Java基础
本文章是作者的学习笔记,帮助初学者快速入门,内容讲的不是很细,适合初学者,不定时更新。
目录
- Java基础
- Java高级
- 主流框架和项目管理
- 网络
- <font color="red">如<font color="orange">果<font color="#FFEB05">你<font color="green">也<font color="skyblue">想<font color="blue">学<font color="purple">习<font color="black">:黑客&网络安全的零基础攻防教程
❤🧡💛💚💙💜🤎🖤🤍💔❣💕💞💓💗💖💘💝💟 🫀👫💑💏💋♥😍😘😻🏩💒💌დღ♡❣❤❥❦❧♥
数据类型
1.基本类型(primitive type)
1-1 整数类型
byte占一个字节 short占两个字节
int占四个字节⭐常用
long占八个字节(long类型要在数字后面加L)
1-2 浮点类型
(1)float占四个字节(float类型要在数字后面加F)
(2)浮点数是约莫类型(x过大时,结果无限接近但不等于x)
因此用float和double比较,会出现错误。
⭐(1)银行运算不用浮点数,而使用BigDecimal等(数学工具类)
double占八个字节⭐常用
1-3 字符类型
char占两个字节
1-4 boolean类型
true 和 false
2.引用数据类型
⭐==和equals的区别
String str1 = "hello";//常量池,String是用final修饰的常量类型
String str2 = new String("hello");//实例化的String对象,在堆内存,引用在栈内存
String str3 = str2;//引用传递,传递的是引用地址(栈)
str1 == str2;//false
str1 == str3;//false
str2 == str3;//true
//equals本身和==没有区别,但是String类重写了equals方法,所以这个equals实际上是比较两个值的内容,地址不比
(1)类Class
(2)接口interface
(3)数组引用
3.类型转换
3-1 内存溢出和强制转换
(1)byte的取值范围:-128~127
int i = 128;
⭐byte b = (byte)i;//此处内存溢出,变成-128
(2)(类型)+变量名=强转(高到低)
3-2 自动类型转换
低到高的转换他会自动转换
⭐转换优先级:
低 ------------------------------------------- 高
byte,short,char→int→long→float→double
⭐注意:(1)不能对布尔值进行转换
(2)不能把对象转换为不相干的类型
(3)精度丢失(转换时默认向0取整)
比如:(int)23.7 = 23 (int)-45.89f = -45
变量
1.类变量(静态变量)
static关键词(全局的,静态的)
2.实例变量
(1)从属于对象,使用需要实例化类
(2)如果不进行初始化,则它的值为这个类型的默认值(0,0.0)
3.局部变量
(1)必须声明和初始化值
4.常量
定义:常量是一种特殊的变量,初始化(initialize)之后不会变动
final 常量名 = 值;
运算符
(1)基本运算符(略)
(2)自增自减(略)
(3)位运算符(略)
(4)⭐三元运算符
x ? y : z
如果x==true,则结果为y,否则结果为z
顺序结构与循环
1-1 if选择结构
略
1-2 Switch选择结构
(2)switch高级应用
多条件
switch(grade){
case 'A':
case 'B':
System.out.println("shit");
break;
default:
System.out.println("什么都没有")
}
1-3 While循环
while(i<=100){
//计算1+2+3+...+100
sum+=i;
i++;
}
do-while循环
⭐区别:do-while至少执行一次,因为他是先执行后判断。
1-4 For循环详解
for(初始化;布尔表达式;更新){
//代码语句
}
(0)增强for循环
for(局部变量:访问数组名){
}
for(int a;aList){
System.out.println("a="+a)
}
(1)break
强行退出此次循环。
(2)continue
只用于循环语句中。
用于终止某一次循环过程,直接进行下一次循环。
(3)goto
在break或者continue后加label,不要求掌握,比较麻烦
方法
1-1 可变参数
在定义方法时,在最后一个形参后加上三点 … 就表示该形参可以接受多个参数值,多个参数值被当成数组传入。上述定义有几个要点需要注意:
- 可变参数只能作为函数的最后一个参数,但其前面可以有也可以没有任何其他参数
- 由于可变参数必须是最后一个参数,所以一个函数最多只能有一个可变参数
- Java的可变参数,会被编译器转型为一个数组
- 变长参数在编译为字节码后,在方法签名中就是以数组形态出现的。这两个方法的签名是一致的,不能作为方法的重载。如果同时出现,是不能编译通过的。可变参数可以兼容数组,反之则不成立
⭐简单来说,你就把他看成数组就行了
1-2 递归
递归包含以下两个部分
⭐递归头:表示什么时候不调用自身方法。如果没有头就会死循环
⭐递归体:表示什么时候需要调用自身方法
public static void main(String[] args){
System.out.println(f(4));
}
public static int fuck(int n){
if(n==1){//递归体,表示什么时候需要递归
return 1;
}else{//递归头,也就是递归的结束条件
return n*f(n-1);
}
}
1-3 异常
https://www.runoob.com/java/java-exceptions.html
1-4 方法的调用
静态方法隶属于类,非静态方法隶属于对象
1-4-1 静态方法
调用形式:类名.方法名
1-4-2 非静态方法
先实例化
Student student = new Student
调用形式:对象名.方法名
1-4-3 形参
形参不同于实参,他只是一个做事的临时工具,而并不是这件事的组成部分。
↓↓↓↓↓↓↓↓↓↓↓
1-4-4 引用传递
当形参是一个对象的时候,传参传递的是引用的地址
public class Demo{
public static void main(String[] args){
Person person = new Person();
System.out.println(person.name);//null
Demo.change(person);
//调用同类型方法,需要用类名.方法名
//因为都是静态方法可以直接调用,非静态方法需要new
System.out.println(person.name);//sb
}
public static void change(Person person){
//person是一个对象:指向的↓
//Person person = new Person();这是一个具体的人,可以
person.name = "sb";
}
}
//定义了一个Person类,有一个属性:name
class Person{
String name;//null
}
1-5 构造方法
在类创建的时候默认会创建一个构造方法
特点:1.必须和类名相同
2.必须没有返回类型,也不能写void
Person p = new Person();//Person()就是构造方法
作用:1.实例化初始值
public Person()//无参构造
this.name = "liubei";
}
2.使用new关键字,必须要有构造器
public Person(String name){//有参构造
this.name = name;//this.name是对象的name。后面的name是传的形参。
}
⭐注意:一旦定义了有参,无参也必须显示定义
数组
1-1 数组的创建方式
dataType[ ] arrayRefVar = new dataType[ arraySize ];//⭐常用
dataType arrayRefVar[ ];
1-2 数组的遍历方式
(1)for-each循环
int[] arrays = {1,2,3,4,5};
for(int array:arrays){//这里的数组不需要加[]
System.out.println(array);//但这里没有带下标
}
//如果我们要打印数组的元素则用下面的方法
public static void printArray(int[] arrays){
for(int i=0;i<arrays.length;i++){
System.out.print(array[i]+"");
}
}
1-3 冒泡排序
public static void main(String[] args){
}
public static int[] pao(int[] array){
//int临时变量
int temp = 0;
for(int i=0;i<array.length();i++){
for(int j=0;j<array.length()-1-i;j++){
if(array[j]<array[j+1]){
temp=array[j];
array[j]=array[j+1];
array[j+1]=temp;
}
}
}
}
冒泡排序的时间复杂度为O(n2);//这里的n2指两次有关长度的操作
1-4 稀疏数组
处理方式:
1.记录数组一共有几行几列,有多少个不同的值
2.把具有不同值的元素和行列及值记录在一个小规模的数组中
面向对象
(OOP)Object-Oriented Programming
面向过程思想:
1.步骤清晰简单,第一步干啥,第二步干啥
2.面对过程适合处理一些简单的问题,比如烧水..
⭐面向对象思想:
1.物以类聚,**分类** 的思维模式。各部门分工合作,大块分小块。
2.面向对象适合处理复杂的问题,适合处理需要多人合作的问题。
⭐本质
面向对象编程的本质就是:以类的方式组织代码,以对象的组织(封装)数据。
高内聚,低耦合。
创建对象内存分析:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Jzze5tb6-1631855103577)(https://edu-10121.oss-cn-beijing.aliyuncs.com/MyJavaStudyImg/A](D_T((E6)]6GCM`[TG53%4.png)
栈相当于目录,堆相当于内容。每当你new一个对象,都是属于“目录”某个章节的一页。比如你new一个“男人”,就是“人”这一章节的其中一页。对象是用过引用来操作的,由栈指向堆
1-1封装
重点:属性私有化。get、set
1-2继承
extends 子类继承父类的所有属性方法,但是私有属性方法无法被子类访问
减少重复代码,维护性提高,提高代码复用性,代码更简洁
继承的缺点:提高了耦合性,面向对象要求低耦合
1-2-1 super关键字
super只能出现在子类的方法或者构造方法中。
super.属性名/方法名 (用来调用父类的属性或方法)
子类默认会调用父类的无参构造函数super()😭在第一行调用)
如果没有无参构造调用有参构造也可以。
⭐注意:不能与this同时用来调用构造方法
1-3多态
Student s1 = new Student();
Person s2 = new Student();
Object s3 = new Student();
//引用类型可以是父类,实际类型是确定的 new Student
⭐多态是方法的多态,属性和变量没有多态
⭐简单来说,静态看左,非静态看右(静态方法不能被重写)
原理:向上转型,里式代换原则(LSP)dd
ps:向下转型则是强制转换: 子类 子类的对象 = (子类)父类的对象
1-3-1 方法重写
⭐重点:父类的引用指向子类的对象
示例:1个行为,不同的对象,他们具体体现出来的方式不一样,
比如: 方法重载 overloading 以及 方法重写(覆盖)override
class Human{
void run(){输出 人在跑}
}
class Man extends Human{
void run(){输出 男人在跑}
}
这个时候,同是跑,不同的对象,不一样(这个是方法覆盖的例子)
class Test{
void out(String str){输出 str}
void out(int i){输出 i}
}
这个例子是方法重载,方法名相同,参数表不同
ok,明白了这些还不够,还用人在跑举例
Human ahuman=new Man();
这样我等于实例化了一个Man的对象,并声明了一个Human的引用,让它去指向Man这个对象
意思是说,把 Man这个对象当 Human看了.
比如去动物园,你看见了一个动物,不知道它是什么, "这是什么动物? " "这是大熊猫! "
这2句话,就是最好的证明,因为不知道它是大熊猫,但知道它的父类是动物,所以,
这个大熊猫对象,你把它当成其父类 动物看,这样子合情合理.
这种方式下要注意 new Man();的确实例化了Man对象,所以 ahuman.run()这个方法 输出的 是 "男人在跑 "
如果在子类 Man下你 写了一些它独有的方法 比如 eat(),而Human没有这个方法, 在调用eat方法时,一定要注意 强制类型转换 ((Man)ahuman).eat(),这样才可以... 对接口来说,情况是类似的...
1-4 抽象
⭐抽象类:只有方法的名字,没有方法的实现。
继承了抽象类的子类,都必须实现抽象类的所有方法。
1-5 接口
⭐接口(Interface)只有规范
接口中所有的方法都是**公共(public)且抽象(abstract)**的
只写返回值类型和方法名就行了。
⭐类可以实现接口
1.implements关键字(实现)
2.接口可以多继承(extends)
3.实现了接口的类,需要实现接口中的所有方法。
1-6 内部类
public class hh{
int a = 0;
class int xx{
System.out.println(a);//内部类可以用外部的属性和方法
}
}
集合
⭐hashCode与equals的区别:
hashCode相等,对象值不一定相等

数组存在很多缺点,比如:
1.长度开始时必须指定,而且一旦指定不能更改
2.保存的为同一类型的值 3.代码比较繁琐
于是,集合他来了

Collection 接口的实现子类:单列集合,存放单个数据
Map 接口的实现子类: 双列集合,键值对形式
⭐Map的实现子类还有Hashtable,Properties是Hashtable的实现子类
⭐List的实现还有Vector
1-1 迭代器
Collection中的Iterator用于遍历集合
(1)hasNext()方法,判断后面是否还有元素。
(2)next()方法,下移并将下移之后集合位置上的元素返回。
⭐用next()之前必须用hasNext(),不然会抛出异常NoSuchElementException
while(iterator.hasNext()){
Object obj = iterator.next();//下移并将下移之后集合位置上的元素返回。
System.out.println(obj);//输出next()方法返回
}
1-2 List
- HashCode的特性
(1)HashCode的存在主要是用于查找的快捷性,如Hashtable,HashMap等,HashCode经常用于确定对象的存储地址;
(2)如果两个对象相同, equals方法一定返回true,并且这两个对象的HashCode一定相同;
(3)两个对象的HashCode相同,并不一定表示两个对象就相同,即equals()不一定为true,只能说明这两个对象在一个散列存储结构中。
(4)如果对象的equals方法被重写,那么对象的HashCode也尽量重写。
本文原创,转载请注明出处:http://blog.csdn.net/seu_calvin/article/details/52094115
- HashCode作用
Java中的集合有两类,一类是List,再有一类是Set。前者集合内的元素是有序的,元素可以重复;后者元素无序,但元素不可重复。 equals方法可用于保证元素不重复,但如果每增加一个元素就检查一次,若集合中现在已经有1000个元素,那么第1001个元素加入集合时,就要调用1000次equals方法。这显然会大大降低效率。 于是,Java采用了哈希表的原理。
哈希算法也称为散列算法,是将数据依特定算法直接指定到一个地址上。这样一来,当集合要添加新的元素时,先调用这个元素的HashCode方法,就一下子能定位到它应该放置的物理位置上。
(1)如果这个位置上没有元素,它就可以直接存储在这个位置上,不用再进行任何比较了;
(2)如果这个位置上已经有元素了,就调用它的equals方法与新元素进行比较,相同的话就不存了;
(3)不相同的话,也就是发生了Hash key相同导致冲突的情况,那么就在这个Hash key的地方产生一个链表,将所有产生相同HashCode的对象放到这个单链表上去,串在一起。这样一来实际调用equals方法的次数就大大降低了,几乎只需要一两次。
int indexOf(obj);//返回obj在集合中第一次出现的位置(int)
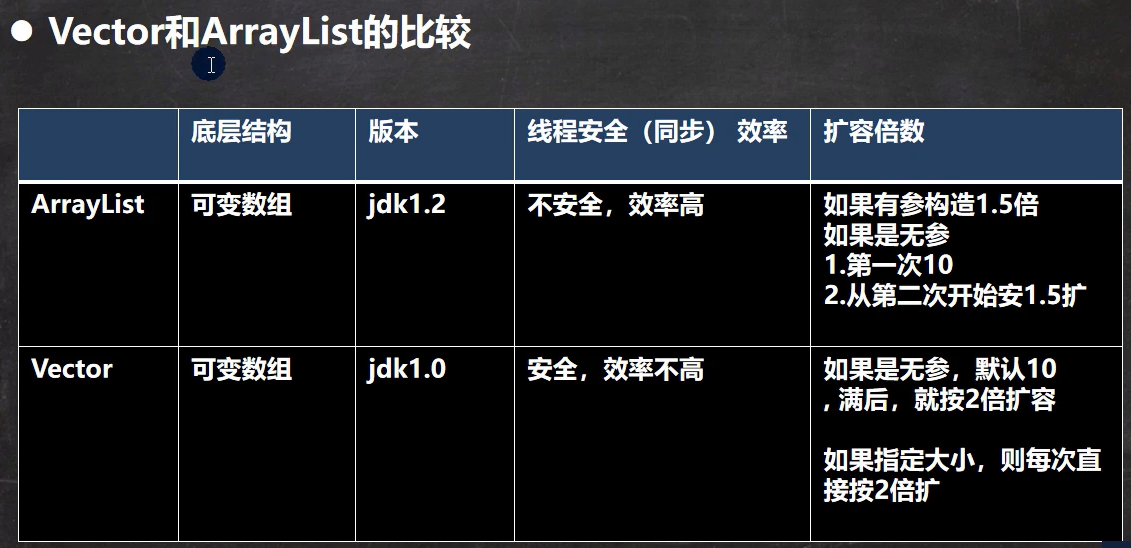
1-2-1 ArrayList
是线程不安全的,可以看源码,没有synchronized,所以多线程不用ArrayList,可以考虑用Vector
底层结构:
(1) ArrayList中维护了一个Object类型的数组elementData.
transient Object[] elementData;//transient 表示瞬间的,短暂的。表示该属性不会被序列化。
(2) 当创建ArrayList对象时,如果使用的是无参构造器,则初始elementData容量为0,第1次添加,扩容为10,如需要再次扩容,则扩容为1.5倍
//0->第一次10->第二次15->第三次22,以此类推
(3) 如果使用的是指定int大小的构造器,那么elementData初始容量为指定的int值,如果要扩容,则扩容为1.5倍
//你指定的int值->int*1.5
源码:
public boolean add(E e){//e:1
//执行list.add,先确定是否要扩容
ensureCapacityInternal(size + 1);
//然后再执行赋值
elementData[size++] = e;
return true;
}
private void ensureCapacityInternal(int minCapacity){
//用来确认最小容量
//首次确认最小容量
if(elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA){
minCapacity = Math.max(DEFAULT_CAPACITY,minCapacity);
//比较默认值与最小值1,然后将其大值赋给minCapacity
}
ensureExplicitCapacity(minCapacity);//继续确认最小容量
}
private void ensureExplicitCapacity(int minCapacity){
//确认完最小容量然后进行判断
modCount++;//记录集合被修改的次数
if(minCapacity - elementData.length>0)//判断容量够不够
grow(minCapacity);//进行扩容,使用的copyof
}
1-2-2 Vector
Vector是线程安全的。它的方法带有synchronized
1-2-3 LinkedList
(1) LinkedList底层维护了一个双向链表
(2) LinkedList中维护了两个属性 first 和 last 分别指向 首节点 和 尾结点
(3) 每个结点里面又维护了三个属性prev,next,item,其中通过next指向后一个节点的地址,prev指向前一个地址。数据的添加不是通过数组完成,无需扩容,所以相对效率高。
底层逻辑:
首先是新建一个Node结点,有三个属性。只有一个值得时候,prev和next都是null
只有item值并且first和last都指向这个Node结点。
有多个结点时,第一个加入的使它等于first,最后一个使它等于last,前后根据prev和next来指向地址,形成双向链表
添加
void linkLast(E e){//Node添加的底层
final Node<E> l = last;
final Node<E> newNode = new Node<>(l,e,null);
//新建一个Node
last = newNode;//管他三七二十一,先把最新的这个Node设为last
if(l == null)//如果这个Node是第一个(null)那就把他设为first
first = newNode;
else
l.next = newNode;//如果这个Node不是第一个,就吧上一个的next指向这个Node
size++;//结点+1
modCount++;//运行计数+1
}
删除
private E unlinkFirst(Node<E>f){//例子:删除第一个
final E element = f.item;
final Node<E> next = f.next;
f.item = null;
f.next = null;
first = next;
//此时原先的第一个结点就变成了孤儿,等待被垃圾回收!
if(next == null)
last = null;
else
next.prev = null;
size--;//结点-1
modCount++;//运行计数+1
return element;
}
1-2-4 List集合选择

1-3 Set
1.set接口对象(接口的实现类的对象),不能存放重复的元素,可以放null
2.set接口对象存放数据是无序的
3.取出对象的顺序虽然不是添加的顺序,但是他是固定的,不会存在第一次第二次取出不一样顺序的情况
1-3-1 HashSet
add()方法执行时会返回一个boolean
set.add("liubei");//true
set.add("liubei");//false,常量池重复
set.add(new Dog("wangcai"));//true
set.add(new Dog("wangcai"));//true,开辟一个新地址,HashCode不一样
⭐面试题
set.add(new String("lsp"));//true
set.add(new String("lsp"));//false
/*以这种方式赋值时,JVM会先从字符串实例池中查询是否存在"lsp"这个对象,
若不存在则会在实例池中创建"lsp"对象,同时在堆中创建"lsp"这个对象,然后将堆中的这个对象的地址返回赋给引用str。
若实例池存在则直接在堆中创建"test"这个对象,然后将堆中的这个对象的地址返回赋给引用str。*/
底层:HashMap,而HashMap的底层是(数组+链表+红黑树)
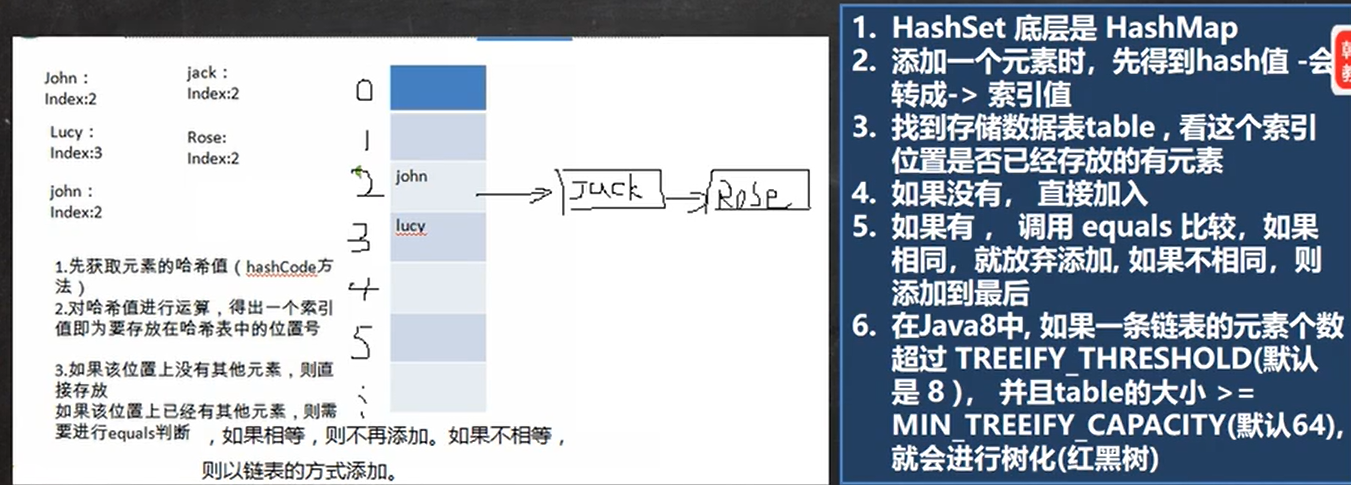
为什么相同的元素就加不了呢?
他有一个hash()和equals()两个方法,用来比较相同的元素,两个方法都成立时,则不允许你的元素添加。
源码:
1.add
(1)执行hashSet()
public HashSet(){
map = new HashMap<>()
}
(2)执行add()
public boolean add(E e){//E是泛型,e是我们输入的对象
return map.put(e,PRESENT)==null;//PRESENT是固定对象
}
(3)执行put(),该方法会执行hash(key)得到key对应的哈希值
public V put(K key,V value){
return putVal()
}
(4)HahMap下面新建一个table数组(是Node[]类型的),然后将hash值,key(你输入的值),value(地址),next=null放入这个table对应的位置。
执行前面两个if语句,如果当前table是null或者大小为0.进行第一次扩容到16。
(5)添加失败的情况:
前面两个if语句是false,然后执行else
final V putVal(int hash,K key,V value,boolean onlyIfAbsent,boolean evict){
Node<K,V>[] tab;Node<K,V> p;int n, i;
if((tab = table)==null||(n=tab.length)==0)
n=(tab=resize()).length;
if((p=tab[i=(n-1)&hash])==null)
tab[i] = newNode(hash,key,value,null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k) )))
//这里的p指向数组链表第1个位置上的结点,如果这次要加的key对象和p指向的这个Node里面的key和hash值一样并且:(两个key是同一个对象或者equals返回true) 那就不能加入。
e = p;
//如果false再判断是不是红黑树,是就调用putTreeVal
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
//和对应那个链表的每个值比较,如果没有这个值就丢在链表
//在添加元素到链表之后,立即判断是否有八个结点,如果有八个就调用treeufyBin()对当前链表树化(树化过程有很多判断)
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
1-4 Map
核心:key-value键值对
1.Map中的key和value可以是任何引用类型的数据,最终会封装到HashMap$Node对象中
HashMap$Node node = new Node(hash,key,value,null);
2.k-v为了方便程序员的遍历,还会创建EntrySet集合,该集合存放的元素类型是Entry,一个Entry包含k,v EntrySet<Entry<K,V>>
3.entrySet中,定义的类型是Map.Entry,但是实际上存放的是HashMap$Node.
为什么?因为HashMap$Node实现了Map.Entry接口,这就是接口的多态!!!
父类的引用(Map.Entry)指向子类的对象(HashMap$Node)
map.put("Number1","hh");
map.put("Number1","xx");
//输出xx,因为有相同的key时,value会替换
注意:Key可以为空,但只能有一个null,value也可以为null。常用String类作为key
⭐总结:HashMap里面有一个table一个entrySet集合,table用来装Node结点,而每个Node的key和value会被封装成entry对象放到entrySet集合中去,而entrySet看似存放的是Map.Entry,其实是HashMap N o d e 因为 H a s h M a p Node因为HashMap Node因为HashMapNode实现了Map.Entry,存的东西说白了就是table中Node结点的引用对象。
1-4-1 HashMap
HashMap的扩容机制:
1.第一次添加,需要扩容为16,临界值为12(16*0.75=12)
2.以后在扩容,扩容table为原来的2倍,临界值为之前的2倍,24,以此类推
3.java8以后如果一跳链表元素超过TREEIFY_THRESHOLD(默认8),并且table大小大于等于MIN_TREEIFY_CAPACITY(默认64),就会树化增加效率。
1-4-2 HashMap和HashTable的区别和底层实现
HashMap线程不安全,HashTable线程安全。HashMap允许k和v为空,HashTable不许。
HashTable相当于给所有方法加了synchronized关键字,效率低,于是乎我们现在一般用ConcurrentHashMap
底层实现:
数组+链表+红黑树
JDK8开始链表高度到8,数组长度超过64,链表转化为红黑树,元素以内部类结点Node形式存在。
(1)计算key的hash值,然后二次hash对数组长度取模,然后给他在数组安排位置,没有hash冲突,就直接将数据存为一个Node
(2)如果产生冲突,则进行equals比较,相同则取代,不同,则判断链表高度插入链表,链表高度达到8,并且数组64则变为红黑树,长度低于6又会变回链表
(3)扩容因子:为什么是0.75?这里回答一下取其他值的缺点就行了:
如果是0.5 ,每次水加到一半就增加杯子的大小,那杯子的空间利用率肯定会越来越小。 如果是1,每次水装满再增加杯子的大小,那肯定会浪费时间(装满了就不能装了,只能等你先增加杯子的大小)
泛型
相当于给你限定一个数据类型E,这个E可以是String,int等,一旦限定,这个参数以后传的就只能是你限定的类型
反射
1-1 反射入门方法
反射(java.lang.reflect)就是还没有new的时候,就可以使用这个类,相当于一个镜子
从这个简单的例子可以看出,一般情况下我们使用反射获取一个对象的步骤:
1.获取类的 Class 对象实例
Class clz = Class.forName("com.zhenai.api.Apple");//Class对象(java.lang.Class)表示某个类加载后在堆中的对象,就是这个com.zhenai.api.Apple
2.根据 Class 对象实例获取 Constructor 对象
Constructor appleConstructor = clz.getConstructor();
3.使用 Constructor 对象的 newInstance 方法获取反射类对象
Object appleObj = appleConstructor.newInstance();
4.而如果要调用某一个方法,则需要经过下面的步骤:
获取方法的 Method 对象
Method setPriceMethod = clz.getMethod("setPrice", int.class);
利用 invoke 方法调用方法
setPriceMethod.invoke(appleObj, 14);
1-2 优点和缺点
反射的优点:
可以动态创建和使用对象(也是框架底层核心),使用灵活
反射的缺点:
使用反射基本是解释执行而不是编译执行,对执行速度有影响.(编译快)
//传统方法调用方法
public void hh(){
Man man = new Man();
long start = System.currentTimeMillis();
for(int i=0;i<100000;i++){
Man.fuck();
}
long end = System.currentTimeMillis();
System.out.println(end-start);
}
//反射的方法
public void hh2() throws Exception{
Class cls = class.forName("com.yc.Man");
Object o = cls.newInstance();
Method fuck = cls.getMethod("fuck");
long start = System.currentTimeMillis();
for(int i=0;i<100000;i++){
fuck.invoke(o);
}
long end = System.currentTimeMillis();
System.out.println(end-start);
}
//很明显,普通方法0ms,反射需要几百到几千ms
//如何优化?用setAccessible禁用访问安全检查,速度就会快很多
fuck.setAccessible(true);
fuck.invoke(o);//true表示禁用
1-3 Class 类
//Class类对象不是new出来的,而是系统创建的
不管是传统方法还是反射方式
都是通过ClassLoader来加载类的Class对象
//某个类的Class类对象,在内存中只有一个,因为类只加载一次,这个对象存在堆
1-3-1 获取Class的几种方式
1.配置文件,读取类全路径,加载类
Class cls1 = Class.forName("java.lang.xx");
2.参数传递,用反射获得构造器等
Class cls2 = xx.class;
3.通过创建好的对象,获取Class对象
XX xx = new XX();
Class cls3 = xx.getClass();
4.其他
四种类加载器去JVM看
1-4 动态和静态加载
1.静态加载(普通):编译时就加载相关的类,如果没有则报错,依赖性强
2.动态加载(反射):运行时并执行到相应代码的时候才加载相关的类
switch(key){
case"1":
Dog dog = new Dog();
dog.cry();
break;
//静态加载
//你只要运行就会报错,因为没有Dog这个类
case"2";
Class cls = Class.forName("Person");
Object o = cls.newInstance();
Method m = cls.getMethod("hi");
m.invoke(o);
break;
//动态加载
//除非你代码走到case"2"不然不会报错
default:
}
1-5 获取类的结构信息
1-6 通过反射爆破创建对象
1.调用类中的public修饰的无参构造器
2.调用类中的指定构造器
3.Class类相关方法
newInstance:调用类中的无参构造器,获取对应类的对象
getConstructor:根据参数列表,获取对应public构造器的对象
getDecalaredConstructor:根据参数列表,获取所有对应构造器对象
⭐4.Constructor类相关方法
⭐setAccessible:爆破
Constructor<?> c1 = userClass.getDecalaredConstructor(int.class,String.class);
c1.setAccessible(true);//爆破,暴力破解使反射可以访问private构造器
Object user2 = c1.newInstance(100,"张三丰");
newInstance(Object…obj):调用构造器
动态代理
IO
文件:保存数据的地方
File file = new File(parentFile,fileName);
//相当于在内存创建了一个对象
file.createNewFile();
//真正把对象创建到硬盘中
1-1 IO流原理
输入input: 读取外部数据(磁盘、光盘等存储设备的数据)到程序(内存)中。
输出output: 将程序(内存)数据输出到磁盘、光盘等存储设备中。
1-2 流的分类
| 抽象基类 字节流 字符流 | ||
|---|---|---|
| 输入流 InputStream Reader | ||
| 输出流 OutputStream Writer |
1-2-1 InputStream
read()方法用来输入
1-2-2 OutputStream
write()方法用来输出
FileOutputStream f = null;
try{
f = new FileOutputStream(filePath);
// = new FileOutputStream(filePath,true);这种方式会追加到文件后面而不是覆盖文件
String str="你是个渣渣";
f.write(str.getBytes(),0,3);//getBytes可以将字符串转换为字符数组
}
catch(IOException e){
}
1-3 文件拷贝
//关键代码
String firstPath = "e:\\1.png";
String lastPath = "d:\\2.png";
FileInputStream fileInputStream = null;
FileOutputStream fileOutputStream = null;
fileInputStream = new FileInputStream(firstPath);
fileOutputStream = new FileOutputStream(lastPath);
//定义一个字节数组,提高效率
byte[] buf = new byte[1024];
int readLen = 0;
while ((readLen = fileInputStream.read(buf))!= -1) {
fileOutputStream.write(buf);//一定要写这个方法
}
System.out.println("拷贝完毕");
if(fileInputStream==null) {
fileInputStream.close();
}
if(fileOutputStream==null) {
fileOutputStream.close();
}
1-4 文件字符流

输入流和字节流一样的玩法
1-5 节点流/处理流
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xmGbevhk-1631855103602)(…/Images/java/8.png)]
1-5-1 BufferedReader
BufferedReader中,有属性Reader,即可以封装一个节点流,该节点流可以是任意。只要是Reader的子类。
public class BufferedReader extends Reader{
private Reader in;
private char cb[];
}
1-5-2 两者关系
1.节点流是底层流/直接根数据源相连
2.处理流包装节点流,即可以消除不同节点流的实现差异,也可以提供更方便的方法来完成输入输出
3.处理流对节点流进行包装,使用了修饰器设计模式,不会直接与数据源相连
1-6 BufferedReader
String filePath = "e:\\a.java";
//创建bufferedReader
BufferedReader br = new BufferedReader(new FileReader(filePath));
//读取
String line;//按行读取,效率高
//readLine()是按行读取,当返回null时,表示文件读取完毕
while((line = bufferedReader.readLine())!=null){
System.out.println(line);
}
//关闭流,这里注意,只需要关闭br,因为底层会自动关闭节点流
bufferedReader.close();
数据库
Redis
1.Nosql
刚开始所有机子都是用的单机mysql
后来为了减轻服务器压力开始改变!
Nosql = Not Only SQL,redis是其中发展最好的
1-1 索引
索引是帮助MySql高效获取数据的排好序的数据结构
1-1-1.引入缓存
Memcached(缓存)+垂直拆分+MYSQL
1-2-1.分库分表+水平拆分+MYSQL集群
有些不会改动的数据,把他放到A集群数据库中,只需要读一次,给他存到缓存里面,要改的东西放在B,C等集群数据库中。
MYISAM存储引擎索引实现:表锁,每次查东西要锁一个表,效率很低
Innodb存储引擎索引实现:行锁,效率问题解决了
数据库不同的引擎,存储的数据库表文件形式不同
以innoDB引擎举例:
test.frm文件存表结构 & innoDB.ibd文件存数据和索引文件
innoDB(聚集索引,因为他的数据和索引都存在ibd文件中,而其他引擎是分开存的,所以他遍历最方便)的存储结构就是B+树
为什么innoDB表必须有主键,并且推荐自增
B+树(多叉平衡树)
(1)非叶子节点不存储data,只存储索引(冗余),可以放更多的索引
(2)叶子节点包含所有索引字段
(3)叶子节点用指针连接,提高区间访问的性能
B+树的叶子节点用指针连接,提高区间访问的性能
我们知道HashMap的底层在最新的jdk里面加入了红黑树,为什么我们数据库不用红黑树?
首先,红黑树(根是黑色,叶子是黑色,每个红色节点必须有两个黑色子节点)的底层数据结构是一种自平衡二叉查找树,典型的用途是实现关联数组,对于插入密集型使用红黑树,对于查找密集型,使用AVL树
2.Nosql四大分类
KV键值对:
*新浪:redis
*美团:redis+tair
*阿里:redis+memecache
文档型数据库(bson格式,和json一样):
(1)MongoDB(一般必须要掌握)
是一个基于分布式文件存储的数据库,由C++编写,用来处理大量的文档
是一个介于关系型数据库和非关系型数据库的中间产品,它是非关系型数据库中功能最丰富,最像关系型数据库的。
3.redis基本数据类型
redis(Remote Dictionary Server),远程字典服务
redis默认16个数据库(0~15),默认使用第0个
select x//切换为第x个数据库
keys * //查看所有key值
flushdb//删库,别乱用
set 变量名 变量值//
exists name//检查name是否存在
move name//移出
expire name time//数据存放time秒
type name//查看name的类型
incr name//使name+1
decr name//使name-1
🧡redis是单线程的,因为它基于内存操作,cpu不是redis性能瓶颈,redis的瓶颈是内存和网络带宽。
redis是c语言写的,官方提供的数据为十万+的QPS(每秒查询率),比Memecache还厉害
String类型
# setex //(set with expire)设置过期时间
# setnx//(set if not exist)不存在则设置,可用于分布式锁
#msetnx //是一个原子性操作,要么一起成功要么一起失败
# getset xx yy//如果不存在xx则返回nil然后创一个xx值为yy
//如果存在值,则返回原来的值,并设置新值yy
List类型
# LPUSH list one//LPUSH 将一个值或多个值插入列表list头部
# RPUSH//插入在list尾部
#LRANGE list 0 -1//查询list中0位到-1位的值
#LINDEX list 0//获取list中某一位的值
两边插入效率高,中间效率会低一点
Set类型
和List一样,命令以S开头
Hash类型
就是Map集合,key-value,命令以H开头
Zset有序集合
在Set集合的基础上,增加了一个值
Zset有多种排序的方法
4.redis特殊数据类型
geospatial 地理位置
5.事务
事务的本质:是一组命令的集合。一个事务中的所有命令都会被序列化,在事务执行过程中,会按照顺序执行。
编译型异常(代码有问题,命令有错),事务中所有命令都不执行(事务单个命令具有原子性,事务不保证原子性,因为事务异常发生后没有回滚!)
运行时异常(命令语法错误)
acid
一次性,顺序性,排他性
127.0.0.1:6379>multi #multi开启事务
ok
127.0.0.1:6379>set k1 v1#向事务加入语句
QUEUED
127.0.0.1:6379>set k2 v2
QUEUED
127.0.0.1:6379>set k3 v3
QUEUED
127.0.0.1:6379>exec #执行事务
127.0.0.1:6379>DISCARD #取消事务,事务队列中的语句都不会执行
127.0.0.1:6379>watch money #监视money对象
Jedis
以前用的
Lettce
现在用的
Java高级
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2o26uv2d-1644913012215)(https://segmentfault.com/img/remote/1460000022180990)]
Spring

1.IOC/DI/AOP
(1)控制反转IOC
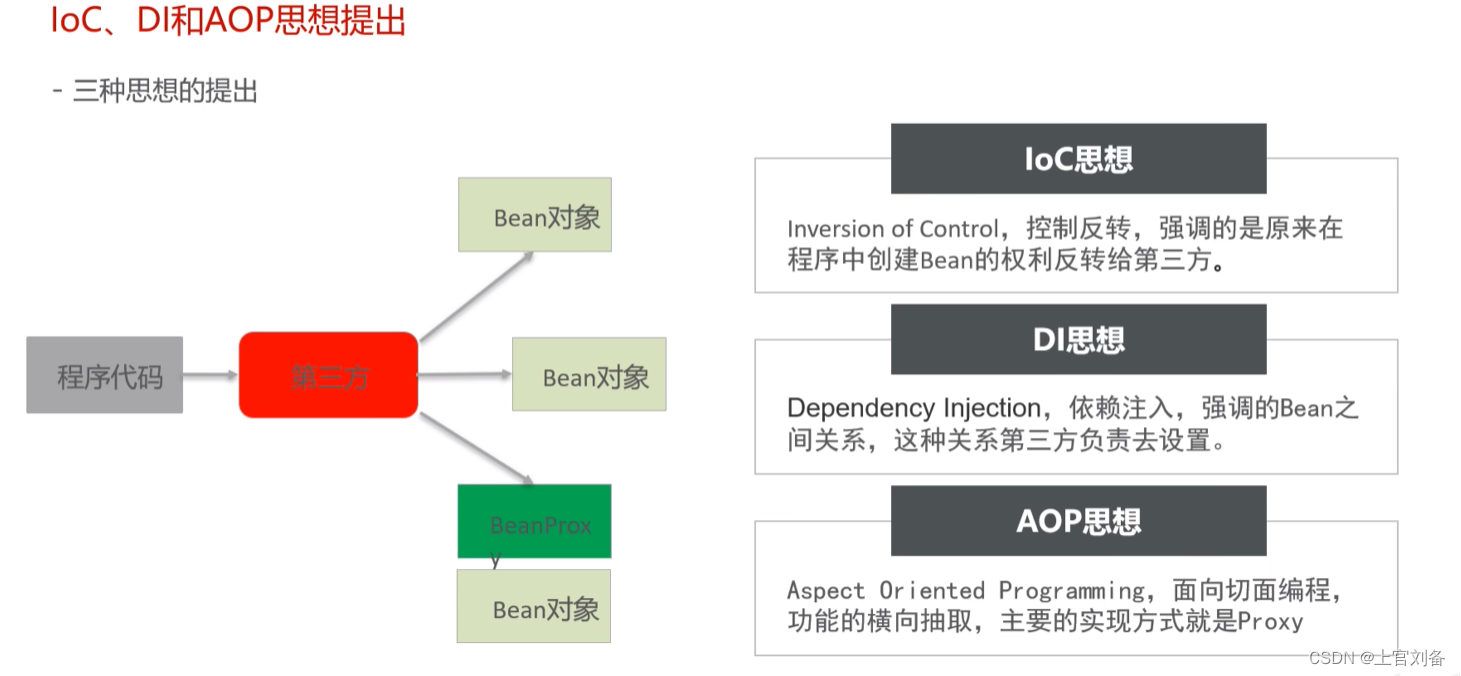
(2)依赖注入DI

步骤1:
UserService userService = new UserService;
for(Field field : userService.getClass().getDeclaredFields()){//遍历获取对象所有的字段
if(field.isAnnotationPresent(Autowired.class)){//判断遍历的对象是否有自动注入关键字
field.set(userService1,??);//如果有则注入值
}
}
那么,问题就来了,这些对象是怎么创建的呢?答案是spring用ApplicationContext.getBean为我们创建的,是注入了值的。(有值的称为bean对象了,他是在实例化后将bean的引用和值注入到bean的属性中)
而简单利用构造器无参构造是没值的

依赖注入之后,把bean对象放入单例池Map中,然后getBean就可以用了,上面因为""里面的名字一样,相当于调用Map里面的同一个对象userService。


JVM虚拟机
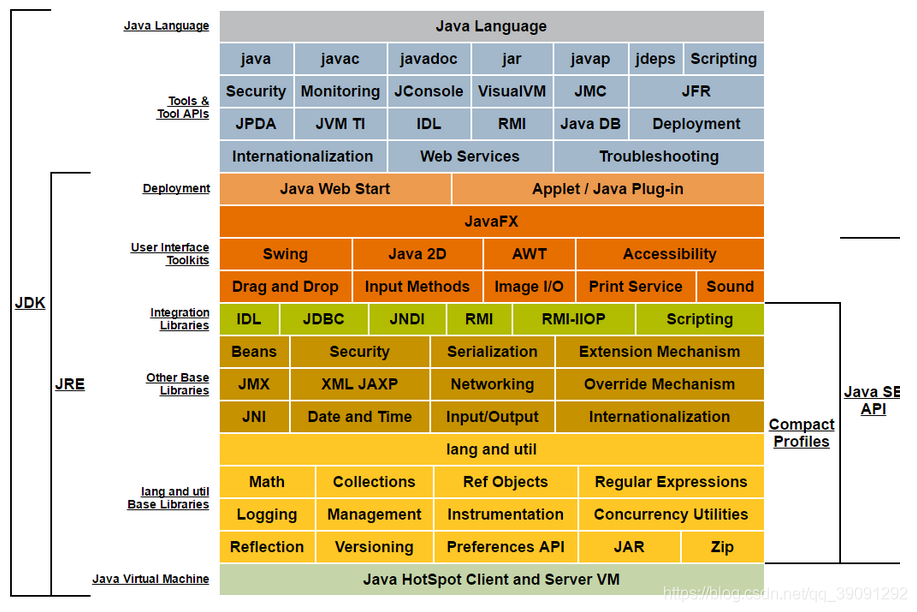
🧡面试题:JDK,JRE,JVM的区别?
JDK:java开发工具:包括JRE和java工具(工具里面有javac)
JRE:java运行时环境 包括jvm和api(api用来解释.class文件)
JVM:java虚拟机(包含在JRE中)

1-1 JVM的位置
JVM包括在JRE中,在操作系统之上。
1-2 类加载

1.加载Loading
在该阶段主要目的是将字节码从不同的数据源(可能是class文件,jar包等)转化为 二进制字节流加载到内存中 ,并生成一个代表该类的java.lang.Class对象
2.连接Linking
(1)验证阶段:
为了确保Class文件中的字节流包含的信息符合当前虚拟机要求,有元数据验证等
(2)准备阶段:
JVM在该阶段对静态变量,分配内存并默认初始化。这些变量所使用的内存都将在方法区中进行分配
class A{
//n1是实例属性,不是静态变量,因此在准备阶段,不会分配内存
//n2是静态变量,分配内存。n2默认为0,而不是20
//n3是final常量,一旦赋值就不会变了,所以默认为30
public int n1 = 10;
public static int n2 = 20;
public sattic final int n3 = 30;
}
(3)解析阶段:
虚拟机将常量池内的符号引用替换为直接引用的过程
a的具体地址指向new出来的堆内存地址
3.Initialization初始化
(1)此阶段,才真正开始执行类中定义的java程序代码,此阶段是执行方法的过程。
(2)()方法:按照语句在文件中出现的顺序,收集整理赋值动作,并进行合并
static{
int num=10;
System.out.println(num);
}
class A{
int num=20;
}
//输出num=20
(3)虚拟机会保证一个类的()方法在多线程环境中被正确的加锁,同步,如果多个线程同时去初始化一个类,那么只会有一个线程去执行这个类的()方法,其他线程都需要阻塞等待,直到活动线程执行完().
⭐可以考虑使用-Xverify:none参数来关闭大多类验证措施
以Car为例子
⭐作用:加载Class文件,初始化生成相应Car Class(相当于一个工厂,用来制造Car类的)相应Class就可以开始实例化对象了
⭐new关键字,底层就是一个LoadClass方法
public Class<?> loadClass(String name)throws ClassNotFoundException{
return loadClass(name,false);
}
⭐反射1-3Class类中的forName方法
对象要变回Class用getClass方法,Class要变回Class Loader用getClassLoader方法
引用在栈,实体在堆:栈存放的是实例,堆存放的是内存地址空间
人住在客栈,人的东西随便放一堆。
扩展:rt.jar是什么,为什么重要?
⭐双亲委派机制(安全)
1.运行一个类之前,类加载器会收到类加载的请求。他会将这个请求向上查找(应用加载器-》扩展加载器-》根加载器)
最终执行最靠近上边的类(比如String类在根加载器,你用String类就是调用的根加载器里面的String,而不是你自己写的)
1-3 沙箱安全机制
(了解)
沙箱机制就是将java代码限定在JVM特定的运行范围中,并且严格限制代码对本地系统资源访问。(保证对代码的有效隔离,防止对本地系统造成破坏)
组成:
字节码校验器:校验字节码,在类加载过程中校验。
⭐扩展>>>>>>编译码校验:在类加载之前校验。
1-4 Native关键字
⭐多线程的start0!!
凡是带了native关键字的,说明java的库作用范围达不到了,就会去调用底层c语言的库
会进入本地方法栈,然后调用:
上面1-1的 本地方法接口(JNI:Java Native Interface)
而JNI的作用就是:扩展Java的使用,融合不同的编程语言(C,C++)为Java所用
所以说本地方法栈就是专门开辟用来调用(C,C++)其他语言的区域
⭐本地方法一般不用,用的最多的本地方法System.currentTimeMillis();
1-5 PC寄存器和方法区
1-5-1 PC寄存器
程序计数器:
每个线程都有一个程序计数器,是线程私有的,就是一个指向方法区中的方法字节码的指针,在执行引擎读取下一条指令
1-5-2 方法区
方法区是被所有线程共享的,所有定义的方法信息都保存在此
⭐静态变量,常量,类信息(构造方法,接口定义),运行时的常量池存在方法区中,但是实例变量存在于堆内存中,和方法区无关
⭐扩展:
元空间不等于方法区,是jdk1.8之后方法区的实现,之前的实现是永久带。字符串常量池以及运行时常量池逻辑上属于方法区,实则属于堆。
1-6 栈与队列
⭐栈:先进后出,对应的线程
队列:先进先出
栈内存:主管程序的运行,生命周期和线程同步(main算作主线程)
因此栈不存在垃圾回收问题(程序结束,栈就拜拜了)
⭐栈帧
Java中的栈帧随着方法调用而创建,随着方法结束销毁,可以理解为分配给方法的一块栈空间,每调用一个方法就创建一个栈帧。
因此,一般我们的main方法的栈帧都在栈底,由于栈是后进先出,所以你现在应该理解为什么main方法最后结束了吧!
因此main方法一般都在栈底,不然会报错StackOverflow
而栈满了也会报此错误
⭐栈主要存放:八大基本类型,引用数据类型等…
⭐为什么java数据要分类型?
引用类型在堆里,基本类型在栈里。
栈空间小且连续,往往会被放在缓存。引用类型cache miss率高且要多一次解引用。
对象还要再多储存一个对象头,对基本数据类型来说空间浪费率太高
1-7 堆!
Heap,一个JVM只有一个堆内存,堆内存的大小是可以调节的
存储的全部是对象,每个对象包含一个与之对应的class信息–class的目的是得到操作指令。
对象在内存中的存储布局分为三部分:
1.对象头
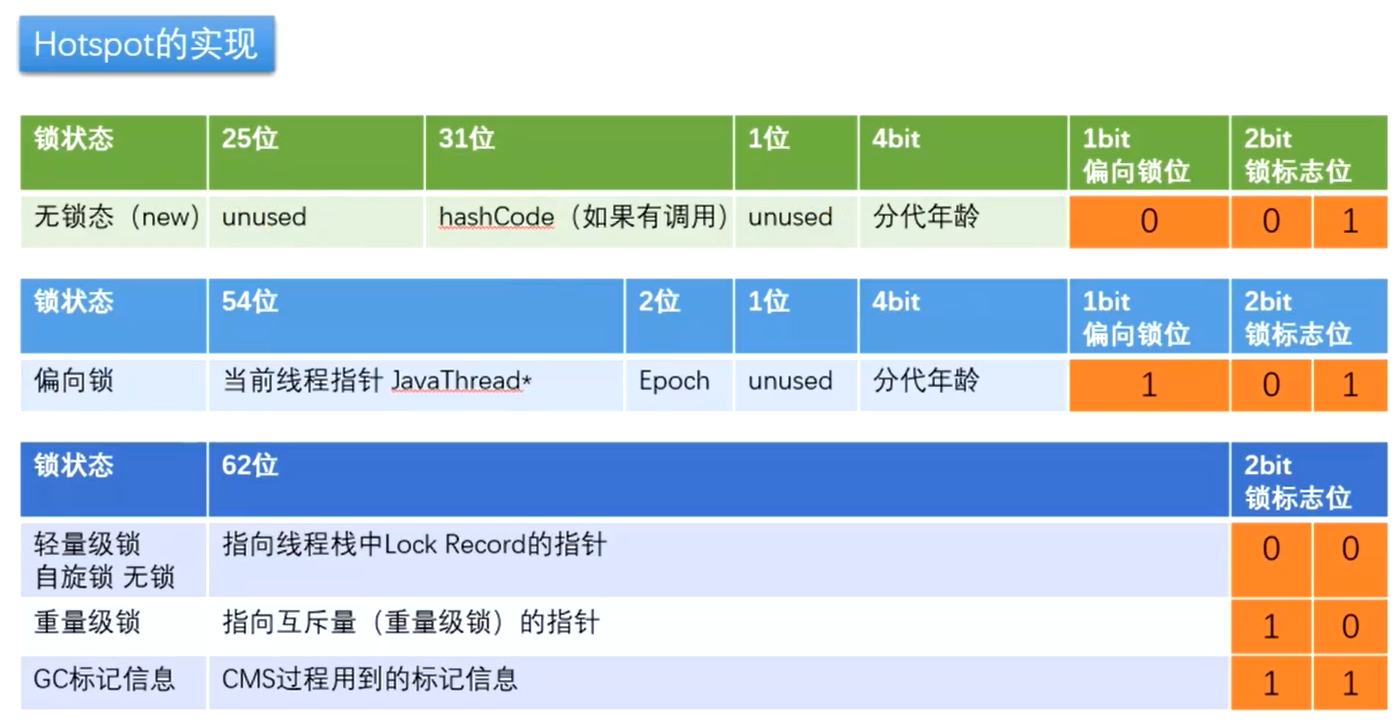
java里面用两个字来表示对象头,一个是Mark Word,一个是Klass pointer(Class MetaData Address)
(1)Mark Word(包含了自身运行时数据)
包括锁状态(lock,bkased_lock等),hashcode,GC分代年龄(age),线程持有的锁等… …
(2)Klass pointer(就是一个指针)
虚拟机通过这个指针来确定对象是哪个类的实例
64位虚拟机的对象组成(有锁无锁):
2.实例数据
就是你在对象里面写的东西()
3.对齐填充
JVM要求对象起始地址必须是8字节的整数倍(8字节对齐),所以不够8字节就由这部分来补充。
OOM:堆内存错误
⭐堆的分区有哪些?分别是什么功能
堆内存分为三个区域:
新生代(Minor GC)新生代采取淘汰机制,活不下去的就被轻GC回收
a.伊甸园
b.幸存from区
淘汰机制就是在from和to去进行言赢算法15次,活下来就可以走,为什么是15次?15=1111 刚好四个字节,存在对象头中
c.幸存to区
老年代(Full GC)
永久代(1.8后改为元空间)
此区域常驻内存,用来存放JDK自身携带的Class对象,Interface元数据,此区域不存在垃圾回收,关闭JVM时永久代自动关闭
1.6之前:永久代,常量池在方法区
1.7:永久代,常量池在堆中
1.8:无永久代
⭐堆内存调优:
jvm分配的堆内存是电脑内存的1/4,初始堆内存是1/64
VM options: -Xms1024m -Xmx1024m -XX:+PrintGCDetails
//Xms最小内存 Xmx最大内存
堆内存=原生代+老年代的内存
1-7-1 堆内存的组成(代码演示)
//先在pom.xml里面引入jol依赖,使得我们可以直观看到堆对象的组成
<dependency>
<groupId>org.openjdk.jol</groupId>
<artifactId>jol-core</artifactId>
<version>0.9</version>
</dependency>
public class A{
private String name;
private int age;
}
import org.openjdk.jol.info.ClassLayout;
public class Test {
static A a = new A();
public static void main(String[] args) {
System.out.println(ClassLayout.parseInstance(a).toPrintable());
}
}
输出演示:

1-8 GC!
垃圾回收机制
⭐GC的算法有哪些?
1.复制算法:
2.标记整体算法:
3.标记清除算法:
4.分代收集算法:
⭐轻GC和重GC分别在什么时候发生
线程
线程是由进程创建的一个实体,线程可以继续创建线程
1.并发:同一个时刻,多个任务交替执行,造成一种“好像是同时”的错觉,单核cpu中多任务就是并发
2.并行:同一时刻,多个任务同时运行,多核cpu可以并行
1-1 创建线程的方式
(1)继承Thread类(Thread类已经实现了Runnable接口),重写run方法
class T1 extends Thread{
run(){
}
}
(2)实现Runnable接口,重写run方法 (run方法是Runnable接口的,Thread是实现的Runnable的run方法)
注意:run()里面写你自己的业务逻辑
(3)用start()方法启动线程,因为run()仅仅只是一个方法,无法达成并行只能串行。启动后不一定马上执行要等待cpu
public synchronized void start(){
start0();//实现多线程效果的是他,而不是run这是个jvm控制的native方法
}
⭐注意:不论是继承Thread还是实现Runnable接口,本质上都是调用start()里面的start0()方法!
1-2 线程常用方法
setName,getName,start,run,setPriority更改优先级,getPriority获取优先级
interrupt,中断线程,实际上用来唤醒正在睡觉的线程
sleep,线程中的静态方法,使线程休眠
// yield : 线程礼让方法,让其他方法先执行,但不一定成功,要看cpu调度
// join : 线程插队方法
Thread t1 = new Thread();
Thread t2 = new Thread();
t2.join();//t1的时候t2调join,t2先插队完全执行完毕,然后执行t1
1-3 线程的种类
用户线程:也叫工作线程,当线程的任务执行完或通知方式结束
守护线程:为工作线程服务,当所有用户线程结束,守护线程自动结束
t1.setDaemon(true);//将t1设置为守护线程,用户线程结束它就结束
常见的守护线程:垃圾回收机制
1-4 线程的生命周期
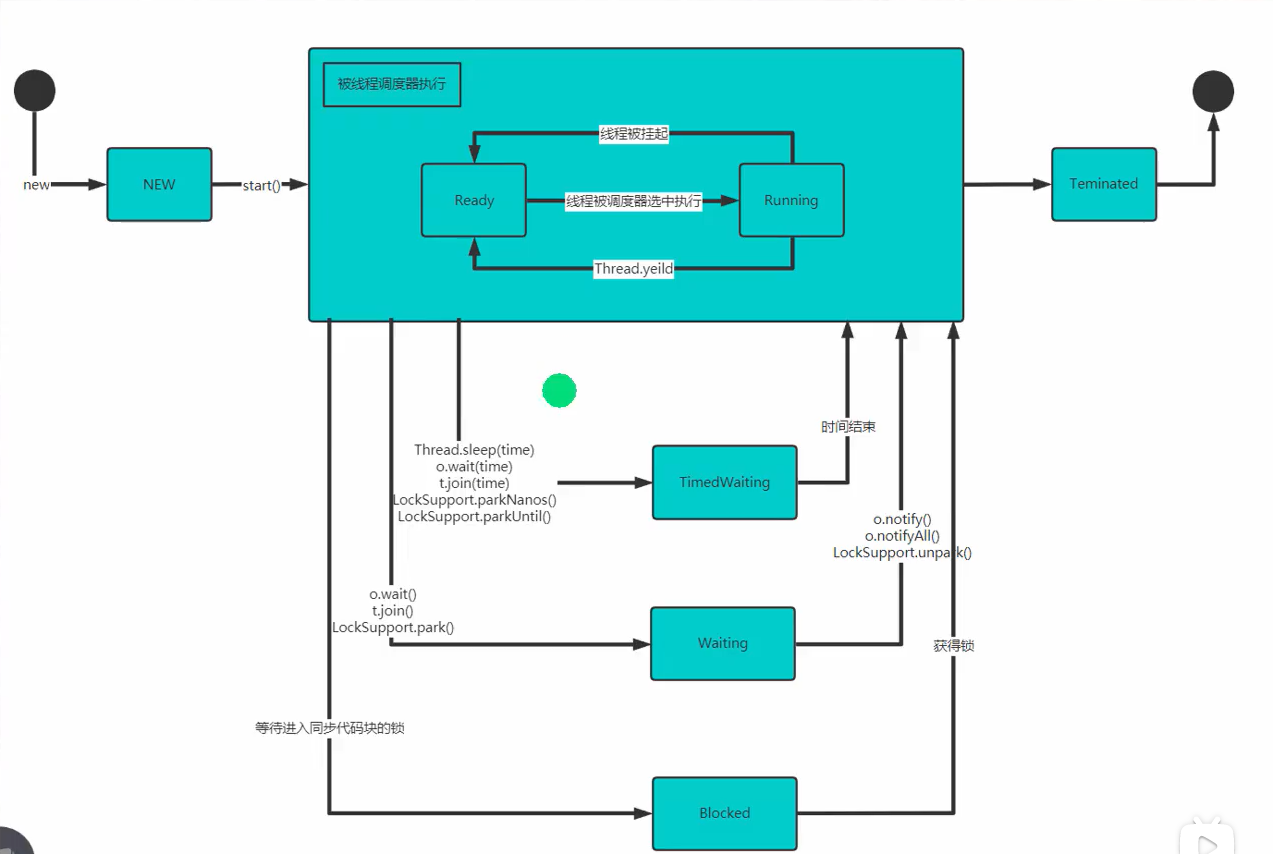
1-6 死锁
多线程/高并发
1.并发基础
1-1 互斥同步
1-2 非阻塞同步
1-3 指令重排
1-4 synchronized(重量级锁)
synchronized相信大家都看过或者用过,synchronized是Java中的关键字,synchronized可以保证方法或者代码块在运行时,同一时刻只有一个方法可以进入到临界区,同时它还可以保证共享变量的内存可见性,Java中每一个对象都可以作为锁,这是synchronized实现同步的基础。
synchronized 关键字可以保证原子性,也可以保证可见性
🧡它修饰的对象有以下几种:
- 修饰一个代码块,被修饰的代码块称为同步语句块,其作用的范围是大括号{}括起来的代码,作用的对象是调用这个代码块的对象;
- 修饰一个方法,被修饰的方法称为同步方法,其作用的范围是整个方法,作用的对象是调用这个方法的对象;
- 修饰一个静态的方法,其作用的范围是整个静态方法,作用的对象是这个类的所有对象;
- 修饰一个类,其作用的范围是synchronized后面括号括起来的部分,作用主的对象是这个类的所有对象。
*synchronized使用详解 *
🧡synchronized的实现过程:
(1)Java代码中:synchronized关键字
(2)编译过程,字节码中:monitorenter(执行开始)moniterexit(执行完)
(3)JVM执行过程中:锁升级环节
(4)cpu中:lock cmpechg
1-5 volatile
使用volatile 关键字,可以强制的从公共内存中读取值。使用volatile关键字增加了实例变量在多个线程之间的可见性。但是volatile关键字的缺点是不支持原子性。
volatile 关键字可以禁止指令进行重排序优化,也可以增加可见性
🧡它修饰的对象是 变量
1-6 关键字的比较
1)volatile 是线程同步的轻量级实现,所以volatile性能肯定比synchronized要好,但是volatile只能修饰变量,而synchronized可以修饰方法,代码块。
2)多线程访问volatile 不会发生阻塞,而synchronized 会发生阻塞。
3)volatile 能保证数据的可见性,但不能保证原子性,而 synchronized可以保证原子性,也可以保证可见性,因为它会将私有内存和公共内存中的数据做同步。
2.锁
⭐锁的种类:
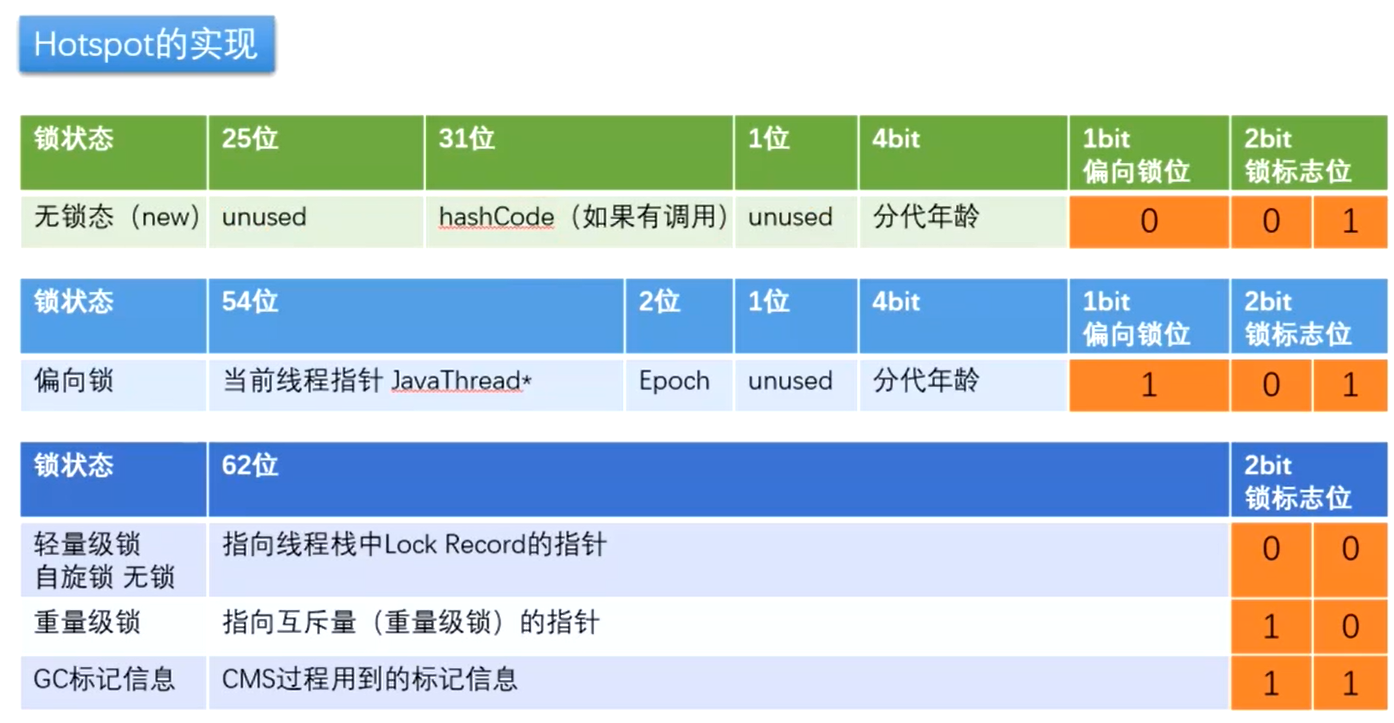
new(啥都没有)---- 偏向锁 ---- 轻量级锁 ---- 重量级锁
第一次上锁为偏向锁,一旦有线程竞争就立马升级为轻量级锁,竞争激烈就变成重量级锁
轻量级锁:假设两个线程抢,先抢到的就把自己的Lock Record指针x贴到对象头上,后来的看看Lock Record都变成这个x,然后自旋,直到前面线程走了,后来的Lock Record就不等于这个x了,就可以把自己的贴上去了。(x抢到了厕所,y原地自旋,等x上完厕所)
重量级锁:用户态转内核态
JVM会检测到一直在给 str 这个对象重复加锁,于是会粗化,到while循环外面加锁,只需加一次了。
2-1 自旋锁
CAS: compare and swap(比较和交换)
重量级锁用的是用户态和内核态的频繁切换,导致重量级锁开销大,损耗高,而JVM的轻量级锁,用的是CAS进行自旋抢锁。
CAS具体操作:当前值和新值不相等就让其他线程改完再进行比较,直到相等的时候更新。
底层用的JNI里面的unsafe
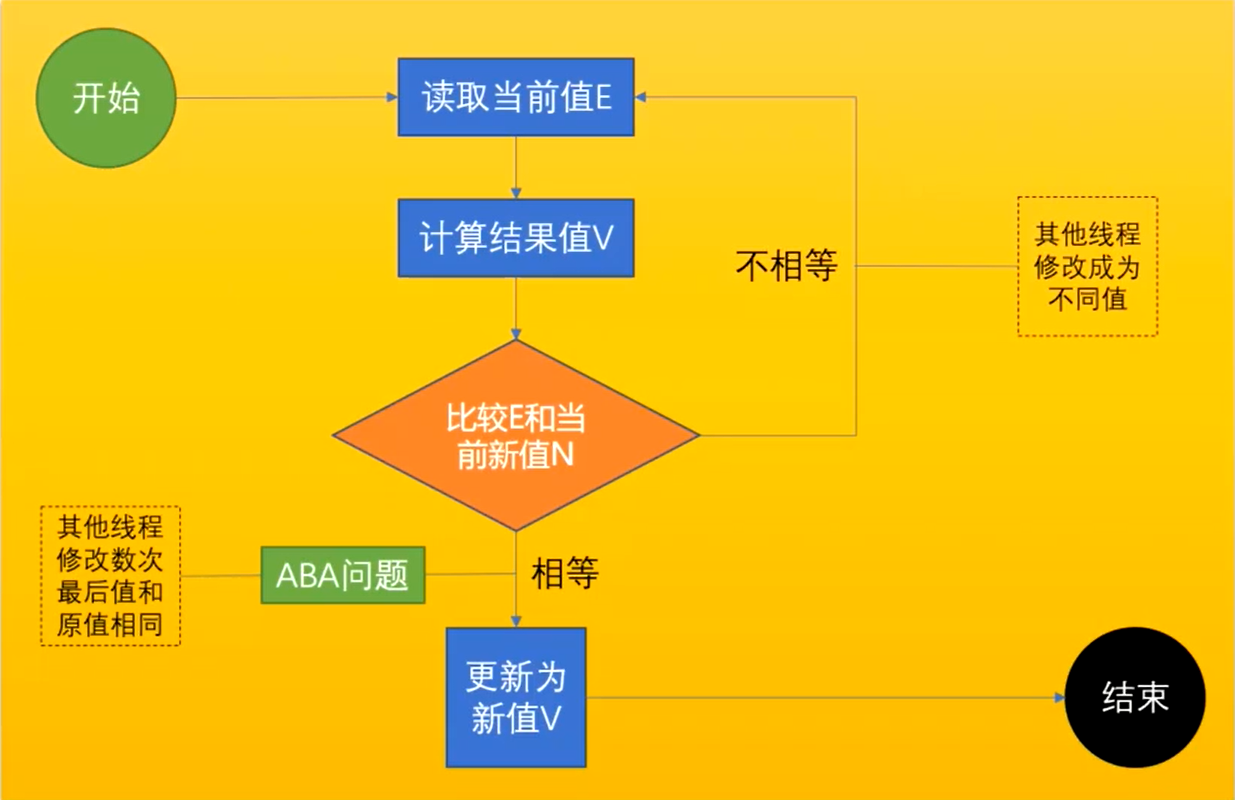
ABA问题:
你女朋友在分手状态时把你绿了,后面他们又分了,然后女朋友和你复合,你复合后不知道他这段时间和别人好了。这就是ABA
如何解决ABA:
离婚证(相当于标记一下)
⭐CAS在底层是通过
lock cmpxchg 指令实现的(这个指令和synconized和voliate有关)
2-2 偏向锁
因为经过HotSpot的作者大量的研究发现,大多数时候是不存在锁竞争的,常常是一个线程多次获得同一个锁,因此如果每次都要竞争锁会增大很多没有必要付出的代价,为了降低获取锁的代价,才引入的偏向锁。
偏向锁的升级:
当线程1访问代码块并获取锁对象时,会在java对象头和栈帧中记录偏向的锁的threadID,因为偏向锁不会主动释放锁,因此以后线程1再次获取锁的时候,需要比较当前线程的threadID和Java对象头中的threadID是否一致,如果一致(还是线程1获取锁对象),则无需使用CAS来加锁、解锁;如果不一致(其他线程,如线程2要竞争锁对象,而偏向锁不会主动释放因此还是存储的线程1的threadID),那么需要查看Java对象头中记录的线程1是否存活,如果没有存活,那么锁对象被重置为无锁状态,其它线程(线程2)可以竞争将其设置为偏向锁;如果存活,那么立刻查找该线程(线程1)的栈帧信息,如果还是需要继续持有这个锁对象,那么暂停当前线程1,撤销偏向锁,升级为轻量级锁,如果线程1 不再使用该锁对象,那么将锁对象状态设为无锁状态,重新偏向新的线程。
偏向锁的取消:
偏向锁是默认开启的,而且开始时间一般是比应用程序启动慢几秒,如果不想有这个延迟,那么可以使用-XX:BiasedLockingStartUpDelay=0;
如果不想要偏向锁,那么可以通过-XX:-UseBiasedLocking = false来设置;
2-3 ReentrantLock可重入锁
在谈ReentrantLock 前,我们先来了解一下另一种锁分类:内置锁和显式锁,我们前面讲到的synchronized就是内置锁,很多小伙伴觉得synchronized已经很好用了啊,为什么还要搞一个什么显式锁呢?接下来就通过ReentrantLock来带大家了解:
有些事情内置锁是做不了的,我们只能搞一个新玩意ReentrantLock来做,比如:
(1)可定时:要加个超时等待时间,超时了就停止获取锁,这样就不会无限等待。
RenentrantLock.tryLock(long timeout, TimeUnit unit);
(2)可中断:通过外部线程发起中断信号,中断某些耗时的线程,唤醒等待线程。
RenentrantLock.lockInterruptibly();
(3)条件队列:
线程在获取锁之后,可能会由于等待某个条件发生而进入等待状态(内置锁通过Object.wait()方法,显式锁通过Condition.await()方法),进入等待状态的线程会挂起并自动释放锁,这些线程会被放入到条件队列当中。synchronized对应的只有一个条件队列,而ReentrantLock可以有多个条件队列
Condition.signal();
Condition.signalAll();//ReentrantLock通过这两种方法唤醒
注意:ReentrantLock 底层是AQS的实现,使用内置锁时,对象本身既是一把锁又是一个条件队列;使用显式锁时,RenentrantLock的对象是锁,条件队列通过RenentrantLock.newCondition()方法获取,多次调用该方法可以得到多个条件队列。
2-3-1 锁的操作
⭐锁升级
锁的4中状态:无锁状态、偏向锁状态、轻量级锁状态、重量级锁状态(级别从低到高)
⭐锁消除:
public void add(String str1,String str2){
StringBuffer sb = new StringBuffer();
sb.append(str1).append(str2);
}
我们都知道StringBuffer是线程安全的,因为它的关键方法都是被synchronized修饰过得,但我们看上面的代码可以发现,sb这个引用只会在add方法中使用,不可能被其他线程引用,因此sb是不可能共享的资源。JVM会自动消除StringBuffer对象内部的锁。
⭐锁粗化:
public String test(String str){
int i=0;
stringBuffer sb = new StringBuffer();
while(i<100){
sb.append(str);
i++;
}
return sb.toString();
}
3.线程池
池化思想:线程池,字符串常量池,数据库连接池
这些都是为了提高资源的利用率
1.手动创建线程对象
2.执行任务
3.执行完毕,释放线程对象
4. 并发容器
5.JUC
5-1executor
5-2collections
5-3locks
5-4 atomic
原子类:许多都是native方法,详情查看1-4 native关键字
5-5 tools
数据结构与算法
1.线性结构和非线性结构
线性:元素之间存在一对一的线性关系,比如数组,队列,链表,栈
非线性:比如二维数组,多维数组,树结构,图结构
设计模式
1-1 单例模式
单例类一定要有并且只能有一个实例,并且只能自己创造实例。
1-1-1 饿汉式
public class Hungry{
//饿汉式会浪费内存
private Hungry(){
//构造器私有
}
private final static Hungry h = new Hungry();
public static Hungry getInstance(){
//getInstance为创建一个唯一的实例,和new不同
return h;
}
}
1-2 工厂模式
实例化对象不用new,用工厂代替(买车要从车厂买)
(1)静态工厂模式
public static void main(String[] args){
//Car car = new BenChi();普通方法new对象
Car car = CarFactory.getCar("奔驰");
/* 优点:不用考虑过程。缺点:违反了开闭原则,需要改进 */
}
(2)方法工厂模式:每个品牌一个类
(3)抽象工厂模式(强化版静态工厂模式,也就是工厂的工厂)
//手机产品接口
public interface IphoneProduct{
void fuck();
void suck();
}
//小米手机
public class XiaoMi implements IphoneProduct{
public void fuck(){
System.out.println("cnm");
}
public void suck(){
System.out.println("gun");
}
}
//工厂接口
public interface IProductFactory{
//小米手机
IphoneProduct iphoneProduct();
//小米叽叽
IJJProduct ijjProdcut();
}
//抽象工厂
public XiaomiFactory implements IProductFactory{
public IphoneProduct iphoneProduct(){
return new XiaoMi();
}
}
1-3原型模式
其特点为复制,复制的对象就是【原型】
创建复杂或耗时的对象时,直接复制是最好的选择。
主流框架和项目管理
微服务概念
(1)微服务是一种架构风格
(2)有多个服务,多个服务独立运行,每个服务占用独立进程,比如我们的商城模块和oss模块。
(3)为什么需要微服务?因为我们之前的web项目是单体架构,所有的东西都耦合在一块,代码量大,维护困难,所以我们需要把一个单体拆分成多个独立运行的服务,每个服务有特有的功能
(4)微服务可以方便多数据源
1.spring cloud
spring cloud不是一种技术,是一系列框架技术的集合
spring cloud需要依赖spring boot 使用
2.Nacos注册中心
常见的注册中心还有ZooKeeper(搭配dubbo使用)
Eureka(springboot原生)
3.Feign(远程调用从这开始到Http Client结束)
Feign是网飞(Netflix)开发的声明式,模板化的http客户端,可以帮助我们快捷方便的使用html API
4.Hystrix
熔断器与服务雪崩:
服务雪崩是指B调用A,然后C和D调用B,这时如果A服务不可用了,那么会引起B不可用,然后C和D因为B不可用所以也不可用,这就叫服务雪崩。原因主要有:
1.硬件故障 2.程序bug 3.缓存击穿 4.用户大量请求
熔断器
开关关闭时,请求允许通过,如果健康状况高于阈值,开关保持关闭,如果低于阈值,开关打开,开关打开时,请求禁止通过,禁止一段时间后,只允许一个请求通过,这一个请求成功时熔断器恢复关闭状态。
5.Ribbon
对请求做负载均衡,比如生产者有一个集群,Ribbon会将这些请求平均分摊到不同的服务器中
Nginx
反向代理服务器,能实现很多功能:
1.请求转发:
什么是请求转发?
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-q5cxhMfX-1644913012221)(C:\Users\86155\AppData\Roaming\Typora\typora-user-images\image-20211114094636893.png)]
2.负载均衡
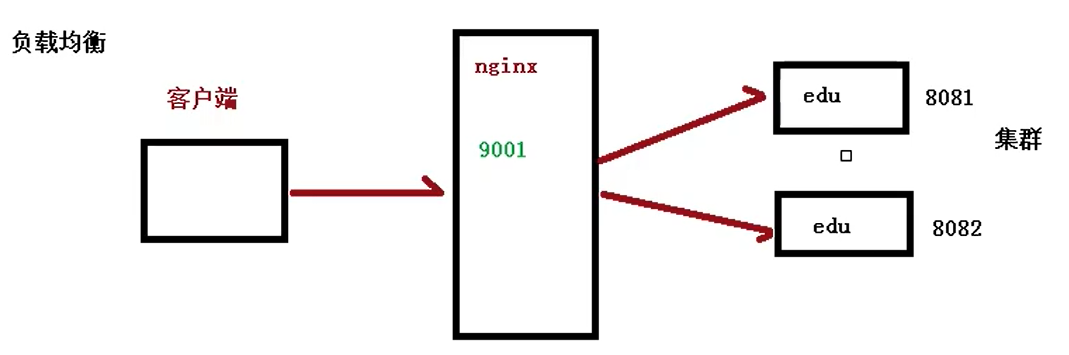
将客户端的请求,平均分摊到你的各个集群服务器中,达到负载均衡
3.动静分离
把java代码动态资源和页面文件那些静态资源分离开,根据请求申请动态或者静态资源
命令:
到文件夹打开cmd:
然后nginx.exe启动
nginx.exe -s stop关闭
RabbitMQ(中小型公司)卡夫卡(大型公司)
本质是个队列,先入先出,在系统高并发搞不定的时候,引入中间件。
主要功能有:
1-1流量消除峰值
在购买人数过多的时候,把超出的一部分延迟下单,虽然影响了用户体验,但是至少是能够下单而不会崩溃。
1-2
SSM
spring
springMVC
MyBatis
项目管理
Maven
Git
网络
1.TCP/IP
TCP可靠协议,传输数据时,会进行检查,没传输成功的他会重传,并且保证数据顺序不会乱!
UDP不可靠协议,他不检查,但是延时低,占用资源少
👇👇👇
如果你也想学习:黑客&网络安全的零基础攻防教程
今天只要你给我的文章点赞,我私藏的网安学习资料一样免费共享给你们,来看看有哪些东西。
在这里领取:

这个是我花了几天几夜自整理的最新最全网安学习资料包免费共享给你们,其中包含以下东西:
1.学习路线&职业规划


2.全套体系课&入门到精通

3.黑客电子书&面试资料

4.漏洞挖掘工具和学习文档
