打卡
日期
心得
我的主语言并不是Python,以及现在从事的工作也并不是开发;所以对于这个系列的课程,学习起来是较为困难的,所以基于这种情况,该如何进行学习?我的做法是全部交给AI,使用AI一步步解析代码,然后自己运行,途中可以通过修改部分代码达到自己逐步学习的一个目的。下面是通过AI进行的本次学习。
昇思MindSpore 入门介绍
工作习惯查看产品的整体架构图,
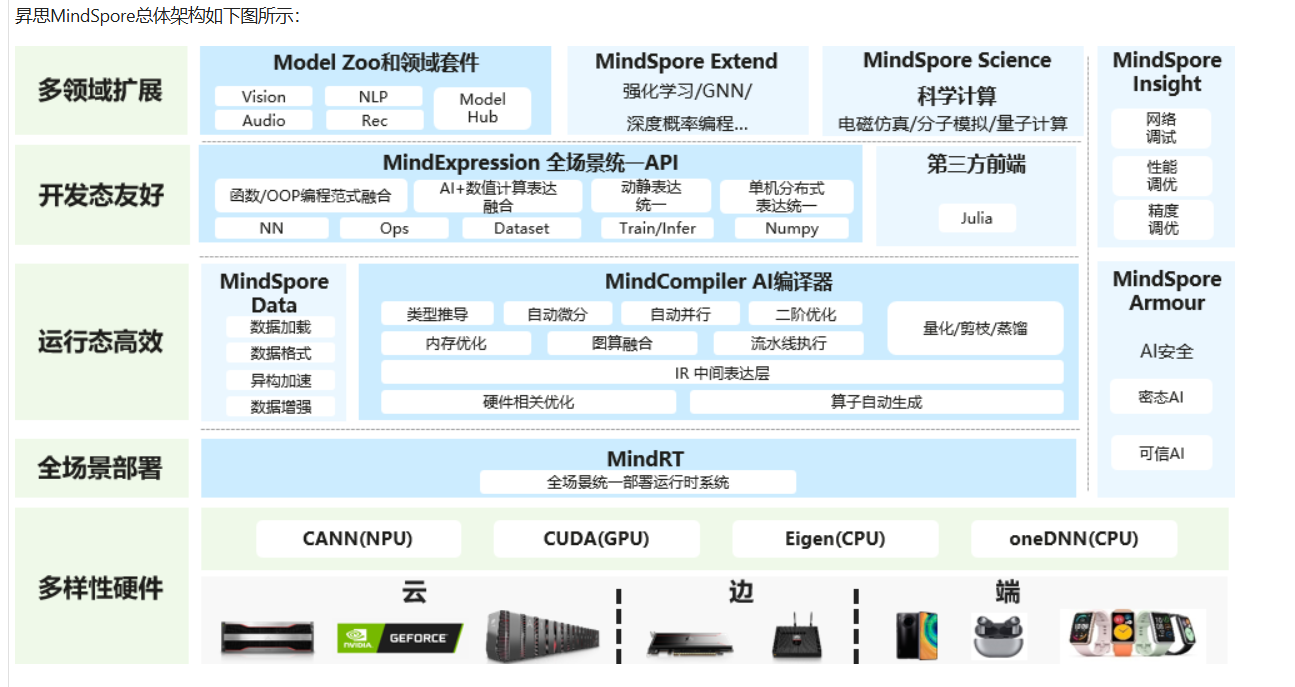
产品架构图解释

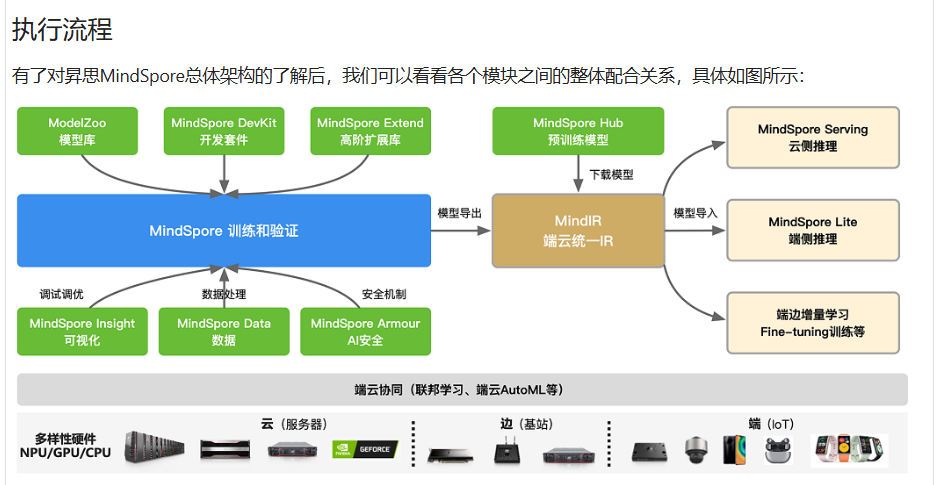
产品执行流程
从中可以意识到,平常使用的模型,都是训练模型完成之后的模型。本次的学习是在于模型前的训练和处理模型应用。
快速入门 (结合AI 进行学习)
导入模块解析
了解了,以下是代码及其解析的完整格式:
import mindspore
from mindspore import nn
from mindspore.dataset import vision, transforms
from mindspore.dataset import MnistDataset
解析:
- 导入MindSpore框架:
import mindspore
这行代码导入了MindSpore框架,这是一个用于构建、训练和部署深度学习模型的开源深度学习框架。
- 从MindSpore中导入神经网络模块:
from mindspore import nn
这行代码从MindSpore中导入神经网络模块(nn),这个模块包含了构建神经网络所需的各种层和功能。
- 从MindSpore的数据处理模块中导入视觉和变换工具:
from mindspore.dataset import vision, transforms
这行代码从MindSpore的数据集模块中导入了视觉工具(vision)和变换工具(transforms)。vision模块用于处理图像相关的数据集,transforms模块用于对数据进行各种变换操作,例如归一化、裁剪等。
- 导入MNIST数据集类:
from mindspore.dataset import MnistDataset
这行代码从MindSpore的数据集模块中导入了MNIST数据集类(MnistDataset),该类用于加载和处理MNIST数据集。MNIST数据集是一个包含手写数字图像的标准数据集,广泛用于训练和测试机器学习模型,特别是图像分类任务。
这段代码主要是为使用MindSpore框架处理MNIST数据集并构建神经网络模型做准备。接下来,通常还会有代码来定义神经网络模型、加载数据集、进行数据预处理、训练模型以及进行模型评估等步骤。
开源数据集下载代码模块解析
# Download data from open datasets
from download import download
url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/" \
"notebook/datasets/MNIST_Data.zip"
path = download(url, "./", kind="zip", replace=True)
解析:
- 从开放数据集中下载数据:
from download import download
这行代码导入了download函数,用于从指定的URL下载文件。
- 定义数据集的URL:
url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/" \
"notebook/datasets/MNIST_Data.zip"
这行代码指定了MNIST数据集的URL地址。这个URL指向一个zip压缩文件,包含了MNIST数据集。
- 下载并解压数据集:
path = download(url, "./", kind="zip", replace=True)
这行代码使用download函数从指定URL下载MNIST数据集,并将其存储在当前目录下。如果已有同名文件存在,将会被替换(replace=True)。参数kind="zip"表示下载的是一个zip压缩文件,会自动解压到指定目录。
通过这段代码,可以确保MNIST数据集被正确下载和解压,为后续的数据处理和模型训练做好准备。
手动下载模型,并查看下模型内容 个人内容
手动下载模型如下
将数据转为图片模式查看
import struct
import numpy as np
from PIL import Image
import os
def read_idx(filename):
"""Read an idx file and return it as a numpy array."""
with open(filename, 'rb') as f:
zero, data_type, dims = struct.unpack('>HBB', f.read(4))
shape = tuple(struct.unpack('>I', f.read(4))[0] for d in range(dims))
return np.frombuffer(f.read(), dtype=np.uint8).reshape(shape)
def save_images(images, output_dir, prefix='image'):
"""Save images to the specified directory with the given prefix."""
for i, img in enumerate(images):
im = Image.fromarray(img)
im.save(f"{output_dir}/{prefix}_{i}.png")
def main():
# Path to the train-images-idx3-ubyte file
idx_file_path = r'D:\桌面\数据源\MNIST_Data\MNIST_Data\train\train-images-idx3-ubyte'
# Output directory to save images
output_dir = r'D:\桌面\数据源\MNIST_Data\MNIST_Data\train\output_images'
# Read images from idx file
images = read_idx(idx_file_path)
# Create output directory if it doesn't exist
if not os.path.exists(output_dir):
os.makedirs(output_dir)
# Save images to the output directory
save_images(images, output_dir)
if __name__ == "__main__":
main()
结果
训练集加载
train_dataset = MnistDataset('MNIST_Data/train')
test_dataset = MnistDataset('MNIST_Data/test')
解析:
- 加载训练数据集:
train_dataset = MnistDataset('MNIST_Data/train')
这行代码通过MnistDataset类加载MNIST训练数据集。路径'MNIST_Data/train'指向之前下载并解压的MNIST数据集的训练数据文件夹。
- 加载测试数据集:
test_dataset = MnistDataset('MNIST_Data/test')
这行代码通过MnistDataset类加载MNIST测试数据集。路径'MNIST_Data/test'指向之前下载并解压的MNIST数据集的测试数据文件夹。
通过这两行代码,您已经成功加载了MNIST数据集的训练和测试数据,为后续的数据预处理和模型训练做好了准备。
训练集打印列名解析
print(train_dataset.get_col_names())
解析:
这行代码用于打印train_dataset数据集的列名。get_col_names()方法返回数据集中所有列的名称,通常这些列名代表了数据集中的特征和标签。
在MNIST数据集中,通常会有两列:一列是图像数据(特征),另一列是对应的标签(目标)。因此,打印出来的结果可能是类似['image', 'label']的内容。
执行这行代码后,您将看到训练数据集的列名,这有助于您了解数据集的结构和内容。
修改训练集打印,验证修改的代码在云上环境可执行 个人内容
改为打印第一行其他数据,验证是否执行了如果要打印其他信息,比如数据集的第一行数据,并且train_dataset不支持索引操作或者没有直接方法来获取单行数据,您可能需要借助于数据集的迭代功能来实现。以下是如何使用迭代器来获取和打印第一行数据的方法:
# 使用迭代器打印训练数据集的第一行数据
for first_row in train_dataset:
print(first_row)
break # 打印第一行后退出循环
解析:
- 创建迭代器:
for first_row in train_dataset:
这行代码创建一个迭代器,用于逐行遍历数据集。train_dataset对象应该是可迭代的,即实现了__iter__方法。
- 打印第一行数据:
print(first_row)
这行代码打印出第一行数据的内容。
- 退出循环:
break
打印第一行数据后立即退出循环,以避免遍历整个数据集。
这种方法适用于大多数数据集对象,因为它不依赖于数据集的具体实现细节,只要数据集是可迭代的即可。
如果您有特定的数据集对象且知道其API支持其他方式获取数据,也可以使用相应的方法。例如,如果有get_batch()或类似方法,可以调整代码来适应您的需求。
结果如下
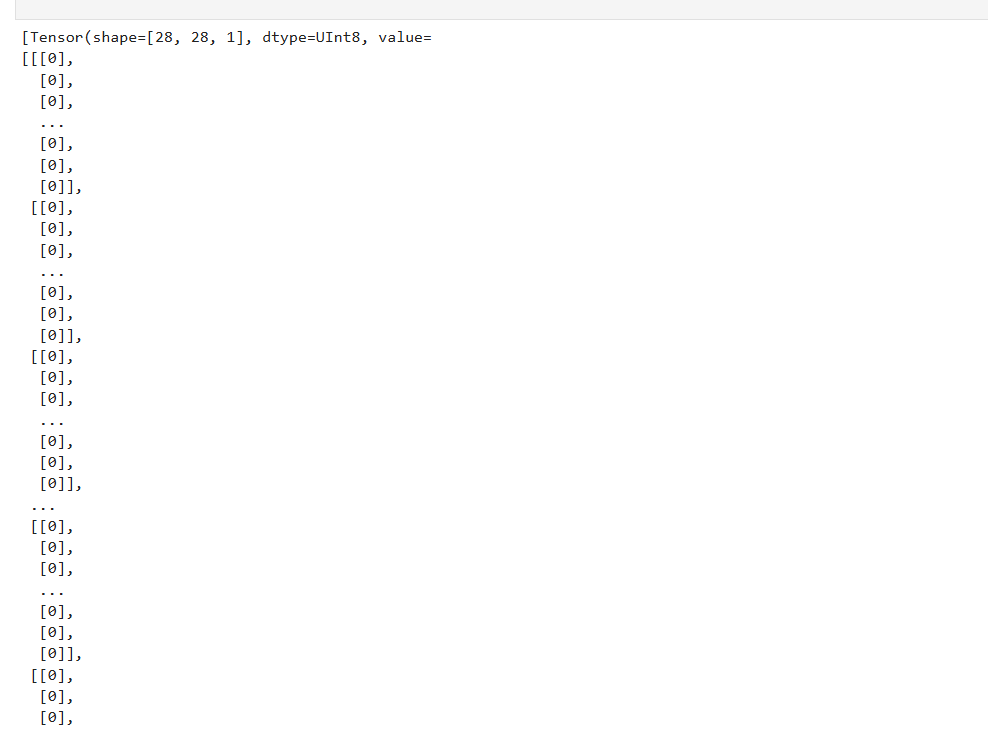
datapipe函数解析(应该是数据处理函数)
当然,以下是对datapipe函数的逐步解析:
def datapipe(dataset, batch_size):
# 定义图像变换操作
image_transforms = [
vision.Rescale(1.0 / 255.0, 0),
vision.Normalize(mean=(0.1307,), std=(0.3081,)),
vision.HWC2CHW()
]
# 定义标签变换操作
label_transform = transforms.TypeCast(mindspore.int32)
# 应用图像变换到数据集
dataset = dataset.map(image_transforms, 'image')
# 应用标签变换到数据集
dataset = dataset.map(label_transform, 'label')
# 将数据集分批处理
dataset = dataset.batch(batch_size)
# 返回处理后的数据集
return dataset
- 函数定义和参数:
def datapipe(dataset, batch_size):
dataset:输入的数据集对象,包含图像和标签。batch_size:用于批处理的批大小。
- 定义图像变换操作:
image_transforms = [
vision.Rescale(1.0 / 255.0, 0),
vision.Normalize(mean=(0.1307,), std=(0.3081,)),
vision.HWC2CHW()
]
Rescale(1.0 / 255.0, 0):将图像像素值从[0, 255]缩放到[0, 1]。Normalize(mean=(0.1307,), std=(0.3081,)):标准化图像,使其均值为0.1307,标准差为0.3081(通常用于MNIST数据集)。HWC2CHW():将图像的维度从Height x Width x Channel转换为Channel x Height x Width,适应大多数深度学习框架的输入格式。
- 定义标签变换操作:
label_transform = transforms.TypeCast(mindspore.int32)
TypeCast(mindspore.int32):将标签的数据类型转换为int32。
- 应用图像变换到数据集:
dataset = dataset.map(image_transforms, 'image')
map方法将一系列图像变换应用到数据集中的图像数据。
- 应用标签变换到数据集:
dataset = dataset.map(label_transform, 'label')
map方法将标签变换应用到数据集中的标签数据。
- 将数据集分批处理:
dataset = dataset.batch(batch_size)
batch方法将数据集按照指定的批大小分批处理,方便后续训练或推理。
- 返回处理后的数据集:
return dataset
- 返回经过图像和标签变换、以及批处理后的数据集对象。
这个函数的主要目的是对数据集进行一系列的预处理操作,包括图像的规范化、数据类型转换以及批处理,以便后续在模型训练或推理中使用。这样做可以确保输入数据的一致性和高效处理。
上述代码片段展示了如何使用datapipe函数对训练数据集和测试数据集进行预处理,并将其分批处理。我们来详细解析一下每一行代码。
训练集模型预处理 批处理解析
# 对训练数据集应用预处理和批处理
train_dataset = datapipe(train_dataset, 64)
- 调用
datapipe函数:train_dataset:这是原始的训练数据集,包含图像和标签。64:这是批处理的批大小。
- 预处理和批处理:
datapipe函数会对train_dataset进行一系列的图像和标签变换操作,然后按批大小为64进行批处理。
- 返回处理后的数据集:
- 处理后的数据集重新赋值给
train_dataset变量,此时train_dataset已经是经过预处理和批处理的版本,可以直接用于模型训练。
- 处理后的数据集重新赋值给
# 对测试数据集应用预处理和批处理
test_dataset = datapipe(test_dataset, 64)
- 调用
datapipe函数:test_dataset:这是原始的测试数据集,包含图像和标签。64:这是批处理的批大小。
- 预处理和批处理:
datapipe函数会对test_dataset进行一系列的图像和标签变换操作,然后按批大小为64进行批处理。
- 返回处理后的数据集:
- 处理后的数据集重新赋值给
test_dataset变量,此时test_dataset已经是经过预处理和批处理的版本,可以直接用于模型评估。
- 处理后的数据集重新赋值给
通过调用datapipe函数对训练和测试数据集进行预处理和批处理,可以确保数据的一致性和高效性。处理后的数据集可以直接输入到模型中进行训练和评估。这种操作简化了数据预处理的流程,提高了代码的可读性和可维护性。
尝试使用 create_tuple_iterator 访问数据集 处理数据集 个人内容
当然,可以通过使用create_tuple_iterator或create_dict_iterator对数据集进行迭代访问,并查看数据和标签的形状(shape)和数据类型(datatype)。下面是一个示例,展示了如何实现这一点。
假设我们已经有了预处理后的训练数据集和测试数据集,我们将使用两种不同的迭代器来访问数据集。
使用 create_tuple_iterator 访问数据集
create_tuple_iterator 会将每个数据样本作为一个tuple返回,这对于包含图像和标签的数据集非常适合。
import mindspore.dataset as ds
# 使用 create_tuple_iterator 迭代访问训练数据集
train_iterator = train_dataset.create_tuple_iterator()
# 获取和打印一个批次的数据和标签的shape和datatype
for batch in train_iterator:
images, labels = batch
print("Images shape:", images.shape)
print("Images datatype:", images.dtype)
print("Labels shape:", labels.shape)
print("Labels datatype:", labels.dtype)
break # 只打印第一个批次的信息,避免输出过多内容
# 使用 create_tuple_iterator 迭代访问测试数据集
test_iterator = test_dataset.create_tuple_iterator()
# 获取和打印一个批次的数据和标签的shape和datatype
for batch in test_iterator:
images, labels = batch
print("Images shape:", images.shape)
print("Images datatype:", images.dtype)
print("Labels shape:", labels.shape)
print("Labels datatype:", labels.dtype)
break # 只打印第一个批次的信息,避免输出过多内容
使用 create_dict_iterator 访问数据集
create_dict_iterator 会将每个数据样本作为一个字典返回,这对于需要通过键名访问数据和标签的数据集非常适合。
# 使用 create_dict_iterator 迭代访问训练数据集
train_iterator = train_dataset.create_dict_iterator()
# 获取和打印一个批次的数据和标签的shape和datatype
for batch in train_iterator:
images = batch['image']
labels = batch['label']
print("Images shape:", images.shape)
print("Images datatype:", images.dtype)
print("Labels shape:", labels.shape)
print("Labels datatype:", labels.dtype)
break # 只打印第一个批次的信息,避免输出过多内容
# 使用 create_dict_iterator 迭代访问测试数据集
test_iterator = test_dataset.create_dict_iterator()
# 获取和打印一个批次的数据和标签的shape和datatype
for batch in test_iterator:
images = batch['image']
labels = batch['label']
print("Images shape:", images.shape)
print("Images datatype:", images.dtype)
print("Labels shape:", labels.shape)
print("Labels datatype:", labels.dtype)
break # 只打印第一个批次的信息,避免输出过多内容
通过以上示例代码,我们演示了如何使用create_tuple_iterator和create_dict_iterator对数据集进行迭代访问,并查看数据和标签的形状和数据类型。这种方法非常有助于调试和确保数据预处理的正确性。
结果如下
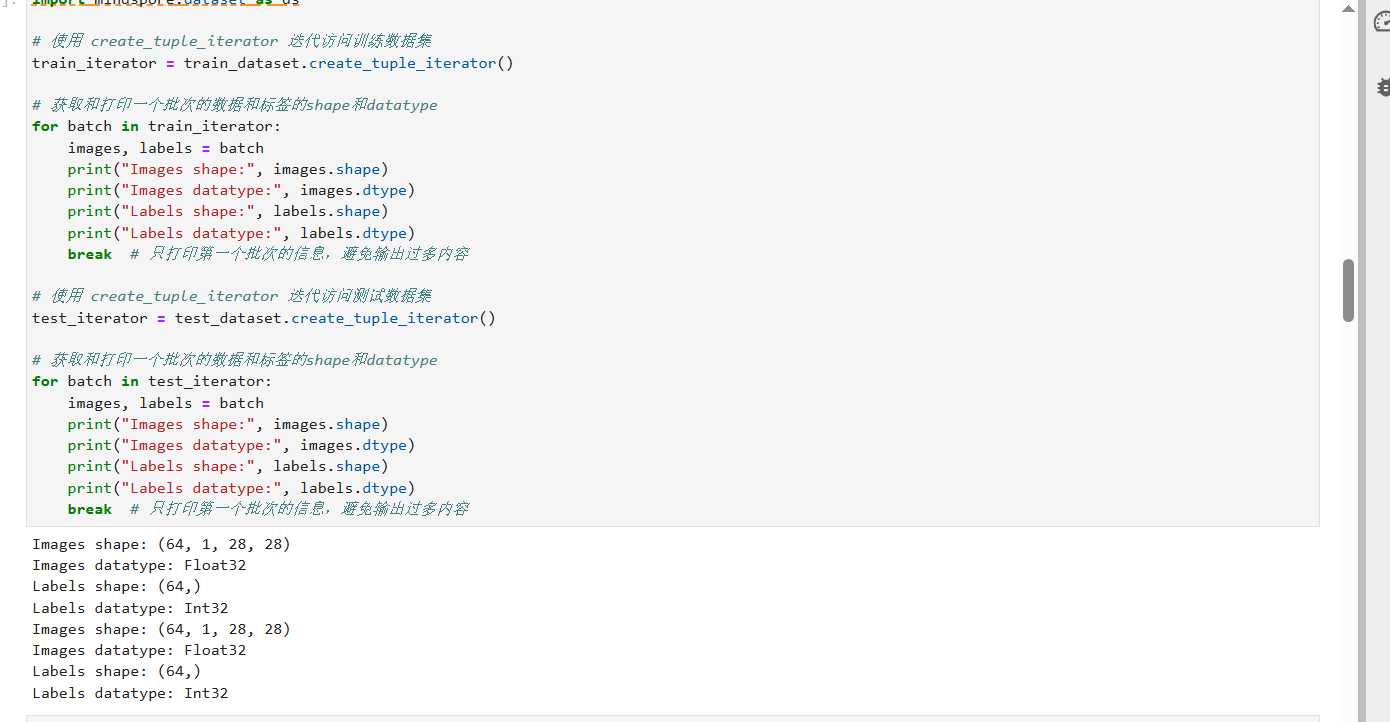
迭代图像集 批次 处理 解析
for image, label in test_dataset.create_tuple_iterator():
print(f"Shape of image [N, C, H, W]: {image.shape} {image.dtype}")
print(f"Shape of label: {label.shape} {label.dtype}")
break
- 创建迭代器:
test_dataset.create_tuple_iterator()创建一个可迭代对象,使得我们可以逐批次访问数据集。在测试数据集中,每个批次包含图像和相应的标签。
- for 循环:
for image, label in test_dataset.create_tuple_iterator():逐批次遍历测试数据集。每次迭代都会获取一个批次的图像和标签。
- 打印图像信息:
print(f"Shape of image [N, C, H, W]: {image.shape} {image.dtype}")打印图像的形状和数据类型。这里的[N, C, H, W]是期望的图像形状,其中N是批次大小,C是通道数,H是高度,W是宽度。
- 打印标签信息:
print(f"Shape of label: {label.shape} {label.dtype}")打印标签的形状和数据类型。通常,标签的形状是[N],对应于批次中的每个图像。
- 终止循环:
break在打印第一个批次的信息后立即终止循环。这确保了我们只打印一次,不会输出过多信息。
通过这段代码,可以快速检查数据集的预处理结果,确认图像和标签的形状与数据类型是否符合预期。这在调试数据预处理和模型输入时非常有帮助。
修改迭代测试,并打印内容 个人内容
# 初始化一个计数器
count = 0
# 迭代测试数据集的元组迭代器
for image, label in test_dataset.create_tuple_iterator():
# 打印图像和标签的形状以及数据类型
print(f"Shape of image [N, C, H, W]: {image.shape} {image.dtype}")
print(f"Shape of label: {label.shape} {label.dtype}")
# 更新计数器
count += 1
# 当迭代五次后跳出循环
if count == 5:
break
这段代码修改了之前的迭代次数,从一次变为五次。我们通过引入一个计数器 count 来跟踪迭代次数,并在迭代五个批次后使用 break 语句退出循环。这样,它将打印前五个批次的图像和标签形状及其数据类型。
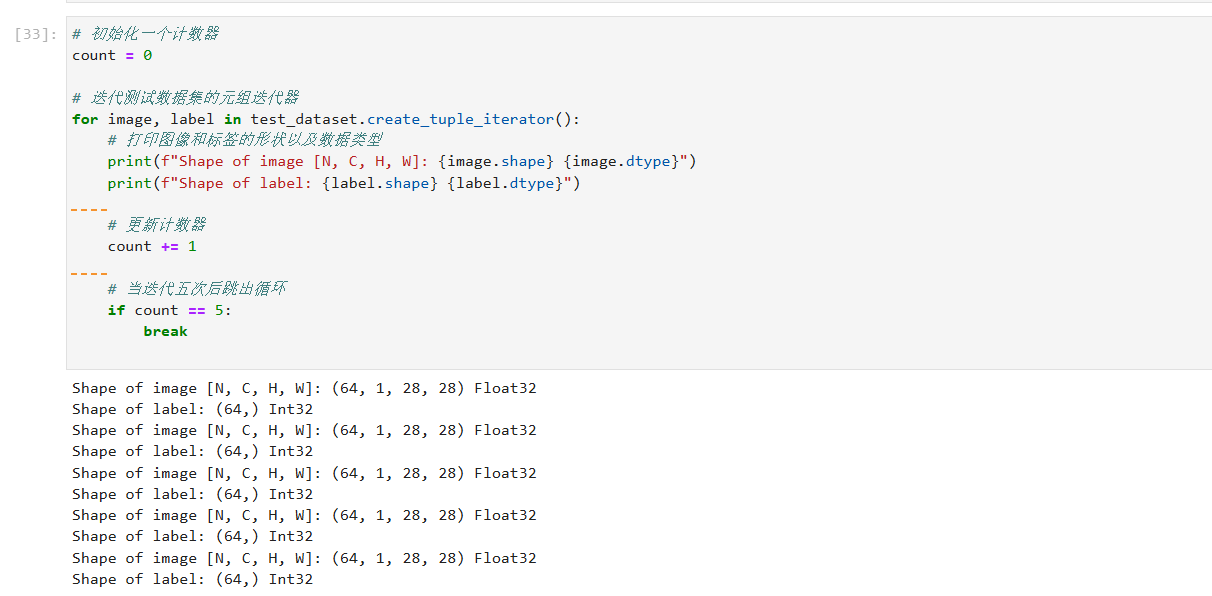
数据集迭代处理 和之前是不同的方式
for data in test_dataset.create_dict_iterator():
print(f"Shape of image [N, C, H, W]: {data['image'].shape} {data['image'].dtype}")
print(f"Shape of label: {data['label'].shape} {data['label'].dtype}")
break
- 创建字典迭代器:
test_dataset.create_dict_iterator()创建一个可迭代对象,使得我们可以逐批次访问数据集。与create_tuple_iterator()不同,create_dict_iterator()返回一个字典,其中键是数据集中的列名(例如 ‘image’ 和 ‘label’),值是相应的数据。
- for 循环:
for data in test_dataset.create_dict_iterator():逐批次遍历测试数据集。每次迭代都会获取一个批次的字典,其中包含图像和标签。
- 打印图像信息:
print(f"Shape of image [N, C, H, W]: {data['image'].shape} {data['image'].dtype}")打印图像的形状和数据类型。这里的[N, C, H, W]是期望的图像形状,其中N是批次大小,C是通道数,H是高度,W是宽度。
- 打印标签信息:
print(f"Shape of label: {data['label'].shape} {data['label'].dtype}")打印标签的形状和数据类型。通常,标签的形状是[N],对应于批次中的每个图像。
- 终止循环:
break在打印第一个批次的信息后立即终止循环。这确保了我们只打印一次,不会输出过多信息。
这段代码与之前的代码功能相似,但使用了字典迭代器来访问数据集中的图像和标签。这种方式在数据集的列名已知且固定时非常有用。
全连接神经网络代码解析
# 导入必要的库
import mindspore.nn as nn
# 定义模型
class Network(nn.Cell):
def __init__(self):
super(Network, self).__init__()
self.flatten = nn.Flatten() # 将输入展平
self.dense_relu_sequential = nn.SequentialCell( # 使用一个顺序容器
nn.Dense(28*28, 512), # 全连接层,输入大小为28*28,输出大小为512
nn.ReLU(), # ReLU激活函数
nn.Dense(512, 512), # 全连接层,输入和输出大小都为512
nn.ReLU(), # ReLU激活函数
nn.Dense(512, 10) # 全连接层,输入大小为512,输出大小为10(假设是10分类任务)
)
def construct(self, x):
x = self.flatten(x) # 展平输入
logits = self.dense_relu_sequential(x) # 前向传播通过顺序容器
return logits # 返回分类结果(未激活的logits)
# 实例化模型
model = Network()
# 打印模型结构
print(model)
- 导入必要的库:
import mindspore.nn as nn导入MindSpore的神经网络模块。
- 定义模型:
- 创建
Network类,继承自nn.Cell,这是MindSpore中的基本模型单元。
- 创建
- **初始化方法 **
__init__:super(Network, self).__init__()调用父类的初始化方法。self.flatten = nn.Flatten()定义一个展平操作,将输入多维张量展平为一维。self.dense_relu_sequential = nn.SequentialCell(...)定义一个顺序容器,包含依次排列的全连接层(nn.Dense)和ReLU激活函数(nn.ReLU)。这个顺序容器中,首先展平输入,然后依次通过三个全连接层,其中前两个全连接层后接ReLU激活函数,最后一个全连接层输出10个类别的logits。
- **前向传播方法 **
construct:x = self.flatten(x)将输入展平。logits = self.dense_relu_sequential(x)将展平后的输入通过顺序容器进行前向传播。return logits返回未激活的logits,表示模型的分类结果。
- 实例化模型:
model = Network()创建Network类的一个实例。
- 打印模型结构:
print(model)打印模型的结构,显示模型各层组成及其连接方式。
这段代码定义了一个简单的全连接神经网络,并展示了如何在MindSpore中构建和打印模型结构。
训练流程代码解析
# Instantiate loss function and optimizer
loss_fn = nn.CrossEntropyLoss()
optimizer = nn.SGD(model.trainable_params(), 1e-2)
# 1. Define forward function
def forward_fn(data, label):
logits = model(data)
loss = loss_fn(logits, label)
return loss, logits
# 2. Get gradient function
grad_fn = mindspore.value_and_grad(forward_fn, None, optimizer.parameters, has_aux=True)
# 3. Define function of one-step training
def train_step(data, label):
(loss, _), grads = grad_fn(data, label)
optimizer(grads)
return loss
def train(model, dataset):
size = dataset.get_dataset_size()
model.set_train()
for batch, (data, label) in enumerate(dataset.create_tuple_iterator()):
loss = train_step(data, label)
if batch % 100 == 0:
loss, current = loss.asnumpy(), batch
print(f"loss: {loss:>7f} [{current:>3d}/{size:>3d}]")
这段代码定义了一个训练过程,使用MindSpore框架来训练一个神经网络模型。以下是对代码的详细解释:
1. 实例化损失函数和优化器
loss_fn = nn.CrossEntropyLoss()
optimizer = nn.SGD(model.trainable_params(), 1e-2)
loss_fn是交叉熵损失函数,常用于分类任务。optimizer是随机梯度下降(SGD)优化器,学习率为1e-2,用于更新模型的参数。
2. 定义前向传播函数
def forward_fn(data, label):
logits = model(data)
loss = loss_fn(logits, label)
return loss, logits
forward_fn函数接收数据和标签,通过模型计算出预测的logits,并计算损失。
3. 获取梯度函数
grad_fn = mindspore.value_and_grad(forward_fn, None, optimizer.parameters, has_aux=True)
grad_fn是一个函数,用于计算forward_fn的输出和梯度。has_aux=True表示forward_fn返回的除了损失外还有其他辅助输出(这里是logits)。
4. 定义单步训练函数
def train_step(data, label):
(loss, _), grads = grad_fn(data, label)
optimizer(grads)
return loss
train_step函数接收数据和标签,计算损失和梯度,并使用优化器更新模型参数。
5. 定义训练函数
def train(model, dataset):
size = dataset.get_dataset_size()
model.set_train()
for batch, (data, label) in enumerate(dataset.create_tuple_iterator()):
loss = train_step(data, label)
if batch % 100 == 0:
loss, current = loss.asnumpy(), batch
print(f"loss: {loss:>7f} [{current:>3d}/{size:>3d}]")
train函数接收模型和数据集,设置模型为训练模式,遍历数据集的每个批次,执行单步训练,并每隔100个批次打印一次损失。
这段代码定义了一个完整的训练流程,包括损失函数和优化器的初始化、前向传播、梯度计算、单步训练和整个数据集的训练循环。通过这个流程,模型会不断更新参数以最小化损失函数,从而提高预测性能。
测试神经网络模型性能的函数 代码解析
这段代码定义了一个用于测试神经网络模型性能的函数。它使用一个给定的数据集来评估模型的准确性和平均损失。下面是对这个测试函数 test 的详细解释:
参数:
model: 已经训练好的神经网络模型。dataset: 用于测试的数据集,它应该是一个MindSpore数据集对象,包含了测试数据和对应的标签。loss_fn: 损失函数,用于计算模型预测和真实标签之间的误差。
def test(model, dataset, loss_fn):
num_batches = dataset.get_dataset_size() # 获取数据集中批次的数量。
model.set_train(False) # 设置模型为评估模式,关闭训练特定的操作,如Dropout。
total, test_loss, correct = 0, 0, 0 # 初始化总样本数、总损失和总正确预测数。
# 遍历测试数据集中的所有批次。
for data, label in dataset.create_tuple_iterator():
pred = model(data) # 使用模型对当前批次的数据进行预测。
total += len(data) # 更新总样本数。
test_loss += loss_fn(pred, label).asnumpy() # 累加当前批次的损失。
correct += (pred.argmax(1) == label).asnumpy().sum() # 累加正确预测的数量。
test_loss /= num_batches # 计算平均损失。
correct /= total # 计算准确率。
# 打印测试结果,包括准确率和平均损失。
print(f"Test: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")
该函数首先计算所有批次的总损失和正确预测的数量,然后计算和打印出平均损失和准确率。这是模型评估的标准做法,能够给出模型在未见过的数据上的表现。
model.set_train(False): 这个调用确保模型在推断模式下运行,这通常意味着关闭了一些只在训练时使用的操作(例如Dropout)。pred = model(data): 对于数据集中的每一个批次,模型会生成预测结果。test_loss += loss_fn(pred, label).asnumpy(): 计算每个批次的损失,并将其转换为numpy数组,然后累加到test_loss变量中。correct += (pred.argmax(1) == label).asnumpy().sum(): 计算每个批次中模型正确预测的样本数。pred.argmax(1)返回每个预测概率分布中概率最高的索引,即模型预测的类别标签。然后,与真实标签进行比较,统计正确预测的数量。
最后,它输出测试数据集上的平均损失和准确率。准确率是正确分类的样本数占总样本数的比例,是评估分类模型性能的常用指标。
训练代码解析
这段代码定义了一个训练循环,其中模型将在指定的epoch数(在这个例子中是3个epoch)内进行训练和测试。每个epoch包括一次完整的训练过程和一次测试过程。以下是对这段代码的详细解释:
epochs = 3 # 设置训练的epoch数为3。
# 对于每个epoch,执行以下操作:
for t in range(epochs):
print(f"Epoch {t+1}\n-------------------------------") # 打印当前epoch的序号。
train(model, train_dataset) # 调用之前定义的train函数,对模型进行训练。
test(model, test_dataset, loss_fn) # 调用之前定义的test函数,对模型进行测试。
print("Done!") # 当所有epoch都完成后,打印"Done!"表示训练过程结束。
epochs = 3: 定义了训练的轮数,即模型将遍历整个训练数据集3次。for t in range(epochs): 这是一个循环,从0到epochs-1(即0到2),每次迭代代表一个epoch。print(f"Epoch {t+1}\n-------------------------------"): 在每个epoch开始时,打印当前epoch的序号和分隔线,以便于区分不同的epoch。train(model, train_dataset): 调用之前定义的train函数,对模型进行训练。这个函数会遍历整个训练数据集,并更新模型的参数。test(model, test_dataset, loss_fn): 调用之前定义的test函数,对模型进行测试。这个函数会计算模型在测试数据集上的准确率和平均损失,并打印结果。print("Done!"): 当所有epoch都完成后,打印"Done!"表示训练过程已经结束。
这个训练循环是机器学习中常见的模式,它允许模型在多个epoch中逐步改进其性能,每个epoch后通过测试来评估模型的当前状态。
检查点 代码解析
# Save checkpoint
mindspore.save_checkpoint(model, "model.ckpt")
print("Saved Model to model.ckpt")
这段代码用于将训练好的模型保存为一个检查点(checkpoint)文件。检查点文件通常包含了模型的参数和其他相关信息,可以在之后用于加载模型以进行进一步的训练、评估或推理。以下是对这段代码的详细解释:
# Save checkpoint
mindspore.save_checkpoint(model, "model.ckpt")
print("Saved Model to model.ckpt")
mindspore.save_checkpoint(model, "model.ckpt"): 这个函数调用将模型的当前状态保存到名为model.ckpt的文件中。model是你要保存的模型对象,"model.ckpt"是保存的文件名。在MindSpore中,检查点文件通常使用.ckpt作为文件扩展名。print("Saved Model to model.ckpt"): 打印一条消息,确认模型已经成功保存到指定的文件中。
保存检查点是一个重要的步骤,因为它允许你在训练过程中断或者需要重新开始时,从保存的状态继续训练,而不是从头开始。此外,保存的检查点文件也可以用于部署模型到生产环境中,或者与其他研究人员共享模型。
重新启动训练或部署模型时恢复模型的状态 代码解析
这段代码展示了如何实例化一个随机初始化的模型,并从以前保存的检查点文件中加载参数到这个模型中。这是一个常见的步骤,用于在重新启动训练或部署模型时恢复模型的状态。以下是对该代码的详细解释:
# Instantiate a random initialized model
model = Network() # 创建一个新实例的模型,这个模型会被随机初始化。
# Load checkpoint and load parameter to model
param_dict = mindspore.load_checkpoint("model.ckpt") # 从检查点文件"model.ckpt"中加载参数字典。
param_not_load, _ = mindspore.load_param_into_net(model, param_dict) # 将加载的参数字典中的参数加载到模型中。
print(param_not_load) # 打印未能加载的参数名,如果有的话。
model = Network(): 这一行代码创建了一个新的模型实例,这个模型是随机初始化的。param_dict = mindspore.load_checkpoint("model.ckpt"): 从检查点文件"model.ckpt"中加载参数。load_checkpoint函数返回一个字典,包含了模型的参数。param_not_load, _ = mindspore.load_param_into_net(model, param_dict): 这个函数将参数字典param_dict中的参数加载到模型model中。它返回两个值:param_not_load: 一个列表,包含了那些未能加载的参数名。通常这些参数可能在当前模型结构中不存在或者名称不匹配。- 第二个返回值是一个空列表或者包含一些额外信息的列表,这里用下划线
_忽略了它。
print(param_not_load): 打印未能加载的参数名。如果列表为空,表示所有参数都成功加载;如果不为空,列出的参数可能由于各种原因未能加载(例如:模型结构发生变化)。
通过这种方式,你可以从之前保存的检查点中恢复模型的状态,继续进行训练或者进行推理,而不用重新训练模型。加载参数时,确保模型结构与保存检查点时一致,否则可能会出现参数无法加载的情况。
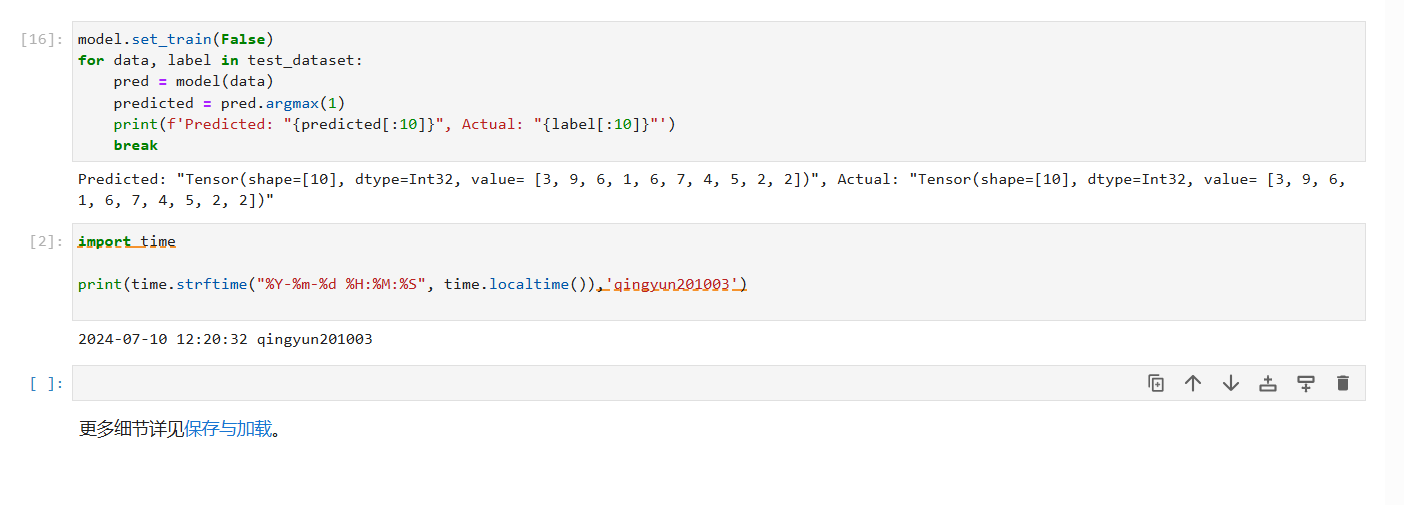
与测试集代码,进行模型预测代码解析
这段代码展示了如何切换模型到评估模式,并使用模型进行预测。代码中的每一步都执行特定的操作来处理测试数据集并输出预测结果和实际标签。以下是对这段代码的详细解释:
model.set_train(False) # 将模型设置为评估模式。
for data, label in test_dataset: # 遍历测试数据集的每一个批次。
pred = model(data) # 使用模型对输入数据进行预测。
predicted = pred.argmax(1) # 获取预测结果中每个样本的最大值索引,这个索引通常对应于分类任务中的预测类别。
print(f'Predicted: "{predicted[:10]}", Actual: "{label[:10]}"') # 打印前10个预测结果和实际标签。
break # 只处理一个批次,所以在处理完第一个批次后就跳出循环。
- 设置模型为评估模式:
model.set_train(False)
在模型评估阶段,通常需要关闭一些训练时特有的方法,比如 Dropout 和 Batch Normalization 的更新。set_train(False) 方法将模型设置为评估模式,以确保这些特性在预测时被禁用。
- 遍历测试数据集:
for data, label in test_dataset:
这行代码遍历测试数据集中的每个批次。test_dataset 是一个迭代器,它每次返回一对数据(data)和对应的标签(label)。
- 进行预测:
pred = model(data)
使用模型对输入的批次数据(data)进行预测,返回预测结果 pred。
- 获取预测类别:
predicted = pred.argmax(1)
pred.argmax(1) 获取预测结果中最大值的索引,这通常代表分类任务中的预测类别。argmax(1) 表示在每个样本的预测结果中选择最大值的索引。
- 打印预测结果和实际标签:
print(f'Predicted: "{predicted[:10]}", Actual: "{label[:10]}"')
打印前10个预测结果和对应的实际标签。这有助于快速检查模型的预测结果是否合理。
- 只处理一个批次:
break
break 语句在处理完第一个批次后跳出循环。如果你想处理整个测试数据集,可以去掉这个 break 语句。
通过这段代码,你可以快速地查看模型在测试数据集上的预测结果,并与实际标签进行比较,从而评估模型的性能。