流中可以多数据做很多处理。但是正常情况下是不会影响原来集合中的元素的。这往往也是我们期望的)正常情况下,只要你不调用set方法之类的。
比如下面我们已经将流使用过一次终结操作了,那么再次使用时便会报错:
ArrayList<Author> authors = getAuthors();
Stream<Author> stream = authors.stream();
stream.map(author -> author.getAge())
.reduce((result, element) -> result > element ? result : element);
stream.map(author -> author.getAge())
.reduce((result, element) -> result > element ? result : element);
Exception in thread "main" java.lang.IllegalStateException: stream has already been operated upon or closed
at java.util.stream.AbstractPipeline.<init>(AbstractPipeline.java:203)
at java.util.stream.ReferencePipeline.<init>(ReferencePipeline.java:94)
at java.util.stream.ReferencePipeline$StatelessOp.<init>(ReferencePipeline.java:618)
at java.util.stream.ReferencePipeline$3.<init>(ReferencePipeline.java:187)
at java.util.stream.ReferencePipeline.map(ReferencePipeline.java:186)
at Stream.Test4.main(Test4.java:18)