一、🌐 WAIC 2025 大会看点:AI 正在“长出眼睛与身体”
在 2025 年的人工智能大会(WAIC 2025)上,“大模型退幕后,具身智能登场”成为最具共识的趋势转向。从展区到主论坛,再到各大企业发布的新品线,可以清晰看到:AI 正在告别纯“云上智囊”式的角色,逐步迈向物理世界中的可视化、可移动、可感知的具身智能系统。

🧠 什么是“具身智能”?它不仅是能动的机器人,更是“有眼、有脑、有反馈”的感知闭环
具身智能(Embodied Intelligence)不是一个新词,但它在 2025 年被重新定义:
不再只指仿生机器人或机械臂;
而是强调AI 在物理世界中拥有“主动感知 + 实时反馈 + 自主控制”能力;
即:AI 拥有“身体”(运动执行器)、“眼睛”(视频输入系统)、“神经”(低延迟数据通道)、“大脑”(模型推理单元);
在今年的 WAIC 2025 上,大量具身 AI 产品亮相,包括:
| 代表设备 | 特点 |
|---|---|
| 🤖 人形机器人 | 全身关节控制 + 多视角相机融合,强调动作实时纠偏 |
| 🚁 无人机智能编队 | 基于视觉感知的自主避障与协同飞行,依赖高清视频流回传 |
| 🏭 工业协作臂 | 集成视频 + 力觉传感,进行动态环境理解与位置自适应 |
| 🕶 XR感知头显 | 实时图传与环境识别辅助远程操控或协同决策 |
这些系统背后的共同特征是:实时视频流成为 AI 感知的主输入,视频质量、延迟、帧同步等技术指标决定了智能行为是否可靠。
🔍 从“对话式AI”到“感知式AI”,核心转折点就是“看见世界”
过去几年,AI 的主旋律是 ChatGPT 引领的自然语言处理与云端大模型,它们擅长理解文本、生成内容、总结知识。
但它们对现实世界看不见、摸不着、感受不到,注定只能是辅助类智能。
而今天的 AI 系统需要:
识别画面中人的行为;
跟随移动物体;
实时避障导航;
精确感知并执行复杂任务。
这一切的前提,是AI 要具备视频级感知能力,甚至像人一样从视频中“学习与行动”。
这就让原本“边缘模块”的视频输入,变成了 AI 系统真正的“第一感官”。
🎥 视频入口:AI具身智能系统中不可忽视的关键基础设施
具身智能从“研究概念”走向“行业系统”,背后正是视频输入与处理技术的成熟推动:
| 能力维度 | 技术要求 |
|---|---|
| 延迟 | 视频采集至推理处理必须控制在 100–250ms 之内 |
| 稳定性 | 断网重连、流中断恢复、码流切换必须支持 |
| 多平台部署 | 能适配机器人、头显、工业盒子、移动端等多种硬件形态 |
| 可编程性 | 支持帧级数据回调(YUV/RGB/裸流),便于对接 AI 模型 |
| 多协议兼容 | 能处理 RTSP、RTMP、HTTP-FLV 等多类型视频流源 |
这背后所依赖的,正是一套工程级、可控、稳定的低延迟视频输入 SDK,它不再是“播放工具”,而是支撑整个 AI 感知系统的大动脉。
二、🎯 AI 进入“视频驱动时代”:感知输入成为核心挑战
随着 AI 从云端大模型演进到“具身智能”,感知输入的重要性正在迅速上升。
如果说过去的 AI 靠“大模型 + 大数据”推动的是知识智能,那么现在的 AI 系统——无论是机器人、无人机还是智能头显——都必须靠摄像头、传感器、音视频流来“看见”和“理解”真实世界。
而视频,正在取代传统结构化数据,成为 AI 系统的第一感知源头。
📌 为什么“视频感知”如此关键?
| 感知维度 | 视频感知的价值 |
|---|---|
| 🧠 认知理解 | 从实时画面中提取行为、动作、目标,成为 AI 推理的基础 |
| 🧍 具身反馈 | 驱动机器人控制、避障导航等动作的依据 |
| 🔄 环境适应 | 根据场景变化动态调整策略(如工业臂避让、巡检转向) |
| 📊 AI训练数据源 | 视频回流供离线分析/标注/微调,持续提升模型性能 |
| 🌐 多模态融合 | 视频+语音+IMU/GPS 构成完整的感知输入链路 |
📉 感知输入的现实挑战有哪些?
虽然视频成为主流感知入口,但在工程落地中,以下问题反复出现:
| 挑战维度 | 典型表现 | 技术影响 |
|---|---|---|
| 延迟问题 | 摄像头到 AI 推理间延迟秒级 | 导致识别/控制滞后,无法闭环 |
| 帧数据不可控 | 无法获取稳定 YUV/RGB 回调帧 | 无法对接 AI 模型或帧级标注工具 |
| 播放模块通用化严重 | 采用 VLC 等通用播放器无回调能力 | 无法参与智能分析,仅能观看 |
| 协议/分辨率不统一 | 摄像头RTSP、无人机裸流、视频文件混合输入 | 系统需要自行转码,资源浪费严重 |
| 平台割裂 | 需要在 Unity、Android、Linux、嵌入式中统一处理视频输入 | 跨平台开发成本高、维护困难 |
| 弱网不稳定 | 网络抖动/断流无自动恢复机制 | 视频输入链断裂,系统失效风险大 |
🧭 具身智能背景下,视频入口模块的新要求
为支撑 AI 系统高质量感知输入,视频处理模块必须从“播放器”转型为“可控、可嵌入、可协同”的输入通道:
| 能力要求 | 描述 |
|---|---|
| ✅ 实时性保障 | 视频接入至可用数据输出的总链路延迟需控制在 100–250ms |
| ✅ 数据开放性 | 支持 YUV、RGB、码流、帧时间戳等数据结构直接回调 |
| ✅ 跨协议解码能力 | 无需依赖云端,边缘端即可解码 RTSP / RTMP / 裸码流等 |
| ✅ 平台兼容性强 | 同一套接口兼容 Unity、Android、Linux、头显等系统 |
| ✅ 边缘运行能力 | 可运行在工业盒子、AI终端等本地硬件中,长时间稳定 |
| ✅ 异常恢复机制 | 自动重连、弱网补偿、状态上报,保障流畅输入不中断 |
✅ 小结:感知入口,决定智能闭环是否成立
如果说“大模型决定了AI的上限”,
那么“视频输入能力决定了AI是否能真正落地”。
没有高质量、低延迟、结构化可控的视频输入,AI 系统就无法真正“看见世界”;
没有标准化、可嵌入的输入模块,具身智能也只能停留在实验室。
三、如何打造具身智能时代的“视频神经系统”?
在 AI 正全面迈向“可视化、可感知、可操控”的具身智能阶段,视频输入模块早已不再是可有可无的“播放器插件”,而是智能系统中与推理引擎并列的重要组成部分。
大牛直播SDK凭借其工程稳定性、低延迟、平台适配广、数据可控度高的优势,逐步确立了在众多“AI 具身系统”中的感知入口标准模块地位,被广泛应用于:
工业机器人智能视觉
无人机回传与控制
XR 沉浸式感知终端
AI边缘盒子与远程识别系统
多模态智能协作平台
✅ 大牛直播SDK架构总览:为“看得见 + 反馈快 + 可编程”而生
以下是大牛直播SDK的典型模块结构,围绕AI视频输入场景专门设计:
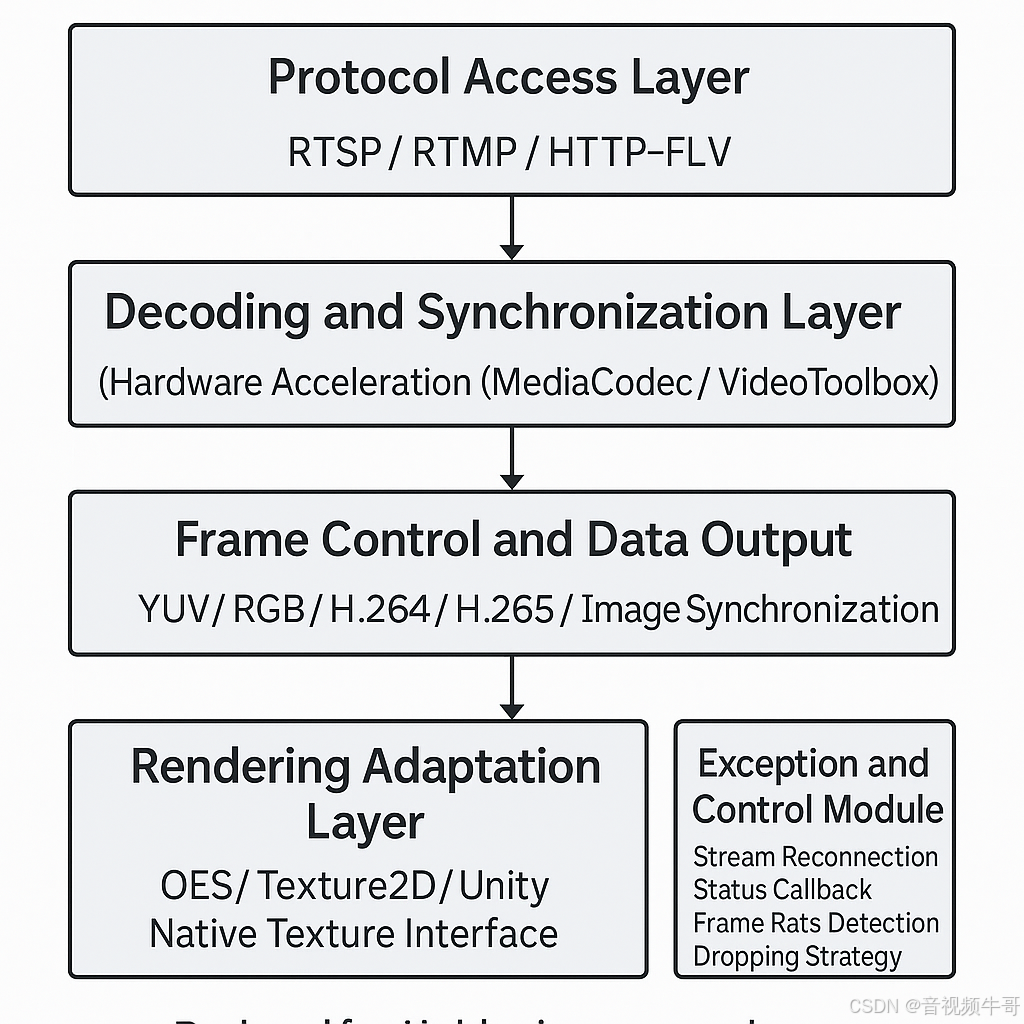
🎯 技术优势一览:解决“具身 AI 视频输入”的六大关键问题
| 问题维度 | 传统方案 | 大牛直播SDK的优势 |
|---|---|---|
| 延迟控制 | 秒级常态,受限于缓冲机制 | 即到即播架构,实测延迟 100–250ms 内,首帧快启 <200ms |
| AI对接能力 | 通用播放器无 YUV/RGB 回调,难集成模型 | 原生支持 YUV、RGB、码流裸流回调,帧级时间戳、格式元信息可同步传出 |
| 平台兼容性 | FFmpeg等开源方案维护复杂,头显/嵌端难适配 | 全平台适配(Android/iOS/Linux/Windows/Unity/Pico/Quest)一套接口多端部署 |
| 协议兼容性 | 多源混流需自行封装切换 | 内建多协议接入(RTSP/RTMP/HTTP-FLV),支持动态切流 |
| 异常容错 | 无断流处理,播放容易中断 | 支持断流自动重连、网络波动恢复、弱网缓冲优化 |
| 渲染效率 | CPU-GPU 数据频繁拷贝,耗电高、发热大 | 支持 OES 纹理 + Unity Shader 渲染,避免冗余传输,适配XR头显实时播放 |
🚀 高度可嵌入:为 AI 系统打造“类驱动级”感知能力
大牛直播SDK不仅仅是“播放器引擎”,更像是一个可内嵌、可调度、可编排的视频输入中间件,其特点包括:
✅ SDK即插件:体积轻,易嵌入,单进程内运行,不依赖外部组件;
✅ 可编程控制:每帧数据可通过 C/C++/Java/C# 回调,供模型分析或保存;
✅ 与AI推理流并行处理:支持边解码边回调、边渲染边分析,保证视频与控制逻辑同步;
✅ 配合边缘计算节点:可运行在 Jetson、RK、全志等 AI SOC 上,与本地模型闭环协作;
✅ 与Unity深度适配:用于构建 XR 可视系统、工业仿真平台、远程交互终端等。
🧬 技术应用延伸:不仅“能播”,更“能用”在AI实际场景中
| 应用领域 | 能力体现 |
|---|---|
| 工业检测 | 高帧率 RTSP、RTMP摄像头输入,YUV回调供图像缺陷检测模型处理 |
| 无人机图传 | 实时回传延迟100-250ms,支持 AI 驾驶辅助与目标跟踪 |
| XR可视终端 | Unity 中低延迟视频贴图,无缝融合场景交互与视觉感知 |
| 智能交通 | 多路摄像头接入 + 分流播放,供 AI 识别异常车辆、交通违章 |
| 医疗辅控 | 远程视频采集 + 回调 + 云端模型识别,实现远程诊断或机器人辅助操作 |
✅ 小结:不是播放器,而是“视觉通感接口层”
Android平台Unity共享纹理模式RTMP播放延迟测试
在具身 AI 系统中,视频输入不再是单向播放,而是交互系统的核心感官通道。
大牛直播SDK通过完整的接入-解码-回调-渲染链路,为 AI 感知系统提供了工程级“视频神经元”,帮助它:
快速感知世界;
高效获取画面;
与识别推理模块实时交互;
构建具身智能中的“视觉闭环”。
这不再是播放器,而是让 AI 真正“看得清、看得快、看得稳”的关键技术基础。
四、📦 面向未来:AI系统中的“视频入口层”标准化趋势
随着 AI 从“可计算”走向“可具身”,系统架构正经历深刻的演变。尤其在机器人、无人机、工业终端、安防平台等具身智能落地场景中,“视频入口层”正成为与算法模型、执行控制并列的核心模块。
而在这个系统中,视频输入不再只是被动的信号源,而是承担着“感知感官”的角色。一个稳定、低延迟、结构化的视频入口,将直接决定 AI 系统是否具备可用性、实时性与闭环能力。
🔍 未来 AI 系统的感知架构趋势:入口层地位持续上升
具身智能系统的标准感知链条逐步清晰:
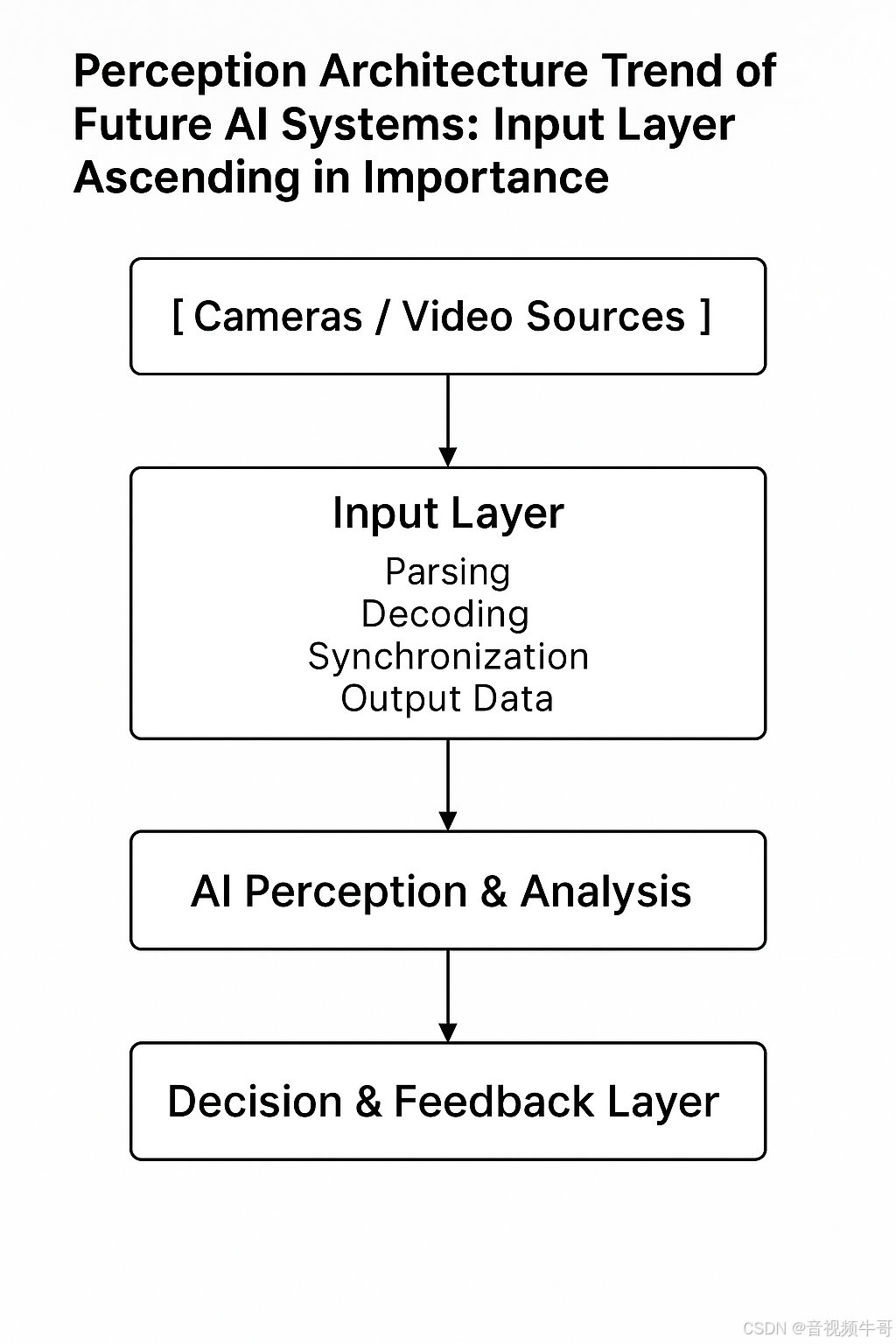
过去,这一流程的“入口层”往往使用开源播放器或简单软解处理,而未来,视频入口将承担以下核心职责:
| 核心职责 | 技术要求 |
|---|---|
| 📶 多源接入 | 支持 RTSP/RTMP/HTTP-FLV等主流流媒体协议 |
| 🧩 可编排性 | 视频数据帧级输出,支持与 AI 模型并行处理 |
| 🧠 智能协同 | 可嵌入到 AI 系统中与识别/控制模块高效协作 |
| 🖥 跨平台适配 | 可运行在 Unity/Android/Linux/边缘盒子等平台 |
| ⛑ 异常恢复 | 网络波动自动重连,断流可自愈 |
| 📊 状态可观测 | 可回调帧率、延迟、错误码、播放状态等指标 |
📈 视频入口标准化的三大发展趋势
| 发展趋势 | 描述 | 典型应用体现 |
|---|---|---|
| ① 低延迟解码标准化 | 从“缓冲优先”转向“即时送帧、边解码边用” | AI控制系统、VR头显远程交互 |
| ② 帧级数据开放 | 从“黑盒播放”转向“YUV/RGB 回调 + 元信息结构化输出” | 视频结构化识别、AI推理接口 |
| ③ 跨平台嵌入标准化 | 支持同一 SDK 在多平台部署,支持嵌入运行 | 多端部署的边缘 AI 模块 / XR设备 |
🧠 为什么说视频入口是“智能系统的神经起点”?
类比人体神经系统:
摄像头等设备 = 感官;
视频入口 = 神经元突触,负责编码并将感知信号送入大脑;
AI模型 = 大脑皮层,进行判断与思考;
执行控制层 = 肌肉系统,执行反应行为。
如果视频入口断、卡、延迟,整个“感知—思考—反馈”链条就中断,系统将陷入“盲视状态”,即便算法模型再强,也无法真实响应世界。
🧩 大牛直播SDK的架构思路:先定义标准,再覆盖平台
在应对这些趋势中,像大牛直播SDK这类工程化组件,已经通过如下方式实现了视频入口标准化能力:
| 架构策略 | 落地能力 |
|---|---|
| 📦 解耦式模块封装 | 协议解析 / 解码 / 渲染 分离,易于嵌入与替换 |
| 🛠 标准接口回调 | C/C++/C#/Java 多语言接口,数据结构统一 |
| 🌍 全平台兼容 | Unity、Android、iOS、Windows、Linux 全覆盖 |
| 📡 多协议接入 | RTSP/RTMP/HTTP-FLV 自动适配、可切流 |
| ⚙️ 状态监控完善 | 延迟、帧率、错误码、解码信息全部可回调 |
| 💾 资源轻量可控 | 支持低功耗设备运行,适配嵌入式/ARM平台 |
✅ 小结:AI 时代的“视频入口层”,应当具备三性合一
| 能力 | 含义 |
|---|---|
| 标准化 | 统一接口、协议、回调,降低系统复杂度 |
| 工程化 | 稳定、可监控、支持部署与远程管理 |
| 智能协同化 | 能与模型推理、控制系统、回传机制实时互动 |
正是这三性融合,让“视频入口”从播放模块变成 AI 系统的“神经核心”。
五、🚀 总结:AI系统的“眼睛”,值得用工业级方案来构建
在具身智能的新时代,AI 不再只是“算力中心”或“语言接口”,而正逐步演化为能看、能感、能动的系统。而“看”的这一步,正是由视频输入能力所决定。
过去,我们或许可以用开源播放器凑合展示一段视频流;但在如今机器人控制、无人机避障、XR 实时渲染、工业瑕疵检测这些强依赖视频实时性与结构化感知的场景下,“视频播放”已经转变为“视频神经系统”。
✅ 为什么视频输入模块值得“工业级对待”?
| 关键能力 | 对AI系统的影响 |
|---|---|
| ⏱ 低延迟 | 决定系统是否“来得及反应”,特别关键于控制闭环 |
| 🎯 数据结构化 | 决定能否用于模型识别、行为判断等智能推理 |
| ⚙️ 跨平台嵌入能力 | 决定是否可部署于真实应用环境中的边缘终端 |
| 🔄 异常容错能力 | 决定系统能否在复杂/弱网/断流情况下持续运行 |
| 🧠 协同控制能力 | 决定视频是否能与 AI 模型、控制逻辑同步配合 |
这些能力不是 VLC 播放器、FFmpeg 解码片段可以“拼”出来的,而必须通过专业的、工程化的 SDK 方案系统构建。
🧩 为什么说视频输入是“智能闭环”的第一步?
如果把一个具身 AI 系统比作“智能生命体”,那么:
视频流 = 感官
视频输入模块 = 神经中枢入口
AI 模型 = 大脑
控制执行 = 肌肉
一个无法看清楚、无法快速感知外界的“生命体”,是不可能做出正确判断、也无法安全地与环境交互的。
🧠 结语:选择“专业的视频入口”,是对整个 AI 系统的尊重
“你为 AI 系统选择的视频输入方式,就是你对其认知与行动能力上限的定义。”
这不是一句口号,而是过去数年中大量 AI 应用工程实践得出的经验结晶:
工业现场不等人,延迟必须受控;
机器人不容错,数据必须完整;
多模态不乱配,接口必须开放;
云边不割裂,架构必须统一。
因此,在 AI 系统中构建“眼睛”时,请放下“能播就行”的幻想,转向一个真正为智能系统设计的工业级视频输入框架。
更令人欣慰的是,在本次 WAIC 2025 大会上,我们也看到了许多来自无人机视觉、工业检测、XR远程协作、AI盒子系统等领域的客户与合作伙伴,他们正是通过大牛直播SDK将“可控、可嵌入的视频能力”部署进了具身智能项目之中。
在这个“AI长出眼睛和身体”的关键时代,能为这些真正落地的智能系统提供一部分“视觉神经”,既是技术积累的结果,也是一份值得珍惜的参与感。
这不是播放器,这是 AI 时代的感知基础设施。
📘 CSDN官方博客专栏:音视频牛哥-CSDN