文章目录
数据集准备

- 数据集常常被分为3部分:训练集(training data)、验证集(validation data)、测试集(testing data)。
- 训练集(training data):用于训练网络模型或确定网络模型参数
- 验证集(validation data):在模型训练过程中,辅助模型优化,通过验证集测试模型的拟合情况;确定一些超参数
- 测试集(testing data):训练完后用来测试训练后模型的泛化能力。
- 数据划分的常见技巧:
- 将数据分为训练、集和测试集,比例可为 8 : 2 8:2 8:2。
- 将数据继续分为训练集、验证集、测试集, 最终比例为 8 : 2 : 2.5 8:2:2.5 8:2:2.5。
- 对训练集随机抽样为小集合,用来训练,并在验证集上记录性能。
- 打散训练集、测试集、验证集中数据的排列方式,井重新训练。
- 从训练集中随机抽取 80% 的数据进行多次训练,把训练集中剩下的数据作为验证集,观察不同抽取结果在测试集中的性能,把最好训练结果当作最终模型。
数据集扩展
- 深度学习依赖大量标注数据,但数据收集成本高昂。以图像分类为例,需通过爬虫等方式获取标注图片,耗费大量人力。医学图像等稀缺正样本更难获取,如每张医学正样本对应一位病患,收集尤为困难。
- 图像数据扩展的常用方法包括:
- 几何变换:旋转、平移、缩放、翻转等;
- 色彩调整:亮度、饱和度、色调的缩放或偏移;
- 像素级操作:整体加减噪声或数值扰动。
# 导入必要的库
import torch
from torchvision import transforms
from PIL import Image
import os
# 设置设备:自动检测是否有 CUDA(GPU)可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")
# 加载原始图像并确保是 RGB 格式(3通道)
img = Image.open('./girl.png').convert('RGB')
# 定义图像增强操作流水线
# 注意:PyTorch 的 transforms 是按顺序执行的函数链
transform = transforms.Compose([
# 随机旋转图像,最大角度为20度
transforms.RandomRotation(20),
# 随机平移图像,横向和纵向移动范围为图像尺寸的 20%
transforms.RandomAffine(
degrees=0,
translate=(0.2, 0.2),
scale=(0.9, 1.1),
fill=0
),
# 随机水平翻转图像,概率默认为0.5
transforms.RandomHorizontalFlip(0.6),
# 随机调整亮度,亮度变化因子在 [0.8, 1.2] 范围内
transforms.ColorJitter(brightness=0.2),
# 将 PIL 图像转换为 PyTorch Tensor(数值范围变为 [0, 1])
transforms.ToTensor(),
transforms.Resize((img.height, img.width)) # 保持原始尺寸
])
# 应用定义好的 transform,将图像转换为 Tensor,并增加一个 batch 维度:
# 原始 shape: (C, H, W) -> 添加 batch 后: (1, C, H, W)
tensor_img = transform(img).unsqueeze(0)
# 将图像张量移动到指定设备(CPU 或 GPU),以便后续加速处理
tensor_img = tensor_img.to(device)
# 定义保存 Tensor 类型图像的函数
def save_tensor_image(tensor, path):
"""
将 GPU 上的 Tensor 转换回 CPU 并保存为图像文件。
参数:
tensor (torch.Tensor): 形状为 [1, C, H, W] 的图像张量
path (str): 图像保存路径
"""
# 移动到 CPU,并去除 batch 维度
tensor = tensor.cpu().squeeze()
# 使用 ToPILImage 将 Tensor 转换为 PIL 图像对象
img_pil = transforms.ToPILImage()(tensor)
# 保存图像
img_pil.save(path)
# 创建输出目录(如果不存在)
os.makedirs('./preview', exist_ok=True)
# 循环生成 20 张增强后的图像
for i in range(20):
with torch.no_grad(): # 禁止梯度计算,节省内存和计算资源
augmented_tensor = tensor_img # 此处可替换为模型推理逻辑
# 构建保存路径
save_path = f'./preview/girl_{i+1}.png'
# 保存图像
save_tensor_image(augmented_tensor, save_path)
# 打印日志
print(f"Saved {save_path}")
数据预处理
- 在数据矩阵中通过不同的提取方式获得不同列的数据,有些数据值特别大、有些数据则是小数,例如 np.array([1024, 222, 0.0216, 0.0412, 19566]),由于数据高度不对称,算法无法处理所有不在同一维度的数据,最终可能会导致网络模型训练失败。因此在获得数据集后,有必要对数据进行预处理操作,使得数据分布无偏低方差。
- 四种预处理的常用方法:
- 0均值(Zero Centralization)
- 归一化(Normalization)
- 主成分分析(Principal Component Analysis,PCA)
- 白化(Whitening)
1. 0均值(Zero Centralization)
- 0均值化是一种常见的数据预处理方法,通过减去每个维度的均值,使数据以0为中心分布
代码实现
import numpy as np
def zero_mean(data):
"""
对数据进行0均值化处理
参数:
data -- 输入数据,形状为(n_samples, n_features)
返回:
zero_mean_data -- 0均值化后的数据
mean_vals -- 每个特征的均值
"""
# 计算每个特征的均值
mean_vals = np.mean(data, axis=0)
# 减去均值
zero_mean_data = data - mean_vals
return zero_mean_data, mean_vals
# 示例使用
if __name__ == "__main__":
# 创建示例数据 (5个样本,3个特征)
data = np.array([
[1.0, 2.0, 3.0],
[4.0, 5.0, 6.0],
[7.0, 8.0, 9.0],
[10.0, 11.0, 12.0],
[13.0, 14.0, 15.0]
])
print("原始数据:")
print(data)
# 应用0均值化
zero_mean_data, means = zero_mean(data)
print("\n每个特征的均值:", means)
print("\n0均值化后的数据:")
print(zero_mean_data)
# 验证处理后数据的均值是否为0
print("\n处理后数据的均值:", np.mean(zero_mean_data, axis=0))
原始数据:
[[ 1. 2. 3.]
[ 4. 5. 6.]
[ 7. 8. 9.]
[10. 11. 12.]
[13. 14. 15.]]
每个特征的均值: [7. 8. 9.]
0均值化后的数据:
[[-6. -6. -6.]
[-3. -3. -3.]
[ 0. 0. 0.]
[ 3. 3. 3.]
[ 6. 6. 6.]]
处理后数据的均值: [0. 0. 0.]
2. 归一化(Normalization)
- 归一化是将数据按比例缩放,使之落入一个小的特定区间(如[0,1]或[-1,1])的方法,常用于消除量纲影响。

实现方法:
- Min-Max归一化:将数据线性变换到[0,1]范围
- Z-Score归一化:基于均值与标准差进行缩放
代码实现
import numpy as np
def min_max_normalize(data):
"""
Min-Max归一化到[0,1]范围
参数:
data -- 输入数据,形状为(n_samples, n_features)
返回:
normalized_data -- 归一化后的数据
min_vals -- 每个特征的最小值
max_vals -- 每个特征的最大值
"""
min_vals = np.min(data, axis=0)
max_vals = np.max(data, axis=0)
normalized_data = (data - min_vals) / (max_vals - min_vals + 1e-8) # 加小值防止除以0
return normalized_data, min_vals, max_vals
def z_score_normalize(data):
"""
Z-Score归一化(均值0,标准差1)
参数:
data -- 输入数据,形状为(n_samples, n_features)
返回:
normalized_data -- 归一化后的数据
mean_vals -- 每个特征的均值
std_vals -- 每个特征的标准差
"""
mean_vals = np.mean(data, axis=0)
std_vals = np.std(data, axis=0)
normalized_data = (data - mean_vals) / (std_vals + 1e-8) # 加小值防止除以0
return normalized_data, mean_vals, std_vals
# 示例使用
if __name__ == "__main__":
data = np.array([
[1.0, 2.0, 3.0],
[4.0, 5.0, 6.0],
[7.0, 8.0, 9.0],
[10.0, 11.0, 12.0],
[13.0, 14.0, 15.0]
])
print("Min-Max归一化:")
norm_data, mins, maxs = min_max_normalize(data)
print(norm_data)
print("\nZ-Score归一化:")
z_data, means, stds = z_score_normalize(data)
print(z_data)
Min-Max归一化:
[[0. 0. 0. ]
[0.25 0.25 0.25]
[0.5 0.5 0.5 ]
[0.75 0.75 0.75]
[1. 1. 1. ]]
Z-Score归一化:
[[-1.41421356 -1.41421356 -1.41421356]
[-0.70710678 -0.70710678 -0.70710678]
[ 0. 0. 0. ]
[ 0.70710678 0.70710678 0.70710678]
[ 1.41421356 1.41421356 1.41421356]]
3. 主成分分析(Principal Component Analysis, PCA)
- PCA是一种线性降维方法,通过正交变换将可能相关的变量转换为一组线性不相关的变量(主成分)。可用于提取数据的主要特征分量,常用于高维数据的降维。
- PCA的目的是寻找有效表示数据主轴的方向。
- 在机器学习或者数据挖掘算法中,数据预处理时可以通过主成分分析进行降维,有效减少后续计算量、降低数据噪声,使得神经网络、 SVM等分类器呈现更好的效果。
实现步骤
- 数据0均值化
- 计算协方差矩阵
- 计算特征值和特征向量
- 选择主成分并转换数据
- 在对数据进行主成分分析之前,不能直接求数据的协方差矩阵,首先需要把数据经过0均值 处理,然后才能计算其协方差矩阵,得到数据不同维度之间的相关性。
代码实现
import numpy as np
def pca(data, n_components=None):
"""
PCA降维实现
参数:
data -- 输入数据,形状为(n_samples, n_features)
n_components -- 保留的主成分数量
返回:
transformed_data -- 降维后的数据
explained_variance_ratio -- 各主成分的方差解释比例
"""
# 0均值化
mean_vals = np.mean(data, axis=0)
centered_data = data - mean_vals
# 计算协方差矩阵
cov_matrix = np.cov(centered_data, rowvar=False)
# 计算特征值和特征向量
eigenvalues, eigenvectors = np.linalg.eig(cov_matrix)
# 按特征值降序排序
sorted_idx = np.argsort(eigenvalues)[::-1]
eigenvalues = eigenvalues[sorted_idx]
eigenvectors = eigenvectors[:, sorted_idx]
# 计算方差解释比例
explained_variance_ratio = eigenvalues / np.sum(eigenvalues)
# 确定保留的主成分数量
if n_components is None:
n_components = data.shape[1]
elif 0 < n_components < 1:
# 按累计方差解释比例选择
cum_explained = np.cumsum(explained_variance_ratio)
n_components = np.where(cum_explained >= n_components)[0][0] + 1
# 选择主成分
components = eigenvectors[:, :n_components]
# 转换数据
transformed_data = np.dot(centered_data, components)
return transformed_data, explained_variance_ratio[:n_components]
# 示例使用
if __name__ == "__main__":
data = np.array([
[1.0, 2.0, 3.0],
[4.0, 5.0, 6.0],
[7.0, 8.0, 9.0],
[10.0, 11.0, 12.0],
[13.0, 14.0, 15.0]
])
print("PCA降维结果:")
pca_data, explained = pca(data, n_components=2)
print("降维后数据:\n", pca_data)
print("方差解释比例:", explained)
PCA降维结果:
降维后数据:
[[-1.03923048e+01 -6.66133815e-16]
[-5.19615242e+00 -3.33066907e-16]
[ 0.00000000e+00 0.00000000e+00]
[ 5.19615242e+00 3.33066907e-16]
[ 1.03923048e+01 6.66133815e-16]]
方差解释比例: [1. 0.]
- SVD 分解一个很好的特性,因为返回的U矩阵是按照其特征值的大小排序的,排在前面的就是主方向,因此可以通过选取前几个特征向量来降低数据的维度, 这就是主成分分析的降维方法。
- SVD实现方法
def pca_with_svd(data, n_components):
mean_vals = np.mean(data, axis=0) # 对输入的数据×进行0均值计算
centered_data = data - mean_vals # 取数据矩阵×的协方差矩阵
# 使用 SVD 分解
U, S, Vt = np.linalg.svd(centered_data) # 协方差矩阵 SVD分解
# 右奇异向量即为主成分方向
components = Vt[:n_components].T
transformed_data = np.dot(centered_data, components)
# 方差解释比例可由奇异值平方得到
explained_variance_ratio = (S[:n_components] ** 2) / np.sum(S ** 2)
return transformed_data, explained_variance_ratio
4. 白化(Whitening)
- 白化是一种数据预处理方法,目的是使特征之间不相关且具有相同的方差(单位方差)。
- 白花的目的是降低数据的冗余性。通过白化操作数据具有以下性质:
- 特征之间相关性较低
- 所有特征具有相同的方差
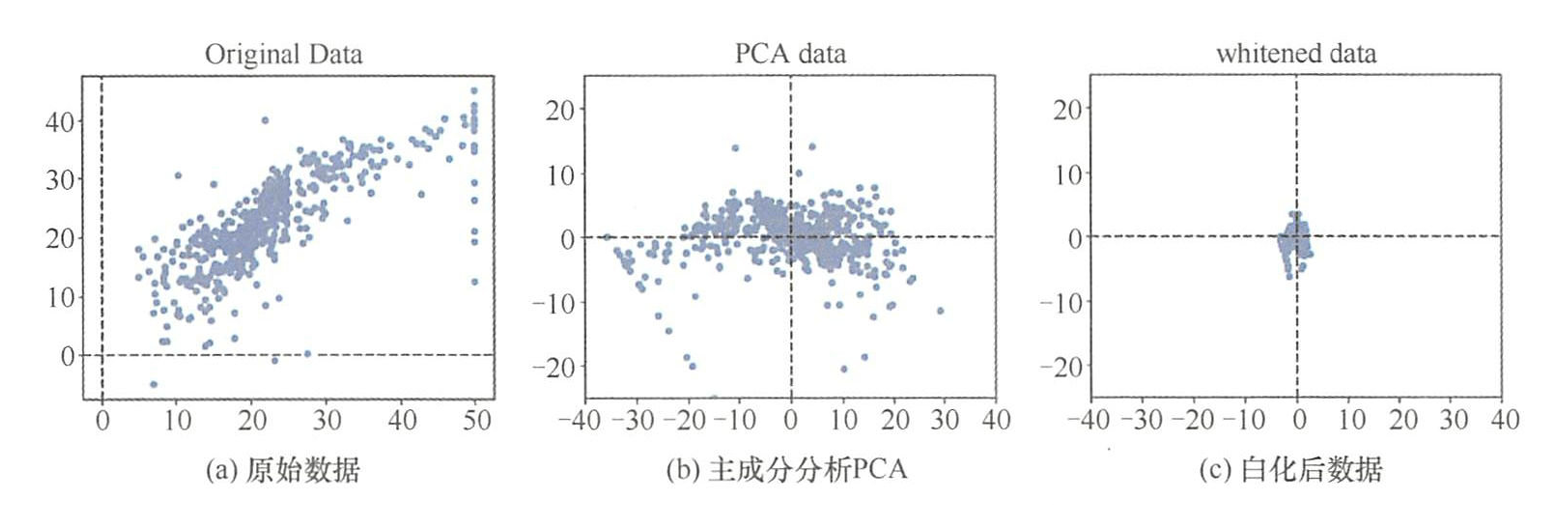
- PCA处理后的数据集,数据以坐标原点为中心,并且根据协方差的特征基进行旋转。白化处理后的数据,每一维的数据根据特征值进行缩放,白化后数据符合高斯分布。
- 白化的过程只需要把通过主成分分析去相关后的数据,从对角矩阵再变成单位矩阵,使得数据具有相同的方差。
实现步骤
- 数据0均值化
- 计算PCA
- 对主成分进行缩放使方差为1
代码实现
import numpy as np
def whitening(data, epsilon=1e-5):
"""
数据白化处理
参数:
data -- 输入数据,形状为(n_samples, n_features)
epsilon -- 防止除以0的小常数
返回:
whitened_data -- 白化后的数据
"""
# 0均值化
mean_vals = np.mean(data, axis=0)
centered_data = data - mean_vals
# 计算协方差矩阵
cov_matrix = np.cov(centered_data, rowvar=False)
# 计算特征值和特征向量
eigenvalues, eigenvectors = np.linalg.eig(cov_matrix)
# 白化变换矩阵
whitening_matrix = np.dot(
eigenvectors,
np.dot(np.diag(1.0 / np.sqrt(eigenvalues + epsilon)), eigenvectors.T)
)
# 应用白化变换
whitened_data = np.dot(centered_data, whitening_matrix)
return whitened_data
# 示例使用
if __name__ == "__main__":
data = np.array([
[1.0, 2.0, 3.0],
[4.0, 5.0, 6.0],
[7.0, 8.0, 9.0],
[10.0, 11.0, 12.0],
[13.0, 14.0, 15.0]
])
print("白化处理结果:")
whitened_data = whitening(data)
print(whitened_data)
# 验证协方差矩阵近似单位矩阵
print("\n白化后数据的协方差矩阵:")
print(np.cov(whitened_data, rowvar=False))
白化处理结果:
[[-0.73029669 -0.73029669 -0.73029669]
[-0.36514834 -0.36514834 -0.36514834]
[ 0. 0. 0. ]
[ 0.36514834 0.36514834 0.36514834]
[ 0.73029669 0.73029669 0.73029669]]
白化后数据的协方差矩阵:
[[0.33333328 0.33333328 0.33333328]
[0.33333328 0.33333328 0.33333328]
[0.33333328 0.33333328 0.33333328]]
特点对比
| 方法 | 目的 | 主要效果 |
|---|---|---|
| 0均值 | 中心化数据 | 均值为0 |
| 归一化 | 消除量纲 | 数据在固定范围 |
| PCA | 降维/去相关 | 特征不相关,保留主要方差 |
| 白化 | 去相关+单位方差 | 协方差矩阵为单位矩阵 |
- 这些预处理方法常组合使用,顺序一般为:0均值 → PCA → 白化。根据具体任务需求选择合适的方法组合。
网络初始化
- 在深度学习模型定义后,权重 W W W和偏置 b b b的初始化至关重要。若全部初始化为 0 0 0,会导致以下问题:
- 对称性问题:所有神经元的输出相同,反向传播时梯度一致,参数更新完全对称,模型无法学习有效特征。
- 训练失效:最终模型退化为无效状态。
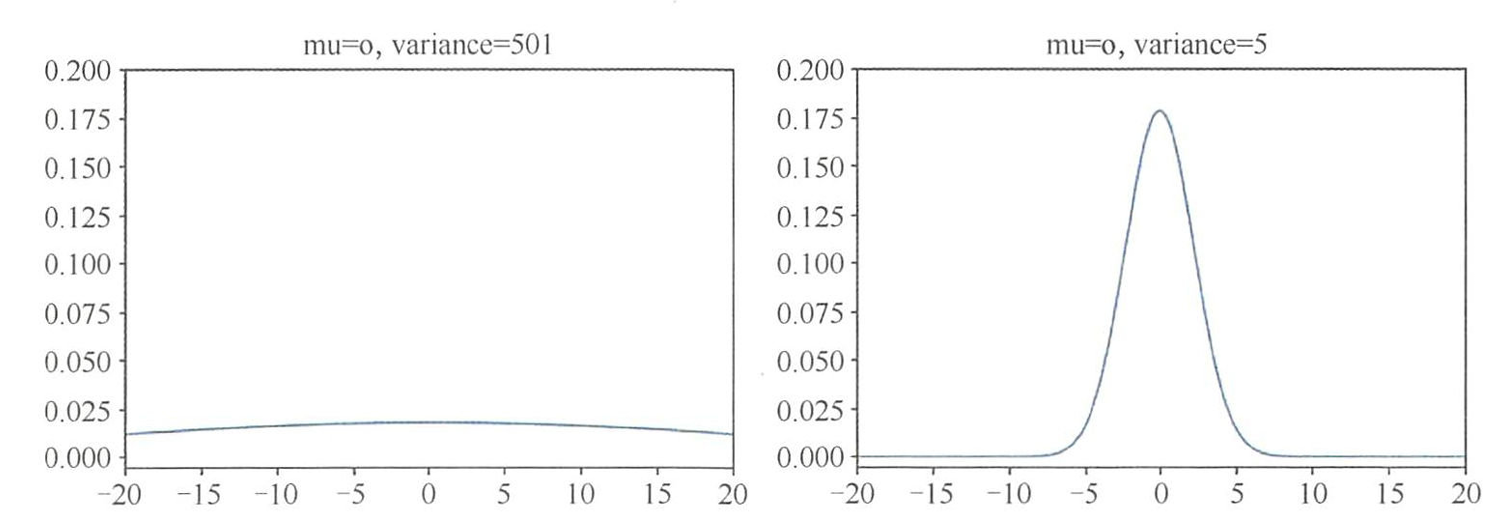
解决方案:采用独立高斯随机初始化(均值为 0,方差较小),使初始权重。
- 足够小以保持稳定性;
- 随机性打破对称性,确保梯度多样性。
优点:
- 避免对称性导致的训练停滞;
- 符合深度学习框架的常规实践(如 He/Xavier 初始化本质是高斯分布的变体)。
import matplotlib.pyplot as plt
import numpy as np
def neurous(sqrt=False,num=1000,b=0):
"""神经元模型"""
x=np.ones(num)
if not sqrt:
w=np.random.rand(num)
else:
w=np.random.rand(num)/np.sqrt(num)
return np.dot(w,x)+b
z1=[]
for i in range(100000):
z1.append(neurous(sqrt=True))
plt.hist(z1,100,alpha=0.8)
plt.show()
sigmoid=lambda x:1/(1+np.exp(-x))
a1=sigmoid(np.array(z1))
plt.hist(a1,100,alpha=0.8)
plt.show()
在实际实践中,为节省时间,使用ImageNet 数据集己经预先训练好的模型,加载到网络中然后开始训练。预先训练好的模型参数己经根据某数据规则经过长时间的训练,网络参数经过一定程度的优化,直接使用该优化参数可以降低重新训练可能造成的优化失败,并减少过度拟合的情况,有效节省大量的时间。
代码示例:使用预训练模型(如基于ImageNet的VGG16)进行迁移学习,包括模型加载、编译、训练和评估的全流程
import numpy as np
import tensorflow as tf
from tensorflow.keras.applications import VGG16 # 使用预训练的VGG16模型
from tensorflow.keras.layers import Dense, GlobalAveragePooling2D
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.preprocessing.image import ImageDataGenerator
# 1. 加载预训练模型(不包含顶层分类器)
base_model = VGG16(weights='imagenet', include_top=False, input_shape=(224, 224, 3))
# 2. 自定义顶层结构(适应新任务)
x = base_model.output
x = GlobalAveragePooling2D()(x) # 全局平均池化替代Flatten
x = Dense(1024, activation='relu')(x)
predictions = Dense(10, activation='softmax')(x) # 假设新任务有10类
model = Model(inputs=base_model.input, outputs=predictions)
# 3. 冻结预训练层的权重(可选)
for layer in base_model.layers:
layer.trainable = False # 初始阶段冻结,避免破坏已有特征
# 4. 编译模型(注意损失函数和指标的正确拼写)
model.compile(
loss="categorical_crossentropy",
optimizer=Adam(learning_rate=1e-3),
metrics=['accuracy'] # 修正拼写:acuracy -> accuracy
)
# 5. 数据准备(示例使用ImageDataGenerator)
train_datagen = ImageDataGenerator(
rescale=1./255,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True
)
train_generator = train_datagen.flow_from_directory(
'data/train',
target_size=(224, 224),
batch_size=32,
class_mode='categorical'
)
# 6. 模型训练(使用fit_generator处理大数据集)
history = model.fit(
train_generator,
steps_per_epoch=len(train_generator),
epochs=10,
verbose=1
)
# 7. 解冻部分层进行微调(进阶步骤)
for layer in base_model.layers[-4:]:
layer.trainable = True # 只微调最后几层
model.compile(
optimizer=Adam(learning_rate=1e-5), # 更小的学习率
loss="categorical_crossentropy",
metrics=['accuracy']
)
# 8. 继续训练
model.fit(train_generator, epochs=5, verbose=1)
# 9. 模型保存
model.save('fine_tuned_model.h5')
网络过拟合(Over Fitting)
- 过拟合:当一个模型从样本中学习到的特征不能够推广到其他新数据,过度拟合发生后,模型试图使用不相关的特征对新数据进行预测,最终导致网络模型预测的结果出错。
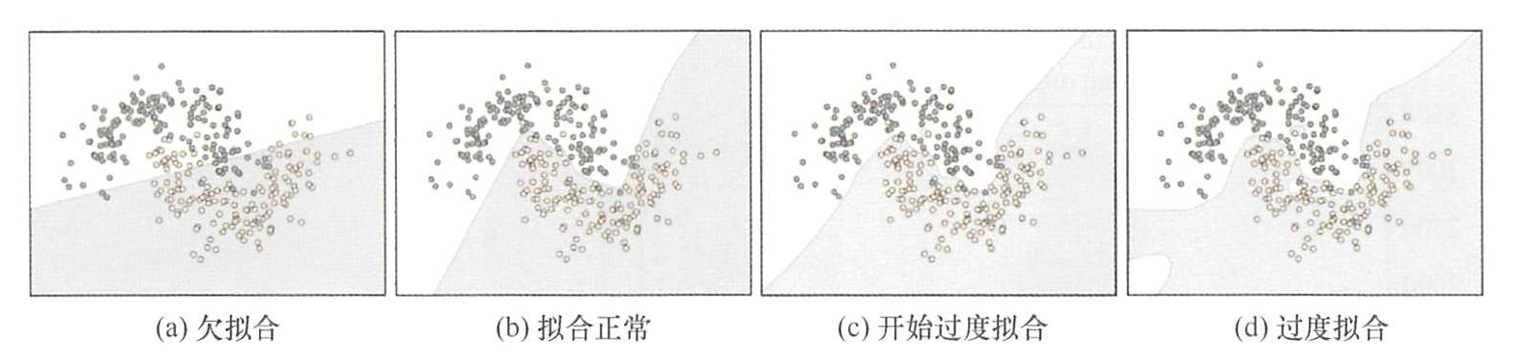
- 当出现过拟合时,增加训练数据量和多样性是直接有效的方法,但仅靠数据扩充可能不足,因为新增数据仍可能存在高相关性。解决过拟合的核心在于控制模型的"容量"(即网络存储信息的能力):
- 高容量模型能学习更多特征,提升性能,但也可能记忆无关特征
- 低容量模型会聚焦关键特征,从而增强泛化能力
调整模型容量的主要方法:
- 结构调节:改变网络层数和每层神经元数量
- 正则化:在权重更新时施加约束
正则化方法
- 正则化的最大作用是防止过度拟合,提高网络模型的泛化能力。
- 具体实现方法是在损失函数中增加惩罚因子。
- 通过使用正则化技术实现惩罚不重要的特征,防止过拟合。
- 正则化包括L1范式、L2范式、最大约束范式、引入Dropout层。
L1正则化
- L1正则化是在原始的损失函数后面加上一个Ll 正则化项 λ n ∑ i n ∣ w i ∣ \frac{\lambda}{n} \sum_i^{n}|w_i| nλ∑in∣wi∣
- L1正则化公式:
L = L 0 + λ n ∑ i n ∣ w i ∣ L=L_0+\frac{\lambda}{n} \sum_i^{n}|w_i| L=L0+nλi∑n∣wi∣ - L1 正则化的目的就是让权值趋向于 0(当权值为正时,更新后的权值变小; 当权值为负时, 更新后的权值变大),使得神经网络中的权值尽可能小(减小了网络复杂度),防止过拟合。
- 一般使用 L2 正则化。 因为 L1 范式会产生稀疏f晖,具有一定特征选择能力,对求解高维特征空间比较有用; L2范式主要是为了防止过度拟合
L2正则化
- L2 正则化就是在损失函数后面增加上L2正则化项 λ 2 n ∑ i n w i 2 \frac{\lambda}{2n} \sum_{i}^{n}w_i^{2} 2nλ∑inwi2
- L2正则化公式:
L = L 0 + λ 2 n ∑ i n w i 2 L=L_0+\frac{\lambda}{2n} \sum_{i}^{n}w_i^{2} L=L0+2nλi∑nwi2 - L2 正则化公式求导:
∂ L ∂ w = ∂ L 0 ∂ w + λ n w \frac{\partial L}{\partial w}=\frac{\partial L_0}{\partial w}+\frac{\lambda}{n}w ∂w∂L=∂w∂L0+nλw - 上式带入梯度下降公式:
w ← ( 1 − η λ n ) w − η ∂ L 0 ∂ w w\leftarrow(1-\eta \frac{\lambda}{n})w-\eta\frac{\partial L_0}{\partial w} w←(1−ηnλ)w−η∂w∂L0 - 使用 L 2 L2 L2正则化后权值 w w w前面的系数为 1 − η λ n 1-\eta \frac{\lambda}{n} 1−ηnλ,使得权值 w w w的系数恒小于1。
- L2 正则化就是用来惩罚特征的权值 w w w的,学术上称为权值衰减(WeightDecay)。
- L2 正则化确实能够让权值变得更小,它可以用于防止过度拟合的原因在于更小的权值表示神经网络的复杂度更低、网络参数越小,这说明网络模型相对简单,越简单的模型引起过度拟合的可能性越小。
最大约束范式(Max-Norm 正则化)
- 原理:限制每个神经元的权重大小,防止权重过大导致过拟合。
具体做法:
- 正常更新网络权重。
- 对每个神经元的权重进行约束,使其满足 ∥ w ∥ 2 ≤ c \|w\|_2 \leq c ∥w∥2≤c(通常 c = 3 c = 3 c=3 或 4 4 4)。
优点:
- 即使学习率较大,也能防止权重膨胀,减少过拟合风险。
- 训练数据越多、多样性越强,正则化的作用越小(因为数据本身已降低过拟合可能)。
引入Dropout层
原理:训练时随机“关闭”部分神经元(使其输出为 0),防止神经元之间过度依赖,从而提升泛化能力。
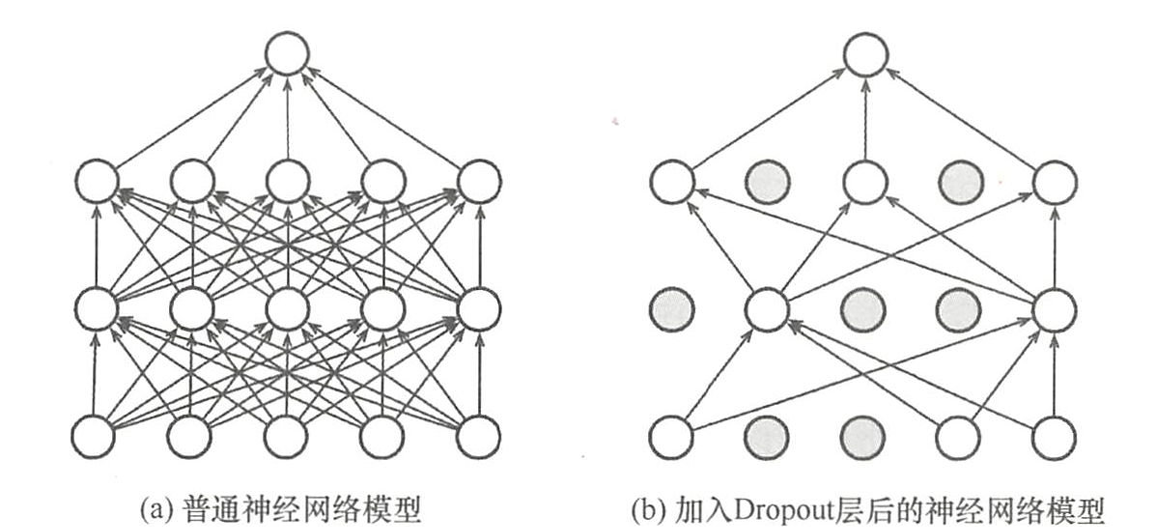
为什么有效?
- 每次训练时随机丢弃部分神经元,迫使网络不依赖单个神经元,减少特征间的协同依赖,避免过拟合。
适用情况:
- 大型网络:Dropout 能有效防止过拟合,但会增加训练时间。
- 小型网络:可能不需要 Dropout,甚至可能降低性能(过拟合风险低)。
如何判断是否使用 Dropout?
- 如果验证集和训练集的误差/准确率接近,说明没有过拟合,可以不用 Dropout 以加快训练。
总结对比
| 方法 | 实现方式 | 适用场景 | 注意事项 |
|---|---|---|---|
| 最大约束范式 | 限制权重大小 | 通用,尤其适合权重控制 | 需选择合适的约束值 ( c ) |
| Dropout | 随机关闭神经元 | 大型网络,过拟合风险高 | 小型网络可能不需要 |
- 两种方法均可独立或组合使用,具体选择取决于模型大小和数据情况。
训练中的技巧
精确率曲线和损失曲线
- 深度神经网络模型的训练时间比 SVM、 Adaboost 等机器学习分类器的训练时间相对要长,因此训练时不应等待训练结束,应持续观察精确率曲线和损失值曲线。如果发现精确率曲线不满足期望,那么可以及时停止训练,分析其原因,修改网络参数或者调整网络模型后重新训练。
- 如果在精确率曲线上发现训练和验证集的精确率差异越来越大,模型可能过拟合。可以及时停止网络模型的训练,向网络模型加入L2 正则化或者添加 Dropout 层等防止过度拟合的方法。
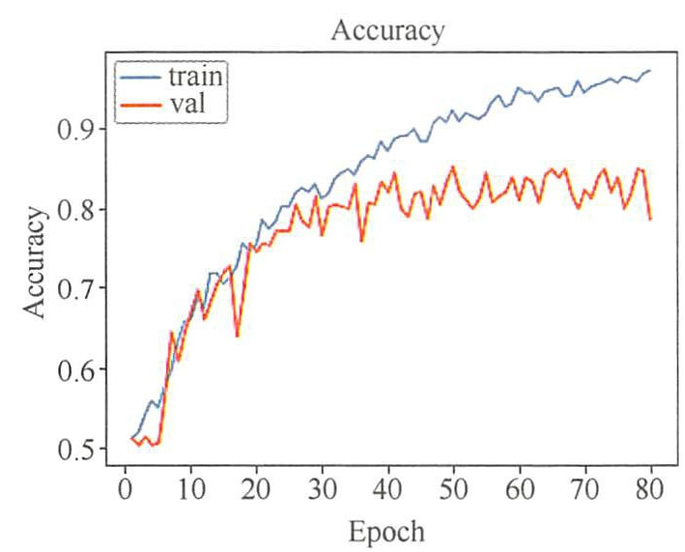
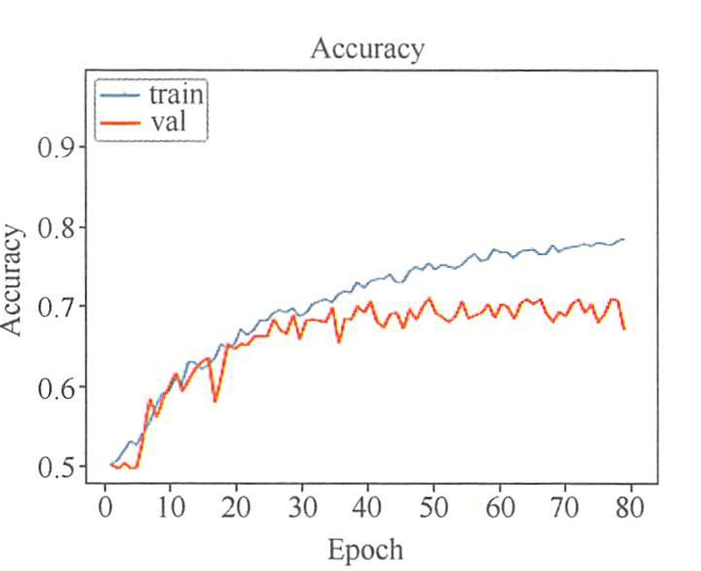
- 如果验证集和训练集的精确率曲线差别较少,但是两者精度都无法继续提升,经网络模型的学习能力差,不能有效提取输入数据的高维特征。可以通过对数据集进行扩展来增强数据的多样性,或者通过修改神经网络模型来增加网络中的“熵容量”,从而提高该网络的学习能力。
网络微调fine-tune
网络模型的微调:将预先训练好的模型权重文件的整体或者某部分用到类似的任务中。优点是节省训练时间,能够避免数据集较小导致数据过拟合的情况。
- 当网络模型修改预测分类时. (从 1000 个分类改为 20 个分类〉,并不需要重新训练该神经网络,只需在修改完网络的输出层参数后微调最后几层全连接层,即可保持在之前的分类准确率的情况下得到新的模型文件。
- 当只增加模型的训练样本数时,只需要对浅层网络层进行一个小规模的网络微调迭代,不需要重新训练网络。
- 当新数据集和预训练模型的数据集相似,且数据集较小,只需对预训练模型的深层网络进行网络微调。
- 如果数据集非常庞大,可以使用较小的学习率,对预训练模型的深层网络进行微调。
如果新数据集与原始数据的差异很大,网络微调的效果较差,建议重新训练网络。