
| 欢迎来到 请回答1024 的博客 |
🍓🍓🍓欢迎来到 请回答1024的博客
关于博主: 我是 请回答1024,一个追求数学与计算的边界、时间与空间的平衡,0与1的延伸的后端开发者。
博客特色: 在我的博客中,开设了如下专栏(点击可以进入专栏奥~): Java、MySQL、Redis、Spring、SpringBoot、SpringCloud、RabbitMQ、微服务、分布式 等相关技术专栏。期待与您一起,探索编程世界中的发现和创新之旅。
🍎🍎🍎我的主页 : https://reply1024.blog.csdn.net
敬请期待定期更新、见解和教程!让我们一起踏上这段编码冒险之旅!
| 数学与计算的边界 时间与空间的平衡 0与1的延伸 |
☃️ 概述
Hash 结构与 Redis 中的Zset非常类似:
- 都是键值存储
- 都需求根据键获取值
- 键必须唯一
区别如下:
- zset的键是member,值是score;hash的键和值都是任意值
- zset要根据score排序;hash则无需排序
☃️底层实现
底层实现方式:压缩列表ziplist 或者 字典dict
当Hash中数据项比较少的情况下,Hash底层才⽤压缩列表ziplist进⾏存储数据,随着数据的增加,底层的ziplist就可能会转成dict,具体配置如下:
hash-max-ziplist-entries 512
hash-max-ziplist-value 64
当满足上面两个条件其中之⼀的时候,Redis 就使⽤ dict 字典来实现hash。
Redis的hash之所以这样设计,是因为当ziplist变得很⼤的时候,它有如下几个缺点:
- 每次插⼊或修改引发的realloc操作会有更⼤的概率造成内存拷贝,从而降低性能。
- ⼀旦发生内存拷贝,内存拷贝的成本也相应增加,因为要拷贝更⼤的⼀块数据。
- 当ziplist数据项过多的时候,在它上⾯查找指定的数据项就会性能变得很低,因为ziplist上的查找需要进行遍历。
总之,ziplist 本来就设计为各个数据项挨在⼀起组成连续的内存空间,这种结构并不擅长做修改操作。⼀旦数据发⽣改动,就会引发内存 realloc,可能导致内存拷贝。
hash结构如下:

zset集合如下:

因此,Hash底层采用的编码与Zset也基本一致,只需要把排序有关的SkipList去掉即可:
- Hash结构默认采用ZipList编码,用以节省内存。 ZipList中相邻的两个entry 分别保存field和value
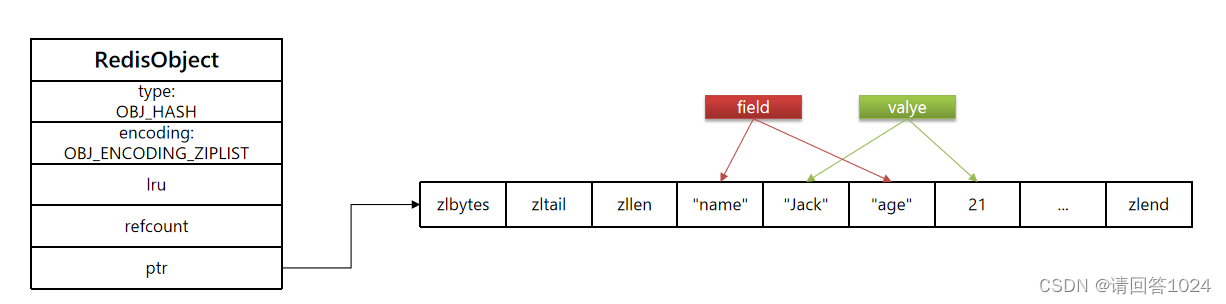
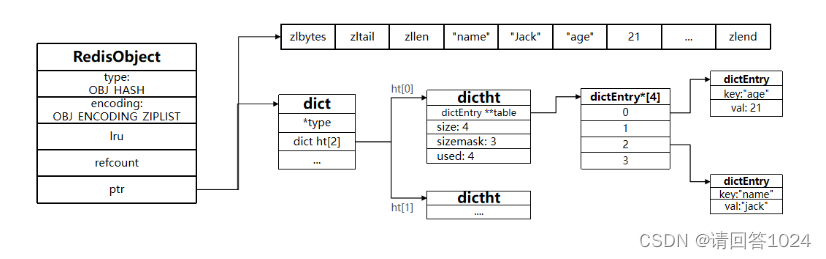
当数据量较大时,Hash结构会转为HT编码,也就是Dict,触发条件有两个:
- ZipList中的元素数量超过了
hash-max-ziplist-entries(默认512) - ZipList中的任意entry大小超过了
hash-max-ziplist-value(默认64字节)
- ZipList中的元素数量超过了
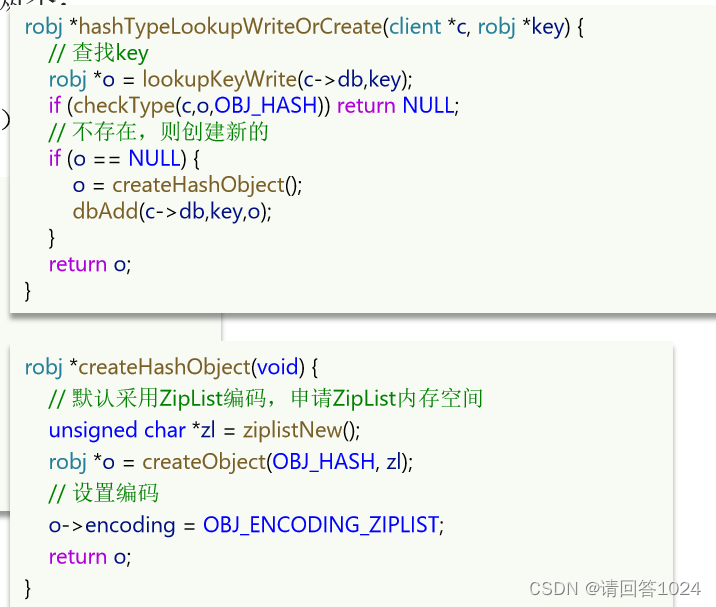
☃️源码



☃️其他
底下的就别看了
在 Redis 中,哈希表(Hash)是一种常见的数据结构,用来存储键值对的集合。在 Redis 中,哈希表通常被用于存储对象,其中每个对象都包含了多个字段和对应的值。
内部结构:
Redis 的哈希表内部使用了哈希算法来将键映射到哈希表的索引位置。每个索引位置上存储了一个链表或者跳跃表,用来解决哈希冲突的问题。在 Redis 的哈希表中,当链表或跳跃表的长度超过一定阈值时,会自动将其转换为跳跃表,以提高查询效率。
应用场景:
哈希表在 Redis 中被广泛应用于存储对象的各个属性。例如,可以使用哈希表来存储用户的信息,每个用户对象对应一个哈希表,其中包含了用户的姓名、年龄、邮箱等信息,每个属性对应哈希表中的一个字段。
优势:
Redis 的哈希表具有快速的查找速度,平均时间复杂度为 O(1)。这使得它非常适合用于存储和查询对象的属性。此外,Redis 的哈希表还支持对单个字段进行增加、删除、修改等操作,使得对对象的操作更加灵活和高效。
总的来说,Redis 的哈希表是一种高效的键值对存储结构,适用于存储和查询对象的属性信息,能够快速地进行增删改查操作,为应用提供了便利的数据存储和管理功能。
