目录
URI
URI是一种用于标识资源的字符串,它通过一种标准化的方式为资源提供一个唯一的名称或地址。
URI是一种更广泛的标识符,它可以用来标识任何资源,包括文档、图片、视频、服务等。
例如:http://example.com/path/to/resource?query=param#fragment

URL
URL是URI的一个子集,它不仅标识资源,还提供了资源的访问位置和方式。URL主要用于定位网络上的资源,并且可以通过网络协议访问这些资源。
URI与URL的区别
- URI用于标识资源,而URL用于定位资源。
- URI的范围更广,包括URL和URN
我们经常使用URL来访问网络资源,因为URL提供了明确的访问路径和协议。而URI则更侧重于资源的唯一标识,适用于更广泛的场景,包括资源的命名和引用。
HTTP请求
客户端可以向服务器发送指令,请求获取资源或执行操作,服务器则根据请求返回相应的响应
HTTP请求的组成:
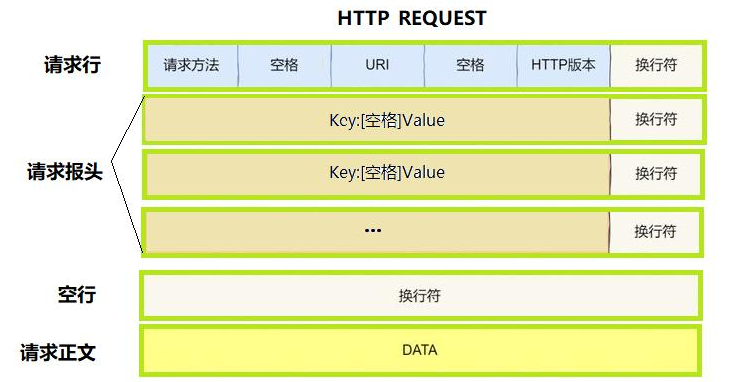
完整的组成由三部分组成请求行,请求头,请求体
请求行:由请求方法、URI、HTTP版本组成
请求头:包含客户端向服务器发送的额外信息,如请求的资源类型、客户端支持的编码方式、用户代理信息等。
请求体:可选部分,用于发送数据给服务器
HTTP请求方法
HTTP的请求方法有多种
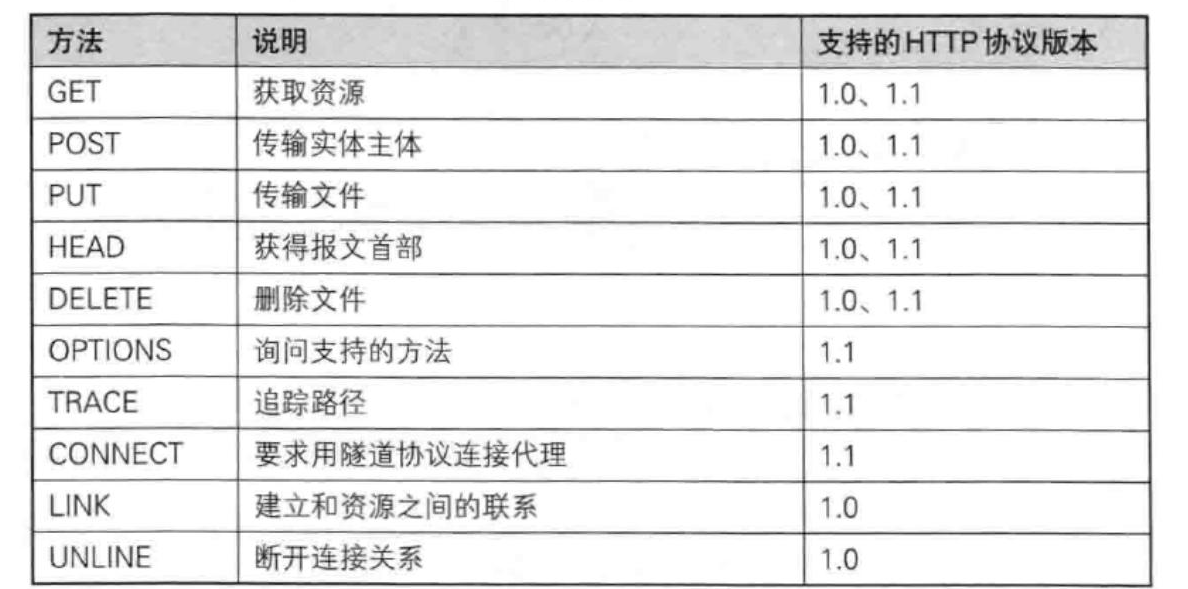
其中最常用的就是GET和POST方法
GET
GET方法用于请求访问服务器上指定的资源。它不会对资源进行修改,只是简单地获取资源的内容。
用途:
获取网页内容(HTML、CSS、JavaScript等)。
获取图片、视频、音频等静态资源。
查询数据库并返回结果(例如,通过URL参数传递查询条件)。
获取API接口的响应数据。
GET如果要进行参数的提交,是通过uri进行提交的
例如:
GET /search?q=example HTTP/1.1参数为:q=example
这就意味着GET方法的参数不可以过长,因为uri的长度是有限的
POST
POST请求用于向服务器提交数据,请求服务器处理这些数据并返回结果。它通常用于创建新的资源或对现有资源进行修改。
用途:
提交表单数据(如用户注册、登录、评论等)。
上传文件(如图片、文档等)。
向服务器发送JSON或XML格式的数据(如API调用)。
创建新的资源(如在数据库中插入一条记录)。
POST与GET提交参数的方法不同
POST进行参数的提交,是通过http request正文提交的
这就意味着POST方法会传递长数据
PUT
PUT方法用于向服务器上传一个资源,或者更新一个已存在的资源。如果资源不存在,则创建它;如果资源已存在,则替换它。
用途:
用于上传文件或更新文件内容。
用于创建或更新数据库中的记录。
HEAD
HEAD方法与GET方法类似,但服务器不会返回响应体,仅返回响应头。通常用于检查资源是否存在,或者获取资源的元信息。
用途:
检查资源是否存在。
获取资源的元信息(如最后修改时间、内容类型等)。
DELETE
DELETE方法用于请求服务器删除指定的资源。
用途:
删除文件或数据库中的记录。
删除用户账户或其他资源。
OPTIONS
OPTIONS方法用于请求服务器返回支持的HTTP方法列表。
用途:
获取服务器支持的HTTP方法。
用于跨域请求的预检。
TRACE
TRACE方法用于回显服务器收到的请求,主要用于测试或诊断。服务器会将收到的请求原样返回给客户端。
用途:
用于调试和测试,查看请求在传输过程中的变化
CONNECT
CONNECT方法用于建立一个到服务器的隧道,通常用于代理服务器或SSL/TLS加密连接。
用途:
建立到代理服务器的隧道。
用于SSL/TLS加密连接。
LINK
LINK方法用于在两个资源之间建立一个关联(如创建一个链接)。这个方法在HTTP/1.1中已经废弃,但在某些旧系统中可能仍然使用。
用途:
在两个资源之间创建一个链接。
UNLINE
UNLINK方法用于移除两个资源之间的关联(如删除一个链接)。这个方法在HTTP/1.1中已经废弃,但在某些旧系统中可能仍然使用。
用途:
移除两个资源之间的链接。
HTTP响应
HTTP响应是服务器对客户端HTTP请求的答复
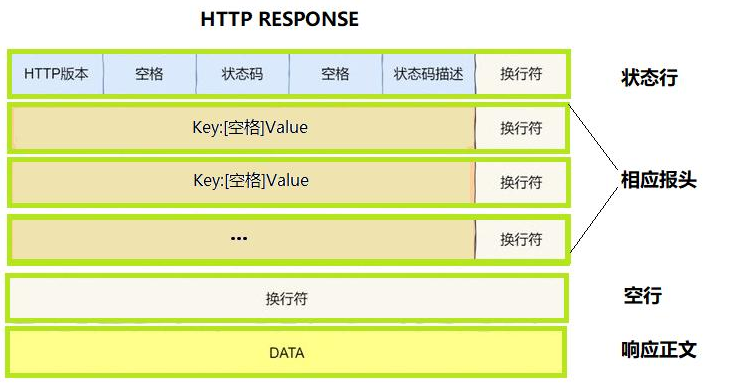
HTTP状态码
HTTP状态码是服务器在响应客户端请求时返回的三位数字代码,用于表示请求的结果。
状态码分为五类,每类都有不同的含义。
1. 1xx(信息性状态码)
这些状态码表示服务器已接收到请求,但仍在处理中,需要客户端继续等待。
100 Continue:服务器已收到请求头,客户端可以继续发送请求体。
101 Switching Protocols:服务器根据客户端的请求切换协议。
102 Processing:服务器已收到请求,正在处理中。
103 Early Hints:服务器已收到请求,但尚未准备好响应,提前发送一些链接信息(HTTP/2扩展)。
2. 2xx(成功状态码)
这些状态码表示请求已成功处理。
200 OK:请求成功,服务器返回了请求的资源。
201 Created:请求成功,并且服务器创建了新的资源。
202 Accepted:请求已接受,但尚未处理完成。
204 No Content:请求成功,但服务器没有返回内容。
3. 3xx(重定向状态码)
这些状态码表示客户端需要进一步操作才能完成请求。
301 Moved Permanently:请求的资源已永久移动到新的URL。(永久重定向)
302 Found:请求的资源临时移动到新的URL。(临时重定向)
304 Not Modified:请求的资源未修改,客户端可以使用缓存的版本。(临时重定向)
301和302都依赖Location选项(Key)
临时重定向
请求的资源临时移动到新的URL。客户端应使用新的URL访问资源,但搜索引擎和浏览器不会将原始URL替换为新的URL。
用途:
适用于临时性的页面跳转,例如在用户登录后跳转到用户主页。
适用于需要动态跳转的场景,例如根据用户位置或设备类型跳转到不同的页面。
永久重定向
请求的资源已永久移动到新的URL。客户端应使用新的URL访问资源,搜索引擎和浏览器会将原始URL替换为新的URL。
用途:
适用于网站结构变更,例如页面永久迁移或域名变更。
适用于优化URL结构,例如将旧的动态URL重定向到新的静态URL。
4. 4xx(客户端错误状态码)
这些状态码表示客户端请求有误。
400 Bad Request:请求格式错误,服务器无法理解。
401 Unauthorized:请求需要用户认证。
403 Forbidden:服务器拒绝执行请求。
404 Not Found:请求的资源不存在。
405 Method Not Allowed:请求方法不被允许。
409 Conflict:请求冲突,无法完成。
413 Payload Too Large:请求体过大,服务器拒绝处理。
429 Too Many Requests:请求频率过高,服务器拒绝处理。
5. 5xx(服务器错误状态码)
这些状态码表示服务器内部错误。
500 Internal Server Error:服务器内部错误,无法完成请求。
501 Not Implemented:服务器不支持请求的功能。
502 Bad Gateway:服务器作为网关或代理时,从上游服务器收到无效响应。
503 Service Unavailable:服务器暂时无法处理请求。
504 Gateway Timeout:服务器作为网关或代理时,上游服务器超时未响应。
HTTP常见Header
请求头
Host
描述:指定请求的主机名和端口号。
示例:Host: www.example.com
用途:用于虚拟主机,帮助服务器区分不同的域名。
User-Agent
描述:标识客户端的类型和版本信息。
示例:User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.164 Safari/537.36
用途:服务器可以根据User-Agent提供不同的内容或优化性能。
Accept
描述:告知服务器客户端可以接受的响应内容类型。
示例:Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
用途:服务器可以根据Accept头返回最合适的内容类型。
Accept-Language
描述:指定客户端希望接收的自然语言。
示例:Accept-Language: en-US,en;q=0.5
用途:服务器可以根据Accept-Language返回本地化的内容。
Accept-Encoding
描述:告知服务器客户端支持的压缩编码方式。
示例:Accept-Encoding: gzip, deflate
用途:服务器可以根据Accept-Encoding对响应内容进行压缩,节省带宽。
Content-Type
描述:指定请求体的媒体类型。
示例:Content-Type: application/json
用途:服务器可以根据Content-Type解析请求体中的数据。
Content-Length
描述:指定请求体的长度(以字节为单位)。
示例:Content-Length: 123
用途:服务器可以根据Content-Length读取完整的请求体。
Cookie
描述:发送存储在客户端的Cookie信息给服务器。
示例:Cookie: session_id=123456789
用途:服务器可以根据Cookie识别客户端的会话状态。
Referer
描述:指定请求的来源页面。
示例:Referer: http://www.example.com/page1
用途:服务器可以根据Referer进行访问控制或统计分析。
Connection
描述:指定连接是否应该保持打开状态(持久连接)或者在响应完成后关闭
示例:它有两个主要的值:Connection: keep-alive(长连接)、Connection: close(不支持长连接)
用途:服务器可以根据Referer进行访问控制或统计分析。
根据http协议,我有可能一次性读取到多个http请求,所以需要长连接
在 HTTP/1.1 协议中,默认使用持久连接
在 HTTP/1.0 协议中,默认连接是非持久的
响应头
Content-Type
同请求头
Content-Length
同请求头
Content-Encoding
同请求头
Content-Language
同请求头
Content-Disposition
描述:指定响应体的文件名,通常用于下载文件。
示例:Content-Disposition: attachment; filename="example.zip"
用途:浏览器可以根据Content-Disposition提示用户下载文件。
Location
描述:用于重定向,指定新的URL。
示例:Location: http://www.example.com/newpage
用途:客户端可以根据Location头跳转到新的页面。
Set-Cookie
描述:设置客户端的Cookie。
示例:Set-Cookie: session_id=123456789; Path=/
用途:服务器可以通过Set-Cookie在客户端存储会话信息。
Cache-Control
描述:指定缓存策略。
示例:Cache-Control: no-cache
用途:客户端可以根据Cache-Control决定是否缓存响应内容。
Expires
描述:指定响应的过期时间。
示例:Expires: Thu, 01 Jan 1970 00:00:00 GMT
用途:客户端可以根据Expires头决定响应是否过期。
Last-Modified
描述:指定资源的最后修改时间。
示例:Last-Modified: Wed, 21 Oct 2015 07:28:00 GMT
用途:客户端可以根据Last-Modified头进行缓存验证。
ETag
描述:用于资源的版本标识,用于缓存验证。
示例:ETag: "123456789"
用途:客户端可以通过ETag验证资源是否被修改。
Server
描述:标识服务器软件的名称和版本。
示例:Server: Apache/2.4.1 (Unix)
用途:客户端可以了解服务器的软件信息。
关于服务器首页和其他资源的访问
如果我们这样通过浏览器访问服务器:47.108.254.197:8080(/)
那么uri默认为/,我们可以设置一个目录为wwwroot,在这个目录下可以存放着我们的首页、以及其它的文件内容等
我们在浏览器段请求的时候,首页作为站点的入口,一个网站就是一棵多叉树
这样我们只需要在服务器接受http请求的uri的时候,我们将uri的路径改为/wwwroot/index.html,这样我们在给客户端发送响应的时候就能使用该路径下的文件内容来给客户端响应
/wwwroot/404.html同理
图片资源
图片资源的后缀一般都为.png、.jpg
所以若是我们收到的请求目标文件的后缀为.png或.jpg或其它等,我们需要去查Content-Type对照表
通过这个表我们可以查到Content-Type的值,将该键值返回给客户端即可,如下为示例:
| 文件扩展名 | Content-Type值 | 描述 |
| .png | image/png | PNG 图像文件 |
| .jpg | image/jpeg | JPEG 图像文件 |
| .html | text/html | HTML 文档 |
| .txt | text/plain | 纯文本文件 |
HTTP/1.1 200 OK
Content-Type: text/html; charset=UTF-8 // 表示访问的资源为.html后缀的资源
Content-Length: 1234若是我们客户端要访问.html的资源, 通常不需要手动指定Content-Type
服务器会根据请求的资源类型自动设置响应的Content-Type
简单的http服务器
#include <iostream>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <string>
#include <cstring>
#include <unistd.h>
void Usage()
{
std::cout << "usage: ./Hello [ip] [port]\n" << std::endl;
}
int main(int argc, char *argv[])
{
if (argc != 3)
{
Usage();
return 1;
}
uint16_t serverport = std::stoi(argv[2]);
std::string serverip = argv[1];
int sockfd = socket(AF_INET, SOCK_STREAM, 0);
if (sockfd < 0)
{
perror("socket fail\n");
return 1;
}
struct sockaddr_in server_addr;
memset(&server_addr, 0, sizeof(server_addr));
server_addr.sin_family = AF_INET;
server_addr.sin_port = ntohs(serverport);
server_addr.sin_addr.s_addr = inet_addr(serverip.c_str());
int n = bind(sockfd, (struct sockaddr*)&server_addr, sizeof(server_addr));
if (n < 0)
{
perror("bind fail\n");
close(sockfd);
return 1;
}
n = listen(sockfd, 10);
if (n < 0)
{
perror("listen fail\n");
close(sockfd);
return 1;
}
while (true)
{
struct sockaddr_in client_addr;
socklen_t len;
int client_fd = accept(sockfd, (struct sockaddr*)&client_addr, &len);
if (client_fd < 0)
{
perror("accept fail\n");
continue;
}
char input_buffer[1024 * 10];
ssize_t m = read(client_fd, input_buffer, sizeof(input_buffer) - 1);
if (m < 0)
{
perror("read fail\n");
continue;
}
input_buffer[m] = 0;
std::cout << "[Request]" << input_buffer << std::endl;
char buffer[1024];
std::string hello = "Mifan: hello world";
sprintf(buffer, "HTTP/1.0 200 OK\nContent-Length:%ld\nContent-Type:text/plain\n\n%s", hello.size(), hello.c_str());
n = write(client_fd, buffer, strlen(buffer));
if (n < 0)
{
perror("write fail\n");
continue;
}
close(client_fd);
}
close(sockfd);
return 0;
}这个服务器开启后,我们通过访问这个服务器就可以得到一个写着hello world的http网页
完