YOLO(You Only Look Once)的数据处理流程是为了解决目标检测领域的核心挑战,核心目标是为模型训练和推理提供高效、规范化的数据输入。其设计方法系统性地解决了以下关键问题,并对应发展了成熟的技术方案:
一、解决的问题与对应方法
1. 输入图像尺寸归一化
问题:
原始图像的尺寸、长宽比差异巨大(如 1920×1080、640×480)导致无法直接批量训练。
方法:
- Letterbox调整(自适应填充缩放):
- 将图像按长边缩放到目标尺寸(如 640×640),保持原始长宽比不变
- 对短边进行对称填充(填充灰色或黑色像素),保证输入统一为方阵
# YOLOv5的letterbox实现示例 def letterbox(im, new_shape=(640, 640)): # 计算缩放比例并调整图像 shape = im.shape[:2] # 原始尺寸 [height, width] r = min(new_shape[0] / shape[0], new_shape[1] / shape[1]) new_unpad = int(round(shape[1] * r)), int(round(shape[0] * r)) dw = new_shape[1] - new_unpad[0] # 宽度填充量 dh = new_shape[0] - new_unpad[1] # 高度填充量 dw, dh = np.mod(dw, 64), np.mod(dh, 64) # 保证填充量能被stride整除 im = cv2.resize(im, new_unpad, interpolation=cv2.INTER_LINEAR) # 添加对称填充 top, bottom = dh // 2, dh - (dh // 2) left, right = dw // 2, dw - (dw // 2) im = cv2.copyMakeBorder(im, top, bottom, left, right, cv2.BORDER_CONSTANT) return im
2. 标注坐标的动态适应
问题:
原始标注框的绝对坐标(如像素坐标 x=320, y=240)无法直接用于不同尺寸的输入。
方法:
- 归一化坐标转换:
将框的坐标转换到[0,1]的相对比例值(公式):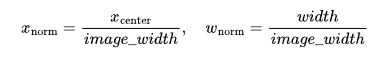
# 像素坐标 → YOLO归一化坐标 def convert_to_yolo(x1, y1, x2, y2, img_w, img_h): x_center = (x1 + x2) / (2 * img_w) y_center = (y1 + y2) / (2 * img_h) width = (x2 - x1) / img_w height = (y2 - y1) / img_h return [x_center, y_center, width, height]
3. 数据分布不平衡
问题:
训练集中小目标样本少、密集目标难检测。
方法:
数据增强策略:
- Mosaic增强:将4张图像拼接以模拟多尺度场景
- MixUp增强:叠加两张图像及其标签
- 随机裁剪/翻转/色彩扰动:增加光照、视角鲁棒性
# YOLOv5的Mosaic增强核心逻辑 def load_mosaic(self, index): # 随机选取3张额外图像构建4宫格 indices = [index] + random.choices(range(len(self)), k=3) # 将4张图像组合到640×640画布 for i, index in enumerate(indices): img, labels = self.load_image_and_labels(index) # 加载原始数据 if i == 0: # 放置左上角主图像 image = np.full((640, 640, 3), 114, dtype=np.uint8) xc, yc = (640 - img.shape[1]) // 2, (640 - img.shape[0]) // 2 image[yc:yc+h, xc:xc+w] = img # 其他3张同理...
4. 训练效率优化
问题:
大规模数据集加载速度慢,内存占用高。
方法:
- 预处理缓存机制:
将处理后的数据(缩放后的图像、标签)缓存为.cache文件,减少重复计算 - 多进程加载(DataLoader):
使用PyTorch的num_workers参数提升CPU-GPU并行效率
5. 异常标注过滤
问题:
标注错误(越界框、负尺寸)会导致训练崩溃。
方法:
- 自动质检器:
def check_annotations(bbox): x, y, w, h = bbox if (x + w/2 > 1.0) or (y + h/2 > 1.0): print("Warning: 目标框越界!") return False return True
二、典型数据处理流程(以YOLOv5为例)
- 原始数据加载:读取图像和对应的
.txt标签文件 - Letterbox调整:统一输入尺寸,保留长宽比
- 坐标逆变换:根据填充量反向修正标签中心点坐标(关键!)
x_center = (x_center_orig * r) + pad_x # r为缩放比例,pad为填充量 y_center = (y_center_orig * r) + pad_y - 数据增强:加入Mosaic、随机透视变换等扰动
- 归一化:像素值归一化到
[0,1](或标准化到ImageNet均值方差)
三、总结
YOLO数据处理的本质,是通过标准化、归一化和增强,将异构的真实世界数据转换为:
- 统一的数学模型可接受输入(如固定张量尺寸)
- 增强空间鲁棒性的样本分布
- 过滤噪声的纯净训练信号
最终实现**“让不同尺寸、光照、视角的目标,都能被统一模型高效检测”**的目标。