通过贝叶斯分类对鸢尾花数据集进行分类并输出分类结果和数据类别散点图。
最小错误率分类:
计算每类的后验概率,选择概率最大的类别。
在测试集上评估准确率,并可视化分类结果。
最小风险分类:
引入损失矩阵,计算每类的风险值,选择风险最小的类别。
同样评估准确率并可视化结果。
import random
import numpy as np
from scipy.stats import multivariate_normal
import matplotlib.pyplot as plt
L11 = 0
L12 = 2#2
L13 = 1
L21 = 3#3
L22 = 0
L23 = 4#4
L31 = 1
L32 = 2#2
L33 = 0
'''
loss_matrix1 = np.array([[0, 2, 1],
[3, 0, 4],
[1, 2, 0]])
loss_matrix2 = np.array([[0, 1, 1],
[1, 0, 1],
[1, 1, 0]])
'''
color_origin = {'1': 'r', '2': 'g', '3': 'b'}
color_new = {'1': 'darkred', '2': 'darkgreen', '3': 'darkblue'}
data_dict = {}
category_means = {}
category_covs = {}
train_data = {}
test_data = {}
with open('Iris数据txt版.txt', 'r') as file:
for line in file:
line = line.strip()
data = line.split('\t')
if len(data) >= 3:
try:
category = data[0]
attribute1 = eval(data[1])
attribute2 = eval(data[2])
if category not in data_dict:
data_dict[category] = {'Length': [], 'Width': []}
data_dict[category]['Length'].append(attribute1)
data_dict[category]['Width'].append(attribute2)
except ValueError:
print(f"Invalid data in line: {line}")
continue
for category, attributes in data_dict.items():
print(f'种类: {category}')
print(len(attributes["Length"]))
print(len(attributes["Width"]))
print(f'属性1: {attributes["Length"]}')
print(f'属性2: {attributes["Width"]}')
#各类的均值和协方差
for category, attributes in data_dict.items():
attribute1_values = [value for value in attributes['Length']]
attribute2_values = [value for value in attributes['Width']]
category_data = np.column_stack((attribute1_values, attribute2_values))
train_samples = random.sample(category_data.tolist(), 45)
train_data[category] = np.array(train_samples)
test_samples = [sample for sample in category_data.tolist() if sample not in train_samples]
test_data[category] = np.array(test_samples)
#train_data[category] = category_data[:45]
#test_data[category] = category_data[45:]
category_means[category] = np.mean(train_data[category], axis=0)
category_covs[category] = np.cov(train_data[category], rowvar=False)
print(category_means[category],category_covs[category])
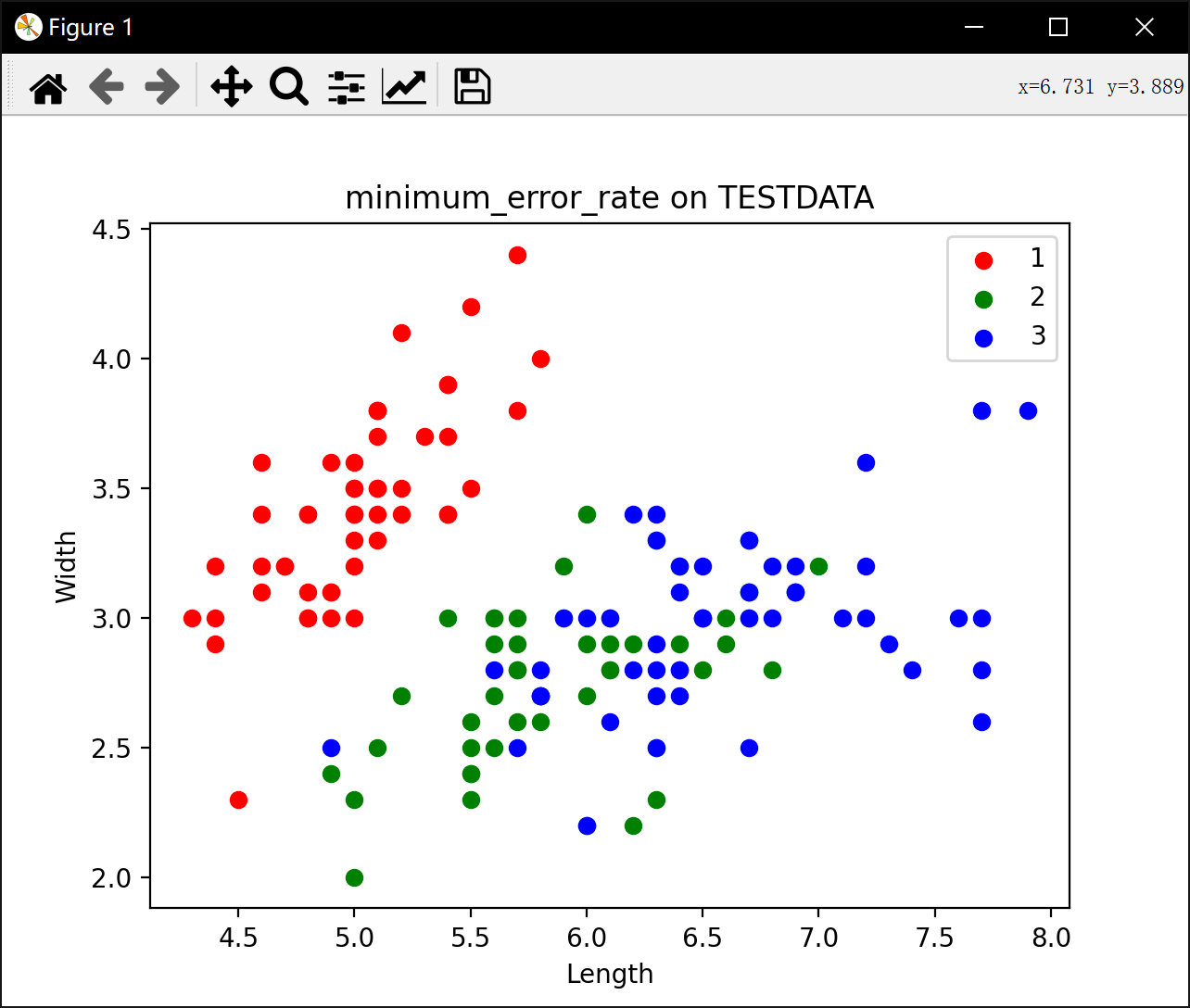
plt.scatter(attribute1_values, attribute2_values, c=color_origin[category], label=category)
plt.title("minimum_error_rate on TESTDATA")
plt.legend()
plt.xlabel('Length')
plt.ylabel('Width')
plt.show()
#先验概率
prior_rate = 1.0/len(data_dict)
print("\n最小错误率:\n")
#最小错误率贝叶斯分类器训练
def min_error_classifier(x):
post_rate = {}
for category in data_dict.keys():
condition_rate = multivariate_normal.pdf(x, mean=category_means[category], cov=category_covs[category])
post_rate[category] = condition_rate*prior_rate
predicted_category = max(post_rate, key=post_rate.get)
#predicted_category = max(post_rate, key=lambda category: np.max(post_rate[category]))
return predicted_category
right = 0
all = 0
#最小错误率贝叶斯分类测试
for category, test_samples in test_data.items():
for x in test_samples:
result = min_error_classifier(x)
print("测试样本属于类别", category, "长宽属性", x, ",分类结果", result)
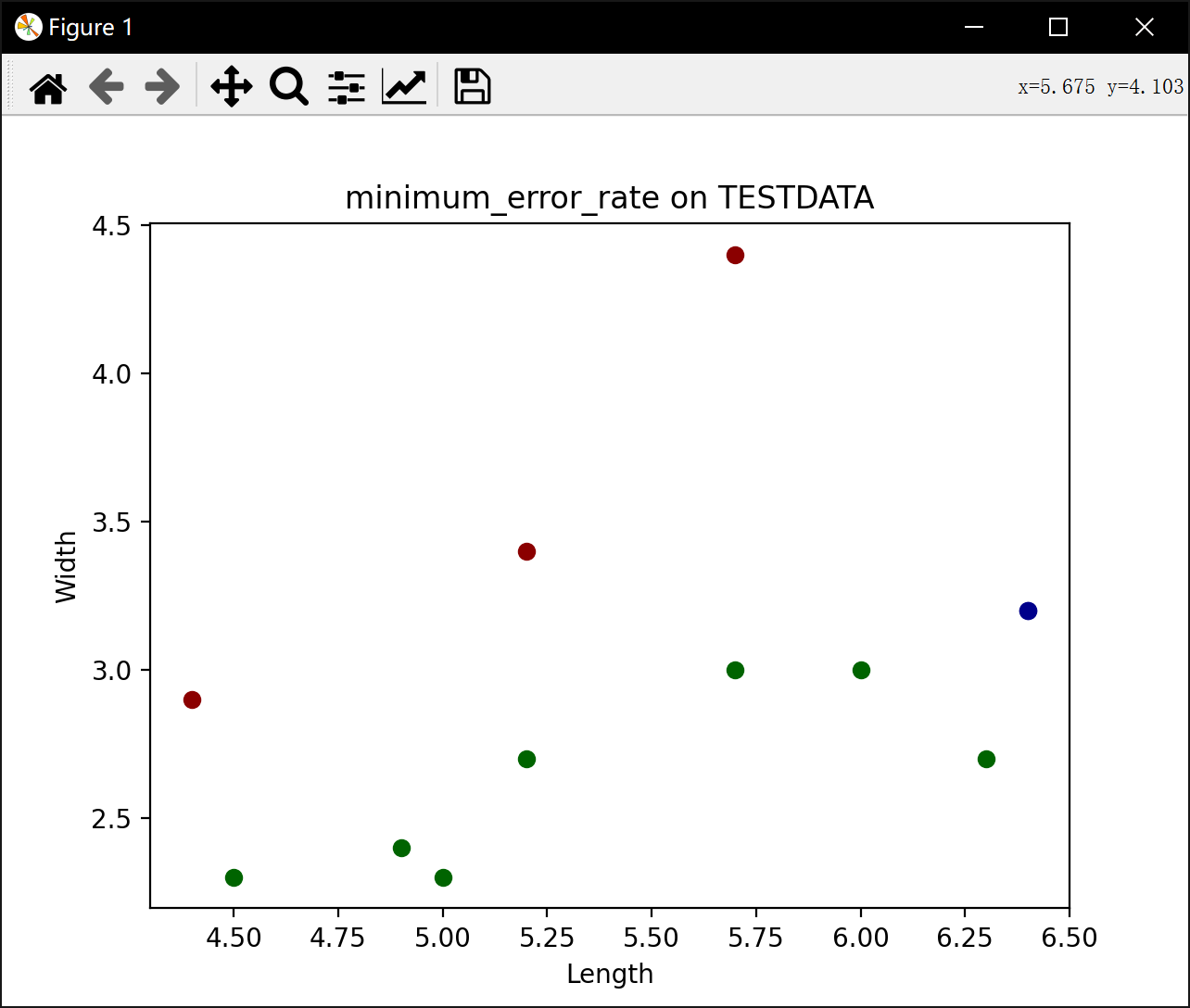
plt.scatter(x[0],x[1],c=color_new[result], label=category)
if result == category:
right += 1
all += 1
print("准确率:", right / all)
plt.title("minimum_error_rate on TESTDATA")
#plt.legend()
plt.xlabel('Length')
plt.ylabel('Width')
plt.show()
#最小风险贝叶斯分类器训练
def min_risk_classifier(x):
post_rate = {}
Class = {}
for category in data_dict.keys():
condition_rate = multivariate_normal.pdf(x, mean=category_means[category], cov=category_covs[category])
post_rate[category] = condition_rate*prior_rate
Class['1'] = L11 * post_rate['1'] + L12 * post_rate['2'] + L13 * post_rate['3']
Class['2'] = L21 * post_rate['1'] + L22 * post_rate['2'] + L23 * post_rate['3']
Class['3'] = L31 * post_rate['1'] + L32 * post_rate['2'] + L33 * post_rate['3']
precdicted_category = min(Class, key=Class.get)
return precdicted_category
print("\n最小风险:\n")
right = 0
all = 0
#最小风险贝叶斯分类测试
for category, test_samples in test_data.items():
for x in test_samples:
result = min_risk_classifier(x)
print("测试样本属于类别", category, "长宽属性",x,",分类结果", result)
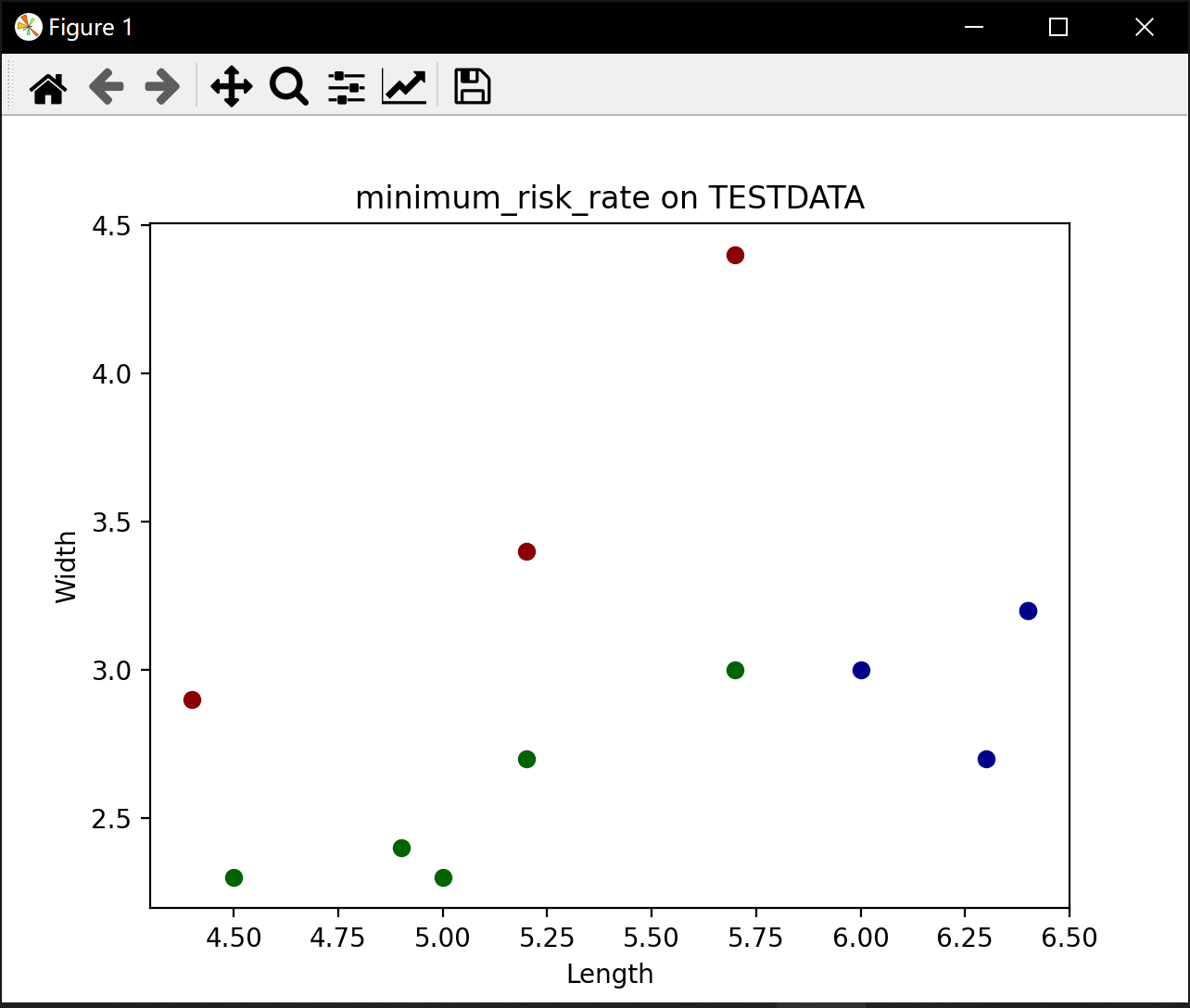
plt.scatter(x[0], x[1], c=color_new[result], label=category)
if result == category:
right += 1
all += 1
print("准确率:", right/all)
plt.title("minimum_risk_rate on TESTDATA")
#plt.legend()
plt.xlabel('Length')
plt.ylabel('Width')
plt.show()运行结果:
种类: 1
50
50
属性1: [5.1, 4.9, 4.7, 4.6, 5.0, 5.4, 4.6, 5.0, 4.4, 4.9, 5.4, 4.8, 4.8, 4.3, 5.8, 5.7, 5.4, 5.1, 5.7, 5.1, 5.4, 5.1, 4.6, 5.1, 4.8, 5.0, 5.0, 5.2, 5.2, 4.7, 4.8, 5.4, 5.2, 5.5, 4.9, 5.0, 5.5, 4.9, 4.4, 5.1, 5.0, 4.5, 4.4, 5.0, 5.1, 4.8, 5.1, 4.6, 5.3, 5.0]
属性2: [3.5, 3.0, 3.2, 3.1, 3.6, 3.9, 3.4, 3.4, 2.9, 3.1, 3.7, 3.4, 3.0, 3.0, 4.0, 4.4, 3.9, 3.5, 3.8, 3.8, 3.4, 3.7, 3.6, 3.3, 3.4, 3.0, 3.4, 3.5, 3.4, 3.2, 3.1, 3.4, 4.1, 4.2, 3.1, 3.2, 3.5, 3.6, 3.0, 3.4, 3.5, 2.3, 3.2, 3.5, 3.8, 3.0, 3.8, 3.2, 3.7, 3.3]
种类: 2
50
50
属性1: [7.0, 6.4, 6.9, 5.5, 6.5, 5.7, 6.3, 4.9, 6.6, 5.2, 5.0, 5.9, 6.0, 6.1, 5.6, 6.7, 5.6, 5.8, 6.2, 5.6, 5.9, 6.1, 6.3, 6.1, 6.4, 6.6, 6.8, 6.7, 6.0, 5.7, 5.5, 5.5, 5.8, 6.0, 5.4, 6.0, 6.7, 6.3, 5.6, 5.5, 5.5, 6.1, 5.8, 5.0, 5.6, 5.7, 5.7, 6.2, 5.1, 5.7]
属性2: [3.2, 3.2, 3.1, 2.3, 2.8, 2.8, 3.3, 2.4, 2.9, 2.7, 2.0, 3.0, 2.2, 2.9, 2.9, 3.1, 3.0, 2.7, 2.2, 2.5, 3.2, 2.8, 2.5, 2.8, 2.9, 3.0, 2.8, 3.0, 2.9, 2.6, 2.4, 2.4, 2.7, 2.7, 3.0, 3.4, 3.1, 2.3, 3, 2.5, 2.6, 3.0, 2.6, 2.3, 2.7, 3.0, 2.9, 2.9, 2.5, 2.8]
种类: 3
50
50
属性1: [6.3, 5.8, 7.1, 6.3, 6.5, 7.6, 4.9, 7.3, 6.7, 7.2, 6.5, 6.4, 6.8, 5.7, 5.8, 6.4, 6.5, 7.7, 7.7, 6.0, 6.9, 5.6, 7.7, 6.3, 6.7, 7.2, 6.2, 6.1, 6.4, 7.2, 7.4, 7.9, 6.4, 6.3, 6.1, 7.7, 6.3, 6.4, 6.0, 6.9, 6.7, 6.9, 5.8, 6.8, 6.7, 6.7, 6.3, 6.5, 6.2, 5.9]
属性2: [3.3, 2.7, 3.0, 2.9, 3.0, 3.0, 2.5, 2.9, 2.5, 3.6, 3.2, 2.7, 3.0, 2.5, 2.8, 3.2, 3.0, 3.8, 2.6, 2.2, 3.2, 2.8, 2.8, 2.7, 3.3, 3.2, 2.8, 3.0, 2.8, 3.0, 2.8, 3.8, 2.8, 2.8, 2.6, 3.0, 3.4, 3.1, 3.0, 3.1, 3.1, 3.1, 2.7, 3.2, 3.3, 3, 2.5, 3, 3.4, 3]
[5.00666667 3.45111111] [[0.12154545 0.09510606]
[0.09510606 0.12619192]]
[5.92444444 2.74444444] [[0.27461616 0.07957071]
[0.07957071 0.08570707]]
[6.55555556 2.97111111] [[0.41025253 0.10300505]
[0.10300505 0.10982828]]最小错误率:
测试样本属于类别 1 长宽属性 [5.4 3.4] ,分类结果 1
测试样本属于类别 1 长宽属性 [5.4 3.4] ,分类结果 1
测试样本属于类别 1 长宽属性 [4.5 2.3] ,分类结果 2
测试样本属于类别 1 长宽属性 [4.6 3.2] ,分类结果 1
测试样本属于类别 2 长宽属性 [5.5 2.3] ,分类结果 2
测试样本属于类别 2 长宽属性 [6.3 3.3] ,分类结果 3
测试样本属于类别 2 长宽属性 [6. 3.4] ,分类结果 3
测试样本属于类别 2 长宽属性 [5.7 2.9] ,分类结果 2
测试样本属于类别 3 长宽属性 [7.7 2.8] ,分类结果 3
测试样本属于类别 3 长宽属性 [6.3 2.7] ,分类结果 2
测试样本属于类别 3 长宽属性 [7.2 3.2] ,分类结果 3
准确率: 0.6363636363636364最小风险:
测试样本属于类别 1 长宽属性 [5.4 3.4] ,分类结果 1
测试样本属于类别 1 长宽属性 [5.4 3.4] ,分类结果 1
测试样本属于类别 1 长宽属性 [4.5 2.3] ,分类结果 2
测试样本属于类别 1 长宽属性 [4.6 3.2] ,分类结果 1
测试样本属于类别 2 长宽属性 [5.5 2.3] ,分类结果 2
测试样本属于类别 2 长宽属性 [6.3 3.3] ,分类结果 3
测试样本属于类别 2 长宽属性 [6. 3.4] ,分类结果 3
测试样本属于类别 2 长宽属性 [5.7 2.9] ,分类结果 2
测试样本属于类别 3 长宽属性 [7.7 2.8] ,分类结果 3
测试样本属于类别 3 长宽属性 [6.3 2.7] ,分类结果 3
测试样本属于类别 3 长宽属性 [7.2 3.2] ,分类结果 3
准确率: 0.7272727272727273进程已结束,退出代码0