Kotaemon是一个新近发布的集成了传统RAG与GraphRAG功能,并提供了UI前端的可扩展RAG工具。你可以简单部署与配置后直接用来作为自己的智能文档问答应用,也可以在它的源代码基础上做扩展或修改。
除了基础的知识库管理与RAG功能外,Kotaemon一些特别的地方有:
默认提供混合检索的RAG管道。可以结合向量与全文检索,以及重排模型以提升检索质量。
**默认提供了多样生成推理模式。**比如基于问题拆分的complex模式;基于ReAct推理的Agentic RAG模式等。
支持多模态文档的解析与索引。能对复杂文档(如PDF)中的表格与图片信息做解析与嵌入,用于后续检索。
**可扩展的RAG管道,并提供了Microsoft GraphRAG的集成实现。**即默认支持构建GraphRAG。
我们将对Kotaemon中多模态文档支持与MS GraphRAG集成两个特性的具体实现做深入揭秘,以方便在自己的RAG应用中参考学习。
本篇先聚焦在Kotaemon多模态文档的解析与索引,主要技术包括:
借助Azure Document Intelligence分析文档
借助**VLM(视觉大模型)**生成图片信息并嵌入
01
启动Kotaemon
我们首先需要简单测试下Kotaemon看一下最终效果。为了深入细节,这里采用源代码的形式来启动,步骤非常简单,一看就懂。首先准备环境与依赖:
# 虚拟环境创建
conda create -n kotaemon python=3.10
conda activate kotaemon
# 下载代码
git clone https://github.com/Cinnamon/kotaemon
cd kotaemon
#安装依赖
pip install -e "libs/kotaemon[all]"
pip install -e "libs/ktem"
然后完成两个配置工作:
在项目根目录下创建**.env文件**,其中主要包含了需要用到的各种模型配置,自行配置即可(也可以启动后在UI界面中设置)。
如果需要在UI中预览检索的源PDF页,可以下载一个pdf.js(一个pdf查看器,github搜索下载),并解压到libs/ktem/ktem/assets/prebuilt目录下。
现在启动Kotaemon应用:
python app.py
启动后会自动打开web页面:
现在你就拥有了一个端到端的RAG应用工具,可以自行配置模型、知识库、解析方法、生成模式等。
02
配置与测试多模态文档RAG
由于我们的目的是了解Kotaemon中对多模态文档的解析过程,因此这里暂时忽略其他功能,用一个多模态的简单文档来测试RAG过程。经过笔者的踩坑,步骤如下:
1. 配置文档加载器
Kotaemon对多模态文档的加载支持两种方式,一种是Adobe API,另一种是借助微软Azure的AI Document Intelligenc****e云服务来完成,这里我们研究第二种模式,后面揭秘代码后你完全可以应用到自己的RAG程序中。
在Kotaemon的Settings菜单中做如下选择:
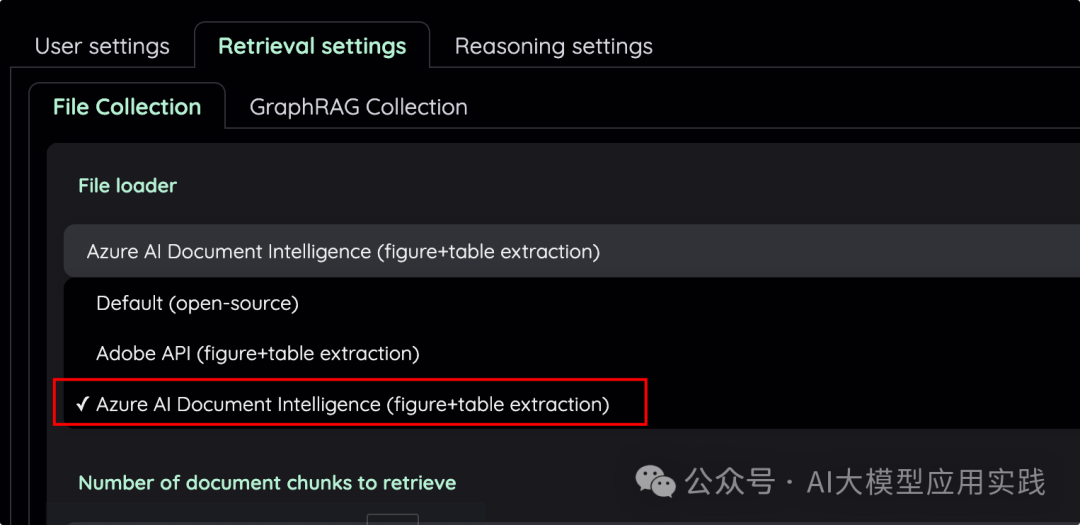
2. 申请与配置Azure AI Document Intelligence服务
登录到微软Azure平台,依次进入Azure服务->Azure AI Services->Document Intelligence,按照向导指引,创建一个文档智能服务即可,选择免费的定价层用于开发与测试。
完成后你将可以在自己的Document Intelligence服务页面看到API的Endpoint与Key,这是调用服务所必需的信息。同时也可以进入Document Intelligence Studio工具,在线测试各种复杂文档的读取与分析功能。


笔者使用多种不同类型文档进行了测试,可以说Azure Document Intelligence的复杂文档解析与提取效果都非常强大与优秀。
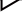

把申请获得的API Endpoint与Key配置到Kotameon的.env文件中:

3. 配置多模态视觉大模型(VLM)
尽管Azure AI Document Intelligence可以帮你从复杂文档中提取文本、表格、图片等,甚至会自动做OCR识别,但不会对其中的图片进行深入理解。所以需要在其基础上借助视觉大模型(VLM)对图片进行深度理解,生成图片的内容信息,这些信息再通过嵌入做向量化,并用于语义检索。在Kotaemon中默认是借助Azure OpenAI的模型来完成,你需要在.env配置如下项目:
AZURE_OPENAI_ENDPOINT:Azure OpenAI服务的endpoint
AZURE_OPENAI_API_KEY:Azure OpenAI服务的Key
OPENAI_VISION_DEPLOYMENT_NAME:模型名称,如gpt-4o-mini
OPENAI_API_VERSION:API的版本,如2024-02-15-preview

如果你需要使用其他视觉模型,比如QWEN-VL,则需要修改部分源码,具体可以参考本文下面的代码介绍。
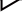
4. 效果测试
我们用一个简单的带有图片的PDF文档做测试,在Kotaemon的Files菜单中上传、解析与索引。完成后可以在下方看到最后被索引的知识块,这里可以看到图片所在的知识块,其中的文字内容是借助VLM生成:
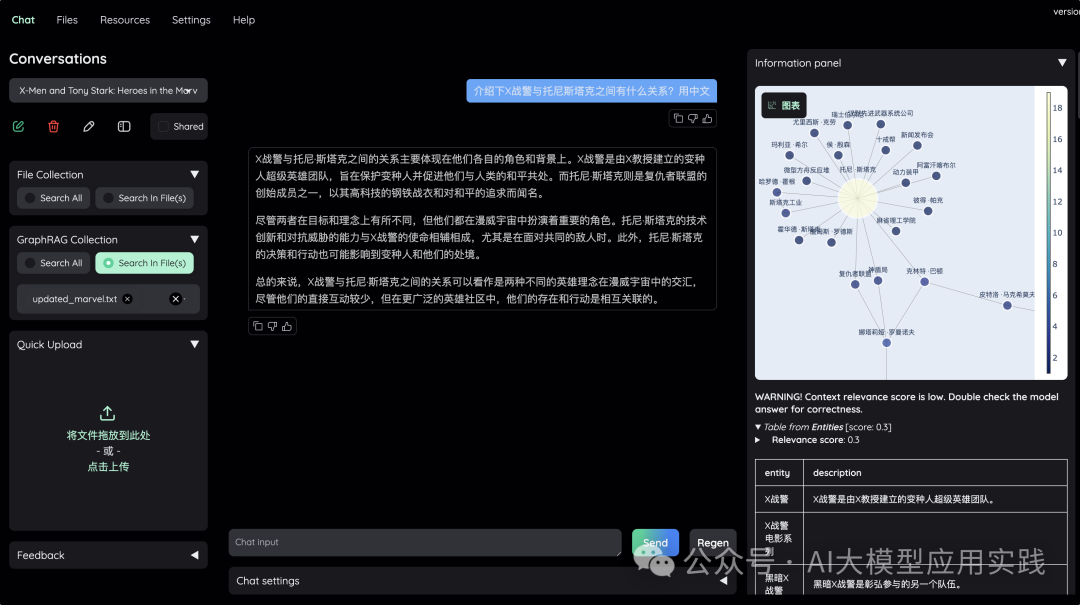
现在做一个如下的简单对话,可以看到借助于文档智能解析与VLM,可以很好的检索到图片中的知识来回答输入问题(右边展示了检索的相关内容):
03
源代码实现
这类多模态文档处理的复杂性主要体现在索引阶段(检索阶段一般仍然是借助向量语义检索),因此重点关注Indexing阶段的处理。
文档解析的核心逻辑位于libs/kotaemon/kotaemon/loaders/azureai_document_intelligence_loader.py文件中,基本处理过程如下:
1. 定义Azure Document Intelligence的客户端
这部分注意首先安装Azure AI Document Intelligence的SDK库。
def client_(self):
try:
from azure.ai.documentintelligence import DocumentIntelligenceClient
from azure.core.credentials import AzureKeyCredential
except ImportError:
raise ImportError("Please install azure-ai-documentintelligence")
return DocumentIntelligenceClient(
self.endpoint, AzureKeyCredential(self.credential)
)
2. 使用SDK进行文档分析
调用begin_analyze_document方法进行文档分析。
......
with open(file_path, "rb") as fi:
poller = self.client_.begin_analyze_document(
self.model,
analyze_request=fi,
content_type="application/octet-stream",
output_content_format=self.output_content_format,
)
result = poller.result()
# the total text content of the document in `output_content_format` format
text_content = result.content
...
这里参数中的model是分析模型,对于PDF内容提取,一般用"prebuilt-layout";如果只是读取文档的全部文本,可以用"prebuild-read";output_content_format(输出格式)一般用markdown。
最后返回结果中的content保存了文档中的全部文本内容(包括图片中的文字、以及表格文字),并以markdown格式表示。
3. 对分析结果中的图片进行提取与总结
Azure Document Intelligence在提取文档中的图片时,并不会直接生成图片下载链接,而是在结果中(JSON格式)中提供了详细的原图片信息,包括图片在文档中的页码、边界区域、坐标、在文本内容中的偏移量、图片所含文本等。因此,这里需要首先把其中的图片提取出来:
....... # 图片信息放在figures部分 figures = [] for figure_desc in result.get("figures", []): if not self.vlm_endpoint: continue if file_path.suffix.lower() not in self.figure_friendly_filetypes: continue # 读取与裁剪图像 page_number = figure_desc["boundingRegions"][0]["pageNumber"] page_width = result.pages[page_number - 1]["width"] page_height = result.pages[page_number - 1]["height"] polygon = figure_desc["boundingRegions"][0]["polygon"] xs = [polygon[i] for i in range(0, len(polygon), 2)] ys = [polygon[i] for i in range(1, len(polygon), 2)] bbox = [ min(xs) / page_width, min(ys) / page_height, max(xs) / page_width, max(ys) / page_height, ] img = crop_image(file_path, bbox, page_number - 1) # 转化base64 img_bytes = BytesIO() img.save(img_bytes, format="PNG") img_base64 = base64.b64encode(img_bytes.getvalue()).decode("utf-8") img_base64 = f"data:image/png;base64,{img_base64}" # 生成图片摘要与内容信息(借助vlm) caption = generate_single_figure_caption( figure=img_base64, vlm_endpoint=self.vlm_endpoint ) # 图片元数据 figure_metadata = { "image_origin": img_base64, "type": "image", "page_label": page_number, } figure_metadata.update(metadata)` `_#将图片摘要与元数据组装成Document对象_ figures.append( Document( text=caption, metadata=figure_metadata, ) ) removed_spans += figure_desc["spans"] ......
解释下这段代码中用到的两个函数:
crop_image:用于根据给定的边界框在源文件中裁剪图像。该函数接受三个参数:图像文件路径 file_path、边界框 bbox(以百分比表示的 [x0, y0, x1, y1])和可选的页码 page_number(默认为 0)。函数利用PIL的Image模块进行处理,如果源文件是PDF,还需要用到PyMuPDF库。
generate_single_figure_caption:这就是上文所说的借助视觉模型VLM生成图片的摘要与描述信息。其实现代码如下,其中generate_gpt4v方法会调用OpenAI的API(如果需要使用其他VLM,重点修改这个方法),注意这里简单修改了prompt:
def generate_single_figure_caption(vlm_endpoint: str, figure: str) -> str:
"""Summarize a single figure using GPT-4V"""
if figure:
output = generate_gpt4v(
endpoint=vlm_endpoint,
prompt="Please provide a detailed description of the image content in Chinese, including a summary of the content and details of any text within the image.",
images=figure,
)
if "sorry" in output.lower():
output = ""
else:
output = ""
return output
4. 对表格信息进行提取
Azure Document Intelligence提取的表格内容以markdown格式放在结果的“tables”字段中,因此表格提取就比较简单,借助于tables中存放的页面信息、内容偏移量、长度等,可以从上面的text_content中独立的提取并构造出Document对象,部分代码如下:
......
offset = table_desc["spans"][0]["offset"]
length = table_desc["spans"][0]["length"]
table_metadata = {
"type": "table",
"page_label": page_number,
"table_origin": text_content[offset : offset + length],
}
table_metadata.update(metadata)
tables.append(
Document(
text=text_content[offset : offset + length],
metadata=table_metadata,
)
)
......
在将全部图片与表格信息提取并构建成Document对象(Document是后续用来分割与嵌入的基本组件)后,就可以将它们与其他文本内容一起用于后续的分割、嵌入与索引,从而可以提供向量检索。
以上就是Kotaemon中借助Azure AI服务与VLM做复杂文档解析与提取的代码,你完全可以做少量修改后用于自己的RAG应用中。
04
小结
上文简单介绍了Kotaemon框架中是如何借助微软Azure Document Intelligence这一在线的AI服务实现复杂文档内容的分析与提取,同时借助视觉大模型与嵌入模型对其中的图片、表格等这类非结构化/半结构化的信息进行嵌入与索引。

大模型&AI产品经理如何学习
求大家的点赞和收藏,我花2万买的大模型学习资料免费共享给你们,来看看有哪些东西。
1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。


(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方图片前往获取
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。

4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓
