前言
本文针对Python+Selenium爬取小说,帮助初学者理解其中逻辑与细节问题;同时,也是对自己学习的记录。
一、如何构建Python程序书写逻辑
请观察如下流程图,是否有些许灵感?
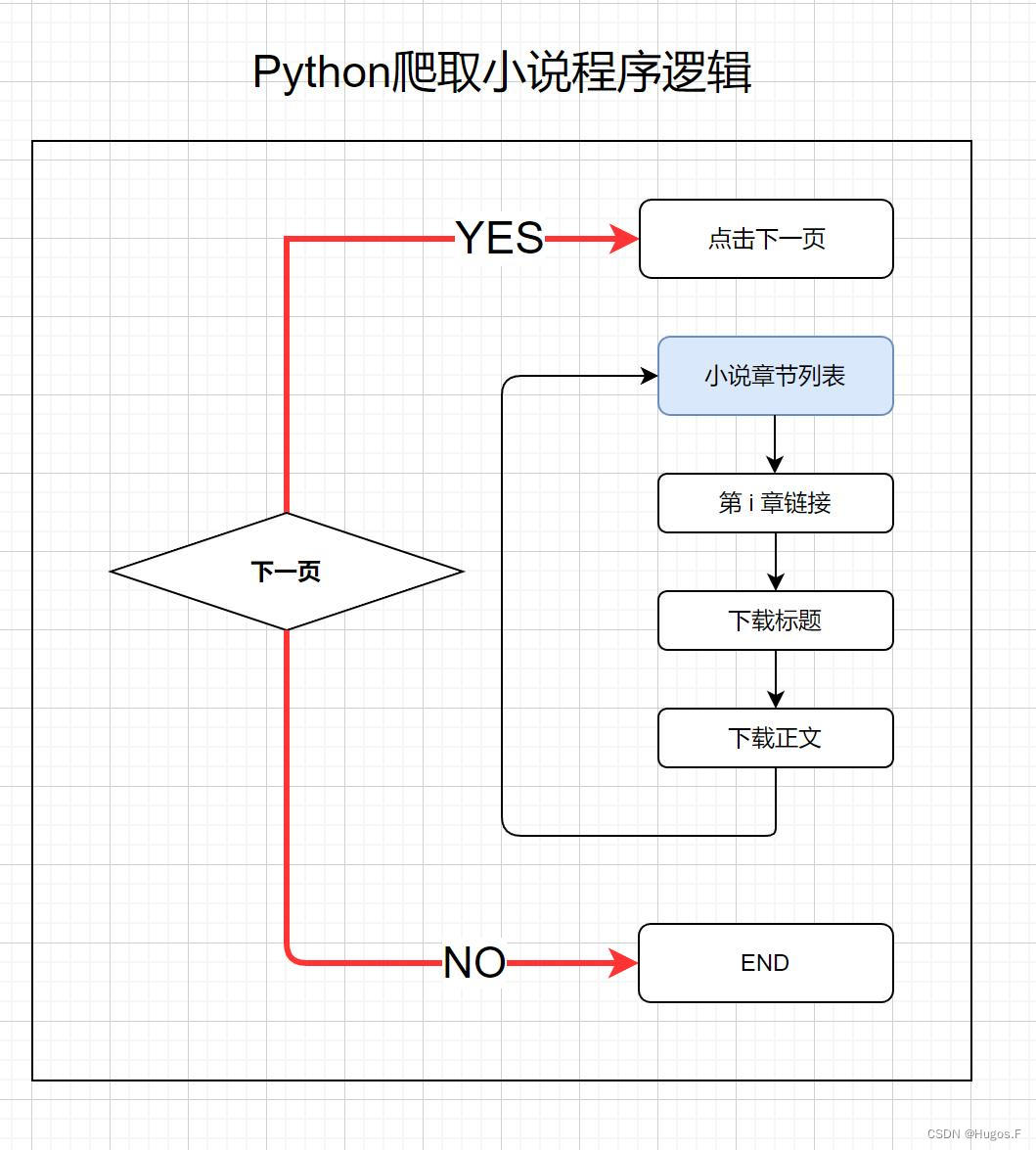
1. 起始页为小说章节列表,循环获取每一章节内容知识点:
- 进入网页:get(url)
- 定位元素:find_element(章节名、正文)、find_elements(每章节链接组成的多元素列表)
- 写入文件:with open("filename", "a") # 注意必须a追加写,w会覆盖
2. 判断返回列表目录之后,是否存在“下一页”提交框
- 定位方法:find_elements ----------------当列表为空时,程序不会报错
二、使用步骤
1.引入库
from selenium import webdriver
from selenium.webdriver.common.by import By2.代码开发
class Spider:
page_num = 0
def __init__(self):
self.driver = webdriver.Chrome()
def chapter_downloader(self, url):
"""
下载每一章节内容
Args:
url: 每章小说的网址
Returns:None
"""
self.driver.get(url)
ctitle = self.driver.find_element(By.CLASS_NAME, 'title').text
content = self.driver.find_element(By.CLASS_NAME, 'text').text
with open(f'e:/{self.novel_name}.txt', 'a') as c:
c.write(ctitle + '\n' + content)
def novel_downloader(self, link):
"""
下载小说
Args:
link: 小说的目录页
Returns:None
"""
self.driver.get(link)
self.novel_name = self.driver.find_element(By.TAG_NAME, 'h3').text
chapters = self.driver.find_elements(By.PARTIAL_LINK_TEXT, '章')
links = self.driver.find_elements(By.LINK_TEXT, '下一页')
if links:
next_page_url = links[0].get_attribute('href')
else:
next_page_url = ''
Spider.page_num += 1
print(f"开始下载第{Spider.page_num}页")
urls = [chapter.get_attribute('href') for chapter in chapters]
for url in urls:
self.chapter_downloader(url)
if next_page_url:
self.novel_downloader(next_page_url)2.传入实参
novel = Spider()
novel.novel_downloader("http://mosaic/mosaic/mosaic/mulu1.htm")具体测试网站不便展示,请自行拓展
总结
以上就是今天要讲的内容,本文仅仅使用创建类的办法爬取小说
本文含有隐藏内容,请 开通VIP 后查看