近红外光谱数据分析是一种重要的分析技术,广泛应用于化学、食品、制药、农业、环境科学等领域。以下是关于近红外光谱数据分析的详细介绍:
一、基本原理
近红外光谱的范围
近红外光谱是指波长范围在780 - 2500纳米的电磁辐射。在这个波段,分子的振动和转动跃迁是主要的光谱特征。特别是分子中的含氢基团(如C - H、N - H、O - H等)会在这个波段产生吸收,这些吸收特征可以用来分析物质的组成和结构。
光谱的产生机制
当近红外光照射到样品时,样品中的分子会吸收特定波长的光,使分子从基态跃迁到振动激发态。这种吸收过程与分子的结构密切相关。不同的分子结构会产生不同的吸收光谱,就像每个人的指纹一样具有独特性。
二、数据采集
仪器设备
近红外光谱仪是获取光谱数据的关键设备。它通常由光源、单色器、样品池、检测器和数据处理系统组成。光源发出的光经过单色器分光后照射到样品上,样品吸收部分光后,剩余的光被检测器接收并转化为电信号,最终通过数据处理系统得到光谱图。
现代近红外光谱仪有多种类型,如傅里叶变换近红外光谱仪(FT - NIR)、光栅扫描近红外光谱仪等。FT - NIR光谱仪具有扫描速度快、分辨率高、信噪比高等优点,是目前应用最广泛的类型之一。
样品准备
样品的制备对光谱数据的质量至关重要。对于固体样品,通常需要研磨成粉末,以保证样品的均匀性。对于液体样品,可以直接测量,但需要控制样品的浓度和厚度。样品的物理状态(如颗粒大小、表面状态)和化学状态(如水分含量、杂质含量)都会影响光谱的形状和强度。
光谱采集条件
采集光谱时需要设置合适的参数,如扫描范围、分辨率、扫描次数等。扫描范围一般根据分析的目标物质和仪器的性能来确定。分辨率越高,光谱的细节越丰富,但数据量也会增加。扫描次数越多,信噪比越高,但采集时间也会延长。
三、数据预处理
背景校正
由于仪器的噪声、样品池的反射等因素,采集到的光谱数据中可能会包含背景信号。背景校正的目的是去除这些无关的信号,使光谱数据更准确地反映样品的真实信息。常用的方法是采集空白样品(如空气或纯溶剂)的光谱,然后从样品光谱中减去空白光谱。
基线校正
基线是指光谱图中没有吸收的水平线。由于仪器漂移、样品的散射等因素,基线可能会发生偏移或弯曲。基线校正的方法有多种,如多项式拟合法、迭代最小二乘法等。通过基线校正,可以使光谱的基线平直,便于后续的分析。
光谱平滑
采集到的光谱数据中可能会包含随机噪声,这些噪声会干扰光谱的特征提取。光谱平滑可以减少噪声的影响,使光谱更加光滑。常用的平滑方法有移动平均法、Savitzky - Golay平滑法等。Savitzky - Golay平滑法不仅可以平滑光谱,还可以对光谱进行微分处理,增强光谱的特征。
归一化
归一化是将光谱数据的强度调整到一个统一的范围内,例如0 - 1或 - 1 - 1。归一化可以使不同样品的光谱数据具有可比性,同时也有助于后续的建模和分析。常见的归一化方法有最大值归一化、面积归一化等。
四、数据分析方法
定性分析
光谱匹配法
这是最简单的定性分析方法。将采集到的未知样品的光谱与已知标准物质的光谱进行比较。如果两者的光谱形状和吸收峰位置非常相似,就可以判断未知样品中含有与标准物质相同的成分。例如,在分析某种植物叶片的成分时,可以将叶片的近红外光谱与已知的叶绿素、纤维素等成分的标准光谱进行匹配。
主成分分析(PCA)
主成分分析是一种多变量统计分析方法。它通过将原始光谱数据投影到一个新的坐标系中,提取出主要的变异信息。在主成分分析中,每个主成分是一个新的变量,它是原始变量的线性组合。通过分析主成分的得分图,可以识别样品的类别和异常样品。例如,在食品质量控制中,可以将不同批次的食品样品的光谱数据进行主成分分析,根据得分图将合格样品和不合格样品区分开来。
定量分析
偏最小二乘回归(PLS)
偏最小二乘回归是一种常用的定量分析方法。它通过建立光谱数据与待测成分浓度之间的线性关系模型,实现对未知样品中成分浓度的预测。PLS模型可以同时考虑多个光谱变量和多个响应变量,具有很强的抗干扰能力。在制药行业,可以利用PLS模型根据药物的近红外光谱数据快速准确地测定药物中有效成分的含量。
人工神经网络(ANN)
人工神经网络是一种模拟人脑神经元网络的计算模型。它可以根据大量的训练样本学习光谱数据与待测成分浓度之间的非线性关系。ANN模型具有很强的自适应性和泛化能力,可以处理复杂的光谱数据。例如,在环境监测中,可以利用ANN模型根据水样的近红外光谱数据预测水样中污染物的浓度。
支持向量机(SVM)
支持向量机是一种基于统计学习理论的分类和回归方法。它通过寻找最优的分类超平面或回归超平面,实现对光谱数据的分类或定量分析。SVM模型在处理高维数据和小样本数据时具有很好的性能。在农产品品质检测中,可以利用SVM模型根据农产品的近红外光谱数据快速准确地检测农产品的品质指标,如糖分含量、酸度等。
五、模型验证
内部验证
内部验证是通过将已知浓度的标准样品的光谱数据代入定量分析模型,计算模型的预测值与实际值之间的偏差来评估模型的性能。常用的内部验证指标有决定系数(R²)、均方根误差(RMSE)等。R²越接近1,RMSE越小,说明模型的拟合效果越好。
外部验证
外部验证是将模型应用于未知样品的光谱数据,通过实验测定未知样品的实际浓度,然后与模型的预测浓度进行比较。外部验证可以评估模型的泛化能力和实际应用价值。如果模型在外部验证中表现出良好的预测精度,说明模型具有较高的可靠性和实用性。
近红外光谱数据分析是一个系统的过程,从数据采集到预处理,再到分析和模型验证,每一步都需要精心设计和操作。通过合理运用各种分析方法和模型验证手段,可以充分发挥近红外光谱技术的优势,为科学研究和实际应用提供有力支持。
ChatGPT4.0在科研工作中的各种使用方法与技巧,以及人工智能领域经典机器学习算法(BP神经网络、支持向量机、决策树、随机森林、变量降维与特征选择、群优化算法等)和热门深度学习方法(卷积神经网络、迁移学习、自编码器、U-Net等)的基本原理及Python、Pytorch代码实现方法。
第一章、ChatGPT4入门基础
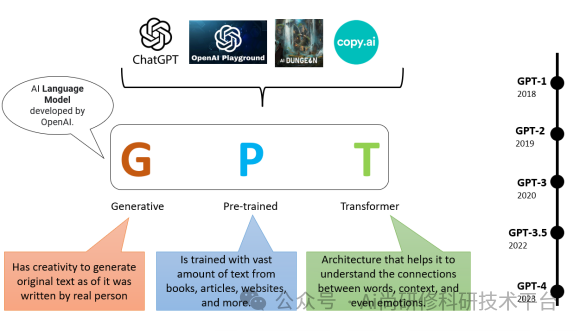
1、ChatGPT概述(GPT-1、GPT-2、GPT-3、GPT-3.5、GPT-4模型的演变)
2、ChatGPT对话初体验(注册与充值、购买方法)
3、GPT-4与GPT-3.5的区别,以及与国内大语言模型(文心一言、星火等)的区别
4、ChatGPT科研必备插件(Data Interpreter、Wolfram、WebPilot、MixerBox Scholar、ScholarAI、Show Me、AskYourPDF等)
5、定制自己的专属GPTs(制作专属GPTs的两种方式:聊天/配置参数、利用Knowledge上传本地知识库提升专属GPTs性能、利用Actions通过API获取外界信息、专属GPTs的分享)
6、GPT Store简介
7、案例
第二章、ChatGPT4 提示词使用方法与技巧
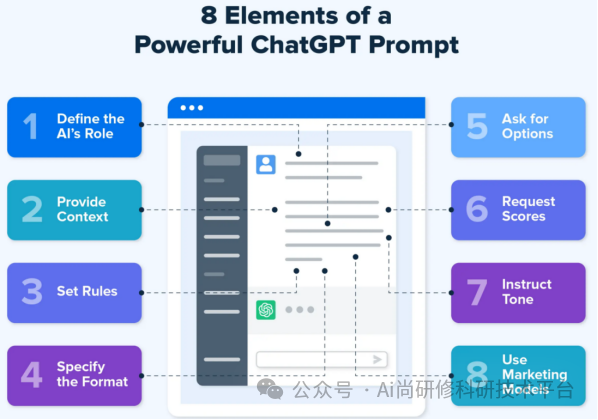
1、ChatGPT Prompt (提示词)使用技巧(为ChatGPT设定身份、明确任务内容、提供任务相关的背景、举一个参考范例、指定返回的答案格式等)
2、常用的ChatGPT提示词模板
3、基于模板的ChatGPT提示词优化
4、利用ChatGPT4 及插件优化提示词
5、通过promptperfect.jina.ai优化提示词
6、利用ChatGPT4 及插件生成提示词
7、ChatGPT4突破Token限制实现接收或输出万字长文(什么是Token?Token数与字符数之间的互相换算、五种方法提交超过Token限制的文本、四种方法让ChatGPT的输出突破Token限制)
8、控制ChatGPT的输出长度(使用修饰语、限定回答的范围、通过上下文限定、限定数量等)
9、利用ChatGPT4 及插件保存喜欢的ChatGPT提示词并一键调用
10、案例演示:利用ChatGPT4实现网页版游戏的设计、代码自动生成与运行
11、实操练习
第三章、ChatGPT4助力信息检索与总结分析
1、传统信息检索方法与技巧总结(Google Scholar、ResearchGate、Sci-Hub、GitHub、关键词检索+同行检索、文献订阅)
2、利用ChatGPT4 及插件实现联网检索文献
3、利用ChatGPT4及插件总结分析文献内容(三句话摘要、子弹式要点摘要、QA摘要、表格摘要、关键词与关键句提取、页面定位、多文档对比、情感分析)
4、利用ChatGPT4 及插件总结Youtube视频内容
5、案例
第四章、ChatGPT4助力论文写作与投稿
1、利用ChatGPT4自动生成论文的总体框架
2、利用ChatGPT4完成论文翻译(指定翻译角色和翻译的领域、给一些背景提示)
3、利用ChatGPT4实现论文语法校正
4、利用ChatGPT4完成段落结构及句子逻辑润色
5、利用ChatGPT4完成论文评审意见的撰写与回复
6、案例

第五章、ChatGPT4助力Python入门基础
1、Python环境搭建( 下载、安装与版本选择)。
2、如何选择Python编辑器?(IDLE、Notepad++、PyCharm、Jupyter…)
3、Python基础(数据类型和变量、字符串和编码、list和tuple、条件判断、循环、函数的定义与调用等)
4、第三方模块的安装与使用
5、Numpy模块库(Numpy的安装;ndarray类型属性与数组的创建;数组索引与切片;Numpy常用函数简介与使用)
6、Matplotlib基本图形绘制(线形图、柱状图、饼图、气泡图、直方图、箱线图、散点图等)、图形的布局(多个子图绘制、规则与不规则布局绘制、向画布中任意位置添加坐标轴)
第六章、ChatGPT4助力近红外光谱数据预处理
1、近红外光谱数据标准化与归一化(为什么需要标准化与归一化?)
2、近红外光谱数据异常值、缺失值处理
3、近红外光谱数据离散化及编码处理
4、近红外光谱数据一阶导数与二阶导数
5、近红外光谱数据去噪与基线校正
6、近红外光谱数据预处理中的ChatGPT提示词模板
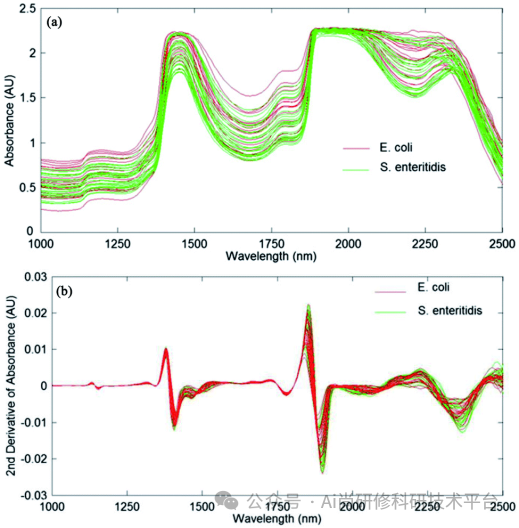
第七章、ChatGPT4助力多元线性回归近红外光谱分析
1、多元线性回归模型(工作原理、最小二乘法)
2、岭回归模型(工作原理、岭参数k的选择、用岭回归选择变量)
3、LASSO模型(工作原理、特征选择、建模预测、超参数调节)
4、Elastic Net模型(工作原理、建模预测、超参数调节)
5、多元线性回归、岭回归、LASSO、Elastic Net的Python代码实现
6、多元线性回归中的ChatGPT提示词模板
7、案例演示:近红外光谱回归拟合建模
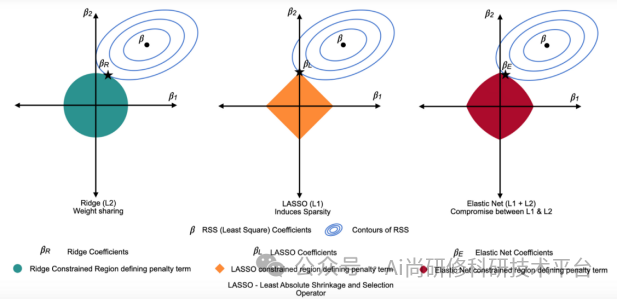
第八章、ChatGPT4助力BP神经网络近红外光谱分析
1、BP神经网络的基本原理(人工智能发展过程经历了哪些曲折?人工神经网络的分类有哪些?BP神经网络的拓扑结构和训练过程是怎样的?什么是梯度下降法?)
2、训练集和测试集划分?BP神经网络常用激活函数有哪些?如何查看模型参数?
3、BP神经网络参数(隐含层神经元个数、学习率)的优化(交叉验证)
4、值得研究的若干问题(欠拟合与过拟合、评价指标的设计、样本不平衡问题等)
5、BP神经网络的Python代码实现
6、BP神经网络中的ChatGPT提示词模板讲解
7、案例演示:1)近红外光谱回归拟合建模;2)近红外光谱分类识别建模
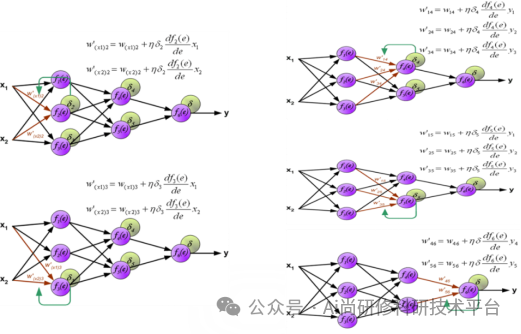
第九章、ChatGPT4助力支持向量机(SVM)近红外光谱分析
1、SVM的基本原理(什么是经验误差最小和结构误差最小?SVM的本质是解决什么问题?SVM的四种典型结构是什么?核函数的作用是什么?什么是支持向量?)
2、SVM扩展知识(如何解决多分类问题?SVM的启发:样本重要性排序及样本筛选)
3、SVM的Python代码实现
4、SVM中的ChatGPT提示词模板讲解
5、案例演示:近红外光谱分类识别建模
第十章、ChatGPT4助力决策树、随机森林、Adaboost、XGBoost和LightGBM近红外光谱分析
1、决策树的基本原理(什么是信息熵和信息增益?ID3和C4.5算法的区别与联系)
2、随机森林的基本原理与集成学习框架(为什么需要随机森林算法?广义与狭义意义下的“随机森林”分别指的是什么?“随机”提现在哪些地方?随机森林的本质是什么?)
4、Bagging与Boosting集成策略的区别
5、Adaboost算法的基本原理
6、Gradient Boosting Decision Tree (GBDT)模型的基本原理
7、XGBoost与LightGBM简介
8、决策树、随机森林、Adaboost、XGBoost与LightGBM的Python代码实现
9、决策树、随机森林、Adaboost、XGBoost与LightGBM的ChatGPT提示词模板讲解
10、案例:近红外光谱回归拟合建模
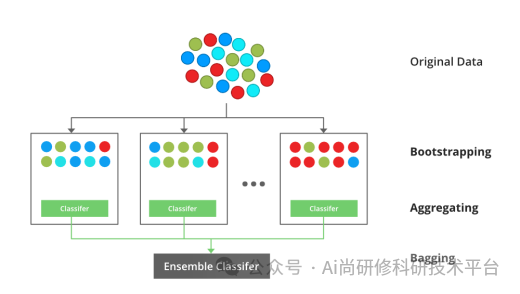
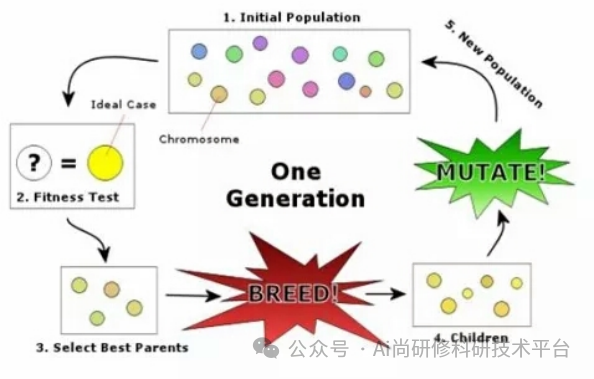
第十一章、ChatGPT4助力遗传算法近红外光谱分析
1、群优化算法概述
2、遗传算法(Genetic Algorithm)的基本原理(什么是个体和种群?什么是适应度函数?选择、交叉与变异算子的原理与启发式策略)
3、遗传算法的Python代码实现
4、遗传算法中的ChatGPT提示词模板讲解
5、案例:基于二进制遗传算法的近红外光谱波长筛选
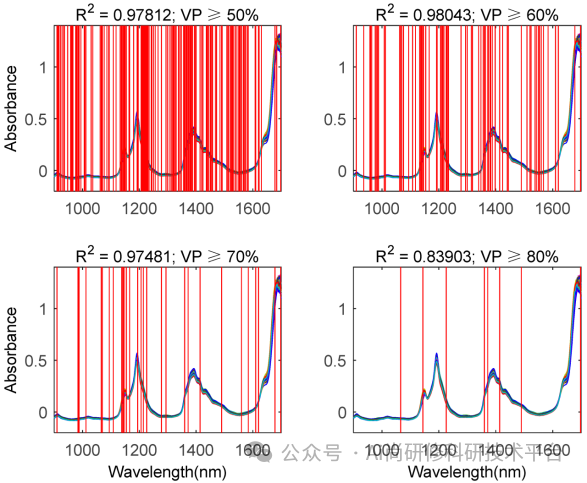
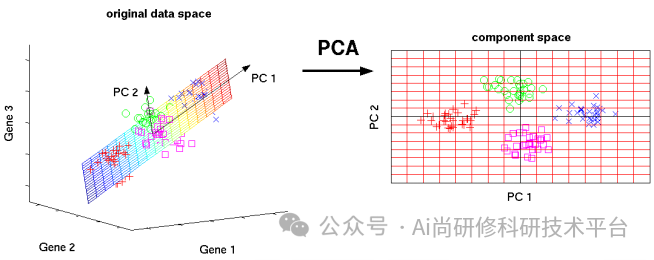
第十二章、ChatGPT4助力近红外光谱变量降维与特征选择
1、主成分分析(PCA)的基本原理
2、偏最小二乘(PLS)的基本原理(PCA与PLS的区别与联系;PCA除了降维之外,还可以帮助我们做什么?)
3、近红外光谱波长选择算法的基本原理(Filter和Wrapper;前向与后向选择法;区间法;无信息变量消除法等)
4、PCA、PLS、特征选择算法的Python代码实现
5、PCA、PLS、特征选择算法中的ChatGPT提示词模板讲解
6、案例:
1)基于L1正则化的近红外光谱波长筛选
2)基于信息熵的近红外光谱波长筛选
3)基于Recursive feature elimination的近红外光谱波长筛选
4)基于Forward-SFS的近红外光谱波长筛选
第十三章、ChatGPT4助力Pytorch入门基础
1、深度学习框架概述(PyTorch、Tensorflow、Keras等)
2、PyTorch简介(动态计算图与静态计算图机制、PyTorch的优点)
3、PyTorch的安装与环境配置(Pip vs. Conda包管理方式、验证是否安装成功)
4、张量(Tensor)的定义,以及与标量、向量、矩阵的区别与联系)
5、张量(Tensor)的常用属性与方法(dtype、device、requires_grad、cuda等)
6、张量(Tensor)的创建(直接创建、从numpy创建、依据概率分布创建)
7、张量(Tensor)的运算(加法、减法、矩阵乘法、哈达玛积(element wise)、除法、幂、开方、指数与对数、近似、裁剪)
8、张量(Tensor)的索引与切片
9、PyTorch的自动求导(Autograd)机制与计算图的理解
10、PyTorch常用工具包及API简介(torchvision(transforms、datasets、model)、torch.nn、torch.optim、torch.utils(Dataset、DataLoader))
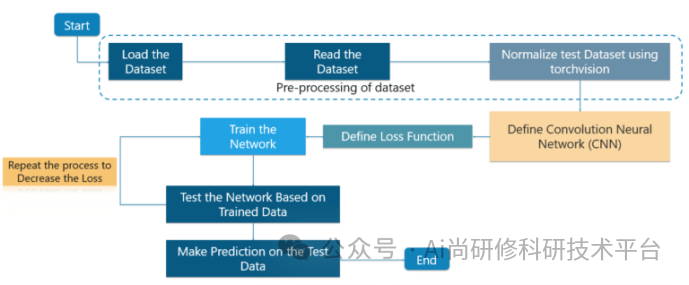
第十四章、ChatGPT4助力卷积神经网络近红外光谱分析
1、深度学习与传统机器学习的区别与联系(神经网络的隐含层数越多越好吗?深度学习与传统机器学习的本质区别是什么?)
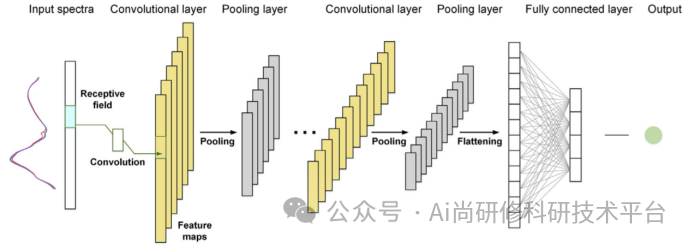
2、卷积神经网络的基本原理(什么是卷积核?CNN的典型拓扑结构是怎样的?CNN的权值共享机制是什么?CNN提取的特征是怎样的?)
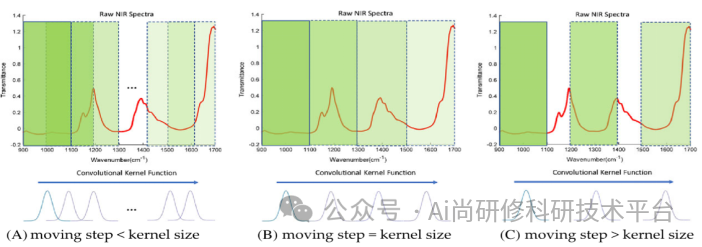
3、卷积神经网络参数调试技巧(卷积核尺寸、卷积核个数、移动步长、补零操作、池化核尺寸等参数与特征图的维度,以及模型参数量之间的关系是怎样的?)
4、卷积神经网络的进化史:LeNet、AlexNet、Vgg-16/19、GoogLeNet、ResNet等经典深度神经网络的区别与联系
5、利用PyTorch构建卷积神经网络(Convolution层、Batch Normalization层、Pooling层、Dropout层、Flatten层等)
6、卷积神经网络中的ChatGPT提示词模板讲解
7、案例:(1)CNN预训练模型实现物体识别;(2)利用卷积神经网络抽取抽象特征;(3)自定义卷积神经网络拓扑结构;(4)基于卷积神经网络的近红外光谱模型建立
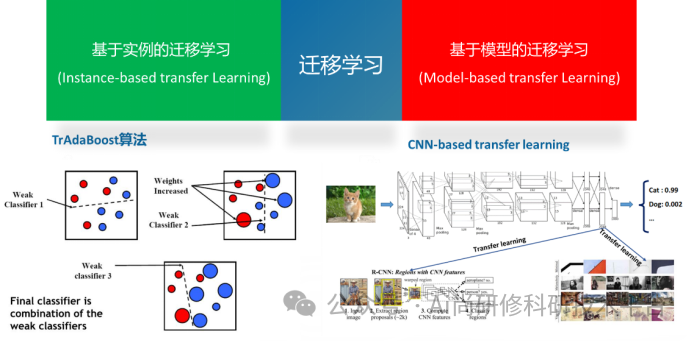
第十五章、ChatGPT4助力近红外光谱迁移学习
1、迁移学习算法的基本原理(为什么需要迁移学习?为什么可以迁移学习?迁移学习的基本思想是什么?)
2、常用的迁移学习算法简介(基于实例、特征和模型,譬如:TrAdaboost算法)
3、基于卷积神经网络的迁移学习算法
4、迁移学习的Python代码实现
5、案例演示:基于迁移学习的近红外光谱的模型传递(模型移植)
第十六章、ChatGPT4助力自编码器近红外光谱分析
1、自编码器(Auto-Encoder的工作原理)
2、常见的自编码器类型简介(降噪自编码器、深度自编码器、掩码自编码器等)
3、自编码器的Python代码实现
4、自编码器中的ChatGPT提示词模板讲解
5、案例演示:
1)基于自编码器的近红外光谱数据预处理
2)基于自编码器的近红外光谱数据降维与有效特征提取

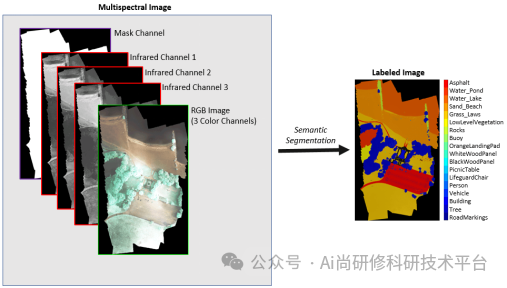
第十七章、ChatGPT4助力U-Net多光谱图像语义分割
1、语义分割(Semantic Segmentation)简介
2、U-Net模型的基本原理
3、语义分割、U-Net模型中的ChatGPT提示词模板讲解
4、案例演示:基于U-Net的多光谱图像语义分割
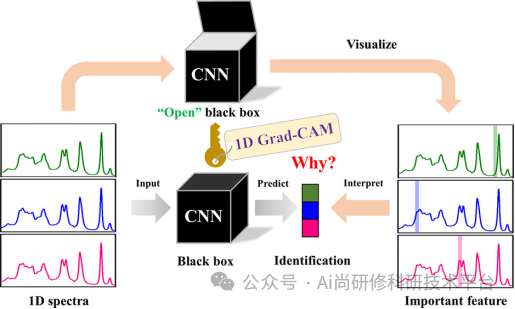
第十八章、ChatGPT4助力深度学习模型可解释性与可视化方法
1、什么是模型可解释性?为什么需要对深度学习模型进行解释?
2、常用的可视化方法有哪些(特征图可视化、卷积核可视化、类别激活可视化等)?
3、类激活映射CAM(Class Activation Mapping)、梯度类激活映射GRAD-CAM、局部可解释模型-敏感LIME(Local Interpretable Model-agnostic Explanation)等原理讲解
4、t-SNE的基本概念及使用t-SNE可视化深度学习模型的高维特征
5、深度学习模型可解释性与可视化中的ChatGPT提示词模板讲解
6、案例演示
第十九章、总结
1、资料分享(图书、在线资源、源代码等)
2、科研与创新方法总结(如何利用Google Scholar、Sci-Hub、ResearchGate等工具查阅文献资料、配套的数据和代码?如何更好地撰写论文的Discussion部分?)


