目录
Flume概述
Flume 1.9.0 User Guide — Apache Flume
Flume 是Cloudera 提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传
输的系统。Flume 基于流式架构,灵活简单。
Flume最主要的作用就是,实时读取服务器本地磁盘的数据,将数据写入到HDFS。
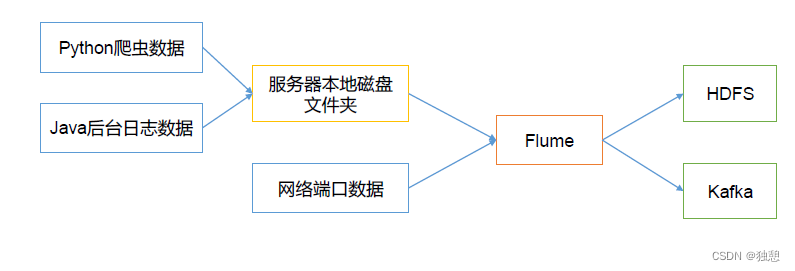
Flume架构
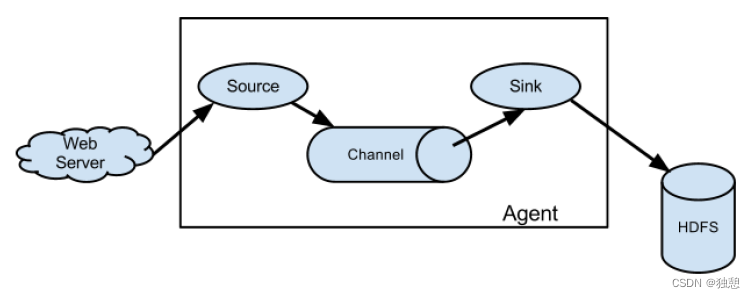
Agent
Agent是一个 JVM 进程,它以事件的形式将数据从源头送至目的。
Agent主要有 3 个部分组成, Source 、 Channel 、 SinkSource
Source是负责接收数据到 Flume Agent 的组件。 Source 组件可以处理各种类型、各种
格式的日志数据,包括 avro 、 thrift 、 exec 、 jms 、 spooling directory 、 netcat 、 taildir 、sequence generator 、 syslog 、 http 、 legacy 。
Sink
Sink不断地轮询 Channel 中的事件且批量地移除它们,并将这些事件批量写入到存储
或索引系统、或者被发送到另一个 Flume Agent 。
Sink组件目的地包括 hdfs 、 logger 、 avro 、 thrift 、 ipc 、 file 、 HBase 、 solr 、自定义。
Channel
Channel是位于 Source 和 Sink 之间的缓冲区。因此, Channel 允许 Source 和 Sink 运作在不同的速率上。 Channel 是线程安全的,可以同时处理几个 Source 的写入操作和几个Sink 的读取操作。Flume 自带两种 Channel Memory Channel 和 File Channel 。
Memory Channel是内存中的队列。 Memory Channel 在不需要关心数据丢失的情景下适用。如果需要关心数据丢失,那么 Memory Channel 就不应该使用,因为程序死亡、机器宕机或者重启都会导致数据丢失。
File Channel将所有事件写到磁盘。因此在程序关闭或机器宕机的情况下不会丢失数
据。Event
传输单元,Flume 数据传输的基本单元,以 Event 的形式将数据从源头送至目的地。
Event 由 Header 和 Body 两部分组成, Header 用来存放该 event 的一些属性,为 K V 结构,Body 用来存放该条数据,形式为字节数组。

Flume案例
入门案例
使用Flume 监听一个端口, 收集该端口数据 ,并打印到控制台。
也就是在本地模拟一个客户端,向本机的端口发送数据
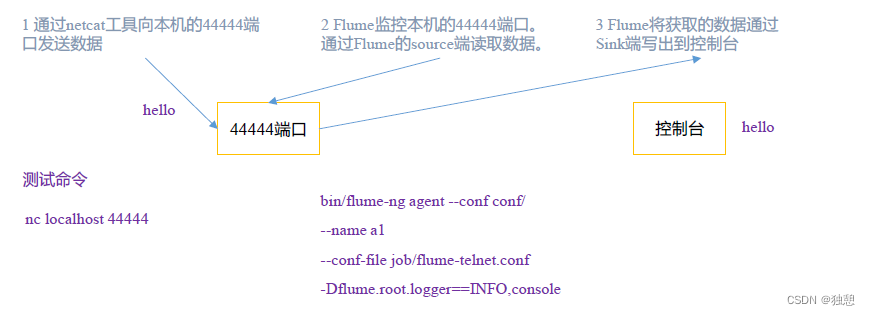
配置文件 job/flume-netcat-logger.conf
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1

开启flume监听端口
bin/flume-ng agent -c conf/ -n a1 -f job/flume-netcat-logger.conf -Dflume.root.logger=INFO,console
再在另外一个shell端开启netcat作为客户端
nc localhost 44444于是两端就能通讯了,在flume这边:
2024-04-14 10:41:13,221 (SinkRunner-PollingRunner-DefaultSinkProcessor)
[INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)]
Event: { headers:{} body: 6F 6B ok }
实时监控单个追加文件
实时监控Hive 日志,并上传到HDFS 中

配置
# Name the components on this agent
a2.sources = r2
a2.sinks = k2
a2.channels = c2
# Describe/configure the source
a2.sources.r2.type = exec
a2.sources.r2.command = tail -F /export/server/hive/logs/hive.log
# Describe the sink
a2.sinks.k2.type = hdfs
a2.sinks.k2.hdfs.path = hdfs://hadoop102:8020/flume/%Y%m%d/%H
上传文件的前缀
a2.sinks.k2.hdfs.filePrefix = logs
是否按照时间滚动文件夹
a2.sinks.k2.hdfs.round = true
多少时间单位创建一个新的文件夹
a2.sinks.k2.hdfs.roundValue = 1
重新定义时间单位
a2.sinks.k2.hdfs.roundUnit = hour
是否使用本地时间戳
a2.sinks.k2.hdfs.useLocalTimeStamp = true
积攒多少个 Event 才 flush 到 HDFS 一次
a2.sin ks.k2.hdfs.batchSize = 100
设置文件类型,可支持压缩
a2.sinks.k2.hdfs.fileType = DataStream
多久生成一个新的文件
a2.sinks.k2.hdfs.rollInterval = 60
设置每个文件的滚动大小
a2.sinks.k2.hdfs.rollSize = 134217700
文件的滚动与 Event 数量无关
a2.sinks.k2.hdfs.rollCount = 0
# Use a channel which buffers events in memory
a2.channels.c2.type = memory
a2.channels.c2.capacity = 1000
a2.channels.c2.transactionCapacity = 10 0
# Bind the source and sink to the channel
a2.sources.r2.channels = c2
a2.sinks.k2.channel = c2然后启动flume,这里其实就是将hive的日志读到hdfs的flume文件夹中
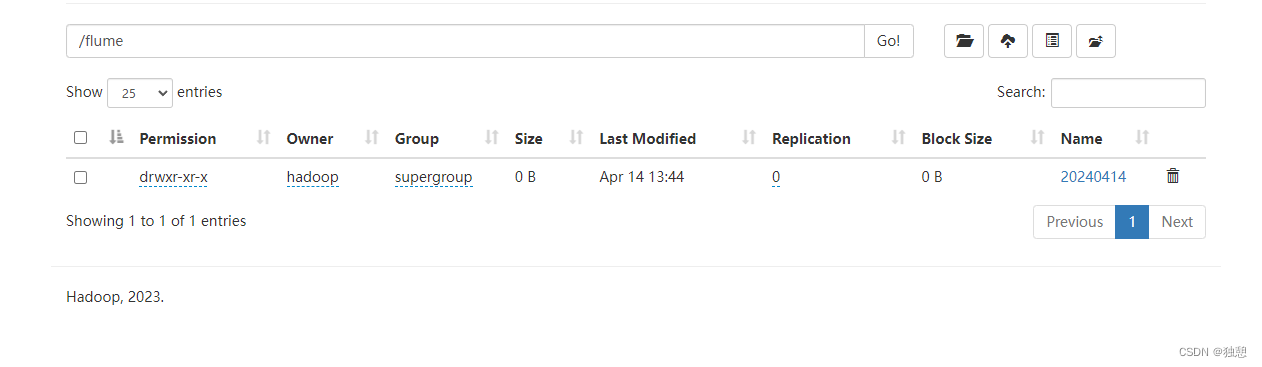


可以看到flume按照flume/%Y%m%d/%H/logs-xxx 的 顺序生成文件
这里是有一些问题的,当某时刻我的flume突然停止运行,再重新启动时,会在hdfs自动生成一个文件,尽管在这个时间内日志根本就没有变化。不能 断电续传
实时监控目录下多个新文件
使用Flume 监听整个目录的文件,并上传至HDFS

其实只是更改了一些配置项:
# Describe/configure the source
a3.sources.r3.type = spooldir
a3.sources.r3.spoolDir = /opt/module/flume/upload
a3.sources.r3.fileSuffix = .COMPLETED
a3.sources.r3.fileHeader = true
#忽略所有以.tmp 结尾的文件,不上传
a3.sources.r3.ignorePattern = ([^ ]*\.tmp)也就是说当一个文件传到upload,flume会自己给它打上 COMPLETED标签,证明其已经被上传
可以自己设定不需要上传的文件的正则或者需要上传的文件的正则
注意事项:
1、上传文件不要上传xx.COMPLETED文件,也就是说这个标签不要自己打,否则无效
2、文件不要重名,比如已经存在了一个1.txt.COMPLETED,此时若再传入一个1.txt,会因为无法再次生成一个1.txt.COMPLETED而上传失败
3、uplaod中的文件不要动态修改,新修改的东西无法上传
实时监控目录下的多个追加文件
Exec source 适用于监控一个实时追加的文件,不能实现断点续传;
Spooldir Source适合用于同步新文件,但不适合对实时追加日志的文件进行监听并同步;
而Taildir Source适合用于监听多个实时追加的文件(来自于不同的目录),并且能够实现断点续传。
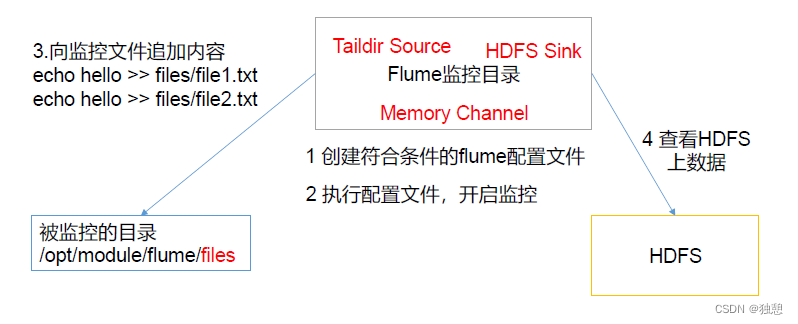
a3.sources.r3.type = TAILDIR
a3.sources.r3.positionFile = /export/server/flume/tail_dir.json
a3.sources.r3.filegroups = f1 f2
a3.sources.r3.filegroups.f1 = /export/server/flume/files/.*file.*
a3.sources.r3.filegroups.f2 = /export/server/flume/files2/.*log.*
# Describe the sink
a3.sinks.k3.type = hdfs
a3.sinks.k3.hdfs.path =hdfs://node1:8020/flume/upload2/%Y%m%d/%H这里可以监控 files文件夹下带有file的文件,和files文件夹下带有log的文件
且会将每个保存文件的保存进度(也就是已经保存到了哪一行)放在json文件中的
json:
[{"inode":58474783,"pos":6,"file":"/export/server/flume/files/file1.txt"},{"inode":8935483,"pos":14,"file":"/export/server/flume/files2/log.txt"}]这里有三个变量:
inode:每个linux文件的唯一标识
pos:当前文件已经被保存到了什么位置
file:文件的绝对路径
当改变文件的inode(删除文件)或者file(文件改名)都会造成重新上传
但是这里存在一个严重的问题:
许多日志系统会在某个时间更新日志文件,例如在每天23:59分将日志 hive.log 更名为 hive.log.2024-01-01(为了防止日志文件过大),然后生成新的hive.log
在这种情况下,flume又会将hive.log.2024-01-01重新上传,而这部分其实在之前已经上传过了,造成了资源的浪费
解决方式也很简单,只需要现在flume,在文件改名的时候不重新上传就行了,因为此时文件的inode是不会改变的
这里需要修改源码,在flume/source/taildir下面:
在TailFile.java文件中,这个函数定义了 写 文件的要求,将条件改为只看inode是不是相等
public boolean updatePos(String path, long inode, long pos) throws IOException {
// if (this.inode == inode && this.path.equals(path))
if (this.inode == inode) {
setPos(pos);
updateFilePos(pos);
logger.info("Updated position, file: " + path + ", inode: " + inode + ", pos: " + pos);
return true;
}
return false;
}
在ReliableTaildirEventReader.java文件下找到updateTailFiles,这里定义了读文件的条件,也是改变条件:
//if (tf == null || !tf.getPath().equals(f.getAbsolutePath())) {
//atguigu
if (tf == null) {
long startPos = skipToEnd ? f.length() : 0;
tf = openFile(f, headers, inode, startPos);
} else {
boolean updated = tf.getLastUpdated() < f.lastModified() || tf.getPos() != f.length();
if (updated) {
if (tf.getRaf() == null) {
tf = openFile(f, headers, inode, tf.getPos());
}
if (f.length() < tf.getPos()) {
logger.info("Pos " + tf.getPos() + " is larger than file size! "
+ "Restarting from pos 0, file: " + tf.getPath() + ", inode: " + inode);
tf.updatePos(tf.getPath(), inode, 0);
}
}
tf.setNeedTail(updated);
}Flume事务
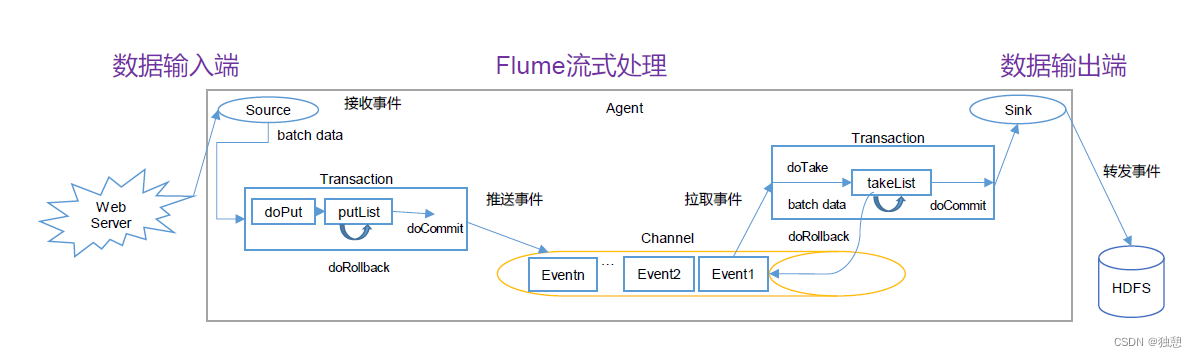
Put事务流程
•doPut:将批数据先写入临时缓冲区putList
•doCommit:检查channel内存队列是否足够合并。
•doRollback:channel内存队列空间不足,回滚数据到SourceTake事务
•doTake:将数据取到临时缓冲区takeList,并将数据发送到HDFS
•doCommit:如果数据全部发送成功,则清除临时缓冲区takeList
•doRollback:数据发送过程中如果出现异常,rollback将临时缓冲区takeList中的数据归还给channel内存队列。
Flume内部原理
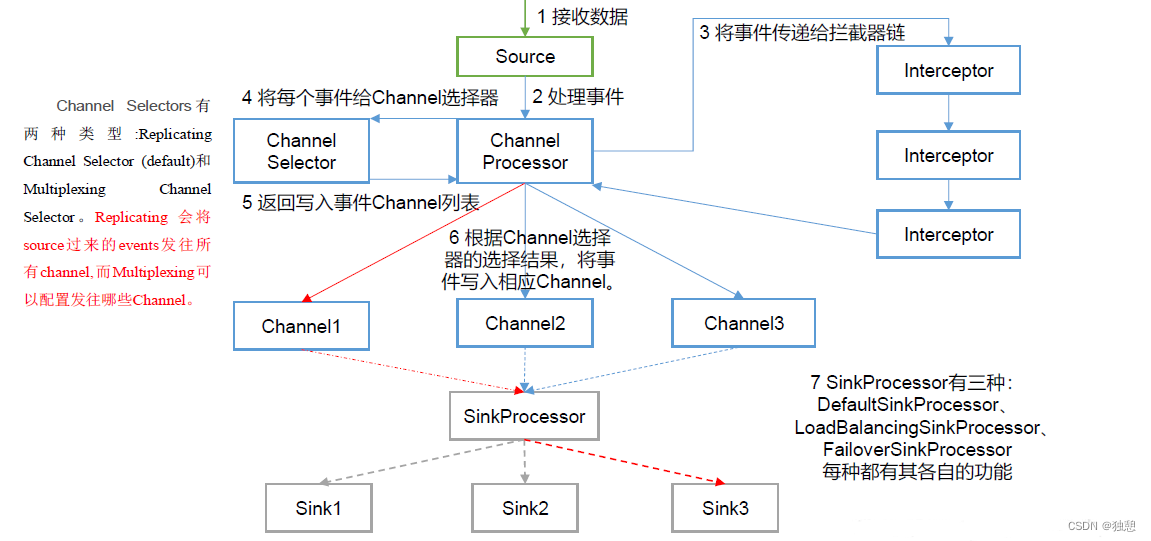
Sorce ->> Channel
当Source对应了多个Channel时,在发送数据时需要定义策略,也就是哪些文件发往哪些channel.
1、首先Source将数据发往 Channel Processor ,其会将事件传递给拦截器链,这些拦截器会定义一些操作,可以过滤数据,也可以对数据进行处理(例如手动添加时间戳)
2、然后Channel Processor将每个事件发给 Channel选择器,ChannelSelector 的作用就是选出Event 将要被发往哪个Channel。其共有两种类型,分别是Replicating(复制)和Multiplexing(多路复用):
ReplicatingSelector 会将同一个Event 发往所有的ChannelMultiplexing 会根据相应的原则,将不同的Event 发往不同的Channel。
Channel ->> Sink
SinkProcessor 共有三种类型, 分别是DefaultSinkProcessor LoadBalancingSinkProcessor 和FailoverSinkProcessor
DefaultSinkProcessor 对应的是单个的Sink ,也就是一个channel只能对应一个sinkLoadBalancingSinkProcessor 可以实现负载均衡的功能,也就是所有sink轮流读取
FailoverSinkProcessor 可以错误恢复的功能。这里会配置sink的优先级,首先优先级最高的sink读取,当这个sink失效之后再由下一个优先级的sink读取
Flume拓扑结构
复制和多路复用
在sink和source之间用 avro 组件 进行连接
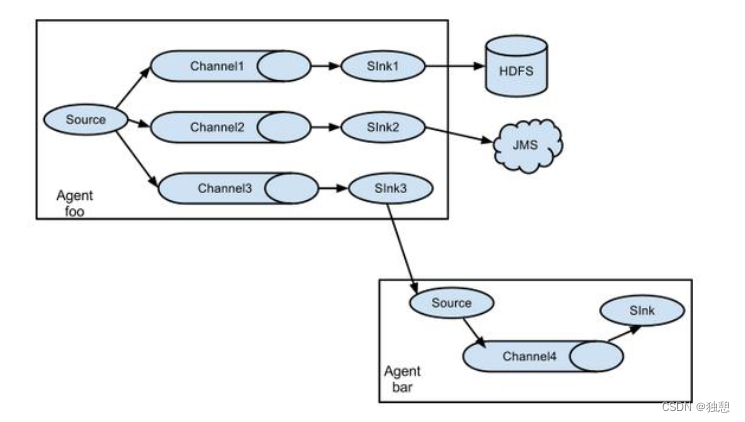
负载均衡和故障转移
取决于第一个agent中的SinkProcessor策略
当数据量很大的时候,多个agent实现负载均衡,原理是多个channel的缓冲效果更好,能及时的将大文件写入hdfs
当数据很重要的时候,多个agent实现故障转移,在当前agent故障时有别的agent补上
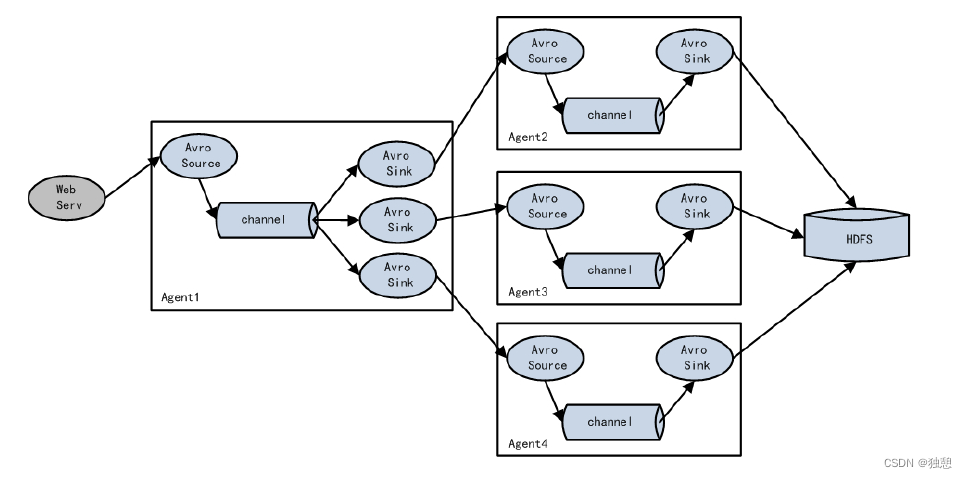
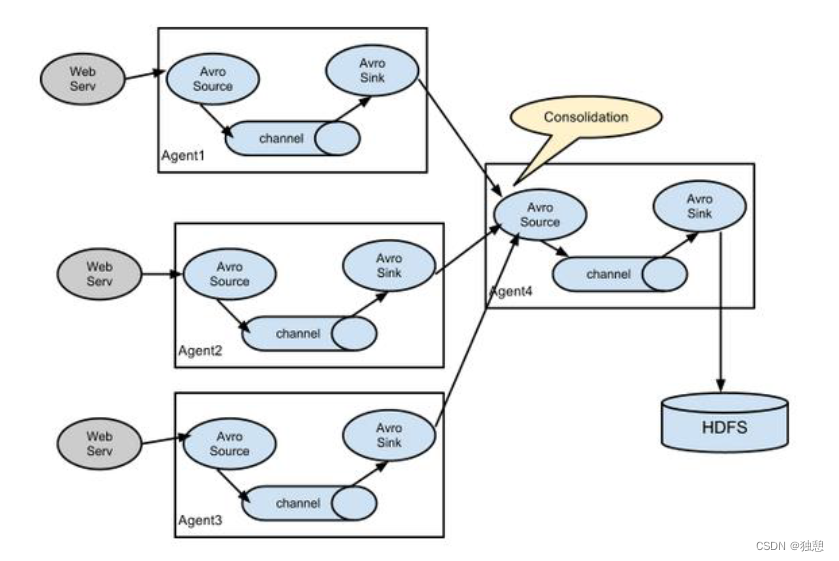
聚合
用的最多,适用于多服务器场景
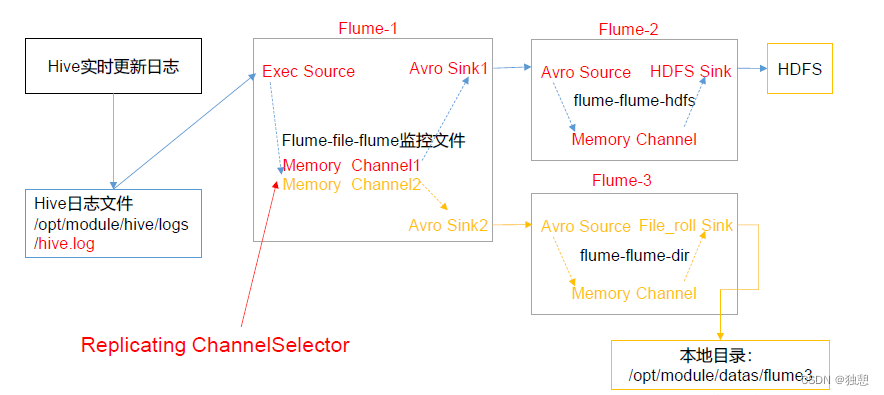
Flume综合案例
复制和多路复用案例
定义flume-1:
# Name the components on this agent
a1.sources = r1
a1.sinks = k1 k2
a1.channels = c1 c2
# 将数据流复制给所有 channel
a1.sources.r1.selector.type = replicating
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /export/server/hive/logs/hive.log
a1.sources.r1.shell = /bin/bash c
# Describe the sink
#sink 端的 avro 是一个数据发送者
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = node1
a1.sinks.k1.port = 4141
a1.sinks.k2.type = avro
a1.sinks.k2.hostname = node2
a1.sinks.k2.port = 4142
# Describe the channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.channels.c2.type = memory
a1.channels.c2.capacity = 1000
a1.channels.c2.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1 c2
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c2这里定义了两个sinks,都是avro sinks,端口分别为4141和4142,仍然监听hive.log
定义了两个channel
定义flume-2:
定义source是4141端口的avro
a2.sources = r1
a2.sinks = k1
a2.channels = c1
# Describe/configure the source
#source 端的 avro 是一个数据接收服务
a2.sources.r1.type = avro
a2.sources.r1.bind = node1
a2.sources.r1.port = 4141
# Describe the sink
a2.sinks.k1.type = hdfs
a2.sinks.k1.hdfs.path = hdfs://node1:8020/flume2/%Y%m%d/%H
#上传文件的前缀
a2.sinks.k1.hdfs.filePrefix = flume2
#是否按照时间滚动文件夹
a2.sinks.k1.hdfs.round = true
#多少时间单位创建一个新的文件夹
a2.sinks.k1.hdfs.roundValue = 1
#重新定义时间单位
a2.sinks.k1.hdfs.roundUnit = hour
#是否使用本地时间戳
a2.sinks.k1.hdfs.useLocalTimeStamp = true
#积攒多少个 Event 才 flush 到 HDFS 一次
a2.sinks.k1.hdfs.batchSize = 100
#设置文件类型,可支持压缩
a2.sinks.k1.hdfs.fileType = DataStream
#多久生成一个新的文件
a2.sinks.k1.hdfs.rollInterval = 30
#设置每个文件的滚动大小大概是 128M
a2.sinks.k1.hdfs.rollSize = 13421770 0
#文件的滚动与 Event 数量无关
a2.sinks.k1.hdfs.rollCount = 0
# Describe the channel
a2.channels.c1.type = memory
a2.channels.c1.capacity = 1000
a2.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a2.sources.r1.channels = c1
a2.sinks.k 1.channel = c1定义flume-3:
定义source是4142端口的avro
# Name the components on this agent
a3.sources = r1
a3.sinks = k1
a3.channels = c2
# Describe/configure the source
a3.sources.r1.type = avro
a3.sources.r1.bind = node1
a3.sources.r1.port = 4142
# Describe the sink
a3.sinks.k1.type = file_roll
a3.sinks.k1.sink.directory = /export/server/data/flume3
# Describe the channel
a3.channels.c2.t ype = memory
a3.channels.c2.capacity = 1000
a3.channels.c2.transactionCapacity = 100
# Bind the source and sink to the channel
a3.sources.r1.channels = c2
a3.sinks.k1.channel = c2
在开启服务时要注意,应该先开启flume2和flume3,因为avro是一个基于服务端和客户端的RPC框架,而flume2和flume3是作为服务端,而flume1是客户端(提供数据),理应先开启服务端
负载均衡和故障转移案例
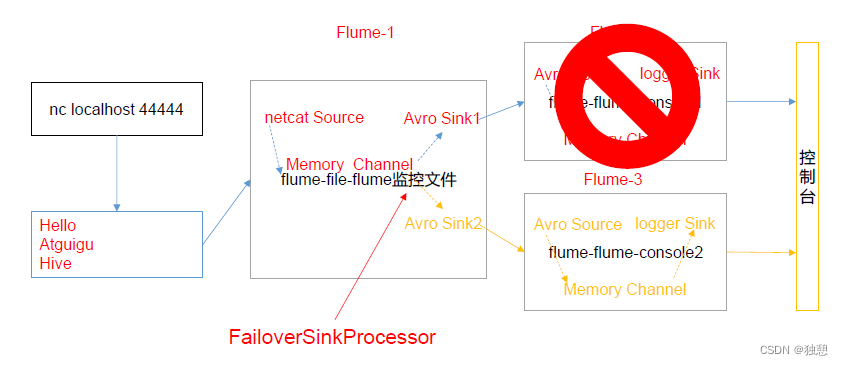
flume1:
需要设置一个sinkgroups,设置两个sink为一个组,并设置为failover(如果要设置为负载均衡,应该设置为 load_balance)
# Name the components on this agent
a1.sources = r1
a1.channels = c1
a1.sinkgroups = g1
a1.sinks = k1 k2
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
a1.sinkgroups.g1.processor.type = failover
a1.sinkgroups.g1.processor.priority.k1 = 5
a1.sinkgroups.g1.processor.priority.k2 = 10
a1.sinkgroups.g1.processor.maxpenalty = 10000
# Describe the sink
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = node1
a1.sinks.k1.port = 4141
a1.sinks.k2.type = avro
a1.sinks.k2.hostname = node1
a1.sinks.k2.port = 4142
# Describe the channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinkgroups.g1.sinks = k1 k2
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c1如果是负载均衡:
a1.sinkgroups = g1
a1.sinkgroups.g1.sinks = k1 k2
a1.sinkgroups.g1.processor.type = load_balance
a1.sinkgroups.g1.processor.backoff = true
a1.sinkgroups.g1.processor.selector = random
flume2:
# Name the components on this agent
a2.source s = r1
a2.sinks = k1
a2.channels = c1
# Describe/configure the source
a2.sources.r1.type = avro
a2.sources.r1.bind = node1
a2.sources.r1.port = 4141
# Describe the sink
a2.sinks.k1.type = logger
# Describe the channel
a2.channels.c1.type = memory
a2.channels.c1.capacity = 1000
a2.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a2.sources.r1.channels = c1flume3:
# Name the components on this agent
a3.sources = r1
a3.sinks = k1
a3.channels = c2
# Describe/configure the source
a3.sources.r1.type = avro
a3.sources.r1.bind = node1
a3.sources.r1.port = 4142
# Describe the sink
a3.sinks.k1.type = logger
# Describe the channel
a3.channels.c2.type = memory
a3.channels.c2.capacity = 1000
a3.channels.c2.transactionCapacity = 100
# Bind the source and sink to the channel
a3.sources.r1.channels = c2聚合案例

这里group.log来node2,netcat来自node3,最后汇总到node1,实现跨机器监听
flume1(node2):
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /opt/module/group.log
a1.sources.r1.shell = /bin/bash -c
# Describe the sink
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = node1
a1.sinks.k1.port = 4141
# Describe the channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c 1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1flume2(node3):
# Name the components on this agent
a2.sources = r1
a2.sinks = k1
a2.channels = c1
# Describe/configure the source
a2.sources.r1.type = netcat
a2.sources.r1.bind = node3
a2.sources.r1.port = 44444
# Describe the sink
a2.sinks.k1.type = avro
a2.sinks.k1.hostname = node1
a2.sinks.k1.port = 4141
# Use a channel which buffers events in memory
a2.channels.c1.type = memory
a2.channels.c1.capacity = 1000
a2.channels.c1.transactionCapacity = 100
# Bind the source and sin k to the channel
a2.sources.r1.channels = c1
a2.sinks.k1.channel = c1flume1 (node1):
# Name the components on this agent
a3.sources = r1
a3.sinks = k1
a3.channels = c1
# Describe/configure the source
a3.sources.r1.type = avro
a3.sources.r1.bind = node1
a3.sources.r1.port = 4141
# Describe the sink
# Describe the sink
a 3.sinks.k1.type = logger
# Describe the channel
a3.channels.c1.type = memory
a3.channels.c1.capacity = 1000
a3.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a3.sources.r1. channels = c1
a3.sinks.k1.channel = c1自定义拦截器
这里的目的是根据头文件的不同,发往不同的channel,然后发往不同的sink

需要自己写一个jar包,这里相当于是自己给netcat的信息增加的头文件,如果信息中含有"lmx’,则在头信息中加入 type:lmx,反之加入type:other
package lmx.interceptor;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
public class TypeIntercepter implements Interceptor {
private List<Event> addHeaderEvents;
@Override
public void initialize() {
addHeaderEvents = new ArrayList<>();
}
@Override
public Event intercept(Event event) {
// 获取事件中的头信息
Map<String, String> headers = event.getHeaders();
// 获取事件中的 body 信息
String body = new String(event.getBody());
// 根据 body 中是否有 lmx 来决定添加怎样的头信息
if (body.contains("lmx")){
// 添加头信息
headers.put("type","lmx");
} else{
// 添加头信息
headers.put("type", "other");}
return event;
}
@Override
public List<Event> intercept(List<Event> list) {
// 清空集合
addHeaderEvents.clear();
// 遍历 events
for (Event event:list) {
// 给每一个事件添加头信息
addHeaderEvents.add(intercept(event));
}
return addHeaderEvents;
}
@Override
public void close() {
}
public static class Builder implements Interceptor.Builder {
@Override
public Interceptor build() {
return new TypeIntercepter();
}
public void configure(Context context) {
}
}
}定义flume1:
# Name the components on this agent
a1.sources = r1
a1.sinks = k1 k2
a1.channels = c1 c2
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = lmx.flume.interceptor.CustomInterceptor$Builder
a1.sources.r1.selector.type = multiplexing
a1 .sources.r1.selector.header = type
a1.sources.r1.selector.mapping.lmx = c1
a1.sources.r1.selector.mapping.other = c2
# Describe the sink
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = node2
a1.sinks.k1.port = 4141
a1.sinks.k2.type=avro
a1.sinks.k2. hostname = node3
a1.sinks.k2.port = 4242
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Use a channel which buffers events in memory
a1.channels.c2 .type = memory
a1.channels.c2.capacity = 1000
a1.channels.c2.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1 c2
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c2官方也提供了一些拦截器:
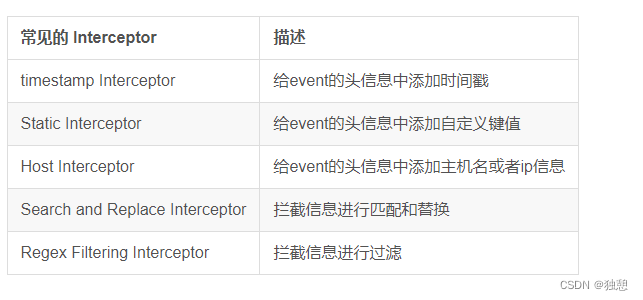
3 flume Sink Processors 、Interceptor | 海汼部落 高品质的 大数据技术社区
自定义Source
根据官方说明自定义,MySource 需要继承 AbstractSource 类并实现 Configurable 和 PollableSource 接口。
实现相应方法:
getBackOffSleepIncrement() //backoff 步长
getMaxBackOffSleepInterval()//backoff 最长时间
configure(Context context)//初始化context(读取配置文件内容)
process()//获取数据封装成event 并写入channel,这个方法将被循环调用。如果一直没有数据,则source去访问数据的时间间隔会逐步变长,例如backoff步长为2,那么第一次等待2s,第二次等待4s,直到达到backoff最大时间或产生了新的数据
需求:使用flume 接收数据,并给每条数据添加前缀,输出到控制台。前缀可从flume 配置文
件中配置。
java:
package lmx.source;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.EventDeliveryException;
import org.apache.flume.PollableSource;
import org.apache.flume.conf.Configurable;
import org.apache.flume.source.AbstractSource;
import org.apache.flume.event.SimpleEvent;
import java.util.HashMap;
public class Mysource extends AbstractSource implements Configurable, PollableSource {
private String prefix;
private String subfix;
private Long delay;
@Override
public void configure(Context context) {
prefix = context.getString("pre","pre-");
subfix = context.getString("sub");
delay = context.getLong("delay");
}
@Override
public Status process() throws EventDeliveryException {
try{
for (int i = 0; i < 5; i++) {
Event event = new SimpleEvent();
HashMap<String, String> hearderMap = new HashMap<>();
// 给事件设置头信息
event.setHeaders(hearderMap);
// 给事件设置内容
event.setBody((prefix+"lmx"+i+subfix).getBytes());
// 将事件写入 channel
getChannelProcessor().processEvent(event);
}
Thread.sleep(delay);
return Status.READY;
}catch (Exception e){
e.printStackTrace();
return Status.BACKOFF;
}
}
@Override
public long getBackOffSleepIncrement() {
return 0;
}
@Override
public long getMaxBackOffSleepInterval() {
return 0;
}
}
配置文件:
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = lmx.source.Mysource
a1.sources.r1.pre = pre-
a1.sources.r1.sub = -sub
a1.sources.r1.delay = 5000
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
结果:
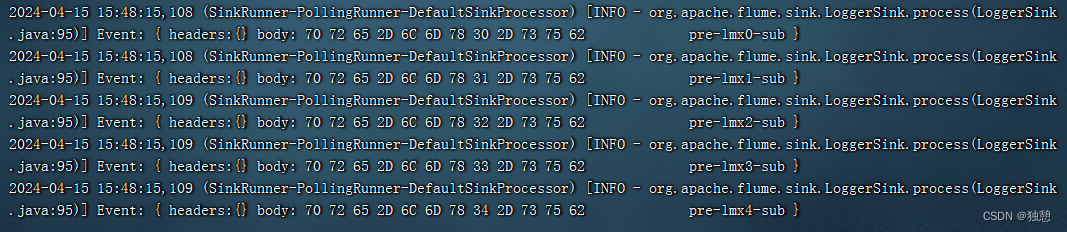
自定义Sink
根据官方说明自定义,MySink 需要继承 AbstractSink 类并实现 Configurable 接口。
实现相应方法:
configure(Context context)//初始化 context (读取配置文件内容
process()// 从 Channel 读取获取数据( event ),这个方法将被循环调用。
需求:使用flume 接收数据,并在 Sink 端给每条数据添加前缀和后缀,输出到控制台。前后
缀可在 flume 任务配置文件中配置。
java:
package lmx.sink;
import org.apache.flume.*;
import org.apache.flume.conf.Configurable;
import org.apache.flume.sink.AbstractSink;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class Mysink extends AbstractSink implements Configurable
{
private String prefix;
private String subfix;
private Long delay;
private static final Logger LOG = LoggerFactory.getLogger(Mysink.class);
@Override
public void configure(Context context) {
prefix = context.getString("pre","pre-");
subfix = context.getString("sub");
}
@Override
public Status process() throws EventDeliveryException {
//声明返回值状态信息
Status status;
//获取当前Sink 绑定的Channel
Channel ch = getChannel();
//获取事务
Transaction txn = ch.getTransaction();
//开启事务
txn.begin();
// 读取 Channel 中的事件,直到读取到事件结束循环
try {
Event event;
while (true) {
event = ch.take();
if (event != null) {
break;
}
}
// 处理事件(打印)
LOG.info(prefix + new String(event.getBody()) + subfix);
// 事务提交
txn.commit();
status = Status.READY;
} catch (Exception e){
// 遇到异常,事务回滚
txn.rollback();
status = Status.BACKOFF;
} finally{
txn.close();
}
return status;
}
}
配置文件:
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# Describe the sink
# Describe the sink
a1.sinks.k1.type = lmx.sink.Mysink
a1.sinks.k1.pre = lala-
a1.sinks.k1.sub = -lmx
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
![]()