
🌈 个人主页:十二月的猫-CSDN博客
🔥 系列专栏: 🏀编译原理_十二月的猫的博客-CSDN博客💪🏻 十二月的寒冬阻挡不了春天的脚步,十二点的黑夜遮蔽不住黎明的曙光
目录
1. 前言
为什么打算开始这一系列的文章——编译原理🎄🎄
其实本学期开始就一直想持续更新,陆陆续续主要更新了实验部分。
正好趁着快要考试,便和大家一起花费几天的时间回顾编译原理的知识点。
目前,十二月猫的回顾计划如下🔞🔞: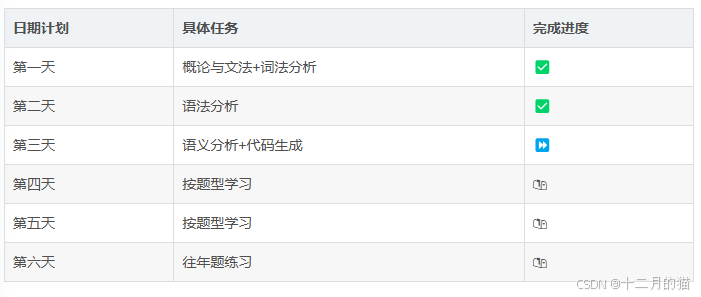
祝大家都能取得好成绩呀~~🥰🥰
参考书籍:
英文名:Compilers: Principles,Techniques,and Tools (龙书)🦖
作者:Alfred V.Aho,Ravi Sethi,Jeffrey D.Ullman
1.本课程介绍编译器构造的一般原理和基本实现方法,主要介绍编译器的各个阶段:词法分析、语法分析、语义分析、中间代码生成、代码优化和目标代码生成。
2.本课程在介绍命令式程序设计语言实现技术的同时,强调一些相关的理论知识,如形式语言和自动机理论、语法制导的定义和属性文法、类型论等。
3.本课程强调形式化描述技术,并以语法制导定义作为翻译的主要描述工具。
4.本课程强调对编译原理和技术在宏观上的理解,而不把读者的注意力分散到一些枝节的算法上,如计算开始符号集合和后继符号集合的算法,回填技术等。作为原理性的教材,本书介绍基本的理论和方法,而不偏向于某种源语言或目标机器。
2. 章节导读
如果问起来编译原理最迷的一章是什么,很多同学的回答将会是这一章,课本里讲了众多的不知道为什么会有的定义和莫名其妙的附加规则,但偏偏没有讲它们是为什么来的。你如果不信,想想这几个问题,为什么会有属性文法?有了那么多语法分析方法找出了语法错误对编译器难道不够么?它跟语法分析有什么联系呢?
首先我们要清楚编译器的工作并不是仅限于我们表面上在IDE里写程序时给我们提醒各种错误,其更重要的工作是将我们的源程序翻译成“目标代码”,翻译成机器能切切实实执行的代码,这是它最初最核心的功能。也就是说编译器首先要理解我们的源程序到底是想让机器干什么,这就是“语义”!你说,学到目前的章节为止,编译器有能力知道么?
没有哦,编译器现在通过词法,语法分析只知道了“结构”,举个例子,它现在知道 “if (a > b) { i++}”是符合语法的,“if (a > b) { i + }”是不符合语法的因为构造不出语法分析树,但真的 a > b了,计算机应该干什么呢?它现在还不知道该i++呢!只有我们学完了这两章,通过附加语义规则让计算机理解了if E {S}这个语法结构的语义是如果E是真的,就执行S的操作,我们才有可能让计算机理解并执行我们的源程序。
第六章主要站在方法论的角度讨论可以用什么样的方式来对不同的属性文法进行翻译,而第七章则举出了几个常用的例子(如何翻译布尔表达式的语义,如何翻译控制语句的语义)来应用第六章讨论的方法,明白所处的位置了吧,让我们开始!
一定要看🥰🥰🥰:
- 表示语义——属性文法
- 语义分析——属性求值
- 属性求值——属性先后计算顺序
- 属性先后计算顺序——依赖图和拓扑排序
- 语义分析和语法分析同时进行——两者顺序需要一样
3. 属性文法
属性文法用来表示语义
拿个实在的例子,对于台式计算器的语法制导定义

左边的一列我们前几章都熟悉,是产生式,右边的就是导读中解释的“语义规则”,即告诉计算机看到左边产生式该干什么,比如看到 E —> E1 + T这样的语法结构,语义规则告诉计算机应当做加法把E和T的值加起来E.val := E1 .val + T.val。
属性文法的定义由此而来,我们把左边的产生式和右边的语义规则的结合叫属性文法,对于每个文法符号(如E),它都有对应的属性(如.value)。
关键点:
- 属性文法 = 产生式 + 语义规则
- 在语义规则中给了文法以属性
3.1 综合属性与继承属性

综合属性是信息流流向产生式左部的属性,在语法树中体现为S属性节点被其子节点的属性值确立;继承属性是流向产生式右部的属性,在语法树中体现为被其父节点或兄弟节点的某些属性值确立的。
简单来说:
- 综合属性就是从右流向左的属性,从分析树的下面流向上面。
- 继承属性就是从左流向右部的属性,从兄弟节点和父节点流过来的属性
综合属性
在分析树上结点N的综合属性通过N的子节点和N本身的属性值来定义。
例如对于产生式E→E1+TE→E1+T,综合属性对应的语义规则可以是E.val=E1.val+T.valE.val=E1.val+T.val。
终结符可以具有综合属性。终结符的综合属性值是由词法分析器提供的词法值,因此在SDD中没有计算终结符属性值的语义规则。
继承属性
在分析树上N结点的继承属性只能通过N的父节点、兄弟节点或者N本身的属性值来定义。
终结符没有继承属性,终结符从词法分析器处获得的属性值被归为综合属性值。
3.2 不同属性文法
右边语义规则存在不同的写法,这会产生不同的属性文法类型。
不同的属性文法处理的方法也不同。
出现不同属性文法的原因就是为了匹配语义分析的流程,让语义分析和语法分析同时进行
S-SDD
仅仅使用综合属性的SDD称为S属性的SDD,也叫S-属性定义,S-SDD。
例如:

这里面所有属性均是综合属性,都是根据子构造的属性 计算出父构造的属性,所以可以自底向上的计算每个属性。
L-SDD
L-属性定义,也叫L属性的SDD或者L-SDD。
一个SDD是L-属性定义,当且仅当它的每个属性要么是一个综合属性,要么是满足如下条件的继承属性:假设存在一个产生式A→X1X2...Xn,其右部符号Xi(1≤i≤n)的继承属性仅依赖于下列属性:
- A的继承属性
- 产生式中XiXi左边的符号 X1,X2,…,Xi−1 的属性
- Xi本身的属性,但Xi的全部属性不能在依赖图中形成环路
所以对于L-SDD,所有的分析树属性都依赖于左边或者下边的节点。所以不会存在环路。
每个S-属性定义都是L-属性定义
4. 语法制导定义(SSD)
语法制导定义和属性文法分不开关系,就是有属性文法,我们才能根据属性文法和产生式构造出分析树,并根据分析树进行语法制导翻译,完成语义分析。
4.1 根据属性文法构造分析树(依赖图)
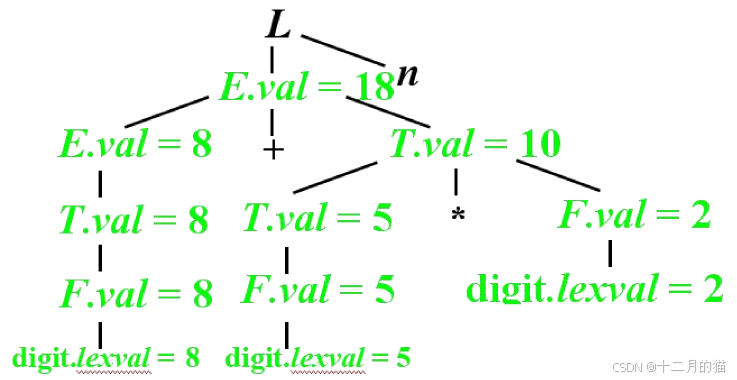
4.1.1 S-SDD分析树
属性文法如下:

S-SDD分析树如下:
4.1.2 L-SDD分析树
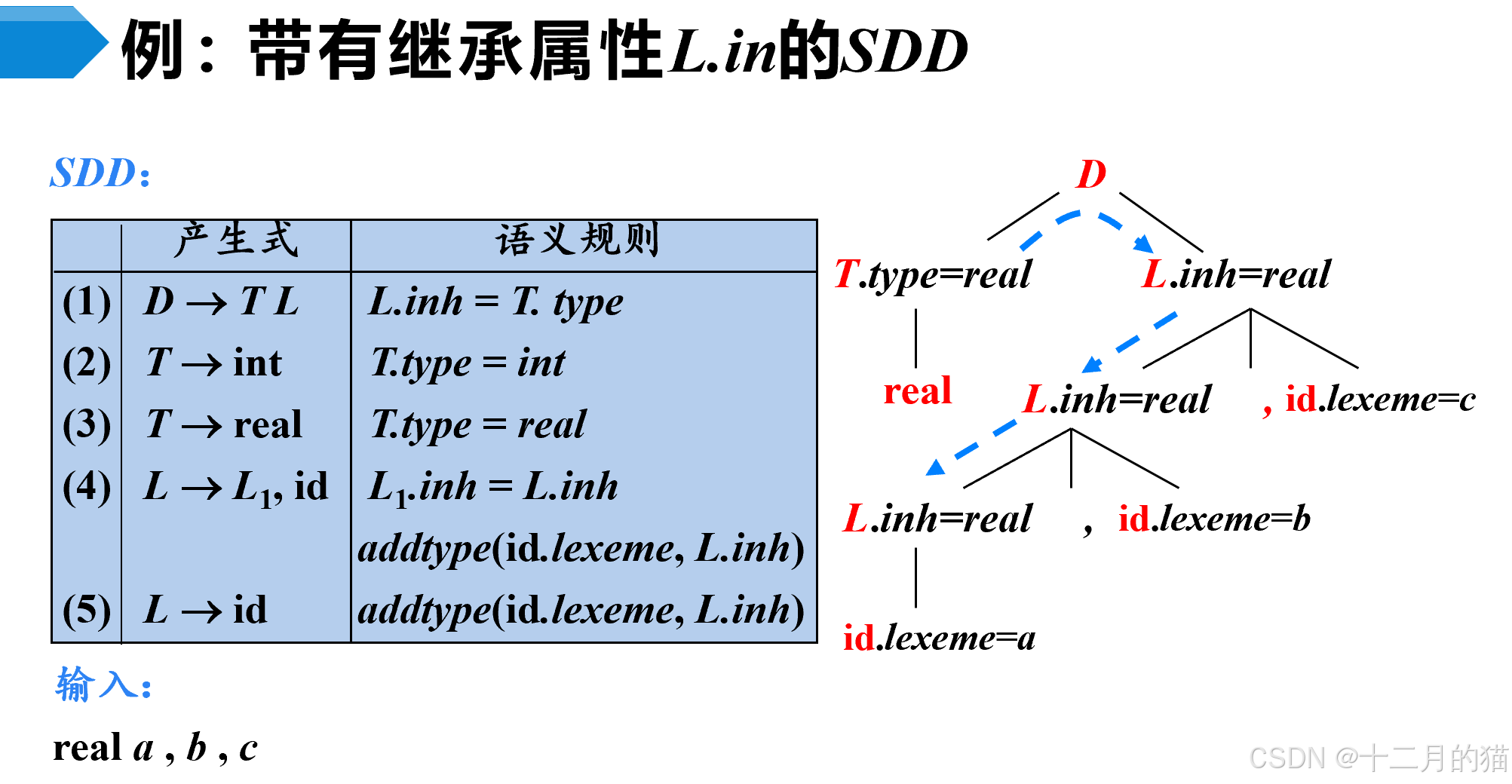
在上面这个SDD就是一个带有继承属性的SDD。首先根据产生式(1)对应的语义规则,得到了最上面的L.inh=T.type=real,然后根据产生式(4)对应的语义规则,得到Lbellow.inh=Lup.inh,然后同样的道理依据产生式(4)得到Lbellow.inh=Lup.inh。
4.2 分析树的计算顺序
- 这边的计算顺序也就是语义分析的顺序。
- 这里的SDD语义分析顺序和语法分析顺序没有关系。
- S-SDD和L-SDD语义分析顺序和语法分析顺序相联系。
SDD为CFG中的文法符号设置语义属性。对于给定的输入串xx,我们将应用语义规则,计算分析树中各结点对应的属性值。SDD声明了语法分析树上属性之间的依赖关系,按照这种依赖关系的拓扑排序可以确定他们的求值顺序。
依赖图是一个有向图,它描述了分析树中结点属性之间的依赖关系。一个依赖关系图有拓扑排序的充要条件是无环。一个依赖图的示例如下所示: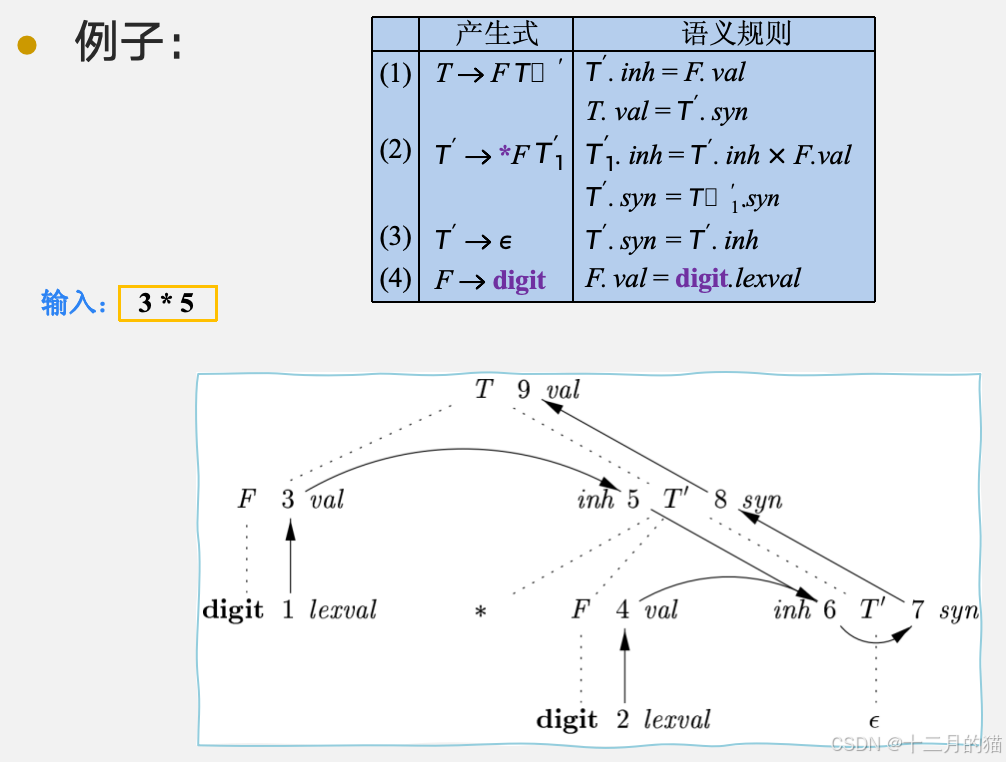
一般说来,给定一个SDD,很难确定是否存在某棵语法分析树,但是,**S-属性定义(S-SDD)和L-属性定义(L-SDD)**一定存在一个拓扑排序,并且这两类SDD可以和自顶向下和自底向上的语法分析过程一起实现。
不同属性文法语法制导得到的分析树如何计算:
- L里面所有属性均是综合属性,都是根据子构造的属性计算出父构造的属性,所以可以自底向上的计算每个属性。
- 对于L-SDD,所有的分析树属性都依赖于左边或者下边的节点。所以不会存在环路。
5 抽象语法树
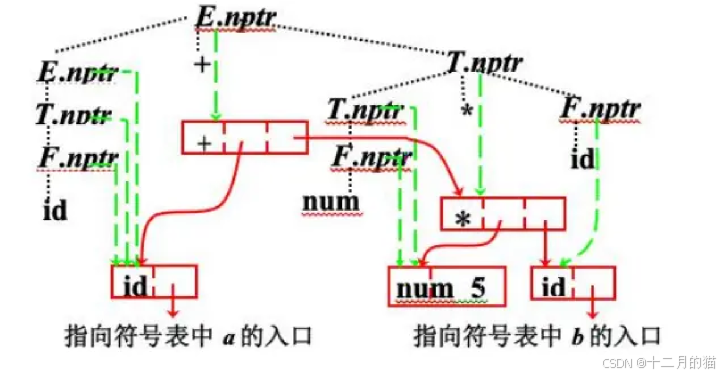
适用于翻译的语法结构不只是语法分析树,抽象语法树将操作符和关键字都不作为叶节点而是把它们当作内部节点,使用如下产生规则构造,可以看出它的核心就在于只为id,num,运算符创造节点(mkleaf(),mknode()),T到E,F到T的规约,E到F的规约只是子树的转移。

最终对a+5*b构造抽象语法树的结果如下图所示,画出如何通过属性文法边分析语法结构(绿线)边构造抽象语法树(红线)也是一个很重要的考察点。
6. 语法制导翻译
将一个S-SDD转换为SDT的方法:将每个语义动作都放在产生式的最后
这就是在做语法归约时从右往左去进行,除了推导外要加上语义信息

将L-SDD转换为SDT:
- 将计算L-SDD某个非终结符号A的继承属性的动作插入到产生式右部中紧靠在A的本次出现之前的位置上。
- 将计算一个产生式左部符号的综合属性的动作放置在这个产生式右部的最右端
这就是在做语法推导时,除了推导外要加上语义信息

SDT可以看作是对SDD的一种补充,是SDD的具体实施方案;它明确指明语义规则的计算顺序,说明实现细节。
5.1 S属性文法的自下而上计算(语法制导翻译的实现)
如果一个SDD的基础文法是LR文法并且此SDD是S属性定义的,那么我们可以构造这样一个SDT,其中的每个动作都放在产生式的最后,并且在按照这个产生式将产生式体归约为产生式头的时候执行这个动作。像这样所有动作都在产生式体最右端的SDT也称为后缀翻译方案(后缀SDT)。
将一个S属性定义的且基础文法为LR文法的SDD转换为一个SDT的规则如下:
- 将计算一个产生式头的综合属性的动作放置在这个产生式体的最右端。
注意到,由于表1中的SDD是S属性定义的且其基础文法G是LR文法,因此可以把它转换成后缀SDT,表3中的SDT就是此SDD的一个转换形式。下面我们进一步改进表3中的SDT,使其能够在语法分析过程中实现: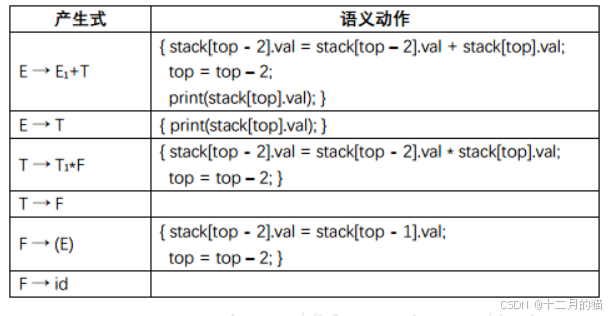
表4中的stack表示LR语法分析栈,top指向栈顶。为了帮助读者理解这个SDT中的语义动作,以产生式F→(E)为例,考虑将(E)归约成F的过程,如图6所示: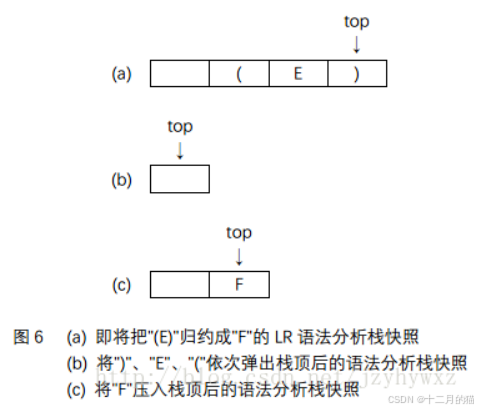
图6显示了把(E)归约成F的LR语法分析过程。图6(a)是即将把(E)归约成F的语法分析栈快照,此时有stack[top]=")",stack[top-1]="E",stack[top-2]="("。执行的归约动作是连续3次出栈操作(将”)”、”E”、”(“依次弹出栈顶,如图6(b))和1次入栈操作(将”F”压入栈顶,如图6(c))。注意到,(c)中的top相当于(a)中的top-2,也就是说,F实际上出现在(a)中的stack[top-2]处;另外,由于E.val将被赋值给F.val,并且E出现在(a)中的stack[top-1]处,因此在(a)中有stack[top-2].val=stack[top-1].val;将(a)变成(c)还需要执行2次出栈操作(实际上是3次出栈操作和1次入栈操作),因此还需要把top指针向下移动2位。
5.2 从SDT中消除左递归
在详细介绍如何在语法分析过程中实现L属性定义的SDT之前,我们先来介绍如何从SDT中消除左递归。在介绍语法分析的时候我们知道了带有左递归的文法不能按照自顶向下的方式进行语法分析,并且我们还知道如何从一个左递归的文法中消除左递归。当文法是SDT的一部分时,我们还需要考虑如何处理其中的语义动作。
情况1
最简单的情况是,我们只需要关心一个SDT中动作的执行顺序。在这种情况下,当对文法进行消除左递归的转换时,可以简单地将动作当成终结符号处理。之所以可以这样做,是因为对文法的转换保持了由文法生成的符号串中终结符号的顺序。举个例子,对下面的SDT:
E → E+T { print('+'); }
E → T将动作看作终结符号,消除左递归后得到的SDT为:
E → TR
R → +T { print('+'); } R | ε情况2
另一种比较复杂的情况是,一个SDT的动作包含了对属性值的计算。举个例子,对下面的SDT:
A → A1Y { A.a = g(A1.a, Y.y); }
A → X { A.a = f(X.x); }现在尝试在文法中加入语义动作。我们给文法符号R附加上两个属性,一个属性i是继承属性,它用来保存函数f和g的结果,另一个属性s是综合属性,它会在计算结束后返回最终的计算结果。得到的SDT为:
A → X { R.i = f(X.x); } R { A.a = R.s; }
R → Y { R1.i = g(R.i, Y.y); } R1 { R.s = R1.s; }
R → ε { R.s = R.i; }5.3 S属性文法的自上而下计算(语法制导翻译的实现)
如果一个SDD的基础文法能够以自顶向下的方式进行语法分析,并且此SDD是L属性定义的,那么我们可以把这个SDD转换成一个L属性定义的SDT。
将一个L属性定义的SDD转换为一个SDT的规则如下:
- 将计算某个非终结符号A的继承属性的动作插入到产生式体中紧靠在A的本次出现之前的位置上。如果A的多个继承属性以无环的方式相互依赖,就需要对这些属性的求值动作进行排序,以便先计算需要的属性;
- 将计算一个产生式头的综合属性的动作放置在这个产生式体的最右端。
在语法分析过程中实现L属性定义的SDT的方法包括:
- 使用一个递归下降的语法分析器。它为每个非终结符号都建立一个函数,对应于非终结符号A的函数以参数的形式接受A的继承属性,并返回A的综合属性;
- 使用一个递归下降的语法分析器,以边扫描边生成的方式生成代码;
- 与LL语法分析器结合实现一个SDT。属性的值存放在语法分析栈中,各个规则从栈中的已知位置获取需要的属性值;
- 与LR语法分析器结合实现一个SDT。如果基础文法是LL的,我们总是可以按照自底向上的方式来处理语法分析和翻译过程。
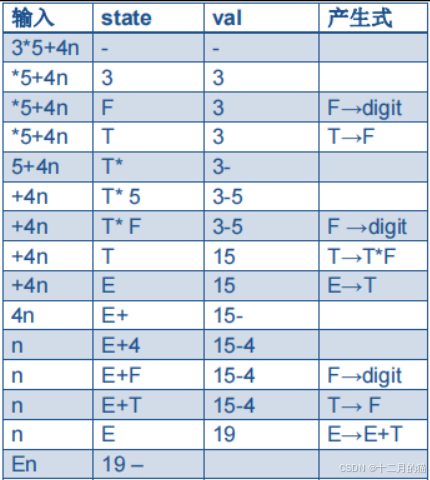
6. 一些习题
例一:
解答:

例二:

解答:
7. 总结
本文到这里就结束啦~~
本系列专栏将专注于【编译原理】知识。
内容包括:知识点讲解、习题练习、重点知识带练等~~目前已完成:
【编译原理】编译原理知识点汇总·词法分析器(正则式到NFA、NFA到DFA、DFA最小化)-CSDN博客
【编译原理】编译原理知识点汇总·语法分析器(消除左递归、消除二义性、自顶向下语法分析、自下向上语法分析)-CSDN博客
【编译原理】词法分析器设计(山东大学实验一)_山东大学编译原理实验-CSDN博客
【编译原理】语法、语义分析器设计(山东大学实验二)_语法分析实验-实现一个简单语法分析器(自上而下方法)实验小结-CSDN博客
【编译原理】代码生成器的构建与测试(山东大学实验三)_编译原理实验语义分析代码-CSDN博客 【编译原理】一篇搞定正规式到NFA、NFA到DFA、DFA最小化-CSDN博客
【编译原理】一篇搞定语法分析器对文法的要求(上下文无法文法、消除二义性文法、消除左递归)-CSDN博客
【编译原理】一篇搞定LR分析法(LR(1)、LR(0)、SLR、LALR)-CSDN博客
期待您的关注~~🥰🥰
猫猫陪你永远在路上💪💪
如果觉得对你有帮助,友友们可以点个赞,收个藏呀~
