Spark SQL
概述
Spark SQL是Apache Spark用于处理结构化数据的模块
特点
1 易整合。无缝的整合了 SQL 查询和 Spark 编程
2 统一的数据访问。使用相同的方式连接不同的数据源

3 兼容 Hive。在已有的仓库上直接运行 SQL 或者 HQL

4 标准数据连接。通过 JDBC 或者 ODBC 来连接

代码
创建 DataFrame
1. 首先,在spark的bin目录下,创建data目录,在里面创建一个json文件,名为 user.json 文件中的数据为:
{"username":"zhangsan","age":20}
{"username":"lisi","age":17}
2. 读取 json 文件创建 DataFrame--------df
val df = spark.read.json("D:/spark/bin/data/user.json")

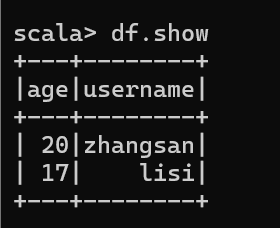
3. 展示数据:
df.show
SQL语法
1. 读取数据-----df1
val df1 = spark.read.json("D:/spark/bin/data/user.json")

2. 对 DataFrame 创建一个临时表
df1.createOrReplaceTempView("people")

3. 通过 SQL 语句实现查询全表
val sqlDF = spark.sql("select * from people")

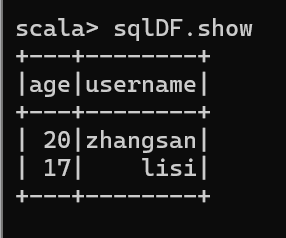
4. 结果展示
sqlDF.show
DSL语法
1. 创建一个 DataFrame-----df2
val df2 = spark.read.json("D:/spark/bin/data/user.json")

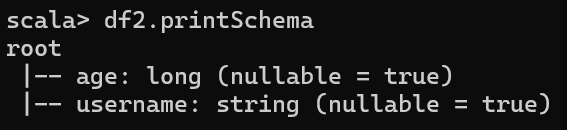
2. 查看 DataFrame 的 Schema 信息
df2.printSchema
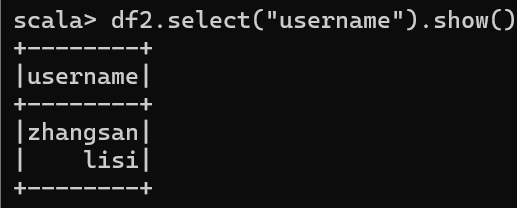
3. 只查看"username"列数据
df2.select("username").show()
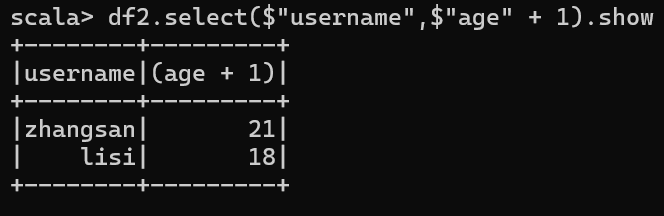
4. 查看"username"列数据以及"age+1"数据
注意:涉及到运算的时候, 每列都必须使用$, 或者采用引号表达式:单引号+字段名
df2.select($"username",$"age" + 1).show
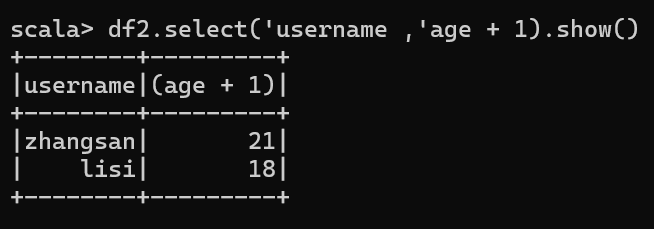
df2.select('username ,'age + 1).show()
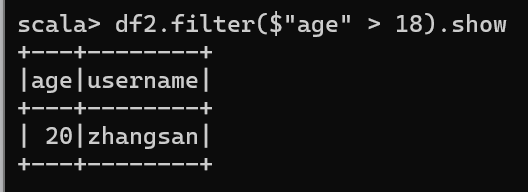
5. 查看"age"大于"18"的数据
df2.filter($"age" > 18).show
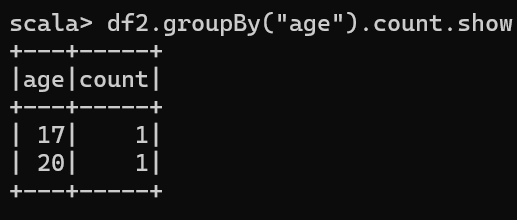
6. 按照"age"分组,查看数据条数
df2.groupBy("age").count.show
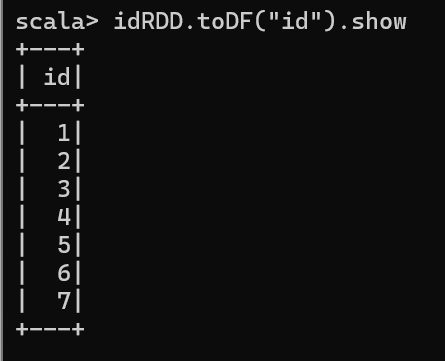
RDD 转换为 DataFrame

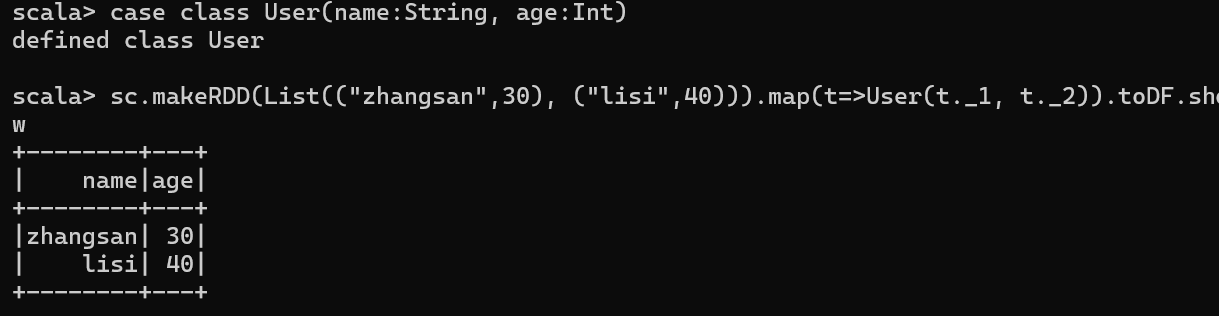
DataFrame 转换为 RDD
val df3 = sc.makeRDD(List(("zhangsan",30), ("lisi",40))).map(t=>User(t._1, t._2)).toDF

val rdd = df.rdd

val array = rdd.collect

注意:此时得到的 RDD 存储类型为 Row
array(0)

array(0)(0)

array(0).getAs[String]("name")

DataSet
1. 使用样例类序列创建 DataSet
case class Person(name: String, age: Long)

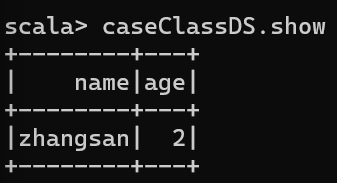
val caseClassDS = Seq(Person("zhangsan",2)).toDS()

caseClassDS.show
2. 使用基本类型的序列创建 DataSet
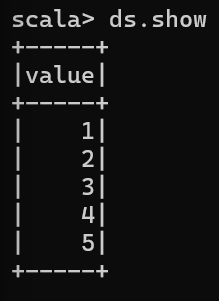
val ds = Seq(1,2,3,4,5).toDS

ds.show
注意:在实际使用的时候,很少用到把序列转换成DataSet,更多的是通过RDD来得到DataSet
RDD 转换为 DataSet
case class User(name:String, age:Int)

sc.makeRDD(List(("zhangsan",30), ("lisi",49))).map(t=>User(t._1, t._2)).toDS

DataSet 转换为 RDD
case class User(name:String, age:Int)

val aaa = sc.makeRDD(List(("zhangsan",30), ("lisi",49))).map(t=>User(t._1, t._2)).toDS

val rdd = aaa.rdd

rdd.collect

DataFrame 和 DataSet 转换
DataFrame 转换为 DataSet
case class User(name:String, age:Int)

val df = sc.makeRDD(List(("zhangsan",30), ("lisi",49))).toDF("name","age")

val ds = df.as[User]

DataSet 转换为 DataFrame
val ds = df.as[User]

val df = ds.toDF

RDD、DataFrame、DataSet 三者的关系
三者的共性
RDD、DataFrame、DataSet 全都是 spark 平台下的分布式弹性数据集,为处理超大型数
据提供便利;
三者都有惰性机制,在进行创建、转换,如 map 方法时,不会立即执行,只有在遇到Action 如 foreach 时,三者才会开始遍历运算;
三者有许多共同的函数,如 filter,排序等;
在对 DataFrame 和 Dataset 进行操作许多操作都需要这个包:
import spark.implicits._(在创建好 SparkSession 对象后尽量直接导入)
三者都会根据 Spark 的内存情况自动缓存运算,这样即使数据量很大,也不用担心会内存溢出
三者都有分区(partition)的概念
DataFrame 和 DataSet 均可使用模式匹配获取各个字段的值和类型
三者的区别
1. RDD
RDD 一般和 spark mllib 同时使用
RDD 不支持 sparksql 操作
2. DataFrame
与 RDD 和 Dataset 不同,DataFrame 每一行的类型固定为Row,每一列的值没法直接访问,只有通过解析才能获取各个字段的值
DataFrame 与 DataSet 一般不与 spark mllib 同时使用
DataFrame 与 DataSet 均支持 SparkSQL 的操作,比如 select,groupby 之类,还能注册临时表/视窗,进行 sql 语句操作
DataFrame 与 DataSet 支持一些特别方便的保存方式,比如保存成 csv,可以带上表头,这样每一列的字段名一目了然
3. DataSet
Dataset 和 DataFrame 拥有完全相同的成员函数,区别只是每一行的数据类型不同。
DataFrame 其实就是 DataSet 的一个特例 type DataFrame = Dataset[Row]
DataFrame 也可以叫 Dataset[Row],每一行的类型是 Row,不解析,每一行究竟有哪些字段,各个字段又是什么类型都无从得知,只能用上面提到的 getAS 方法或者共性里提到的模式匹配拿出特定字段。而 Dataset 中,每一行是什么类型是不一定的,在自定义了 case class 之后可以很自由的获得每一行的信息。
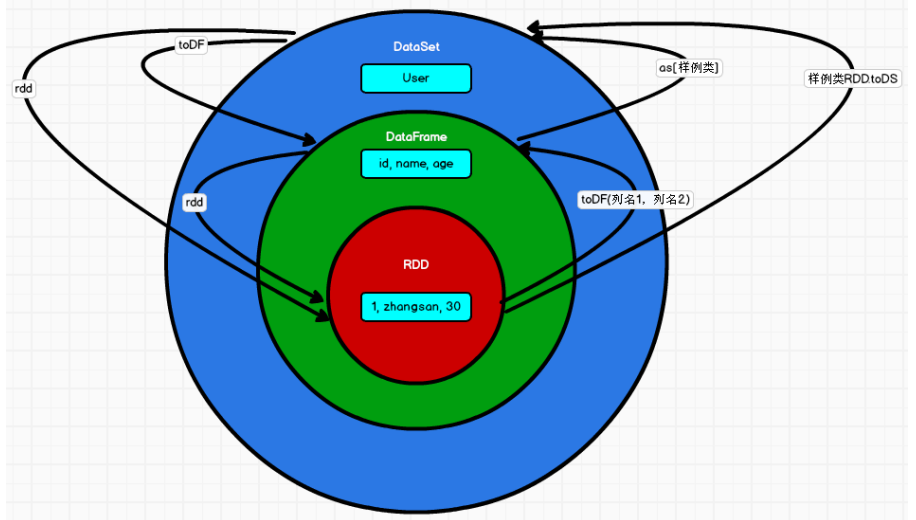
三者可以通过上图的方式进行相互转换。