
我们继续上篇文章所讲的数据查询
字符匹配
匹配固定字符串
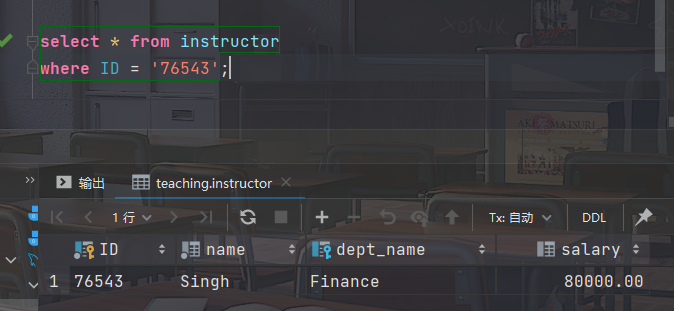
- 找出工号为76543的教师的详细情况
select * from instructor where ID = '76543'
select * from instructor where ID = '76543';
通配符(重要!!)
- %(百分号)代表任意长度(长度可以为0)的字符串
-
- 例如:a%b表示以a开头,以b结尾的任意长度的字符串.如acb,addgb,ab等都慢则该匹配串
- _(下划线)代表任意单个字符
-
- 例如:a_b表示以a开头,以b结尾的长度为3的任意字符串.如acb,afb等都满足该匹配串.注意!!!长度!!!
- 当用户要查询的字符串本身就含有%或者_时,就要使用ESCAPE'<换码字符>'短语对通配符进行转义
-
- like 'ab\%cd|' escape'\' #(匹配所有以"ab%cd"开头的字符串)
- like 'ab\\cd%' escape '\' #(匹配所有以"ab\cd"开头的字符串)
匹配含有通配符的字符串
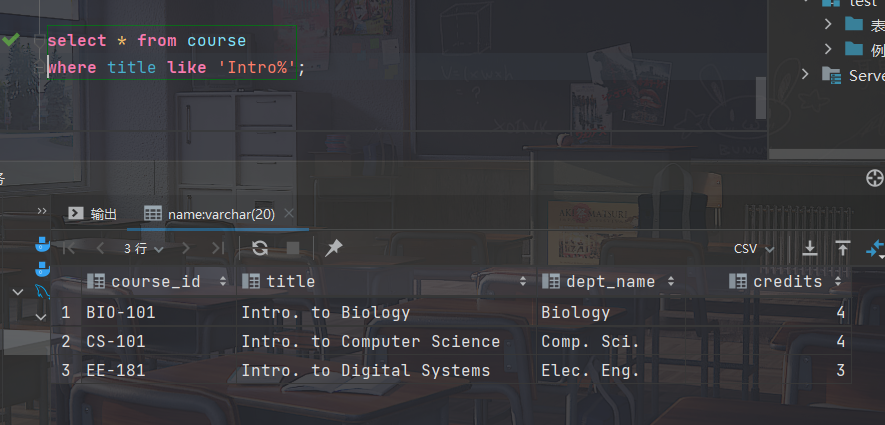
- 找出课程名以"Intro"为开头的课程的详细信息
select * from course where title like 'Intro%';
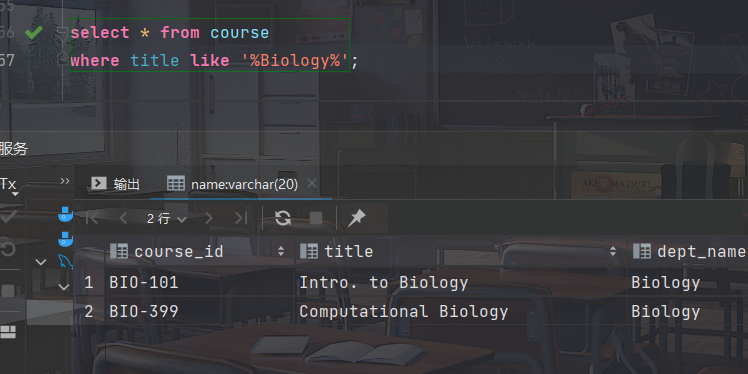
- 找出课程名字中包含子串"Biology"的课程的详细信息
select * from course where title like '%Biology%';
- SQL标准中,字符串上的相等运算大小写敏感
- MySQL在匹配字符串时并不区分大小写
空值(NULL)
- 空值表示"不知道","不确定"
- 涉及空值的运算
-
- 涉及控制的算术运算的结果为空,如:5+null 返回null
- 涉及空值的比较运算的结果为unknown,如: 5 < null ; null <>null ; null = null
- 涉及空值的逻辑运算
-
-
- OR:
- (unknown or true) = true,
- (unknown or false) = unknown
- (unknown or unknown) = unknown
- AND:
- (true and unknown) = unknown
- (false and unknown) = false
- (unknown and unknown) = unknown
- NOT:
- (not unknown) = unknown
-
- 如果where子句对一个元组计算出false或unknown,那么该元组不能被加入到结果集中.
- 使用IS NULL 和IS NOT NULL 测试空值
-
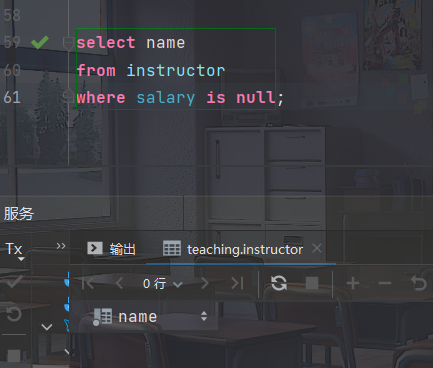
- 例如:找出instructor关系中salary为空值的所有教师
select name from instructor where salary is null;
没有不是空值的
ORDER BY子句
- ORDER BY 子句
-
- 可以按一个或者多个属性列排序
- 升序:ASC
- 降序:DESC
- 默认是升序
- 当排序列含空值的时候
-
- ASC:排序列为空值的元组最先显示
- DESC:排序列为空值的元组最后显示
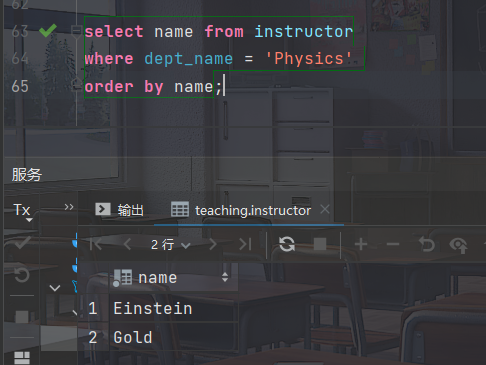
- 按字母顺序列出在Physics系的所有老师
select name from instructor where dept_name = 'Physics' order by name;
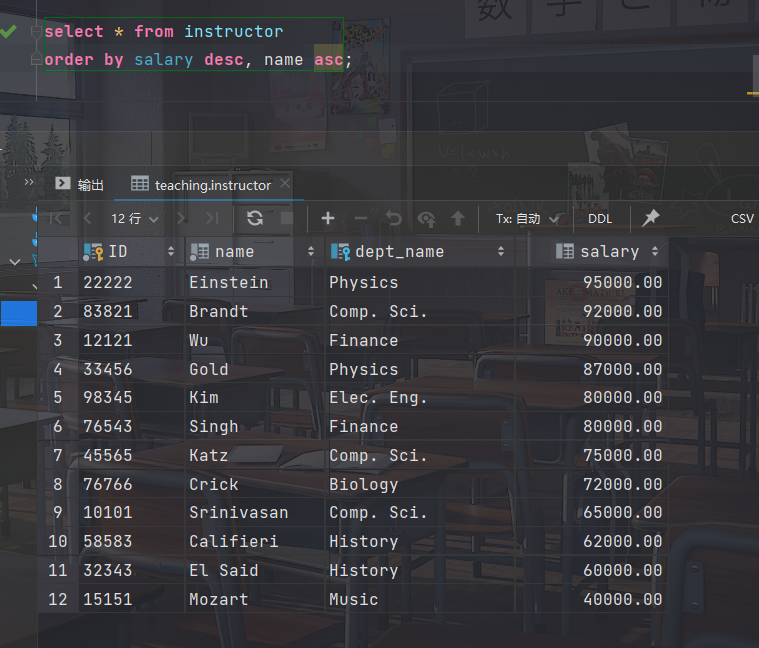
- 将Instructor 关系按照salary降序,salary相同时按照name升序排列
select * from instructor order by salary desc, name asc;
聚集函数
- 聚集函数是以值的一个集合作为输入,返回单个值的函数
- 五个聚集函数
-
- 平均值:AVG
- 最小值:MIN
- 最大值:MAX
- 总和:SUM
- 计数:COUNT

- DISTINCT短语:在计算时要取消指定列中的重复值
- ALL短语:不取消重复值
- ALL为缺省值
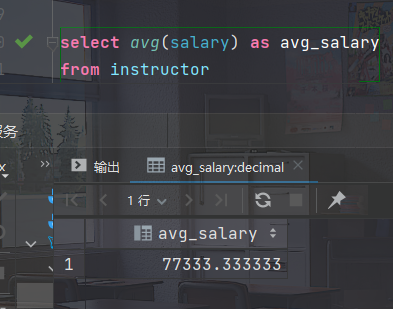
- 找出"Comp. Sci."系教师的平均工资
select avg(salary) as avg_salary from instructor where dept_name = 'Comp. Sci.';
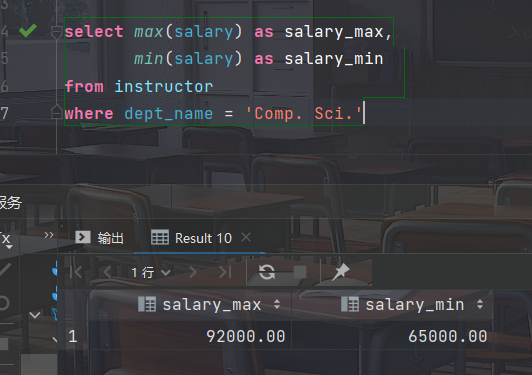
- 找出“Comp. Sci. ”系教师的最高工资和最低工资
select max(salary) as salary_max, min(salary) as salary_min from instructor where dept_name = 'Comp. Sci.'
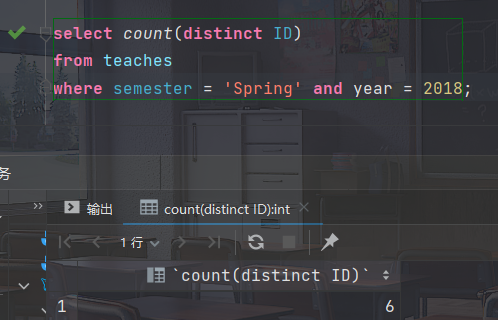
- 找出在2018年春季学期讲授课程的教师总数
select count(distinct ID) from teaches where semester = 'Spring' and year = 2018;
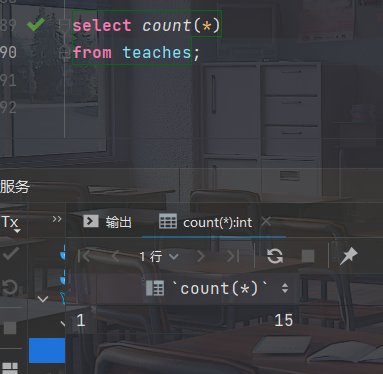
- 计算teaches关系中元组的个数
select count(*) from teaches;
聚集函数处理空值的原则
- 假设instructor关系中有些元组在salary上取空值,考虑计算所有工资总额的查询
select sum(salary) from instructor;
- 上述的查询中sum运算符是自动忽略NULL的值
- 如果所有元组上salary都取空值,则查询结果为NULL
- 除了count(*)外的所有聚集函数都忽略输入集合中的空值
- 如果集合中只有空值呢?
-
- count运算返回0
- 其余聚集函数的运算返回NULL
- 对于更加复杂的SQL语句,空值的影响会更加难以捉摸
GROUP BT子句
- 细化聚集函数的作用对象
-
- 未对查询结果分组,聚集函数将作用于整个查询结果.
- 对查询结果分组后,聚集函数将分别作用于每个组
- 按照指定的一列或者多列值分组,值相等的为一组
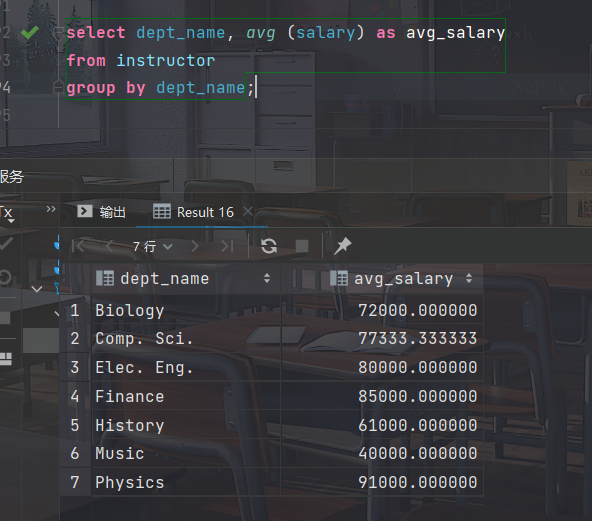
- 找出每个系教师的平均工资
select dept_name, avg (salary) as avg_salary from instructor group by dept_name;
- 限制分组的条件:利用having子句
Having子句
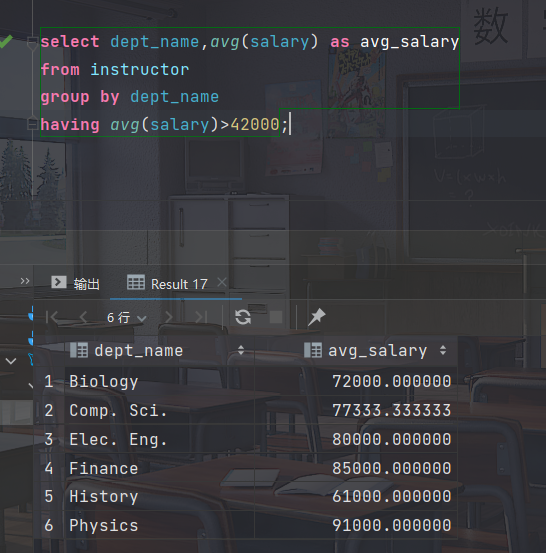
找出教师平均工资超过42000美元的系
select dept_name,avg(salary) as avg_salary from instructor group by dept_name having avg(salary)>42000;
Having 短语和WHERE子句的区别
- 作用对象不同
- WHERE子句作用于基本表或者试图,从中选择满足条件的元组
- Having短语作用于分组,从中选择满足条件的分组
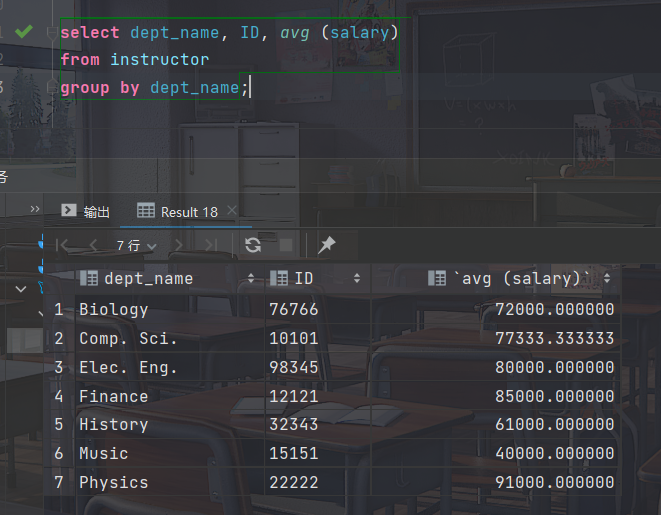
- 保证出现在select语句中 但没有被聚集的属性只能是出现在group by 子句中的那些属性
select dept_name, ID, avg (salary) from instructor group by dept_name;
连接查询
- 当查询同时涉及两个以上的表时,称为连接查询,连接查
询可实现从多个表中提取数据。
连接查询的三种方法
- 方法1:表之间满足一定的条件的元组进行连接,此时FROM子句中指明进行连接的表名, WHERE子句指明连接的列名及其连接条件;
- 方法2:利用关键字JOIN进行连接,并用ON表明连接条件;
- 方法3:利用关键字JOIN进行连接,并用USING指定连接的属性列表
- 找出所有教师的姓名,所在院系以及院系所在建筑的名称
select name, instructor.dept_name, building from instructor, department where instructor.dept_name= department.dept_name;
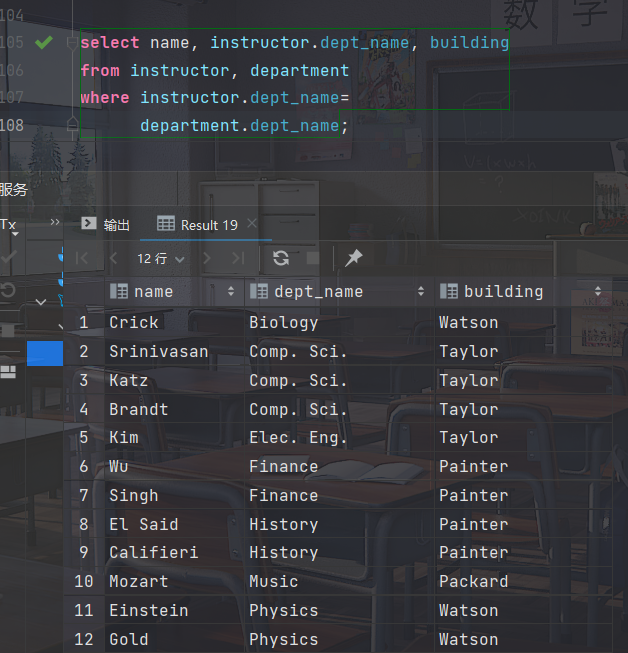
- 找出所有教师的姓名,所在院系以及院系所在建筑的名称
select name, T.dept_name, building from instructor as T, department as D where T.dept_name= D.dept_name;
- 找出满足下面条件的所有教师的姓名,他们的工资至少比Biology系某一个教师的工资要高
select distinct T.name from instructor as T, instructor as S where T.salary > S.salary and S.dept_name = ’Biology’;
利用join关键字连接
- 当将JOIN关键字放于FROM子句中时,应有关键字ON与之相对应,以表明连接的条件。
语句格式:
SELECT {*|<表达式>,…,<表达式>}
FROM <表名> JOIN <表名> ON <条件表达式>
- 找出所有教师的姓名,所在院系以及院系所在建筑的名称
select name, instructor.dept_name, building from instructor, department where instructor.dept_name= department.dept_name; select name, instructor.dept_name, building from instructor join department on instructor.dept_name= department.dept_name;
- 将instructor关系与teaches关系做等值连接
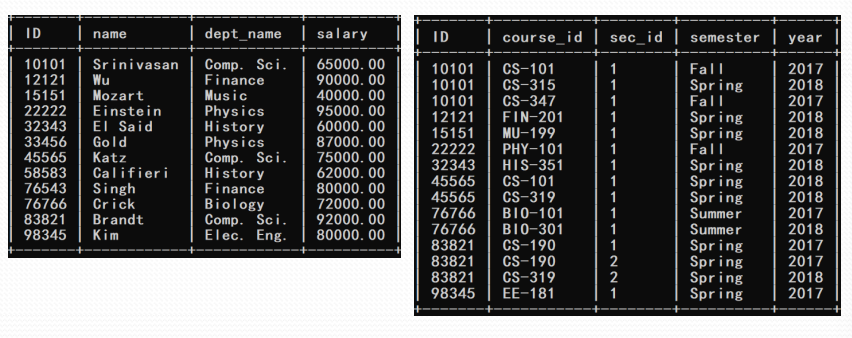
这是两个表的内容
- 等价的两种形式
select * from instructor, teaches where instructor.ID= teaches.ID; select * from instructor join teaches on instructor.ID= teaches.ID;
自然连接
select * from instructor natural join teaches
- 找出每个系在2018年春季学期讲授课程的教师人数
select dept_name, count(distinct ID) as instr_count from instructor natural join teaches where semester = ‘Spring’ and year = 2018 group by dept_name;
外连接
在结果中创建带空值的元组,以此来保留在连接中丢失的
那些元组。

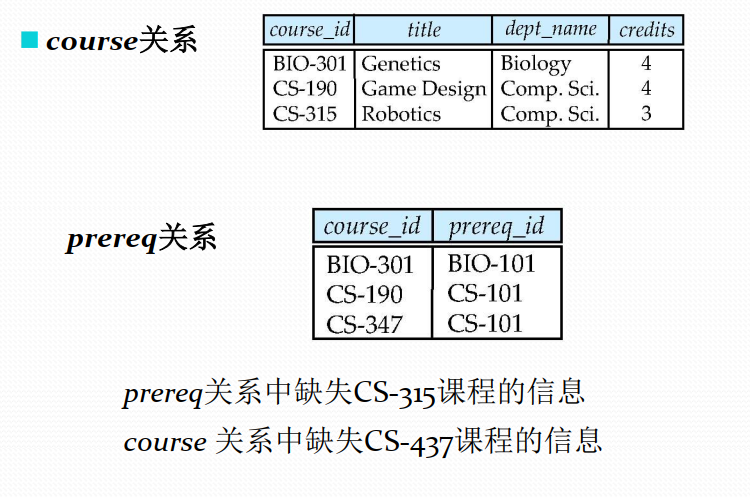
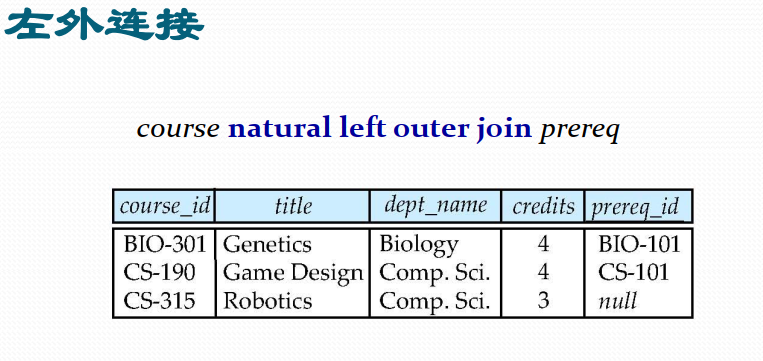

- 考虑查询“找出所有未授课教师的ID、姓名、所在系别”
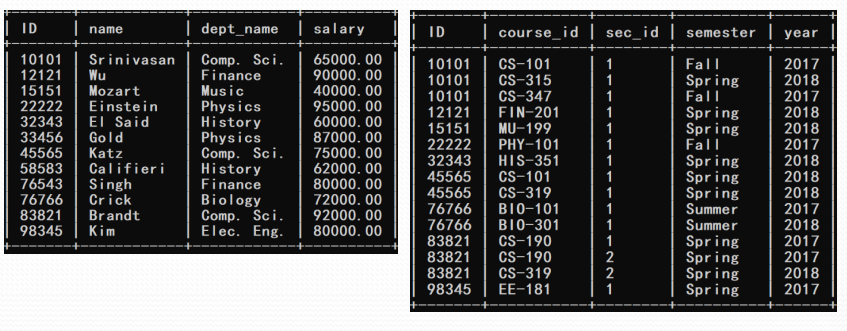
左外连接
- 给出所有教师的个人信息及其授课信息,如果有教师不授
课,其授课信息用NULL表示
select * from instructor natural left outer join teaches;
- 找出所有未授课教师的ID、姓名、所在系别
select ID, name, dept_name from instructor natural left outer join teaches where course_id is null;
考虑查询“找出没有选修任何课程的学生
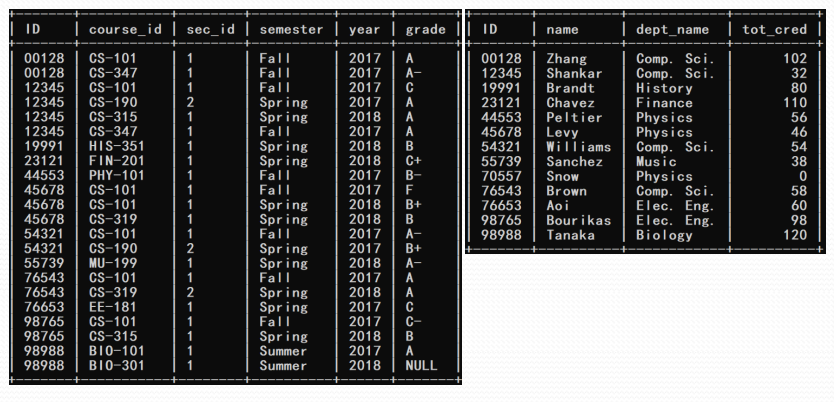
select * from takes natural right outer join student;
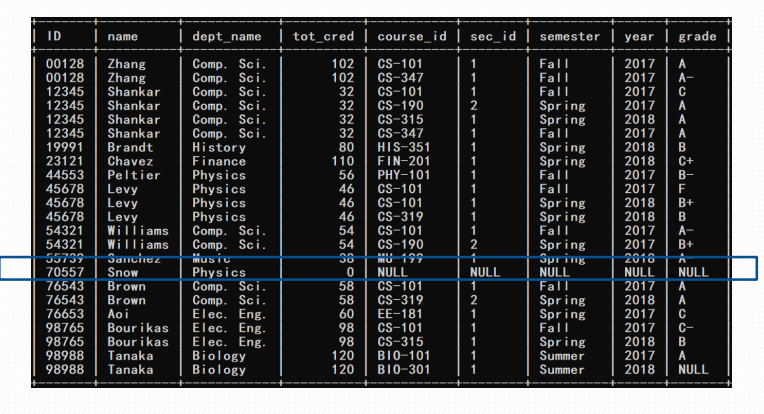
- 找出没有选修任何课程的学生
select ID from takes natural right outer join student where course_id is null;
ON条件与外连接
考虑查询: select * from takes right outer join student on takes.ID= student.ID; 等同于: select * from takes natural right outer join student;
只不过第一个查询中属性ID在结果中出现两次
USING条件连接
- USING指定连接的属性名列表
select * from takes right outer join student using (ID);

多表连接
假设:
instructor(ID, name, dept_name, salary)
teaches(ID, course_id, sec_id, semester, year)
course(course_id, title, dept_name, credits)
考虑查询:列出教师的名字以及他们所讲授课程的名称
select name, title
from instructor natural join teaches natural
join course;
列出教师的名字以及他们所讲授课程的名称
select name, title
from (instructor natural join teaches) join course
using (course_id);
内连接和外连接
SQL把常规连接称作内连接,用inner join表示。
关键词inner是可选的,当join子句中没有使用outer前缀时,
默认的连接类型是inner join。
select *
from student join takes using (ID);
等价于:
select *
from student inner join takes using (ID);
连接类型和连接条件
连接类型 |
Inner join |
Left outer join |
Right outer join |
Full outer join |

集合查询
SQL 作用在关系上的union, intersect和except 运算
分别对应于数学集合论中的∪ , ∩ 和 −。
假设关系c1:在2017年秋季学期开设的所有课程的集合
select course_id from section
where semester = ’Fall’ and year= 2017;
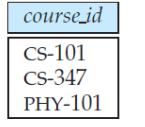
关系c2:在2018年春季学期开设的所有课程的集合:
select course_id from section
where semester = ’Spring’ and year= 2018;
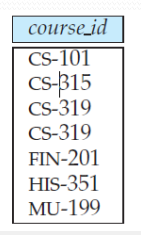
并运算
找出在2017年秋季开设,或者在2018年春季开设或两个学
期都开设的所有课程
(select course_id from section where semester = ’Fall’ and year= 2017) union (select course_id from section where semester = ’Spring’ and year= 2018);
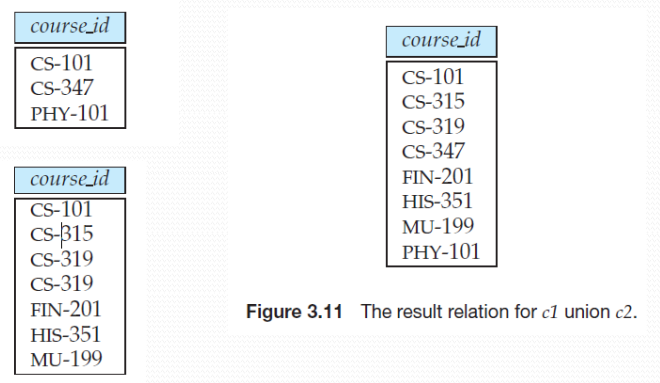
与select不同, union运算自动去除重复
如何保留重复元组?
(select course_id from section where semester = ’Fall’ and year= 2017) union all (select course_id from section where semester = ’Spring’ and year= 2018);
结果中的重复元组数等于在c1和c2中出现的重复元组数的
和
交运算intersect
找出在2017年秋季和2018年春季都开设的课程的集合: (select course_id from section where semester = ’Fall’ and year= 2017) intersect (select course_id from section where semester = ’Spring’ and year= 2018);
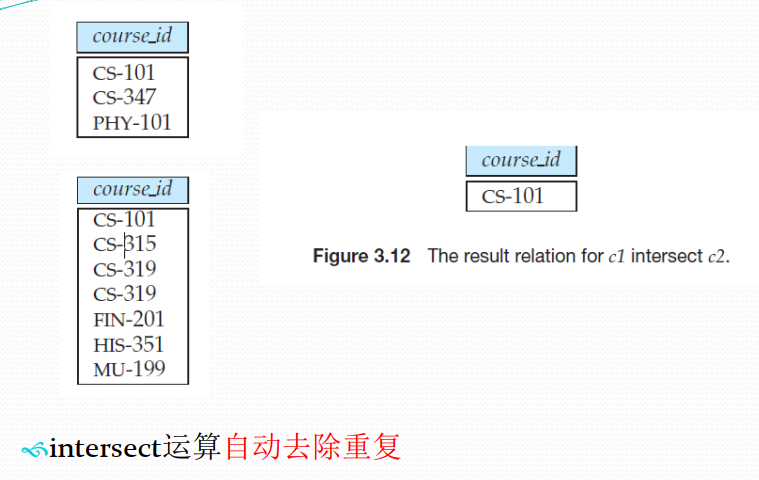
保留重复加all
差运算
找出在2017年秋季学期开设但不在2018年春季学期开设的
所有课程:
(select course_id
from section
where semester = ’Fall’ and year= 2017)
except
(select course_id
from section
where semester = ’Spring’ and year= 2018);

结果中的重复元组数等于c1中出现的重复元组数减去c2中
出现的重复元组数(前提是此差为正)。
MySQL中的集合查询
SQL Server数据库中支持关键字:union,intersect和except
MySQL中只支持union关键字
那我们如何在MySQL中实现intersect和except呢?
嵌套查询
一个 SELECT-FROM-WHERE语句称为一个查询块
将一个查询块嵌套在另外一个查询块的WHERE子句或FROM子句中的查询称为嵌套查询
子查询是嵌套在另一个查询中的SELECT-FROM-WHERE表达式
查询: 找出在2017年秋季学期开课的教师姓名
SELECT name /*外层查询/父查询*/ FROM instructor WHERE ID IN (SELECT ID /*内层查询/子查询*/ FROM teaches WHERE semester = ’Fall’ and year= 2017 );
嵌套查询求解方法
不相关子查询:子查询的查询条件不依赖于父查询
- 由里向外逐层处理
- 即每个子查询在上一级查询处理之前求解,子查询的结果用于建立其夫查询的查找条件
相关子查询:子查询的查询条件依赖于父查询
- 首先取外层查询中表的第一个元组,根据它与内层查询相关的属性值处理内层查询,若WHERE子句返回值为真,则取此元组放入结果表.
- 然后再取外层表的下一个元组
- 重复这一过程,知道外层表全部检查完为止
子查询的位置
WHERE子句
通常用于集合的成员资格,集合的比较以及集合的基数进行检查
FROM子句
任何SELECT-FROM-WHERE表达式返回的结果都是关系,因而可以被插入到另一个SELECT-FROM-WHERE中任何关系可以出现的地方
SELECT,WHERE和HAVING子句
标量子查询返回包含单个属性的单个元组
集合成员资格
- SQL允许测试元组在关系中的成员资格
-
- 集合是由select子句产生的一组值构成的
- 连接词in测试元组是否是集合中的成员
- 连接词not in则测试元组是否不是集合中的成员
- 考虑查询:找出在2017年球季和2018年春季同时开设的所有课程的集合
-
- 交运算
- 自然连接
- in连接词
- 找出2018年春季开设的所有课程
(select course_id from section where semester = 'Spring' and year = 2018);
- 从子查询形成的课程集合中找出那些在2017年秋季开设的课程
select distinct course_id from section where semester = 'Fall' and year = 2017 and course_id in (select course_id from section where semester = 'Spring' and year = 2018);
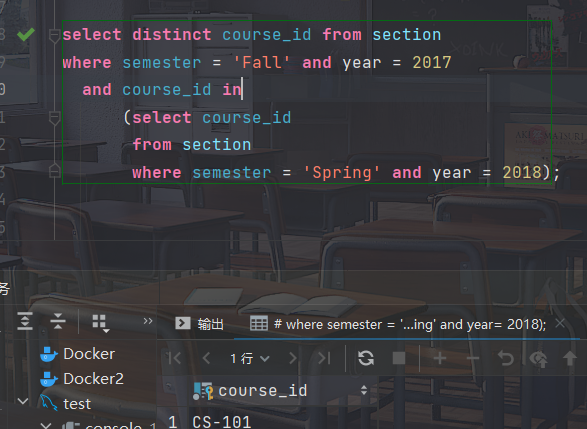
找出在2017年秋季学期开设但不在2018年春季学期
开设的所有课程
select distinct course_id from section where semester = ’Fall’ and year= 2017 and course_id not in (select course_id from section where semester = ’Spring’ and year= 2018);
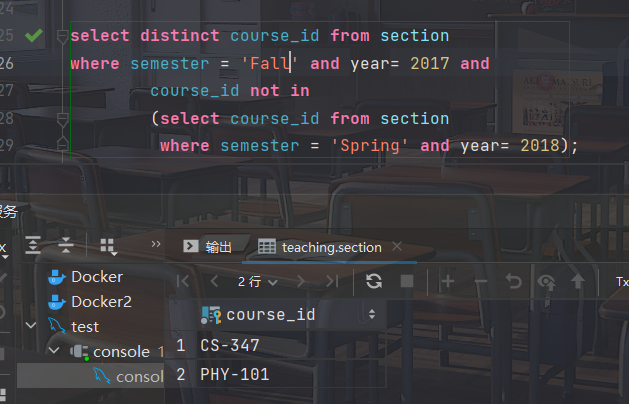
IN和NOT IN用于枚举集合
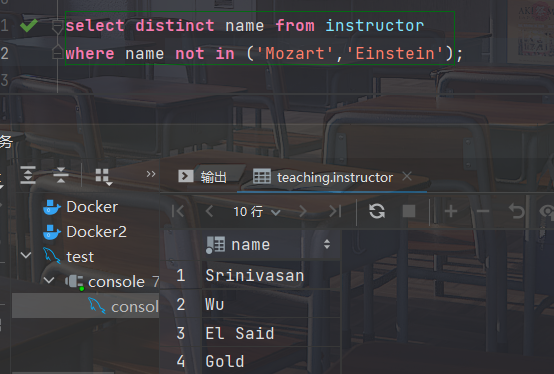
- 找出名字既不是"Mozart"也不是"Einstein"的教师姓名
select distinct name from instructor
where name not in ('Mozart','Einstein');
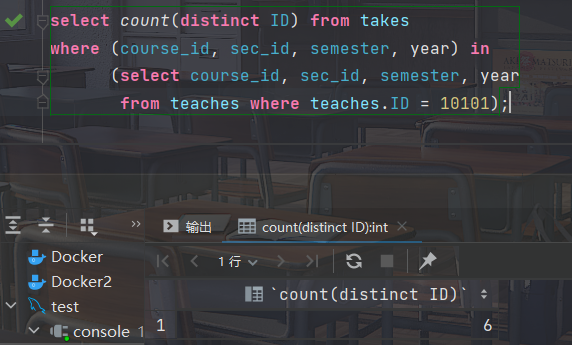
IN 和 NOT IN 用于多属性关系
- 找出学生总数,他们选修了ID为"10101"的教师所讲授的课程端
select count(distinct ID) from takes where (course_id, sec_id, semester, year) in (select course_id, sec_id, semester, year from teaches where teaches.ID = 10101);
集合的比较
- 考虑查询 "找出满足下面条件的所有教师的姓名,他们的工资至少比Biology系某一个教师的工资要高"
select distinct T.name from instructor as T, //这里创建两个关系,一个是所有的,一个是生物系的老师 instructor as S where T.salary > S.salary and S.dept_name = 'Biology';
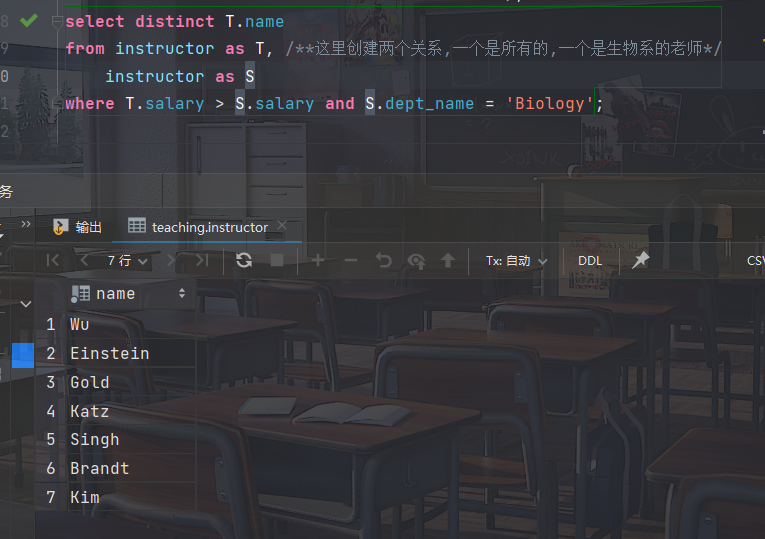
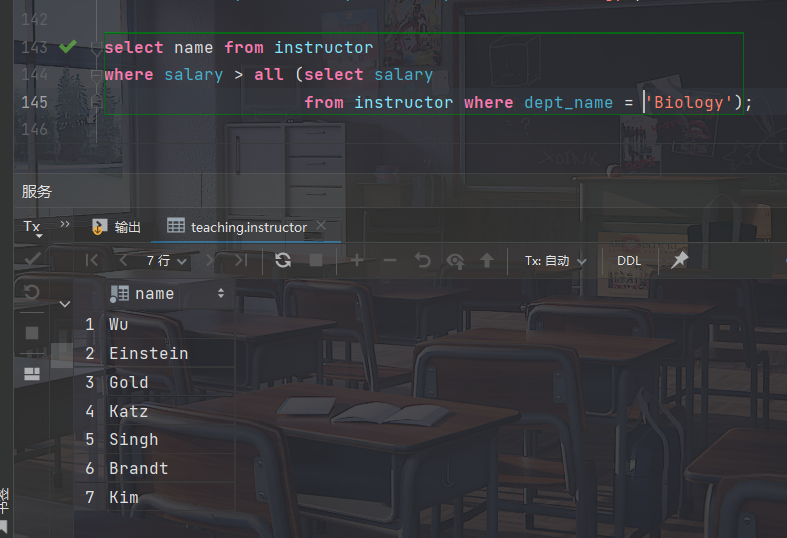
select name from instructor where salary > all (select salary from instructor where dept_name = ’Biology’);
找出平均工资最高的系
select dept_name from instructor group by dept_name having avg (salary) >= all (select avg(salary) from instructor group by dept_name);
集合比较
> SOME 大于子查询结果中的某个值
> ALL 大于子查询结果中的所有值
< SOME 小于子查询结果中的某个值
< ALL 小于子查询结果中的所有值
>= SOME 大于等于子查询结果中的某个值
>= ALL 大于等于子查询结果中的所有值
<= SOME 小于等于子查询结果中的某个值
<= ALL 小于等于子查询结果中的所有值
= SOME 等于子查询结果中的某个值
=ALL 等于子查询结果中的所有值(通常没有实际意义)
!=(或<>) SOME 不等于子查询结果中的某个值
!=(或<>) ALL 不等于子查询结果中的任何一个值
SOME ,ALL谓词与聚集函数,IN谓词的等价转换关系
= |
<>或!= |
< |
<= |
> |
>= |
|
SOME |
IN |
-- |
<MAX |
<=MAX |
>MIN |
>= MIN |
ALL |
-- |
NOT IN |
<MIN |
<= MIN |
>MAX |
>= MAX |
空关系测试
- 测试一个子查询的结果中是否存在元组
- EXISTS结构
-
- 带有EXISTS谓词的子查询不返回任何数据,只产生逻辑真值"true"或逻辑假值"false"
- 子查询非空时返回真值
- 由EXISTS引出的子查询,其目标列表达式通常都用*,因为带EXISTS的子查询只返回真值或假值,给出列名无实际意义
- NOT EXISTS结构
-
- 若子查询结果非空,则外层的WHERE子句返回价值
- 若子查询结果为空,则外层的WHERE子句返回真值
EXISTS
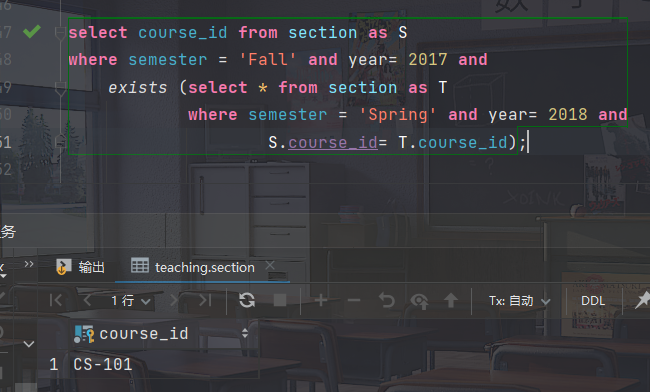
找出在2017年秋季学期和2018年春季学期同时开设的所有课程
select course_id from section as S where semester = 'Fall' and year= 2017 and exists (select * from section as T where semester = 'Spring' and year= 2018 and S.course_id= T.course_id);
- NOT EXISTS结构测试子查询结果是否不存在元组
- 使用NOT EXISTS结构模拟集合包含操作
-
- "关系A包含关系B”写成“NOT EXISTS (B except A)”
- 考虑查询:"找出选修了Biology系开设的所有课程的学生"
select distinct S.ID, S.name from student as S where not exists ((select course_id from course where dept_name = 'Biology') except /*上面是在生物系的课程id,下面是 全部课程都学的课程id*/ (select T.course_id from takes as T where S.ID = T.ID));
- UNIQUE用于测试一个子查询的结果中是否存在重复元组
- 如果作为参数的子查询结果中没有重复的元组, UNIQUE将返回true值;
- 如果作为参数的子查询结果中存在重复的元组, NOT UNIQUE将返回true值。
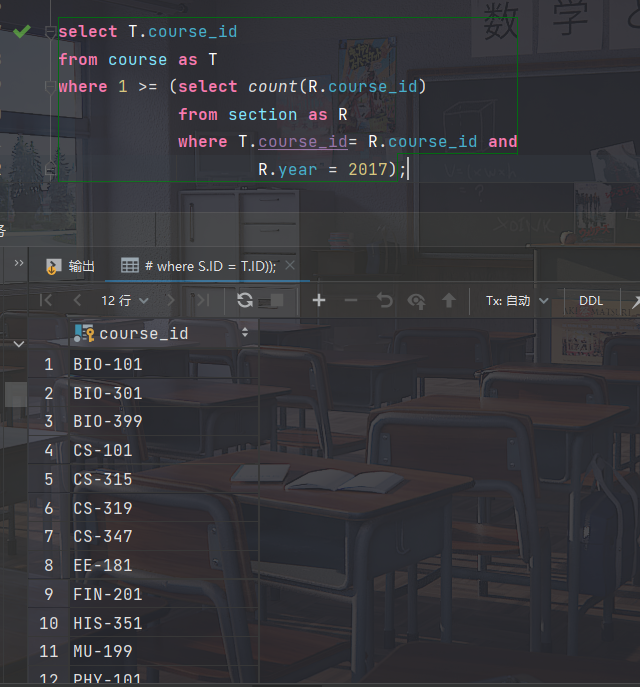
“找出所有在2017年最多开设一次的课程”
select T.course_id from course as T where 1 >= (select count(R.course_id) from section as R where T.course_id= R.course_id and R.year = 2017);
UNIQUE结构
“找出所有在2017年最多开设一次的课程”
select T.course_id from course as T where unique (select R.course_id from section as R where T.course_id= R.course_id and R.year = 2017);
NOT UNIQUE结构
找出所有在2017年最少开设两次的课程”
select T.course_id from course as T where not unique (select R.course_id from section as R where T.course_id= R.course_id and R.year = 2017);
FROM子句中的子查询
考虑查询 "找出系平均工资超过42000美元的那些系中教师的平均工资"
方法1 使用having子句
select dept_name, avg (salary) as avg_salary from instructor group by dept_name having avg (salary) > 42000;
方法2 在FROM子句中使用
select dept_name, avg_salary from (select dept_name, avg(salary) as avg_salary from instructor group by dept_name) as dept_avg where avg_salary > 42000;
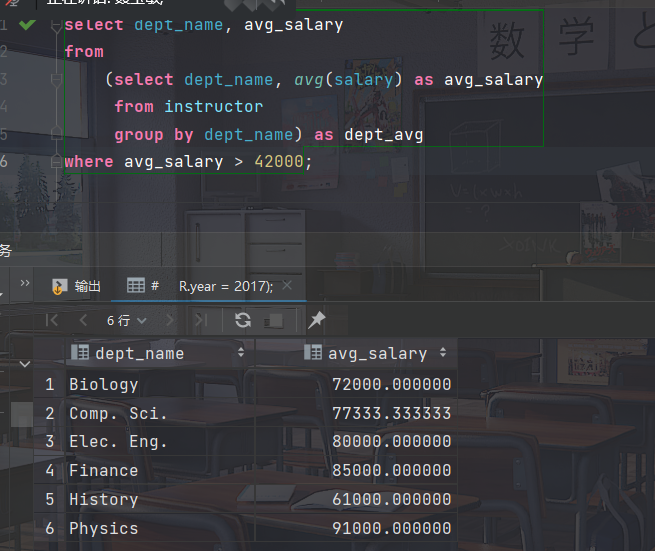
- MySQL要求对每一个子查询所得到的关系都给一个名字,即使该名字从不被使用。
- Oracle允许对子查询结果关系命名(省略关键字as),但是不允许对关系中的属性重命名。
- 找出在所有系中工资总额最大的系
select dept_name from (select dept_name,sum(salary) as sum_salary from instructor
group by dept_name) as total_dept1
where sum_salary = (select max(sum_salary) from
(select dept_name,sum(salary) as sum_salary from instructor
group by dept_name) as total_dept);
WITH子句
- WITH子句提供定义临时关系的方法
- 定义只对包含WITH子句的查询有效
- 考虑查询 "具有最大预算值的系"
with max_budget (value) as (select max(budget) from department) select department from department, max_budget where department.budget = max_budget.value;
with dept_total (dept_name, value) as (select dept_name, sum(salary) from instructor group by dept_name), dept_total_avg(value) as (select avg(value) from dept_total) select dept_name from dept_total, dept_total_avg where dept_total.value >= dept_total_avg.value;
标量子查询
SQL允许子查询出现在返回单个值的表达式能够出现的任何地方,只要该子查询只返回包含单个属性的单个元组。
这样的子查询叫做标量子查询
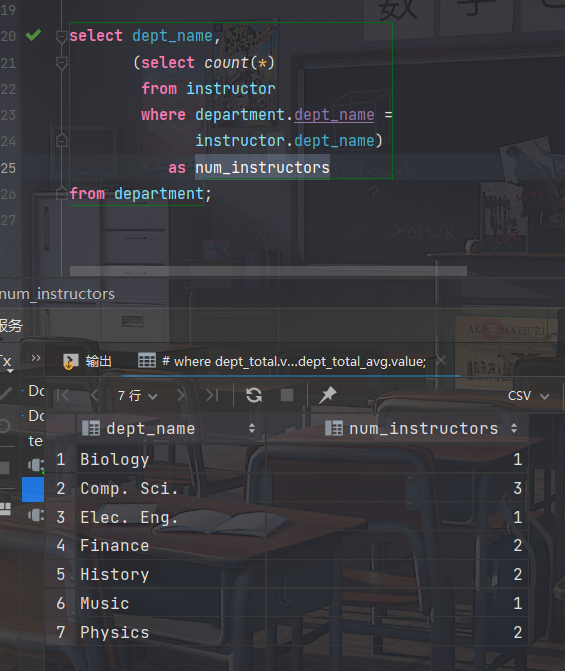
- 考虑查询:"列出所有的系以及他们拥有的教师数量"
select dept_name, (select count(*) from instructor where department.dept_name = instructor.dept_name) as num_instructors from department;
数据更新
插入数据
让Music系每个修满144学分的学生成为Music系的教师,其工资为18000美元
insert into instructor select ID, name, dept_name, 18000 from student where dept_name = 'Music' and tot_cred > 144;
对工资低于平均数的教师涨5%的工资
update instructor set salary = salary * 0.5 where salary < (select avg(salary) from instructor);
删除在Watson大楼工作的教师元组
delete from instructor where dept_name in ( select dept_name from department where building = 'Watson' );
删除工资低于大学平均工资的教书记录
delete from instructor where salary < (select avg(salary) from instructor);