在 Python 中将 PDF 文件保存为图片,最常用的方法是使用 pdf2image 库。这个库实际上是 poppler 工具的 Python 封装,能够将 PDF 的每一页渲染为高质量的图片(如 PNG 或 JPEG)。
以下是详细的操作步骤和代码示例:
第一步:安装依赖库
pip install pdf2image pillowpdf2image: 用于将 PDF 转换为图像。Pillow(PIL): 用于图像处理和保存。
第二步:安装 poppler
pdf2image 依赖于 poppler,需要单独安装:
Windows:
下载 poppler for Windows:https://github.com/oschwartz10612/poppler-windows/releases/
解压后,将 poppler-xx.x.x\bin 目录添加到系统环境变量 PATH 中。或者在代码中指定 poppler_path。
第三步:Python 代码示例
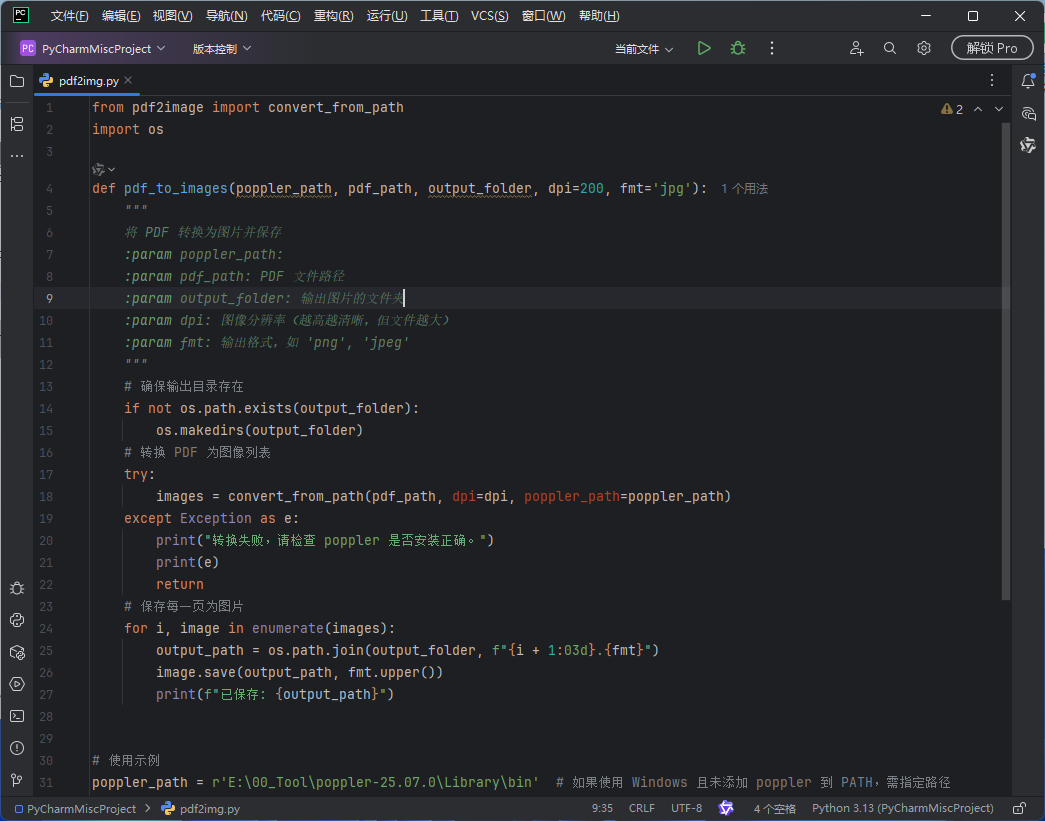
from pdf2image import convert_from_path
import os
def pdf_to_images(poppler_path, pdf_path, output_folder, dpi=200, fmt='jpg'):
"""
将 PDF 转换为图片并保存
:param poppler_path:
:param pdf_path: PDF 文件路径
:param output_folder: 输出图片的文件夹
:param dpi: 图像分辨率(越高越清晰,但文件越大)
:param fmt: 输出格式,如 'png', 'jpeg'
"""
# 确保输出目录存在
if not os.path.exists(output_folder):
os.makedirs(output_folder)
# 转换 PDF 为图像列表
try:
images = convert_from_path(pdf_path, dpi=dpi, poppler_path=poppler_path)
except Exception as e:
print("转换失败,请检查 poppler 是否安装正确。")
print(e)
return
# 保存每一页为图片
for i, image in enumerate(images):
output_path = os.path.join(output_folder, f"{i + 1:03d}.{fmt}")
image.save(output_path, fmt.upper())
print(f"已保存: {output_path}")
# 使用示例
poppler_path = r'E:\00_Tool\poppler-25.07.0\Library\bin' # 如果使用 Windows 且未添加 poppler 到 PATH,需指定路径
input_file_path = r"E:\****报告.pdf"
file_name = os.path.basename(input_file_path)
file_name_without_extension, file_extension = os.path.splitext(file_name)
# 创建输出文件夹
desktop_path = os.path.join(os.path.expanduser("~"), "Desktop") # 桌面路径
output_folder = os.path.join(desktop_path, file_name_without_extension) # 输出文件夹
pdf_to_images(poppler_path, input_file_path, output_folder, dpi=200, fmt='png')
输出格式说明
fmt='png': 推荐用于清晰文本和透明背景。fmt='jpeg': 文件更小,适合照片类 PDF,但有损压缩。提高
dpi值可以提升图像质量,但会增加处理时间和文件大小。如果 PDF 有加密或损坏,转换可能失败。