插入排序
一、排序
排序大家都很了解,就是2431变成1234这样。但是我们都知道,一般讲一个东西都是有定义的,排序的定义就是:
排序(sort)是重新排列表中的元素,使表中的元素满足按关键字有序的过程。
输入:n 个记录 R1,R2,……,Rn,对应的关键字为 k1,k2,……,kn。
输出:输入序列的一个重排 R1’,R2’,……,Rn’,使得有 k1’ ≤ k2’ ≤ …… ≤ kn’(也可以递减)
排序算法的评价指标当然还是时间复杂度和空间复杂度了,这个和其他算法一样的。但是!不一样的是,排序还有一个评价的指标,叫做“稳定性”
排序算法的稳定性:若待排序表中有两个元素 Ri 和 Ri ,其对应的关键字相同,即 keyi = keyj,且在排序前 Ri 在 Rj 的前面,若使用某一排序算法排序后, Ri 仍在 Rj 的前面,则成这个排序算法是稳定的,否则称排序算法是不稳定的。
举个栗子就很直观了,比如:
| 6 | 3 | 2 | 5 | 1 | 4 | 3 |
|---|
排序后变成:
| 1 | 2 | 3 | 3 | 4 | 5 | 6 |
|---|
就说这个排序算法是稳定的,即关键字相同的元素在排序之后相对位置不变
如果排序后变成:
| 1 | 2 | 3 | 3 | 4 | 5 | 6 |
|---|
就说这个排序算法是不稳定的,即关键字相同的元素在排序之后相对位置变了
当然,稳定的排序算法不一定比不稳定的好,具体需要看实际需求。
我们排序算法其实按照数据存放在哪可以分为两种,内部排序和外部排序:
- 内部排序——数据都在内存中
- 外部排序——数据太多,无法全部放入内存
啥意思呢?这个“内”和“外”其实是看你的数据在内存“里”还是在内存“外”,因为我们的内存不是无限大的,当内存不够大的时候就要存储在磁盘中,所以就有了这两个划分。
但是我们在对这些数据进行一些操作的时候,如果是放在外存的,那就得通过“读磁盘”读到内存中,然后再把结果“写磁盘”写到外存里。但是还记得吗?内存的读写速度要比外存快得多,所以我们“内部排序”和“外部排序”要考虑的地方就不一样了。
如果是内部排序,因为内存本身读写就很快,所以我们的内部排序只需要关注如何使时、空复杂度更低就可以了;但是外部排序,由于多了读写磁盘,所以我们除了关注如何使时、空复杂度更低之外,还要关注如何使读/写磁盘次数更少。
我们之后的排序算法都在之前给过的旧金山大学的链接里面有的。在哪?在前几篇吧。好吧不用找了,再发一次:
https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
二、插入排序
什么是插入排序呢?就是拎出来,找到合适的位置插进去。这个“合适的位置”就是看我们的算法是要正序还是逆序了,正序就是把拎出来的插在它之前比它大的前面,逆序就是把拎出来的插在它之前比它小的前面,当然指针是一个一个从前往后遍历走的哈。
举个易于理解的栗子:
比如给一个序列4321,要正序排,怎么排序?先看第一个“4”,给它拎出来,发现它前面没有比它大的,所以下一个;(现在还是4321)
下一个“3”,也给它拎出来,发现前一个就是比它大的,所以把它前一个“4”往后挪一格,即放到拎出来的那个位置,再往前看。发现往前没了,所以把拎出来的“3”插到现在空出来的位置上;(现在是3421)
再下一个“2”,还是给它拎出来,发现前一个就是比它大的,所以把它前一个“4”往后挪一格,即放到拎出来的那个位置;再往前看“3”,发现还是比拎出来的“2”大的,所以把“3”也往后挪一格;再往前看,发现往前没了,遂把拎出来的“2”插到现在空出来的位置上;(现在是2341)
最后一个“1”,当然还是给它拎出来,发现前一个就是比它大的,所以把它前一个“4”往后挪一格,即放到拎出来的那个位置;再往前看“3”,发现还是比拎出来的“1”大的,所以把“3”也往后挪一格;再往前看“2”,发现又是比拎出来的“1”大的,所以把“2”也往后挪一格;再往前看,发现往前没了,遂把拎出来的“1”插到现在空出来的位置上;(现在是1234)
所以插入排序的算法思想是:每次将一个待排序的记录按其关键字大小插入到前面已排好序的子序列中,直到全部记录插入完成。
1.直接插入排序
比如我们有一个序列:
| 49(1) | 38 | 65 | 97 | 76 | 13 | 27 | 49(2) |
|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
指针 i 指向 1 ,首先我们把“38”拎出来:
38
| 49(1) | 65 | 97 | 76 | 13 | 27 | 49(2) | |
|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
我们依次遍历检查指针 i 前面位置的所有元素,把所有大于刚拎出来的值的元素都向后挪一位
发现只有一个“49”比“38”大,于是前面的“49”往后挪一个位置:
| 49(1) | 65 | 97 | 76 | 13 | 27 | 49(2) | |
|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
“38”插入到空的位置:
| 38 | 49(1) | 65 | 97 | 76 | 13 | 27 | 49(2) |
|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
指针 i 指向 2 ,我们把“65”拎出来:
65
| 38 | 49(1) | 97 | 76 | 13 | 27 | 49(2) | |
|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
我们依次遍历检查指针 i 前面位置的所有元素,把所有大于刚拎出来的值的元素都向后挪一位
(弱弱插一句,其实你有没有发现,我们从前往后一个一个顺序执行这个过程,那么指针 i 前面的元素就一定是有序的,因为执行完指针 i 指的这一轮的排序才可以向后移动指针 i ,所以 i 前面必有序。
so往前一个一个找,目的是把所有比它大的往后挪,那也就是说如果遇到比它小的则就不用往前找了,因为前面肯定也比它小。
我们说回正题。指针 i 前面位置的所有元素,一个一个往前找都没有比拎出来的“65”大的,所以“65”还是放回原来的位置:
| 38 | 49(1) | 65 | 97 | 76 | 13 | 27 | 49(2) |
|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
指针 i 接着往后走。
指针 i 指向 3 ,我们把“97”拎出来:
97
| 38 | 49(1) | 65 | 76 | 13 | 27 | 49(2) | |
|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
我们依次遍历检查指针 i 前面位置的所有元素,把所有大于刚拎出来的值的元素都向后挪一位
显然和上面“65”流程一样的,这里不再赘述。结果还是“97”放回原来的位置:
| 38 | 49(1) | 65 | 97 | 76 | 13 | 27 | 49(2) |
|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
指针 i 接着往后走。
指针 i 指向 4 ,我们把“76”拎出来:
76
| 38 | 49(1) | 65 | 97 | 13 | 27 | 49(2) | |
|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
我们依次遍历检查指针 i 前面位置的所有元素,把所有大于刚拎出来的值的元素都向后挪一位
发现“97”比“76”大,于是前面的“97”往后挪一个位置:
| 38 | 49(1) | 65 | 97 | 13 | 27 | 49(2) | |
|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
“65”比“76”小,所以前面的就不用比了,肯定也比“76”小“。
“76”遂插入到空的位置:
| 38 | 49(1) | 65 | 76 | 97 | 13 | 27 | 49(2) |
|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
指针 i 接着往后走。
指针 i 指向 5 ,我们把“13”拎出来:
13
| 38 | 49(1) | 65 | 76 | 97 | 27 | 49(2) | |
|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
我们依次遍历检查指针 i 前面位置的所有元素,把所有大于刚拎出来的值的元素都向后挪一位
发现依次比,前面所有的元素都比“13”大,于是前面的全部都往后挪一个位置:
| 38 | 49(1) | 65 | 76 | 97 | 27 | 49(2) | |
|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
“13”遂插入到空的位置:
| 13 | 38 | 49(1) | 65 | 76 | 97 | 27 | 49(2) |
|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
指针 i 接着往后走。
指针 i 指向 6 ,我们把“27”拎出来:
27
| 13 | 38 | 49(1) | 65 | 76 | 97 | 49(2) | |
|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
我们依次遍历检查指针 i 前面位置的所有元素,把所有大于刚拎出来的值的元素都向后挪一位
发现依次往前比,比到“38”的时候还是比“27”大,但是再往前的“13”就比“27”小了。所以“13”后面的都往后挪,“13”不动:
| 13 | 38 | 49(1) | 65 | 76 | 97 | 49(2) | |
|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
“27”遂插入到空的位置:
| 13 | 27 | 38 | 49(1) | 65 | 76 | 97 | 49(2) |
|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
指针 i 接着往后走。
指针 i 指向 7 ,我们把“49”拎出来:
49(2)
| 13 | 27 | 38 | 49(1) | 65 | 76 | 97 | |
|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
我们依次遍历检查指针 i 前面位置的所有元素,把所有大于刚拎出来的值的元素都向后挪一位
发现前面的“97”,“76”,“65”都比“49”大,再往前就不比“49”大了,所以“97”,“76”,“65”向后挪:
| 13 | 27 | 38 | 49(1) | 65 | 76 | 97 | |
|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
“49”遂插入到空的位置:
| 13 | 27 | 38 | 49(1) | 49(2) | 65 | 76 | 97 |
|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
所以我们能很明显地看出,插入排序算法是稳定的。
我没说出来,其实刚刚我们走过的排序操作就是插入排序算法实现的操作,这知识不就进脑子了~话不多说,上代码:
//直接插入排序
void insertSort(int A[],int n){
int i,j,temp;
for( i=1;i<n;i++){ //将各元素插入已排好序的序列中
if(A[i] < A[i-1]){ //若A[i]关键字小于前驱
temp = A[i]; //用temp暂存A[j]
for( j=i-1; j>=0 && A[j]>temp; --j){//检查所有前面已排好序的元素
A[j+1] = A[j]; //所有大于temp的元素都向后挪位
}
A[j+1] = temp; //复制到插入位置
}
}
return;
}
非常清晰吧。
But其实还有一种方式,就是我们上面的算法其实用了一个temp变量存储我们拎出来的那个元素,但其实我们可以不用temp来存,也就是用“哨兵”的方式,把表中的第一个元素用来存放我们拎出来的那个东西。
好处就是每轮不用再判断 j 指针是不是 ≥ 0,有没有越界了,因为我们A[0]存放的就是拎出来的那个元素,再怎么比当比到A[0]的时候A[0]也不可能比拎出来的元素大,所以不会越界。
当然看不明白也没关系,会上面那个就可以了,这都没啥。
带哨兵的算法实现:
//直接插入排序(带哨兵)
void insertSortWithHead(int A[],int n){
int i,j;
for( i=2;i<=n;i++){ //依次将A[2]~A[n]插入到前面已排序序列
if(A[i] < A[i-1]){ //若A[i]关键码小于其前驱,将A[i]插入有序表
A[0] = A[i]; //复制为哨兵,A[0]不存放元素
for( j=i-1; A[0]<A[j];j--){ //从后往前查找待插入位置
A[j+1] = A[j]; //向后挪位
}
A[j+1] = A[0]; //复制到插入位置
}
}
}
2.折半插入排序
其实这个我们刚刚就已经想到了,是吧。
因为显然啊,每一轮比的时候,它前面都有序了,一个一个遍历找多麻烦,不如直接把前面的进行折半查找,这样的话比较省时间。
思路:先用折半查找找到应该插入的位置,再移动元素
这有点麻烦,那还说不说啊
算了说吧,举个栗子,看不看都行,反正我们会前面那个就可以了。
| 55 | 20 | 30 | 40 | 50 | 60(1) | 70 | 80 | 55 | 60(2) | 90 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
这是带哨兵的。
我们现在的指针 i 指向的是 8,
所以把指向位置的元素放到哨兵位置,指针 i 既然移到了这个位置,说明前面都是有序的,如上图所示。现在我们来折半查找哨兵应该插入的位置:
还记得吗?首先当然是 low high mid。low指向下标为1在的地方,high指向下标为7在的地方,所以现在mid = (low+high)/2 = 4 ;
mid是“50”,50<55,所以应该往mid右半边找,so low新=mid+1=5,high还是7,所以mid新 = (low新+high)/2 = 6;
mid是“70”,70>55,所以应该往mid左半边找,so low还是5,high新=mid-1=5,所以mid新 = (low+high新)/2 = 5;
mid是“60”,60>55,所以应该往mid左半边找,so low还是5,high新=mid-1=4,所以mid新 = (low+high新)/2 = 4?错!
现在low>high了,这是不可以的,有违我们折半查找祖制
so当 low>high 时折半查找停止,应将 [low,i - 1] 内的元素全部右移,并将 A[0] 复制到 low 所指位置。
为啥?其实稍微想一下就明白了,这个我们在折半查找那篇也说过,现在再说一遍。
首先这个序列由小到大,我们low>high之前一定先是low==high,完了如果现在我们mid值比我们关键字小,是不是说明应该往mid右半边找,也就是low=mid+1(导致了low>high),但是此时这个关键字应该插入的位置就是mid右边,所以应该把low及之后到i-1的全部右移;
如果现在我们mid值比我们关键字大,那就说明应该往mid左半边找,也就是high=mid-1(导致了low>high),但是此时这个关键字应该插入的位置就是mid左边,所以还是应该把low及之后到i-1的全部右移。
好了回到正题,so我们应该把 [low,i - 1] ( [5,7] )元素往后挪,再把 A[0](55) 复制到 low(5) 所指位置,即:
| 55 | 20 | 30 | 40 | 50 | 55 | 60(1) | 70 | 80 | 60(2) | 90 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
接下来我们现在的指针 i 指向的是 9
所以把指向位置的元素放到哨兵位置:
| 60(2) | 20 | 30 | 40 | 50 | 55 | 60(1) | 70 | 80 | 60(2) | 90 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
再来折半查找元素“60”应该放的位置,初始low指向下标为1在的地方,high指向下标为8在的地方,所以现在mid = (low+high)/2 = 4
mid是“50”,50<60,所以应该往mid右半边找,so low新=mid+1=5,high还是8,所以mid新 = (low新+high)/2 = 6;
ATTENTION!此时 A[mid]和A[0]是相等的。这个时候应该怎么做?
答案是当 A[mid]==A[0] 时,为了保证算法的“稳定性”,应继续在 mid 所指位置右边寻找插入位置。
so我们继续往mid右半边找,low新=mid+1=7,high还是8,所以mid新 = (low新+high)/2 = 7;
mid是“70”,70>60,所以应该往mid左半边找,so low还是7,high新=mid-1=6,所以 low>high
之前我们说当 low>high 时折半查找停止,应将 [low,i - 1] 内的元素全部右移,并将 A[0] 复制到 low 所指位置。
所以我们应该把 [low,i - 1] ( [7,8] )元素往后挪,再把 A[0](60(2)) 复制到 low(7) 所指位置,即:
| 60(2) | 20 | 30 | 40 | 50 | 55 | 60(1) | 60(2) | 70 | 80 | 90 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
………………
后面过程不再赘述,还是按照这种方式,直到 i == 11 排完序为止。
话不多说,上代码:
//折半插入排序
void InsertSortWithMid(int A[],int n){
int i,j,low,high,mid;
for(i = 2; i <= n; i++){ //依次将A[2]~A[n]插入前面的已排序序列
A[0] = A[i]; //将A[i]暂存到A[0]
low = 1; //设置折半查找的范围
high = i-1;
while(low <=high){ //折半查找(默认递增有序)
mid=(low+high)/2; //取中间点
if(A[mid] > A[0]){ //查找左半子表
high = mid - 1;
}else{
low = mid + 1; //查找右半子表
}
}
for(j=i-1;j>=high+1;j--){
A[j+1] = A[j]; //统一后移元素,空出插入位置
}
A[high+1] = A[0]; //插入操作
}
}
代码还是更加清晰一些,其实和插入排序没什么区别,主要就是注意两个,一个是遇到和mid相等的了就往人右半部分找,还有一个是low>high了折半查找停止了,就在low这个位置做文章,low及其之后到i-1都往后挪,然后low不就空出来了吗,哨兵再放到low就vans了。
3.性能
首先我们的空间复杂度肯定是O(1),这没得说。其次我们就要看时间复杂度是多少了
时间消耗主要来自于对比关键字、移动元素。
如果有 n 个元素,则需要 n-1 轮处理
最好情况当然是原本就有序,这样就不需要移动元素,而且每一趟只需要对比关键字1次就可以了,所以最好时间复杂度是O(n);
最坏情况是逆序,每一趟都要把前面的元素比完,且要移动前面元素个数+1(自己也要移动)个,又因为 n 个元素要 n 趟处理,所以最坏时间复杂度是 O(n2).
那我们优化过后的折半插入排序呢?
比起直接插入排序,折半插入排序比较关键字的次数减少了,但是移动元素的次数没变。总体看起来,时间复杂度依然是O(n2)。(所以这其实也没必要用,反正也差不多)
那我们刚刚说的是顺序表,如果是链表呢?
用链表肯定第一反应是移动元素不用一批一批往后挪了,直接随机插入得了,所以移动元素的次数肯定是变少了。但是关键字该比还是得比,不然怎么直到插到哪,所以关键字对比的次数依然是O(n2),so正题来看时间复杂度又双叒叕还是O(n2)。
对了插入排序是稳定的哈
三、希尔排序
希尔排序是一个叫希尔的人搞出来的,所以叫这个名字,没别的意思。
希尔排序(Shell Sort)思想:先追求表中元素部分有序,再逐渐逼近全局有序。
啥意思呢?我们来看:
1.算法过程
希尔排序:先将待排序表分割成若干形如 L[ i,i+d,i+2d,……,i+kd] 的“特殊”子表,对各个子表分别进行直接插入排序。缩小
增量d,重复上述过程,直到 d=1 为止。
看起来难以理解,其实举个栗子就很易懂了。比如这是我们的顺序表:
| 49(1) | 38 | 65 | 97 | 76 | 13 | 27 | 49(2) | |
|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
我们第一趟让 d1 = n/2 = 4:
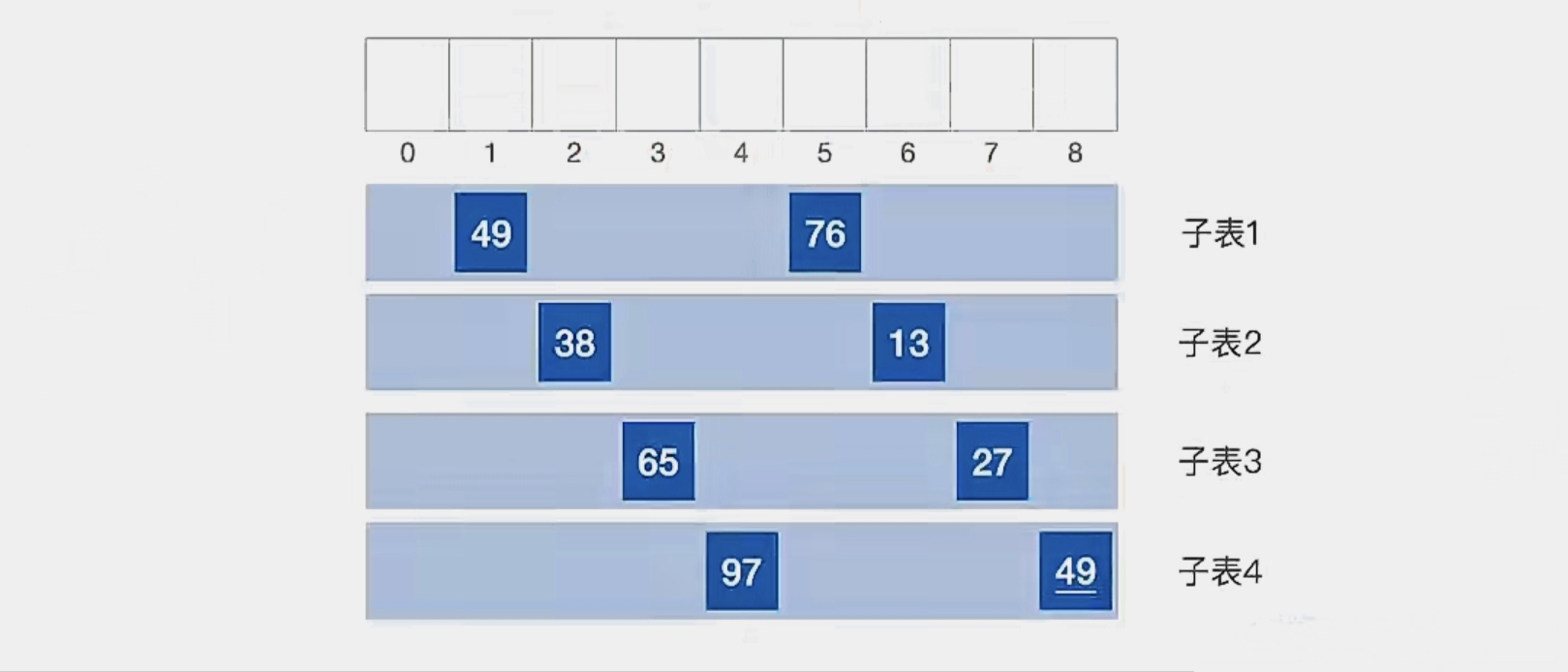
可以看到当间隔为“4”的时候,可以分为 4批,即
“第1个元素和第5个元素”
“第2个元素和第6个元素”
“第3个元素和第7个元素”
“第4个元素和第8个元素”
4个子表
现在我们对各个子表分别进行直接插入排序:
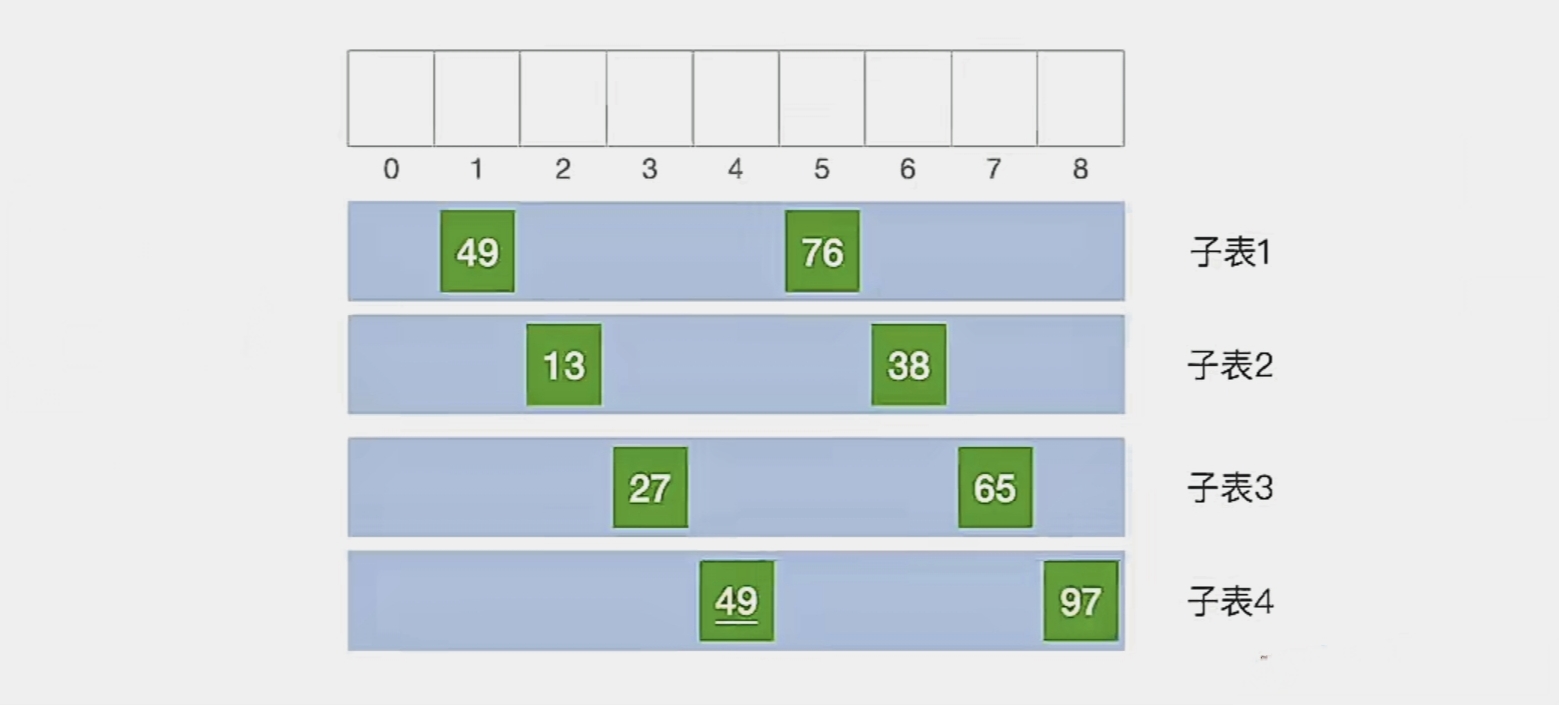
那我们第1趟就结束了,现在我们的顺序表是这样的:
我们缩小增量d,进行第二趟
我们第二趟让 d2 = d1/2 = 2:
可以看到当间隔为“2”的时候,可以分为2批,即
“第1个元素、第3个元素、第5个元素、第7个元素”
"第2个元素、第4个元素、第6个元素、第8个元素”
2个子表
现在我们对各个子表分别进行直接插入排序:
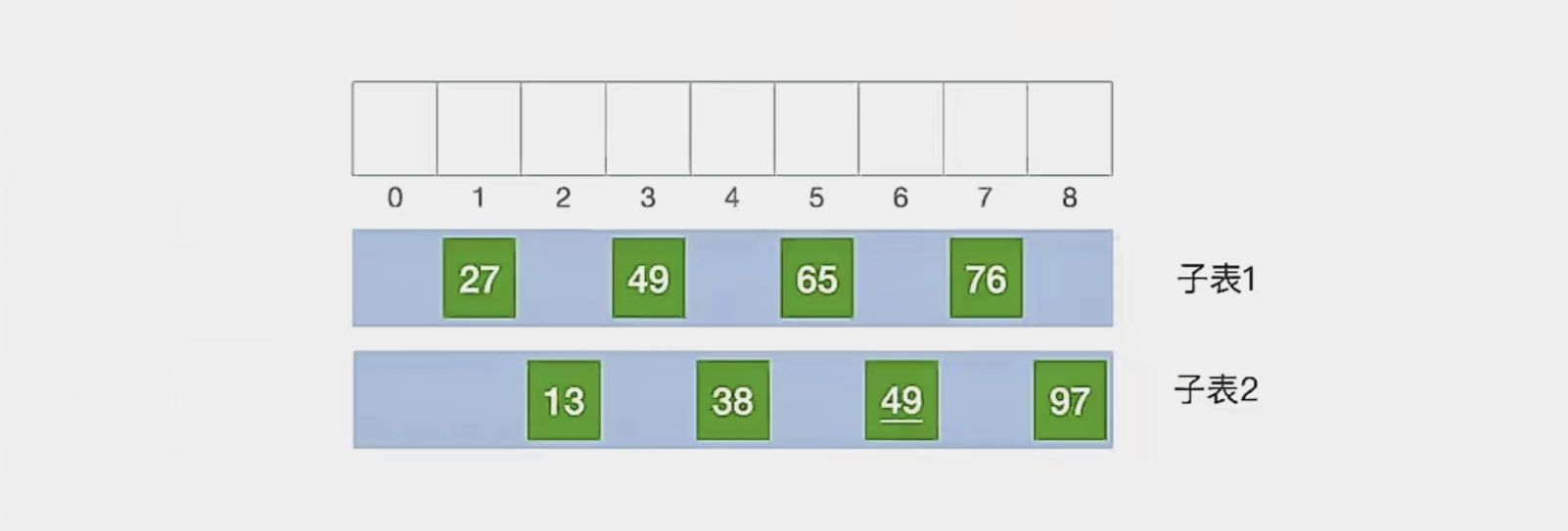
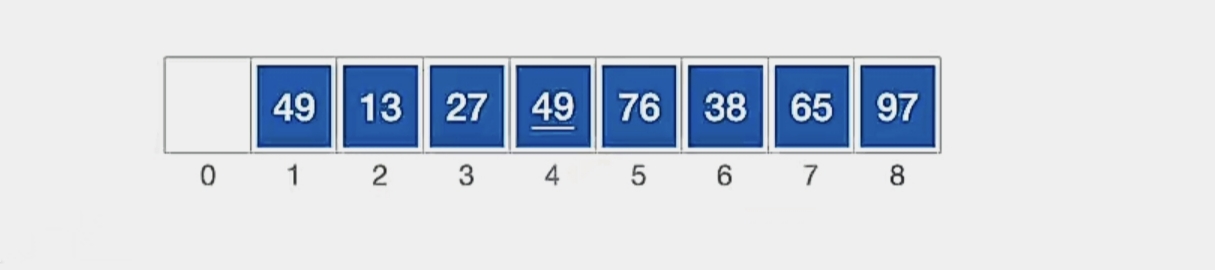
那我们第2趟就结束了,现在我们的顺序表是这样的:
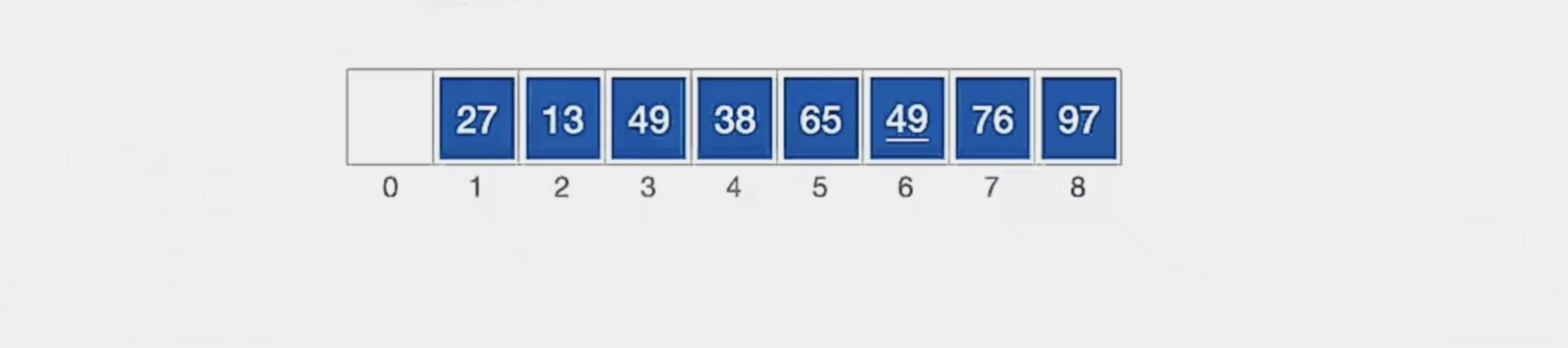
我们缩小增量d,进行第三趟
我们第三趟让 d3 = d2/2 = 1:
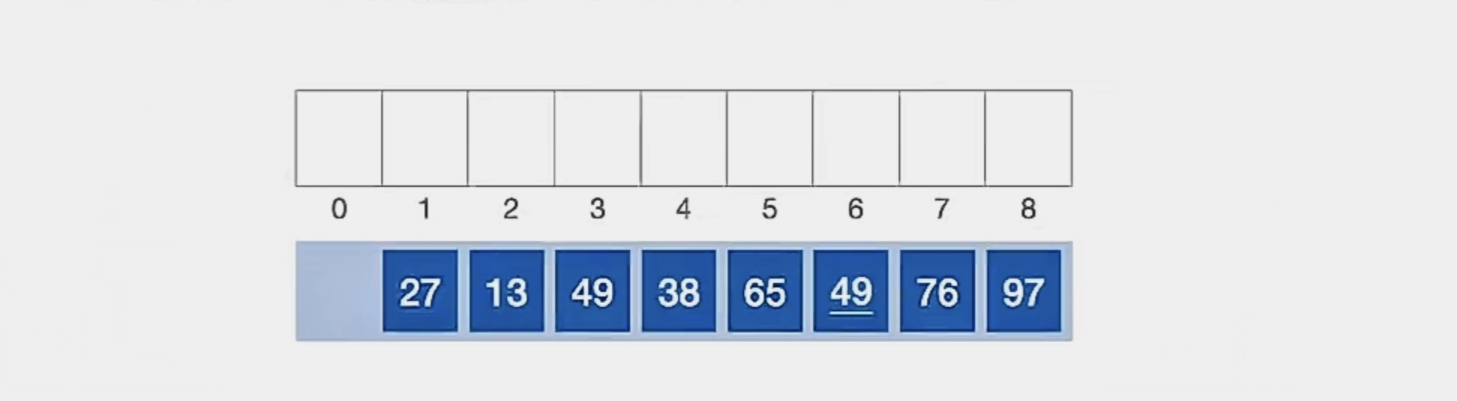
可以看到当间隔为“1”的时候,可以分为1批,即
“所有元素”
1个子表
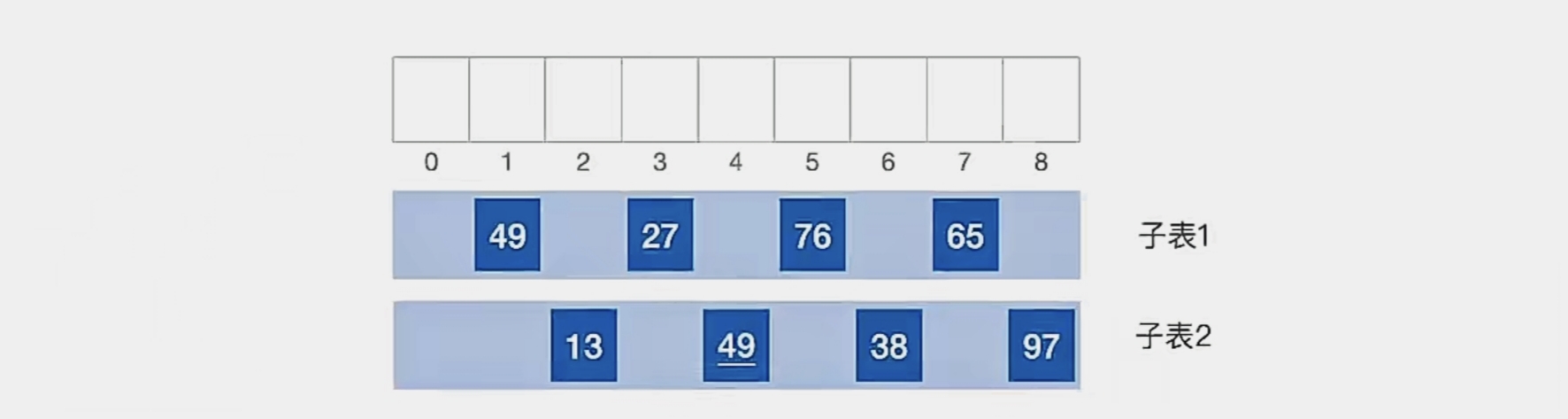
可以看到,整个表已经呈现出“基本有序”。现在我们再对这个表整体进行一次直接插入排序:
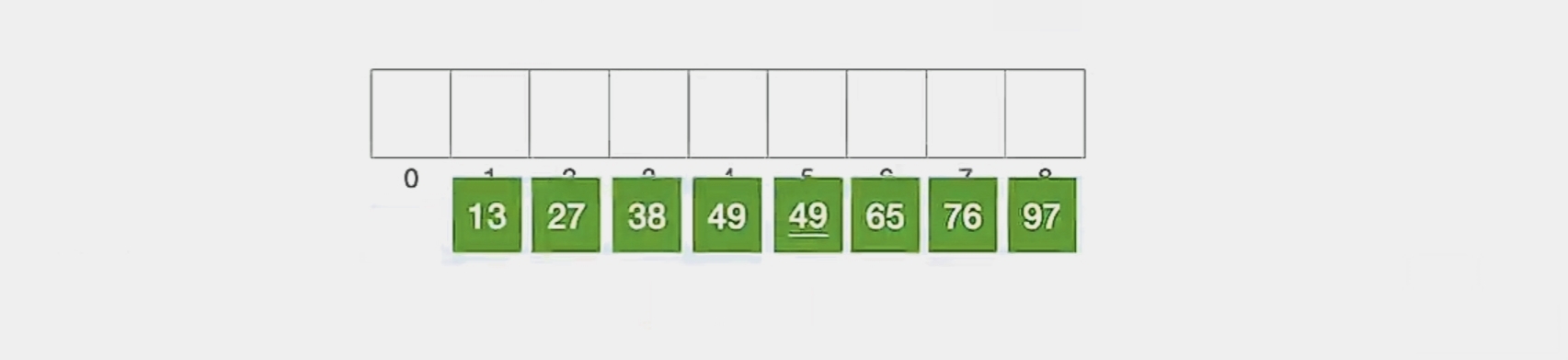
那么我们就完成了排序,可以看到这个希尔排序其实是基于直接插入排序的。总体再来感受一下,每一趟的结果就是这样的:
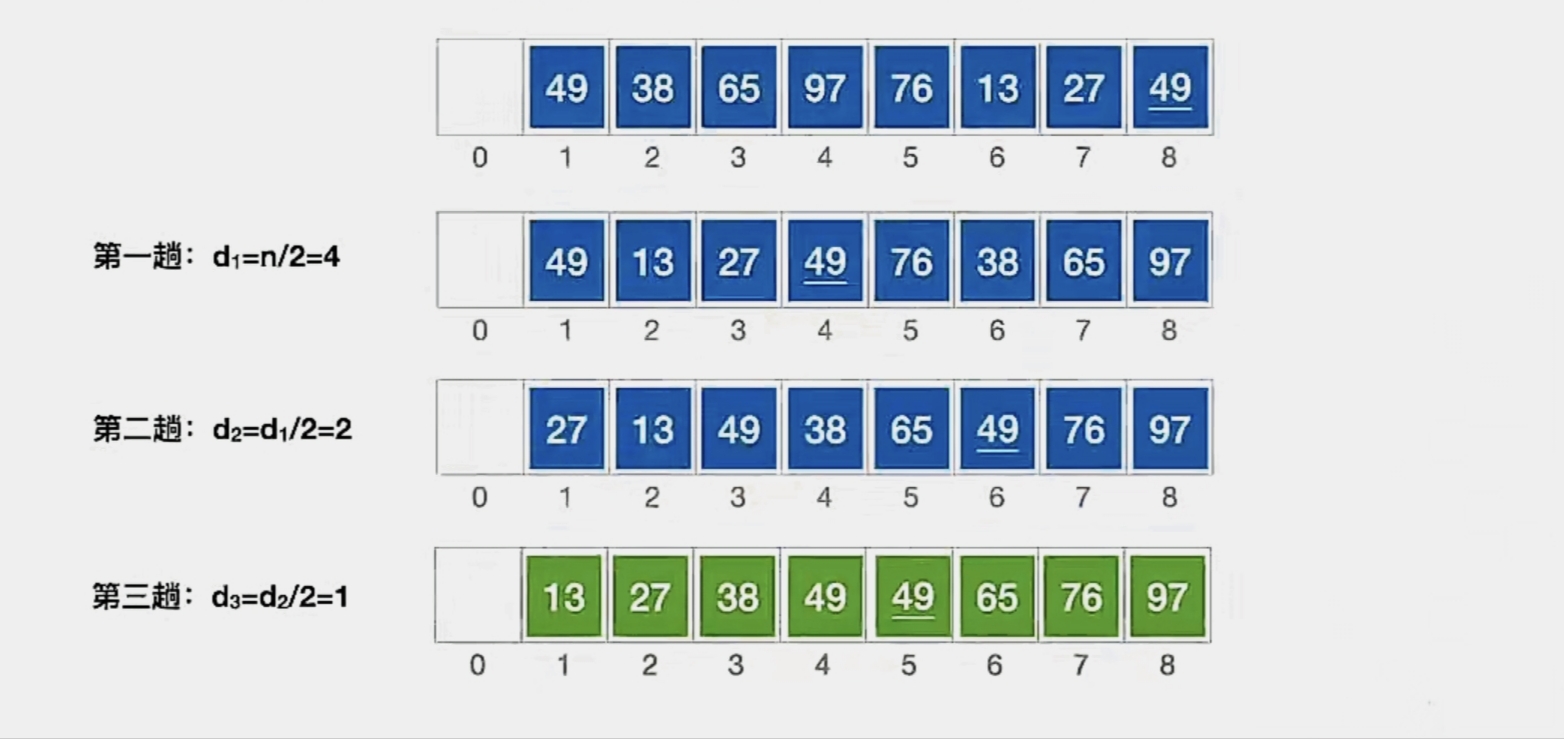
那么说到这里,可能就会发出疑问,这个“增量”到底为什么我们让它每次砍半?为毛不是变成1/4啥的?那这就得开麦回应一下了,没有为毛,人家希尔自己说的,他建议每次将增量缩小一半。
现在我们了解了希尔排序,来看代码:
//希尔排序
void ShellSort(int A[],int n){
int d,i,j;
//A[0]只是暂存单元,不是哨兵,当j<=0时,插入位置已到
for(d = n/2; d>=1; d=d/2){ //步长变化
for(i = d+1; i<=n; i++){
if(A[i] < A[i-d]){ //需将A[i]插入有序增量子表
A[0]=A[i]; //暂存在A[0]
for(j=i-d; j>0 && A[0]<A[j]; j-=d){
A[j+d]=A[j]; //记录后移,查找插入的位置
}
A[j+d]=A[0]; //插入
}
}
}
}
代码还是更加清晰。可以看到其实我们是针对每一个子表进行的直接插入操作,这个子表间隔就是我们直接插入排序的指针 i 每次移动的位置,然后哨兵的位置暂存一下拎出来的元素。其他的就和插入排序一毛一样了,不过还要注意一下宏观,增量减到1为止,这里不再赘述。
2.性能
希尔排序的性能不太好判断,和增量序列 d1,d2,d3,……的选择有关,目前无法用数学手段证明确切的时间复杂度。
最坏时间复杂度为O(n2),当n在某个范围内时,可达O(n1.3)。
那它稳不稳定呢?
举个栗子吧,比如我们的序列是 3 2 “2”,现在我们来由小到大排序,第一趟增量d1=2
那这一趟下来就变成了 “2” 2 3
第二趟增量d2 = d1 /2 = 1
这趟下来还是 “2” 2 3
所以希尔排序是不稳定的。
总结
插入排序就是指针 i 每往后一个就是一趟,每趟都看前面那些比它大(小),直接插入排序就是依次对比找到比它大(小)的往后挪,折半插入排序就是折半查找到比它大(小)的往后挪(因为指针 i 前面一定是有序的),要注意的地方就是折半插入排序的两个点,一个是遇到和mid相等的了就往人右半部分找,可以保证稳定性;还有一个是low>high了折半查找停止了,就在low这个位置做文章,low及其之后到i-1都往后挪,然后low不就空出来了吗,哨兵再放到low就vans了。
希尔排序主要是根据增量序列分成几个子表,再对每个子表进行直接插入排序,增量逐个减半,直到为1为止(为1就是这个表本身了),主要还是得能在给出增量序列的时候,分析每一趟排序后的状态,其他没啥。