 这里有Coursera吴恩达《深度学习》课程的完整学习笔记,一共5门课:《神经网络和深度学习》、《改善深层神经网络》、《结构化机器学习项目》、《卷积神经网络》和《序列模型》,
这里有Coursera吴恩达《深度学习》课程的完整学习笔记,一共5门课:《神经网络和深度学习》、《改善深层神经网络》、《结构化机器学习项目》、《卷积神经网络》和《序列模型》,
第一门课:神经网络和深度学习基础,介绍一些基本概念。(四周)
第二门课:深度学习方面的实践,严密的构建神经网络,如何真正让它表现良好。超参数调整,正则化诊断偏差和方差,高级优化算法,如Momentum和Adam算法。(三周)
第三门课:学习如何结构化你的机器学习项目,构建机器学习系统的策略改变深度学习的错误,以及端对端深度学习。(两周)
第四门课:大名鼎鼎的卷积神经网络CNN,常应用于图像领域,介绍如何搭建这样的模型,包括卷积层,池化层和全连接层这些组件;经典模型(VGG、AlexNet和LeNet-5,以及ResNets和Inception系列)。(四周)
第五门课:序列模型,如何将它们应用于自然语言处理以及其他问题。系列模型包括的模型有循环神经网络RNN,长短期记忆网络LSTM模型,应用于序列数据NLP,或者语音识别或者编曲。(三周)
01 神经网络和深度学习(Neural Networks and Deep Learning)
1-1 深度学习概论
1-1 Coursera吴恩达《神经网络与深度学习》第一周课程笔记-深度学习概论
1-2 神经网络基础
1-2 Coursera吴恩达《神经网络与深度学习》第二周课程笔记-神经网络基础
1-3 浅层神经网络
1-3 Coursera吴恩达《神经网络与深度学习》第三周课程笔记-浅层神经网络
- 主要介绍:神经网络、激活函数、梯度下降法、反向传播、随机初始化等;
神经网络的基本结构,包括输入层(input layer),隐藏层(hidden layer)和输出层(output layer)。然后以简单的2层神经网络为例,详细推导了其正向传播过程和反向传播过程,使用梯度下降的方法优化神经网络参数。同时,我们还介绍了不同的激活函数,比较各自优缺点,讨论了激活函数必须是非线性的原因。最后介绍了神经网络参数随机初始化的必要性,特别是权重W,不同神经元的W不能初始化为同一零值。
1-4 深层神经网络
- 主要介绍:深度神经网络、DNN的前向和反向传播、参数和超参数等;
1-4 Coursera吴恩达《神经网络与深度学习》第四周课程笔记-深层神经网络
神经网络的层数是从左到右,由0开始定义
当我们算神经网络的层数时,我们不算输入层,只算隐藏层和输出层。
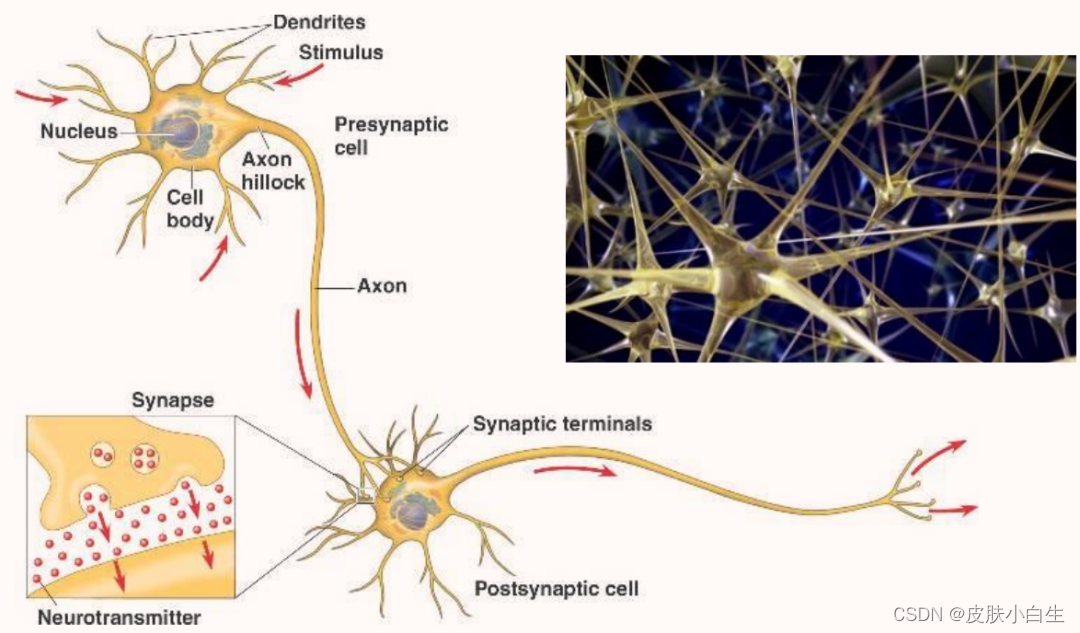
4.8这和大脑有什么关系》What does this have to do with the brain?
那么,神经网络跟人脑机制到底有什么联系呢?究竟有多少的相似程度?其实关联性不大。当你在实现一个神经网络的时候,那些公式是你在做的东西,你会做前向传播、反向传播、梯度下降法,其实很难表述这些公式具体做了什么,深度学习像大脑这样的类比其实是过度简化了我们的大脑具体在做什么,但因为这种形式很简洁,也能让普通人更愿意公开讨论,也方便新闻报道并且吸引大众眼球,但这个类比是非常不准确的。
一个神经网络的逻辑单元可以看成是对一个生物神经元的过度简化,但它是极其复杂的,单个神经元到底在做什么目前还没有人能够真正可以解释。这是值得生物学家探索的事情。
深度学习的确是个很好的工具来学习各种很灵活很复杂的函数,学习到从x到y的映射,在监督学习中学到输入到输出的映射。 .
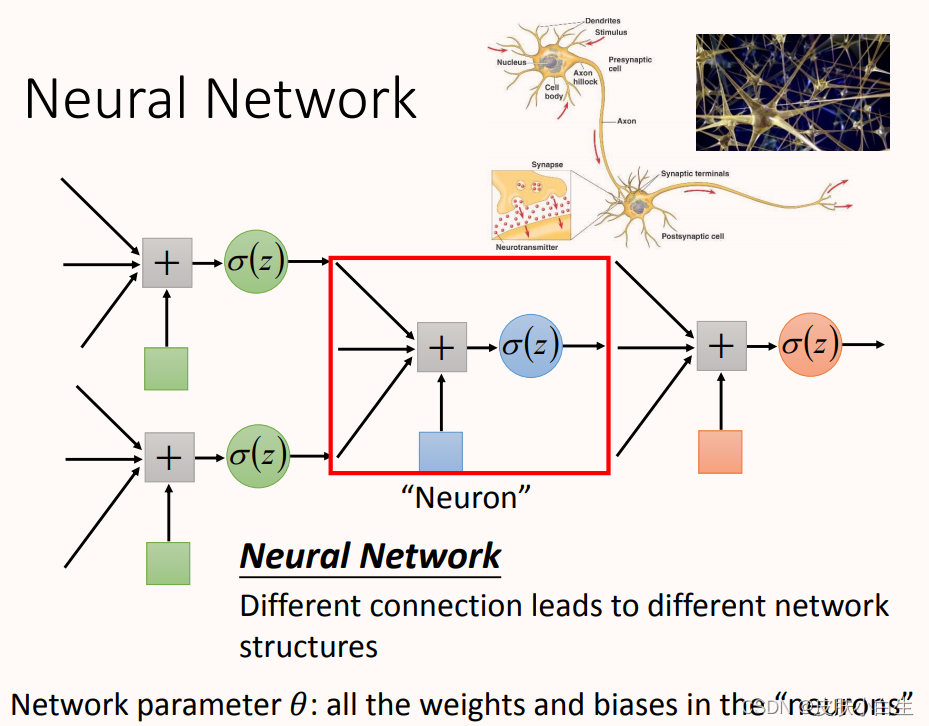
在这个神经网络里面,一个神经元就相当于一个逻辑回归函数,所以上图中有很多逻辑回归函数,其中每个逻辑回归都有自己的权重和自己的偏差,这些权重和偏差就是参数。
图中红框表示的就是神经元,多个神经元以不同的方式进行连接,就会构成不同结构神经网络。神经元的连接方式是由人工设计的。
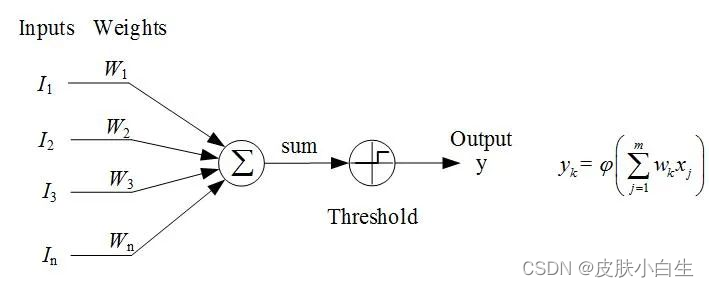
神经元:神经元的结构如图所示
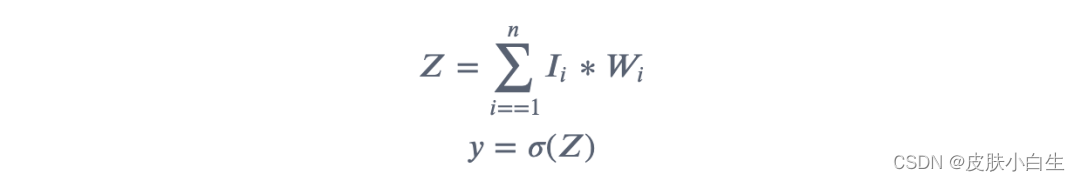
02 改善深层神经网络:超参数调试、正则化以及优化(Improving Deep Neural Networks: Hyperparameter tuning, Regularization and Optimization)
2-1 深度学习的实践方面
- 主要介绍:训练测试集划分、偏差和方差、正则化、Dropout、输入归一化、梯度消失与梯度爆炸、权重初始化、梯度检验等;
2-1 Coursera吴恩达《改善深度神经网络》 第一周课程笔记-深度学习的实践方面
防止过拟合的两种方法:正则化(如L2 regularization)和Dropout
2-2 优化算法
2-2 Coursera吴恩达《改善深度神经网络》第二周课程笔记-优化算法
主要介绍:Mini-batch梯度下降、指数加权平均、Momentum梯度下降、RMSprop、Adam优化算法、衰减学习率、局部最优等
对原始数据集进行分割,使用mini-batch 梯度下降算法,
三种常用的加速神经网络学习速度的三种算法:
动量梯度下降(Momentum)、
RMSprop
Adam算法。其中,Adam结合了动量梯度下降和RMSprop各自的优点,实际应用中表现更好。
另外一种提高学习速度的方法:学习率衰减(learning rate decay)
通过不断减小学习因子,减小步进长度,来减小梯度振荡。最后,我们对深度学习中局部最优(local optima)的概念作了更深入的解释。
2-3 超参数调试和Batch Norm及框架
2-3 Coursera吴恩达《改善深度神经网络》第三周课程笔记-超参数调试、Batch正则化和编程框架
TensorFlow的优点在于建立了计算图(computation graph),通过用这个计算损失,计算图基本实现前向传播,TensorFlow已经内置了所有必要的反向函数,回忆一下训练深度神经网络时的一组前向函数和一组反向函数,而像TensorFlow之类的编程框架已经内置了必要的反向函数,这也是为什么通过内置函数来计算前向函数,它也能自动用反向函数来实现反向传播,即便函数非常复杂,再帮你计算导数,这就是为什么你不需要明确实现反向传播,这是编程框架能帮你变得高效的原因之一。
Batch归一化,以及如何用它来加速神经网络的训练
03 结构化机器学习项目(Structuring Machine Learning Projects)
3-1 机器学习策略(1)
3-1 Coursera吴恩达《构建机器学习项目》 第一周课程笔记-机器学习策略(1)
查准率的定义是在你的分类器标记为猫的例子中,有多少真的是猫。
查全率定义就是,对于所有真猫的图片,你的分类器A正确识别出了多少百分比。实际为猫的图片中,有多少被系统识别出来?
想想学车的时候,一辆车有三个主要控制,第一是方向盘(steering),方向盘决定我们往左右偏多少,还有油门(acceleration)和刹车(braking)。就是这三个控制,其中一个控制方向,另外两个控制速度,这样就比较容易解读。知道不同控制的不同动作会对车子运动有什么影响。所以正交化的概念是指,可以想出一个维度,这个维度是控制转向角,还有另一个维度来控制速度,那么就需要一个旋钮尽量只控制转向角,另一个旋钮,在这个开车的例子里其实是油门和刹车控制了速度。
首先,你的算法对训练集的拟合很好,这可以看成是你能做到可避免偏差很低。还有第二件事你可以做好的是,在训练集中做得很好,然后推广到开发集和测试集也很好,这就是说方差不是太大。
练错误率和贝叶斯错误率的距离(可避免偏差)以及开发错误率和训练错误率的距离(方差)
解决可避免偏差的常用方法包括:
Train bigger model
Train longer/better optimization algorithms: momentum, RMSprop, Adam
NN architecture/hyperparameters search
解决方差的常用方法包括:
More data
Regularization: L2, dropout, data augmentation
NN architecture/hyperparameters search
3-2 机器学习策略(2)
3-2 Coursera吴恩达《构建机器学习项目》 第二周课程笔记-机器学习策略(2)
04 卷积神经网络(Convolutional Neural Networks)
4-1 卷积神经网络基础
4-1 Coursera吴恩达《卷积神经网络》 第一周课程笔记-卷积神经网络基础
卷积,padding,步长的概念,卷积层,池化层,全连接层这些组件
4-2 卷积神经网络实例模型
4-2 Coursera吴恩达《卷积神经网络》 第二周课程笔记-深度卷积模型:实例探究
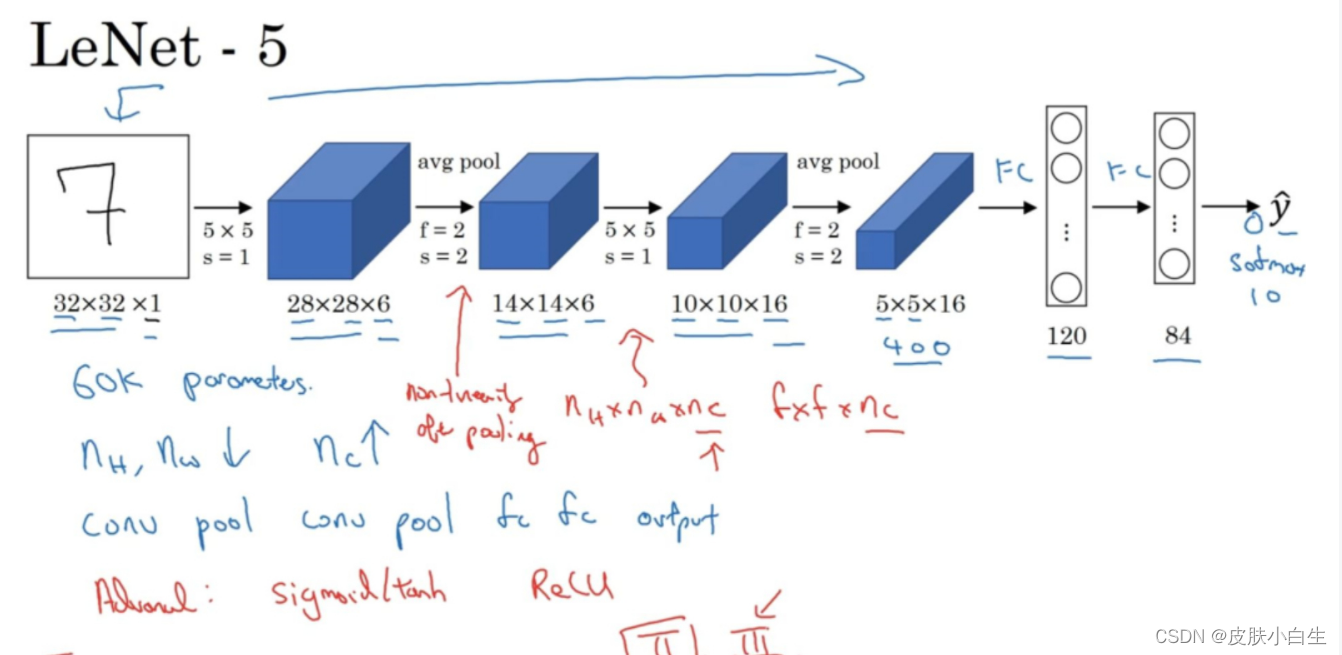
上图是LeNet-5的网络结构,假设有一张32×32×1的图片(输入),LeNet-5可以识别图中的手写数字,比如像这样手写数字7。LeNet-5是针对灰度图片训练的,所以图片的大小只有32×32×1。实际上LeNet-5的结构和我们上周讲的最后一个范例非常相似,使用6个5×5的过滤器,步幅为1。由于使用了6个过滤器,步幅为1,padding为0,输出结果为28×28×6,图像尺寸从32×32缩小到28×28。然后进行池化(pooling)操作,在这篇论文发布的那个年代,人们更喜欢使用平均池化,而现在我们可能用最大池化更多一些。在这个例子中,我们进行平均池化,过滤器的宽度为2,步幅为2,图像的尺寸,高度和宽度都缩小了2倍,输出结果是一个14×14×6的图像。这张图片应该不是完全按照比例绘制的,如果严格按照比例绘制,新图像的尺寸应该刚好是原图像的一半。
接下来是卷积层,用一组16个5×5的过滤器,新的输出结果有16个通道。LeNet-5的论文是在1998年撰写的,当时人们并不使用padding,或者总是使用valid卷积,这就是为什么每进行一次卷积,图像的高度和宽度都会缩小,所以这个图像从14到14缩小到了10×10。然后又是池化层,高度和宽度再缩小一半,输出一个5×5×16的图像。将所有数字相乘,乘积是400。
下一层是全连接层,在全连接层中,有400个节点,每个节点有120个神经元,这里已经有了一个全连接层。但有时还会从这400个节点中抽取一部分节点构建另一个全连接层,就像这样,有2个全连接层。
最后一步就是利用这84个特征得到最后的输出,我们还可以在这里再加一个节点用来预测y帽的值,y帽有10个可能的值(对应识别0-9这10个数字)。在现在的版本中则使用softmax函数输出十种分类结果,而在当时,LeNet-5网络在输出层使用了另外一种,现在已经很少用到的分类器。
相比现代版本,这里得到的神经网络会小一些,只有约6万个参数。而现在经常看到含有一千万(10 million)到一亿(100 million)个参数的神经网络,比这大1000倍的神经网络也不在少数。
不管怎样,如果我们从左往右看,随着网络越来越深,图像的高度和宽度在缩小,从最初的32×32缩小到28×28,再到14×14、10×10,最后只有5×5。与此同时,随着网络层次的加深,通道数量一直在增加,从1增加到6个,再到16个
①读到这篇经典论文时,你会发现,过去人们使用sigmoid函数和tanh函数,而不是ReLu函数,这篇论文中使用的正是sigmoid函数和tanh函数。这种网络结构的特别之处还在于,各网络层之间是有关联的,
②经典的LeNet-5网络使用了非常复杂的计算方式,每个过滤器都采用和输入模块一样的通道数量。论文中提到的这些复杂细节,现在一般都不用了。
 AlexNet首先用一张227×227×3的图片作为输入(实际上原文中使用的图像是224×224×3),但是如果你尝试去推导一下,你会发现227×227这个尺寸更好一些。第一层使用96个11×11的过滤器,步幅为4,因此尺寸缩小到55×55,缩小了4倍左右。然后用一个3×3的过滤器构建最大池化层,f = 3,步幅为2,卷积层尺寸缩小为27×27×96。接着再执行一个5×5的卷积,padding之后,输出是27×27×276。然后再次进行最大池化,尺寸缩小到13×13。再执行一次same卷积,相同的padding,得到的结果是13×13×384,384个过滤器。再做一次same卷积。再做一次同样的操作,最后再进行一次最大池化,尺寸缩小到6×6×256。6×6×256等于9216,将其展开为9216个单元,然后是一些全连接层。最后使用softmax函数输出识别的结果,看它究竟是1000个可能的对象中的哪一个。
AlexNet首先用一张227×227×3的图片作为输入(实际上原文中使用的图像是224×224×3),但是如果你尝试去推导一下,你会发现227×227这个尺寸更好一些。第一层使用96个11×11的过滤器,步幅为4,因此尺寸缩小到55×55,缩小了4倍左右。然后用一个3×3的过滤器构建最大池化层,f = 3,步幅为2,卷积层尺寸缩小为27×27×96。接着再执行一个5×5的卷积,padding之后,输出是27×27×276。然后再次进行最大池化,尺寸缩小到13×13。再执行一次same卷积,相同的padding,得到的结果是13×13×384,384个过滤器。再做一次same卷积。再做一次同样的操作,最后再进行一次最大池化,尺寸缩小到6×6×256。6×6×256等于9216,将其展开为9216个单元,然后是一些全连接层。最后使用softmax函数输出识别的结果,看它究竟是1000个可能的对象中的哪一个。
实际上,AlexNet神经网络与LeNet有很多相似之处,不过AlexNet要大得多。正如前面讲到的LeNet或LeNet-5大约有6万个参数,而AlexNet包含约6000万个参数。当用于训练图像和数据集时,AlexNet能够处理非常相似(pretty similar)的基本构造模块(basic building blocks),这些模块往往包含着大量的隐藏单元或数据,这一点AlexNet表现出色。AlexNet比LeNet表现更为出色的另一个原因是它使用了ReLu激活函数。
下面提一些比较深奥的内容,如果你并不打算阅读论文,不听也没有关系。(上图下方的红色笔记)(1)第一点,在写这篇论文的时候,GPU的处理速度还比较慢,所以AlexNet采用了非常复杂的方法在两个GPU上进行训练。大致原理是,这些层分别拆分到两个不同的GPU上,同时还专门有一个方法用于两个GPU进行交流。(2)论文还提到,经典的AlexNet结构还有“局部响应归一化层”(Local Response Normalization),即LRN层,这类层应用得并不多,所以Andrew并没有专门讲。局部响应归一层的基本思路(basic idea)是,假如这是网络的一块,比如是13×13×256,LRN要做的就是选取一个位置,从这个位置穿过整个通道,能得到256个数字,并进行归一化。进行局部响应归一化的动机是,对于这张13×13的图像中的每个位置来说,我们可能并不需要太多的高激活神经元(a very high activation)。后来,很多研究者发现LRN起不到太大作用,现在并不用LRN来训练网络。
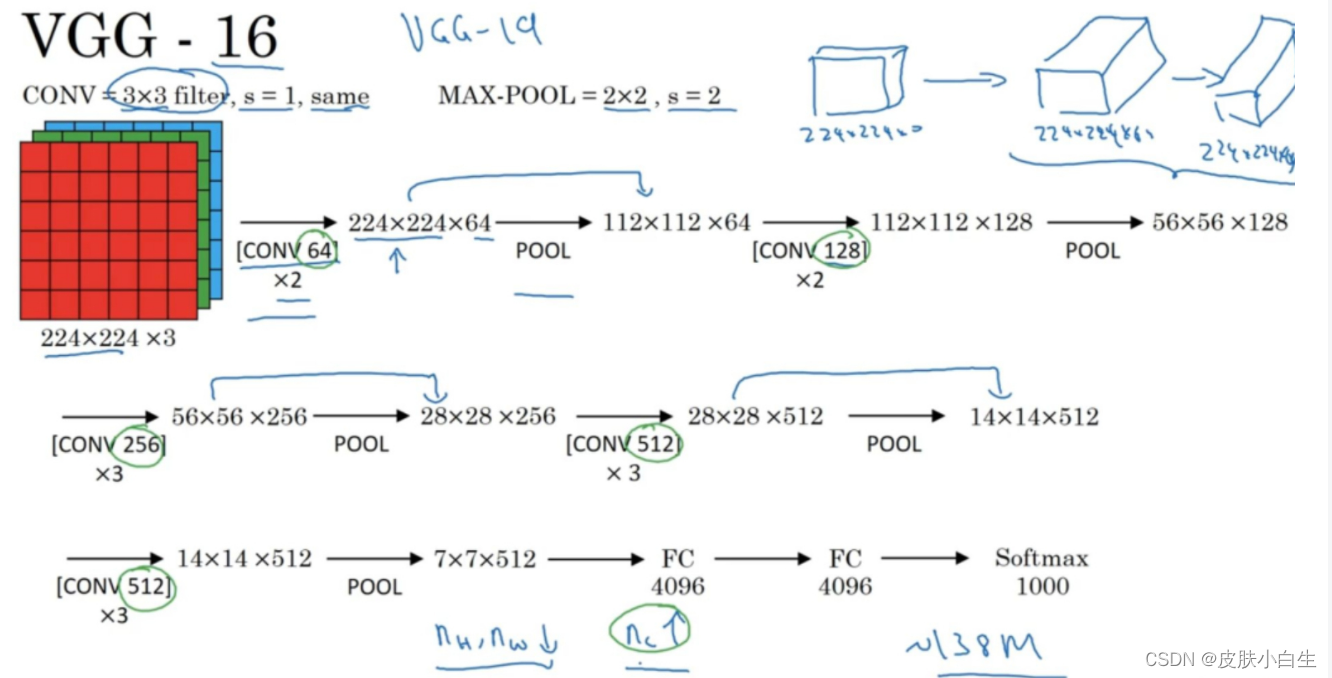
也叫作VGG-16网络。VGG-16网络没有那么多超参数,这是一种只需要专注于构建卷积层的简单网络。首先用3×3,步幅为1的过滤器构建卷积层,padding参数为same卷积中的参数。然后用一个2×2,步幅为2的过滤器构建最大池化层。因此VGG网络的一大优点是它确实简化了神经网络结构,下面具体看看这种网络结构。
假设要识别这个图像224×224×3,在最开始的两层用64个3×3的过滤器对输入图像进行卷积,输出结果是224×224×64,因为使用了same卷积,通道数量也一样。(注意这里没有画出所有的卷积层)进行第一个卷积之后得到224×224×64的特征图,接着还有一层224×224×64,得到这样2个厚度为64的卷积层,意味着我们用64个过滤器进行了两次卷积。接下来创建一个池化层,池化层将输入图像进行压缩,从224×224×64缩小到多少呢?没错,减少到112×112×64。然后又是若干个卷积层,使用129个过滤器,以及一些same卷积,我们看看输出什么结果,112×112×128。然后进行池化,可以推导出池化后的结果是这样(56×56×128)。接着再用256个相同的过滤器进行三次卷积操作,然后再池化,然后再卷积三次,再池化。如此进行几轮操作后,将最后得到的7×7×512的特征图进行全连接操作,得到4096个单元,然后进行softmax激活,输出从1000个对象中识别的结果。
VGG-16的16,就是指这个网络中包含16个卷积层和全连接层。确实是个很大的网络,总共包含约1.38亿个参数,即便以现在的标准来看都算是非常大的网络。但VGG-16的结构并不复杂,这点非常吸引人,而且这种网络结构很规整(quite uniform),都是几个卷积层后面跟着可以压缩图像大小的池化层,池化层缩小图像的高度和宽度。同时,卷积层的过滤器数量变化存在一定的规律,由64翻倍变成128,再到256和512。作者可能认为512已经足够大了,后面的层就不再翻倍了。无论如何,每一步都进行翻倍,或者说在每一组卷积层进行过滤器翻倍操作,正是设计此种网络结构的另一个简单原则(another simple principle)。这种相对一致的网络结构对研究者很有吸引力,而它的主要缺点(downside)是需要训练的特征数量非常巨大。
Andrew最喜欢它的一点是:随着网络的加深,图像的高度和宽度都在以一定的规律不断缩小,每次池化后刚好缩小一半,而通道数量在不断增加,而且刚好也是在每组卷积操作后增加一倍。图像缩小的比例和通道数增加的比例是有规律的。
2.3 残差网络(ResNets)》Residual Networks (ResNets)
非常非常深的神经网络是很难训练的,因为存在梯度消失和梯度爆炸问题。这节课我们学习跳跃连接(Skip connection),它可以从某一层网络层获取激活,然后迅速反馈给另外一层,甚至是神经网络的更深层。利用跳跃连接构建能够训练深度网络的ResNets,有时深度能够超过100层。ResNets是由残差块(Residual block)构建的,首先看一下什么是残差块。
假设使用标准优化算法(梯度下降法等)训练一个普通网络,如果没有残差,没有这些捷径或者跳跃连接,凭经验你会发现随着网络深度的加深,训练错误会先减少,然后增多。而理论上,随着网络深度的加深,应该训练得越来越好才对,网络深度越深模型效果越好。但实际上,如果没有残差网络,对于一个普通网络来说,深度越深意味着用优化算法越难训练,随着网络深度的加深,训练错误会越来越多。
但有了ResNets就不一样了,即使网络再深,训练的表现却不错,比如说训练误差减少,就算是训练深达100层的网络也不例外。对x的激活,或者这些中间的激活能够到达网络的更深层。这种方式有助于解决梯度消失和梯度爆炸问题,在训练更深网络的同时,又能保证良好的性能。
4-3目标检测
- 主要介绍:目标定位、目标检测、Bounding Box预测、交并比、非最大值抑制NMS、Anchor box、YOLO算法、候选区域region proposals等;
4-3 Coursera吴恩达《卷积神经网络》 第三周课程笔记-目标检测
4-4 特殊应用:人脸识别和神经风格迁移
- 主要介绍:人脸识别、one-shot学习、Siamese网络、Triplet损失、风格迁移、内容损失、风格损失、1D-3D卷积等;
4-4 Coursera吴恩达《卷积神经网络》 第四周课程笔记-特殊应用:人脸识别和神经风格转换
05 序列模型(Sequence Models)
5-1 循环神经网络
- 主要介绍:循环神经网络、不同类型的RNN、语言模型、新序列采样、RNN梯度消失、GRU、LSTM、双向RNN、深层RNNs等;
5-1 Coursera吴恩达《序列模型》 第一周课程笔记-循环序列网络(RNN)
5-2 自然语言处理和词嵌入
- 主要介绍:词汇表征、Word Embedding、嵌入矩阵、Word2Vec、负采样、GloVe词向量、情感分类、词嵌入消除偏见等;
5-2 Coursera吴恩达《序列模型》 第二周课程笔记-自然语言处理和词嵌入
5-3 序列模型和注意力机制
- 主要介绍:序列到序列模型、集束搜索(Beam search)、集束搜索误差分析、Bleu得分、注意力模型、注意力权重、语音识别、触发字检测等;
5-3 Coursera吴恩达《序列模型》 第三周课程笔记-序列模型和注意力机制
06 人工智能大师访谈
【人工智能行业大师访谈1】吴恩达采访 Geoffery Hinton
【人工智能行业大师访谈2】吴恩达采访 Pieter Abbeel
【人工智能行业大师访谈3】吴恩达采访 Ian Goodfellow
【人工智能行业大师访谈4】吴恩达采访Yoshua Bengio
【人工智能行业大师访谈5】吴恩达采访林元庆
【人工智能行业大师访谈6】吴恩达采访 Andrej Karpathy
【人工智能行业大师访谈7】吴恩达采访 Ruslan Salakhutdinov