数据分析是对数据进行系统性梳理,方便人们更好的去了解。其目的是提炼核心结论,揭示数据背后的规律,为决策提供理论依据。接下来我从以下几个方面展示一份数据是怎么做到可视化的效果的,为决策提供理论的。
一,提取数据
数据分为开源数据和闭源数据,顾名思义,开源数据就是对外公开的数据,闭源数据就是仅供内部人员使用的数据,对外不公开的数据。接下来为大家展示的为一个开源数据,是在和鲸社区找到的一个开源数据。
这是文档的大体内容,接下来我们根据这个文档来写代码实现可视化和预测。
读取文件:
在python里我们要首先导入这个csv文件,,对这个文件有一个初步的了解
import numpy as np
import pandas as pd
df = pd.read_csv('双十一淘宝美妆数据.csv')
df.head() #查看数居前五行 df.info() #查看数据特征
df.shape #查看数据量
df.describe()#计算基本信息
二,数据清洗
数据清洗,顾名思义清洗数据,就是将文档的空值用各种方法去填充或者删除或者是忽略等等,还有重复值的处理等等
data = df.drop_duplicates(inplace = False)##去重
data.reset_index(inplace = True,drop = True)##重置行索引
data.shape#查看格式
data.loc[data['sale_count'].isnull()].head()#查看前五行
data.loc[data['comment_count'].isnull()].tail()#查看后五行
#填补缺失值
data=data.fillna(0) #用0填补缺失值
data.isnull().any() #查看是否还有空值三,分析数据
这里我们要导入jieba库,对中文进行分词,方便我们接下来的可视化。
#使用jieba包对title进行分词,进一步了解每一个商品的特征
import jieba
subtitle=[]
for each in data['title']:
k=jieba.lcut_for_search(each) #搜索引擎模式
subtitle.append(k)
data['subtitle']=subtitle
data[['title','subtitle']].head()运行结果如下: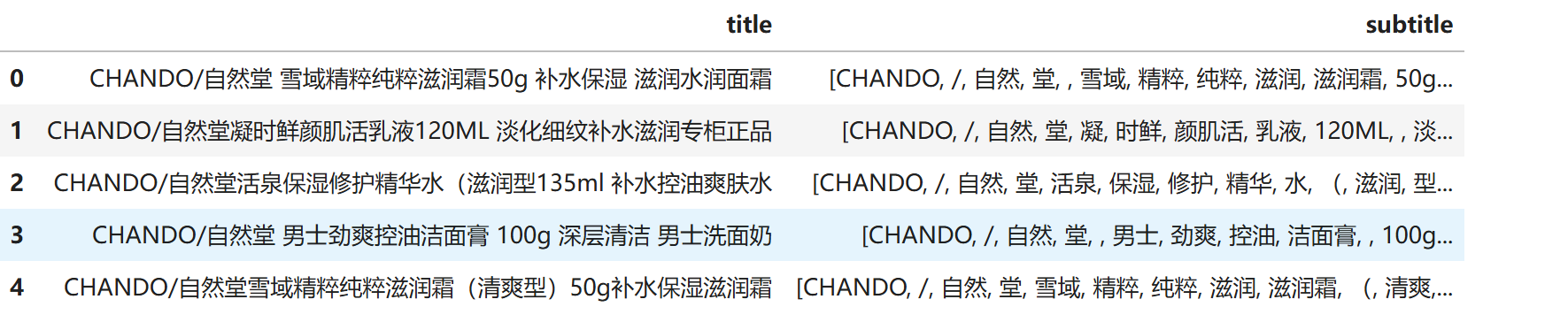
可以看到,jieba 库对我们的题目进行了分词,方便我们接下来的可视化,比如男士的东西,我们就可以搜索男,男生,男生,剖去斩男的词汇。这样我们可以更深层次的分析了。
# 给商品添加分类
sub_type = [] #子类别
main_type = [] #主类别
basic_data = """护肤品 乳液类 乳液 美白乳 润肤乳 凝乳 柔肤液 亮肤乳 菁华乳 修护乳
护肤品 眼部护理类 眼霜 眼部 眼膜
护肤品 面膜类 面膜
护肤品 清洁类 洗面 洁面 清洁 卸妆 洁颜 洗颜 去角质 磨砂
护肤品 化妆水 化妆水 爽肤水 柔肤水 补水露 凝露 柔肤液 精粹水 亮肤水 润肤水 保湿水 菁华水 保湿喷雾 舒缓喷雾
护肤品 面霜类 面霜 日霜 晚霜 柔肤霜 滋润霜 保湿霜 凝霜 日间霜 晚间霜 乳霜 修护霜 亮肤霜 底霜 菁华霜
护肤品 精华类 精华液 精华水 精华露 精华素 精华
护肤品 防晒类 防晒
护肤品 补水类 补水
化妆品 口红类 唇釉 口红 唇彩 唇膏
化妆品 底妆类 散粉 蜜粉 粉底液 定妆粉 气垫 粉饼 BB CC 遮瑕 粉霜 粉底膏 粉底霜
化妆品 眼部彩妆 眉粉 染眉膏 眼线 眼影 睫毛膏 眉笔
化妆品 修容类 鼻影 修容粉 高光 腮红"""
##主观的分类,不在这些类别里的并入其他类。第一列是大类,第二列是小类,后面都是关键词这里我们对商品进行了分类,分为主类别和小类别
dcatg={}
catg=basic_data.split('\n')
for i in catg:
main_cat=i.strip().split('\t')[0]
sub_cat=i.strip().split('\t')[1]
o_cat=i.strip().split('\t')[2:len(catg)]
for j in o_cat:
dcatg[j]=(main_cat,sub_cat)
dcatg对商品进行了分类。
sub_type = [] #主类
main_type = [] #次类
for i in range(len(data)):
exist = False
for j in data['subtitle'][i]:
if j in dcatg:
sub_type.append(dcatg[j][1])
main_type.append(dcatg[j][0])
exist = True
break
if not exist :
sub_type.append('其他')
main_type.append('其他')
data['sub_type']=sub_type
data['main_type']=main_type
data.loc[data['sub_type'] == '其他'].count() ##查看分类为其他的有多少商品sex=[]
for i in range(len(data)):
if '男士' in data['subtitle'][i] :
sex.append('是')
elif '男生' in data['subtitle'][i] :
sex.append('是')
elif '男' in data['subtitle'][i] and '女' not in data['subtitle'][i] and '斩男' not in data['subtitle'][i]:
sex.append('是')
else :
sex.append('否')
data['是否男士专用']=sex
data.loc[data['是否男士专用'] == '是'].head()这段代码就是查看男士专用的,
data['是否男士专用'].value_counts()查看男士专用的个数
data['销售额'] = data.price * data.sale_count
data.head()这段代码实行的是增加了一个新列表,是销售额,销售额是商品单价*销售数量,并查看前五行
分类我们也做完了,接下来就是数据的可视化。
四,数据可视化
所有准备工作已经做完了,接下来就是数据的可视化,这里极为重要,我们之前所做的一切都是为了这铺垫的
import matplotlib.pyplot as plt #导包
plt.rcParams['font.sans-serif'] = [u'SimHei'] ##显示中文,设置字体
plt.rcParams['axes.unicode_minus'] = False ##显示符号
plt.figure(figsize = (12,10))#设置画布的大小
# 各店铺的商品数量
plt.subplot(2,2,1)#创建一个(2,2)的第一个子图
plt.tick_params(labelsize=15)#x,y的轴的标签的字体大小
data['店名'].value_counts().sort_values().plot.bar()#以店名为索引,对商品数量提取,进行排序,绘制柱状图。
plt.title('各品牌商品数',fontsize = 20)#标题的名称和大小
plt.ylabel('商品数量',fontsize = 15)#对Y轴进行标签的定义,还有y轴标签的大小
plt.xlabel('店名')#对X轴进行标签的定义
# 各店铺的销量
plt.subplot(2,2,2)#创建一个(2,2)的第二个子图
plt.tick_params(labelsize=15)#同上,基本差不多
data.groupby('店名').sale_count.sum().sort_values().plot.bar()#以店名进行分组,对销量求和,排序,绘制柱状图
plt.title('各品牌所有商品的销量',fontsize = 20 )
plt.ylabel('商品总销量',fontsize = 15)
#各店铺总销售额
plt.subplot(2,2,3)
plt.tick_params(labelsize=15)
data.groupby('店名')['销售额'].sum().sort_values().plot.bar()
plt.title('各品牌总销售额', fontsize = 20)
plt.ylabel('商品总销售额' , fontsize = 15)
#旋转显示plt.xticks(rotation=45)
##补充绘图,挖掘数据,各品牌的平均每单单价,三个销量为0的品牌暂时不考虑
plt.subplot(2,2,4)
plt.tick_params(labelsize = 15)
avg_price=data.groupby('店名')['销售额'].sum()/data.groupby('店名').sale_count.sum() ###每个品牌售出的商品的平均单价
avg_price.sort_values().plot.bar()
plt.title('各品牌平均每单单价', fontsize = 20)
plt.ylabel('售出商品的平均单价' , fontsize = 15)
##自适应调整子图间距
plt.tight_layout()
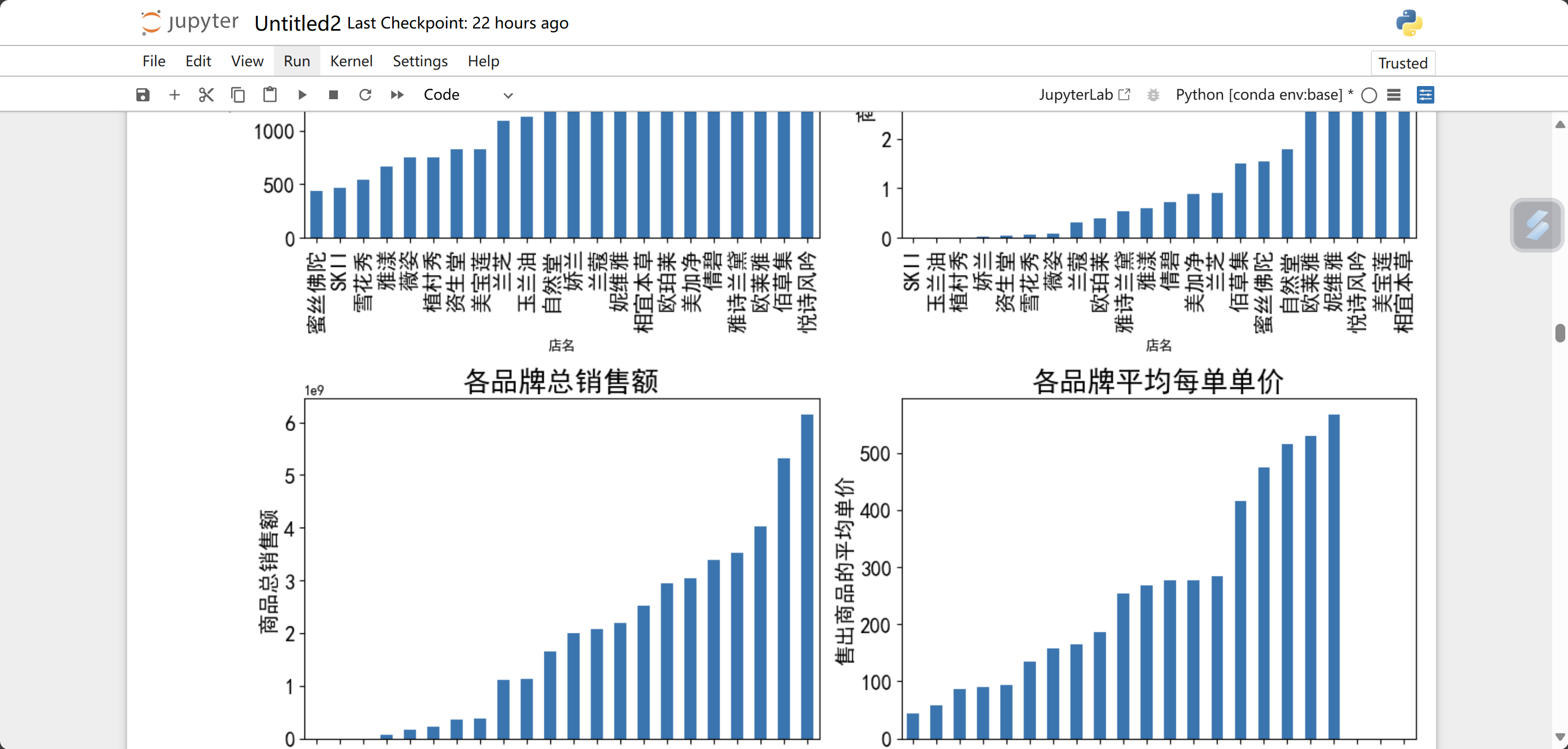
plt.show()这段代码实现的是,我们创建了四个子图(方便比较),第一个为各品牌的商品数,第二个是各品牌所有商品的销量,第三个是各品牌总销售量,第四个为各品牌平均每单单价。代码具体含义我已经标注在代码后边了
运行结果为:
A = avg_price[(avg_price <= 100) & (avg_price > 0)].index
B = avg_price[(avg_price <= 200) & (avg_price > 100)].index
C = avg_price[(avg_price <= 300) & (avg_price > 200)].index
D = avg_price[avg_price > 300].index
sum_sale = data.groupby('店名')['销售额'].sum()
plt.figure(figsize=(16, 8)) # 新建画布
# 子图1:各类、各品牌的销售额占比
ax1 = plt.subplot(1, 2, 1)
sum_sale_byprice = pd.concat([
sum_sale[A].sort_values(),
sum_sale[B].sort_values(),
sum_sale[C].sort_values(),
sum_sale[D].sort_values()
])
ax1.pie(
x=sum_sale_byprice,
labels=sum_sale_byprice.index,
colors=['grey']*len(A) + ['g']*len(B) + ['y']*len(C) + ['m']*len(D),
autopct='%0f%%',
pctdistance=0.9
)
# 子图2:各类的平均每个店销售额
ax2 = plt.subplot(1, 2, 2)
ax2.tick_params(labelsize=15)
ax2.bar('均价0-100元', np.mean(sum_sale[A]), color='grey')
ax2.bar('均价100-200元', np.mean(sum_sale[B]), color='g')
ax2.bar('均价200-300元', np.mean(sum_sale[C]), color='y')
ax2.bar('均价300元以上', np.mean(sum_sale[D]), color='m')
ax2.set_title('不同类别的平均每个店销售额', fontsize=20)
ax2.set_ylabel('平均销售额', fontsize=20)
plt.tight_layout() # 自动优化布局
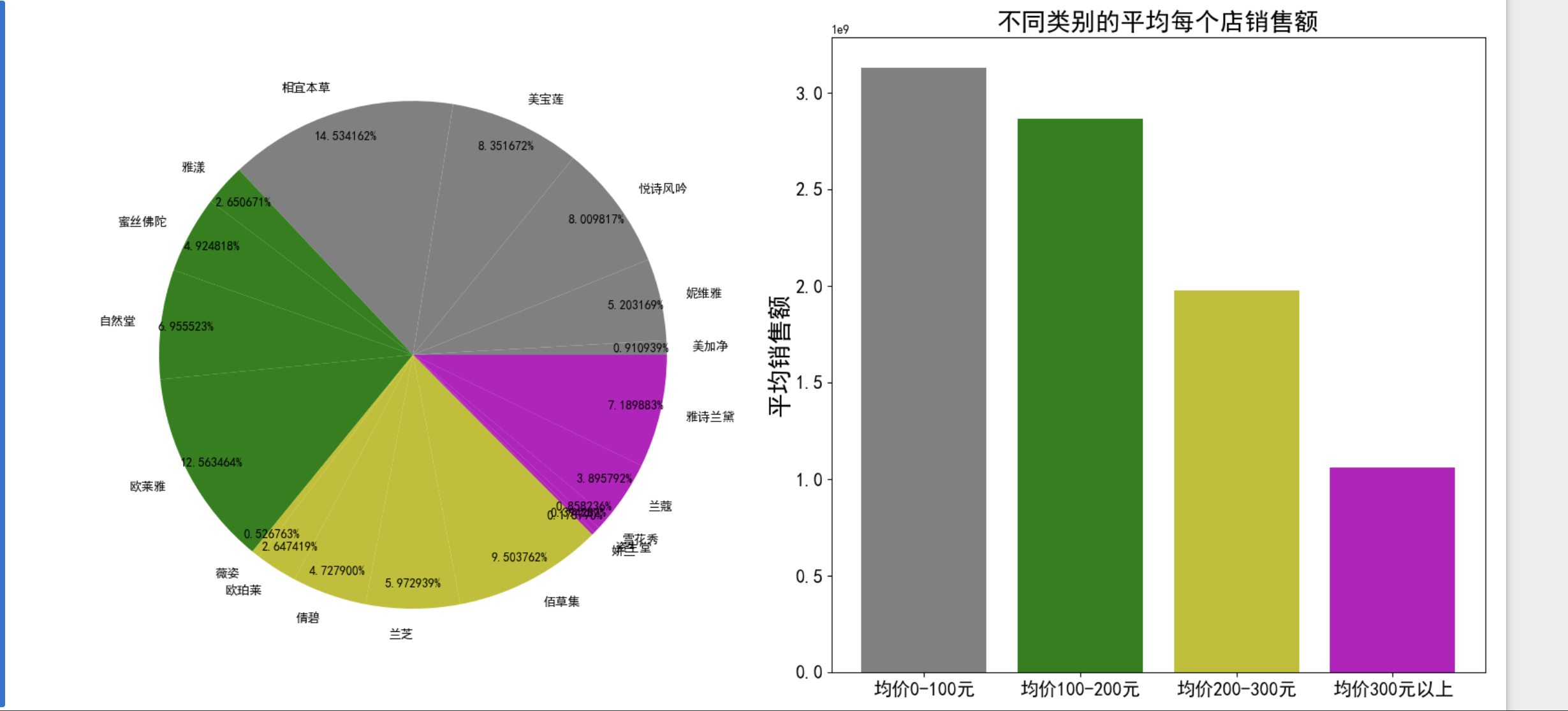
plt.show() # 显示当前画布运行结果为:
#大类销售量、销售额的占比
plt.figure(figsize = (12,12))
#销售量
plt.subplot(2,2,1)
data.groupby('main_type').sale_count.sum().plot.pie(autopct = '%0f%%',title = '各大类销售量占比')
#销售额
plt.subplot(2,2,2)
data.groupby('main_type')['销售额'].sum().plot.pie(autopct = '%0f%%',title = '各大类销售额占比')
#小类销售量、销售额的占比
plt.subplot(2,2,3)
data.groupby('sub_type').sale_count.sum().plot.pie(autopct = '%0f%%',title = '各小类销售量占比')
plt.subplot(2,2,4)
data.groupby('sub_type')['销售额'].sum().plot.pie(autopct = '%0f%%',title = '各小类销售额占比')
plt.tight_layout()
plt.show()运行结果为: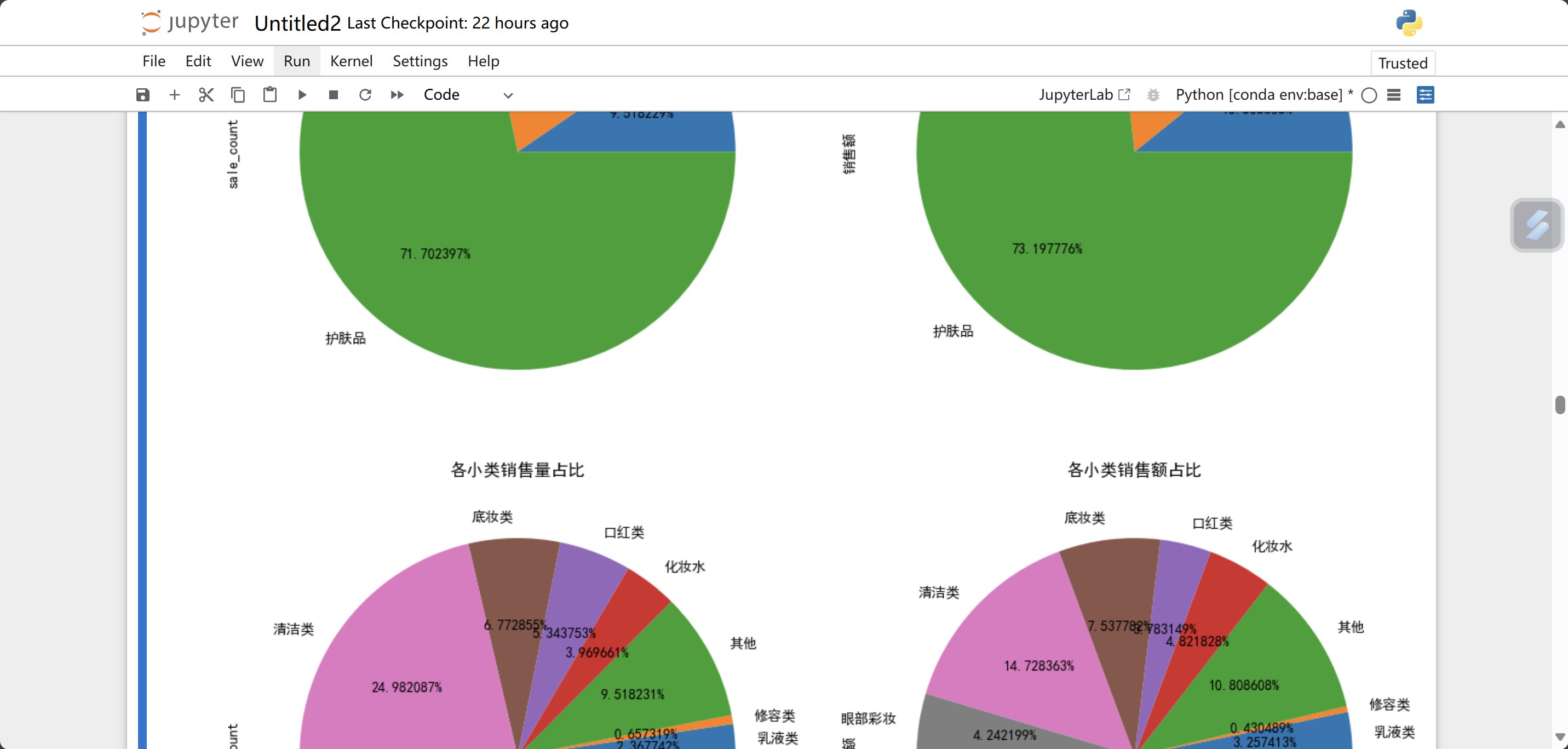
##为了减少图形复杂度,先去掉总销量为0的店铺,分别为SKII,植村秀,玉兰油
data1 = data.drop(index = data[data['店名'].isin(data.groupby('店名').sale_count.sum()[data.groupby('店名').sale_count.sum() == 0].index)].index)
data1['店名'].value_counts()接下来我们导入了seaborn库来绘制较为复杂的图形
import seaborn as sns#导包
plt.figure(figsize=(16, 12))#设置画布的大小
plt.subplot(2, 1, 1)#(2,1)的第一个子图
plt.tick_params(labelsize=10)#x,y标签的大小
sns.barplot(x='店名', y='sale_count', hue='main_type',
estimator=np.sum, data=data1, errorbar=('ci', 0)) #设置了x,y轴,hue是嵌套,绘制的嵌套的图形,对estimator进行求和
plt.title('各店铺中各大类的销售量', fontsize=20)#题目的名称和大小
plt.ylabel('销量', fontsize=15)#y轴的标签和大小
# 第二个子图,原理同上
plt.subplot(2, 1, 2)
plt.tick_params(labelsize=10)
sns.barplot(x='店名', y='销售额', hue='main_type',
estimator=np.sum, data=data1, errorbar=('ci', 0))
plt.title('各店铺中各大类的销售额', fontsize=20)
plt.ylabel('销售额', fontsize=15)
plt.tight_layout()#自适应绘制子图
plt.show()运行结果: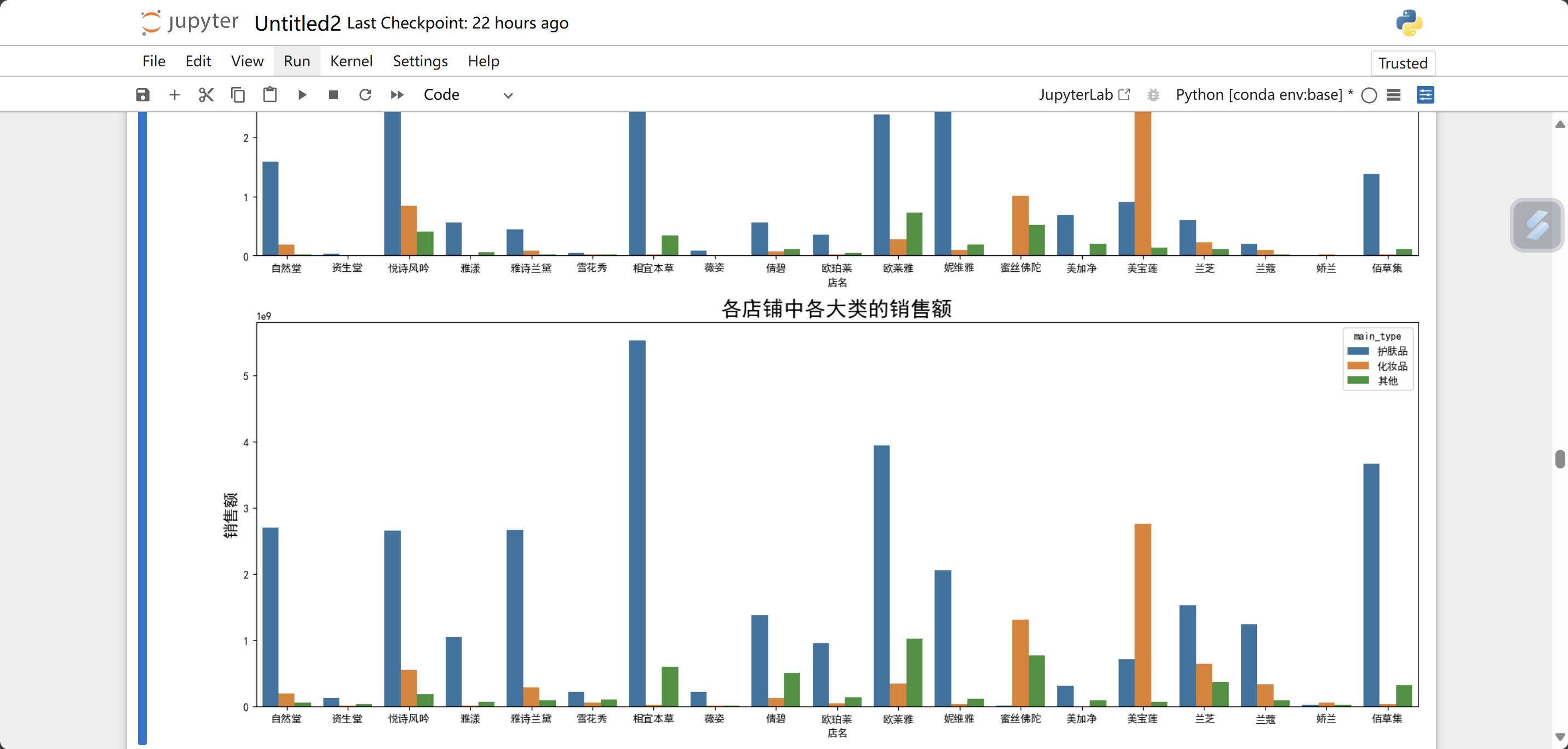
下边的多种柱状图就是嵌套形成的
plt.figure(figsize = (16,12))
plt.subplot(2,1,1)
plt.tick_params(labelsize = 10)
sns.barplot(x = 'sub_type', y = 'sale_count', hue = '店名' ,estimator=np.sum, data = data1 , errorbar=('ci', 0))####estimator参数取该列的什么值
plt.title('各小类中各店铺的销售量',fontsize = 20)
plt.ylabel('销量',fontsize = 15)
plt.subplot(2,1,2)
plt.tick_params(labelsize = 10)
sns.barplot(x = 'sub_type', y = '销售额', hue = '店名' ,estimator=np.sum, data = data1 , errorbar=('ci', 0))
plt.title('各小类中各店铺的销售额',fontsize = 20)
plt.ylabel('销售额',fontsize = 15)
plt.tight_layout()
plt.show()小类商品的销售量运行结果:
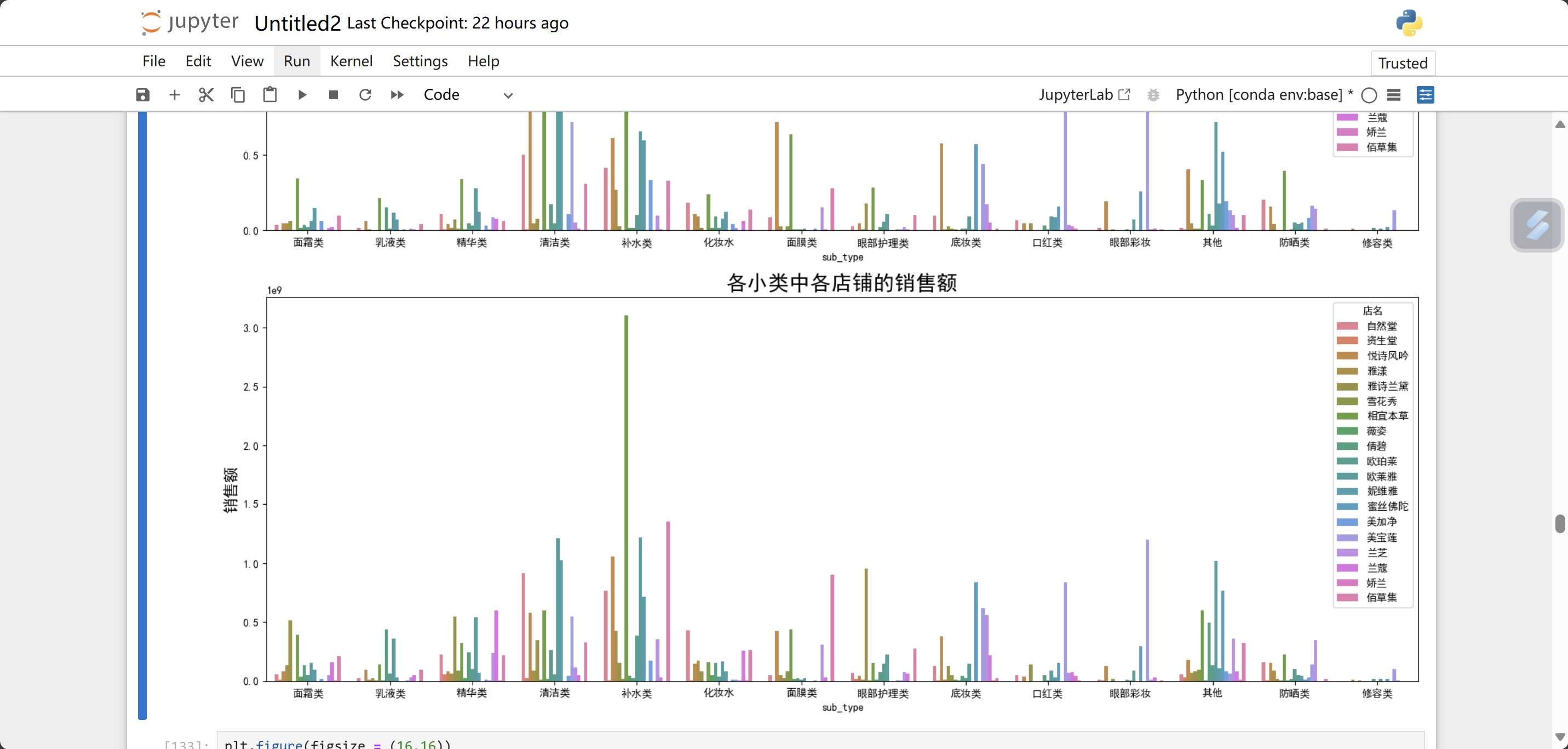
plt.figure(figsize = (16,16))
#男士专用中各类销量占比
plt.subplot(2,2,1)
data.loc[data['是否男士专用'] == '是'].groupby('sub_type').sale_count.sum().plot.pie(autopct = '%0f%%',title = '男士各小类销售量占比', pctdistance=0.8)
#非男士专用中各类销量占比
plt.subplot(2,2,2)
data.loc[data['是否男士专用'] == '否'].groupby('sub_type').sale_count.sum().plot.pie(autopct = '%0f%%',title = '非男士专用各小类销售量占比', pctdistance=0.8)
#男士专用销售量占总销售量
plt.subplot(2,2,3)
data.groupby('是否男士专用').sale_count.sum().plot.pie(autopct = '%0f%%',title = '男士专用销售量占比', pctdistance=0.8)
#男士专用销售额占总销售额
plt.subplot(2,2,4)
data.groupby('是否男士专用')['销售额'].sum().plot.pie(autopct = '%0f%%',title = '男士专用销售额占比', pctdistance=0.8)
plt.tight_layout()
plt.show()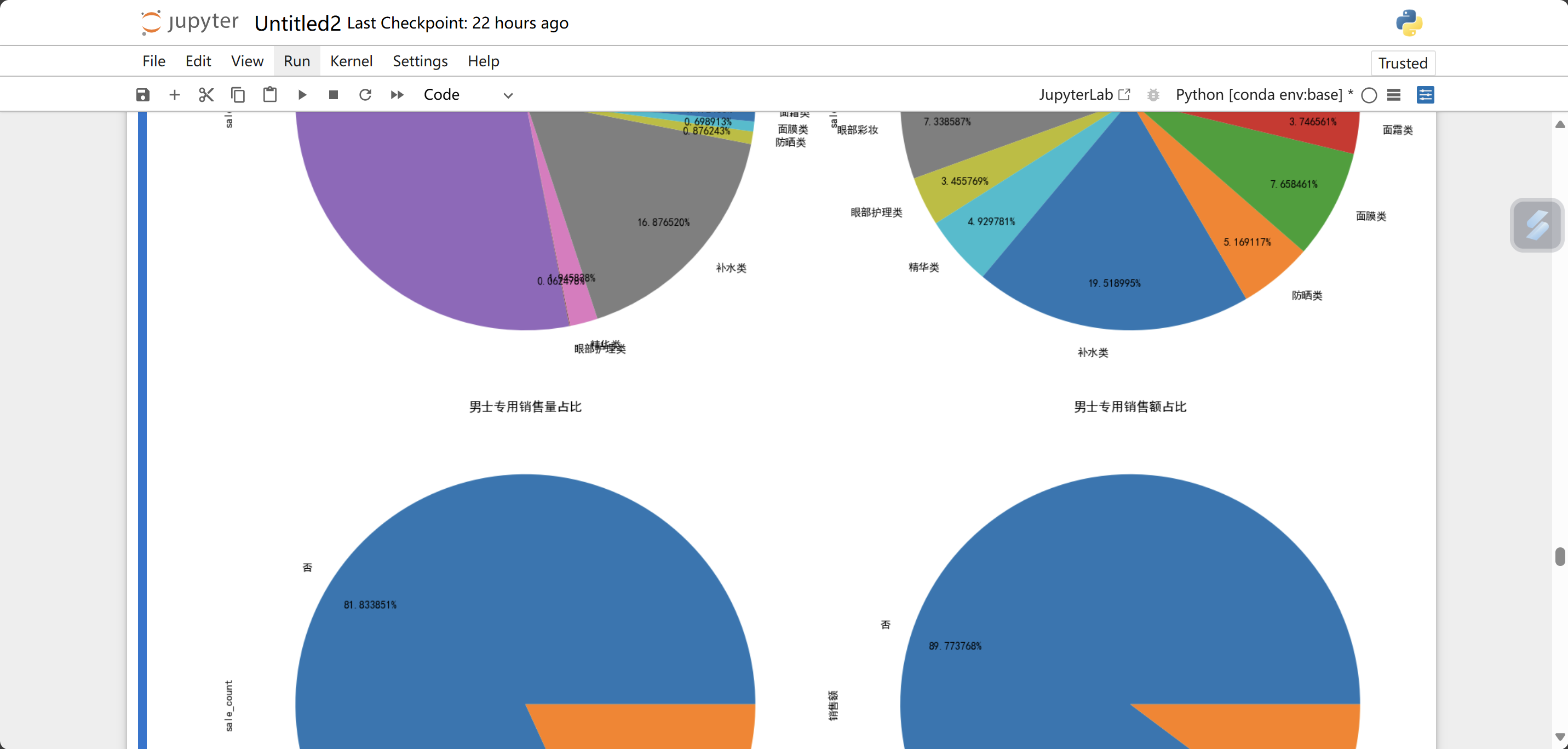
plt.rcParams["font.family"] = ["SimHei", "Microsoft YaHei", "SimSun"]
plt.rcParams["axes.unicode_minus"] = False
# 创建画布
plt.figure(figsize=(12, 12))
# 处理每日销量
sale_day = data.groupby('update_time').sale_count.sum()
sale_day.index = [datetime.strptime(i, '%Y/%m/%d') for i in sale_day.index]
sale_day = sale_day.sort_index()
# 绘制每日销量
plt.subplot(2, 1, 1)
plt.tick_params(labelsize=15)
sale_day.plot()
plt.grid(linestyle='-.')
plt.title('每日销售量', fontsize=15)
plt.ylabel('销量', fontsize=10)
# 处理每日销售额
r_day = data.groupby('update_time')['销售额'].sum()
r_day.index = [datetime.strptime(i, '%Y/%m/%d') for i in r_day.index]
r_day = r_day.sort_index()
# 绘制每日销售额
plt.subplot(2, 1, 2)
plt.tick_params(labelsize=15)
r_day.plot()
plt.grid(linestyle = '-.')
plt.title('每日销售额', fontsize=15)
plt.ylabel('销售额', fontsize=15)
plt.tight_layout()
plt.show()绘制每日销售量的折线图
运行结果: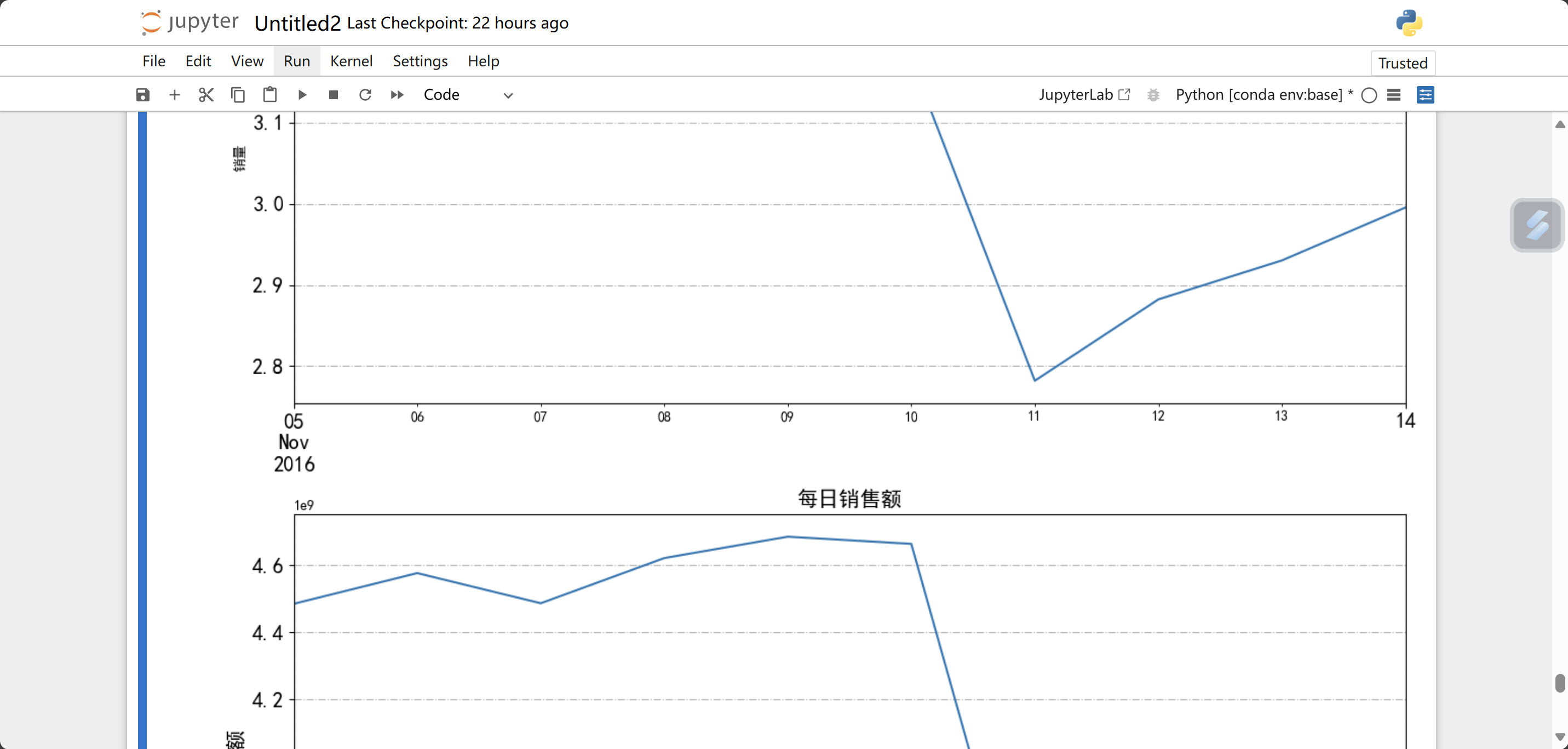
五,总结
等等,我们还可以根据这个格式可视化出更多的东西,例如每个店铺平均每多少单有一个评论等等。可视化是我们的目的之一,我们主要是为了分析,做出来可视化我们也更好的去分析问题,例如,我在以后的双十一可以在11.09设置一个合理的价格。或者是以后我如果想开一个店铺的话我应该多进什么品牌的化妆品,主要针对人群是什么。
例如:
先观察销量,各店小类中销量最高的是相宜本草的补水类商品以及妮维雅的清洁类商品,这两类销量很接近。而销售额上,相宜本草的补水类商品比妮维雅的清洁类商品要高得多,这显然是商品平均单价不同所导致的。由于不同的类别使用量也不同,销量自然也会有所区别,所以相对于比较每个店铺的不同类别的销售量,比较每个不同类别的各店铺的销售量应该更有价值。
不难看出,欧莱雅和妮维雅占据了男性专用商品的绝大部分市场,不管是销量还是销售额。这一点在不区分是否男性专用的商品中是有所出入的。欧莱雅在无论在哪个方面都表现的很好,虽然销量在非男士专用商品里属于一般水平,但销售额都名列前茅。而妮维雅在非男士专用商品里的销售情况就很差了,这说明妮维雅主打的就是男士专用商品。而相宜本草在非男士专用商品的表现还是遥遥领先,其在男士专用商品中也排在第三位,虽然和前两名都有比较大的差距。