我之前发过一篇基于孪生网络的人脸对比的文章,这篇文章也到了百度的推荐位置:
但是,效果并不是很好。经过大量的搜索,我发现了一种新的方法,可以非常好的实现人脸对比。
原理分析
我们先训练一个普通的人脸分类模型,这个人脸分类模型可以认为是这样的:
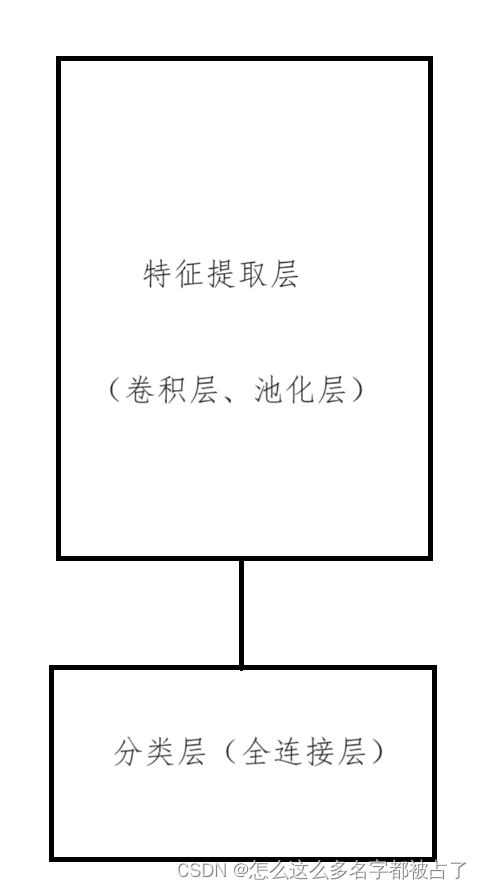
因此,在训练完分类模型后,只需要去掉底下的分类层(在模型中一般是全连接层),只看特征提取层的输出的相似程度即可。
如何比较两个输出的相似度呢?其实,这两个输出都是向量,因此我们可以采用两向量之间的夹角判断相似度。这个方法甚至在高中的信息技术课本里就有提到:

课本中是使用这种方法进行自然语言处理的,我们也可以使用这种方法进行人脸对比。其实就是根据两向量的乘积等于两向量的长度乘上两向量之间夹角的余弦值。
在paddle中,提供了专门的函数计算这个相似度:
import paddle.nn.functional as F
cosine_similarity = F.cosine_similarity(vec1, vec2) 注意,这里的vec1、vec2都应该是paddle的张量类型,可以使用paddle.to_tensor()函数转换为张量类型。
数据集加载
我们可以按照正常的图片分类的方式加载图片,我采用这个开源的数据集:
人脸数据_数据集-飞桨AI Studio星河社区 (baidu.com)
代码如下:
import numpy as np
from PIL import Image
import paddle
from random import shuffle
import pickle
class FaceData(paddle.io.Dataset):
def __init__(self, mode):
super().__init__()
# 训练集/测试集
file = 'facecap/facecap/train_list.txt' if mode == 'train' else 'facecap/facecap/test_list.txt'
self.imgs = []
self.labels = []
with open(file) as f:
# 读取数据集文件信息数据并洗牌
lines = f.readlines()
shuffle(lines)
print('read down')
# 加载数据集
for line in lines:
line = line.strip()
img, label = line.split(' ')
pil_img = Image.open(f'facecap\\facecap\\{img}').convert('RGB').resize((96, 96))
self.imgs.append(np.array(pil_img).transpose((2, 0, 1)))
self.labels.append(label)
self.imgs = np.array(self.imgs, dtype=np.float32)
self.labels = np.array(self.labels, dtype=np.int32)
print('load down')
def __getitem__(self, idx):
return self.imgs[idx], self.labels[idx]
def __len__(self):
return len(self.labels)
if __name__ == '__main__':
train_dataset = FaceData(mode='train')
test_dataset = FaceData(mode='test')
pickle.dump(train_dataset, open('./database/train.data', 'wb'), protocol=4)
pickle.dump(test_dataset, open('./database/test.data', 'wb'), protocol=4)
脚本采用pickle存储加载后的数据集,方便使用。
训练脚本
训练脚本非常简单,我们采用resnet模型,如下:
import paddle
from dataset import FaceData
import pickle
paddle.set_device('gpu')
train_dataset = pickle.load(open('./database/train.data', 'rb'))
test_dataset = pickle.load(open('./database/test.data', 'rb'))
net = paddle.vision.resnet18(num_classes=500)
model = paddle.Model(net)
model.load('./output/model')
model.prepare(
paddle.optimizer.Adam(parameters=model.parameters()),
paddle.nn.CrossEntropyLoss(),
paddle.metric.Accuracy()
)
model.fit(train_dataset, epochs=20, batch_size=64, verbose=1, save_dir='./cache/model')
model.evaluate(test_dataset, batch_size=64, verbose=1)
model.save('./output/model')
推理脚本
推理脚本需要注意去除最后的全连接层,代码如下:
import paddle
from dataset import FaceData
import numpy as np
import paddle.nn.functional as F
state_dict = paddle.load('./output/model.pdparams')
old_net = paddle.vision.resnet18(num_classes=500)
old_net.load_dict(state_dict)
new_layers = list(old_net.children())[:-1] # 移除全连接层
net = paddle.nn.Sequential(*new_layers)
model = paddle.Model(net)
def predict(img1, img2):
"""
推理两张图片的相似度
:param img1: 第一张图片的PIL数据
:param img2: 第二张图片的PIL数据
:return: 相似度,属于区间[0, 1]。越大越相似
"""
d1 = np.array(img1, dtype=np.float32).transpose((2, 0, 1))
d2 = np.array(img2, dtype=np.float32).transpose((2, 0, 1))
p1 = model.predict_batch(np.expand_dims(d1, axis=0))[0]
p2 = model.predict_batch(np.expand_dims(d2, axis=0))[0]
t1 = paddle.to_tensor(p1)
t2 = paddle.to_tensor(p2)
return float(F.cosine_similarity(t1, t2)[0][0][0])
测试
采用网上的图片进行一次测试,结果也非常的好,相同的人脸相似度为0.9,不同的人脸为0.8。实际应用中,可以将当前人脸与数据库中的所有人脸进行对比,确定当前人脸
参考
使用PaddlePaddle实现人脸对比和人脸识别_paddle 人脸识别-CSDN博客
教育科学出版社 高中教材 信息技术 选择性必修4