图注意力神经网络
前言
这篇论文提出的核心方法就是在计算一个节点的输出的时候考虑与其相邻的节点对当前节点的影响,同时也将节点对自己的影响考虑在内,为了方便后续解释中将Graph Attention Networks简化成GAT来表述,阅读原版论文有困难可以看一下Aleksa大神录制的讲解视频辅助理解,我在看完视频以后对第多头注意力下的结果输出部分茅塞顿开,同时对自己看论文的时候的一些理解也更加深刻了;另外还有B站上的GAT代码讲解视频的讲解很详细,相比于pytorch给出的源码更加容易理解,本次是笔者的论文复现入门,代码部分采用的是Vscode中的Jupyter代码块的方式,抛弃了Pycharm的繁重以及自建库的调用,直接用逐行运行的方式进行,小白友好。
一、论文解读
1.1 模型架构
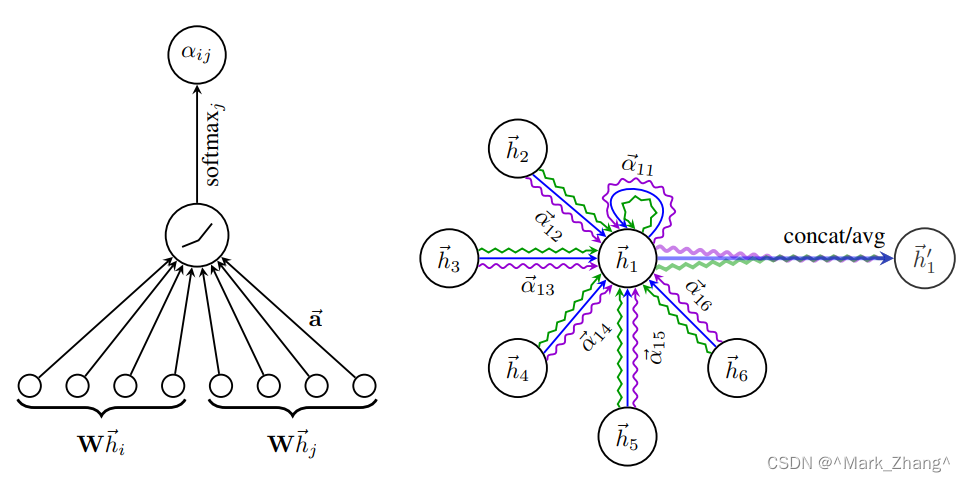
- 左边的单层网络展示了如何根据输入数据(图类型的数据,有节点和边的信息),计算出节点之间的注意力系数, α i j \alpha_{ij} αij( j j j节点对 i i i节点的重要程度),这里计算的时候我们只关心每个节点的入边不关心出边。公式如下:
e i j = a ( W h ⃗ i , W h ⃗ j ) e_{ij}=a(\mathbf{W}\vec{h}_i,\mathbf{W}\vec{h}_j) eij=a(Whi,Whj)
- 首先通过这一步计算节点与其相邻节点的注意力系数
- 这里的 a a a的作用是将拼接以后的高维特征映射到一个实数上
这一步计算出来的 e i j e_{ij} eij是相邻节点之间的注意力系数,这一点在代码层面有细节就是先计算所有节点之间的注意力系数然后再挑出来相邻的节点的注意力系数。
α i j = exp ( LeakyReLU ( a ⃗ T [ W h ⃗ i ∥ W h ⃗ j ] ) ) ∑ k ∈ N i exp ( LeakyReLU ( a ⃗ T [ W h ⃗ i ∥ W h ⃗ k ] ) ) \alpha_{ij}=\frac{\exp\left(\text{LeakyReLU}\left(\vec{\mathbf{a}}^T[\mathbf{W}\vec{h}_i\|\mathbf{W}\vec{h}_j]\right)\right)}{\sum_{k\in\mathcal{N}_i}\exp\left(\text{LeakyReLU}\left(\vec{\mathbf{a}}^T[\mathbf{W}\vec{h}_i\|\mathbf{W}\vec{h}_k]\right)\right)} αij=∑k∈Niexp(LeakyReLU(aT[Whi∥Whk]))exp(LeakyReLU(aT[Whi∥Whj]))
- α \alpha α是一个形状为2F’*1的权重向量,作用如上
- W是一个形状为F’*F的权重矩阵
- h ⃗ i \vec{h}_i hi是当前节点的特征列向量; h ⃗ j \vec{h}_j hj是与当前处理的节点相邻的节点的特征列向量,形状都是F*1
- ||表示将两个矩阵拼接起来
- 最后计算以后用sigmoid函数进行归一化,统一所有自注意力系数的评价标准
这个公式实现的是将注意力系数从一个值转换成一个能够用来评价的概率值 α i j \alpha_{ij} αij,同时这个值也能用于后续更新模型参数。
最后的单层结构的输出求解公式如下两种情况:
- 第一种对应的是在最后一层输出之前的隐藏层还在计算注意力的时候需要将多头注意力拼接起来形成更加高维抽象的特征向量。
h ⃗ i ′ = ∏ k = 1 K σ ( ∑ j ∈ N i α i j k W k h ⃗ j ) \vec{h}_i'=\prod\limits_{k=1}^K\sigma\left(\sum\limits_{j\in\mathcal{N}_i}\alpha_{ij}^k\mathbf{W}^k\vec{h}_j\right) hi′=k=1∏Kσ(j∈Ni∑αijkWkhj)
- 第二情况是当进行到最后一层输出的时候直接求平均值然后输出每一种类别对应的概率值。
h ⃗ i ′ = σ ( 1 K ∑ k = 1 K ∑ j ∈ N i α i j k W k h ⃗ j ) \vec{h}_i^{\prime}=\sigma\left(\frac1K\sum_{k=1}^K\sum_{j\in\mathcal{N}_i}\alpha_{ij}^k\mathbf{W}^k\vec{h}_j\right) hi′=σ(K1∑k=1K∑j∈NiαijkWkhj)
- 右边的网络架构展示了GAT的工作原理,在模型的隐藏层,当前节点会计算对其他节点的注意力系数,同时这里引入了多头注意力机制的概念,也就是在计算当前层的输出的时候,当前层会“看一看”当前层的其他节点(论文中说的是与之相邻的第一跳节点,也就是第一层)来最终决定当前的输出(通过在训练的时候改变权重矩阵W来实现) h ⃗ i ′ \vec{h}_i' hi′,具体的实现形式参考Transformer架构,或者可以参考3B1B最近的注意力机制视频。比较形象地展示多头注意力如何工作的有一张图:
这里的黄色箭头就很形象地展示了多头注意力。
1.2 数学推导

我简单写了一个手写版本的推导,可以看到最后成功输出了对应每个节点所注意的特征。
二、代码复现
2.1 数据准备
首先是导入数据:
# cora数据集导入
cora_path = '../dataset/cora/cora/cora.content'
cora = pd.read_csv(cora_path, sep='\t', header=None)
cora_cites = pd.read_csv('../dataset/cora/cora/cora.cites', sep='\t', header=None)
print('cora_cites:\n',cora_cites.head())
# print('cora:\n',cora.head())
# 将编号转换成0-2707,方便进行下下标索引
labelencoder = LabelEncoder()
cora[0] = labelencoder.fit_transform(cora[0])
print('cora:\n',cora.head())
2.1.1 数据转化
由于原始数据中都是点集,这里需要将数据转换成模型更加容易处理的图状结构,并生成相对应的邻接矩阵,另外由于最后的的标签是字符串,如果要导入模型需要用one-hot(热独)编码进行转化。
标签one-hot编码:
# 定义辅助函数热独编码,这里的labels是一个列表
def encode_onehot(labels):
classes = sorted(list(set(labels))) # set去重,sorted按照从小到大排序
classes_dict = {c: np.identity(len(classes))[i, :] for i, c in enumerate(classes)} # 生成热独编码字典 {类别:热独编码}
labels_onehot = np.array(list(map(classes_dict.get, labels)), dtype=np.int32) # map函数,对labels中的每个元素进行热独编码,get函数单独使用,返回字典中key对应的value
return labels_onehot # 返回热独编码后的标签,shape为(N,C)
生成图结构:
# 生成图结构
idx = np.array(idx_features_labels[:, 0], dtype=np.int32) # 提取索引
idx_map = {j: i for i, j in enumerate(idx)} # 生成索引字典,{原索引:新索引},enumerate将列表转换为索引-值对
# 生成边信息
edges_unordered = np.genfromtxt(cora_cites_path, dtype=np.int32) # 读取边信息,shape=(5429,2)
edges = np.array(list(map(idx_map.get, edges_unordered.flatten())), dtype=np.int32).reshape(edges_unordered.shape) # 生成重新编号的边信息,shape=(5429,2)
生成邻接矩阵:
adj = sp.coo_matrix((np.ones(edges.shape[0]), (edges[:, 0], edges[:, 1])), shape=(labels.shape[0], labels.shape[0]), dtype=np.float32) # 生成邻接矩阵的稀疏矩阵,np.ones(edges.shape[0])表示矩阵中所有非零元素的值,edges[:, 0]和edges[:, 1]分别表示这些非零元素的行索引和列索引。
adj = adj + adj.T.multiply(adj.T > adj) - adj.multiply(adj.T > adj) # 对称归一化邻接矩阵,因为无向图,所以邻接矩阵应该是对称的,这段代码将adj更新为adj和adj.T中的较大值
2.1.2 创建数据集
# 加载数据
idx_features_labels = np.genfromtxt(cora_content_path, dtype=np.dtype(str)) # 读取数据
# 从数据中提取特征
features = sp.csr_matrix(idx_features_labels[:, 1:-1], dtype=np.float32) # 提取特征
# 提取标签
labels = encode_onehot(idx_features_labels[:, -1]) # 提取标签,-1表示最后一列,同时进行热独编码
2.2 模型构建
2.2.1 参数设置

首先是Transductive Learning的部分,蓝色的部分是可以适用于Cora数据集和Citeseer数据集的模型参数;绿色部分是为了Pubmed数据集修改的参数:
- 第一层:
- 多头注意力 K = 8
- 输出维度 F’ = 8
- 激活函数用 ELU
- 第二层:
- 一个单注意力层
- 输出只有一个attention head,如果是Pubmed则修改为8个
- 训练参数:
- λ \lambda λ = 0.0005,如果是Pubmed则修改成0.001
- p p p = 0.6

之后是Inductive Learning的部分,定义了三层的GAT模型,同时给出了参数设置:
- 前两层参数定义:
- 多头注意力 K = 4
- 输出维度 F’ = 256
- 激活函数 Func = ELU
- 后一层参数定义
- 多头注意力 K = 6
- 使用求平均的方法
- 用sigmoid函数做激活函数
- 训练参数:
- 数据量够大,不需要dropout
- batch:2
2.2.2 模型代码
单层的模型部分
class GSingleLayer(nn.Module):
def __init__(self, in_features, out_features, dropout, alpha, concat = True): # in_features是输入特征维度,out_features是输出特征维度,dropout是dropout的概率,alpha是leakyrelu的参数,concat是否要拼接
super(GSingleLayer, self).__init__()
self.dropout = dropout # 在数据量较少的时候,可以使用dropout防止过拟合
self.in_features = in_features # 输入特征维度F
self.out_features = out_features # 输出特征维度F'
self.concat = concat # 是否要拼接,对于中间层,需要拼接因为这里使用的是多头注意力,但是对于最后一层就不需要拼接直接计算平均值
self.alpha = alpha # leakyrelu的参数
# 定义权重矩阵
self.W = nn.Parameter(torch.empty(size=(in_features, out_features))) # 定义权重矩阵,shape=[F,F'],这里跟论文中的不一样是后面在将数据导入模型的时候纬度是[N,F]。这里要相应进行调整
# 用Xavier方法初始化权重矩阵
nn.init.xavier_uniform_(self.W.data, gain=1.414) # 使用Xavier方法初始化权重矩阵
# 定义权重向量a
self.a = nn.Parameter(torch.empty(size=(2*out_features, 1))) # 定义权重向量a,shape=[2F',1]
# 用Xavier方法初始化权重向量a
nn.init.xavier_uniform_(self.a.data, gain=1.414)
# 定义leakyrelu激活函数
self.leakyrelu = nn.LeakyReLU(self.alpha)
# 定义在这一层节点会进行什么操作
# h就是论文中的输入特征集合,adj就是邻接矩阵
def forward(self, h, adj):
# 首先是e的计算,矩阵的使用用高维的避免了循环遍历
Wh = torch.mm(h, self.W) # shape [N, F']
Wh1 = torch.matmul(Wh,self.a[:self.out_features, :]) # shape [N, 1], 这里将a拆开相当于后面将两个拼接起来
Wh2 = torch.matmul(Wh,self.a[self.out_features:, :]) # shape [N, 1],这里一定要记住不能少了后面这个冒号!!!!!
e = self.leakyrelu(Wh1 + Wh2.T) # shape [N, N],同时这里使用了广播相加
# 计算注意力系数a
zero_vec = -9e15*torch.ones_like(e) # 生成负无穷矩阵,方便后续经过softmax函数直接变成0
attention = torch.where(adj > 0, e, zero_vec) # 前面计算了所有节点之间的相关性系数,这里筛选出有边关系的保留attention,剩下的不保留
attention = F.softmax(attention, dim = 1)
attention = F.dropout(attention, self.dropout, training = self.training)
h_prime = torch.matmul(attention, Wh) # 将所有的attention和Wh相乘得到当前层的输出
if self.concat: # 如果是拼接的话
return F.elu(h_prime)
else:
return h_prime
模型网络架构部分
class GAT_Network(nn.Module):
def __init__(self, nfeature, nhidden, nclass, dropout, alpha, nheads): # nfeature是输入特征的维度,nhidden是隐藏层的维度,nclass是输出的类别数,dropout是dropout的概率,alpha是leakyrelu的参数,nheads是多头注意力的头数
super(GAT_Network, self).__init__()
self.dropout = dropout
self.nheads = nheads
# 定义多个注意力层
self.attentions = [GSingleLayer(nfeature, nhidden, dropout, alpha) for _ in range(nheads)] # 定义多个注意力层,输出是[nhidden, nheads]
for i, attention in enumerate(self.attentions):
# 将多个注意力层加入到模型中,并行计算
self.add_module('attention_{}'.format(i), attention)
# 定义输出层,输出层的输入维度就是上一层[nhidden, nheads],由于这里是最后一层,根据论文中说的就不进行拼接了
self.out_att = GSingleLayer(nhidden * nheads, nclass, dropout, alpha, concat = False)
# 定义在网络架构中信息的传递规则
def forward(self, x, adj):
x = F.dropout(x, self.dropout, training = self.training) # dropout
x = torch.cat([att(x, adj) for att in self.attentions], dim = 1) # 将多个注意力层的输出拼接起来
x = F.dropout(x, self.dropout, training = self.training)
x = F.elu(self.out_att(x, adj)) # 用elu激活函数
return F.log_softmax(x, dim = 1) # softmax将输出转换为概率分布
2.2.3 pytorch官方GAT源码实现
class GATConv(MessagePassing):
def __init__(self, in_channels: Union[int, Tuple[int, int]],
out_channels: int, heads: int = 1, concat: bool = True,
negative_slope: float = 0.2, dropout: float = 0.,
add_self_loops: bool = True, bias: bool = True, **kwargs):
kwargs.setdefault('aggr', 'add')
super(GATConv, self).__init__(node_dim=0, **kwargs)
self.in_channels = in_channels
self.out_channels = out_channels
self.heads = heads
self.concat = concat
self.negative_slope = negative_slope
self.dropout = dropout
self.add_self_loops = add_self_loops
if isinstance(in_channels, int):
self.lin_l = Linear(in_channels, heads * out_channels, bias=False)
self.lin_r = self.lin_l
else:
self.lin_l = Linear(in_channels[0], heads * out_channels, False)
self.lin_r = Linear(in_channels[1], heads * out_channels, False)
self.att_l = Parameter(torch.Tensor(1, heads, out_channels))
self.att_r = Parameter(torch.Tensor(1, heads, out_channels))
if bias and concat:
self.bias = Parameter(torch.Tensor(heads * out_channels))
elif bias and not concat:
self.bias = Parameter(torch.Tensor(out_channels))
else:
self.register_parameter('bias', None)
self._alpha = None
self.reset_parameters()
def reset_parameters(self):
glorot(self.lin_l.weight)
glorot(self.lin_r.weight)
glorot(self.att_l)
glorot(self.att_r)
zeros(self.bias)
def forward(self, x: Union[Tensor, OptPairTensor], edge_index: Adj,
size: Size = None, return_attention_weights=None):
H, C = self.heads, self.out_channels
x_l: OptTensor = None
x_r: OptTensor = None
alpha_l: OptTensor = None
alpha_r: OptTensor = None
if isinstance(x, Tensor):
assert x.dim() == 2, 'Static graphs not supported in `GATConv`.'
x_l = x_r = self.lin_l(x).view(-1, H, C)
alpha_l = (x_l * self.att_l).sum(dim=-1)
alpha_r = (x_r * self.att_r).sum(dim=-1)
else:
x_l, x_r = x[0], x[1]
assert x[0].dim() == 2, 'Static graphs not supported in `GATConv`.'
x_l = self.lin_l(x_l).view(-1, H, C)
alpha_l = (x_l * self.att_l).sum(dim=-1)
if x_r is not None:
x_r = self.lin_r(x_r).view(-1, H, C)
alpha_r = (x_r * self.att_r).sum(dim=-1)
assert x_l is not None
assert alpha_l is not None
if self.add_self_loops:
if isinstance(edge_index, Tensor):
num_nodes = x_l.size(0)
if x_r is not None:
num_nodes = min(num_nodes, x_r.size(0))
if size is not None:
num_nodes = min(size[0], size[1])
edge_index, _ = remove_self_loops(edge_index)
edge_index, _ = add_self_loops(edge_index, num_nodes=num_nodes)
elif isinstance(edge_index, SparseTensor):
edge_index = set_diag(edge_index)
# propagate_type: (x: OptPairTensor, alpha: OptPairTensor)
out = self.propagate(edge_index, x=(x_l, x_r),
alpha=(alpha_l, alpha_r), size=size)
alpha = self._alpha
self._alpha = None
if self.concat:
out = out.view(-1, self.heads * self.out_channels)
else:
out = out.mean(dim=1)
if self.bias is not None:
out += self.bias
if isinstance(return_attention_weights, bool):
assert alpha is not None
if isinstance(edge_index, Tensor):
return out, (edge_index, alpha)
elif isinstance(edge_index, SparseTensor):
return out, edge_index.set_value(alpha, layout='coo')
else:
return out
def message(self, x_j: Tensor, alpha_j: Tensor, alpha_i: OptTensor,
index: Tensor, ptr: OptTensor,
size_i: Optional[int]) -> Tensor:
alpha = alpha_j if alpha_i is None else alpha_j + alpha_i
alpha = F.leaky_relu(alpha, self.negative_slope)
alpha = softmax(alpha, index, ptr, size_i)
self._alpha = alpha
alpha = F.dropout(alpha, p=self.dropout, training=self.training)
return x_j * alpha.unsqueeze(-1)
def __repr__(self):
return '{}({}, {}, heads={})'.format(self.__class__.__name__,
self.in_channels,
self.out_channels, self.heads)
这个源码看起来还是有点费劲的,跟原论文的匹配程度不是非常高。
2.3 模型训练

论文中给出了训练的参数设置如下:
- 初始化:使用Glorot初始化方法来初始化模型参数比如 W W W权重矩阵和 α \alpha α权重向量。
- 优化器:使用Adam SGD优化器
- 学习率:Pubmed是0.01,其他数据集是0.005
- 训练轮次:100
模型参数定义:
# 设置随机种子,保证实验的可重复性
seed = 72
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
# 定义训练参数序列
param = {
"epochs": 200, # "Number of epochs to train."
'lr': 0.005, # "Initial learning rate."
'weight_decay': 5e-4, # "Weight decay (L2 loss on parameters)."
'hidden': 8, # "Number of hidden units."
'nb_heads': 8, # "Number of head attentions."
'dropout': 0.6, # "Dropout rate (1 - keep probability)."
'alpha': 0.2, # "Alpha for the leaky_relu."
'patience': 100, # "Patience"
'fastmode': False # "Activate fast mode (i.e. validate during training)."
}
定义模型:
model = GAT_Network(
nfeature = features.shape[1],
nhidden = param["hidden"],
nclass = labels.max().item() + 1,
dropout = param["dropout"],
alpha = param["alpha"],
nheads = param["nb_heads"]
)
optimizer = optim.Adam(
model.parameters(), # 模型参数
lr = param["lr"],
weight_decay = param["weight_decay"]
)
训练代码:
def train(epoch):
t = time.time()
# 训练模型
model.train() # 训练模式
optimizer.zero_grad() # 梯度清零
output = model(features, adj) # 前向传播
loss_train = F.nll_loss(output[idx_train], labels[idx_train]) # 计算损失
acc_train = accuracy(output[idx_train], labels[idx_train]) # 计算准确率
loss_train.backward() # 反向传播
optimizer.step() # 更新参数
if not param["fastmode"]: # 如果不是快速模式,验证集和测试集也要进行训练
model.eval()
output = model(features, adj)
loss_val = F.nll_loss(output[idx_val], labels[idx_val])
acc_val = accuracy(output[idx_val], labels[idx_val])
print('Epoch: {:04d}'.format(epoch+1),
'loss_train: {:.4f}'.format(loss_train.item()),
'acc_train: {:.4f}'.format(acc_train.item()),
'loss_val: {:.4f}'.format(loss_val.item()),
'acc_val: {:.4f}'.format(acc_val.item()),
'time: {:.4f}s'.format(time.time() - t))
return loss_val.data.item()
测试代码:
def test():
model.eval() # 测试模式
output = model(features, adj) # 前向传播
loss_test = F.nll_loss(output[idx_test], labels[idx_test]) # 计算损失
acc_test = accuracy(output[idx_test], labels[idx_test]) # 计算准确率
print("Test set results:",
"loss= {:.4f}".format(loss_test.item()),
"accuracy= {:.4f}".format(acc_test.item()))
三、结果展示
3.1 复现结果
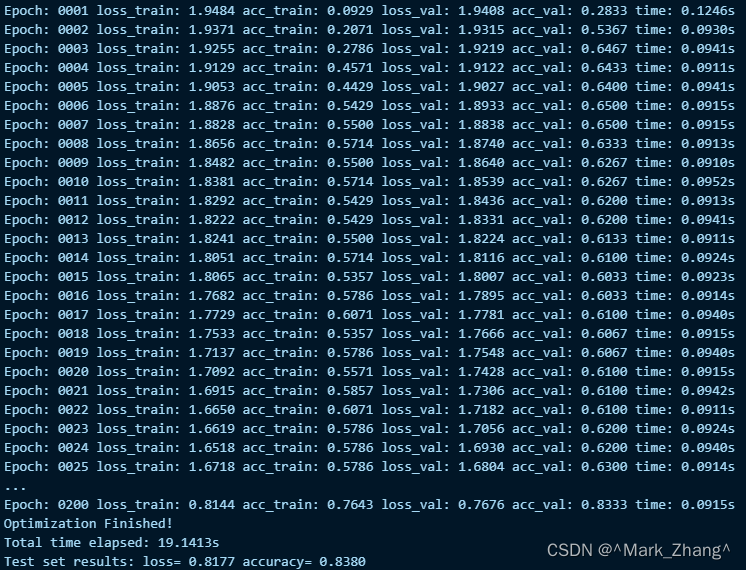
这里跑出来的结果符合官网的要求,哈哈哈哈哈,同时也能看到loss_val是越来越小了,我的显卡是8G显存的3060,一共跑了20秒就出结果了。
3.2 论文结果
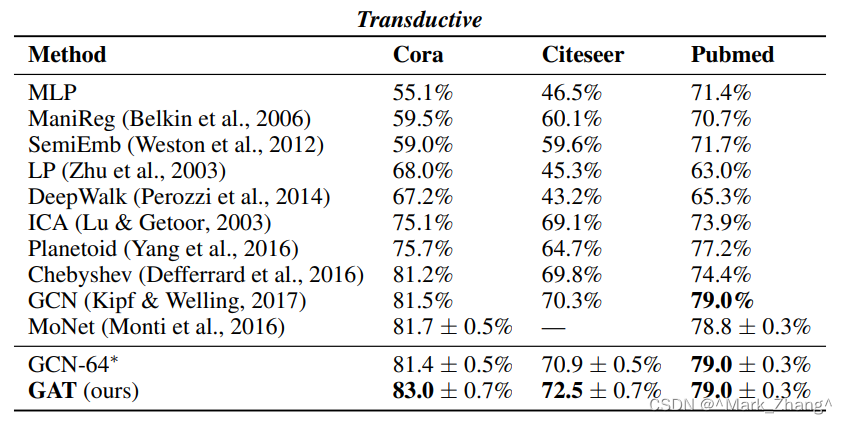
这个是推理(Transductive)的准确度评价表格,评价模型在已知训练集的情况下在测试集下的表现情况,从图结构中直观看就是知道一个节点的信息就可以推测出与之相连的一级节点的信息。
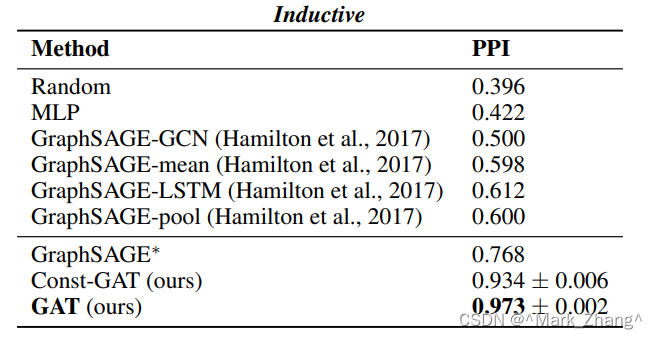
这个是归纳式学习(Inductive)的准确度评价表格,评价经过现有数据训练的模型在遇到新数据的表现情况,在论文中就是通过论文引用训练的数据去预测蛋白质相关的信息。
四、代码细节
- torch中的forward函数
在创建一个继承自nn.module的类的时候,后续用到model()函数的时候模型会自动调用forward函数进行前向传播的方法。 - torch中的dot mm mv matmul的区别
- dot:用于处理两个一维向量的点积
- mm:用于二维矩阵的相乘
- mv:用于计算一维向量和二维矩阵的乘积,注意中间的维度要对应。
- matmul:用于处理高维度矩阵的乘法,如果维度不同则会采用广播的方法,这个最常用。
- 将数据升维可以避免循环
arr1 = [1, 2, 3]
arr2 = [4, 5, 6]
result = []
for i in range(len(arr1)):
for j in range(len(arr2)):
result.append(arr1[i] * arr2[j])
比如上面这段代码要求每个元素的乘积,可以通过变成二维数组进行计算如下:
import numpy as np
arr1 = np.array([1, 2, 3])
arr2 = np.array([4, 5, 6])
arr1_2d = np.tile(arr1, (len(arr2), 1))
arr2_2d = np.tile(arr2, (len(arr1), 1)).T
result = arr1_2d * arr2_2d
这样就避免了循环,由于显卡可以并行计算这里换成用矩阵进行乘法可以大大提升计算速度。
- where函数简化判断
attention = torch.where(adj_nodes > 0, e, zero_vec) # 将邻接矩阵中的0位置的值替换成-9e15,这样在softmax后就会变成0
这行代码表示如果adi_nodes中的张量大于零张量,那么就选取e张量中对应的张量,否则选择zero_vec中对应的张量。
- 对从文件中读取的信息重新编码
np.array(list(map(classes_dict.get, labels)), dtype=np.int32)
这里map会将get函数会对classes_dict中的每个元素获取对应下标并作为labels中每个元素的对应索引,之后转换成list。
- 生成对称矩阵的快捷方法
adj = adj + adj.T.multiply(adj.T > adj) - adj.multiply(adj.T > adj)
这段代码的功能跟adj[i,j]=max(adj[i,j],adj[j,i])是一样的,但是不用循环遍历了
代码链接
我所有涉及到的代码都在这个Github链接直接点开ipynb文件,然后可以跟着conda环境搭建教程用文件夹里面的requirements.txt配置一下conda环境然后直接点击run all就可以看到结果了。