01总体设计
我们为什么需要数据湖,数据湖又能解决哪些痛点问题?
在数据应用中,需要存储的数据不仅有格式化数据,也有非格式化数据,如:文本视频、图片、音乐等。多种数据格式的数据,如何进行集中式的数据存储,那就是今天的主角数据湖,数据湖可以实现离线和实时底层数据存储的统一,并解决Kappa架构的痛点问题。
Kappa架构痛点问题:
1)Kafka不支持海量数据存储;
2)Kappa架构中使用Kafka做分层,Kafka不支持SQL、 OLAP分析;
3)Kafka做分层,不能很好集成原有的数据血缘关系系统、数据质量管理系统;
4)Kafka不支持数据的更新,只支持数据的Appand。
02系统核心设计
数据驱动决策正在加速推动数据存储的转变,各行业陆续跟进采用了数据湖存储各种数据。但数据湖采用新的原始数据存储和处理范式,缺乏构造和治理,会迅速沦为“数据沼泽”。
可视化湖仓一体作为一种新型数据架构,它同时吸收了数据仓库和数据湖的优势,数据开发工程师、数据分析师和数据科学家可以在同一个数据存储中对数据进行操作,同时它也能对当前数据治理以及过去数据沼泽开荒带来更多的便利性。
科杰科技核心设计如下图所示:
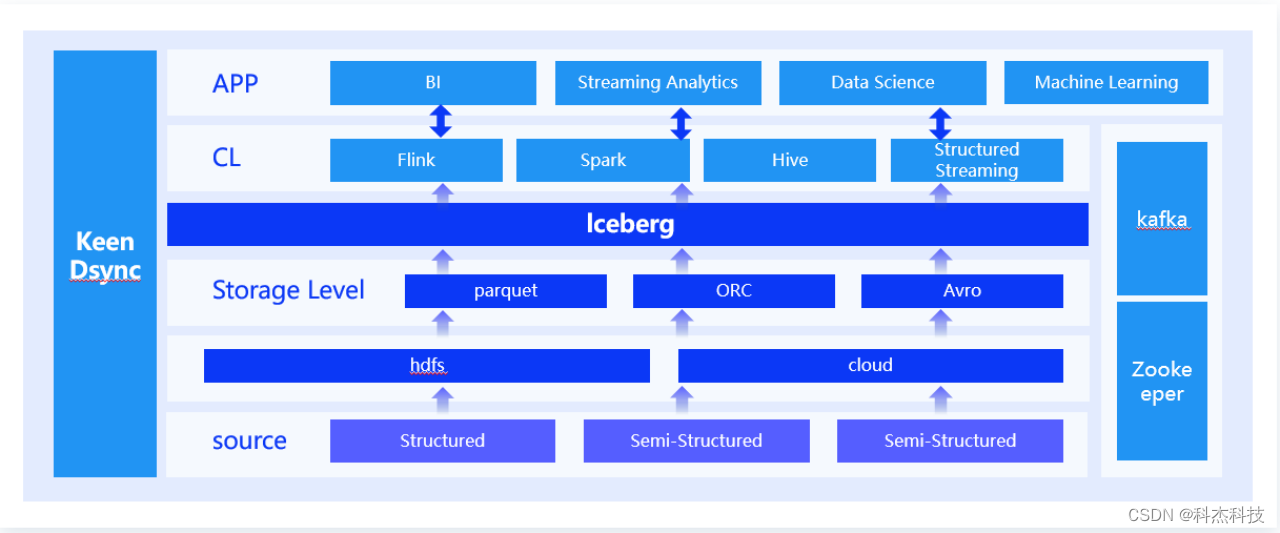
Iceberg概念及特点
Apache Iceberg 是一种用于大型数据分析场景的开放表格式(Table Format)。Iceberg 使用一种类似于SQL表的高性能表格式,其格式表单表可以存储10PB+数据,适配Spark、Trino、PrestoDB、Flink和Hive等计算引擎提高性能的读写和元数据管理功能,同时Iceberg是一种数据湖解决方案。
Iceberg非常轻量级,可以作为lib与Spark/Flink进行集成,它具备以下特点:
1) 支持实时/批量数据写入和读取,支持Spark/Flink计算引擎;
2) 支持事务ACID,支持添加、删除、更新数据;
3) 不绑定任何底层存储,支持Parquet、ORC、Avro格式兼容存储和列存储;
4) 支持隐藏分区和分区变更,方便业务进行数据分区策略;
5) 支持快照数据重复查询,具备版本回滚功能;
6) 扫描计划非常快,读取表或者查询文件可以不需要分布式SQL引擎;
7) 通过表元数据来查询进行高效过滤;
8) 基于乐观锁的并发支持,提供多线程并发写入能力并保证数据线性一致。
支持的数据格式
boolean、int、float、double、decimal、time、timestamptz、Fixed(L)、Binary、List<E>、Map<K,V>
03技术架构
整合Hive与Iceberg
Iceberg是一种表格式,用它来对Hive进行读写操作。要基于Iceberg表来查询,我们需要下载Hive的lib里面加入Icebeg功能依赖包。配置hive-site.xml,iceberg.engine.hive.enabled 为true重启Hive。
在Hive的角度来看,Hive的运行环境中有Catalog概念,与Iceberg整合时,Iceberg支持多种不同的Catalog类型,在实际场景中,Hive 可能使用到Iceberg 能够支持的任意场景,甚至需要跨不同Catalog类型进行join数据操作,为此提供了Hive Iceberg Storage Handler来读写Iceberg表,并通过在Hive中设置iceberg.catalog.<catalog_name>.type 属性来决定加载Iceberg表的方式。iceberg.catalog.<catalog_name>.warehouse指定数据路径。如果没有设置iceberg.catalog属性,默认使用Hive catalog来加载和Hive warehouse存储路径。设置iceberg.catalog,那么必须指定warehouse 存储路径。在Iceberg和Hive整合中iceberg catalog指定成location_based_table,默认是将Iceberg数据对应的路径加载成Iceberg表。
Hive 和Iceberg整合中要注意的点Iceberg表有分区,使用Hive创建时直接指定分区就可以,Hive创建不支持隐藏分区。加载Iceberg数据路径是分区表,创建Iceberg表时分区字段当普通字段处理即可。
整合Spark 与Iceberg
Spark可以操作Iceberg数据湖,在Spark2.4版本中操作Iceberg时不支持DDL、增加分区及分区转换、Iceberg元数查询、insert into/overwrite等操作,建议使用Spark3.x以上的版本来整合Iceberg。
在SparkSQL中通常使用以下方式来指定使用的Catalog:

如果是Hive_prod需要指定下两个属性,Hadoop 的Catalog只需要指定Warehouse路径存储。

Spark 与Iceberg的DDL操作,首先创建一张Iceberg表,在创建表阶段中不仅可以创建普通表还可以创建分区表,向Iceberg表中插入数据之前,需要对数据按照分区列进行排序。

基于Iceberg创建隐藏分区,基于已有的列进行转换得到分区,插入的数据这种需要必须提前排序,只要是相同日期数据写在一起就可以如下:

整合StructureStreaming 与Iceberg
目前Spark 中 StructuredStreaming 只支持实时向Iceberg中写入数据,不支持实时从Iceberg中读取数据,科杰科技采用的方式是使用Structured Streaming从kafka中实时读取数据,再写入到Iceberg。
1)首先准备对象,指定Catalog类型;
2)创建Iceberg表,bootStrapServers如果用多个topic我们用逗号分开;
3)启动任务读取kafka数据;
4)转换成df.,如:df.selectExpr(“cast (key as String)”,”cast (value as String)”)
.as[(String,String)].toDF(“key”,”data”)
5) 最后将结果写入到Iceberg。
Structuerd Streaming 向Iceberg实时写入数据需要注意点:
写Iceberg表支持两种模式,append和complete,append是将每个微批数据行追加到表中,complete 是替换每个微批数据内容。
向Iceberg中写出数据时指定的path可以是HDFS路径,可以是Iceberg表名,如果是表名,要预先创建好Iceberg表。
写出参数fanout-enabled指的是如果iceberg写出的表是分区表,在向表中写数据之前要求Spark每个分区的数据必须排序,但这样会带来数据延迟,为了避免这个延迟,可以设置“faniout-enabled”参数为true,可以针对每个Spark分区打开一个文件,直到当前task批次数据写完,这个文件才关闭。
实时向Iceberg表中写数据时,建议trigger设置至少为1分钟提交一次,因为每次提交都会产生一个新的数据文件和元数据文件,这样可以减少一些小文件。为了进一步减少数据文件,建议定期合并“data files”。
整合Flink与Iceberg
目前Flink支持使用DataStream API 和SQL API 方式实时读取和写入Iceberg表,在多方案和实践中推荐使用SQL API 方式实时读取和写入Iceberg表。
1) 创建Flink境 StreamExecutionEnvironment.getExecutionEnvironment();
2) 设置chekpoint;
3) 采用Flink读取Kafka中的数据,bootStrapServers中多个topic用逗号隔开;
4) dataStream.map 数据转换成df;
5) 配置catalog和表的schema和数据存储路径,创建Iceberg表schema如果有分区指定对应分区,也可以指定unpartitioned 方法不设置分区。指定Iceberg表数据格式化存储格式如:parquet、ORC、avro;
6) 将流式结果写入Iceberg表中。
Flink SQL API 步骤:
1)创建Catalog,当前使用的Catalog类型;
2)创建数据库和当前使用的数据库;
3)创建Iceberg表;
4)向Iceberg表中插入数据。
04构建湖仓
Iceberg比传统的湖仓支持的存储格式增加了ORC,Iceberg支持SparkSQL和FlinkSQL,Schema与计算引擎是解耦的,不依赖任何的计算引擎。通过以科杰科技方案整合,数据从web等客户端发生,存储到线上数据库,最终进入到数据湖中。通过建立Iceberg表构造仓体,ods 层Iceberg表直接存放业务系统数据进入湖的最初状态,将不同业务系统中的数据汇聚在一起。在DataWareHouse Iceberg表按照主题建立数据模型,元数归类汇总防止数据解决数据沼泽产生。数据服务层,按照主题业务组织主题建立宽表,可以用于最上层OLAP分析。Data Mart 基于DW上的基础数据,整合汇总成分析某个主题域的报表数据等。