一、背景
最近出现的新一波 AI 生成模型几乎可以以假乱真,并且使用门槛较低。许多研究人员和公司声称可以生成与真实内容没有区别的图像、语音和视频内容。通常,使用这些工具需要一些技术专业知识。但是,许多公司都努力使它们尽可能易于使用,从而减少或消除对任何特定技术知识的需求。如果没有适当的验证,这可能会导致虚假和误导性内容的扩散,这些内容甚至可能进入善意和信誉良好的新闻机构的页面。
解决这一新问题的一种方法是将 AI 用作检测内容是否真实的工具。毕竟,如果 AI 足够强大,可以用生成的内容来欺骗我们的感官,那么它可能也比我们检测虚假内容的能力更强大。虚假内容检测这一具有挑战性的领域是一个非常活跃的研究领域。
针对鉴别TTS合成的语音,Resemble AI开发了一个音频水印工具,它使用机器学习模型将数据包嵌入到我们生成的语音内容中,并可以从添加水印的音频中检测出嵌入的数据。数据以难以察觉且难以检测的方式嵌入,充当“不可见的水印”。由于数据难以察觉,同时与语音信息紧密耦合,因此既难以删除。重要的是,这种“水印”技术还可以容忍各种音频作,例如加速、减慢速度、转换为 MP3 等压缩格式,也就是说经过这些操作后,水印依旧存在。
二、WaterMarker
水印器是一种为音频剪辑添加数字水印的工具。此水印可用于识别剪辑的来源或证明剪辑未被篡改。Resemble AI 的 PerTh Watermarker 是一种深度神经网络水印器,它以难以察觉且难以检测的方式嵌入数据。
2.1 PerTh Watermarker
PerTh,它是 Perceptual 和 Threshold 的组合。它是基于利用我们感知音频的方式来寻找不可听见的声音,然后将数据编码到这些区域中的概念设计的。进一步的措施是确保我们可以从音频的任何部分(除了静音)提取嵌入的数据,这些数据是被编码到语音最常用的频率中。这确保了我们的数据负载难以被常见的音频操作所破坏。PerTh使你能够在音频文件中嵌入不可察觉的水印,并在音频经过各种转换或操作后进行检测。该库实现了多种水印技术,包括基于神经网络的方法。
他们利用心理声学(研究人类声音感知的学科)来寻找最佳的数据编码方式。心理声学的一个现象是,我们对不同频率的敏感度各不相同——这意味着我们可以将更多的信息嵌入到我们不太敏感的频率中。还存在一个更有趣的现象,称为“听觉掩蔽”,即在频率和时间上与较响声音接近的较弱声音不会被察觉。因此,掩蔽声(较响的声音)在振幅 - 频率 - 时间空间中形成一个“遮蔽层”,掩盖了其下方的其他声音。以下是在频率 - 振幅空间中的一个示例:
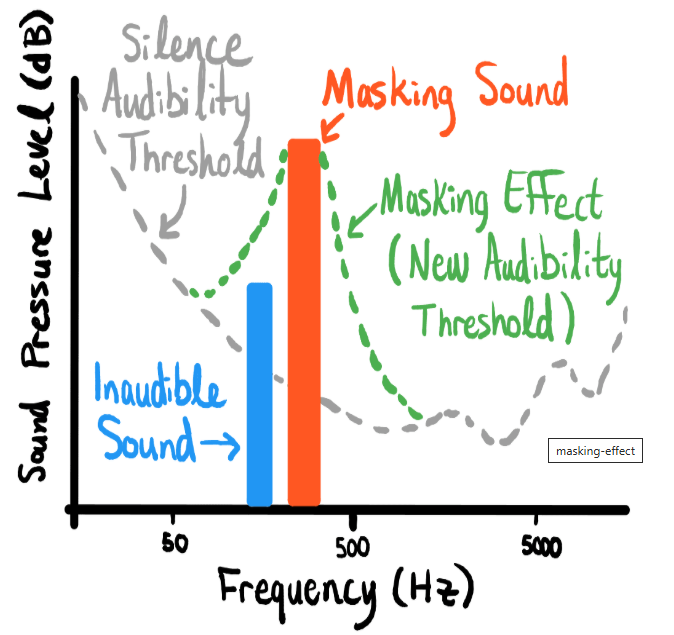
对上述图片进行简单的解释:
这张图展示了声音掩蔽效应(Masking Effect)的概念。图中横轴表示频率(Hz),纵轴表示声压级(dB)。图中包含以下元素:
- Silence Audibility Threshold(寂静可听阈值):用灰色虚线表示,表示在没有其他声音干扰的情况下,人耳能够听到的最小声音强度(虚线之上可以听到,以下听不到)。
- Masking Effect(掩蔽效应):用绿色虚线表示,表示由于掩蔽声的存在,人耳对其他声音的可听阈值发生了变化,形成了新的可听阈值(New Audibility Threshold)。
- Inaudible Sound(不可听见的声音):用蓝色柱状图表示,表示在寂静时可听的声音。
- Masking Sound(掩蔽声):用红色柱状图表示,表示一个较大的声音,其频率在480Hz左右。
具体来说,图中展示了以下过程:
- 在没有掩蔽声(很响的声音)的情况下,人耳能够听到的较小声音(蓝色柱状图)。
- 当引入掩蔽声(红色柱状图)时,掩蔽声会提高其他频率声音的可听阈值,形成新的可听阈值(绿色虚线)。
- 这意味着在掩蔽声的影响下,原本可听到的较小声音(蓝色柱状图)变得不可听见,因为它们现在低于新的可听阈值(灰色虚线)。
2.2 PerTh 包的使用方法
github:https://github.com/resemble-ai/Perth
从PyPI 安装
pip install resemble-perth
从源代码 安装
git clone https://github.com/resemble-ai/Perth
cd Perth
pip install -e .
快速开始
命令行使用
# 给音频文件添加水印
perth input.wav -o output.wav
# 从音频文件中提取水印
perth input.wav --extract
Python API 使用
添加水印
import perth
import librosa
import soundfile as sf
# 加载音频文件
wav, sr = librosa.load("input.wav", sr=None)
# 初始化水印器
watermarker = perth.PerthImplicitWatermarker()
# 添加水印
watermarked_audio = watermarker.apply_watermark(wav, watermark=None, sample_rate=sr)
# 保存水印音频
sf.write("output.wav", watermarked_audio, sr)
提取水印
import perth
import librosa
# 加载水印音频
watermarked_audio, sr = librosa.load("output.wav", sr=None)
# 初始化水印器(与用于嵌入的相同)
watermarker = perth.PerthImplicitWatermarker()
# 提取水印
watermark = watermarker.get_watermark(watermarked_audio, sample_rate=sr)
print(f"提取的水印: {watermark}")
PerTh水印器
PerTh网络隐式水印器使用基于神经网络的方法进行水印嵌入和提取。它旨在对各种音频操作保持强大的鲁棒性,同时保持高音频质量。
from perth.perth_net.perth_net_implicit.perth_watermarker import PerthImplicitWatermarker
watermarker = PerthImplicitWatermarker(device="cuda") # 使用GPU进行更快的处理
评估水印音频
该库包括评估水印音频质量和鲁棒性的实用工具:
import librosa
from perth.utils import calculate_audio_metrics, plot_audio_comparison
# 加载原始和水印音频
original, sr = librosa.load("input.wav", sr=None)
watermarked, _ = librosa.load("output.wav", sr=None)
# 计算质量指标
metrics = calculate_audio_metrics(original, watermarked)
print(f"信噪比: {metrics['snr']:.2f} dB")
print(f"峰值信噪比: {metrics['psnr']:.2f} dB")
# 可视化差异
plot_audio_comparison(original, watermarked, sr, output_path="comparison.png")
2.3 PerTh代码解析
PerTh 网络其实就只有两部分,一部分是Encoder,另外一部分是Decoder。Encoder的作用是用来给音频加水印,Decoder的作用是从加水印的音频中提取出水印。
2.3.1 Encoder
Encoder,用于在音频的幅度频谱(magnitude spectrogram)中嵌入数字水印。核心思路是通过卷积网络生成残差信号,将水印信息以不可感知的方式添加到频谱图的特定子带区域。
class Encoder(nn.Module):
"""
Inserts a watermark into a magnitude spectrogram.
"""
def __init__(self, hidden, subband):
super().__init__()
self.subband = subband
# residual encoder
self.layers = nn.Sequential(
Conv(self.subband, hidden, k=1),
*[Conv(hidden, hidden, k=7) for _ in range(5)],
Conv(hidden, self.subband, k=1, act=False),
)
def forward(self, magspec):
magspec = magspec.clone() # magspec.clone():避免修改原始输入张量
# create mask for valid watermark locations
mask = magmask(magspec)[:, None]
# crop required region of spectrogram
sub_mag = magspec[:, :self.subband]
# encode watermark as spectrogram residual 制作水印
res = self.layers(sub_mag) * mask
# add residual 添加水印
magspec[:, :self.subband] += res
# return wmarked signal and mask
return magspec, mask
magmask的代码:
def magmask(magspec, p=0.05):
#对输入的频谱数据magspec沿通道维度(dim=1)求和,得到每个时间帧的总能量:
s = magspec.sum(dim=1) # (B, T)
# 计算每个批次样本的最大能量值,并乘以比例系数p,得到动态阈值
thresh = s.max(dim=1).values * p # (B,)
#将每个时间帧的总能量与动态阈值比较,大于阈值的位置设为1,否则设为0,得到二进制掩码
return (s > thresh[:, None]).float() # (B, T)
2.3.2 Decoder
Decoder用于从音频的幅度谱中解码水印信息。采用多尺度处理策略(慢速、正常、快速分支)并通过注意力机制融合结果。
class Decoder(nn.Module):
"""
Decoder a watermark from a magnitude spectrogram.
"""
def __init__(self, hidden, subband):
super().__init__()
self.subband = subband
# multi-scale decoder
self.slow_layers = _layers(subband, hidden)
self.normal_layers = _layers(subband, hidden)
self.fast_layers = _layers(subband, hidden)
def forward(self, magspec):
mask = magmask(magspec.detach())[:, None] # (B, 1, T)
subband = magspec[:, :self.subband]
B, _, T = subband.shape
# slow branch
slow_subband = _lerp(subband, int(T * 1.25))
slow_out = self.slow_layers(slow_subband) # (B, 2, T_slow)
slow_attn = slow_out[:, :1] # (B, 1, T_slow)
slow_wmarks = slow_out[:, 1:] # (B, 1, T_slow)
slow_mask = _nerp(mask, slow_wmarks.size(2)) # (B, 1, T_slow)
slow_wmarks = _masked_mean(slow_wmarks, slow_mask) # (B, 1)
slow_attn = _masked_mean(slow_attn, slow_mask) # (B, 1)
# normal branch
normal_out = self.normal_layers(subband) # (B, 2, T_normal)
normal_attn = normal_out[:, :1] # (B, 1, T_normal)
normal_wmarks = normal_out[:, 1:] # (B, 1, T_normal)
normal_mask = _nerp(mask, normal_wmarks.size(2)) # (B, 1, T_normal)
normal_wmarks = _masked_mean(normal_wmarks, normal_mask) # (B, 1)
normal_attn = _masked_mean(normal_attn, normal_mask) # (B, 1)
# fast branch
fast_subband = _lerp(subband, int(T * 0.75))
fast_out = self.fast_layers(fast_subband) # (B, 2, T_fast)
fast_attn = fast_out[:, :1] # (B, 1, T_fast)
fast_wmarks = fast_out[:, 1:] # (B, 1, T_fast)
fast_mask = _nerp(mask, fast_wmarks.size(2)) # (B, 1, T_fast)
fast_wmarks = _masked_mean(fast_wmarks, fast_mask) # (B, 1)
fast_attn = _masked_mean(fast_attn, fast_mask) # (B, 1)
# combine branches with attention
attn = torch.cat([slow_attn, normal_attn, fast_attn], dim=1) # (B, 3)
attn = F.softmax(attn, dim=1) # (B, 3)
wmarks = torch.cat([slow_wmarks, normal_wmarks, fast_wmarks], dim=1) # (B, 3)
wmarks = (wmarks * attn).sum(dim=1) # (B,)
# single float for each batch item indicating confidence of watermark
return wmarks