PyTorch和torchvision为例,如何使用预训练的ResNet模型来训练水稻虫害分类数据集 14类 从数据准备到模型训练、评估全流程
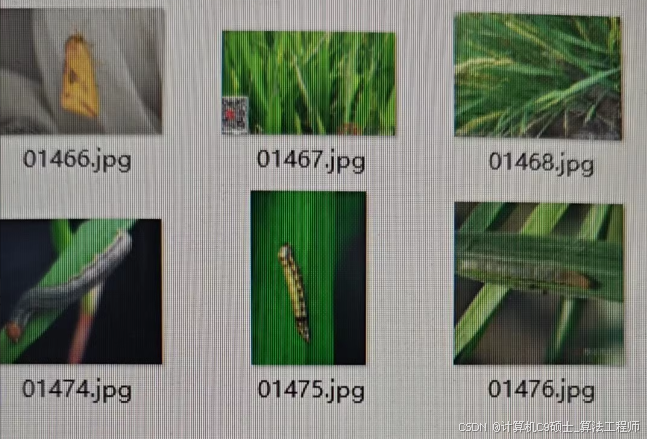
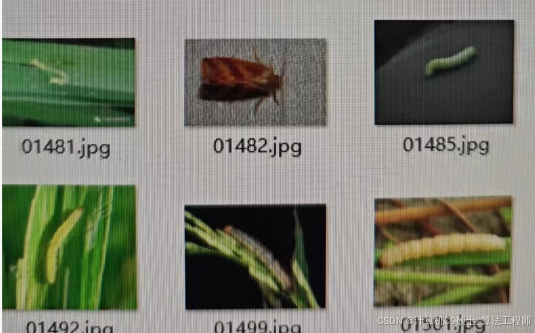
水稻虫害分类数据集
包含14个类别共8417张图像:稻纵卷叶螟(rice leaf roller)、稻叶毛虫(rice leaf caterpillar)、稻潜叶蝇(paddy stem maggot)、水稻二化螟(asiatic rice borer)、水稻三化螟(yellow rice borer)、稻瘿蚊(rice gall midge)、稻秆蝇(Rice Stemfly)
褐稻虱(brown plant hopper)、白背飞虱(white backed plant)、灰飞虱(small brown plant)、稻水象甲(rice water weevil)、稻叶蝉(rice leafhopper)、谷物撒布机蓟马(grain spreader thrips)、稻苞虫(rice shell pest),训练集、验证集、测试集分别有5043、843、2531张
使用适合图像分类任务的模型进行处理。对于图像分类任务,可以使用ResNet、EfficientNet等深度学习模型。这里以PyTorch和torchvision为例,展示如何使用预训练的ResNet模型来训练这个水稻虫害分类数据集。
1. 环境准备
确保安装了必要的依赖项:
pip install torch torchvision torchaudio matplotlib
2. 数据准备
首先,确保您的数据集按照以下结构组织:
path/to/dataset/
train/
rice_leaf_roller/
img1.jpg
img2.jpg
...
rice_leaf_caterpillar/
img1.jpg
img2.jpg
...
...
val/
rice_leaf_roller/
img1.jpg
img2.jpg
...
rice_leaf_caterpillar/
img1.jpg
img2.jpg
...
...
test/ # 如果有测试集的话
rice_leaf_roller/
img1.jpg
img2.jpg
...
rice_leaf_caterpillar/
img1.jpg
img2.jpg
...
...

3. 数据加载与增强
使用torchvision.datasets.ImageFolder来加载数据,并应用一些数据增强技术。
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
# 定义数据预处理流程
data_transforms = {
'train': transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'val': transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}
data_dir = './path/to/dataset'
image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x), data_transforms[x]) for x in ['train', 'val']}
dataloaders = {x: DataLoader(image_datasets[x], batch_size=32, shuffle=True, num_workers=4) for x in ['train', 'val']}
dataset_sizes = {x: len(image_datasets[x]) for x in ['train', 'val']}
class_names = image_datasets['train'].classes
4. 模型定义与训练
使用预训练的ResNet模型并进行微调。
import torch.nn as nn
import torch.optim as optim
from torchvision import models
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 加载预训练的ResNet模型
model_ft = models.resnet18(pretrained=True)
num_ftrs = model_ft.fc.in_features
# 更改最后全连接层的输出为类别数
model_ft.fc = nn.Linear(num_ftrs, len(class_names))
model_ft = model_ft.to(device)
criterion = nn.CrossEntropyLoss()
# 观察所有参数都更新
optimizer_ft = optim.SGD(model_ft.parameters(), lr=0.001, momentum=0.9)
# 每7个epoch后降低学习率
exp_lr_scheduler = optim.lr_scheduler.StepLR(optimizer_ft, step_size=7, gamma=0.1)
训练模型
def train_model(model, criterion, optimizer, scheduler, num_epochs=25):
best_model_wts = model.state_dict()
best_acc = 0.0
for epoch in range(num_epochs):
print(f'Epoch {epoch}/{num_epochs - 1}')
print('-' * 10)
# 每个epoch都有训练和验证阶段
for phase in ['train', 'val']:
if phase == 'train':
model.train() # 设置模型为训练模式
else:
model.eval() # 设置模型为评估模式
running_loss = 0.0
running_corrects = 0
# 迭代数据
for inputs, labels in dataloaders[phase]:
inputs = inputs.to(device)
labels = labels.to(device)
# 零参数梯度
optimizer.zero_grad()
# 前向传播
with torch.set_grad_enabled(phase == 'train'):
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
# 只在训练阶段反向传播和优化
if phase == 'train':
loss.backward()
optimizer.step()
# 统计损失
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
if phase == 'train':
scheduler.step()
epoch_loss = running_loss / dataset_sizes[phase]
epoch_acc = running_corrects.double() / dataset_sizes[phase]
print(f'{phase} Loss: {epoch_loss:.4f} Acc: {epoch_acc:.4f}')
# 深拷贝模型
if phase == 'val' and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = model.state_dict()
print(f'Best val Acc: {best_acc:4f}')
# 加载最佳模型权重
model.load_state_dict(best_model_wts)
return model
# 训练并保存最佳模型
model = train_model(model_ft, criterion, optimizer_ft, exp_lr_scheduler, num_epochs=25)
torch.save(model.state_dict(), './rice_pest_classification_resnet.pth')
5. 测试模型(可选)
如果有一个单独的测试集,可以使用相似的方法来评估模型性能。
test_dataset = datasets.ImageFolder(os.path.join(data_dir, 'test'), data_transforms['val'])
test_dataloader = DataLoader(test_dataset, batch_size=32, shuffle=False, num_workers=4)
model.eval()
running_corrects = 0
for inputs, labels in test_dataloader:
inputs = inputs.to(device)
labels = labels.to(device)
with torch.no_grad():
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
running_corrects += torch.sum(preds == labels.data)
accuracy = running_corrects.double() / len(test_dataset)
print(f'Test Accuracy: {accuracy:.4f}')
以上步骤提供了一个完整的流程,从环境配置到数据准备、模型训练及评估的具体实现。确保你根据实际情况调整路径和其他设置。