IOMMU
1.IOMMU(Input-Output Memory Management Unit):IOMMU是一种内存管理单元,专门用于处理外设(如网卡、硬盘控制器、GPU等)与主内存之间的地址映射。IOMMU允许外设使用虚拟地址来访问主内存,而不是物理地址。它的作用类似于MMU(Memory Management Unit),但IOMMU是用于外设的内存访问管理。IOMMU的实现为IO设备提供了DMA接口和功能,并为IO设备提供了SVA(Shared Virtual Addressing)功能。SMMU是一种特殊类型的IOMMU,通常用于ARM架构(但其他架构也有类似的实现)。SMMU主要用于管理系统内存,并提供对外设和加速器(如GPU、DSP、NPU等)内存访问的虚拟地址翻译和内存保护。SMMU发展历程如下图:

SMMU的使用方式如下图所示:
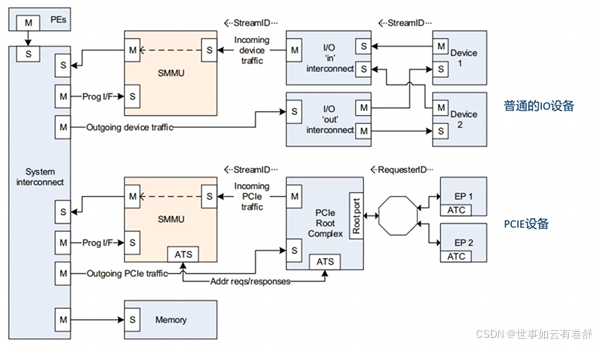
对于输入(传送数据到CPU)需要进过SMMU进行地址转换,对于输出(CPU向外传输数据)则不用经过SMMU。
2.MMU-600(基于SMMUv3.1规范实现的控制器):支持2阶段的地址转换或者Bybass模式,MMU-600将设备IOVA转换到PA,可实现:Stage1:转换IOVA->PA 或者IOVA ->IPA、Stage2:IPA -> PA、Both:IOVA->IPA->PA或者Bypass模式(即相当于没有MMU-600),其结构如下图所示:
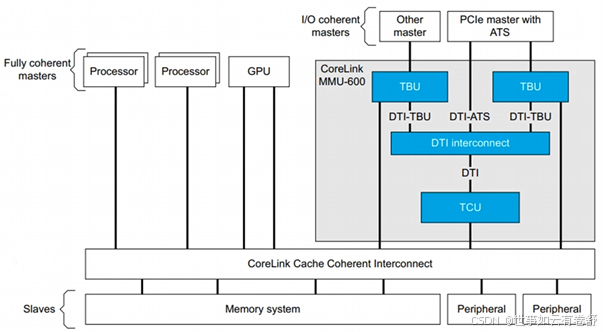
上图中的主要组成单元有:TBU (Translation Buffer Unit):包含TLB用来缓存转换结果、每个连接的Master至少有一个TBU、如果TBU没有找到TLB表项,那么发送请求给TCU;TCU(Translation Control Unit):进行地址转换的硬件单元、MMU-600只有一个TCU管理内存请求、遍历页表、执行配置页表、Implements backup caching structures、SMMU编程接口;DTI:用来连接TBU到TCU使用AXI stream协议。
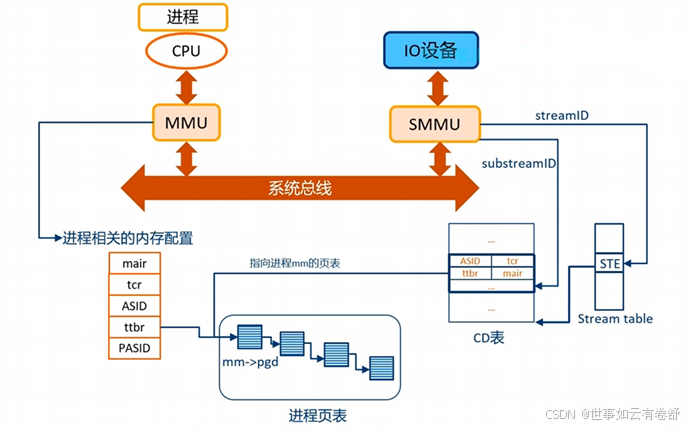
3.Stream ID:Stream ID主要用来关联和区分一个设备,可以用Steam ID用来索引Stream Table,Stream Table包含per-SMMU相关的页表信息,在 IOMMU 的管理下,设备使用的 IOVA 会被转换成物理地址(PA),在这种转换过程中,设备通过 Stream ID 来识别不同的虚拟地址空间(每个设备有不同的地址空间,他们可能有相同的IOVA),并在 IOMMU 中查询相应的页表条目来完成地址映射。一次DMA传输包括:目标地址,大小,读写属性,安全属性,共享属性,缓存性,以及Stream ID。对于PCle设备,Stream ID[15:0]==Requester lD[15:0],等于BDF(Bits [15:8]: Bus number、Bits [7:3]: Device number、Bits [2:0]: Function number),对于非PCle设备,通过DTS(Device Tree Source)来获取Stream ID。Stream Table中的每个表项STE(Stream Table Entry)包含了stage2转换的页表基地址、一个指向Context Descriptors的指针。Context Descriptors里面包含了stage1的转换页表基地址、ASID、页表属性等信息。Steam Table需要OS软件来创建和填充。如下图所示:
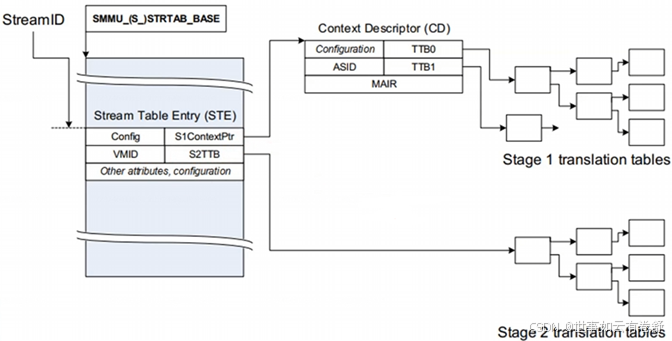
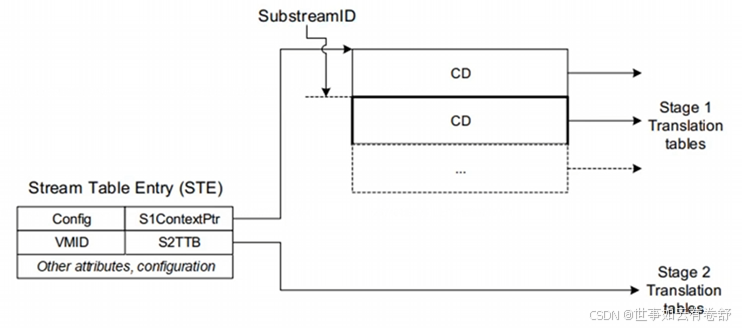
支持虚拟化时Hypervisor管理Stream Table和stage2页表,Guest OS管理Context Descriptors和stage1页表,没有虚拟化时OS管理Stream Table和Context Descriptors。一个设备可能被多个进程使用,SMMU通过Substream ID来进行区分,可以每个进程有一个Substream ID,STE中的S1ContextPtr指向一个CD表,Substream ID用来索引这个表,每个Context Descriptors里都包含了stage1中要用的页表基地址。对于PCIe设备,使用PASID作为Substream ID。如下图所示:
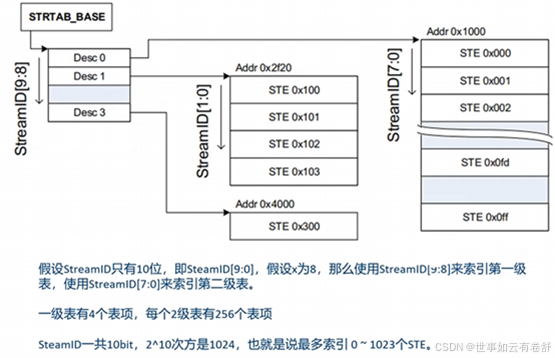
Steam Table可以使用一级或者二级表,当STE数量大于64时必须使用二级表。Stream ID[n:x]索引第一级表,Stream lD[x-1 :0]索引第二级表,N表示Stream ID的最高位,通常是15,X是Split点。例如: 对于n=15、x=8,那么Stream ID[15:8]索引第一级表,Stream ID[7:0]索引第二级表,下图是一个例子:
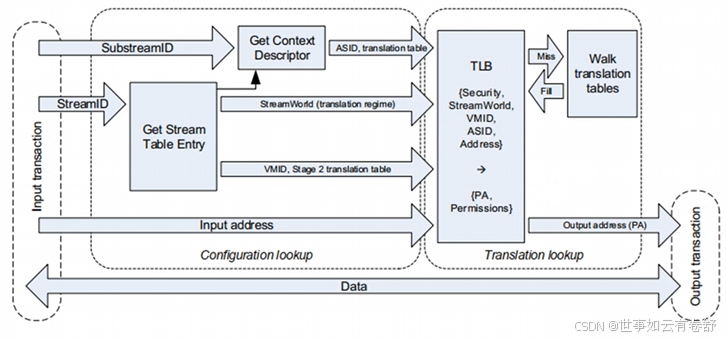
下图展示了SMMU的地址转换过程:
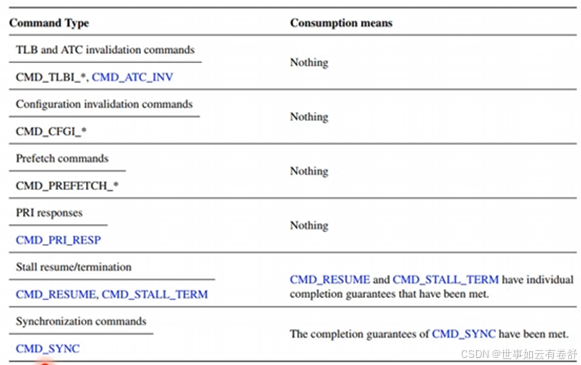
与GICv3类似,SMMU通过command queue和event queue来控制硬件实现输入输,command queue用于输入(CPU发送给外设),event queue用于输出(外设传数据给CPU)。每个queue都有生产者和消费者,输出队列包含由SMMU产生的数据,然后由软件来消费,输入queue是由软件产生数据,然后SMMU来消费。支持的命令如下所示(可参考SMMUv3手册第4章):
4.IOMMU Domain:每个IOMMU Domain包含一个或多个设备,这些设备共享同一个IOMMU页表,因此它们的虚拟地址空间(IOVA)是相互隔离的。每个设备访问内存时,都需要通过IOMMU进行地址转换,IOMMU会根据设备的Stream ID来查询页表,进行虚拟地址到物理地址的转换。
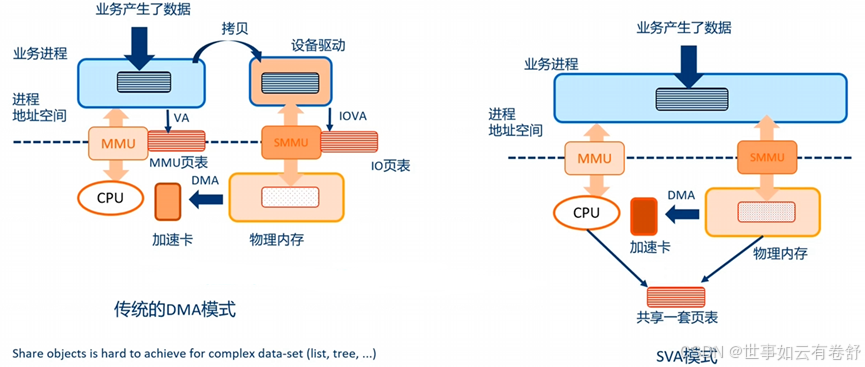
5.SVA(Shared Virtual Addressing): 是一种通过共享虚拟地址空间来简化内存访问和资源共享的机制,主要应用于多处理器或多核系统中。它可以提高内存共享的效率,并优化数据传输和通信,但也需要处理缓存一致性等问题。下图展示了SVA机制的好处,省去了拷贝的步骤,提高了性能:
如下图所示,展示了SVA的具体实现原理,进程的MMU和设备的SMMU之间共享同一个页表,实现了进程和设备的绑定:
在SVA中IO缺页异常处理过程如下:对于CPU侧的缺页异常走CPU的缺页异常处理方式(handle_mm_fault);对于设备侧的缺页异常,若是PCle设备则利用PR扩展(Page Request Interface),若是平台设备则利用SMMU的stall模式(Stall模式:当IO设备触发异常时,传输事务被暂停,把这个事件记录在even queue里,OS软件需要处理,然后发送CMDRESUME命令恢复传输事务。)
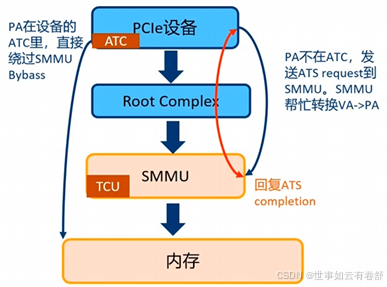
6.PCIe中的ATS(Address Translation Services)支持:设备缓存虚拟地址(VA)对应的物理地址(PA)放在ATC(Address Translation Cache)中,类似于TLB,在进行内存访问时无需经过SMMU页表转换。在设备执行直接内存访问(DMA)前,会查询ATC是否有对应的VA条目。如果存在,直接使用PA访问内存;如果不存在,则发送ATS请求至SMMU,SMMU找到PA后回复ATS完成。如下图所示:
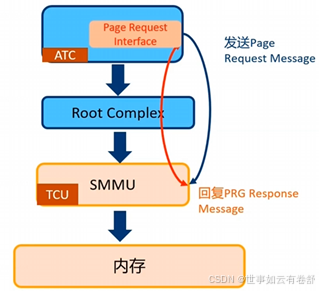
7.PRI(Page Request Interface):是一种用于处理DMA(直接内存访问)操作中的内存分配的机制。它允许在DMA操作开始之前,不必预先分配(pinned)DMA缓冲区,从而减少了对内存资源的预分配需求。这对于高速网络设备尤其有用,因为在高速数据传输(burst)情况下,主机(Host)不需要提前预留和占用大量的缓冲区。其工作流程为:当设备的地址翻译缓存(ATC)在查找TLB时发现缺失,它会发送一个Page Request Message给SMMU、SMMU将缺页请求写入PRI队列,并触发一个PRI中断、操作系统(OS)软件响应这个中断,申请所需的物理内存、一旦物理内存被分配,操作系统软件会回复一个CMD_PRI_RESP命令,以完成内存分配过程。如下图所示:
AMBA总线
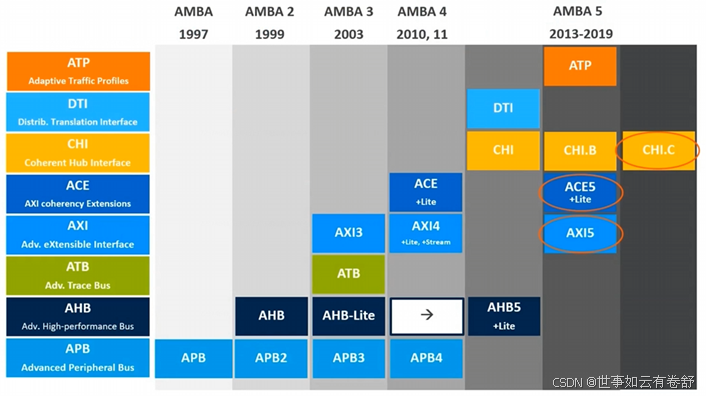
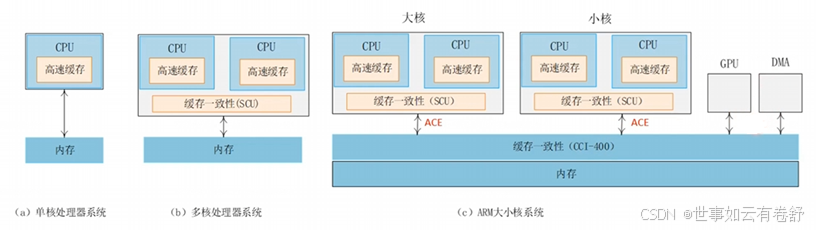
1.AMBA(Advanced Microcontroller Bus Architecture):是ARM公司开发的一种开放标准的总线架构,主要用于片上系统(SoC,System on Chip)设计中。AMBA定义了一组接口和协议,旨在提高不同模块(如处理器、内存、外设等)之间的通信效率,并促进SoC的设计和开发。下图展示了AMBA总线协议的发展历程:
外部总线:连接外围设备,易受外界干扰,信号完整性差,例如I2C、UART、SP、PCle、USB;内部总线:用于soc内部,在芯片内部走线,距离极短,很多干扰和信号完整性问题不需要考虑,如AXI总线。
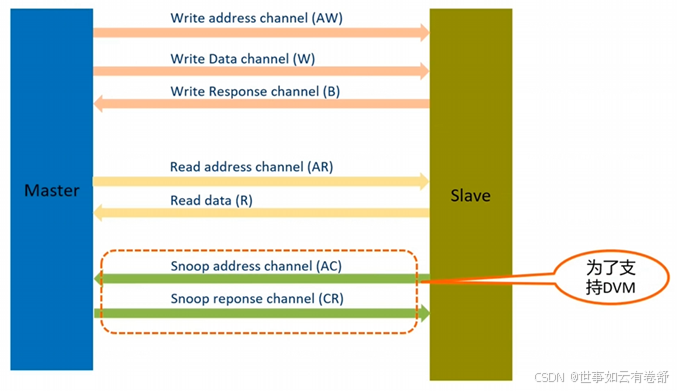
2.AXI总线(Advanced eXtensible Interface):是一个芯片内部的同步串行总线。AXI总线优点有:高带宽(high-bandwidth)、低延时(low-latency)、高频率(High-frequency)、可灵活扩展总线位宽以及拓扑连接、兼容AHB和APB总线。AXI总线特点如下:
- 独立的地址/控制和数据通道(sperate read & write channel)
- 支持burst传输(指在数据传输过程中,允许数据以连续的、高速的块(burst)形式进行传输,而不是单个数据包逐一传输)
- 支持超前传输(multiple outstanding addresses)
- 在发送地址与数据阶段之间没有严格的时序要求
- 支持乱序传输 (out-of-order transaction completion)
- 支持非对齐数据传输(support unaligned data transfer)
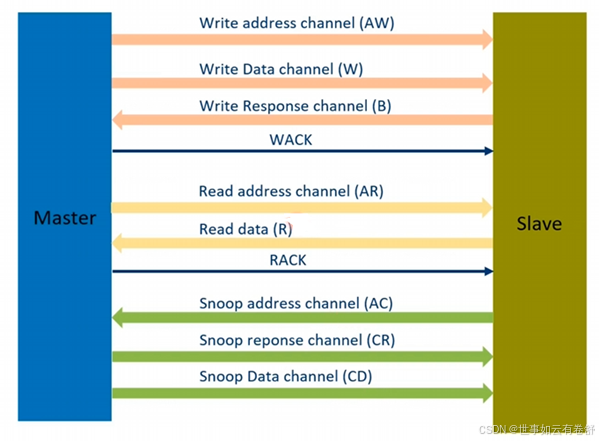
AXI总线采用主从机制,只能由master发起请求,slave对请求进行应答,支持一对一、一对多、多对一及多对多连接,如下图所示:
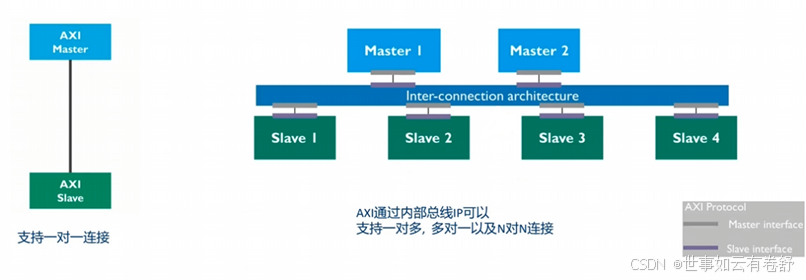
AXI定义了五个独立的传输通道(channel),如下图所示:

- 读地址通道AR
- 读数据通道R
- 写地址通道AW
- 写数据通道W
- 写回应通道B
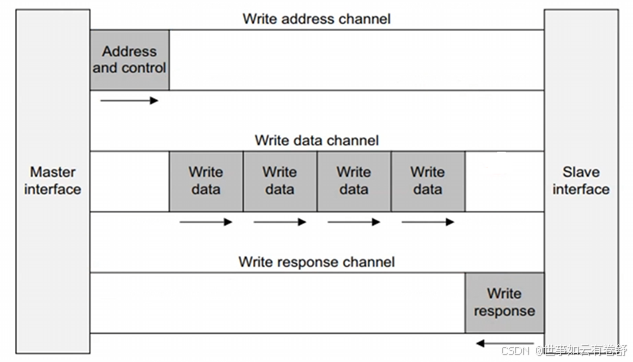
需要注意的是,每个channel不止一根信号线,而是一组信号线。写传输事务步骤为:首先master通过write address channel发起写传输,包括地址和控制信息,接着master通过write data channel写数据给slave,然后slave通过write response channel回应。如下图所示:
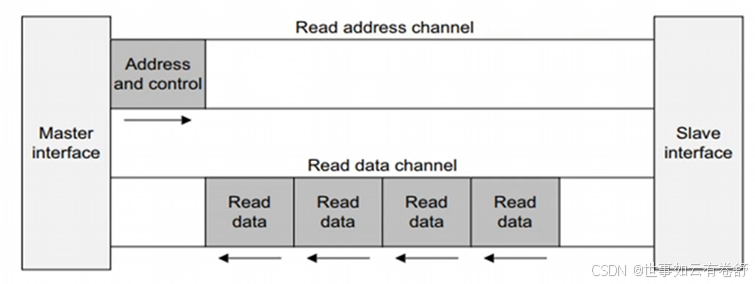
读传输事务步骤为:master通过read address channel发送地址和控制信息给slave,slave通过read data channel返回数据,回应信息包含在返回数据里。如下图所示:
握手信号:5个channel都使用相同的握手信号,即VALID和READY,source端产生VALID信号表明地址,数据,控制信号等已经ready了,destination端产生READY信号表明它可以开始接收信息了。如下图:

下面两张图展示了五个通道的信号线的具体组成:
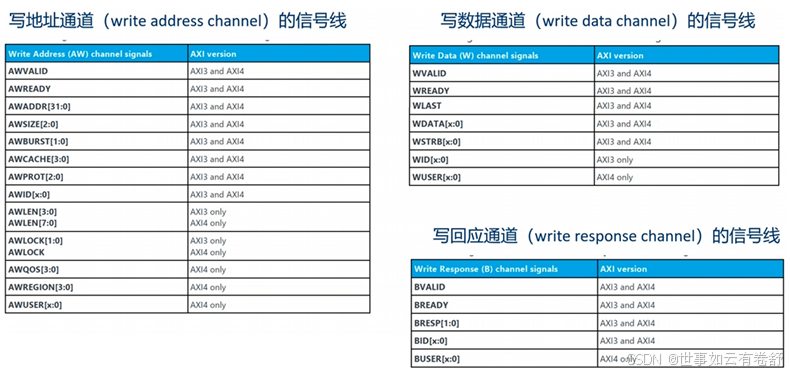
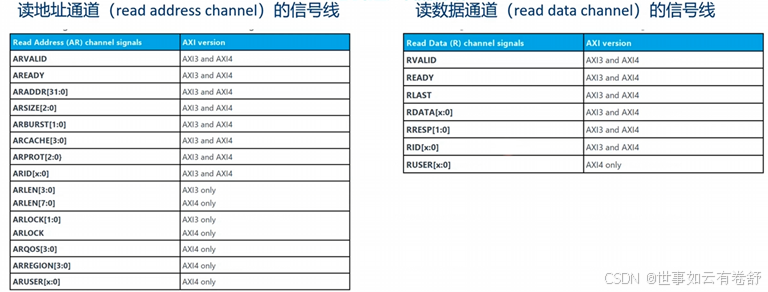
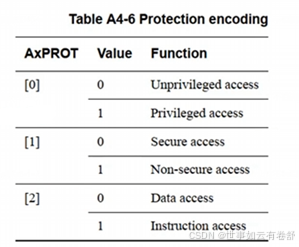
AxLEN[3:0](或AxLEN[7:0],x可为W或R表示写地址或读地址通道,下同)用来指明一次burst传送的数据数量,在AXI3协议中,一次最多可以包括16个数据,计算公式为Length=AxLEN[3:0]+1;在AXI4协议中,一次最多可以包括256个数据,计算公式为Length=AxLEN[7:0]+1。AxSIZE信号线用来指明每个数据的大小,例如0b111表示128字节。AxBURST指明传输类型,有以下三种:FIXED:固定地址模式,适用于FIFO(先进先出队列);INCR:地址递增模式,适用于RAM,支持1到256个数据,并且支持未对齐的传输(unaligned transfer);WRAP:地址递增,达到上限后绕回,适用于Cache。ARPROT[2:0]和AWPROT[2:0]分别用来指明读事务和写事务的访问权限,具体如下表所示:
AxCACHE[3:0]信号线用来实现对高速缓存的支持,如下图:
xRESP[1:0]信号线用来实现回应,如下图所示,OKAY表示normal access成功或者exclusive access has failed;EXOKAY表示exclusive access成功;SLVERR表示slave error;DECERR表示解码错误。

WDTRB[N:0]用来表示WDATA上数据是否有效,一个bit表示一个字节,若为1表示有效,这主要是为了支持不对齐访问。AxQOS[3:0]信号用来提供优先级,0表示最低优先级,FF表示最高优先级。
3.各通道之间的依赖关系如下:
- 依赖关1:在AWVALID有效之前,WVALID先设置是有效的。其中,AWVALID表示write address channel有效,WVALID表示write data channel有效。也就是说写地址有效之前,可以先把数据发送出去
- 依赖关系2: 在BVALID有效之前,必须发送WLAST。其中BVALID表示write response channel有效,WLAST表示是事务中最后一个数据transfer。也就是说在写回应包发送之前,所有的写data和地址address必须发送完成
- 依赖关系3:在ARADDR发送完成之前,RVALID不能有效。其中ARADDR表示读事务的第一个数据transfer的地址,RVALID表示read data channel有效。也就是说如果地址没有发送完成,不应该看到有读数据返回
4.Locked accesses:只在AXI3协议中存在,AXI4已经将其遗弃,因为Locked accesses操作会直接将总线锁住,除了占有总线的master之外,其他master都无法使用总线。AXI4引入了Exclusive accesses,该机制主要用于实现对特定内存位置的原子操作(例如,读取并写入一个内存位置的操作),以便实现一些同步机制,例如在并发系统中处理互斥锁、计数器或信号量等。Exclusive access比Locked access更高效,不需要锁住总线,其他master可以同时访问总线。但需要在slave端实现exclusive monitor来协同完成exclusive access。具体访问流程为:
- master发起exclusive读,slave的exclusive monitor把读事物的ID(ARID),地址以及数据填入到exclusive monitor表里面
- master对同一个地址发起exclusive写操作。exclusive monitor查表并比较写事务ID(AWID)和读事物ID(ARID)是否一致。若返回EXOKAY(成功),表示ID一致,这期间没有其他master对这个地址进行写入,那么exclusive写操作就成功;如果返回OKAY(失败),表示这个期间有其他master对这个地址进行写入或还没有进行读操作,那么exclusive写失败
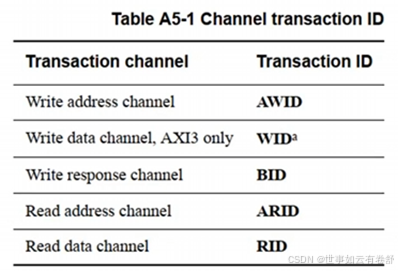
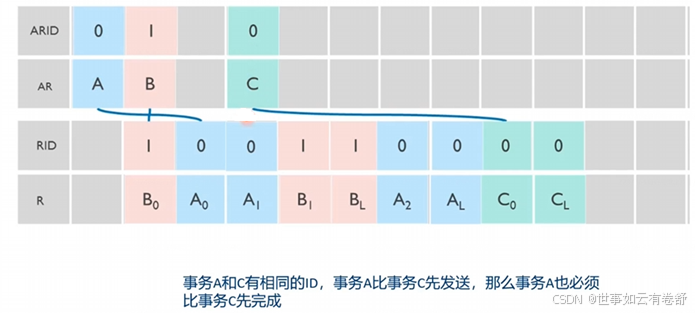
5.乱序传输:AXI为每个事务通道有一个独立的事务ID,所有的transfer(即各个通道里传输的一个个数据)必须有一个ID,在同一个事务里的transfer有相同的ID,使用事务ID是为了乱序传输,ID定义如下表:
写事务规则如下:
- 在write data channel写数据的次序必须和write address channel中的地址传输次序一致
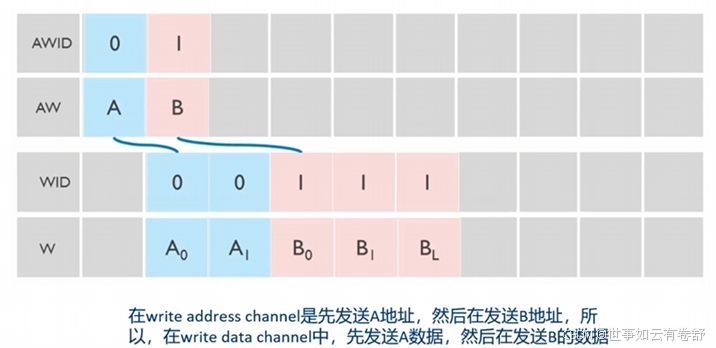
- 不同ID的写事务之间可以任意次序完成:
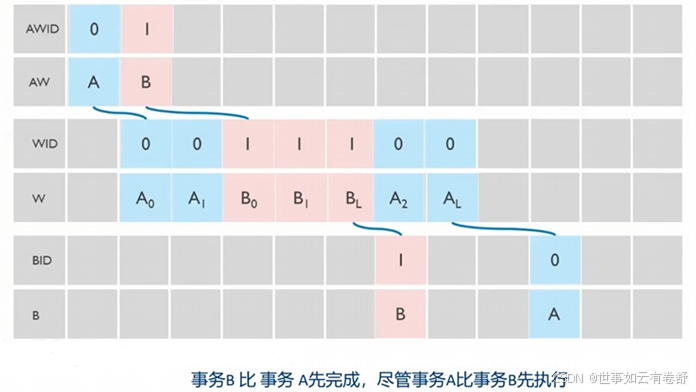
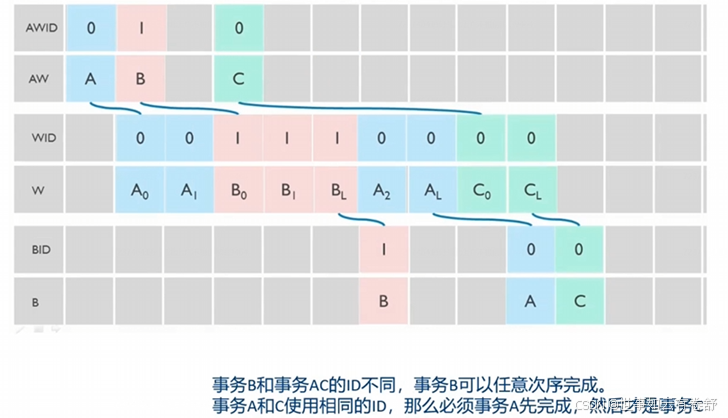
- 相同ID的事务,按照顺序执行和按照顺序完成:
读事务规则如下:
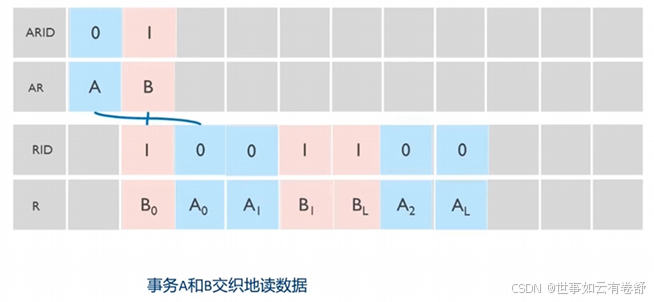
- 在read data channel中不同的ID的事务可以任意次序:

- 不同的ID的事务的传输在read data channel可以交织地读取:
- 相同ID的事务必须按顺序完成
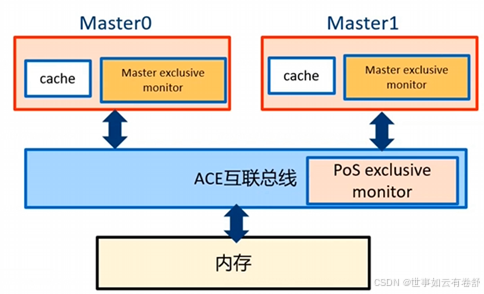
6.ACE(AXI Coherency Extensions):是一个在AXI(Advanced eXtensible Interface)协议基础上扩展出来的机制,旨在支持缓存一致性协议,确保多个处理器或核心访问共享内存时的数据一致性。是基于AXI总线的硬件缓存一致性解决方案。如下图:
ACE给cache定义了几种状态:valid(cache line有效)、invalid(cache line无效)、unique(表示这个cache line是独占,只有当前master有)、shared(多个master都有这个cache line的拷贝)、clean(表示cache line的内容和内存一致)、dirty(cache line的内容和内存不一致,稍后需要回写到内存),这几个状态组合起来共有下表所示的几种情况:

ACE在AXI的基础上新增了几个通道,如下图所示:
另外,对于AXI中原有的五个通道,ACE有增加了以下信号线(具体可参考AMBA® AXI and ACE Protocol Specification手册的D3.1节):

引入shareability domain的目的是确定事务的作用范围,例如在发起coherency或者barrier传输事务之前,master用来确定这些事务传输应该发送给哪些master。了如对于coherent事务:确定哪些master可能有这个数据的拷贝,用来发送snoop事务,对于barrier事务(内存屏障):确定与哪些master会建立排序的关系,以及barrier事务要传播到多远。
7.Snoop事务(Snoop Transaction)是一个用于缓存一致性的概念,特别是在多核处理器或多处理器系统中。当多个处理器或核心访问共享内存时,它们可能在各自的缓存中持有数据的副本。为了确保这些缓存中的数据始终保持一致,需要通过一种机制来检测并响应其他核心对内存的访问,这就是Snoop。
8.ACE也支持Exclusive access,执行流程为:执行exclusive load、计算、执行exclusive store,在此期间如果有其他master对这个地址写操作则fail,在此期间如果没有其他master对这个地址写操作则success。对于Non-shareable和System shareable内存地址进行ACE的exclusive access,其行为与AXI一样;对于inner share和outer share内存Master的exclusive monitor保证在exclusive load之后没有其他master来写这个地址,与总线互联的Pos exclusive monitor用来实现访问序列化。如下图所示:
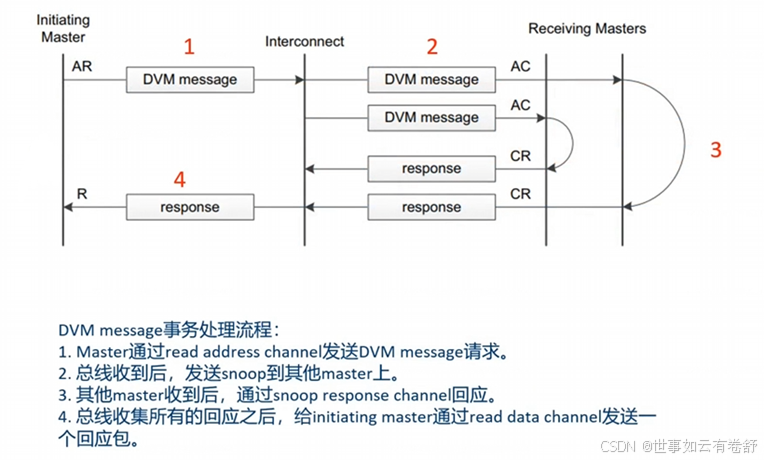
9.DVM (Distributed Virtual Memory) :在ARM架构中,分布式虚拟内存(DVM)与TLB一致性密切相关。DVM确保多个核心共享同一虚拟地址空间,并通过适当的协议和机制来维护不同核心的TLB缓存一致性。DVM主要用于TLB广播,它可以发送广播到其他master:实现TLB Invalidate、Branch Predictor Invalidate、Physical instruction Cache Invalidate、Virtual instruction Cache Invalidate、Synchronization等。DVM message transactions的流程如下图所示(总线上的信号传递):
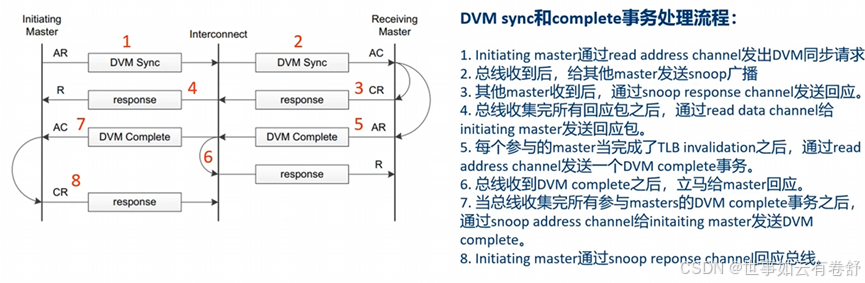
DVM Synchronization和DVM Complete transactions的流程如下图:
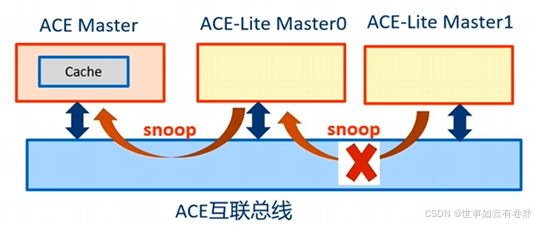
ACE-Lite:应用在不需要参与系统缓存一致性的硬件设备,例如没有本地cache的硬件设备,如下图所示:
ACE-Lite和DVM常常组合使用,此时总线结构如下图:
ACE-Lite和DVM应用场景如下图:
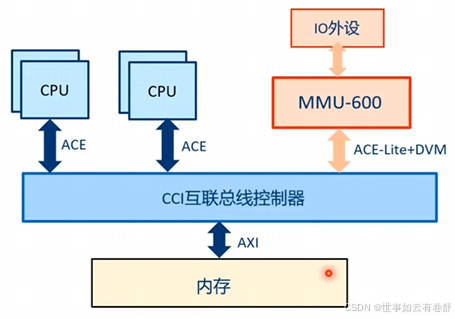
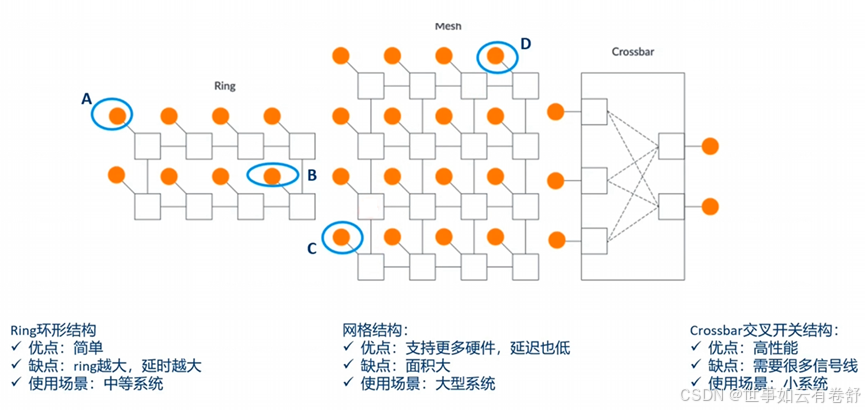
10.CHI总线(Coherent Hub Interface):是ARM架构中一种用于高效连接处理器核心、外设和内存控制器的高速总线接口标准,是下一代的硬件缓存一致性协议。常见的总线连接结构及其优缺点如下图所示,从左到右依次是环形结构、网络结构和交叉开关结构:
Arm® Core Link™ CI-700(某款CHI总线)的网络结构如下图所示:
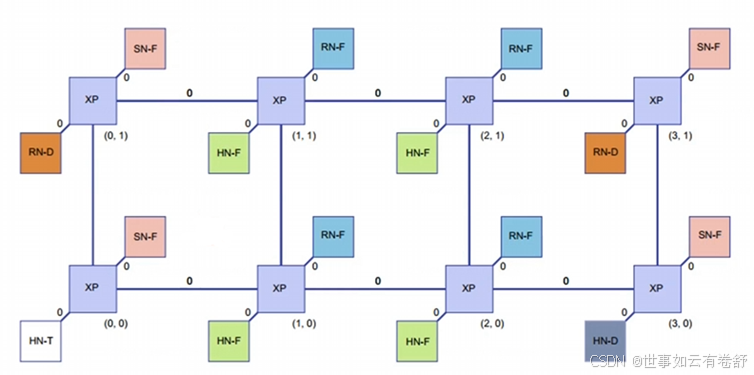
CI-700最大支持8个CPU cluster、最大支持12个crosspoint(XP,即路由或者switch的硬件组件),C1-700通过XP组成一个网格,每个XP可以有上下左右4个邻居XP,每个网格可以支持4个device port,每个device port可以用来连接缓存一致性的master(RN-F)或者slave设备(SN-F)。CI-700网络结构中的各个节点定义如下图所示:

下图是一个各个节点使用的例子:
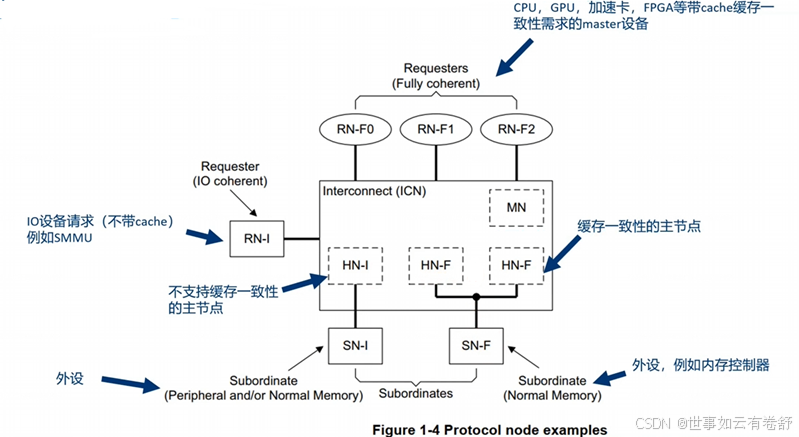
和ACE类似,CHI给cache定义了几种状态:valid(cache line有效)、invalid(cache line无效)、unique(表示这个cache line是独占,只有当前master有)、shared(多个master都有这个cache line的拷贝)、clean(表示cache line的内容和内存一致)、dirty(cache line的内容和内存不一致,稍后需要回写到内存),这几个状态组合起来共有下表所示的几种情况(红色部分是CHI相对于ACE新增的状态):

CHI定义的channel和ACE完全不一样,如下图:
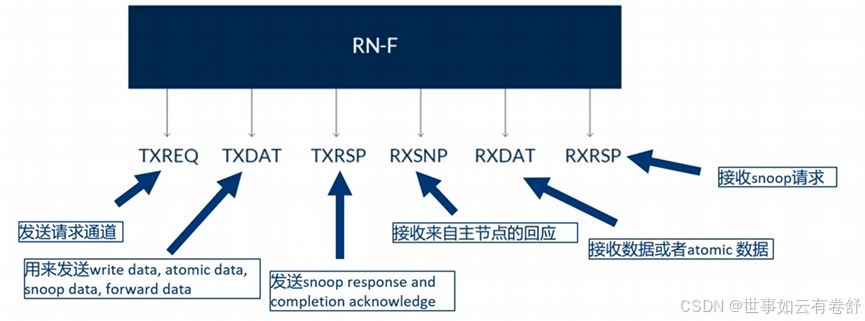
在CHI中,channel中的握手协议与AXI/ACE不同,FLITV信号拉高,表明transmitter准备发送数据包,包已经valid;LCDRV信号拉高表明receiver发送一个credit给transmitter:你可以发送了。
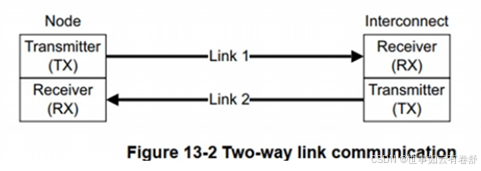
11.CHI的链路层为节点和互连IP之间基于packet-base的通信提供了一种流线型的机制,提供了一种two-way link传输模式:Transmitter->Receiver和Receiver ->Transmitter。如下图:
CHI用Flit(Flow control unit)来描述包,是在链路层传输的最小单元,一个packet包含多个Flits。Flit可分为:用来传输协议信息的Protocol Flit(又可分为Request flit、Response flit、Snoop flit和Data flit)和用来传输链路维护(link maintenance)信息的Link Flit,每个flit都有自己的格式(具体可参考CHI手册的第13.9章)。CHI中的消息包(protocol messages)包括各种ID,opcodes,内存属性,地址,数据error response等信息。CHI中定义的各种ID如下图(可参考CHI手册第2.2和2.5章):

12.CHI中的exclusive access与ACE中的类似,如下图:
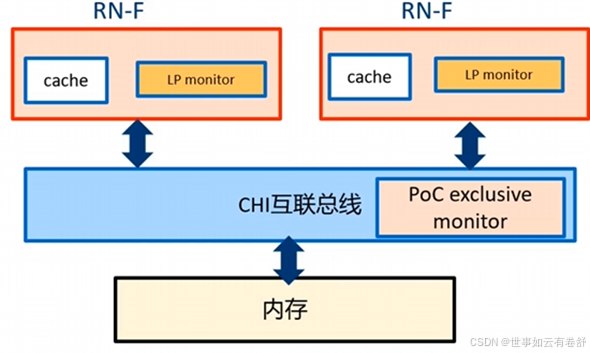
LP monitor位于RN-F,每个RN-F必须实现一个exclusive monitor,用来观察和监视exclusive访问的那个内存地址。当CPU开始一个exclusive load的时候,LP monitor会被设置。当下面情况,LP monitor会被reset:如果这个地址被其他LP改写了;如果LP对这个地址执行了另外一个store操作。PoC monitor位于HN-F,PoC monitor会记录每一个LP执行exclusive访问的snoop事务,monitor会并行地监视所有LP的exclusive访问。当HN-F收到一个exclusive load或者store操作,monitor就会把这个信息注册为:某某正在尝试一个exclusive访问。当LP执行exclusive store失败之后,LP需要重启exclusive load 和store的访问序列。当HN-F收到一个exclusive store操作:如果在PoC monitor里已经注册了这个地址对应的exclusive 访问记录,并且它还没有被其他LP给reset掉,那么exclusive store会成功,然后其他所有尝试exclusive的访问记录会被reset;如果LP执行一个exclusive访问,但是在PoC monitor里没有找到,那么exclusive store会失败。
13.CHI支持atomic access:Atomic访问在CHB协议中添加,Atomic访问允许在靠近数据的地方执行运算和计算(HN-F或者SN里面有ALU逻辑计算单元)Atomic访问的好处主要有:更准确和可预测的延时;不用和其他requester争用cache,减少了访问内存出现的阻塞和cache颠簸;公平性:多个requester同时访问一个内存地址时候,通过Pos或者POC来做仲裁。如下图:
下图展示了atomic access支持的四种操作:
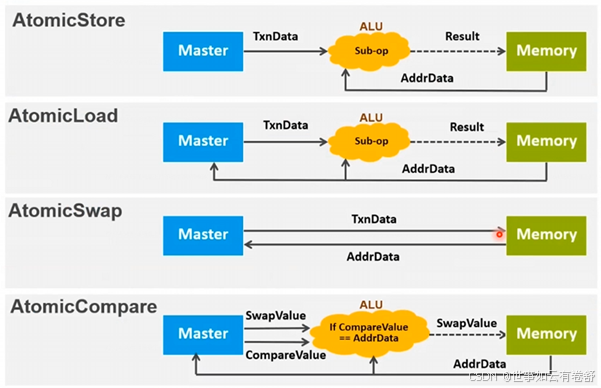
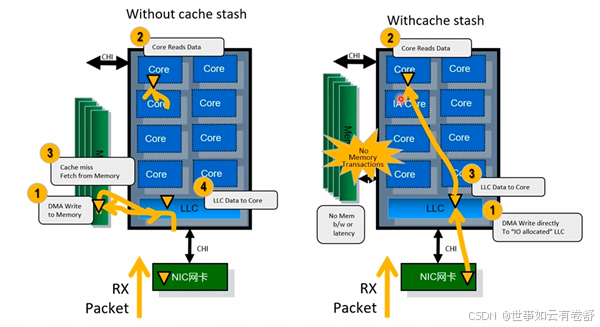
14.CHI引入的新特性如下:
- cache stash:IO设备可以直接把数据写入到目标RN-F的cache里面(而不用经过DMAbuffer),引入cache stash后的效果如下图:
- DMT(Direct Memory Transfer)和DCT(Direct Cache Transfer):这两个特性是在CHI.B中引入的,引入这两个特性前后的区别如下图所示:
