目录
习题6-2 推导公式(6.40)和公式(6.41)中的梯度.
习题6-3 当使用公式作为循环神经网络的状态更新公式时, 分析其可能存在梯度爆炸的原因并给出解决方法.
习题6-2P 设计简单RNN模型,分别用Numpy、Pytorch实现反向传播算子,并代入数值测试
分别用Numpy、Pytorch实现反向传播算子,并代入数值测试对比
习题6-1P 推导RNN反向传播算法BPTT

习题6-2 推导公式(6.40)和公式(6.41)中的梯度.
(续6-1)

习题6-3 当使用公式 作为循环神经网络的状态更新公式时, 分析其可能存在梯度爆炸的原因并给出解决方法.
作为循环神经网络的状态更新公式时, 分析其可能存在梯度爆炸的原因并给出解决方法.

习题6-2P 设计简单RNN模型,分别用Numpy、Pytorch实现反向传播算子,并代入数值测试
ref :RNN与LSTM详解
RNN单元模型

前向传播:
'''
@ Function: 实现RNN单元的前向传播步骤
@Author: lxy
@ date: 2024/12/3
'''
import numpy as np
import torch.nn.functional as F
import torch
# 实现了RNN单元的单个前向步骤
def rnn_cell_forward(xt, a_prev, parameters):
'''
xt:在时间步“t”的输入数据,形状为(n_x, m)的numpy数组
a_prev:在时间步“t - 1”的隐藏状态,形状为(n_a, m)的numpy数组
parameters:
Wax:用于乘以输入的权重矩阵,形状为(n_a, n_x)的numpy数组
Waa:用于乘以隐藏状态的权重矩阵,形状为(n_a, n_a)的numpy数组
Wya:将隐藏状态与输出相关联的权重矩阵,形状为(n_y, n_a)的numpy数组
ba:偏置项,形状为(n_a, 1)的numpy数组
by:将隐藏状态与输出相关联的偏置项,形状为(n_y, 1)的numpy数组
'''
# 从parameters字典中获取各个参数
Wax = parameters["Wax"]
Waa = parameters["Waa"]
Wya = parameters["Wya"]
ba = parameters["ba"]
by = parameters["by"]
# 计算下一个激活状态
a_next = np.tanh(np.dot(Wax, xt) + np.dot(Waa, a_prev) + ba)
# 计算当前单元的输出
yt_pred = F.softmax(torch.from_numpy(np.dot(Wya, a_next) + by), dim=0)
# 将反向传播所需的值存储在cache中
cache = (a_next, a_prev, xt, parameters)
return a_next, yt_pred, cache # a_next:下一个隐藏状态,形状为(n_a, m) , yt_pred:在时间步“t”的预测结果,形状为(n_y, m)的numpy数组
if __name__ =='main':
np.random.seed(1)
xt = np.random.randn(3, 10)
a_prev = np.random.randn(5, 10)
Wax = np.random.randn(5, 3)
Waa = np.random.randn(5, 5)
Wya = np.random.randn(2, 5)
ba = np.random.randn(5, 1)
by = np.random.randn(2, 1)
parameters = {"Wax": Wax, "Waa": Waa, "Wya": Wya, "ba": ba, "by": by}
a_next, yt_pred, cache = rnn_cell_forward(xt, a_prev, parameters)
print("下一个隐藏状态的第五行内容 = ", a_next[4])
print("下一个隐藏状态的形状 = ", a_next.shape)
print("在时间步“t”的预测结果的第二行内容 =", yt_pred[1])
print("在时间步“t”的预测结果的形状 = ", yt_pred.shape)运行结果:
下一个隐藏状态的第五行内容 = [-0.97683053 0.99993218 0.9999085 0.99720415 0.96532437 0.24615069
0.89433073 0.88371261 0.40821569 -0.99446565]
下一个隐藏状态的形状 = (5, 10)
在时间步“t”的预测结果的第二行内容 = tensor([0.0617, 0.9972, 0.9895, 0.8253, 0.8099, 0.9891, 0.9262, 0.9997, 0.9953,
0.0052], dtype=torch.float64)
在时间步“t”的预测结果的形状 = torch.Size([2, 10])
反向传播:

完整代码:
'''
@ Function: 实现RNN单元的反向传播步骤
@Author: lxy
@ date: 2024/12/3
'''
import numpy as np
import torch.nn.functional as F
import torch
from rnn_cell_forward import rnn_cell_forward
def rnn_cell_backward(da_next, cache):
"""
da_next -- 相对于下一个隐藏状态的损失梯度
cache -- 包含有用值的Python字典(rnn_cell_forward()的输出)
返回gradients -- 包含以下内容的Python字典:
dx -- 输入数据的梯度,形状为(n_x, m)
da_prev -- 先前隐藏状态的梯度,形状为(n_a, m)
dWax -- 输入到隐藏层权重的梯度,形状为(n_a, n_x)
dWaa -- 隐藏层到隐藏层权重的梯度,形状为(n_a, n_a)
dba -- 偏置向量的梯度,形状为(n_a, 1)
"""
# 从缓存中获取值
(a_next, a_prev, xt, parameters) = cache
# 从参数字典中获取值
Wax = parameters["Wax"]
Waa = parameters["Waa"]
Wya = parameters["Wya"]
ba = parameters["ba"]
by = parameters["by"]
### ================以下是具体的反向传播计算步骤 =======================###
# 1、计算tanh函数关于a_next的梯度
# 按元素逐个计算的,即与da_next对应元素相乘,dtanh可看作中间结果的一种表示方式
dtanh = (1 - a_next * a_next) * da_next
#2、 计算相对于Wax的损失梯度
# 先计算dxt,它等于da_next与Wax的转置矩阵做点积dtanh
dxt = np.dot(Wax.T, dtanh)
# 再计算dWax,它等于dtanh与xt的转置矩阵做点积
dWax = np.dot(dtanh, xt.T)
'''
解释一下上面的公式推导:
根据公式原理,dxt = da_next.( Wax.T . (1- tanh(a_next)**2) ),这里的.表示矩阵点积,
进一步展开就是da_next.( Wax.T . dtanh * (1/d_a_next) ),化简后得到Wax.T . dtanh
同理,dWax = da_next.( (1- tanh(a_next)**2). xt.T),展开并化简后得到da_next.( dtanh * (1/d_a_next). xt.T ),即dtanh. xt.T
'''
# 3、计算相对于Waa的梯度
da_prev = np.dot(Waa.T, dtanh)
dWaa = np.dot(dtanh, a_prev.T)
# 4、计算相对于偏置b的梯度
# axis=0表示在列方向上进行操作,axis=1表示在行方向上进行操作,keepdims=True用于保持矩阵的二维特性
dba = np.sum(dtanh, keepdims=True, axis=-1)
### ======================结束反向传播计算步骤======================= ###
# 将计算得到的各个梯度存储在一个Python字典中
gradients = {"dxt": dxt, "da_prev": da_prev, "dWax": dWax, "dWaa": dWaa, "dba": dba}
return gradients
if __name__ =='main':
np.random.seed(1)
xt = np.random.randn(3, 10)
a_prev = np.random.randn(5, 10)
Wax = np.random.randn(5, 3)
Waa = np.random.randn(5, 5)
Wya = np.random.randn(2, 5)
b = np.random.randn(5, 1)
by = np.random.randn(2, 1)
parameters = {"Wax": Wax, "Waa": Waa, "Wya": Wya, "ba": b, "by": by}
a_next, yt, cache = rnn_cell_forward(xt, a_prev, parameters)
da_next = np.random.randn(5, 10)
gradients = rnn_cell_backward(da_next, cache)
# 输出输入数据梯度中第二行第三列的元素值
print("输入数据梯度中第二行第三列的元素值 =", gradients["dxt"][1][2])
print("输入数据梯度的形状 =", gradients["dxt"].shape)
# 输出先前隐藏状态梯度中第三行第四列的元素值
print("先前隐藏状态梯度中第三行第四列的元素值 =", gradients["da_prev"][2][3])
print("先前隐藏状态梯度的形状 =", gradients["da_prev"].shape)
# 输出输入到隐藏层权重梯度中第四行第二列的元素值
print("输入到隐藏层权重梯度中第四行第二列的元素值 =", gradients["dWax"][3][1])
print("输入到隐藏层权重梯度的形状 =", gradients["dWax"].shape)
# 输出隐藏层到隐藏层权重梯度中第二行第三列的元素值
print("隐藏层到隐藏层权重梯度中第二行第三列的元素值 =", gradients["dWaa"][1][2])
print("隐藏层到隐藏层权重梯度的形状 =", gradients["dWaa"].shape)
# 输出偏置向量梯度中第五行的元素值(这里是一个包含一个元素的列表形式)
print("偏置向量梯度中第五行的元素值 =", gradients["dba"][4])
print("偏置向量梯度的形状 =", gradients["dba"].shape)
# 以下是对示例中具体赋值情况的展示
gradients["dxt"][1][2] = -0.4605641030588796
gradients["dxt"].shape = (3, 10)
gradients["da_prev"][2][3] = 0.08429686538067724
gradients["da_prev"].shape = (5, 10)
gradients["dWax"][3][1] = 0.39308187392193034
gradients["dWax"].shape = (5, 3)
gradients["dWaa"][1][2] = -0.28483955786960663
gradients["dWaa"].shape = (5, 5)
gradients["dba"][4] = [0.80517166]
gradients["dba"].shape = (5, 1)运行结果:
输入数据梯度中第二行第三列的元素值 = -1.3872130506020928
输入数据梯度的形状 = (3, 10)
先前隐藏状态梯度中第三行第四列的元素值 = -0.1523994937739543
先前隐藏状态梯度的形状 = (5, 10)
输入到隐藏层权重梯度中第四行第二列的元素值 = 0.41077282493545836
输入到隐藏层权重梯度的形状 = (5, 3)
隐藏层到隐藏层权重梯度中第二行第三列的元素值 = 1.1503450668497135
隐藏层到隐藏层权重梯度的形状 = (5, 5)
偏置向量梯度中第五行的元素值 = [0.20023491]
偏置向量梯度的形状 = (5, 1)
RNN模型
 前向传播:
前向传播:
针对每个时间步,调用 rnn_cell_forward 函数来更新下一个隐藏状态 a_next 、计算当前时间步的预测结果 yt_pred 并获取缓存 cache 。

完整代码:
'''
@ Function: 实现RNN的前向传播步骤
@Author: lxy
@ date: 2024/12/3
'''
import numpy as np
import torch.nn.functional as F
import torch
from rnn_cell_forward import rnn_cell_forward
def rnn_forward(x, a0, parameters):
"""
x -- 每个时间步的输入数据,形状为(n_x, m, T_x)。
a0 -- 初始隐藏状态,形状为(n_a, m)。
parameters -- 包含以下内容的Python字典:
Waa -- 用于乘以隐藏状态的权重矩阵,形状为(n_a, n_a)的numpy数组。
Wax -- 用于乘以输入的权重矩阵,形状为(n_a, n_x)的numpy数组。
Wya -- 将隐藏状态与输出相关联的权重矩阵,形状为(n_y, n_a)的numpy数组。
ba -- 偏置项,形状为(n_a, 1)的numpy数组。
by -- 将隐藏状态与输出相关联的偏置项,形状为(n_y, 1)的numpy数组。
返回:
a -- 每个时间步的隐藏状态,形状为(n_a, m, T_x)的numpy数组。
y_pred -- 每个时间步的预测结果,形状为(n_y, m, T_x)的numpy数组。
caches -- 用于反向传播所需值的元组,包含(缓存列表,输入数据x)。
"""
# 初始化“caches”,它将包含所有缓存的列表
caches = []
# 从输入数据x和权重矩阵Wya的形状中获取维度信息
n_x, m, T_x = x.shape
n_y, n_a = parameters["Wya"].shape
### ===============以下是前向传播的具体计算步骤 ===============###
# 1、用零初始化“a”和“y”
a = np.zeros((n_a, m, T_x))
y_pred = np.zeros((n_y, m, T_x))
#2、 初始化下一个隐藏状态
a_next = a0
# 3、遍历所有时间步
for t in range(T_x):
# 调用cell前向传播函数更新下一个隐藏状态,计算预测结果,获取缓存(大约一行代码)
a_next, yt_pred, cache = rnn_cell_forward(x[:, :, t], a_next, parameters)
# 将新的“下一个”隐藏状态的值保存到a中(大约一行代码)
a[:, :, t] = a_next
# 将预测结果的值保存到y_pred中(大约一行代码)
y_pred[:, :, t] = yt_pred
# 将“cache”添加到“caches”列表中(大约一行代码)
caches.append(cache)
### ====================结束前向传播的计算步骤============= ###
# 将反向传播所需的值存储在缓存中
caches = (caches, x)
return a, y_pred, caches
if __name__=="main":
np.random.seed(1)
x = np.random.randn(3, 10, 4)
a0 = np.random.randn(5, 10)
Waa = np.random.randn(5, 5)
Wax = np.random.randn(5, 3)
Wya = np.random.randn(2, 5)
ba = np.random.randn(5, 1)
by = np.random.randn(2, 1)
parameters = {"Waa": Waa, "Wax": Wax, "Wya": Wya, "ba": ba, "by": by}
a, y_pred, caches = rnn_forward(x, a0, parameters)
# 输出隐藏状态数组中第五行(索引从0开始,所以索引4对应第五行)第二列(索引从0开始,所以索引1对应第二列)的元素值
print("隐藏状态数组中第五行第二列的元素值 = ", a[4][1])
print("隐藏状态数组的形状 = ", a.shape)
# 输出预测结果数组中第二行(索引从0开始,所以索引1对应第二行)第四列(索引从0开始,所以索引3对应第四列)的元素值
print("预测结果数组中第二行第四列的元素值 =", y_pred[1][3])
print("预测结果数组的形状 = ", y_pred.shape)
# 输出缓存元组中第二个元素(索引从0开始,所以索引1对应第二个元素)的列表中第四个元素(索引从0开始,所以索引3对应第四个元素)的值
print("缓存元组中第二个元素的列表中第四个元素的值 =", caches[1][1][3])
print("缓存元组的长度 = ", len(caches))运行结果:
隐藏状态数组中第五行第二列的元素值 = [-0.99999375 0.77911235 -0.99861469 -0.99833267]
隐藏状态数组的形状 = (5, 10, 4)
预测结果数组中第二行第四列的元素值 = [0.79560373 0.86224861 0.11118257 0.81515947]
预测结果数组的形状 = (2, 10, 4)
缓存元组中第二个元素的列表中第四个元素的值 = [-1.1425182 -0.34934272 -0.20889423 0.58662319]
缓存元组的长度 = 2
反向传播:
实现rnn_backward函数。首先用零初始化返回变量,然后循环遍历所有时间步,同时在每个时间步调用rnn_cell_backward,相应地更新其他变量。

'''
@ Function: 实现RNN的反向传播步骤
@Author: lxy
@ date: 2024/12/3
'''
import numpy as np
import torch.nn.functional as F
import torch
from rnn_cell_forward import rnn_cell_forward
from rnn_cell_backward import rnn_cell_backward
from rnn_forward import rnn_forward
# 实现RNN的反向步骤
def rnn_backward(da, caches):
"""
da -- 所有隐藏状态的上游梯度,形状为(n_a, m, T_x)。
caches -- 包含来自前向传播(rnn_forward)信息的元组。
返回:
gradients -- 包含以下内容的Python字典:
dx -- 相对于输入数据的梯度,形状为(n_x, m, T_x)的numpy数组。
da0 -- 相对于初始隐藏状态的梯度,形状为(n_a, m)的numpy数组。
dWax -- 相对于输入权重矩阵的梯度,形状为(n_a, n_x)的numpy数组。
dWaa -- 相对于隐藏状态权重矩阵的梯度,形状为(n_a, n_a)的numpy数组。
dba -- 相对于偏置的梯度,形状为(n_a, 1)的numpy数组。
"""
###========================= 以下是反向传播的具体计算步骤================= ###
# 1、从caches的第一个缓存(t = 1时)中获取值
(caches_list, x) = caches
(a1, a0, x1, parameters) = caches_list[0] # 获取t = 1时的值
# 2、从da和x1的形状中获取维度信息
n_a, m, T_x = da.shape
n_x, m = x1.shape
# 3、用合适的大小初始化各个梯度
dx = np.zeros((n_x, m, T_x))
dWax = np.zeros((n_a, n_x))
dWaa = np.zeros((n_a, n_a))
dba = np.zeros((n_a, 1))
da0 = np.zeros((n_a, m))
da_prevt = np.zeros((n_a, m))
# 4、循环遍历所有时间步
for t in reversed(range(T_x)):
# 在时间步t计算梯度。在反向传播步骤中,要明智地选择“da_next”和“cache”来使用
# 这里将当前时间步的梯度da[:, :, t]与上一个时间步累积的梯度da_prevt相加作为输入
gradients = rnn_cell_backward(da[:, :, t] + da_prevt, caches_list[t])
# 从计算得到的梯度字典中获取各个导数(大约一行代码)
dxt, da_prevt, dWaxt, dWaat, dbat = gradients["dxt"], gradients["da_prev"], gradients["dWax"], gradients[
"dWaa"], gradients["dba"]
# 通过加上在时间步t的导数来累加相对于参数的全局导数
dx[:, :, t] = dxt
dWax += dWaxt
dWaa += dWaat
dba += dbat
# 5、将经过所有时间步反向传播得到的a的梯度赋给da0
da0 = da_prevt
### ===================结束反向传播的计算步骤 ====================###
# 将计算得到的各个梯度存储在一个Python字典中
gradients = {"dx": dx, "da0": da0, "dWax": dWax, "dWaa": dWaa, "dba": dba}
return gradients
np.random.seed(1)
x = np.random.randn(3, 10, 4)
a0 = np.random.randn(5, 10)
Wax = np.random.randn(5, 3)
Waa = np.random.randn(5, 5)
Wya = np.random.randn(2, 5)
ba = np.random.randn(5, 1)
by = np.random.randn(2, 1)
parameters = {"Wax": Wax, "Waa": Waa, "Wya": Wya, "ba": ba, "by": by}
a, y, caches = rnn_forward(x, a0, parameters)
da = np.random.randn(5, 10, 4)
gradients = rnn_backward(da, caches)
# 输出相对于输入数据梯度中第二行第三列的元素值
print("相对于输入数据梯度中第二行第三列的元素值 =", gradients["dx"][1][2])
print("相对于输入数据梯度的形状 =", gradients["dx"].shape)
# 输出相对于初始隐藏状态梯度中第三行第四列的元素值
print("相对于初始隐藏状态梯度中第三行第四列的元素值 =", gradients["da0"][2][3])
print("相对于初始隐藏状态梯度的形状 =", gradients["da0"].shape)
# 输出相对于输入权重矩阵梯度中第四行第二列的元素值
print("相对于输入权重矩阵梯度中第四行第二列的元素值 =", gradients["dWax"][3][1])
print("相对于输入权重矩阵梯度的形状 =", gradients["dWax"].shape)
# 输出相对于隐藏状态权重矩阵梯度中第二行第三列的元素值
print("相对于隐藏状态权重矩阵梯度中第二行第三列的元素值 =", gradients["dWaa"][1][2])
print("相对于隐藏状态权重矩阵梯度的形状 =", gradients["dWaa"].shape)
# 输出相对于偏置梯度中第五行的元素值(这里是一个包含一个元素的列表形式)
print("相对于偏置梯度中第五行的元素值 =", gradients["dba"][4])
print("相对于偏置梯度的形状 =", gradients["dba"].shape)运行结果;
相对于输入数据梯度中第二行第三列的元素值 = [-2.07101689 -0.59255627 0.02466855 0.01483317]
相对于输入数据梯度的形状 = (3, 10, 4)
相对于初始隐藏状态梯度中第三行第四列的元素值 = -0.3149423751266506
相对于初始隐藏状态梯度的形状 = (5, 10)
相对于输入权重矩阵梯度中第四行第二列的元素值 = 11.264104496527771
相对于输入权重矩阵梯度的形状 = (5, 3)
相对于隐藏状态权重矩阵梯度中第二行第三列的元素值 = 2.303333126579893
相对于隐藏状态权重矩阵梯度的形状 = (5, 5)
相对于偏置梯度中第五行的元素值 = [-0.74747722]
相对于偏置梯度的形状 = (5, 1)
RNN的前向传播、反向传播都是基于一个RNNcell的,于是我给代码添加了if __name__=='main'方法,这样可以使其 import 到其他的 python 脚本中被调用(模块重用)执行,简化后面代码的书写过程。
分别用Numpy、Pytorch实现反向传播算子,并代入数值测试对比
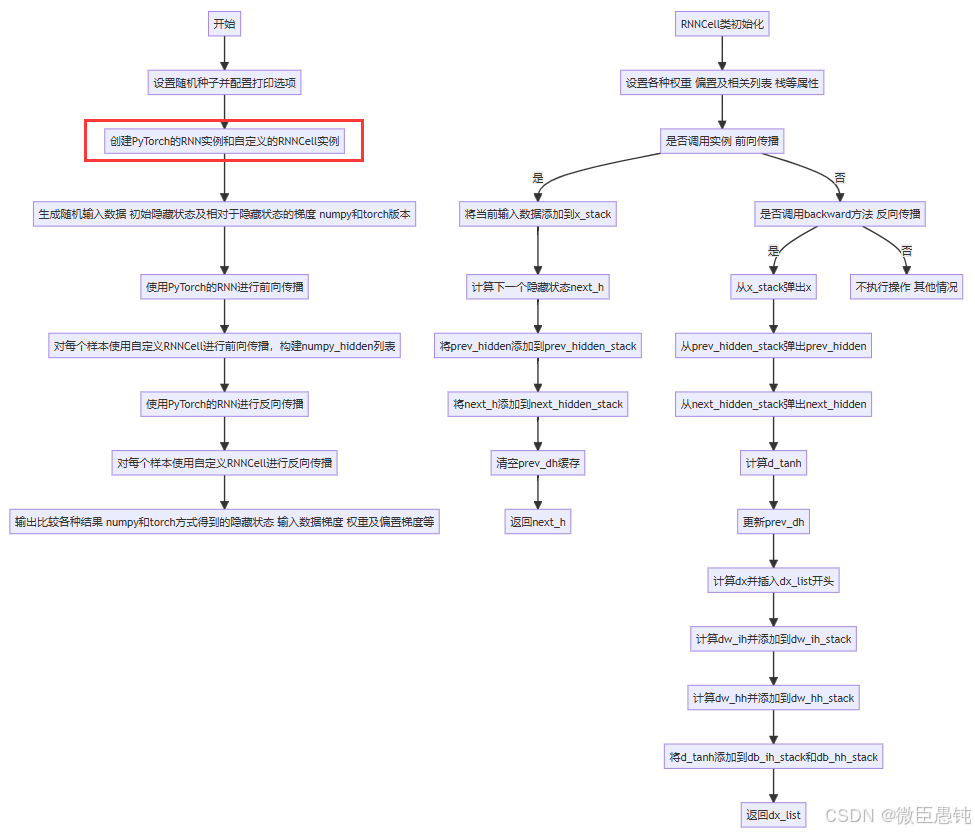
'''
@ Function: 分别用numpy和torch实现RNN的前向和反向传播
@Author: lxy
@ date: 2024/12/3
'''
import torch
import numpy as np
# 定义RNNCell类,用于实现一个简单的循环神经网络单元的功能
class RNNCell:
def __init__(self, weight_ih, weight_hh,
bias_ih, bias_hh):
"""
参数:
weight_ih: 输入到隐藏层的权重矩阵
weight_hh: 隐藏层到隐藏层的权重矩阵
bias_ih: 输入到隐藏层的偏置向量
bias_hh: 隐藏层到隐藏层的偏置向量
"""
self.weight_ih = weight_ih
self.weight_hh = weight_hh
self.bias_ih = bias_ih
self.bias_hh = bias_hh
# 用于存储输入数据的列表
self.x_stack = []
# 用于存储输入数据梯度的列表
self.dx_list = []
# 用于存储输入到隐藏层权重梯度的栈
self.dw_ih_stack = []
# 用于存储隐藏层到隐藏层权重梯度的栈
self.dw_hh_stack = []
# 用于存储输入到隐藏层偏置梯度的栈
self.db_ih_stack = []
# 用于存储隐藏层到隐藏层偏置梯度的栈
self.db_hh_stack = []
# 用于存储上一个隐藏状态的栈
self.prev_hidden_stack = []
# 用于存储下一个隐藏状态的栈
self.next_hidden_stack = []
# 临时缓存,用于存储上一步的隐藏状态梯度
self.prev_dh = None
def __call__(self, x, prev_hidden):
"""
使类的实例可像函数一样被调用,实现前向传播计算下一个隐藏状态
参数:
x: 当前时间步的输入数据
prev_hidden: 上一个时间步的隐藏状态
返回:
next_h: 当前时间步计算得到的下一个隐藏状态
"""
# 将当前输入数据添加到输入数据列表中
self.x_stack.append(x)
# 计算下一个隐藏状态,通过双曲正切函数激活
next_h = np.tanh(
np.dot(x, self.weight_ih.T)
+ np.dot(prev_hidden, self.weight_hh.T)
+ self.bias_ih + self.bias_hh)
# 将上一个隐藏状态添加到上一个隐藏状态栈中
self.prev_hidden_stack.append(prev_hidden)
# 将当前计算得到的下一个隐藏状态添加到下一个隐藏状态栈中
self.next_hidden_stack.append(next_h)
# 清空临时缓存,初始化为与下一个隐藏状态相同形状的零数组
self.prev_dh = np.zeros(next_h.shape)
return next_h
def backward(self, dh):
"""
实现反向传播,计算输入数据、权重和偏置的梯度
参数:
dh: 相对于当前隐藏状态的梯度
返回:
self.dx_list: 输入数据的梯度列表
"""
# 从输入数据列表中取出最后一个输入数据
x = self.x_stack.pop()
# 从上一个隐藏状态栈中取出最后一个上一个隐藏状态
prev_hidden = self.prev_hidden_stack.pop()
# 从下一个隐藏状态栈中取出最后一个下一个隐藏状态
next_hidden = self.next_hidden_stack.pop()
# 计算双曲正切函数的梯度,根据链式法则,结合传入的当前隐藏状态梯度dh和之前的缓存prev_dh
d_tanh = (dh + self.prev_dh) * (1 - next_hidden ** 2)
# 更新临时缓存prev_dh,用于下一次反向传播计算
self.prev_dh = np.dot(d_tanh, self.weight_hh)
# 计算输入数据的梯度
dx = np.dot(d_tanh, self.weight_ih)
# 将计算得到的输入数据梯度插入到输入数据梯度列表的开头
self.dx_list.insert(0, dx)
# 计算输入到隐藏层权重的梯度
dw_ih = np.dot(d_tanh.T, x)
# 将计算得到的输入到隐藏层权重梯度添加到对应的栈中
self.dw_ih_stack.append(dw_ih)
# 计算隐藏层到隐藏层权重的梯度
dw_hh = np.dot(d_tanh.T, prev_hidden)
# 将计算得到的隐藏层到隐藏层权重梯度添加到对应的栈中
self.dw_hh_stack.append(dw_hh)
# 将双曲正切函数的梯度添加到输入到隐藏层偏置梯度的栈中
self.db_ih_stack.append(d_tanh)
# 将双曲正切函数的梯度添加到隐藏层到隐藏层偏置梯度的栈中
self.db_hh_stack.append(d_tanh)
return self.dx_list
if __name__ == '__main__':
np.random.seed(123)
torch.random.manual_seed(123)
np.set_printoptions(precision=6, suppress=True)
# 创建一个PyTorch的RNN实例,输入维度为4,隐藏层维度为5,数据类型为双精度浮点数
rnn_PyTorch = torch.nn.RNN(4, 5).double()
# 创建一个自定义的RNNCell实例,使用PyTorch的RNN实例的权重和偏置数据
rnn_numpy = RNNCell(rnn_PyTorch.all_weights[0][0].data.numpy(),
rnn_PyTorch.all_weights[0][1].data.numpy(),
rnn_PyTorch.all_weights[0][2].data.numpy(),
rnn_PyTorch.all_weights[0][3].data.numpy())
nums = 3
# 生成随机的输入数据,形状为(nums, 3, 4),即3个样本,每个样本有3个时间步,每个时间步输入维度为4
x3_numpy = np.random.random((nums, 3, 4))
# 将生成的随机输入数据转换为PyTorch的张量,设置requires_grad=True以便计算梯度
x3_tensor = torch.tensor(x3_numpy, requires_grad=True)
# 生成随机的初始隐藏状态,形状为(1, 3, 5),即1个批次,3个样本,每个样本隐藏层维度为5
h3_numpy = np.random.random((1, 3, 5))
# 将生成的随机初始隐藏状态转换为PyTorch的张量,设置requires_grad=True以便计算梯度
h3_tensor = torch.tensor(h3_numpy, requires_grad=True)
# 生成随机的相对于隐藏状态的梯度,形状为(nums, 3, 5),即3个样本,每个样本有3个时间步,每个时间步隐藏层维度为5
dh_numpy = np.random.random((nums, 3, 5))
# 将生成的随机相对于隐藏状态的梯度转换为PyTorch的张量,设置requires_grad=True以便计算梯度
dh_tensor = torch.tensor(dh_numpy, requires_grad=True)
# 使用PyTorch的RNN实例进行前向传播,计算得到新的隐藏状态
h3_tensor = rnn_PyTorch(x3_tensor, h3_tensor)
h_numpy_list = []
h_numpy = h3_numpy[0]
# 对每个样本进行自定义RNNCell的前向传播计算
for i in range(nums):
h_numpy = rnn_numpy(x3_numpy[i], h_numpy)
h_numpy_list.append(h_numpy)
# 使用PyTorch的RNN实例进行反向传播,传入相对于隐藏状态的梯度
h3_tensor[0].backward(dh_tensor)
# 对每个样本进行自定义RNNCell的反向传播计算,传入相对于隐藏状态的梯度
for i in reversed(range(nums)):
rnn_numpy.backward(dh_numpy[i])
print("numpy方式得到的隐藏状态列表:\n", np.array(h_numpy_list))
print("torch方式得到的隐藏状态:\n", h3_tensor[0].data.numpy())
print("-----------------------------------------------")
print("numpy方式计算的输入数据梯度列表:\n", np.array(rnn_numpy.dx_list))
print("torch方式计算的输入数据梯度:\n", x3_tensor.grad.data.numpy())
print("------------------------------------------------")
print("numpy方式计算的输入到隐藏层权重梯度总和(按轴0求和):\n",
np.sum(rnn_numpy.dw_ih_stack, axis=0))
print("torch方式计算的输入到隐藏层权重梯度:\n",
rnn_PyTorch.all_weights[0][0].grad.data.numpy())
print("------------------------------------------------")
print("numpy方式计算的隐藏层到隐藏层权重梯度总和(按轴0求和):\n",
np.sum(rnn_numpy.dw_hh_stack, axis=0))
print("torch方式计算的隐藏层到隐藏层权重梯度:\n",
rnn_PyTorch.all_weights[0][1].grad.data.numpy())
print("------------------------------------------------")
print("numpy方式计算的输入到隐藏层偏置梯度总和(按轴0和轴1求和):\n",
np.sum(rnn_numpy.db_ih_stack, axis=(0, 1)))
print("torch方式计算的输入到隐藏层偏置梯度:\n",
rnn_PyTorch.all_weights[0][2].grad.data.numpy())
print("-----------------------------------------------")
print("numpy方式计算的隐藏层到隐藏层偏置梯度总和(按轴0和轴1求和):\n",
np.sum(rnn_numpy.db_hh_stack, axis=(0, 1)))
print("torch方式计算的隐藏层到隐藏层偏置梯度:\n",
rnn_PyTorch.all_weights[0][3].grad.data.numpy())numpy方式得到的隐藏状态列表:
[[[ 0.4686 -0.298203 0.741399 -0.446474 0.019391]
[ 0.365172 -0.361254 0.426838 -0.448951 0.331553]
[ 0.589187 -0.188248 0.684941 -0.45859 0.190099]]
[[ 0.146213 -0.306517 0.297109 0.370957 -0.040084]
[-0.009201 -0.365735 0.333659 0.486789 0.061897]
[ 0.030064 -0.282985 0.42643 0.025871 0.026388]]
[[ 0.225432 -0.015057 0.116555 0.080901 0.260097]
[ 0.368327 0.258664 0.357446 0.177961 0.55928 ]
[ 0.103317 -0.029123 0.182535 0.216085 0.264766]]]
torch方式得到的隐藏状态:
[[[ 0.4686 -0.298203 0.741399 -0.446474 0.019391]
[ 0.365172 -0.361254 0.426838 -0.448951 0.331553]
[ 0.589187 -0.188248 0.684941 -0.45859 0.190099]]
[[ 0.146213 -0.306517 0.297109 0.370957 -0.040084]
[-0.009201 -0.365735 0.333659 0.486789 0.061897]
[ 0.030064 -0.282985 0.42643 0.025871 0.026388]]
[[ 0.225432 -0.015057 0.116555 0.080901 0.260097]
[ 0.368327 0.258664 0.357446 0.177961 0.55928 ]
[ 0.103317 -0.029123 0.182535 0.216085 0.264766]]]
-----------------------------------------------
numpy方式计算的输入数据梯度列表:
[[[-0.643965 0.215931 -0.476378 0.072387]
[-1.221727 0.221325 -0.757251 0.092991]
[-0.59872 -0.065826 -0.390795 0.037424]]
[[-0.537631 -0.303022 -0.364839 0.214627]
[-0.815198 0.392338 -0.564135 0.217464]
[-0.931365 -0.254144 -0.561227 0.164795]]
[[-1.055966 0.249554 -0.623127 0.009784]
[-0.45858 0.108994 -0.240168 0.117779]
[-0.957469 0.315386 -0.616814 0.205634]]]
torch方式计算的输入数据梯度:
[[[-0.643965 0.215931 -0.476378 0.072387]
[-1.221727 0.221325 -0.757251 0.092991]
[-0.59872 -0.065826 -0.390795 0.037424]]
[[-0.537631 -0.303022 -0.364839 0.214627]
[-0.815198 0.392338 -0.564135 0.217464]
[-0.931365 -0.254144 -0.561227 0.164795]]
[[-1.055966 0.249554 -0.623127 0.009784]
[-0.45858 0.108994 -0.240168 0.117779]
[-0.957469 0.315386 -0.616814 0.205634]]]
------------------------------------------------
numpy方式计算的输入到隐藏层权重梯度总和(按轴0求和):
[[3.918335 2.958509 3.725173 4.157478]
[1.261197 0.812825 1.10621 0.97753 ]
[2.216469 1.718251 2.366936 2.324907]
[3.85458 3.052212 3.643157 3.845696]
[1.806807 1.50062 1.615917 1.521762]]
torch方式计算的输入到隐藏层权重梯度:
[[3.918335 2.958509 3.725173 4.157478]
[1.261197 0.812825 1.10621 0.97753 ]
[2.216469 1.718251 2.366936 2.324907]
[3.85458 3.052212 3.643157 3.845696]
[1.806807 1.50062 1.615917 1.521762]]
------------------------------------------------
numpy方式计算的隐藏层到隐藏层权重梯度总和(按轴0求和):
[[ 2.450078 0.243735 4.269672 0.577224 1.46911 ]
[ 0.421015 0.372353 0.994656 0.962406 0.518992]
[ 1.079054 0.042843 2.12169 0.863083 0.757618]
[ 2.225794 0.188735 3.682347 0.934932 0.955984]
[ 0.660546 -0.321076 1.554888 0.833449 0.605201]]
torch方式计算的隐藏层到隐藏层权重梯度:
[[ 2.450078 0.243735 4.269672 0.577224 1.46911 ]
[ 0.421015 0.372353 0.994656 0.962406 0.518992]
[ 1.079054 0.042843 2.12169 0.863083 0.757618]
[ 2.225794 0.188735 3.682347 0.934932 0.955984]
[ 0.660546 -0.321076 1.554888 0.833449 0.605201]]
------------------------------------------------
numpy方式计算的输入到隐藏层偏置梯度总和(按轴0和轴1求和):
[7.568411 2.175445 4.335336 6.820628 3.51003 ]
torch方式计算的输入到隐藏层偏置梯度:
[7.568411 2.175445 4.335336 6.820628 3.51003 ]
-----------------------------------------------
numpy方式计算的隐藏层到隐藏层偏置梯度总和(按轴0和轴1求和):
[7.568411 2.175445 4.335336 6.820628 3.51003 ]
torch方式计算的隐藏层到隐藏层偏置梯度:
[7.568411 2.175445 4.335336 6.820628 3.51003 ]
观察可以看出使用NMumpy与Pytorch计算得到的梯度结果一致。