论文地址
论文首页

笔记框架
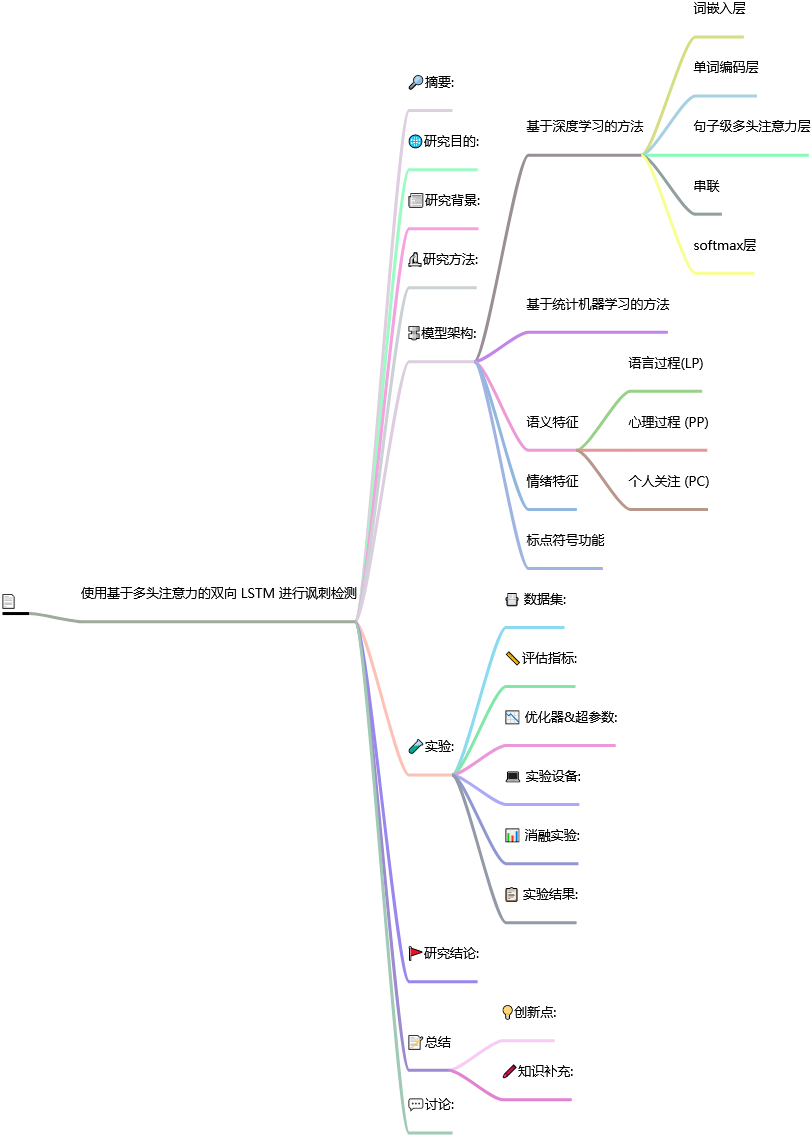
使用基于多头注意力的双向 LSTM 进行讽刺检测
📅出版年份:2020
📖出版期刊:IEEE Access
📈影响因子:3.9
🧑文章作者:Kumar Avinash,Narapareddy Vishnu Teja,Aditya Srikanth Veerubhotla,Malapati Aruna,Neti Lalita Bhanu Murthy
📍 期刊分区:JCR分区: Q2 中科院分区升级版: 计算机科学3区 中科院分区基础版: 工程技术3区 影响因子: 3.9 5年影响因子: 4.1 EI: 是 南农高质量: B
🔎摘要:
在社交媒体中,讽刺经常被用来使用正面或有意的正面词语来表达负面意见。这种有意的模糊性使得讽刺检测成为情感分析的一项重要任务。讽刺检测被认为是一个二元分类问题,在这个问题上,已经成功建立了特征丰富的传统模型和深度学习模型来预测讽刺评论。在以前的研究工作中,已经利用词汇、语义和语用特征建立了模型。我们提取了最重要的特征,并建立了一个特征丰富的 SVM,其性能优于这些模型。在本文中,我们引入了基于多头注意力的双向长短记忆(MHA-BiLSTM)网络来检测给定语料库中的讽刺性评论。实验结果表明,多头注意力机制提高了 BiLSTM 的性能,其表现优于特征丰富的 SVM 模型。
🌐研究目的:
使用基于多头注意力的双向长短期记忆(MHA-BiLSTM)网络的深度学习模型,用于讽刺检测。
📰研究背景:
讽刺性评论在社交媒体平台上很常见。此前,已经提出了几种统计机器学习和神经网络方法来检测讽刺,但它们在捕获用于表达讽刺的隐式模式和上下文方面似乎存在局限性。
🔬研究方法:
🔩模型架构:

使用基于多头注意力的双向长短期记忆(MHA-BiLSTM)网络的深度学习模型,并且还开发了支持向量机(SVM)模型。
基于深度学习的方法
具有多头机制的双向 LSTM由五个主要部分组成,多头注意力允许模型共同关注来自不同位置的不同表示子空间的信息。

词嵌入层
我们使用预训练的单词嵌入 Glove [24] 将句子中的每个单词转换为向量。
单词编码层
在这一层中,通过总结评论中两个方向的上下文信息来实现每个单词的新表示。
句子级多头注意力层
同时关注评论的不同部分,以理解评论语义的各个方面。
串联
我们为给定的评论提取基于语义、情感和标点符号的手工特征,创建一个 d 维的辅助特征向量 F与自注意力句子嵌入 M 相结合,生成新的句子表示。
softmax层
基于统计机器学习的方法
我们使用 SVM 开发基于统计机器学习的模型。
语义特征
使用 LIWC 词典来获取基于语义信息的模式。

语言过程(LP)
分类为代词、冠词、动词、副词、连词、否定、量词等的单词均归入此类。
心理过程 (PP)
标记为社交、情感、认知生物过程的单词均归入此类。
个人关注 (PC)
与工作、成就、休闲、家庭、宗教、死亡等相关的单词都归入此类。
情绪特征
夸张
正/负标点符号
正/负省略号
最大长度正/负短语
标点符号功能
引号数量
感叹号的数量
问号数量
省略号数量
感叹词数量
🧪实验:
📇 数据集:
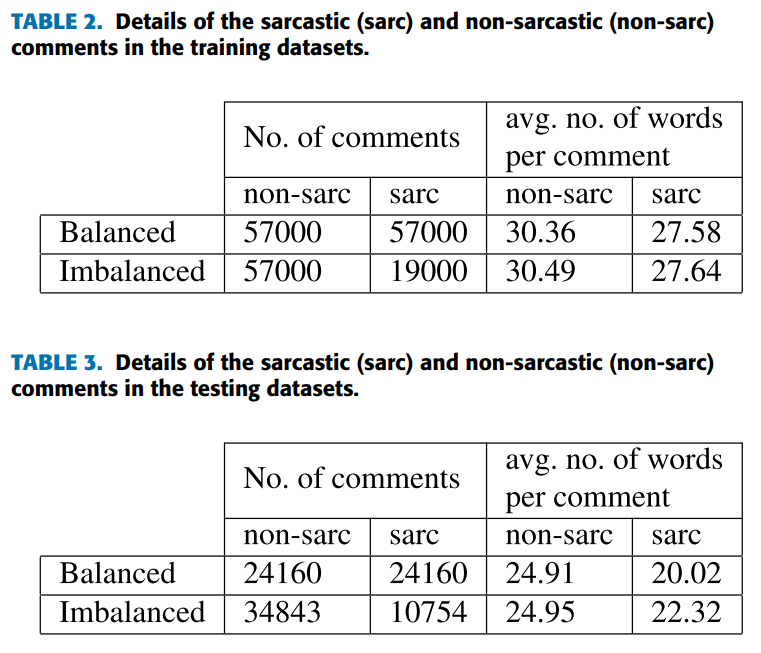
使用大型自注释讽刺语料库 SARC 1 [20] 来创建我们的数据集。
我们使用 SARC 语料库的训练和测试数据集来为我们的实验创建平衡和不平衡的数据集(代表了现实世界的场景)。
我们在训练/测试数据集中保持讽刺和非讽刺评论之间的比例为 25:75(大约)。
我们将每个训练集随机分为两个训练集(90%)和验证集(10%)。
📏评估指标:
我们使用精度、召回率和 F1分数来评估讽刺检测模型的性能。
📉 优化器&超参数:
利用二元交叉熵损失训练该模型。
我们使用带有 RBF 核的 SVM 来训练所有基于统计的机器学习模型,默认参数和最大迭代次数为 1000。
100 维词嵌入、100 个隐藏单元并将 dropout 固定为 0.5。
对于自注意力句子嵌入,我们使用隐藏单元为 200 的 MLP 层, 4 个注意力头和 11 维辅助特征向量。
使用标准 Adam 优化器,学习率为 0.005,小批量大小为 128,轮次为 50。(并设置5轮提前停止)
💻 实验设备:
📊 消融实验:
通过将注意力头的数量从1增加到4,可以提高MHA-BiLSTM在两个数据集上的F分数,但注意力头的进一步增加会降低MHA-BiLSTM的性能。
📋 实验结果:
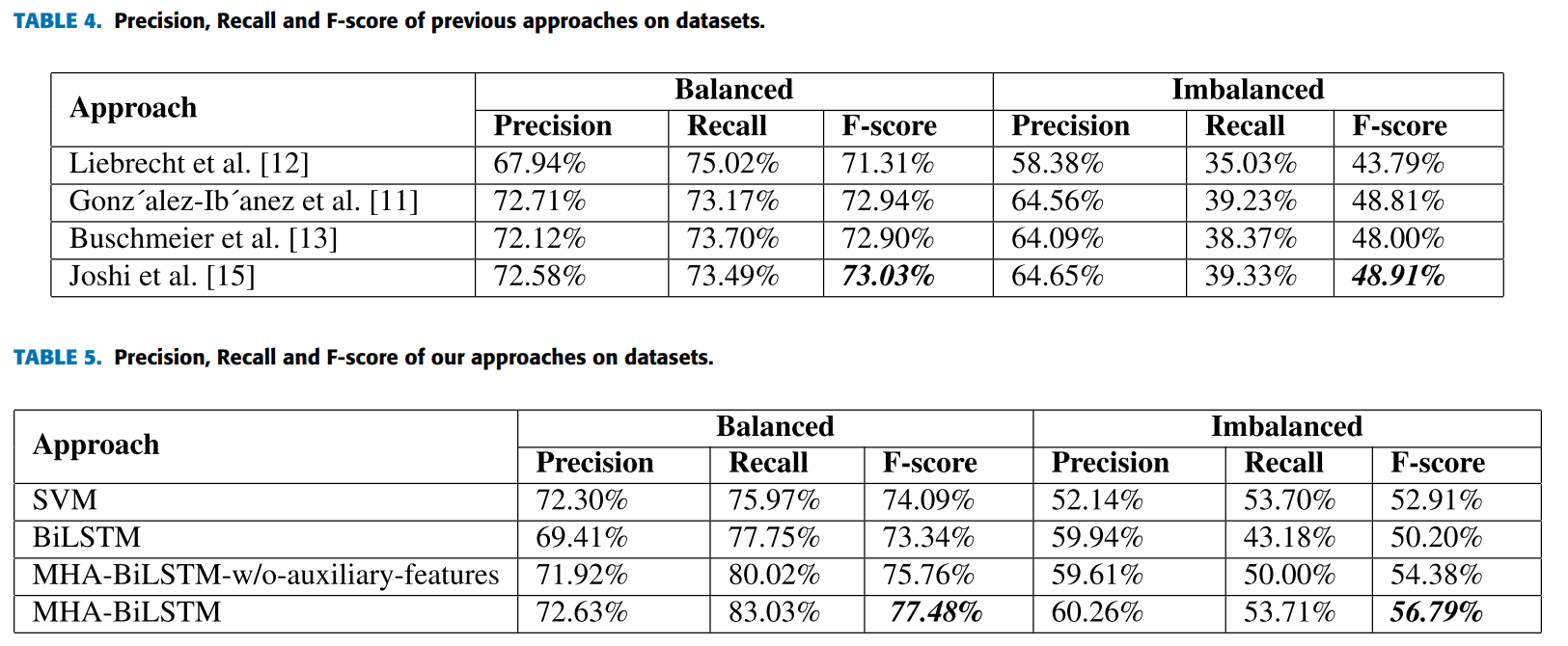
据观察,没有注意力机制的 BiLSTM 在两个数据集上都显示出最小的 F 分数。
特征丰富的 SVM 的性能优于 BiLSTM,但在两个数据集上其性能均明显低于 MHA-BiLSTM。
多头自注意力机制提高了深度神经网络的性能。
手动设计的辅助特征在提升 MHA-BiLSTM 的性能方面发挥着重要作用。
🚩研究结论:
我们将我们的 SVM 模型与之前的四个模型进行比较,发现我们的特征丰富的模型比其他模型具有更好的 F 分数。
这项工作的主要贡献是引入基于多头注意力的双向长短期记忆(MHA-BiLSTM)来进行讽刺检测。
我们发现,在网络中包含手动生成的辅助特征进一步增强了 BiLSTM 模型的有效性。
📝总结
💡创新点:
考虑各种手工特征并构建用于讽刺检测的支持向量机(SVM)模型。
我们提出了一种基于多头自注意力的双向长短期记忆(MHA-BiLSTM)网络。
🖍️知识补充:
双向 LSTM 由前向 LSTM 层和后向 LSTM 层组成。前向层捕获序列的历史信息;后向层捕获序列的未来信息。
在给定的评论中,评论的特定部分在检测讽刺方面起着重要作用。然而,一个单词可能有多个因素受到关注,因此我们需要多个注意力头,其中每个单词从多个因素中被赋予适当的重要性,以代表评论的整体语义。
注意力分析:多头自注意力背后的直觉是提取评论的不同方面。单一注意力头通常专注于评论的特定部分,这种机制有助于理解评论中语义的一个方面。