文章目录
四、存储器系统
4.1 存储器系统特性概述
- Cortex-M3处理器的存储器架构预先定义了存储器映射,其中指定了在访问某个存储器位置时,应该使用哪个总线接口。这个特性使得在访问不同设备时,处理器可以对这些访问进行优化。
- Cortex-M3存储器系统支持位段操作,可以为存储器或者外设中的位数据提供原子操作。只有一些特殊的存储器区域才支持位段操作。
- Cortex-M3存储器系统支持非对称访问和排他访问。
- 支持小端和大端两种配置。
4.2 存储器映射
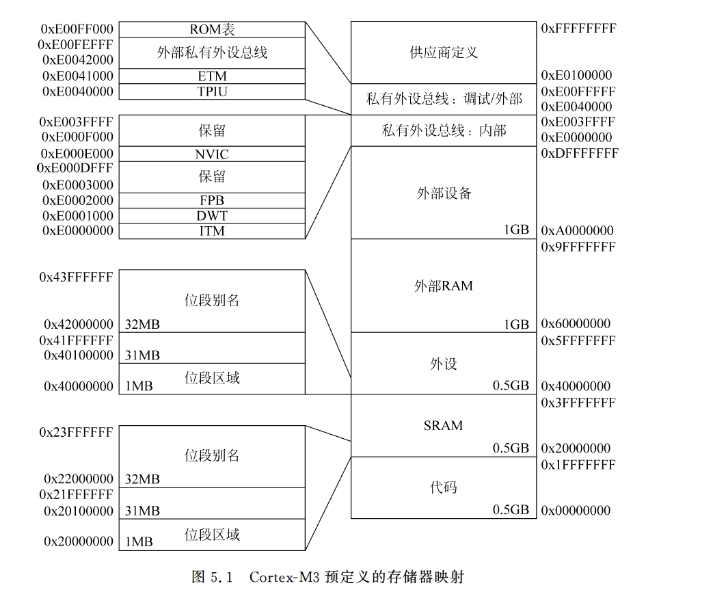
Cortex-M3处理器具有固定的存储器映射(见图5.1),这样Cortex-M3设备间的软件移植就变得更加容易了。例如,前面谈到的部件,如嵌套向量中断控制器(NVIC)和存储器保护单元(MPU)等,在所有Cortex-M3产品中的存储器位置都是相同的。不过,存储器映射具有极大的灵活性,生产厂家可以在他们基于Cortex-M3的产品中加入自己的设计。
有些存储器位置被定义为像调试部件之类的私有外设,它们位于私有外设存储器区域,这些调试部件包括:
- ITM:指令跟踪宏单元
- DWT:数据监视点和跟踪单元
- FPB:Flash补丁和断点单元
- TRIU:跟踪端口接口单元
- ETM:嵌入式跟踪宏单元
- ROM表
在后面介绍调试特性的章节中,会有这些部件的详细信息。
Cortex-M3处理器总共具有4GB的地址空间,程序代码可以位于:
- 代码区。
- 静态随机访问存储器SRAM区域。
- 外部RAM区域。
不过程序代码最好位于代码区域,因为这样处理器可以同时在两个独立的总线接口上执行取址和数据访问。
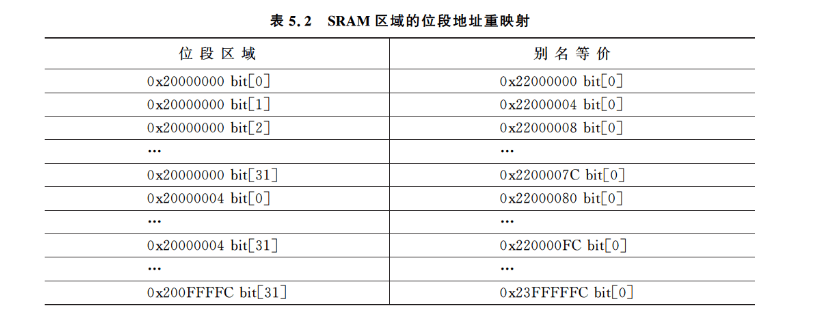
SRAM存储器区域用于连接内部SRAM,对这个区域的访问要经过系统接口总线,在这个区域,32MB被定义为位段别名。在该32位位段别名存储器区域中,每个字地址代表 1MB位段区域的一个位。对位段别名存储器区域的写访问,会被转换为对位段区域的读-修改-写访问的原子操作。位段区域仅用于数据访问,而不是取指。通过将Boolean信息(单个位)放入位段区域,我们可以把多个Boolean数据打包成一个字,而且它们还可以通过位段别名单独访问,因此,这种无须软件实现读-修改-写的操作可以节省存储器空间。本章稍后有位段别名的细节内容。
地址区域的另外0.5GB的块用于片上外设,和SRAM区域类似,该区域也支持位段别名而且可以通过系统接口访问,不过,其不支持指令执行。由于外设区域支持位段特性,外设的控制和状态位的修改会非常简单,对外设控制的编程也就更加简单了。
外部RAM和外部设备分别具有1GB的存储器空间,这两块的区别为外部设备空间不允许程序执行,并且在缓存的处理上也有所不同。
最后的0.5GB用于系统级部件、内部外设总线、外部外设总线和供应商特定的系统外设。私有外设总线(PPB)包括两个部分:
- 高级高性能总线(AHB)PPB,仅用于Cortex-M3的内部AHB外设,包括NVIC、 FPB、DWT和ITM;
- 高级外设总线(APB)PPB,用于Cortex-M3的内部APB设备以及外部外设(Cortex- M3处理器外部),Cortex-M3允许供应商在私有外设总线上添加额外的经由APB接口的片上APB外设。
NVIC位于被称作系统控制空间(SCS)的存储器区域(见图5.2),除了可以提供中断控制特性外,该区域还包括SYSTICK的控制寄存器、MPU以及代码调试控制。
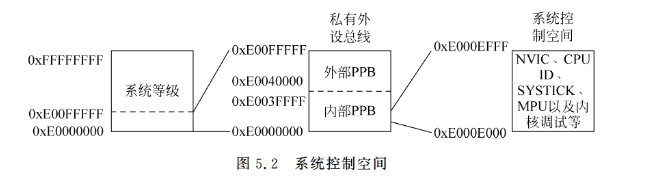
剩下的未使用的供应商特定的存储器区域可以通过系统总线接口访问,不过,该区域不允许指令执行。
Cortex-M3处理器还包括一个可选的MPU,芯片生产商可以在他们的产品中加人MPU。
这里的存储器映射内容仅仅是一个例子,每个半导体供应商都会提供包括ROM、RAM大小以及外设存储器实际位置的存储器映射。
4.3 存储器访问属性
通过存储器映射,可以了解每个存储器区域中包含的内容,除了解析要访问的存储器块和设备,存储器映射还定义了访问的存储器属性。Cortex-M3中的存储器属性包括:
- 可缓冲(bufferable):在处理器继续执行下一条指令时,写缓冲可以继续写入存储器。
- 可缓存(cacheable):从存储器读操作中获取的数据可以被复制到存储器缓存中,这样下次再访问时,就可以从缓存中取出数据从而加快程序执行。
- 可执行(executable):处理器可以从这种存储器区域中取出并执行程序代码。
- 可共用(sharable):这种存储器区域中的数据可以被多个总线主设备共用,存储器系统需要确保这种区域的数据在不同的主设备访问时的一致性。
在每次指令和数据传输时,Cortex-M3总线接口将存储器访问属性信息输出到存储器系统。若存在MPU并且MPU区域的默认配置被修改了,默认的存储器属性可能会被覆盖。尽管Cortex-M3处理器没有缓存存储器或缓存控制器,微控制器上可以添加缓存单元,这样就可以利用存储器属性信息来定义存储器访问行为了。另外,根据芯片生产商使用的存储器控制器,缓存属性可能会影响片上存储器和片外存储器的控制器操作。
每个存储器区域的存储器访问属性定义如下:
- 缓存存储器区域(
0x00000000~0x1fffffff):该区域为可执行,缓存属性为写通(WT),你也可以将数据存储器放到这个区域。如果在这个区域里执行数据操作,它们可以通过数据总线接口执行。对这个区域的写传输为可缓冲的。 - SRAM存储器区域(
0x20000000~0x3fffffff):该区域用于片上RAM,对这个区域的写传输是可缓冲的,并且缓冲属性为写回写分配(WB-WA)。这个区域是可执行的,因此你可以将程序代码复制到这里并执行。 - 外设区域(
0x40000000~0x5fffffff):该区域用于外设,并且对其的访问是不可缓存的,该区域不允许程序执行(Execute Never)。 - 外部RAM区域(
0x60000000~0x7fffffff):该区域可用于片上或片外存储器,对其的访问是可缓存的(WB-WA),可以在这个区域中执行代码。 - 外部RAM区域(
0x80000000~0x9fffffff):该区域可用于片上或片外存储器,对其的访问是可缓存的(WT),可以在这个区域中执行代码。 - 外部设备(
0xa0000000~0xdfffffff):该区域用于外部设备以及/或者需要顺序/非缓冲访问的存储器,也是不可执行区域。 - 系统区域(
0xe0000000~0xffffffff):该区域用于私有外设和供应商特定的设备,并且为不可执行的。对于PPB存储器区域,访问为强序的(不可缓存、不可缓冲);而对于供应商特定的存储器区域,访问则为可缓冲和不可缓存的。
应该注意的是,从Cortex-M3的版本1开始,输出到外部存储器系统的代码区域属性被硬连接为可缓存和不可缓冲的,MPU配置无法进行修改。这个更新只会影响处理器外的存储器系统(例如,2级缓存和带有缓存特性的某种类型的存储器控制器),而在处理器内部,内部写缓冲仍可用于访问代码区域的写传输。
4.4 默认的存储器访问权限
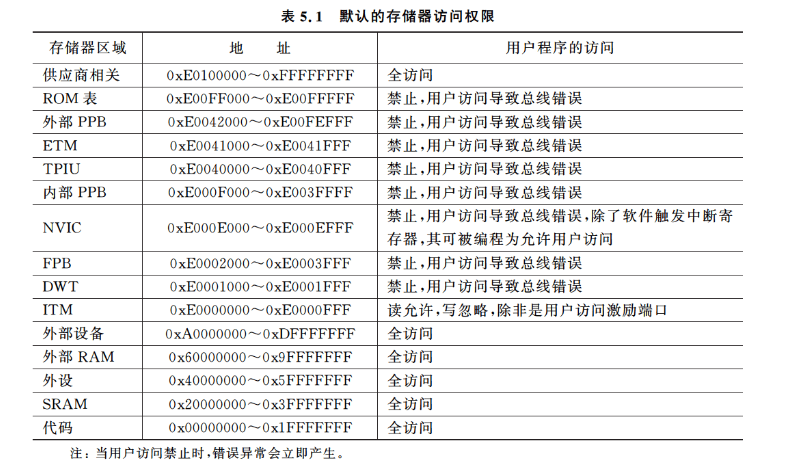
Cortex-M3的存储器映射对存储器访问权限具有默认的配置,这样可以防止用户程序(非特权)访问系统控制存储器空间(如NVIC)。在MPU不存在或者MPU存在但未使能等情况下,默认的存储器访问权限会启用。
如果MPU存在且使能,MPU设置里的访问权限则会决定是否允许用户访问。
默认的存储器访问权限如表5.1所示。
4.5 位段操作
位段操作允许单次加载/存储操作(读/写)访问单个数据位,对于Cortex-M3,两个预定义的位段区域支持这种特性,其中一个位于SRAM区域的头1MB,另外一个则位于外设区域的头1MB。这两个区域可以同普通存储器一样访问,不过它们还可以通过被称作位段别名的独立区域进行操作(见图5.3)。当使用位段别名地址时,可以通过每个字对齐的地址中数据的最低位,来访问每个单独的位。
例如,要将地址0x20000000中数据的第2位置1,除了可以通过读出数据、设置位然后写回数据的方式外,还可以通过单一指令执行这个操作(见图5.4)。图5.5展示了这两种情况的汇编执行流程。
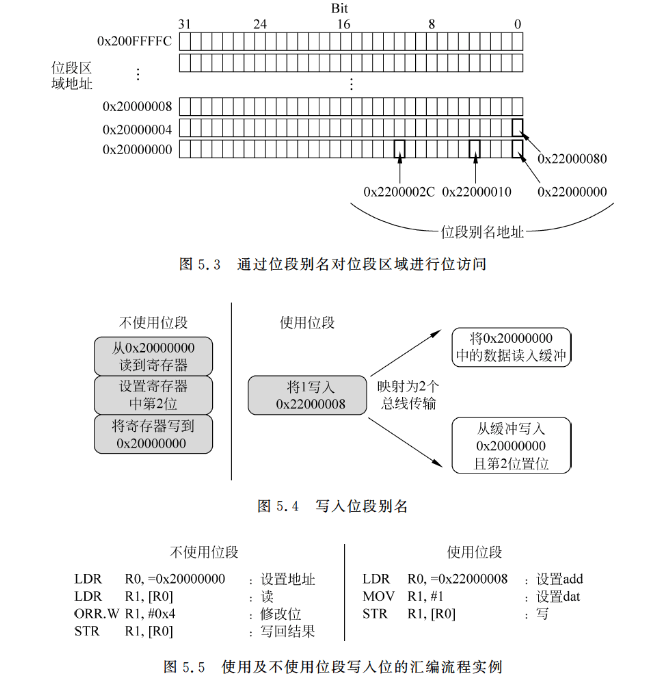
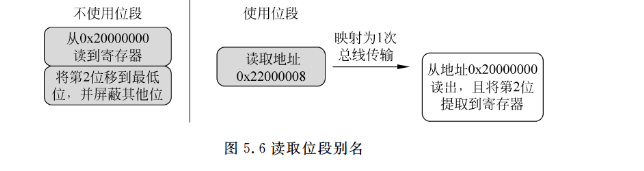
类似地,如果我们需要读取存储器位置中的一个位,位段特性可以简化应用程序代码。例如,如果我们需要确定地址0x20000000处数据的第2位,我们可以采取图5.6所示的步骤。这两种情况的汇编执行顺序可以参考图5.7。

位段操作并不是一个新的想法,事实上,类似的特性已经在像8051之类的8位微处理器上存在30多年了。尽管Cortex-M3并没有位操作的特殊指令,而定义了特殊区域却可以让对这些区域的访问自动转换为位段操作。
- 位段区域:支持位段操作的存储器区域。
- 位段别名:访问位段别名会引起对应位段区域的访问(位段操作)。(存储器的重映射)
在位段区域里,每个字被位段别名寻址区域里的32个字的最低位表示。事实上,在访问位段别名区域时,地址被重映射为位段地址。对于读操作,字被读出并且选定的位会被移入读返回数据的最低位;对于写操作,写入的位数据会被移入所需位的位置,并且执行读-修改-写的操作。
两个区域可以用于位段操作:
0x20000000~0x200fffff:SRAM,1MB。0x40000000~0x400fffff:外设,1MB。

4.5.1 位段操作的优势
看了以上的内容,位段操作有什么作用?举个例子来说,我们可以使用从通用目的输入/输出到串行设备的串行数据传输。由于对串行数据的访问和时钟信号可以分离,应用程序代码可以简单实现。

位段操作还可简化跳转决断,例如,若跳转执行需要基于外设的状态寄存器中的单一位,除了
- 读出整个寄存器;
- 屏蔽不需要的位;
- 比较并跳转。
还可以将操作简化为
- 通过位段别名读出状态位(得到0或1);
- 比较并跳转。
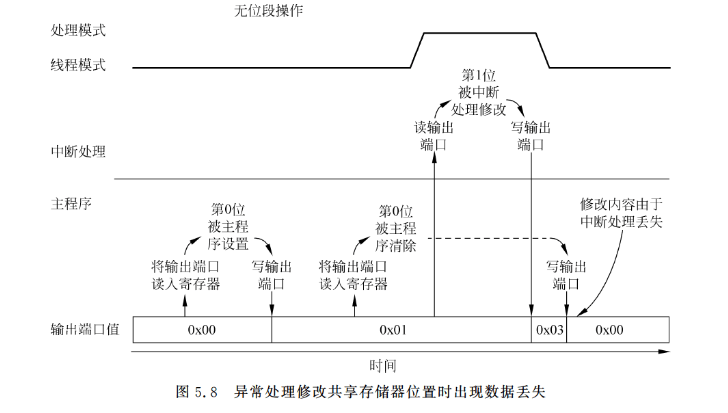
除了可以使用较少的指令提供较快的位操作外,Cortex-M3的位段特性也可用于其他情况,如多个进程共用相同的资源时。位段操作的重要优势或特点之一是它的原子性,换句话说,读-修改-写流程不能被其他的总线行为打断。若没有这一特性,那么在使用读修改写的流程时,就需要考虑下面的问题了:假定主程序使用了一个简单端口的第0位,而第1位则是被中断处理使用,如图5.8所示,基于软件的读-修改-写操作会引发数据冲突。
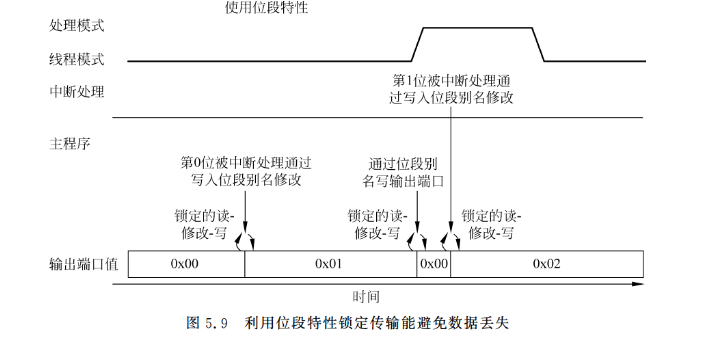
利用Cortex-M3的位段特性,由于读-修改-写是在硬件层执行的原子操作,而且中断也不会在这期间产生,因此竞态条件就可以被避免了(见图5.9)。
多任务系统中也存在着类似的问题,例如,如果输出端口的第0位被进程A使用,而第1位被进程B使用,基于软件的读-修改-写就会产生数据冲突(见图5.10)。
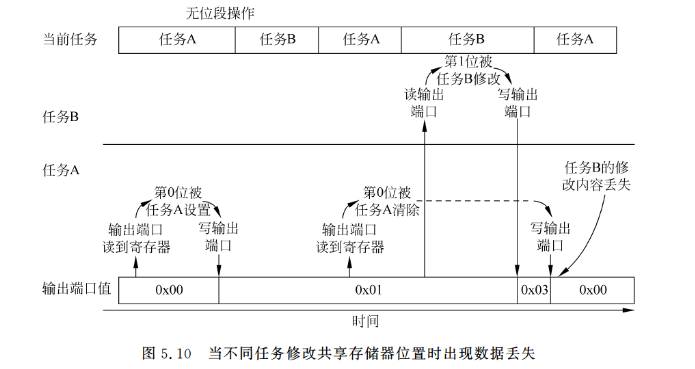
再次强调一下,位段特性可以确保每个任务的位操作相互独立,因此不会造成数据冲突(见图5.11)。
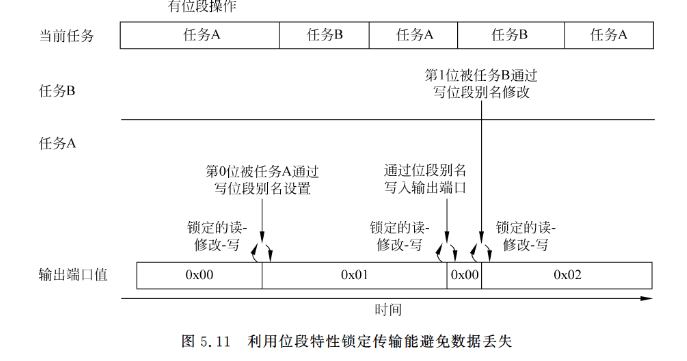
除了I/O功能外,位段特性可以用于存储和处理位于SRAM区域的Boolean类型的数据。例如,多个Boolean变量可以位于同一个存储器位置上,以节省空间,而通过位段别名地址区域执行的访问仍可使得对每个位的操作完全独立。
片上系统(SoC)设计者在设计具有位段特性的设备时,设备的存储器地址应该位于位段区域内,而且还应该检查AHB总线上的锁定信号(HNASTLOCK),以确保当锁定传输执行时,只有总线才能更改可写寄存器的内容。
4.5.2 不同数据宽度的位段操作
位段操作并不局限于字传输,字节或半字传输也可以使用。例如,当使用字节访问指令(LDRB/STRB)访问位段别名地址区域时,对位段区域产生的访问就是字节大小的,半字传输(LDRH/STH)的情况也是一样的。当使用字以外的传输访问位段别名地址时,地址值应该仍是字对齐的。
4.5.3 C程序实现位段操作
大多数C编译器是不支持位段传输的,例如,在使用两个不同的地址时,C编译器不会认为访问的是同一存储器区域,而且它们也不知道对位段别名的访问只会操作该存储器位置的最低位。在用C实现位段特性时,最简单的方法是对某存储器位置的地址和位段别名单独定义,例如

也可以使用C宏定义简化对位段别名的访问,例如,我们可以定义一个宏将位段地址和位编号转换为位段别名地址,并且定义另一个宏在访问该存储器位置时将地址数值当做一个指针。
应该注意的是,在使用位段特性时,变量可能需要被声明为volatile。C编译器不知道同一个数据可以在两个不同的地址中访问,因此volatile属性可以确保每次在操作一个变量时,访问的是存储器位置而不是处理器内部的本地数据复制。
从ARM RealView开发组件版本4.0和Keil MDK-ARM版本3.80开始,编译器通过 C语言扩展attribute((bitband))和命令行选项bitband(参见参考文献[6])实现了对位段的支特。《ARM应用笔记l79》(ARM RealView Compiler Tools,参考文献[7])中的ARM RealView编译器工具中还有C宏定义进行位段访问的其他例子。
4.6 非对称传输
Cortex-M3支持单次访问的非对齐传输,数据存储器访问可以被定义为对齐或是非对齐的。传统的ARM处理器(如ARM7/ARM9/ARM1O)只允许对齐传输,这就意味着在存储器访问时,字传输地址的bit[1]和bit[0]必须为0,半字传输地址的bit[0]必须为0。例如,字数据可以位于0x1000或0x1004,但不能位于0x1001、0x1002或0x1003。对于半字数据,地址可以为0x1000或0x1002,但不能为0x1001。
那么,非对齐传输是什么样的呢?图5.12一图5.16中列出了几个例子。假定存储器为32位(4字节)宽,如图5.12图5.14所示,非对齐访问可以为任何字大小的读/写,因此地址也不必是4的倍数,或者如图5.15和图5.16所示,当传输为半字时,地址也不必是2的倍数。
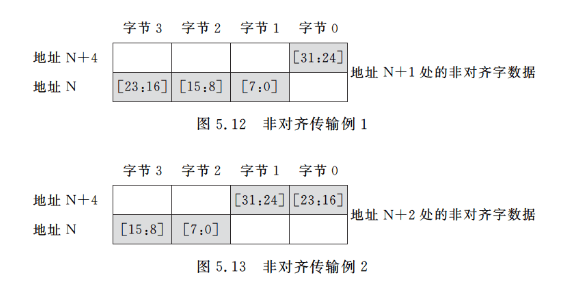
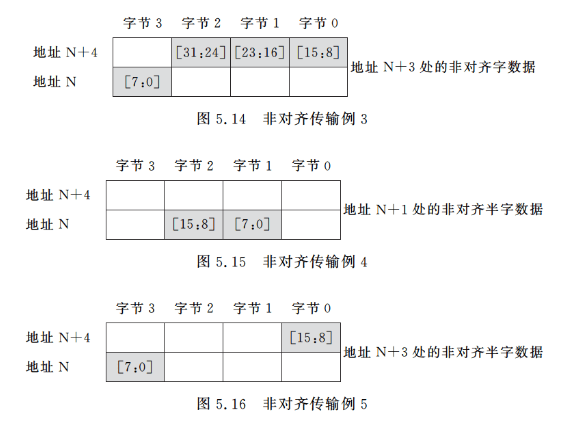
由于地址的最小单位为1字节,因此所有的字节传输在Cortex-M3上都是对齐的。
对于Cortex-M3,普通的存储器访问都支持非对齐访问(如LDR、LDRH、STR和 STRH指令),当然,也存在一些限制:
- 多加载/存储指令不支持非对齐传输;
- 栈操作(PUSH/POP)必须是对齐的:
- 排他访问(如LDREX或STREX)必须是对齐的,否则,错误异常(使用错误)就会产生;
- 位段操作不支持非对齐传输,非要这么做的话可能会导致不可预料的结果。
在使用非对齐传输时,实际上它们会被处理器的总线接口单元转换为多次对齐传输,这个转换对用户是透明的,因此应用程序开发人员无须考虑这个问题。不过,当发生非对齐访问时,它会被分解为几个独立的传输,因此,一次数据访问会花费更多的时钟周期,而当系统对性能要求较高的时候可能就不适用了。要获得最佳性能,确保数据正确的对齐是很有必要的。
也可以对NVIC进行设置,使得非对齐访问发生时可以触发异常。可以通过设置 NV1C中配置控制寄存器(地址0xE000ED14)的UNALIGN TRP(非对齐陷阱)位来实现这一功能。这样,在进行非对齐访问时,Cortex-M3就会产生使用错误异常。在软件开发过程中,在测试应用程序是否会产生非对齐访问时,可以利用这一特性。
4.7 排他访问
注意,Cortex-M3没有SWP指令(交换),该指令在ARM7TDMI等传统的ARM处理器上用于信号量操作,现在它已经被排他访问操作取代了。排他访问是从6架构才开始出现的(例如ARM1136)。
信号量通常用于分配多个应用程序的共享资源,当共享资源只能被一个目标或者应用处理器使用时,我们可以将其称为互斥体(MUTEX)。在这种情况下,当资源被一个进程使用时,它就会被锁定到那个进程上,并且在解除锁定前不能被其他的进程使用。要建立一个 MUTEX信号量,需要将一个存储器位置定义为锁定标志,表明共享资源是否被某个进程锁定。当进程或应用程序想使用该资源时,就需要首先检查资源是否被锁定了。若其没被使用,则可以设置锁定标志以表明该资源目前已被锁定。对于传统的ARM处理器,对锁定标志的访问由SWP指令执行,SWP可以确保读写锁定标志操作的原子性,防止资源被两个进程同时锁定。
而对于较新的处理器,读/写访问可以在独立的总线上执行。在这种情况下,由于锁定传输流程的读写必须在同一个总线上,因此SWP指令已经无法保证存储器访问的原子性了。因此,锁定传输被排他访问取代。排他传输操作的理念相当简单,不过与SWP不同,它允许另一个总线主控设备或者同一个处理器上的另一个进程访问信号量所在的存储器位置(见图5.17)。
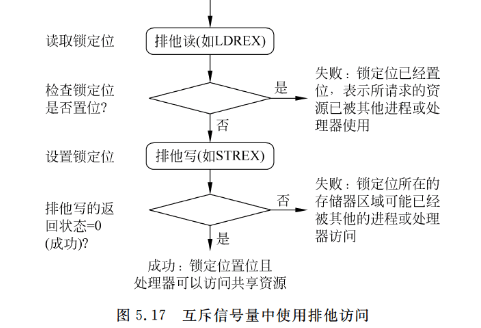
要保证排他访问可以在多处理器环境中正常工作,还需要另外的被称作“排他访问监控”的硬件。该监控检查共享地址所在位置的传输并且在排他访问成功后向处理器做出回应,处理器的总线接口也对该监控提供了其他的控制信号,指示当前传输是否为排他访问。
如果存储器设备被另外一个主控总线的访问处于排他写和排他读之间,当处理器试图进行排他写时,排他访问监控会通过总线标记为排他失败。这样会导致排他写的返回状态置1,在排他写失败的情况下,排他访问监控也会阻止写传输获取排他访问地址。

第10章中有排他访问的例子代码,微控制器供应商的符合Cortex微控制器软件接口标准(CMSIS)的设备驱动库提供了LDREX、LDREXH、LDREXB、 STREX、 STREXH和STREXB等函数,C语言用户也可以通过这些内在函数使用排他访问指令。附录G中有这些函数的更多细节。
在进行排他访问时,Cortex-M3总线接口上的内部写缓冲将不会再使用,即使MPU将这段区域定义为了可缓冲的。这样可以确保物理存储器上的信号量信息始终是最新的,而且总线间也是一致的。使用Cortex-M3的SoC设计人员在设计多处理器系统时,应该确保排他传输出现时存储器系统的数据一致性。
4.8 端模式
Cortex-M3支持大端和小端模式,不过,其所支持的存储器类型取决于微控制器设计的剩余部分(总线连接、存储器控制器以及外设等)。在开发软件前,应仔细查看微控制器的数据手册。多数情况下,基于Cortex-M3的微控制器都是小端的。在使用小端模式时,字数据的第一个字节存储在32位存储器位置的最低字节(见表5.4)。

有些微控制器使用大端模式,在这种情况下,字大小数据的第一个字节存储在32位地址存储器位置的最高字节(见表5.5)。
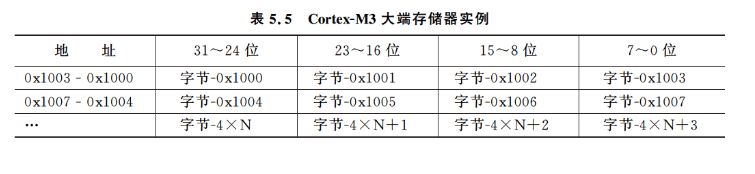
Cortex-M3中大端的定义同ARM7TDMI不同。在ARM7TDMI中,其大端被称作字不变大端,在ARM文献中也被称作BE-32,而Cortex-M3的大端则被称作字节不变大端,也可以叫做BE8(ARM架构6和v7都支持字节不变大端)。两种体系的存储器布局是相同的,不过数据传输中总线接口的字节通道的使用方式是不同的(见表5.6和表5.7)。
在Cortex-M3处理器中,端模式在处理器退出复位时设置,之后不能改变(无动态端切换,不支持SETEND指令)。取指总是以小端方式,因其数据访问发生在系统控制器空间(如NVIC和FPB)以及外部存储器区域(0xE0000000到0xE00 FFFFF的区域总是小端的)。
若SoC不支持大端,而所使用的一个或多个外设中包含大端数据,那么使用Cortex-M3中数据类型转换指令很容易地就能将数据在小端和大端间转换。例如,REV和REV16可用于此类转换。